

무료 추천: python 비디오 튜토리얼
오랜만에 크롤러 글을 작성했습니다. 이전에 Honor of Kings의 모든 영웅 스킨을 크롤링하기 위해 20줄 Python 코드를 작성했습니다. , 그리고 반응이 뜨거웠고 그 중 많은 학생들이 리그오브레전드 공식 홈페이지에 스킨 크롤링에 대한 또 다른 글을 써주길 희망했지만, 할 일이 너무 많아서 지금까지 계속해서 미뤄왔습니다. 따라서 이 기사에서는 리그 오브 레전드 웹사이트 전체를 크롤링하는 방법을 알아봅니다.
import requests url = 'http://www.baidu.com'response = requests.get(url)print(response.text)
get을 통해 함수는 지정된 매개변수를 사용하여 URL에 요청을 보낼 수 있습니다. 얻은 응답 개체는 많은 응답 정보를 캡슐화합니다. 획득한 콘텐츠에 잘못된 문자가 있습니다. 이는 일관되지 않은 인코딩 및 디코딩으로 인해 발생합니다. 먼저 바이너리 데이터를 가져온 다음 다시 디코딩하세요.
import requests url = 'http://www.baidu.com'response = requests.get(url)print(response.content.decode())
get函数就能够向指定参数的url发送请求,得到的response对象中封装了很多响应的信息,其中的text即为响应内容,注意到获取的内容里有乱码,这是编解码不一致造成的,只需先获取二进制数据,然后重新解码即可:import json
json_str = '{"name":"zhangsan","age":"20"}'rs = json.loads(json_str)print(type(rs))print(rs)运行结果:
json模块可以对json字符串和Python数据类型进行相互转换,比如将json转换为Python对象:
<class>
{'name': 'zhangsan', 'age': '20'}</class>使用loads函数即可将json字符串转为字典类型,运行结果:
import json
str_dict = {'name': 'zhangsan', 'age': '20'}json_str = json.dumps(str_dict)print(type(json_str))print(json_str)而若是想将Python数据转为json字符串,也非常简单:
<class>
{"name": "zhangsan", "age": "20"}</class>通过dumps函数即可将Python数据转为json字符串,运行结果:
https://game.gtimg.cn/images/lol/act/img/skin/big1000.jpg https://game.gtimg.cn/images/lol/act/img/skin/big1001.jpg https://game.gtimg.cn/images/lol/act/img/skin/big1002.jpg https://game.gtimg.cn/images/lol/act/img/skin/big1003.jpg https://game.gtimg.cn/images/lol/act/img/skin/big1004.jpg https://game.gtimg.cn/images/lol/act/img/skin/big1005.jpg https://game.gtimg.cn/images/lol/act/img/skin/big1006.jpg https://game.gtimg.cn/images/lol/act/img/skin/big1007.jpg https://game.gtimg.cn/images/lol/act/img/skin/big1008.jpg https://game.gtimg.cn/images/lol/act/img/skin/big1009.jpg https://game.gtimg.cn/images/lol/act/img/skin/big1010.jpg https://game.gtimg.cn/images/lol/act/img/skin/big1011.jpg https://game.gtimg.cn/images/lol/act/img/skin/big1012.jpg
前面介绍了两个模块,通过这两个模块我们就能够完成这个程序了。
在正式开始编写代码之前,我们首先需要分析数据来源,来到官网:https://lol.qq.com/main.shtml,往下拉找到英雄列表: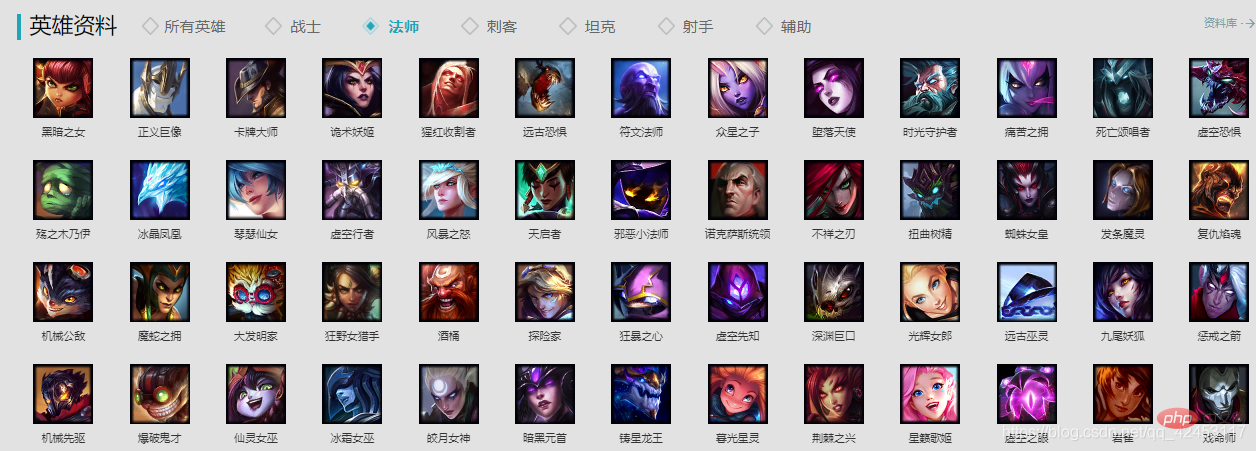
我们随意点击一个英雄进去查看: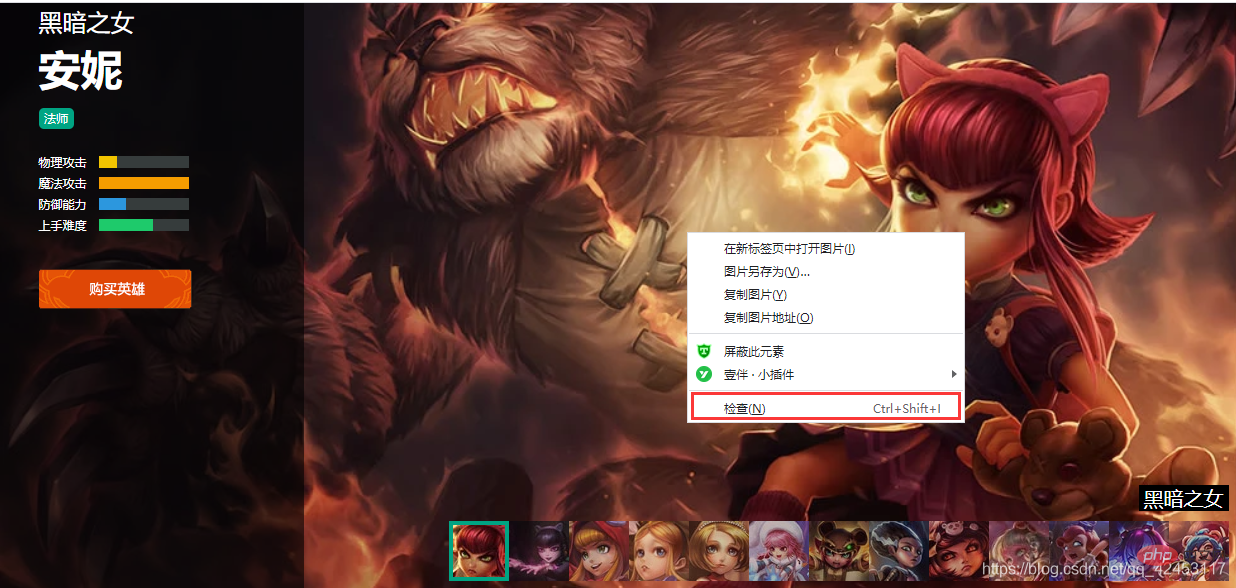
在皮肤图片上右键点击检查: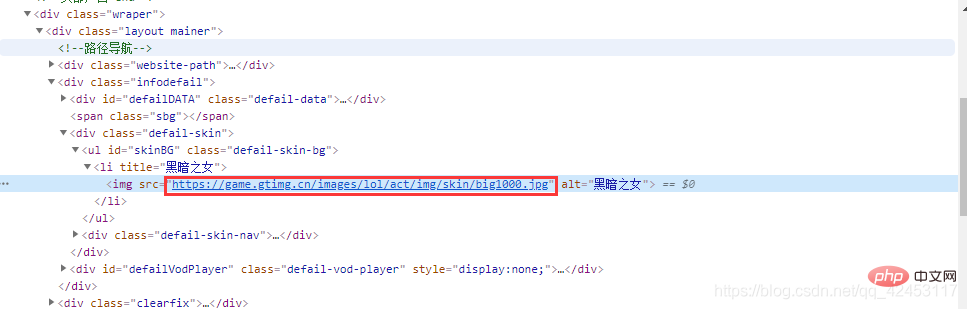
这样就找到了这个皮肤的url,我们再选择第二个皮肤,看看它的url: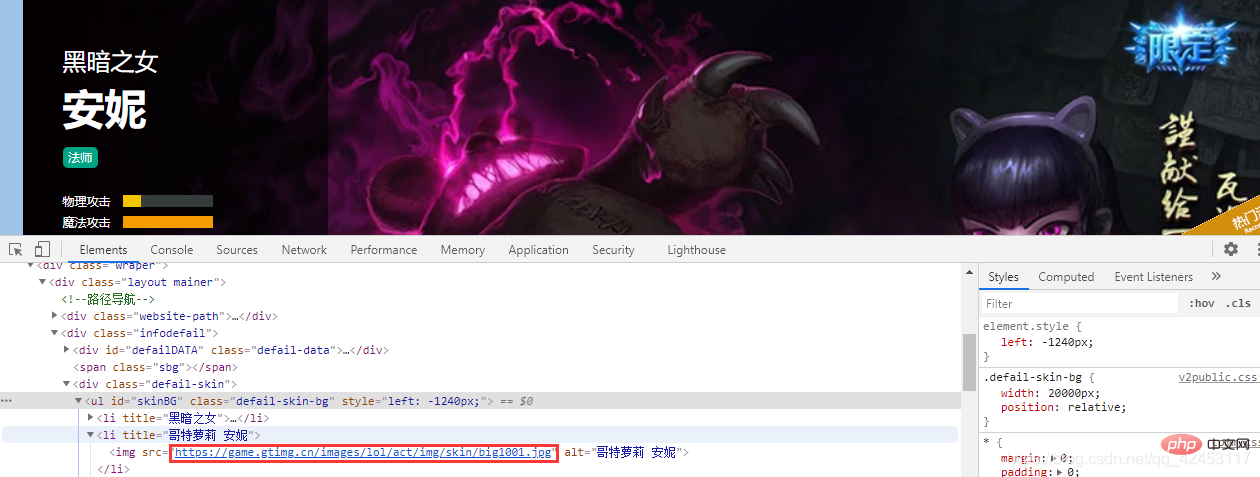
我们将安妮所有皮肤的url全部拿出来看看:
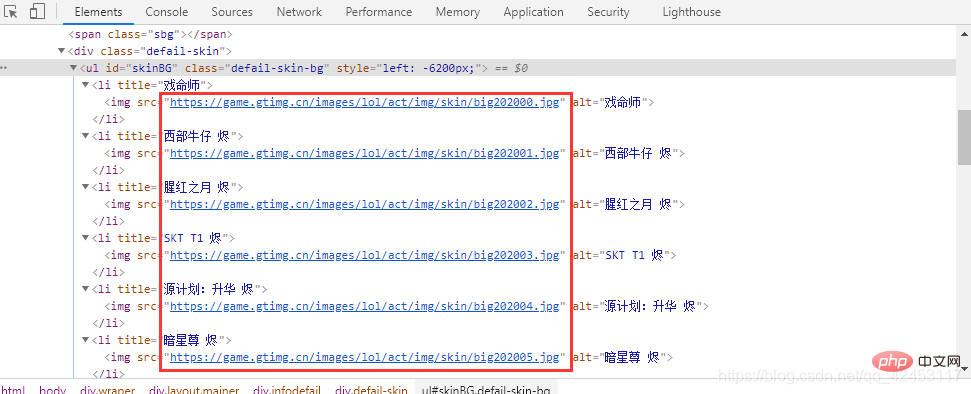
https://game.gtimg.cn/images/lol/act/img/skin/big202000.jpg https://game.gtimg.cn/images/lol/act/img/skin/big202001.jpg https://game.gtimg.cn/images/lol/act/img/skin/big202002.jpg https://game.gtimg.cn/images/lol/act/img/skin/big202003.jpg https://game.gtimg.cn/images/lol/act/img/skin/big202004.jpg https://game.gtimg.cn/images/lol/act/img/skin/big202005.jpg
