

2020년 새로운 Java 기본 면접 질문 요약


Java에서 ==, Equals, hashCode의 차이점
(더 많은 면접 질문 추천: java 면접 질문 및 답변)
1. ==
Java의 데이터 유형은 두 가지 범주로 나눌 수 있습니다. :
기본 데이터 유형, 기본 데이터 유형이라고도 함 byte, short, char, int, long, float, double, boolean을 비교하려면 이중 등호(==)를 사용하고 해당 값을 비교합니다.
참조 유형(클래스, 인터페이스, 배열) (==)를 사용하여 비교할 때 메모리의 저장 주소를 비교합니다. 따라서 동일한 새 개체가 아닌 경우 비교 결과는 true이고, 그렇지 않으면 비교 결과는 false입니다. 객체는 힙에 배치되고 객체의 참조(주소)는 스택에 저장됩니다. 먼저 가상 머신 메모리 맵과 코드를 살펴보세요.
public class testDay {
public static void main(String[] args) {
String s1 = new String("11");
String s2 = new String("11");
System.out.println(s1 == s2);
System.out.println(s1.equals(s2));
}
}결과는 다음과 같습니다.
false
true

s1과 s2는 각각 해당 객체의 주소를 저장합니다. 따라서 s1== s2를 사용하면 두 객체의 주소 값을 비교(즉, 참조가 동일한지 여부)하는 결과가 거짓이 됩니다. 같음 방향을 호출하면 해당 주소의 값을 비교하므로 값이 true가 됩니다. 여기서는 equals()를 자세히 설명해야 합니다.
2.equals() 메소드에 대한 자세한 설명
equals() 메소드는 다른 객체가 이 객체와 동일한지 여부를 확인하는 데 사용됩니다. Object에 정의되어 있으므로 모든 객체에는 equals() 메서드가 있습니다. 차이점은 메서드가 재정의되는지 여부입니다.
먼저 소스 코드를 살펴보겠습니다.
public boolean equals(Object obj) { return (this == obj);
}분명히 Object는 두 객체의 주소 값 비교(즉, 참조가 동일한지 비교하는 것)를 정의합니다. 그런데 String에서 equals()를 호출하면 주소가 아닌 힙 메모리 주소의 값이 비교되는 이유는 무엇입니까? 여기서 핵심은 String, Math, Integer, Double 등의 캡슐화 클래스가 equals() 메서드를 사용할 때 이미 객체 클래스의 equals() 메서드를 다루었다는 것입니다. 문자열에서 다시 작성된 equals()를 살펴보세요:
public boolean equals(Object anObject) { if (this == anObject) { return true;
} if (anObject instanceof String) {
String anotherString = (String)anObject;
int n = value.length; if (n == anotherString.value.length) {
char v1[] = value;
char v2[] = anotherString.value;
int i = 0; while (n-- != 0) { if (v1[i] != v2[i]) return false;
i++;
} return true;
}
} return false;
}다시 작성한 후에는 내용 비교이며 더 이상 이전 주소 비교가 아닙니다. 비유하자면 Math, Integer, Double 등과 같은 클래스는 모두 내용을 비교하기 위해 equals() 메서드를 재정의합니다. 물론 기본 유형은 값 비교를 수행합니다.
equals() 메서드가 재정의되면 hashCode()도 재정의된다는 점에 유의해야 합니다. 일반 hashCode() 메소드의 구현에 따르면 동일한 객체는 동일한 해시코드를 가져야 합니다. 왜 그럴까요? 여기서는 해시코드에 대해 간단히 언급합니다.
3. hashcode()에 대한 간략한 토론
분명히 Java에서 ==, equals, hashCode의 차이점에 대한 질문인데 갑자기 hashcode()와 관련이 있는 이유는 무엇입니까? 당신은 매우 우울할 것입니다. 좋습니다. 간단한 예를 들어보겠습니다. 그러면 == 또는 같음일 때 hashCode가 관련되는 이유를 알게 될 것입니다.
예를 들어보겠습니다. 컬렉션에 객체가 포함되어 있는지 확인하려면 프로그램을 어떻게 작성해야 할까요? indexOf 메서드를 사용하지 않는 경우 컬렉션을 탐색하여 생각나는지 비교하면 됩니다. 컬렉션에 10,000개의 요소가 포함되어 있다면 피곤할 것 같은데요? 따라서 효율성을 높이기 위해 해시 알고리즘이 탄생했습니다. 핵심 아이디어는 컬렉션을 여러 저장 영역(버킷으로 볼 수 있음)으로 나누는 것입니다. 각 객체는 해시 코드를 계산할 수 있으며, 각 그룹은 특정 저장 영역에 해당합니다. 객체는 해시 코드에 따라 그룹화될 수 있습니다. 해당 해시 코드는 여러 저장 영역(다른 영역)으로 나눌 수 있습니다.
그래서 요소를 비교할 때 실제로는 해시코드를 먼저 비교하고, 같으면 같음 메서드를 비교합니다.
해시코드 다이어그램을 보세요:

객체에는 일반적으로 키와 값이 있습니다. 해당 hashCode 값은 키를 기반으로 계산된 다음 hashCode 값을 기반으로 다른 저장 영역에 저장됩니다. 위 그림에 나와 있습니다. 해시 충돌이 발생하기 때문에 서로 다른 영역에 여러 값을 저장할 수 있습니다. 단순: 서로 다른 두 개체의 hashCode가 동일한 경우 이 현상을 해시 충돌이라고 합니다. 간단히 말하면, hashCode는 동일하지만 같음은 값이 다르다는 의미입니다. 10,000개의 요소를 비교하기 위해 전체 컬렉션을 순회할 필요 없이 찾고자 하는 객체의 키에 대한 hashCode를 계산한 후 해당 hashCode에 해당하는 저장 영역을 찾으면 됩니다.

