

Python의 내장 함수가 전부가 아닌 이유를 이해하시나요?

python 동영상 튜토리얼 칼럼에서는 Python 내장 함수를 소개합니다.

이전 글 Python Cat에서는 목록을 생성하는 두 가지 방법, 즉 리터럴 사용법[]과 내장형 사용법 list()를 비교한 후 분석해 보았습니다. 그들의 달리기 속도. Python猫的上一篇文章中,我们对比了两种创建列表的方法,即字面量用法 [] 与内置类型用法 list(),进而分析出它们在运行速度上的差异。
在分析为什么 list() 会更慢的时候,文中说到它需要经过名称查找与函数调用两个步骤,那么,这就引出了一个新的问题:list() 不是内置类型么,为什么它不能直接就调用创建列表的逻辑呢?也就是说,为什么解释器必须经过名称查找,才能“认识”到该做什么呢?
其实原因很简单:内置函数/内置类型的名称并不是关键字,它们只是解释器内置的一种便捷功能,方便开发者开箱即用而已。
PS:内置函数 built-in function 和内置类型 built-in type 很相似,但 list() 实际是一种内置类型而不是内置函数。我曾对这两种易混淆的概念做过辨析,请查看这篇文章。为了方便理解与表述,以下统称为内置函数。
1、内置函数的查找优先级最低
内置函数的名称并不属于关键字,它们是可以被重新赋值的。
比如下面这个例子:
# 正常调用内置函数list(range(3)) # 结果:[0, 1, 2]# 定义任意函数,然后赋值给 listdef test(n):
print("Hello World!")
list = test
list(range(3)) # 结果:Hello World!复制代码
在这个例子中,我们将自定义的 test 赋值给了 list,程序并没有报错。这个例子甚至还可以改成直接定义新的同名函数,即"def list(): …"。
这说明了 list 并不是 Python 限定的关键字/保留字。
查看官方文档,可以发现 Python 3.9 有 35 个关键字,明细如下:

如果我们将上例的 test 赋值给任意一个关键字,例如"pass=test",就会报错:SyntaxError: invalid syntax。
由此,我们可以从这个角度看出内置函数并不是万能的:它们的名称并不像关键字那般稳固不变,虽然它们处在系统内置作用域里,但是却可以被用户局部作用域的对象所轻松拦截掉!
因为解释器查找名称的顺序是“局部作用域->全局作用域->内置作用域”,因此内置函数其实是处在最低优先级。
对于新手来说,这有一定的可能会发生意想不到的情况(内置函数有 69 个,要全记住是有难度的)。
那么,为什么 Python 不把所有内置函数的名称都设为不可复写的关键字呢?
一方面原因是它想控制关键字的数量,另一方面可能是想留给用户更多的自由。内置函数只是解释器的推荐实现而已,开发者可以根据需要,实现出与内置函数同名的函数。
不过,这样的场景极少,而且开发者一般会定义成不同名的函数,以 Python 标准库为例,ast模块有 literal_eval() 函数(对标 eval() 内置函数)、pprint 模块有 pprint() 函数(对标 print() 内置函数)、以及itertools
list()는 내장 유형이 아닙니다. 왜 목록 생성 로직을 직접 호출할 수 없나요? 즉, 통역사가 무엇을 해야 할지 "알기" 위해 이름 조회를 거쳐야 하는 이유는 무엇입니까?
사실 그 이유는 매우 간단합니다. 내장 함수/내장 유형의 이름은 키워드가 아니라 개발자가 즉시 사용할 수 있도록 인터프리터에 내장된 편리한 함수일 뿐입니다.PS: 내장 함수는 내장 유형과 매우 유사하지만 list()는 실제로 내장 함수가 아닌 내장 유형입니다. 나는 이 두 가지 혼란스러운 개념에 대해 몇 가지 분석을 수행했습니다. 이 기사를 확인하십시오. 이하에서는 이해와 표현을 용이하게 하기 위해 내장기능이라 통칭합니다.
