

MySQL 실행 계획 설명 및 인덱스 데이터 구조 추론

mysql 튜토리얼이 열에서는 실행 계획 설명 및 인덱스 데이터 구조를 소개합니다

준비 작업
먼저 데이터베이스 테이블, 데모용 MySQL 테이블, 테이블 생성 문을 빌드합니다.
CREATE TABLE `emp` ( `id` int(11) NOT NULL AUTO_INCREMENT COMMENT '主键', `empno` int(11) DEFAULT NULL COMMENT '雇员工号', `ename` varchar(255) DEFAULT NULL COMMENT '雇员姓名', `job` varchar(255) DEFAULT NULL COMMENT '工作', `mgr` varchar(255) DEFAULT NULL COMMENT '经理的工号', `hiredate` date DEFAULT NULL COMMENT '雇用日期', `sal` double DEFAULT NULL COMMENT '工资', `comm` double DEFAULT NULL COMMENT '津贴', `deptno` int(11) DEFAULT NULL COMMENT '所属部门号', PRIMARY KEY (`id`) USING BTREE ) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='雇员表';CREATE TABLE `dept` ( `id` int(11) NOT NULL AUTO_INCREMENT COMMENT '主键', `deptno` int(11) DEFAULT NULL COMMENT '部门号', `dname` varchar(255) DEFAULT NULL COMMENT '部门名称', `loc` varchar(255) DEFAULT NULL COMMENT '地址', PRIMARY KEY (`id`) USING BTREE ) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='部门表';CREATE TABLE `salgrade` ( `id` int(11) NOT NULL COMMENT '主键', `grade` varchar(255) DEFAULT NULL COMMENT '等级', `lowsal` varchar(255) DEFAULT NULL COMMENT '最低工资', `hisal` varchar(255) DEFAULT NULL COMMENT '最高工资', PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='工资等级表';CREATE TABLE `bonus` ( `id` int(11) NOT NULL COMMENT '主键', `ename` varchar(255) DEFAULT NULL COMMENT '雇员姓名', `job` varchar(255) DEFAULT NULL COMMENT '工作', `sal` double DEFAULT NULL COMMENT '工资', `comm` double DEFAULT NULL COMMENT '津贴', PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='奖金表';复制代码
위의 표를 기반으로 후속 실행 계획, 쿼리 최적화, 인덱스 최적화 및 기타 지식 훈련을 수행합니다.
MySQL 실행 계획
SQL 튜닝을 수행하려면 튜닝할 SQL 문이 어떻게 실행되는지 알아야 하며, SQL 문의 구체적인 실행 프로세스를 확인하여 SQL 문의 실행 효율성을 높일 수 있습니다.
explain + SQL 문을 사용하여 SQL 쿼리 문을 실행하는 최적화 프로그램을 시뮬레이션하여 MySQL이 SQL 문을 처리하는 방법을 알 수 있습니다. explain + SQL语句来模拟优化器执行SQL查询语句,从而知道MySQL是如何处理SQL语句的。
关于explain可以看看官网介绍。
explain的输出格式
mysql> explain select * from emp; +----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------+| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------+| 1 | SIMPLE | emp | NULL | ALL | NULL | NULL | NULL | NULL | 1 | 100.00 | NULL | +----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------+复制代码
字段id,select_type等字段的解释:
| Column | Meaning | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| id | The SELECT identifier(该SELECT标识符) |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| select_type | The SELECT
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||
id, select_type과 같은 필드 설명: |
| 열 | 의미 | id |
|---|---|
SELECT 식별자(SELECT 식별자) |
|
SELECT 유형(SELECT 유형) |
|
| 출력 행에 대한 테이블(출력 테이블 행 이름) | |
| 일치하는 파티션 | |
| 조인 유형 | |
| 선택 가능한 인덱스) | |
| 실제로 색인은 selected(실제로 선택한 인덱스) | |
| 선택한 키의 길이(선택한 키의 길이) | |
| 인덱스와 비교한 열 |
id
select查询的序列号,包含一组数字,表示查询中执行select子句或者操作表的顺序。
id号分为三类:
- 如果id相同,那么执行顺序从上到下
mysql> explain select * from emp e join dept d on e.deptno = d.deptno join salgrade sg on e.sal between sg.lowsal and sg.hisal; +----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+----------------------------------------------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+----------------------------------------------------+ | 1 | SIMPLE | e | NULL | ALL | NULL | NULL | NULL | NULL | 1 | 100.00 | NULL | | 1 | SIMPLE | d | NULL | ALL | NULL | NULL | NULL | NULL | 1 | 100.00 | Using where; Using join buffer (Block Nested Loop) | | 1 | SIMPLE | sg | NULL | ALL | NULL | NULL | NULL | NULL | 1 | 100.00 | Using where; Using join buffer (Block Nested Loop) | +----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+----------------------------------------------------+复制代码
这个查询,用explain执行一下,
id序号都是1,那么MySQL的执行顺序就是从上到下执行的。
- 如果id不同,如果是子查询,id的序号会递增,id值越大优先级越高,越先被执行