大概可以知道,先通过hashcode来比较,如果hashcode相等,那么就用equals方法来比较两个对象是否相等。再重写了equals最好把hashCode也重写。其实这是一条规范,如果不这样做程序也可以执行,只不过会隐藏bug。一般一个类的对象如果会存储在HashTable,HashSet,HashMap等散列存储结构中,那么重写equals后最好也重写hashCode。
总结:
- hashCode是为了提高在散列结构存储中查找的效率,在线性表中没有作用。
- equals重写的时候hashCode也跟着重写
- 两对象equals如果相等那么hashCode也一定相等,反之不一定。
2. int、char、long 各占多少字节数
byte 是 字节
bit 是 位
1 byte = 8 bit
char在java中是2个字节,java采用unicode,2个字节来表示一个字符
short 2个字节
int 4个字节
long 8个字节
float 4个字节
double 8个字节
3. int和Integer的区别
- Integer是int的包装类,int则是java的一种基本数据类型
- Integer变量必须实例化后才能使用,而int变量不需要
- Integer实际是对象的引用,当new一个Integer时,实际上是生成一个指针指向此对象;而int则是直接存储数据值
- Integer的默认值是null,int的默认值是0
延伸: 关于Integer和int的比较
- 由于Integer变量实际上是对一个Integer对象的引用,所以两个通过new生成的Integer变量永远是不相等的(因为new生成的是两个对象,其内存地址不同)。
Integer i = new Integer(100); Integer j = new Integer(100); System.out.print(i == j); //false
- Integer变量和int变量比较时,只要两个变量的值是向等的,则结果为true(因为包装类Integer和基本数据类型int比较时,java会自动拆包装为int,然后进行比较,实际上就变为两个int变量的比较)
Integer i = new Integer(100); int j = 100; System.out.print(i == j); //true
- 非new生成的Integer变量和new Integer()生成的变量比较时,结果为false。(因为非new生成的Integer变量指向的是java常量池中的对象,而new Integer()生成的变量指向堆中新建的对象,两者在内存中的地址不同)
Integer i = new Integer(100); Integer j = 100; System.out.print(i == j); //false
- 对于两个非new生成的Integer对象,进行比较时,如果两个变量的值在区间-128到127之间,则比较结果为true,如果两个变量的值不在此区间,则比较结果为false
Integer i = 100; Integer j = 100; System.out.print(i == j); //true
Integer i = 128; Integer j = 128; System.out.print(i == j); //false
对于第4条的原因: java在编译Integer i = 100 ;时,会翻译成为Integer i = Integer.valueOf(100);,而java API中对Integer类型的valueOf的定义如下:
public static Integer valueOf(int i){
assert IntegerCache.high >= 127; if (i >= IntegerCache.low && i <p>java对于-128到127之间的数,会进行缓存,Integer i = 127时,会将127进行缓存,下次再写Integer j = 127时,就会直接从缓存中取,就不会new了</p><h2 id="java多态的理解">4. java多态的理解</h2><h3 id="多态概述">1.多态概述</h3><ol>
<li><p>多态是继封装、继承之后,面向对象的第三大特性。</p></li>
<li><p>多态现实意义理解:</p></li>
</ol>现实事物经常会体现出多种形态,如学生,学生是人的一种,则一个具体的同学张三既是学生也是人,即出现两种形态。
Java作为面向对象的语言,同样可以描述一个事物的多种形态。如Student类继承了Person类,一个Student的对象便既是Student,又是Person。
多态体现为父类引用变量可以指向子类对象。
前提条件:必须有子父类关系。
注意:在使用多态后的父类引用变量调用方法时,会调用子类重写后的方法。
- 多态的定义与使用格式
定义格式:父类类型 变量名=new 子类类型();
2.多态中成员的特点
- 多态成员变量:编译运行看左边
Fu f=new Zi();
System.out.println(f.num);//f是Fu中的值,只能取到父中的值
- 多态成员方法:编译看左边,运行看右边
Fu f1=new Zi();
System.out.println(f1.show());//f1的门面类型是Fu,但实际类型是Zi,所以调用的是重写后的方法。
3.instanceof关键字
作用:用来判断某个对象是否属于某种数据类型。
* 注意: 返回类型为布尔类型
使用案例:
Fu f1=new Zi();
Fu f2=new Son();if(f1 instanceof Zi){
System.out.println("f1是Zi的类型");
}else{
System.out.println("f1是Son的类型");
}4.多态的转型
多态的转型分为向上转型和向下转型两种
-
向上转型:多态本身就是向上转型过的过程
使用格式:父类类型 变量名=new 子类类型();
适用场景:当不需要面对子类类型时,通过提高扩展性,或者使用父类的功能就能完成相应的操作。
-
向下转型:一个已经向上转型的子类对象可以使用强制类型转换的格式,将父类引用类型转为子类引用各类型
使用格式:子类类型 变量名=(子类类型)父类类型的变量;
适用场景:当要使用子类特有功能时。
5.多态案例:
例1:
package day0524;
public class demo04 {
public static void main(String[] args) {
People p=new Stu();
p.eat();
//调用特有的方法
Stu s=(Stu)p;
s.study();
//((Stu) p).study();
}
}
class People{
public void eat(){
System.out.println("吃饭");
}
}
class Stu extends People{
@Override
public void eat(){
System.out.println("吃水煮肉片");
}
public void study(){
System.out.println("好好学习");
}
}
class Teachers extends People{
@Override
public void eat(){
System.out.println("吃樱桃");
}
public void teach(){
System.out.println("认真授课");
}
}答案:吃水煮肉片 好好学习
例2:
请问题目运行结果是什么?
package day0524;
public class demo1 {
public static void main(String[] args) {
A a=new A();
a.show();
B b=new B();
b.show();
}
}
class A{
public void show(){
show2();
}
public void show2(){
System.out.println("A");
}
}
class B extends A{
public void show2(){
System.out.println("B");
}
}
class C extends B{
public void show(){
super.show();
}
public void show2(){
System.out.println("C");
}
}答案:A B
5. String、StringBuffer和StringBuilder区别
1、长度是否可变
- String 是被 final 修饰的,他的长度是不可变的,就算调用 String 的concat 方法,那也是把字符串拼接起来并重新创建一个对象,把拼接后的 String 的值赋给新创建的对象
- StringBuffer 和 StringBuilder 类的对象能够被多次的修改,并且不产生新的未使用对象,StringBuffer 与 StringBuilder 中的方法和功能完全是等价的。调用StringBuffer 的 append 方法,来改变 StringBuffer 的长度,并且,相比较于 StringBuffer,String 一旦发生长度变化,是非常耗费内存的!
2、执行效率
- 三者在执行速度方面的比较:StringBuilder > StringBuffer > String
3、应用场景
- 如果要操作少量的数据用 = String
- 单线程操作字符串缓冲区 下操作大量数据 = StringBuilder
- 多线程操作字符串缓冲区 下操作大量数据 = StringBuffer
StringBuffer和StringBuilder区别
1、是否线程安全
- StringBuilder 类在 Java 5 中被提出,它和 StringBuffer 之间的最大不同在于 StringBuilder 的方法不是线程安全的(不能同步访问),StringBuffer是线程安全的。只是StringBuffer 中的方法大都采用了 synchronized 关键字进行修饰,因此是线程安全的,而 StringBuilder 没有这个修饰,可以被认为是线程不安全的。
2、应用场景
- 由于 StringBuilder 相较于 StringBuffer 有速度优势,所以多数情况下建议使用 StringBuilder 类。
- 然而在应用程序要求线程安全的情况下,则必须使用 StringBuffer 类。 append方法与直接使用+串联相比,减少常量池的浪费。
6. 什么是内部类?内部类的作用
内部类的定义
将一个类定义在另一个类里面或者一个方法里面,这样的类称为内部类。
内部类的作用:
成员内部类 成员内部类可以无条件访问外部类的所有成员属性和成员方法(包括private成员和静态成员)。 当成员内部类拥有和外部类同名的成员变量或者方法时,会发生隐藏现象,即默认情况下访问的是成员内部类的成员。
局部内部类 局部内部类是定义在一个方法或者一个作用域里面的类,它和成员内部类的区别在于局部内部类的访问仅限于方法内或者该作用域内。
匿名内部类 匿名内部类就是没有名字的内部类
静态内部类 指被声明为static的内部类,他可以不依赖内部类而实例,而通常的内部类需要实例化外部类,从而实例化。静态内部类不可以有与外部类有相同的类名。不能访问外部类的普通成员变量,但是可以访问静态成员变量和静态方法(包括私有类型) 一个 静态内部类去掉static 就是成员内部类,他可以自由的引用外部类的属性和方法,无论是静态还是非静态。但是不可以有静态属性和方法
(学习视频推荐:java课程)
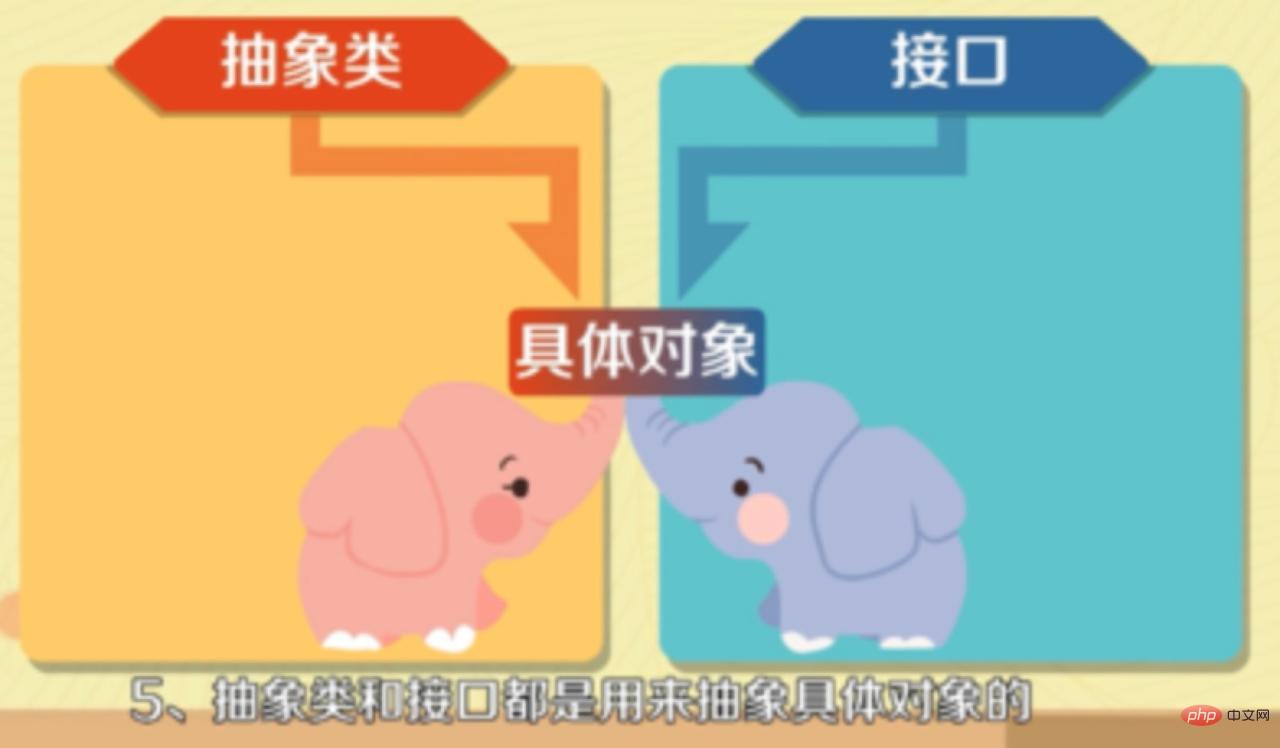
7. 추상 클래스와 인터페이스의 차이점
- 추상 클래스는 하위 클래스로 상속되어야 하고, 인터페이스는 클래스로 구현되어야 합니다.