 PS: 내장 함수는 내장 유형과 매우 유사하지만 list()는 실제로 내장 함수가 아닌 내장 유형입니다. 나는 이 두 가지 혼란스러운 개념에 대해 몇 가지 분석을 수행했습니다. 이 기사를 확인하십시오. 이하에서는 이해와 표현을 용이하게 하기 위해 내장기능이라 통칭합니다.
PS: 내장 함수는 내장 유형과 매우 유사하지만 list()는 실제로 내장 함수가 아닌 내장 유형입니다. 나는 이 두 가지 혼란스러운 개념에 대해 몇 가지 분석을 수행했습니다. 이 기사를 확인하십시오. 이하에서는 이해와 표현을 용이하게 하기 위해 내장기능이라 통칭합니다. 1. 내장 함수의 검색 우선순위가 가장 낮습니다
내장 함수의 이름은 키워드가 아니며 재지정될 수 있습니다.
예: rrreee
 이 예에서는 사용자 정의 테스트를 목록에 할당했지만 프로그램은 오류를 보고하지 않았습니다. 이 예는 동일한 이름의 새 함수, 즉 "def list(): ..."를 직접 정의하도록 변경될 수도 있습니다.
이 예에서는 사용자 정의 테스트를 목록에 할당했지만 프로그램은 오류를 보고하지 않았습니다. 이 예는 동일한 이름의 새 함수, 즉 "def list(): ..."를 직접 정의하도록 변경될 수도 있습니다.
이것은 list가 Python에서 제한된 키워드/예약어가 아님을 보여줍니다.
🎜공식 문서를 보면 Python 3.9에는 35개의 키워드가 있는 것을 확인할 수 있으며, 세부 내용은 다음과 같습니다. 🎜🎜 🎜🎜위 예의 테스트를 "pass=test"와 같은 임의의 키워드에 할당하면 , 오류가 보고됩니다: SyntaxError:잘못된 구문. 🎜🎜따라서 우리는 내장 기능이 전능하지 않다는 것을 알 수 있습니다. 🎜그 이름은 시스템의 내장 범위에 있지만 사용자가 로컬에서 사용할 수 있는 키워드만큼 안정적이지 않습니다. . 범위 개체를 쉽게 가로챌 수 있습니다! 🎜🎜🎜통역사가 이름을 찾는 순서는 "로컬 범위 -> 전역 범위 -> 내장 범위"이므로 실제로 내장 함수의 우선순위가 가장 낮습니다. 🎜🎜초보자의 경우 예상치 못한 상황이 발생할 수 있습니다. (69개의 내장된 기능이 있어 다 기억하기 어렵습니다.) 🎜🎜그래서, 🎜왜 Python은 모든 내장 함수의 이름을 재정의할 수 없는 키워드로 만들지 않습니까? 🎜🎜🎜한편으로는 키워드 수를 제어하고 다른 한편으로는 사용자에게 더 많은 자유를 주고 싶을 수도 있습니다. 내장 함수는 인터프리터의 권장 구현일 뿐입니다. 개발자는 필요에 따라 내장 함수와 동일한 이름을 가진 함수를 구현할 수 있습니다. 🎜🎜그러나 이러한 시나리오는 드물며 개발자는 일반적으로 Python 표준 라이브러리를 예로 들어 함수를 정의합니다.