mysql> explain select * from emp e where e.deptno in (select d.deptno from dept d where d.dname = 'SALEDept'); +----+--------------+-------------+------------+------+---------------+------+---------+------+------+----------+----------------------------------------------------+| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+--------------+-------------+------------+------+---------------+------+---------+------+------+----------+----------------------------------------------------+| 1 | SIMPLE | <subquery2> | NULL | ALL | NULL | NULL | NULL | NULL | NULL | 100.00 | NULL | | 1 | SIMPLE | e | NULL | ALL | NULL | NULL | NULL | NULL | 2 | 50.00 | Using where; Using join buffer (Block Nested Loop) | | 2 | MATERIALIZED | d | NULL | ALL | NULL | NULL | NULL | NULL | 1 | 100.00 | Using where | +----+--------------+-------------+------------+------+---------------+------+---------+------+------+----------+----------------------------------------------------+复制代码</subquery2>
这个例子的执行顺序是先执行
id为2的,然后执行id为1的。
- id相同和不同的,同时存在:相同的可以认为是一组,从上往下顺序执行,在所有组中,id值越大,优先级越高,越先执行
还是上面那个例子,先执行
id为2的,然后按顺序从上往下执行id为1的。
select_type
主要用来分辨查询的类型,是普通查询还是联合查询还是子查询。
select_type Value |
JSON Name | Meaning |
|---|---|---|
| SIMPLE | None | Simple SELECT (not using UNION or subqueries) |
| PRIMARY | None | Outermost SELECT |
| UNION | None | Second or later SELECT statement in a UNION |
| DEPENDENT UNION | dependent (true) | Second or later SELECT statement in a UNION, dependent on outer query |
| UNION RESULT | union_result | Result of a UNION. |
| SUBQUERY | None | First SELECT in subquery |
| DEPENDENT SUBQUERY | dependent (true) | First SELECT in subquery, dependent on outer query |
| DERIVED | None | Derived table |
| MATERIALIZED | materialized_from_subquery | Materialized subquery |
| UNCACHEABLE SUBQUERY | cacheable (false) | A subquery for which the result cannot be cached and must be re-evaluated for each row of the outer query |
| UNCACHEABLE UNION | cacheable (false) | The second or later select in a UNION that belongs to an uncacheable subquery (see UNCACHEABLE SUBQUERY) |
-
SIMPLE简单的查询,不包含子查询和union
mysql> explain select * from emp; +----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------+| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------+| 1 | SIMPLE | emp | NULL | ALL | NULL | NULL | NULL | NULL | 3 | 100.00 | NULL | +----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------+复制代码
-
primary查询中若包含任何复杂的子查询,最外层查询则被标记为Primary -
union若第二个select出现在union之后,则被标记为union
mysql> explain select * from emp where deptno = 1001 union select * from emp where sal | NULL | ALL | NULL | NULL | NULL | NULL | NULL | NULL | Using temporary | +----+--------------+------------+------------+------+---------------+------+---------+------+------+----------+-----------------+复制代码
这条语句的select_type包含了primary和union
-
dependent union跟union类似,此处的depentent表示union或union all联合而成的结果会受外部表影响 -
union result从union表获取结果的select -
dependent subquerysubquery的子查询要受到外部表查询的影响
mysql> explain select * from emp e where e.empno in ( select empno from emp where deptno = 1001 union select empno from emp where sal | NULL | ALL | NULL | NULL | NULL | NULL | NULL | NULL | Using temporary | +----+--------------------+------------+------------+------+---------------+------+---------+------+------+----------+-----------------+复制代码
这条SQL执行包含了PRIMARY、DEPENDENT SUBQUERY、DEPENDENT UNION和UNION RESULT
-
subquery在select或者where列表中包含子查询
举例:
mysql> explain select * from emp where sal > (select avg(sal) from emp) ; +----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+| 1 | PRIMARY | emp | NULL | ALL | NULL | NULL | NULL | NULL | 4 | 33.33 | Using where | | 2 | SUBQUERY | emp | NULL | ALL | NULL | NULL | NULL | NULL | 4 | 100.00 | NULL | +----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+复制代码
-
DERIVEDfrom子句中出现的子查询,也叫做派生表 -
MATERIALIZEDMaterialized subquery? -
UNCACHEABLE SUBQUERY表示使用子查询的结果不能被缓存
例如:
mysql> explain select * from emp where empno = (select empno from emp where deptno=@@sort_buffer_size); +----+----------------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+----------------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+| 1 | PRIMARY | emp | NULL | ALL | NULL | NULL | NULL | NULL | 4 | 100.00 | Using where | | 2 | UNCACHEABLE SUBQUERY | emp | NULL | ALL | NULL | NULL | NULL | NULL | 4 | 25.00 | Using where | +----+----------------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+复制代码