- 인터페이스는 메서드 선언만 할 수 있는 반면 추상 클래스는 메서드 선언과 메서드 구현을 만들 수 있습니다.
- 인터페이스에 정의된 변수는 공개 정적 상수만 가능하며, 추상 클래스의 변수는 일반 변수입니다.
- 인터페이스는 디자인의 결과물이고 추상 클래스는 리팩토링의 결과물입니다.
- 추상 클래스와 인터페이스는 특정 객체를 추상화하는 데 사용되지만 인터페이스는 가장 높은 수준의 추상화를 갖습니다.
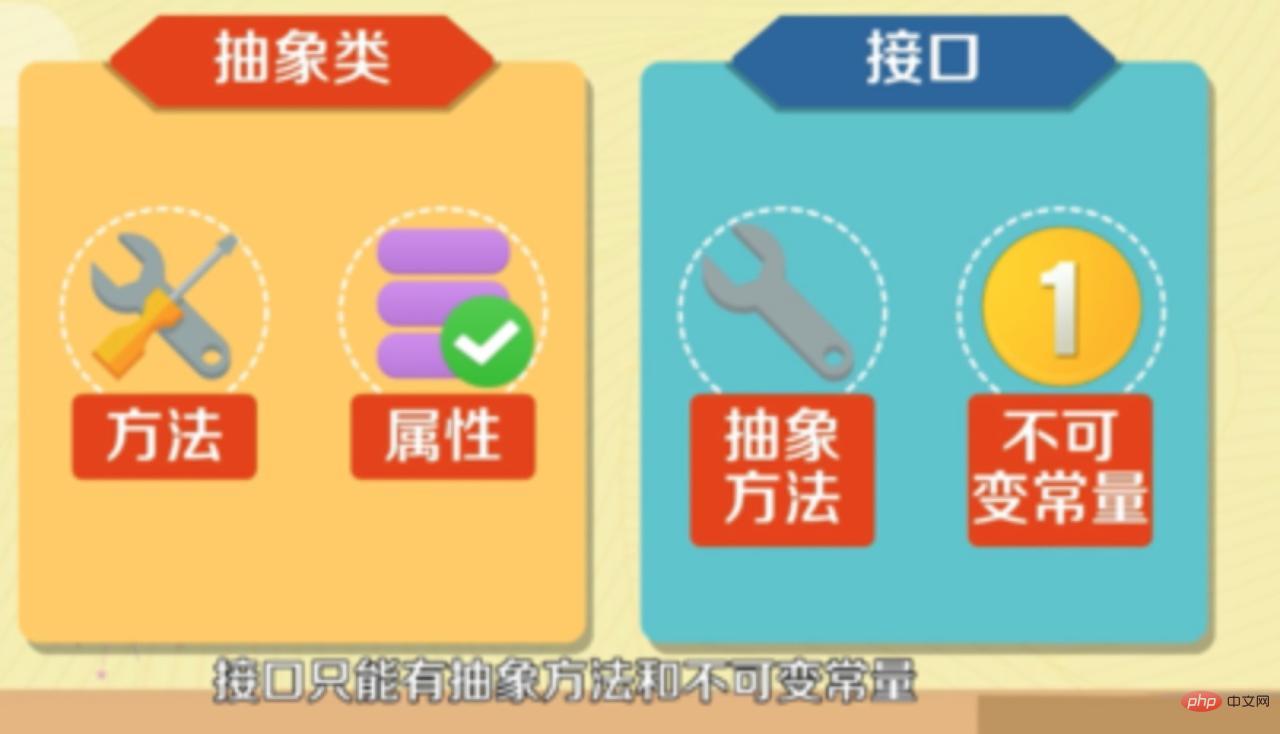
- 추상 클래스는 특정 메서드와 속성을 가질 수 있지만 인터페이스는 추상 메서드와 불변 상수만 가질 수 있습니다.
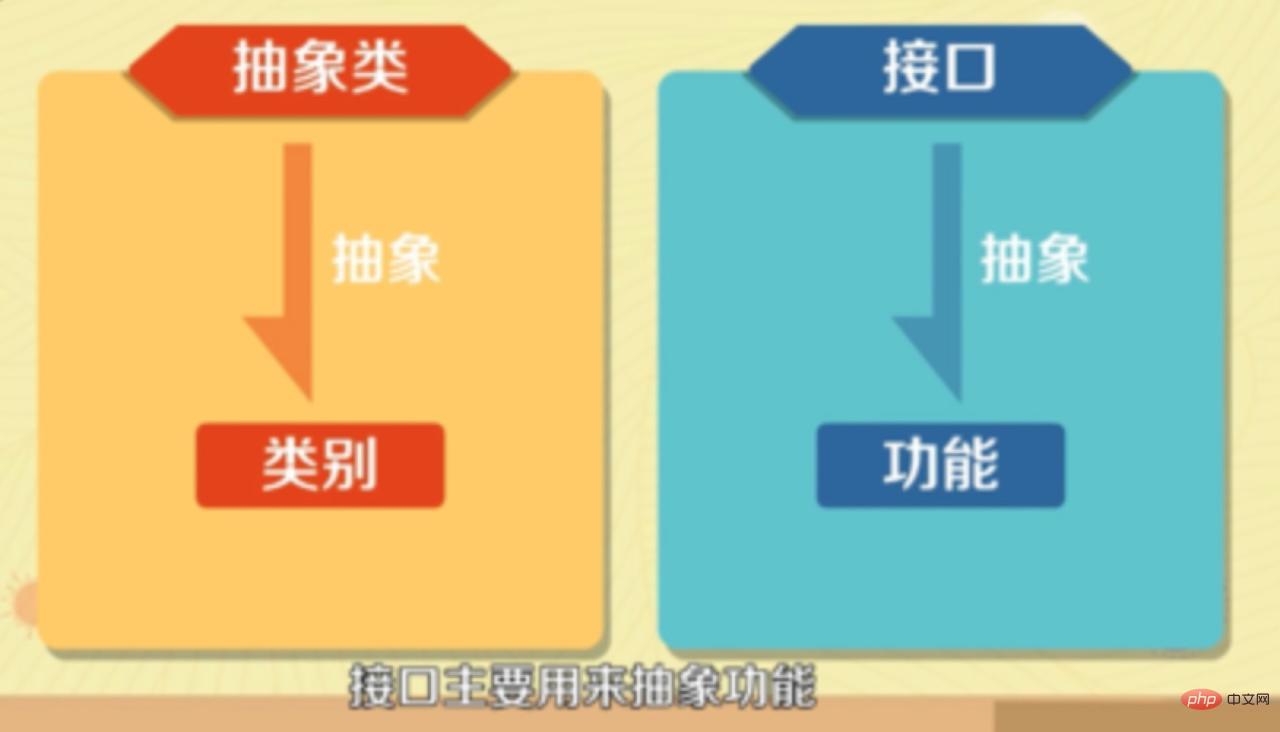
- 추상 클래스는 주로 범주를 추상화하는 데 사용되고, 인터페이스는 주로 함수를 추상화하는 데 사용됩니다.
