
오늘은

주로 참조 카운터 기반, 코드 재활용 및 마크 삭제로 보완
Python의 C 소스 코드에는 refchain이라는 순환 이중 연결 리스트가 있습니다. 이 연결 목록은 매우 훌륭합니다. Python 프로그램에서 개체가 생성되면 해당 개체가 참조 체인 연결 목록에 추가되기 때문입니다. 즉, 그는 모든 개체를 저장합니다.
age = 18number = age # 对象18的引用计数器 + 1del age # 对象18的引用计数器 - 1def run(arg): print(arg) run(number) # 刚开始执行函数时,对象18引用计数器 + 1,当函数执行完毕之后,对象18引用计数器 - 1 。num_list = [11,22,number] # 对象18的引用计数器 + 1复制代码
참조 카운터를 기반으로 하는 가비지 수집은 매우 편리하고 간단하지만 여전히 순환 참조 문제가 있어 일부 데이터를 정상적으로 재활용할 수 없습니다. 예:
v1 = [11,22,33] # refchain中创建一个列表对象,由于v1=对象,所以列表引对象用计数器为1.v2 = [44,55,66] # refchain中再创建一个列表对象,因v2=对象,所以列表对象引用计数器为1.v1.append(v2) # 把v2追加到v1中,则v2对应的[44,55,66]对象的引用计数器加1,最终为2.v2.append(v1) # 把v1追加到v1中,则v1对应的[11,22,33]对象的引用计数器加1,最终为2.del v1 # 引用计数器-1del v2 # 引用计数器-1复制代码
Mark Clear: 목록, 튜플, 사전, 컬렉션, 사용자 정의 클래스 및 기타 개체를 저장하기 위해 특별히 연결된 목록을 만든 다음 연결 목록의 개체에 대한 순환 참조가 있는지 확인하고, 그렇다면 양 당사자의 참조 카운터가 모두 - 1이 되도록 합니다.
세대 재활용: 표시 지우기에서 연결 목록을 최적화하고 순환 참조가 있을 수 있는 개체를 3개의 연결 목록으로 분할합니다. 연결 목록은 0/1/2 3세대라고 합니다. 임계값에 도달하면 해당 연결 목록의 각 개체가 검색됩니다. 단, 순환 참조는 제외됩니다. 각 개체는 1씩 감소하고 참조 카운터가 0인 개체는 삭제됩니다.
// 分代的C源码#define NUM_GENERATIONS 3struct gc_generation generations[NUM_GENERATIONS] = { /* PyGC_Head, threshold, count */
{{(uintptr_t)_GEN_HEAD(0), (uintptr_t)_GEN_HEAD(0)}, 700, 0}, // 0代
{{(uintptr_t)_GEN_HEAD(1), (uintptr_t)_GEN_HEAD(1)}, 10, 0}, // 1代
{{(uintptr_t)_GEN_HEAD(2), (uintptr_t)_GEN_HEAD(2)}, 10, 0}, // 2代};复制代码특별 참고 사항: 0세대와 1세대 및 2세대의 임계값과 개수는 서로 다른 의미를 갖습니다.
0세대, count는 0세대 연결 목록의 개체 수를 나타내고, 임계값은 0세대 연결 목록의 개체 수에 대한 임계값을 나타내며, 이를 초과하는 경우 0세대 검색 검사가 수행됩니다. 1세대, count는 0세대 연결 목록 검색 수를 나타내고, 임계값은 0세대 연결 목록 검색 수의 임계값을 나타냅니다. 임계값을 초과하는 경우 1세대 검색 검사가 수행됩니다. 2세대에서 count는 1세대 연결리스트의 스캔 횟수를 나타내고, 임계값은 1세대 연결리스트의 스캔 횟수에 대한 임계값을 나타내며, 임계값을 초과하는 경우 2세대 스캔 검사를 수행합니다.
C 언어의 최하층을 기반으로 메모리 관리와 가비지 컬렉션의 세부 과정을 다이어그램과 결합하여 설명합니다.
1단계: age=19 객체가 생성되면 해당 객체가 참조 체인 목록에 추가됩니다.
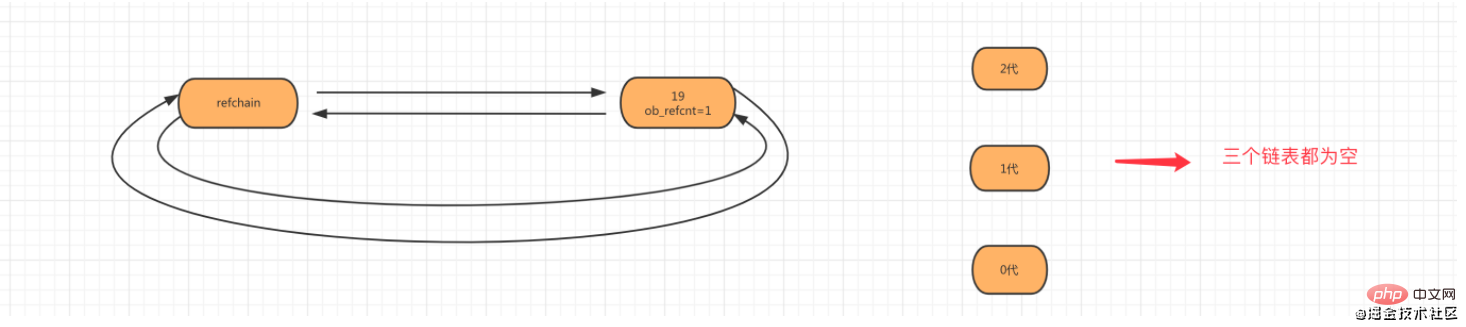
2단계: 객체 num_list = [11,22]가 생성되면 목록 객체가 참조 체인 및 0세대에 추가됩니다.