-
uncacheable union表示union的查询结果不能被缓存
table
对应行正在访问哪一个表,表名或者别名,可能是临时表或者union合并结果集。
- 如果是具体的表名,则表明从实际的物理表中获取数据,当然也可以是表的别名
- 表名是derivedN的形式,表示使用了id为N的查询产生的衍生表
- 当有union result的时候,表名是union n1,n2等的形式,n1,n2表示参与union的id
type
type显示的是访问类型,访问类型表示我是以何种方式去访问我们的数据,最容易想到的是全表扫描,直接暴力的遍历一张表去寻找需要的数据,效率非常低下。
访问的类型有很多,效率从最好到最坏依次是:
system > const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL
一般情况下,得保证查询至少达到range级别,最好能达到ref
-
all全表扫描,一般情况下出现这样的sql语句而且数据量比较大的话那么就需要进行优化
通常,可以通过添加索引来避免ALL
-
index全索引扫描这个比all的效率要好,主要有两种情况:- 一种是当前的查询时覆盖索引,即我们需要的数据在索引中就可以索取
- 一是使用了索引进行排序,这样就避免数据的重排序
-
range表示利用索引查询的时候限制了范围,在指定范围内进行查询,这样避免了index的全索引扫描,适用的操作符: =, , >, >=,
官网上举例如下:
SELECT * FROM tbl_name WHERE key_column = 10;
SELECT * FROM tbl_name WHERE key_column BETWEEN 10 and 20;
SELECT * FROM tbl_name WHERE key_column IN (10,20,30);
SELECT * FROM tbl_name WHERE key_part1 = 10 AND key_part2 IN (10,20,30);
-
index_subquery利用索引来关联子查询,不再扫描全表
value IN (SELECT key_column FROM single_table WHERE some_expr)
-
unique_subquery该连接类型类似与index_subquery,使用的是唯一索引
value IN (SELECT primary_key FROM single_table WHERE some_expr)
-
index_merge在查询过程中需要多个索引组合使用 -
ref_or_null对于某个字段既需要关联条件,也需要null值的情况下,查询优化器会选择这种访问方式
SELECT * FROM ref_table
WHERE key_column=expr OR key_column IS NULL;
-
fulltext使用FULLTEXT索引执行join -
ref使用了非唯一性索引进行数据的查找
SELECT * FROM ref_table WHERE key_column=expr;
SELECT * FROM ref_table,other_table WHERE ref_table.key_column=other_table.column;
SELECT * FROM ref_table,other_table WHERE ref_table.key_column_part1=other_table.column AND ref_table.key_column_part2=1;
-
eq_ref使用唯一性索引进行数据查找
SELECT * FROM ref_table,other_table WHERE ref_table.key_column=other_table.column;
SELECT * FROM ref_table,other_table WHERE ref_table.key_column_part1=other_table.column AND ref_table.key_column_part2=1;
-
const这个表至多有一个匹配行
SELECT * FROM tbl_name WHERE primary_key=1;
SELECT * FROM tbl_name WHERE primary_key_part1=1 AND primary_key_part2=2;
例如:
mysql> explain select * from emp where id = 1; +----+-------------+-------+------------+-------+---------------+---------+---------+-------+------+----------+-------+| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+-------+---------------+---------+---------+-------+------+----------+-------+| 1 | SIMPLE | emp | NULL | const | PRIMARY | PRIMARY | 4 | const | 1 | 100.00 | NULL | +----+-------------+-------+------------+-------+---------------+---------+---------+-------+------+----------+-------+复制代码
-
system表只有一行记录(等于系统表),这是const类型的特例,平时不会出现
possible_keys
显示可能应用在这张表中的索引,一个或多个,查询涉及到的字段上若存在索引,则该索引将被列出,但不一定被查询实际使用

key
实际使用的索引,如果为null,则没有使用索引,查询中若使用了覆盖索引,则该索引和查询的select字段重叠

key_len
表示索引中使用的字节数,可以通过key_len计算查询中使用的索引长度,在不损失精度的情况下长度越短越好
ref
显示索引的哪一列被使用了,如果可能的话,是一个常数
rows
根据表的统计信息及索引使用情况,大致估算出找出所需记录需要读取的行数,此参数很重要,直接反应的sql找了多少数据,在完成目的的情况下越少越好

extra
包含额外的信息
-
using filesort说明mysql无法利用索引进行排序,只能利用排序算法进行排序,会消耗额外的位置 -
using temporary建立临时表来保存中间结果,查询完成之后把临时表删除 -
using index这个表示当前的查询是覆盖索引的,直接从索引中读取数据,而不用访问数据表。如果同时出现using where 表明索引被用来执行索引键值的查找,如果没有,表示索引被用来读取数据,而不是真的查找 -
using where使用where进行条件过滤 -
using join buffer使用连接缓存 -
impossible wherewhere语句的结果总是false
MySQL索引基本知识
想要了解索引的优化方式,必须要对索引的底层原理有所了解。
索引的优点
- 大大减少了服务器需要扫描的数据量
- 帮助服务器避免排序和临时表
- 将随机io变成顺序io(提升效率)
索引的用处
- 快速查找匹配WHERE子句的行
- 从consideration中消除行,如果可以在多个索引之间进行选择,mysql通常会使用找到最少行的索引
- 如果表具有多列索引,则优化器可以使用索引的任何最左前缀来查找行
- 当有表连接的时候,从其他表检索行数据
- 查找特定索引列的min或max值
- 如果排序或分组时在可用索引的最左前缀上完成的,则对表进行排序和分组
- 在某些情况下,可以优化查询以检索值而无需查询数据行
MySQL 실행 계획 설명 및 인덱스 데이터 구조 추론
MySQL索引数据结构推演
索引用于快速查找具有特定列值的行。
如果没有索引,MySQL必须从第一行开始,然后通读整个表以找到相关的行。
表越大花费的时间越多,如果表中有相关列的索引,MySQL可以快速确定要在数据文件中间查找的位置,而不必查看所有数据。这比顺序读取每一行要快得多。
既然MySQL索引能帮助我们快速查询到数据,那么它的底层是怎么存储数据的呢?
几种可能的存储结构
hash
hash表的索引格式

해시 테이블에 데이터를 저장하는 것의 단점:
- 해시 저장소를 사용하는 경우 모든 데이터 파일을 메모리에 추가해야 하며 이로 인해 더 많은 메모리 공간이 소모됩니다.