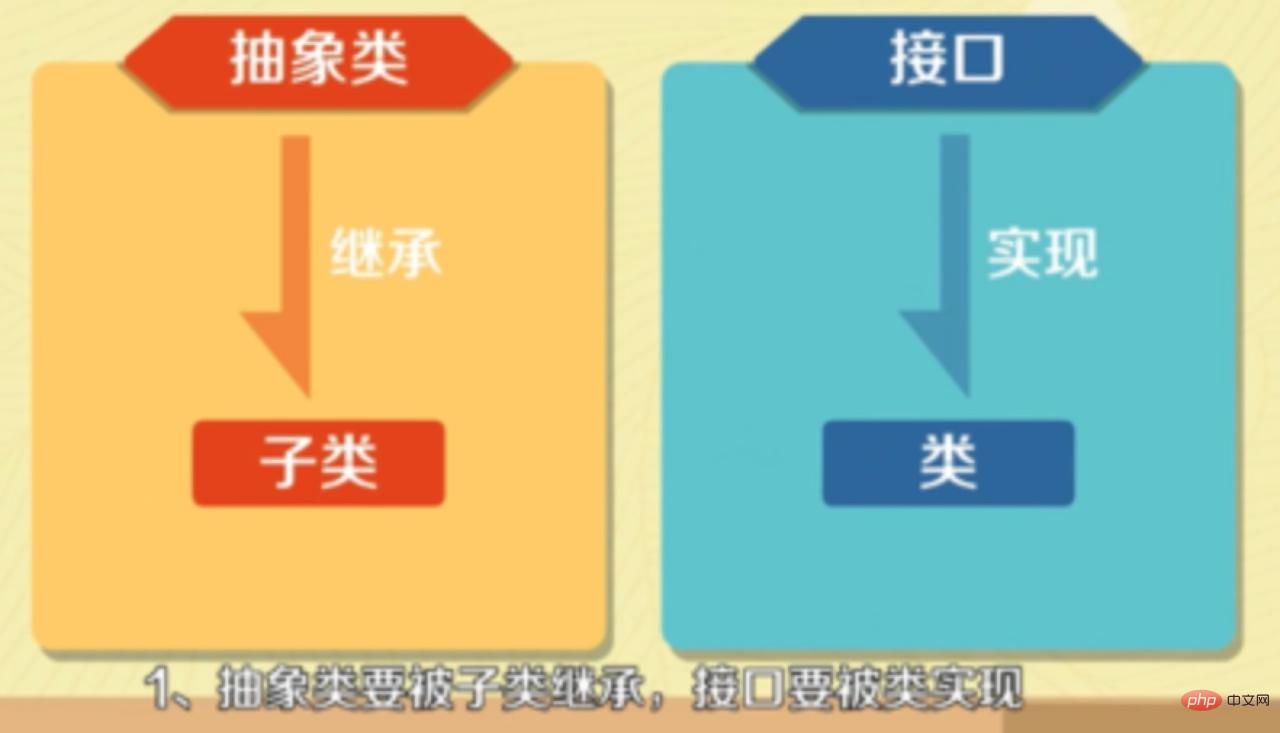
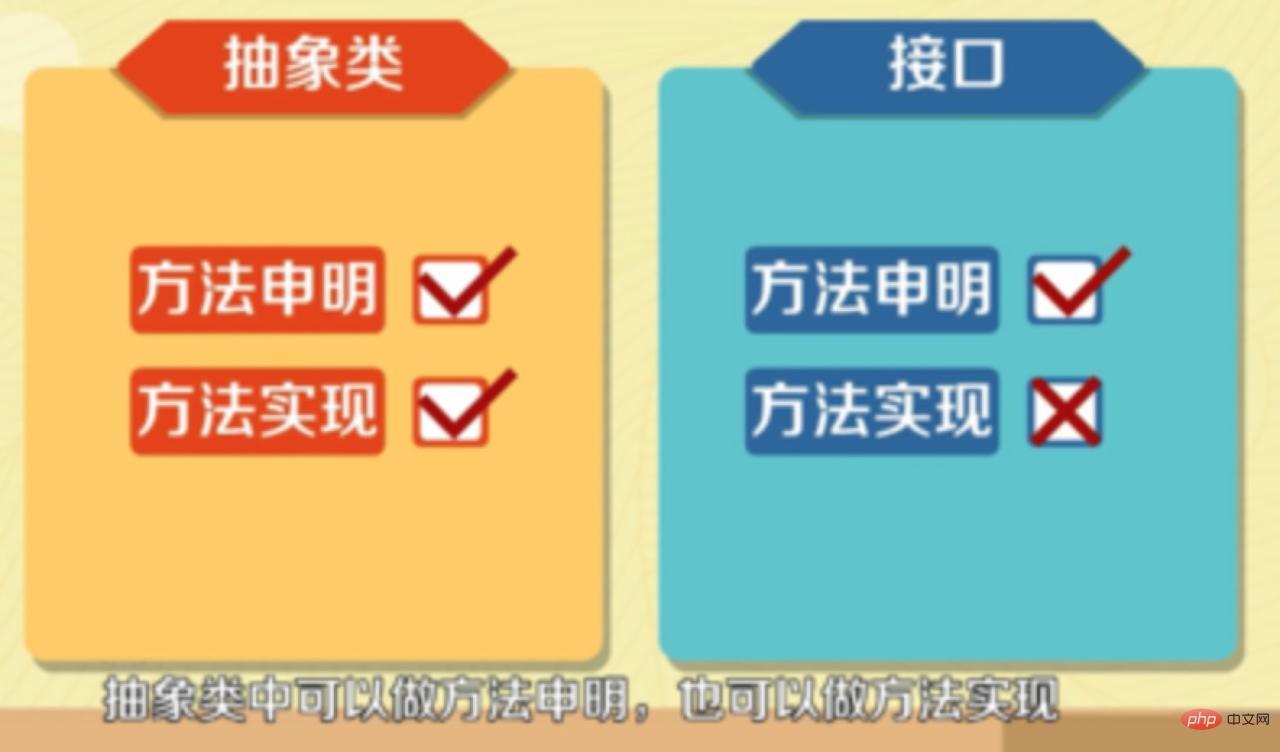
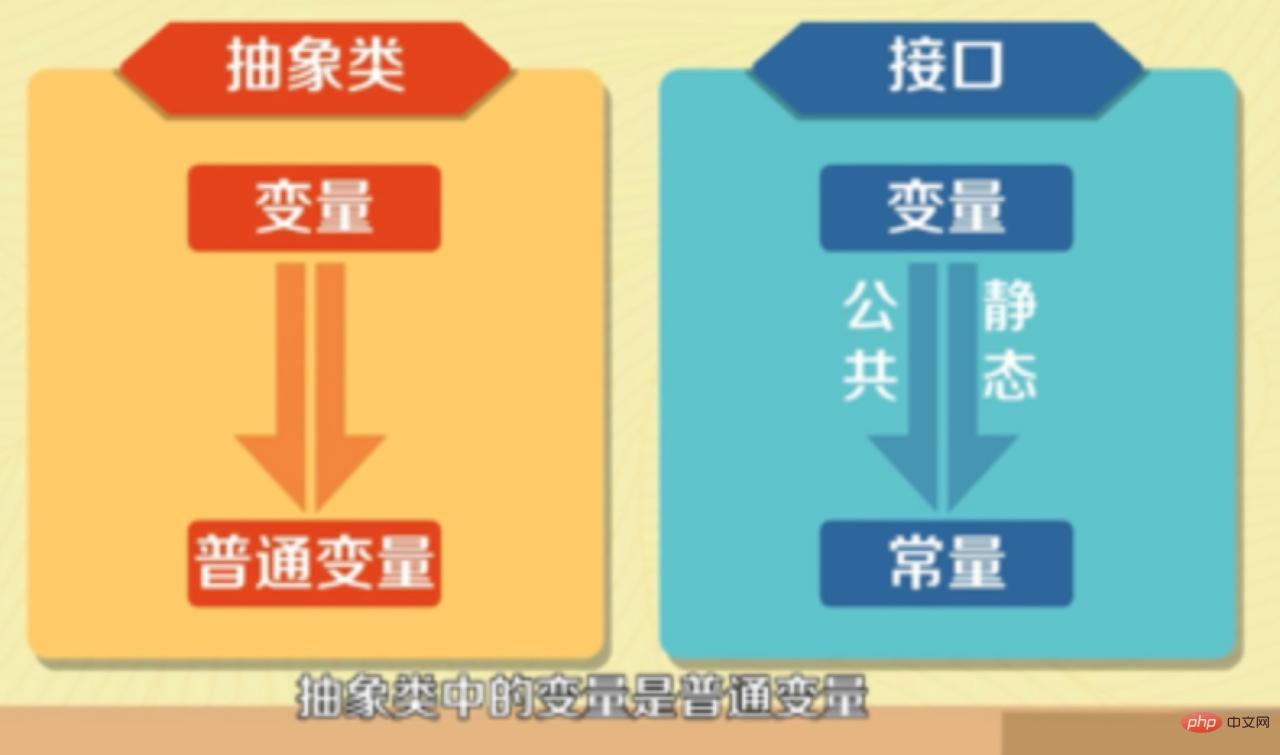
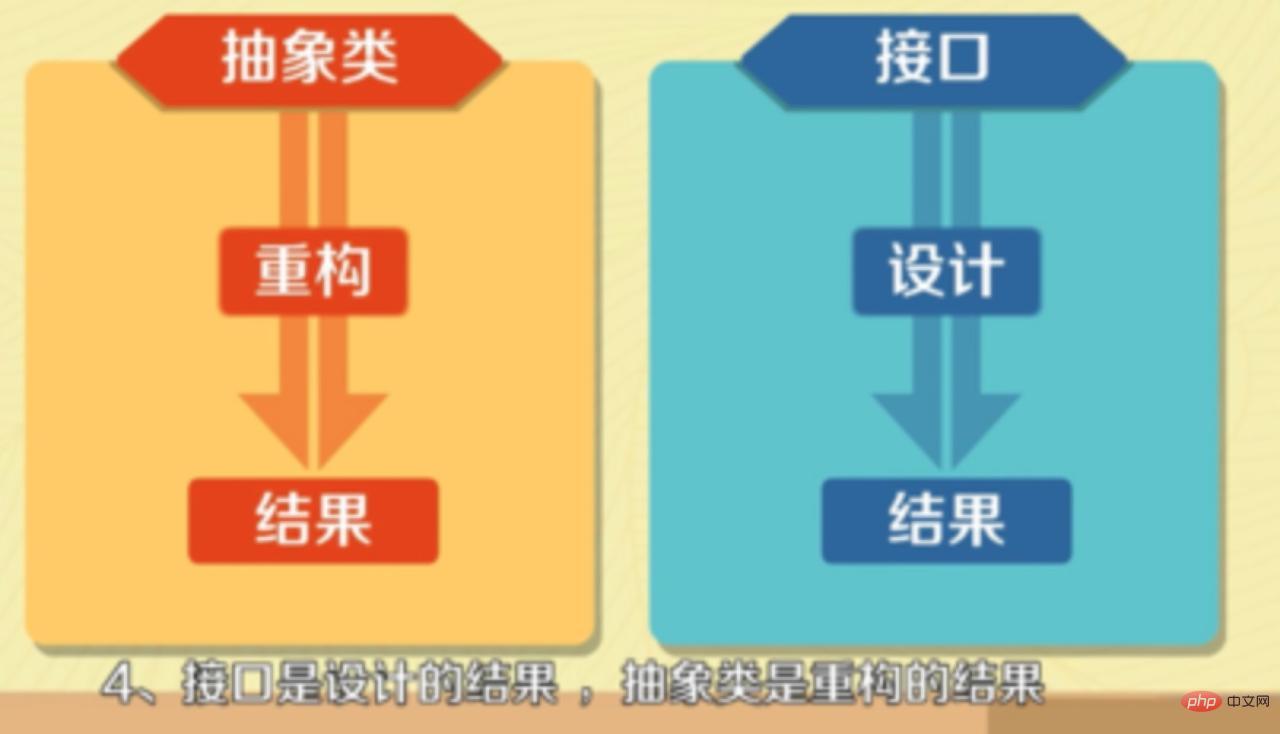
8.추상 클래스의 의미
추상 클래스: 클래스에 추상 메서드가 포함된 경우 해당 클래스는 abstract 키워드를 사용하여 추상 클래스로 선언되어야 합니다.
의미:
- 하위 클래스에 공통 유형을 제공합니다.
- 하위 클래스에서 반복되는 내용(멤버 변수 및 메서드)을 캡슐화합니다.
- 서브클래스의 구현이 다르지만 메서드 정의는 일관됩니다.
9. 추상 클래스 및 인터페이스의 응용 시나리오
1. 인터페이스의 응용 시나리오:
- 구현 방법에 관계없이 클래스 간 조정을 위해서는 특정 인터페이스가 필요합니다.
- 특정 기능을 구현할 수 있는 식별자로 존재하거나, 인터페이스 메소드가 없는 순수 식별자로 존재할 수도 있습니다.
- 클래스 그룹을 단일 클래스로 처리해야 하며 호출자는 인터페이스를 통해 이 클래스 그룹에만 연락합니다.
- 특정 여러 기능을 구현해야 하며 이러한 기능은 전혀 연결되지 않을 수 있습니다.
2. 추상 클래스(abstract.class) 적용 사례:
한마디로 통합 인터페이스와 인스턴스 변수 또는 기본 메서드가 모두 필요할 때 사용할 수 있습니다. 가장 일반적인 것들은 다음과 같습니다:
- 인터페이스 세트를 정의하지만 각 구현 클래스가 모든 인터페이스를 구현하도록 강제하고 싶지는 않습니다. abstract.class를 사용하여 메소드 본문 세트 또는 심지어 빈 메소드 본문을 정의할 수 있으며, 그런 다음 서브클래스에서 다루고자 하는 메소드를 선택할 수 있습니다.
- 어떤 경우에는 순수한 인터페이스만으로는 클래스 간의 조정을 만족시킬 수 없습니다. 클래스의 상태를 나타내는 변수도 서로 다른 관계를 구별하는 데 필요합니다. Abstract의 중개자 역할은 이를 매우 잘 충족시킬 수 있습니다.