从这些url中能发现什么规律呢?其实规律非常明显,url前面的内容都是一样的,唯一不同的是big1000.jpg,而每个皮肤图片就是在该url的基础上加1。
那么问题来了,它是如何区分这张图片所属的英雄的呢?我们观察浏览器上方的地址: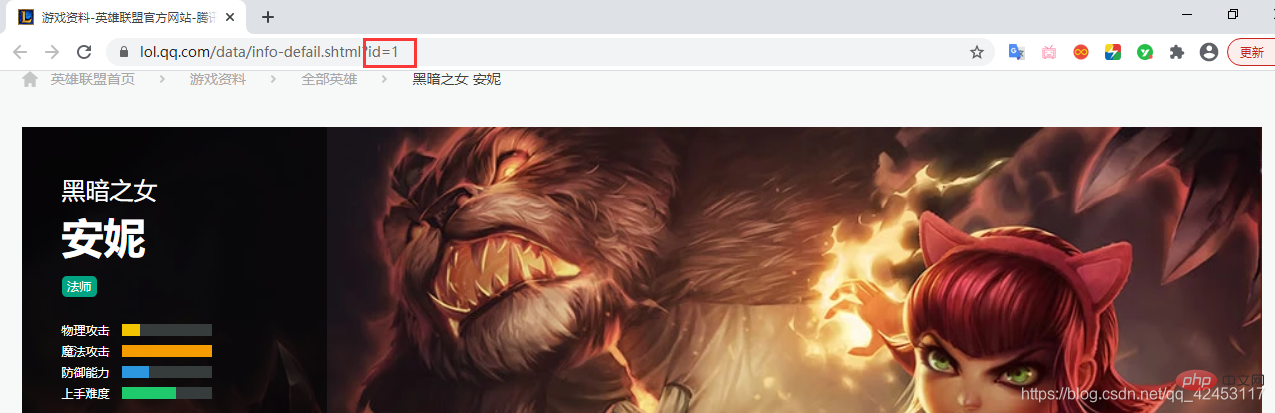
地址上有一个属性值id为1,那么我们可以猜测一下,皮肤图片url中的big1000.jpg是不是由英雄id和皮肤id共同组成的呢?
要想证明我们的猜想,就必须再去看看其它英雄皮肤是不是也满足这一条件: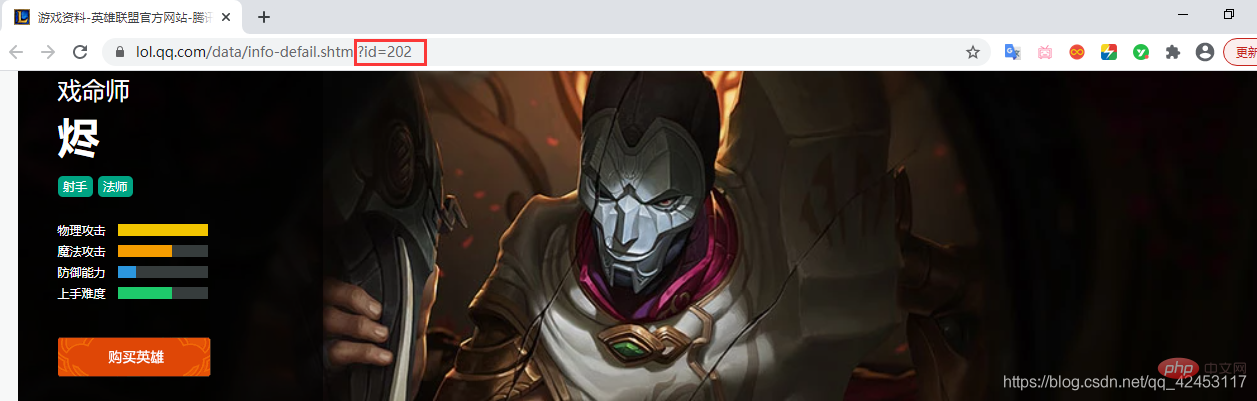
打开烬的详情页面,其id为202,由此,烬的皮肤图片url最后部分应为:big ' + 202 + ' 皮肤编号.jpg실행 결과:
 🎜🎜json 모듈🎜🎜json 모듈은 json 문자열과 Python 데이터 유형을 서로 변환할 수 있습니다. , 예를 들어 json을 Python 객체로 변환하는 경우: 🎜
🎜🎜json 모듈🎜🎜json 모듈은 json 문자열과 Python 데이터 유형을 서로 변환할 수 있습니다. , 예를 들어 json을 Python 객체로 변환하는 경우: 🎜import jsonimport requests# 定义一个列表,用于存放英雄名称和对应的idhero_id = []url = 'https://game.gtimg.cn/images/lol/act/img/js/heroList/hero_list.js?v=20'response = requests.get(url)text = response.text# 将json字符串转为列表hero_list = json.loads(text)['hero']# 遍历列表for hero in hero_list:
# 定义一个字典
hero_dict = {'name': hero['name'], 'id': hero['heroId']}
# 将列表加入字典
hero_id.append(hero_dict)print(hero_id)loads 함수를 사용하여 json 문자열을 사전 유형으로 변환하면 실행 결과는 다음과 같습니다. 🎜import jsonimport requests url = 'https://game.gtimg.cn/images/lol/act/img/js/hero/31.js'response = requests.get(url)text = response.text# 将json字符串转为列表skins_list = json.loads(text)['skins']skin_num = len(skins_list)