- 모든 쿼리가 동일한 쿼리라면 해싱은 실제로 그러나 실제 작업 환경에서는 동등한 쿼리보다는 범위 검색 데이터가 더 많습니다. 이 경우 해시는 적합하지 않습니다
실제로 MySQL 스토리지 엔진이 메모리 code>, 인덱스 데이터 구조는 해시 테이블을 사용합니다. <code>memory时,索引数据结构采用的就是hash表。
MySQL 실행 계획 설명 및 인덱스 데이터 구조 추론
MySQL 실행 계획 설명 및 인덱스 데이터 구조 추론的结构是这样的:
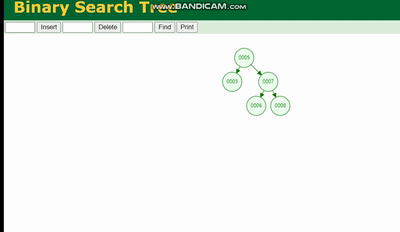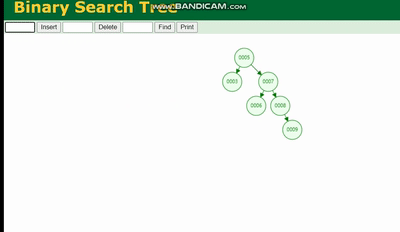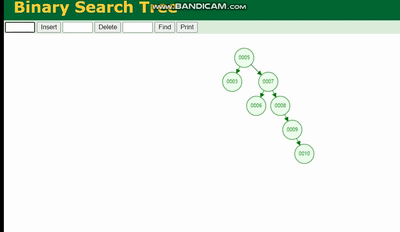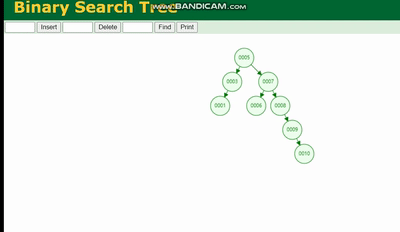
MySQL 실행 계획 설명 및 인덱스 데이터 구조 추론会因为树的深度而造成数据倾斜,如果树的深度过深,会造成io次数变多,影响数据读取的效率。
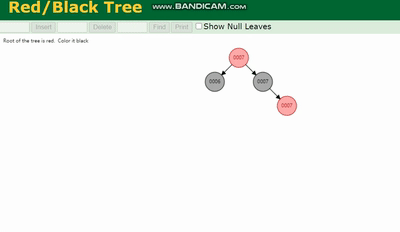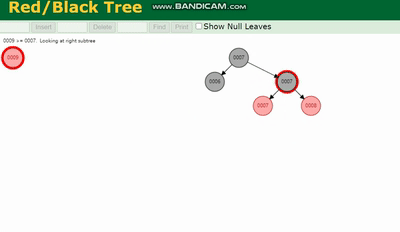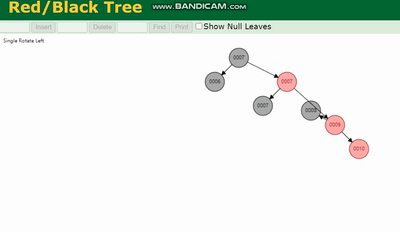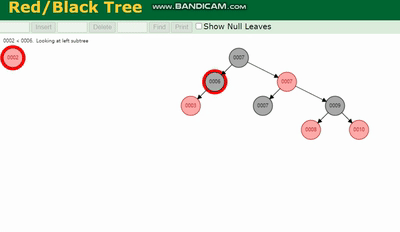
MySQL 실행 계획 설명 및 인덱스 데이터 구조 추론 需要旋转,看图例:
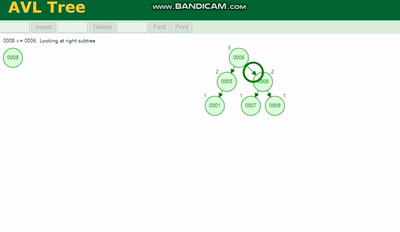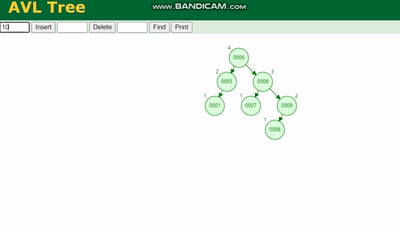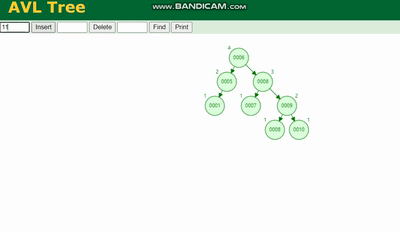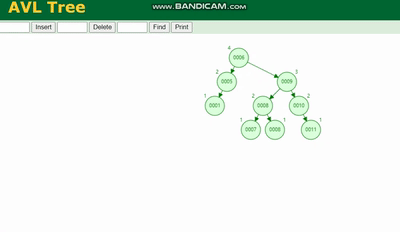
MySQL 실행 계획 설명 및 인덱스 데이터 구조 추론 除了旋转操作还多了一个变色的功能(为了减少旋转),这样虽然插入的速度快,但是损失了查询的效率。
MySQL 실행 계획 설명 및 인덱스 데이터 구조 추론、MySQL 실행 계획 설명 및 인덱스 데이터 구조 추론、MySQL 실행 계획 설명 및 인덱스 데이터 구조 추론 都会因为树的深度过深而造成io次数变多,影响数据读取的效率。
再来看一下 B树
B树特点:
- 所有键值分布在整颗树中