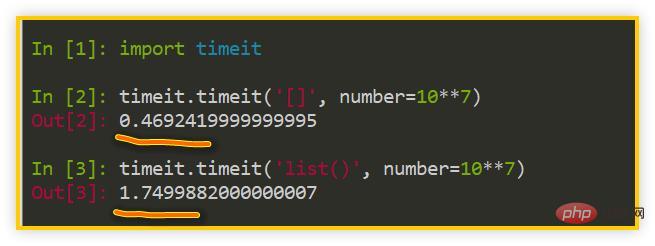
🎜🎜위 예의 테스트를 "pass=test"와 같은 임의의 키워드에 할당하면 , 오류가 보고됩니다: SyntaxError:잘못된 구문. 🎜🎜따라서 우리는 내장 기능이 전능하지 않다는 것을 알 수 있습니다. 🎜그 이름은 시스템의 내장 범위에 있지만 사용자가 로컬에서 사용할 수 있는 키워드만큼 안정적이지 않습니다. . 범위 개체를 쉽게 가로챌 수 있습니다! 🎜🎜🎜통역사가 이름을 찾는 순서는 "로컬 범위 -> 전역 범위 -> 내장 범위"이므로 실제로 내장 함수의 우선순위가 가장 낮습니다. 🎜🎜초보자의 경우 예상치 못한 상황이 발생할 수 있습니다. (69개의 내장된 기능이 있어 다 기억하기 어렵습니다.) 🎜🎜그래서, 🎜왜 Python은 모든 내장 함수의 이름을 재정의할 수 없는 키워드로 만들지 않습니까? 🎜🎜🎜한편으로는 키워드 수를 제어하고 다른 한편으로는 사용자에게 더 많은 자유를 주고 싶을 수도 있습니다. 내장 함수는 인터프리터의 권장 구현일 뿐입니다. 개발자는 필요에 따라 내장 함수와 동일한 이름을 가진 함수를 구현할 수 있습니다. 🎜🎜그러나 이러한 시나리오는 드물며 개발자는 일반적으로 Python 표준 라이브러리를 예로 들어 함수를 정의합니다. ast 모듈에는 literal_eval() 함수(내장 eval( ) 함수), pprint 모듈에는 pprint() 함수가 있고(print() 내장 함수와 비교) itertools 모듈에는 zip_longest() 함수가 있습니다. (zip() 내장 함수와 비교)...🎜🎜2. 내장 함수가 가장 빠르지 않을 수 있습니다🎜🎜 내장 함수의 이름은 예약어가 아니며, 이름 검색 마지막 순서에서는 내장 기능이 가장 빠르지 않을 수 있습니다. 🎜🎜🎜🎜🎜이전 기사에서는 []가 list()보다 2~3배 빠르다는 사실을 보여주었습니다. 실제로 이는 str(), tuple(), set()과 같은 내장 유형으로도 확장될 수 있습니다. ), dict() 등 모든 리터럴 사용은 내장 유형 사용보다 약간 빠릅니다. 🎜🎜이러한 내장 유형의 경우 xxx()를 호출하면 클래스가 인스턴스화된다는 것을 간단히 이해할 수 있습니다. 객체 지향 언어에서는 클래스가 먼저 인스턴스화되고 사용되는 것이 일반적입니다. 🎜🎜그러나 이 접근 방식은 때때로 번거로워 보일 수 있습니다. 🎜사용의 용이성을 위해 Python은 문자열, 목록, 튜플 및 사전과 같은 데이터 유형을 나타내는 일반적으로 사용되는 일부 내장 유형, 즉 "", [], (), {} 등에 대한 리터럴 표현을 제공합니다. 🎜🎜🎜🎜🎜🎜문서 출처: docs.python.org/3/reference…🎜일반적으로 모든 프로그래밍 언어에는 리터럴 표현이 있어야 하지만 기본적으로 숫자 유형, 문자열, 부울 유형 및 null과 같은 기본 유형으로 제한됩니다.
Python은 여러 데이터 구조 유형에 대한 리터럴도 추가하여 더 편리합니다. 이는 내장 기능이 가장 빠르지 않은 이유도 설명합니다.
일반적으로 말하면, 내장 함수는 동일한 완전한 함수를 사용하여 항상 사용자 정의 함수보다 빠릅니다. 왜냐하면 인터프리터가 len()과 같은 일부 기본 최적화를 수행할 수 있기 때문입니다. 내장 함수는 사용자 정의 x보다 확실히 빠릅니다. .len() 이 기능은 빠릅니다.