- 상호 조정된 메서드 집합을 표준화합니다. 그 중 일부는 공통적이고 상태 독립적이며 하위 클래스가 별도로 구현할 필요 없이 공유할 수 있지만 다른 메서드는 각 하위 클래스가 고유한 특정 상태에 따라 특정 메서드를 구현해야 합니다. . 함수
10. 추상 클래스에는 메서드와 속성이 없을 수 있나요?
답은 다음과 같습니다. 예
추상 클래스에는 추상 메서드가 필요하지 않지만, 추상 메서드가 있는 클래스는 추상 클래스여야 합니다. 따라서 Java의 추상 클래스에는 추상 메소드가 있을 수 없습니다. 추상 메서드와 속성이 없는 추상 클래스도 인스턴스화할 수 없습니다.
11. 接口的意义
- 定义接口的重要性:在Java编程,abstract class 和interface是支持抽象类定义的两种机制。正是由于这两种机制的存在,才使得Java成为面向对象的编程语言。
- 定义接口有利于代码的规范:对于一个大型项目而言,架构师往往会对一些主要的接口来进行定义,或者清理一些没有必要的接口。这样做的目的一方面是为了给开发人员一个清晰的指示,告诉他们哪些业务需要实现;同时也能防止由于开发人员随意命名而导致的命名不清晰和代码混乱,影响开发效率。
- 有利于对代码进行维护:比如你要做一个画板程序,其中里面有一个面板类,主要负责绘画功能,然后你就这样定义了这个类。可是在不久将来,你突然发现现有的类已经不能够满足需要,然后你又要重新设计这个类,更糟糕是你可能要放弃这个类,那么其他地方可能有引用他,这样修改起来很麻烦。如果你一开始定义一个接口,把绘制功能放在接口里,然后定义类时实现这个接口,然后你只要用这个接口去引用实现它的类就行了,以后要换的话只不过是引用另一个类而已,这样就达到维护、拓展的方便性。
- 保证代码的安全和严密:一个好的程序一定符合高内聚低耦合的特征,那么实现低耦合,定义接口是一个很好的方法,能够让系统的功能较好地实现,而不涉及任何具体的实现细节。这样就比较安全、严密一些,这一思想一般在软件开发中较为常见。
12. Java泛型中的extends和super理解
在平时看源码的时候我们经常看到泛型,且经常会看到extends和super的使用,看过其他的文章里也有讲到上界通配符和下届通配符,总感觉讲的不够明白。这里备注一下,以免忘记。
- extends也成为上界通配符,就是指定上边界。即泛型中的类必须为当前类的子类或当前类。
- super也称为下届通配符,就是指定下边界。即泛型中的类必须为当前类或者其父类。
这两点不难理解,extends修饰的只能取,不能放,这是为什么呢? 先看一个列子:
public class Food {}
public class Fruit extends Food {}
public class Apple extends Fruit {}
public class Banana extends Fruit{}
public class GenericTest {
public void testExtends(List extends Fruit> list){
//报错,extends为上界通配符,只能取值,不能放.
//因为Fruit的子类不只有Apple还有Banana,这里不能确定具体的泛型到底是Apple还是Banana,所以放入任何一种类型都会报错
//list.add(new Apple());
//可以正常获取
Fruit fruit = list.get(1);
}
public void testSuper(List super Fruit> list){
//super为下界通配符,可以存放元素,但是也只能存放当前类或者子类的实例,以当前的例子来讲,
//无法确定Fruit的父类是否只有Food一个(Object是超级父类)
//因此放入Food的实例编译不通过
list.add(new Apple());
// list.add(new Food());
Object object = list.get(1);
}
}在testExtends方法中,因为泛型中用的是extends,在向list中存放元素的时候,我们并不能确定List中的元素的具体类型,即可能是Apple也可能是Banana。因此调用add方法时,不论传入new Apple()还是new Banana(),都会出现编译错误。
理解了extends之后,再看super就很容易理解了,即我们不能确定testSuper方法的参数中的泛型是Fruit的哪个父类,因此在调用get方法时只能返回Object类型。结合extends可见,在获取泛型元素时,使用extends获取到的是泛型中的上边界的类型(本例子中为Fruit),范围更小。
总结:在使用泛型时,存取元素时用super,获取元素时,用extends。
13. 父类的静态方法能否被子类重写
不能,父类的静态方法能够被子类继承,但是不能够被子类重写,即使子类中的静态方法与父类中的静态方法完全一样,也是两个完全不同的方法。
class Fruit{
static String color = "五颜六色";
static public void call() {
System.out.println("这是一个水果");
}
}
public class Banana extends Fruit{
static String color = "黄色";
static public void call() {
System.out.println("这是一个香蕉");
}
public static void main(String[] args) {
Fruit fruit = new Banana();
System.out.println(fruit.color); //五颜六色
fruit.call(); //这是一个水果
}
}如代码所示,如果能够被重写,则输出的应该是这是一个香蕉。与此类似的是,静态变量也不能够被重写。如果想要调用父类的静态方法,应该使用类来调用。 那为什么会出现这种情况呢? 我们要从重写的定义来说:
重写指的是根据运行时对象的类型来决定调用哪个方法,而不是根据编译时的类型。
对于静态方法和静态变量来说,虽然在上述代码中使用对象来进行调用,但是底层上还是使用父类来调用的,静态变量和静态方法在编译的时候就将其与类绑定在一起。既然它们在编译的时候就决定了调用的方法、变量,那就和重写没有关系了。
静态属性和静态方法是否可以被继承
可以被继承,如果子类中有相同的静态方法和静态变量,那么父类的方法以及变量就会被覆盖。要想调用就就必须使用父类来调用。
class Fruit{
static String color = "五颜六色";
static String xingzhuang = "奇形怪状";
static public void call() {
System.out.println("这是一个水果");
}
static public void test() {
System.out.println("这是没有被子类覆盖的方法");
}
}
public class Banana extends Fruit{
static String color = "黄色";
static public void call() {
System.out.println("这是一个香蕉");
}
public static void main(String[] args) {
Banana banana = new Banana();
banana.test(); //这是没有被子类覆盖的方法
banana.call(); //调用Banana类中的call方法 这是一个香蕉
Fruit.call(); //调用Fruit类中的方法 这是一个水果
System.out.println(banana.xingzhuang + " " + banana.color); //奇形怪状 黄色
}
}从上述代码可以看出,子类中覆盖了父类的静态方法的话,调用的是子类的方法,这个时候要是还想调用父类的静态方法,应该是用父类直接调用。如果子类没有覆盖,则调用的是父类的方法。静态变量与此相似。
14. 스레드와 프로세스의 차이점
- 정의: 프로세스는 특정 데이터 수집에 대한 프로그램의 실행 활동입니다. 스레드는 프로세스의 실행 경로입니다. (프로세스는 여러 스레드를 생성할 수 있습니다.)
- 역할 측면: 스레드 메커니즘을 지원하는 시스템에서 프로세스는 시스템 자원 할당 단위이고 스레드는 CPU 스케줄링 단위입니다.
- 리소스 공유: 프로세스 간에 리소스를 공유할 수 없지만 스레드는 자신이 위치한 프로세스의 주소 공간과 기타 리소스를 공유합니다. 동시에 스레드에는 자체 스택, 스택 포인터, 프로그램 카운터 및 기타 레지스터도 있습니다.
- 독립성 측면에서: 프로세스는 자신만의 독립적인 주소 공간을 가지고 있지만 스레드는 존재하지 않는 프로세스에 의존해야 합니다.
- 비용 측면에서요. 프로세스 전환 비용이 많이 듭니다. 스레드는 상대적으로 작습니다. (앞서 말씀드렸던 것처럼 스레드 도입도 비용 문제 때문입니다.)
이 글을 읽어보세요: juejin.im/post/684490…
15 final, finally, finalize의 차이점
- final은 속성, 메서드 및 클래스를 선언하는 데 사용됩니다. 이는 각각 속성이 변경 불가능하고, 메서드가 재정의될 수 없으며, 클래스가 상속될 수 없음을 의미합니다.