- 搜索有可能在非叶子结点结束,在关键字全集内做一次查找,性能逼近二分查找
- 每个节点最多拥有m个子树
- 根节点至少有2个子树
- 分支节点至少拥有m/2颗子树(除根节点和叶子节点外都是分支节点)
- 所有叶子节点都在同一层、每个节点最多可以有m-1个key,并且以升序排列
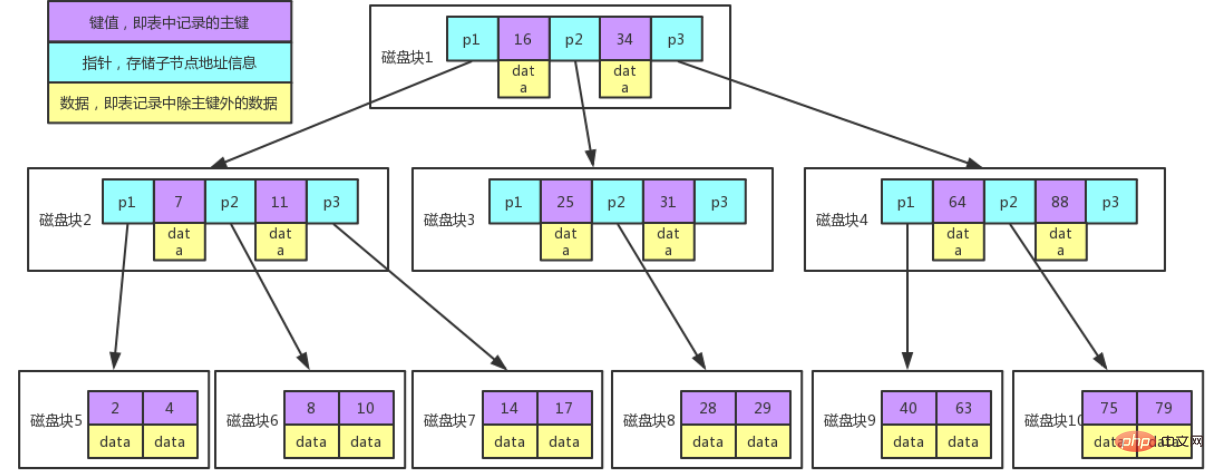
图例说明:
每个节点占用一个磁盘块,一个节点上有两个升序排序的关键字和三个指向子树根节点的指针,指针存储的是子节点所在磁盘块的地址。
两个关键词划分成的三个范围域对应三个指针指向的子树的数据的范围域。
以根节点为例,关键字为 16 和 34,P1 指针指向的子树的数据范围为小于 16,P2 指针指向的子树的数据范围为 16~34,P3 指针指向的子树的数据范围为大于 34。
查找关键字过程:
1、根据根节点找到磁盘块 1,读入内存。【磁盘 I/O 操作第 1 次】
2、比较关键字 28 在区间(16,34),找到磁盘块 1 的指针 P2。
3、根据 P2 指针找到磁盘块 3,读入内存。【磁盘 I/O 操作第 2 次】
4、比较关键字 28 在区间(25,31),找到磁盘块 3 的指针 P2。
5、根据 P2 指针找到磁盘块 8,读入内存。【磁盘 I/O 操作第 3 次】
6、在磁盘块 8 中的关键字列表中找到关键字 28。
由此,我们可以得知MySQL 실행 계획 설명 및 인덱스 데이터 구조 추론的缺点:
- 每个节点都有key,同时也包含data,而每个页存储空间是有限的,如果data比较大的话会导致每个节点存储的key数量变小
- 当存储的数据量很大的时候会导致深度较大,增大查询时磁盘io次数,进而影响查询性能
那么MySQL索引数据结构是什么呢
官网:Most MySQL indexes (PRIMARY KEY, UNIQUE, INDEX, and FULLTEXT) are stored in B-trees
不要误会,其实MySQL索引的存储结构是B+树,上面我们一顿分析,知道B树
이진 트리
이진 트리의 구조는 다음과 같습니다. 이진 트리는 트리의 깊이로 인해 데이터 왜곡을 발생시킵니다. 트리가 너무 깊어지면 IO 횟수가 늘어나 데이터 읽기 효율성에 영향을 미칩니다.
이진 트리는 트리의 깊이로 인해 데이터 왜곡을 발생시킵니다. 트리가 너무 깊어지면 IO 횟수가 늘어나 데이터 읽기 효율성에 영향을 미칩니다.
AVL 트리
를 회전해야 합니다. 범례를 참조하세요.