이를 바탕으로 "내장 기능이 항상 빠르다"는 오해를 형성하는 사람들도 있습니다.
사용자 정의 함수에 비해 통역사의 내장 기능은 백도어에 가깝지만 리터럴 표현은 내장 함수에 비해 백도어가 더 빠릅니다.
즉, 일부 내장 함수/내장 유형은 리터럴 표현이 있을 때 가장 빠르지 않습니다!
요약
파이썬 자체가 전능하지 않고 문법적 구성 요소(내장 함수/유형)도 전능하지 않다는 것은 사실입니다. 그러나 일반적으로 우리는 내장된 함수/유형이 항상 "우수"하고, 많은 특별 우대를 받으며, "전능한" 것처럼 보인다고 생각합니다.
이 글은 "list()가 실제로 []에게 진다"는 문제를 해결하고 실제로 내장 함수에 몇 가지 단점이 있음을 두 가지 관점에서 드러냅니다. 내장 함수의 이름은 키워드가 아니며, 내장 범위는 우선 순위가 가장 낮은 이름 검색에 위치하므로 일부 내장 함수/유형은 호출 시 해당 리터럴 표현보다 훨씬 느리게 실행됩니다.
이 기사는 이전 주제인 "왜 Python"에 대한 토론을 확장하는 동시에 이전 내용을 풍부하게 하는 동시에 모든 사람이 Python의 몇 가지 기본 개념과 구현을 이해하는 데도 도움이 됩니다.
이 글이 마음에 드셨다면 좋아요와 응원 부탁드립니다! 또한, 비슷한 주제를 20개 이상 작성했습니다. Python猫를 따라 확인하고 Github에서 작은 별표를 눌러주세요~~
관련 무료 학습 권장 사항: python 비디오 튜토리얼
위 내용은 Python의 내장 함수가 전부가 아닌 이유를 이해하시나요?의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

Video Face Swap
완전히 무료인 AI 얼굴 교환 도구를 사용하여 모든 비디오의 얼굴을 쉽게 바꾸세요!

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7889
7889
 15
1650
14
1411
52
1302
25
1248
29
15
1650
14
1411
52
1302
25
1248
29

 PHP와 Python : 다른 패러다임이 설명되었습니다
Apr 18, 2025 am 12:26 AM
PHP와 Python : 다른 패러다임이 설명되었습니다
Apr 18, 2025 am 12:26 AM
PHP는 주로 절차 적 프로그래밍이지만 객체 지향 프로그래밍 (OOP)도 지원합니다. Python은 OOP, 기능 및 절차 프로그래밍을 포함한 다양한 패러다임을 지원합니다. PHP는 웹 개발에 적합하며 Python은 데이터 분석 및 기계 학습과 같은 다양한 응용 프로그램에 적합합니다.
 PHP와 Python 중에서 선택 : 가이드
Apr 18, 2025 am 12:24 AM
PHP와 Python 중에서 선택 : 가이드
Apr 18, 2025 am 12:24 AM
PHP는 웹 개발 및 빠른 프로토 타이핑에 적합하며 Python은 데이터 과학 및 기계 학습에 적합합니다. 1.PHP는 간단한 구문과 함께 동적 웹 개발에 사용되며 빠른 개발에 적합합니다. 2. Python은 간결한 구문을 가지고 있으며 여러 분야에 적합하며 강력한 라이브러리 생태계가 있습니다.
 PHP와 Python : 그들의 역사에 깊은 다이빙
Apr 18, 2025 am 12:25 AM
PHP와 Python : 그들의 역사에 깊은 다이빙
Apr 18, 2025 am 12:25 AM
PHP는 1994 년에 시작되었으며 Rasmuslerdorf에 의해 개발되었습니다. 원래 웹 사이트 방문자를 추적하는 데 사용되었으며 점차 서버 측 스크립팅 언어로 진화했으며 웹 개발에 널리 사용되었습니다. Python은 1980 년대 후반 Guidovan Rossum에 의해 개발되었으며 1991 년에 처음 출시되었습니다. 코드 가독성과 단순성을 강조하며 과학 컴퓨팅, 데이터 분석 및 기타 분야에 적합합니다.