- finally는 항상 실행됨을 나타내는 예외 처리 문 구조의 일부입니다. finalize는 Object 클래스의 메서드입니다. 이 메서드는 가비지 수집기가 실행될 때 호출됩니다. 이 메서드는 파일 닫기 등의 가비지 수집 중에 다른 리소스 재활용을 제공하도록 재정의될 수 있습니다. 16. Android에서 Serialized와 Parcelable
- 의 차이점 Intent가 클래스 객체를 전달하려는 경우 두 가지 방법으로 이를 달성할 수 있습니다.
직렬화 가능(Java와 함께 제공):
직렬화 가능은 직렬화를 의미하며, 이는 객체를 저장 가능하거나 전송 가능한 상태로 변환하는 것을 의미합니다. 직렬화된 객체는 네트워크를 통해 전송되거나 로컬에 저장될 수 있습니다. 직렬화 가능은 태그가 지정된 인터페이스입니다. 이는 Java가 메소드를 구현하지 않고도 이 객체를 효율적으로 직렬화할 수 있음을 의미합니다.
Parcelable(Android 전용): Android의 Parcelable은 원래 직렬화 가능이 너무 느리기 때문에 설계되었습니다(리플렉션 사용). 이는 프로그램 내 여러 구성 요소 간 및 여러 Android 프로그램(AIDL) 간에 데이터를 효율적으로 전송하도록 설계되었습니다. 메모리에 존재합니다. Parcelable 메소드의 구현 원리는 완전한 객체를 분해하는 것이며 분해 후의 각 부분은 Intent에서 지원하는 데이터 유형이므로 객체를 전달하는 기능을 구현합니다.
효율성과 선택: Parcelable은 직렬화보다 성능이 더 좋습니다. 후자는 반사 프로세스 중에 GC가 자주 발생하기 때문입니다. 따라서 활동 간 데이터 전송과 같이 메모리 간 데이터 전송 시 Parcelable을 사용하는 것이 좋습니다. Serialized는 쉬운 저장을 위해 데이터를 유지할 수 있으므로 네트워크를 통해 데이터를 저장하거나 전송해야 하는 경우 Serialized를 선택하세요. Parcelable은 Android 버전마다 다를 수 있으므로 데이터 지속성을 위해 Parcelable을 사용하지 않는 것이 좋습니다. Parcelable은 외부 세계가 변경될 때 데이터의 지속성을 보장할 수 없기 때문에 데이터를 디스크에 저장할 때 사용할 수 없습니다. 직렬화 가능은 덜 효율적이지만 현재로서는 여전히 직렬화 가능을 사용하는 것이 좋습니다.
인텐트를 통해 복잡한 데이터 유형을 전달할 때 먼저 두 인터페이스 중 하나를 구현해야 합니다. 해당 메소드는 getSerializedExtra() 및 getParcelableExtra()입니다.
17. 정적 속성과 정적 메서드를 상속받을 수 있나요? 다시 쓸 수 있나요? 그리고 왜?
상위 클래스의 정적 속성과 메서드는 하위 클래스에서 상속될 수 있습니다.하위 클래스는 재정의할 수 없습니다.: 상위 클래스의 참조가 하위 클래스를 가리키는 경우 개체를 사용하여 정적 메서드나 정적 변수를 호출하는 것은 에서 호출하는 부모 클래스 메서드나 변수. 하위클래스에 의해 재정의되지 않습니다.
이유:
프로그램이 실행되기 시작한 이후 정적 메서드가 메모리를 할당했기 때문에 하드코딩되었기 때문입니다. 이 메서드를 참조하는 모든 개체(상위 클래스의 개체 또는 하위 클래스의 개체)는 정적 메서드인 메모리의 동일한 데이터 조각을 가리킵니다. 동일한 이름의 정적 메서드가 하위 클래스에 정의되어 있으면 재정의되지 않으며, 대신 하위 클래스의 다른 정적 메서드를 메모리에 할당해야 하며 재정의는 없습니다.
18. Java에서 정적 내부 클래스의 설계 의도
Inner 클래스
내부 클래스는 클래스 내부에 정의된 클래스입니다. 왜 내부 클래스가 있나요?
Java에서 클래스는 단일 상속이고 클래스는 다른 구체적인 클래스나 추상 클래스(여러 인터페이스를 구현할 수 있음)만 상속할 수 있다는 것을 알고 있습니다. 이 디자인의 목적은 다중 상속에서 여러 부모 클래스에 중복된 속성이나 메서드가 있는 경우 하위 클래스의 호출 결과가 모호해지기 때문에 단일 상속이 사용된다는 것입니다.
내부 클래스를 사용하는 이유는 각 내부 클래스가 독립적으로 (인터페이스의) 구현을 상속할 수 있기 때문입니다. 따라서 외부 클래스가 (인터페이스의) 구현을 상속했는지 여부는 내부 클래스에 아무런 영향을 미치지 않습니다.
프로그래밍에는 때때로 인터페이스를 사용하여 해결하기 어려운 문제가 있습니다. 이때 내부 클래스에서 제공하는 기능을 사용하여 여러 구체적 또는 추상 클래스를 상속하여 이러한 프로그래밍 문제를 해결할 수 있습니다. 인터페이스는 문제의 일부만 해결하고 내부 클래스는 다중 상속 솔루션을 더욱 완벽하게 만든다고 말할 수 있습니다.
정적 내부 클래스
정적 내부 클래스에 대해 이야기하기 전에 먼저 멤버 내부 클래스(비정적 내부 클래스)에 대해 이해해 보겠습니다.
Member 내부 클래스
Member 내부 클래스는 가장 일반적인 내부 클래스이기도 합니다. 따라서 비공개 클래스이기는 하지만 외부 클래스의 모든 멤버 속성과 메서드에 무제한으로 액세스할 수 있습니다. , 외부 클래스 클래스가 내부 클래스의 멤버 속성과 메서드에 액세스하려면 내부 클래스 인스턴스를 통해 액세스해야 합니다.
멤버 내부 클래스에서 주의할 점 두 가지:
멤버 내부 클래스에는 정적 변수와 메서드가 있을 수 없습니다.
멤버 내부 클래스는 외부 클래스에 연결되므로 생성만 가능합니다. 외부 클래스가 먼저 생성되어야 내부 클래스가 생성될 수 있습니다.
정적 내부 클래스
정적 내부 클래스와 비정적 내부 클래스 사이에는 가장 큰 차이점이 하나 있습니다. 비정적 내부 클래스는 컴파일 후 암시적으로 참조가 생성된 지점을 가리키는 참조를 저장합니다. s 외부 클래스이지만 정적 내부 클래스는 그렇지 않습니다.
이 참조가 없다는 것은 다음을 의미합니다:
그것의 생성은 주변 클래스에 의존할 필요가 없습니다.
비정적 멤버 변수와 주변 클래스의 메서드를 사용할 수 없습니다.
다른 두 내부 클래스: 로컬 내부 클래스 및 익명 내부 클래스
로컬 내부 클래스
로컬 내부 클래스는 메서드 및 범위 내에 중첩되어 있으며, 이 클래스는 주로 응용 프로그램 및 솔루션 비교에 사용됩니다. , 우리는 솔루션을 지원하기 위해 클래스를 만들고 싶지만 그 당시에는 이 클래스를 공개적으로 사용할 수 없도록 하여 로컬 내부 클래스가 생성됩니다. 멤버 내부 클래스처럼 로컬 내부 클래스가 생성됩니다. 범위가 변경되면 메서드와 속성 내에서만 사용할 수 있으며 메서드와 속성 외부에서는 유효하지 않게 됩니다.
익명 내부 클래스
익명 내부 클래스에는 액세스 수정자가 없습니다.
new 익명 내부 클래스, 이 클래스가 먼저 존재해야 합니다.