import requestsimport jsonimport osimport tracebackfrom tqdm import tqdmdef spider_lol():
# 定义一个列表,用于存放英雄名称和对应的id
hero_id = []
skins = []
url = 'https://game.gtimg.cn/images/lol/act/img/js/heroList/hero_list.js?v=20'
response = requests.get(url)
text = response.text # 将json字符串转为列表
hero_list = json.loads(text)['hero']
# 遍历列表
for hero in hero_list:
# 定义一个字典
hero_dict = {'name': hero['name'], 'id': hero['heroId']}
# 将列表加入字典
hero_id.append(hero_dict)
# 得到每个英雄对应的id后,即可获得英雄对应皮肤的url
# 英雄id + 001
# 遍历列表
for hero in hero_id:
# 得到英雄名字
hero_name = hero['name']
# 得到英雄id
hero_id = hero['id']
# 创建文件夹
os.mkdir('C:/Users/Administrator/Desktop/lol/' + hero_name)
# 进入文件夹
os.chdir('C:/Users/Administrator/Desktop/lol/' + hero_name)
# 得到id后即可拼接存储该英雄信息的url
hero_info_url = 'https://game.gtimg.cn/images/lol/act/img/js/hero/' + hero_id + '.js'
# 通过访问该url获取英雄的皮肤数量
text = requests.get(hero_info_url).text
info_list = json.loads(text)
# 得到皮肤名称
skin_info_list = info_list['skins']
skins.clear()
for skin in skin_info_list:
skins.append(skin['name'])
# 获得皮肤数量
skins_num = len(skin_info_list)
# 获得皮肤数量后,即可拼接皮肤的url,如:安妮的皮肤url为:
# https://game.gtimg.cn/images/lol/act/img/skin/big1000.jpg ~ https://game.gtimg.cn/images/lol/act/img/skin/big1012
s = ''