 Python vs. JavaScript : 학습 곡선 및 사용 편의성
Apr 16, 2025 am 12:12 AM
Python vs. JavaScript : 학습 곡선 및 사용 편의성
Apr 16, 2025 am 12:12 AM
Python은 부드러운 학습 곡선과 간결한 구문으로 초보자에게 더 적합합니다. JavaScript는 가파른 학습 곡선과 유연한 구문으로 프론트 엔드 개발에 적합합니다. 1. Python Syntax는 직관적이며 데이터 과학 및 백엔드 개발에 적합합니다. 2. JavaScript는 유연하며 프론트 엔드 및 서버 측 프로그래밍에서 널리 사용됩니다.
 숭고한 코드 파이썬을 실행하는 방법
Apr 16, 2025 am 08:48 AM
숭고한 코드 파이썬을 실행하는 방법
Apr 16, 2025 am 08:48 AM
Sublime 텍스트로 Python 코드를 실행하려면 먼저 Python 플러그인을 설치 한 다음 .py 파일을 작성하고 코드를 작성한 다음 CTRL B를 눌러 코드를 실행하면 콘솔에 출력이 표시됩니다.
 Windows 8에서 코드를 실행할 수 있습니다
Apr 15, 2025 pm 07:24 PM
Windows 8에서 코드를 실행할 수 있습니다
Apr 15, 2025 pm 07:24 PM
VS 코드는 Windows 8에서 실행될 수 있지만 경험은 크지 않을 수 있습니다. 먼저 시스템이 최신 패치로 업데이트되었는지 확인한 다음 시스템 아키텍처와 일치하는 VS 코드 설치 패키지를 다운로드하여 프롬프트대로 설치하십시오. 설치 후 일부 확장은 Windows 8과 호환되지 않을 수 있으며 대체 확장을 찾거나 가상 시스템에서 새로운 Windows 시스템을 사용해야합니다. 필요한 연장을 설치하여 제대로 작동하는지 확인하십시오. Windows 8에서는 VS 코드가 가능하지만 더 나은 개발 경험과 보안을 위해 새로운 Windows 시스템으로 업그레이드하는 것이 좋습니다.
 Python에서 비주얼 스튜디오 코드를 사용할 수 있습니다
Apr 15, 2025 pm 08:18 PM
Python에서 비주얼 스튜디오 코드를 사용할 수 있습니다
Apr 15, 2025 pm 08:18 PM
VS 코드는 파이썬을 작성하는 데 사용될 수 있으며 파이썬 애플리케이션을 개발하기에 이상적인 도구가되는 많은 기능을 제공합니다. 사용자는 다음을 수행 할 수 있습니다. Python 확장 기능을 설치하여 코드 완료, 구문 강조 및 디버깅과 같은 기능을 얻습니다. 디버거를 사용하여 코드를 단계별로 추적하고 오류를 찾아 수정하십시오. 버전 제어를 위해 git을 통합합니다. 코드 서식 도구를 사용하여 코드 일관성을 유지하십시오. 라인 도구를 사용하여 잠재적 인 문제를 미리 발견하십시오.
 vscode에서 코드를 작성하는 위치
Apr 15, 2025 pm 09:54 PM
vscode에서 코드를 작성하는 위치
Apr 15, 2025 pm 09:54 PM
Visual Studio Code (VSCODE)에서 코드를 작성하는 것은 간단하고 사용하기 쉽습니다. vscode를 설치하고, 프로젝트를 만들고, 언어를 선택하고, 파일을 만들고, 코드를 작성하고, 저장하고 실행합니다. VSCODE의 장점에는 크로스 플랫폼, 무료 및 오픈 소스, 강력한 기능, 풍부한 확장 및 경량 및 빠른가 포함됩니다.