익명 내부 클래스에서 메소드의 형식 매개변수를 사용해야 하는 경우 형식 매개변수는 최종 매개변수여야 합니다.
익명 내부 클래스에는 명시적인 생성자가 없으며 컴파일러는 외부 클래스를 참조하는 생성자를 자동으로 생성합니다.
관련 권장 사항: Java 시작하기
위 내용은 2020년 새로운 Java 기본 면접 질문 요약의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

Video Face Swap
완전히 무료인 AI 얼굴 교환 도구를 사용하여 모든 비디오의 얼굴을 쉽게 바꾸세요!

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7817
7817
 15
1646
14
1402
52
1300
25
1238
29
15
1646
14
1402
52
1300
25
1238
29

 Java 8 Stream foreach에서 나누거나 돌아 오시겠습니까?
Feb 07, 2025 pm 12:09 PM
Java 8 Stream foreach에서 나누거나 돌아 오시겠습니까?
Feb 07, 2025 pm 12:09 PM
Java 8은 스트림 API를 소개하여 데이터 컬렉션을 처리하는 강력하고 표현적인 방법을 제공합니다. 그러나 스트림을 사용할 때 일반적인 질문은 다음과 같은 것입니다. 기존 루프는 조기 중단 또는 반환을 허용하지만 스트림의 Foreach 메소드는이 방법을 직접 지원하지 않습니다. 이 기사는 이유를 설명하고 스트림 처리 시스템에서 조기 종료를 구현하기위한 대체 방법을 탐색합니다. 추가 읽기 : Java Stream API 개선 스트림 foreach를 이해하십시오 Foreach 메소드는 스트림의 각 요소에서 하나의 작업을 수행하는 터미널 작동입니다. 디자인 의도입니다
 PHP : 웹 개발의 핵심 언어
Apr 13, 2025 am 12:08 AM
PHP : 웹 개발의 핵심 언어
Apr 13, 2025 am 12:08 AM
PHP는 서버 측에서 널리 사용되는 스크립팅 언어이며 특히 웹 개발에 적합합니다. 1.PHP는 HTML을 포함하고 HTTP 요청 및 응답을 처리 할 수 있으며 다양한 데이터베이스를 지원할 수 있습니다. 2.PHP는 강력한 커뮤니티 지원 및 오픈 소스 리소스를 통해 동적 웹 컨텐츠, 프로세스 양식 데이터, 액세스 데이터베이스 등을 생성하는 데 사용됩니다. 3. PHP는 해석 된 언어이며, 실행 프로세스에는 어휘 분석, 문법 분석, 편집 및 실행이 포함됩니다. 4. PHP는 사용자 등록 시스템과 같은 고급 응용 프로그램을 위해 MySQL과 결합 할 수 있습니다. 5. PHP를 디버깅 할 때 error_reporting () 및 var_dump ()와 같은 함수를 사용할 수 있습니다. 6. 캐싱 메커니즘을 사용하여 PHP 코드를 최적화하고 데이터베이스 쿼리를 최적화하며 내장 기능을 사용하십시오. 7
 PHP vs. Python : 차이점 이해
Apr 11, 2025 am 12:15 AM
PHP vs. Python : 차이점 이해
Apr 11, 2025 am 12:15 AM
PHP와 Python은 각각 고유 한 장점이 있으며 선택은 프로젝트 요구 사항을 기반으로해야합니다. 1.PHP는 간단한 구문과 높은 실행 효율로 웹 개발에 적합합니다. 2. Python은 간결한 구문 및 풍부한 라이브러리를 갖춘 데이터 과학 및 기계 학습에 적합합니다.
 캡슐의 양을 찾기위한 Java 프로그램
Feb 07, 2025 am 11:37 AM
캡슐의 양을 찾기위한 Java 프로그램
Feb 07, 2025 am 11:37 AM
캡슐은 3 차원 기하학적 그림이며, 양쪽 끝에 실린더와 반구로 구성됩니다. 캡슐의 부피는 실린더의 부피와 양쪽 끝에 반구의 부피를 첨가하여 계산할 수 있습니다. 이 튜토리얼은 다른 방법을 사용하여 Java에서 주어진 캡슐의 부피를 계산하는 방법에 대해 논의합니다. 캡슐 볼륨 공식 캡슐 볼륨에 대한 공식은 다음과 같습니다. 캡슐 부피 = 원통형 볼륨 2 반구 볼륨 안에, R : 반구의 반경. H : 실린더의 높이 (반구 제외). 예 1 입력하다 반경 = 5 단위 높이 = 10 단위 산출 볼륨 = 1570.8 입방 단위 설명하다 공식을 사용하여 볼륨 계산 : 부피 = π × r2 × h (4
 PHP 대 기타 언어 : 비교
Apr 13, 2025 am 12:19 AM
PHP 대 기타 언어 : 비교
Apr 13, 2025 am 12:19 AM
PHP는 특히 빠른 개발 및 동적 컨텐츠를 처리하는 데 웹 개발에 적합하지만 데이터 과학 및 엔터프라이즈 수준의 애플리케이션에는 적합하지 않습니다. Python과 비교할 때 PHP는 웹 개발에 더 많은 장점이 있지만 데이터 과학 분야에서는 Python만큼 좋지 않습니다. Java와 비교할 때 PHP는 엔터프라이즈 레벨 애플리케이션에서 더 나빠지지만 웹 개발에서는 더 유연합니다. JavaScript와 비교할 때 PHP는 백엔드 개발에서 더 간결하지만 프론트 엔드 개발에서는 JavaScript만큼 좋지 않습니다.
 PHP vs. Python : 핵심 기능 및 기능
Apr 13, 2025 am 12:16 AM
PHP vs. Python : 핵심 기능 및 기능
Apr 13, 2025 am 12:16 AM
PHP와 Python은 각각 고유 한 장점이 있으며 다양한 시나리오에 적합합니다. 1.PHP는 웹 개발에 적합하며 내장 웹 서버 및 풍부한 기능 라이브러리를 제공합니다. 2. Python은 간결한 구문과 강력한 표준 라이브러리가있는 데이터 과학 및 기계 학습에 적합합니다. 선택할 때 프로젝트 요구 사항에 따라 결정해야합니다.
 미래를 창조하세요: 완전 초보자를 위한 Java 프로그래밍
Oct 13, 2024 pm 01:32 PM
미래를 창조하세요: 완전 초보자를 위한 Java 프로그래밍
Oct 13, 2024 pm 01:32 PM
Java는 초보자와 숙련된 개발자 모두가 배울 수 있는 인기 있는 프로그래밍 언어입니다. 이 튜토리얼은 기본 개념부터 시작하여 고급 주제를 통해 진행됩니다. Java Development Kit를 설치한 후 간단한 "Hello, World!" 프로그램을 작성하여 프로그래밍을 연습할 수 있습니다. 코드를 이해한 후 명령 프롬프트를 사용하여 프로그램을 컴파일하고 실행하면 "Hello, World!"가 콘솔에 출력됩니다. Java를 배우면 프로그래밍 여정이 시작되고, 숙달이 깊어짐에 따라 더 복잡한 애플리케이션을 만들 수 있습니다.
 Spring Tool Suite에서 첫 번째 Spring Boot 응용 프로그램을 실행하는 방법은 무엇입니까?
Feb 07, 2025 pm 12:11 PM
Spring Tool Suite에서 첫 번째 Spring Boot 응용 프로그램을 실행하는 방법은 무엇입니까?
Feb 07, 2025 pm 12:11 PM
Spring Boot는 강력하고 확장 가능하며 생산 가능한 Java 응용 프로그램의 생성을 단순화하여 Java 개발에 혁명을 일으킨다. Spring Ecosystem에 내재 된 "구성에 대한 협약"접근 방식은 수동 설정, Allo를 최소화합니다.