색상 변경 함수(회전을 줄이기 위해) 삽입 속도는 빠르지만 쿼리 효율성이 떨어집니다. 🎜🎜<img class="lazyload lazy" src="/static/imghw/default1.png" data-src="https://img.php.cn/upload/article/000/000/052/31bcbfbf611743c8c81e5f982e3f5b2b-7.gif" alt="레드 블랙 트리" data- style="max-width:90%" data- style="max-width:90%">🎜🎜🎜Binary tree🎜, 🎜AVL tree🎜, 🎜Red-black tree🎜는 모두 트리 깊이가 너무 깊어 데이터 효율성에 영향을 미치기 때문에 더 많은 IO 시간을 발생시킵니다. 독서. 🎜🎜 🎜B-tree🎜🎜🎜를 살펴보겠습니다. B-tree의 특징: 🎜<ul>🎜모든 키 값은 전체 트리에 분산되어 있습니다.🎜🎜검색은 리프가 아닌 노드에서 끝날 수 있으며, 검색은 전체 키워드 집합 내에서 수행됩니다. 성능은 이진 검색에 가깝습니다.🎜🎜각 노드에는 최대 m개의 하위 트리가 있습니다.🎜🎜루트 노드에는 최소 2개의 하위 트리가 있습니다.🎜🎜분기 노드에는 최소 m/2개의 하위 트리가 있습니다( 루트 노드와 리프 노드를 제외한 모든 분기 노드)🎜🎜모두 리프 노드는 모두 동일한 레이어에 있고, 각 노드는 최대 m-1개의 키를 가질 수 있으며 오름차순으로 정렬됩니다🎜</ul>🎜<img class="lazyload lazy" src="/static/imghw/default1.png" data-src="https://img.php.cn/upload/article/000/000/052/4aca3b2aed5686c270fecd75338a9566-8.png" alt="B-트리 저장소" data- style="max-width:90%" data- style="max-width:90%">🎜🎜🎜범례 설명🎜:🎜🎜각 노드 하나의 디스크 블록을 점유하고, 하나의 노드에는 하위 트리의 루트 노드에 대한 두 개의 오름차순 키와 세 개의 포인터가 있습니다. 포인터는 디스크 블록의 주소를 저장합니다. 하위 노드가 위치합니다. 🎜🎜두 개의 키워드로 나누어진 세 개의 범위 필드는 세 개의 포인터가 가리키는 하위 트리의 데이터 범위 필드에 해당합니다. 🎜🎜루트 노드를 예로 들면, 키워드는 16과 34이고, P1 포인터가 가리키는 하위 트리의 데이터 범위는 16 미만이고, P2 포인터가 가리키는 하위 트리의 데이터 범위는 16~34이며, P3 포인터가 가리키는 하위 트리의 데이터 범위가 34보다 큽니다. 🎜🎜키워드 검색 과정: 🎜🎜1. 루트 노드를 기준으로 디스크 블록 1을 찾아 메모리로 읽어옵니다. [디스크 I/O 작업 1차] 🎜🎜2. 간격(16,34)에서 키워드 28을 비교하여 디스크 블록 1의 포인터 P2를 찾습니다. 🎜🎜3. P2 포인터에 따라 디스크 블록 3을 찾아 메모리로 읽습니다. [디스크 I/O 작업 2차] 🎜🎜4. 간격(25,31)에서 키워드 28을 비교하여 디스크 블록 3의 포인터 P2를 찾습니다. 🎜🎜5. P2 포인터에 따라 디스크 블록 8을 찾아 메모리로 읽어옵니다. [디스크 I/O 작업 3번째] 🎜🎜6. 디스크 블록 8의 키워드 목록에서 키워드 28을 찾습니다. 🎜🎜이로부터 B-트리 저장의 단점을 알 수 있습니다: 🎜<ul>🎜각 노드에는 키가 있고 데이터도 포함되어 있으며, 각 페이지의 저장 공간은 상대적으로 제한됩니다. 왜냐하면 각 노드에 저장되는 키의 개수가 작아지기 때문입니다🎜🎜저장된 데이터의 양이 많으면 깊이가 깊어지고, 쿼리 중 디스크 IO 횟수가 늘어나 쿼리 성능에 영향을 미치게 됩니다🎜</ul>
<h3 id="그럼-MySQL-인덱스-데이터-구조는-무엇인가요">그럼 MySQL 인덱스 데이터 구조는 무엇인가요?</h3>
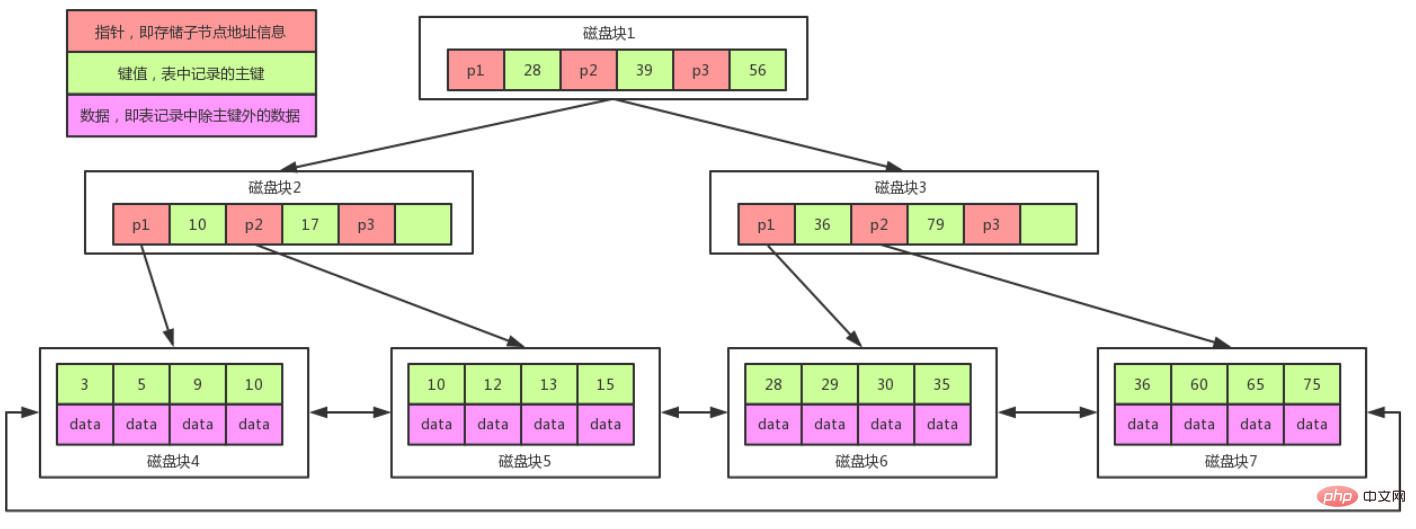
<blockquote>🎜공식 웹사이트: 대부분의 MySQL 인덱스(PRIMARY KEY, UNIQUE, INDEX 및 FULLTEXT)는 다음 위치에 저장됩니다. B-trees🎜</blockquote>🎜오해하지 마세요. 실제로 MySQL 인덱스의 저장 구조는 <code>B+ 트리입니다. 위의 분석을 통해 B 트리를 알 수 있습니다. 는 부적절합니다. 🎜🎜🎜mysql 인덱스 데이터 구조---B+Tree🎜🎜🎜B+Tree는 BTree를 기반으로 한 최적화입니다. 변경 사항은 다음과 같습니다. 🎜🎜1 B+Tree의 각 노드에는 더 많은 노드가 포함될 수 있습니다. 첫 번째 이유는 트리의 높이를 줄이기 위함이고, 두 번째 이유는 데이터 범위를 여러 간격으로 변경할수록 데이터 검색 속도가 빨라지기 때문입니다. 🎜🎜2. 리프가 아닌 노드는 키를 저장하고, 리프 노드는 키와 데이터를 저장합니다. 🎜🎜3. 리프 노드의 두 포인터가 서로 연결되어(디스크의 미리 읽기 특성에 맞춰) 순차 쿼리 성능이 더 높습니다. 🎜🎜B+ 트리 저장 및 검색 다이어그램: 🎜🎜🎜🎜注意:
在B+Tree上有两个头指针,一个指向根节点,另一个指向关键字最小的叶子节点,而且所有叶子节点(即数据节点)之间是一种链式环结构。
因此可以对 B+Tree 进行两种查找运算:一种是对于主键的范围查找和分页查找,另一种是从根节点开始,进行随机查找。
由于B+树叶子结点只存放data,根节点只存放key,那么我们计算一下,即使只有3层B+树,也能制成千万级别的数据。
你得知道的技(zhuang)术(b)名词
假设有这样一个表如下,其中id是主键:
mysql> select * from stu; +------+---------+------+| id | name | age | +------+---------+------+| 1 | Jack Ma | 18 | | 2 | Pony | 19 | +------+---------+------+复制代码
回表
我们对普通列建普通索引,这时候我们来查:
select * from stu where name='Pony';复制代码
由于name建了索引,查询时先找name的B+树,找到主键id后,再找主键id的B+树,从而找到整行记录。
这个最终会回到主键上来查找B+树,这个就是回表。
覆盖索引
如果是这个查询:
mysql> select id from stu where name='Pony';复制代码
就没有回表了,因为直接找到主键id,返回就完了,不需要再找其他的了。
没有回表就叫覆盖索引。
最左匹配
再来以name和age两个字段建组合索引(name, age),然后有这样一个查询:
select * from stu where name=? and age=?复制代码
这时按照组合索引(name, age)查询,先匹配name,再匹配age,如果查询变成这样:
select * from stu where age=?复制代码
直接不按name查了,此时索引不会生效,也就是不会按照索引查询---这就是最左匹配原则。
加入我就要按age查,还要有索引来优化呢?可以这样做:
- (推荐)把组合索引(name, age)换个顺序,建(age, name)索引
- 或者直接把
age字段单独建个索引
索引下推
可能也叫
谓词下推。。。
select t1.name,t2.name from t1 join t2 on t1.id=t2.id复制代码
t1有10条记录,t2有20条记录。
我们猜想一下,这个要么按这个方式执行:
先t1,t2按id合并(合并后20条),然后再查t1.name,t2.name
或者:
先把t1.name,t2.name找出来,再按照id关联
如果不使用索引条件下推优化的话,MySQL只能根据索引查询出t1,t2合并后的所有行,然后再依次比较是否符合全部条件。
当使用了索引条件下推优化技术后,可以通过索引中存储的数据判断当前索引对应的数据是否符合条件,只有符合条件的数据才将整行数据查询出来。
小结
-
Explain为了知道优化SQL语句的执行,需要查看SQL语句的具体执行过程,以加快SQL语句的执行效率。 - 索引优点及用处。
- 索引采用的数据结构是B+树。
- 回表,覆盖索引,最左匹配和索引下推。
更多相关免费学习推荐:mysql教程(视频)
위 내용은 MySQL 실행 계획 설명 및 인덱스 데이터 구조 추론의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

Video Face Swap
완전히 무료인 AI 얼굴 교환 도구를 사용하여 모든 비디오의 얼굴을 쉽게 바꾸세요!

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)



 MySQL의 역할 : 웹 응용 프로그램의 데이터베이스
Apr 17, 2025 am 12:23 AM
MySQL의 역할 : 웹 응용 프로그램의 데이터베이스
Apr 17, 2025 am 12:23 AM
웹 응용 프로그램에서 MySQL의 주요 역할은 데이터를 저장하고 관리하는 것입니다. 1. MySQL은 사용자 정보, 제품 카탈로그, 트랜잭션 레코드 및 기타 데이터를 효율적으로 처리합니다. 2. SQL 쿼리를 통해 개발자는 데이터베이스에서 정보를 추출하여 동적 컨텐츠를 생성 할 수 있습니다. 3.mysql은 클라이언트-서버 모델을 기반으로 작동하여 허용 가능한 쿼리 속도를 보장합니다.