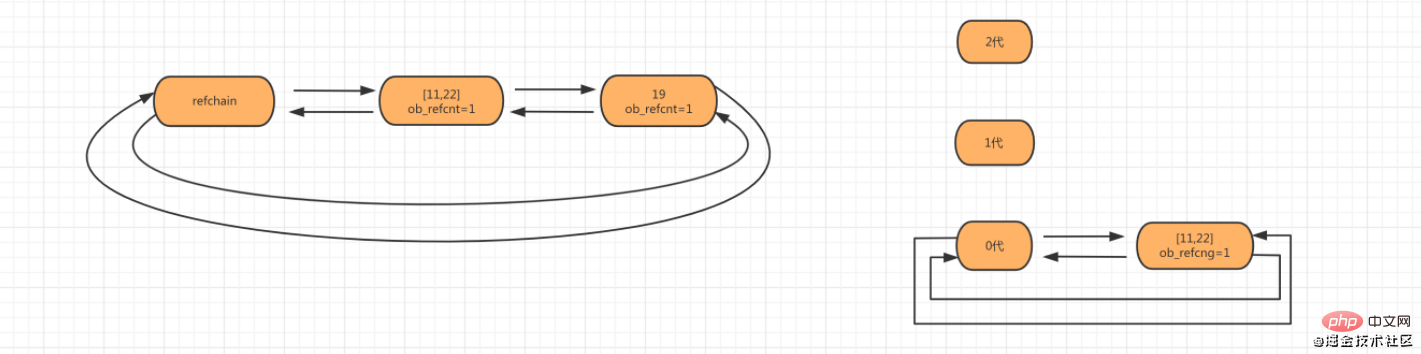
3단계: 새로 생성된 개체로 인해 0세대 연결 목록의 개체 수가 임계값 700보다 커지면 연결 목록의 개체를 스캔하고 확인합니다.
0세대가 임계값보다 큰 경우 하위 레이어는 0세대를 직접 스캔하지 않지만 먼저 2와 1도 임계값을 초과하는지 확인합니다.
연결된 연결 목록을 스캔할 때 주요 목적은 순환을 제거하는 것입니다. 참조 및 쓰레기 처리 세부 절차:
至此,垃圾回收的过程结束。
从上文大家可以了解到当对象的引用计数器为0时,就会被销毁并释放内存。而实际上他不是这么的简单粗暴,因为反复的创建和销毁会使程序的执行效率变低。Python中引入了“缓存机制”机制。
例如:引用计数器为0时,不会真正销毁对象,而是将他放到一个名为 free_list 的链表中,之后会再创建对象时不会在重新开辟内存,而是在free_list中将之前的对象来并重置内部的值来使用。
v1 = 3.14 # 开辟内存来存储float对象,并将对象添加到refchain链表。 print( id(v1) ) # 内存地址:4436033488 del v1 # 引用计数器-1,如果为0则在rechain链表中移除,不销毁对象,而是将对象添加到float的free_list. v2 = 9.999 # 优先去free_list中获取对象,并重置为9.999,如果free_list为空才重新开辟内存。 print( id(v2) ) # 内存地址:4436033488 # 注意:引用计数器为0时,会先判断free_list中缓存个数是否满了,未满则将对象缓存,已满则直接将对象销毁。复制代码
v1 = 38 # 去小数据池small_ints中获取38整数对象,将对象添加到refchain并让引用计数器+1。 print( id(v1)) #内存地址:4514343712 v2 = 38 # 去小数据池small_ints中获取38整数对象,将refchain中的对象的引用计数器+1。 print( id(v2) ) #内存地址:4514343712 # 注意:在解释器启动时候-5~256就已经被加入到small_ints链表中且引用计数器初始化为1, # 代码中使用的值时直接去small_ints中拿来用并将引用计数器+1即可。另外,small_ints中的数据引用计数器永远不会为0 # (初始化时就设置为1了),所以也不会被销毁。复制代码
v1 = "A" print( id(v1) ) # 输出:4517720496 del v1 v2 = "A" print( id(v1) ) # 输出:4517720496 # 除此之外,Python内部还对字符串做了驻留机制,针对只含有字母、数字、下划线的字符串(见源码Objects/codeobject.c),如果 # 内存中已存在则不会重新在创建而是使用原来的地址里(不会像free_list那样一直在内存存活,只有内存中有才能被重复利用)。 v1 = "asdfg" v2 = "asdfg" print(id(v1) == id(v2)) # 输出:True复制代码
list类型,维护的free_list数组最多可缓存80个list对象。
v1 = [11,22,33] print( id(v1) ) # 输出:4517628816del v1 v2 = ["你","好"] print( id(v2) ) # 输出:4517628816复制代码
v1 = (1,2)
print( id(v1) )del v1 # 因元组的数量为2,所以会把这个对象缓存到free_list[2]的链表中。v2 = ("哈哈哈","Alex") # 不会重新开辟内存,而是去free_list[2]对应的链表中拿到一个对象来使用。print( id(v2) )复制代码 v1 = {"k1":123}
print( id(v1) ) # 输出:4515998128
del v1
v2 = {"name":"哈哈哈","age":18,"gender":"男"}
print( id(v1) ) # 输出:4515998128复制代码C语言源码底层分析
相关免费学习推荐:python教程(视频)
위 내용은 Python 가비지 수집 메커니즘 분석의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!



















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