 Docker의 MySQL을 시작하는 방법
Apr 15, 2025 pm 12:09 PM
Docker의 MySQL을 시작하는 방법
Apr 15, 2025 pm 12:09 PM
Docker에서 MySQL을 시작하는 프로세스는 다음 단계로 구성됩니다. MySQL 이미지를 가져와 컨테이너를 작성하고 시작하고 루트 사용자 암호를 설정하고 포트 확인 연결을 매핑하고 데이터베이스를 작성하고 사용자는 데이터베이스에 모든 권한을 부여합니다.
 LARAVEL 소개 예
Apr 18, 2025 pm 12:45 PM
LARAVEL 소개 예
Apr 18, 2025 pm 12:45 PM
Laravel은 웹 응용 프로그램을 쉽게 구축하기위한 PHP 프레임 워크입니다. 설치 : Composer를 사용하여 전 세계적으로 Laravel CLI를 설치하고 프로젝트 디렉토리에서 응용 프로그램을 작성하는 등 다양한 기능을 제공합니다. 라우팅 : Routes/Web.php에서 URL과 핸들러 간의 관계를 정의하십시오. 보기 : 리소스/뷰에서보기를 작성하여 응용 프로그램의 인터페이스를 렌더링합니다. 데이터베이스 통합 : MySQL과 같은 데이터베이스와 상자 외 통합을 제공하고 마이그레이션을 사용하여 테이블을 작성하고 수정합니다. 모델 및 컨트롤러 : 모델은 데이터베이스 엔티티를 나타내고 컨트롤러는 HTTP 요청을 처리합니다.
 데이터베이스 연결 문제 해결 : Minii/DB 라이브러리 사용 실질적인 사례
Apr 18, 2025 am 07:09 AM
데이터베이스 연결 문제 해결 : Minii/DB 라이브러리 사용 실질적인 사례
Apr 18, 2025 am 07:09 AM
작은 응용 프로그램을 개발할 때 까다로운 문제가 발생했습니다. 가벼운 데이터베이스 운영 라이브러리를 신속하게 통합해야합니다. 여러 라이브러리를 시도한 후에는 기능이 너무 많거나 호환되지 않는다는 것을 알았습니다. 결국, 나는 내 문제를 완벽하게 해결하는 YII2를 기반으로 단순화 된 버전 인 Minii/DB를 발견했습니다.
 Laravel 프레임 워크 설치 방법
Apr 18, 2025 pm 12:54 PM
Laravel 프레임 워크 설치 방법
Apr 18, 2025 pm 12:54 PM
기사 요약 :이 기사는 Laravel 프레임 워크를 쉽게 설치하는 방법에 대한 독자들을 안내하기위한 자세한 단계별 지침을 제공합니다. Laravel은 웹 애플리케이션의 개발 프로세스를 가속화하는 강력한 PHP 프레임 워크입니다. 이 자습서는 시스템 요구 사항에서 데이터베이스 구성 및 라우팅 설정에 이르기까지 설치 프로세스를 다룹니다. 이러한 단계를 수행함으로써 독자들은 라벨 프로젝트를위한 탄탄한 토대를 빠르고 효율적으로 놓을 수 있습니다.
 CentOS7에 MySQL을 설치하는 방법 7
Apr 14, 2025 pm 08:30 PM
CentOS7에 MySQL을 설치하는 방법 7
Apr 14, 2025 pm 08:30 PM
MySQL을 우아하게 설치하는 열쇠는 공식 MySQL 저장소를 추가하는 것입니다. 특정 단계는 다음과 같습니다. 피싱 공격을 방지하기 위해 MySQL 공식 GPG 키를 다운로드하십시오. MySQL 리포지토리 파일 추가 : rpm -uvh https://dev.mysql.com/get/mysql80-community-release-el7-3.noarch.rpm yum repository cache : yum 업데이트 설치 mysql : yum 설치 mysql-server startup startup mysql 서비스 : systemctl start mysqlctl start mysqlctl.
 MySQL 및 Phpmyadmin : 핵심 기능 및 기능
Apr 22, 2025 am 12:12 AM
MySQL 및 Phpmyadmin : 핵심 기능 및 기능
Apr 22, 2025 am 12:12 AM
MySQL 및 Phpmyadmin은 강력한 데이터베이스 관리 도구입니다. 1) MySQL은 데이터베이스 및 테이블을 작성하고 DML 및 SQL 쿼리를 실행하는 데 사용됩니다. 2) PHPMYADMIN은 데이터베이스 관리, 테이블 구조 관리, 데이터 운영 및 사용자 권한 관리에 직관적 인 인터페이스를 제공합니다.
 MySQL 대 기타 프로그래밍 언어 : 비교
Apr 19, 2025 am 12:22 AM
MySQL 대 기타 프로그래밍 언어 : 비교
Apr 19, 2025 am 12:22 AM
다른 프로그래밍 언어와 비교할 때 MySQL은 주로 데이터를 저장하고 관리하는 데 사용되는 반면 Python, Java 및 C와 같은 다른 언어는 논리적 처리 및 응용 프로그램 개발에 사용됩니다. MySQL은 데이터 관리 요구에 적합한 고성능, 확장 성 및 크로스 플랫폼 지원으로 유명하며 다른 언어는 데이터 분석, 엔터프라이즈 애플리케이션 및 시스템 프로그래밍과 같은 해당 분야에서 이점이 있습니다.