for i in tqdm(range(skins_num), '正在爬取' + hero_name + '的皮肤'):
if len(str(i)) == 1:
s = '00' + str(i)
elif len(str(i)) == 2:
s = '0' + str(i)
elif len(str(i)) == 3:
pass
try:
# 拼接皮肤url
skin_url = 'https://game.gtimg.cn/images/lol/act/img/skin/big' + hero_id + '' + s + '.jpg'
# 访问当前皮肤url
im = requests.get(skin_url)
except:
# 某些英雄的炫彩皮肤没有url,所以直接终止当前url的爬取,进入下一个
continue
# 保存图片
if im.status_code == 200:
# 判断图片名称中是否带有'/'、'\'
if '/' in skins[i] or '\' in skins[i]:
skins[i] = skins[i].replace('/', '')
skins[i] = skins[i].replace('\', '')
with open(skins[i] + '.jpg', 'wb') as f:
f.write(im.content)def main():
try:
spider_lol()
except Exception as e:
# 打印异常信息
print(e)if __name__ == '__main__':
main()dumps 함수는 Python 데이터를 json 문자열로 변환할 수 있습니다. 실행 결과는 다음과 같습니다. 🎜rrreee🎜Preparation🎜🎜앞서 소개한 두 모듈은 이 두 모듈을 통해 우리는 이 프로그램을 완료할 수 있습니다. 🎜 공식적으로 코드 작성을 시작하기 전에 먼저 데이터 소스를 분석해야 합니다. 공식 웹사이트로 이동하세요: https://lol.qq.com/main.shtml, 아래로 스크롤하여 영웅 목록을 찾으세요: 🎜🎜 영웅을 클릭하면 볼 수 있습니다: 🎜🎜 피부 이미지를 마우스 오른쪽 버튼으로 클릭하여 검사하세요. 🎜 이런 식으로 우리는 이 스킨의 URL을 선택하고 두 번째 스킨을 선택하겠습니다. 해당 URL을 살펴보세요: 🎜🎜 애니 스킨의 모든 URL을 살펴보겠습니다. 🎜rrreee🎜이 URL에서 어떤 패턴을 찾을 수 있나요? 실제로 패턴은 매우 명확합니다. URL 앞의 내용은 동일합니다. 유일한 차이점은 big1000.jpg이며 각 스킨 사진은 URL에 1을 추가합니다. 🎜🎜그렇다면 이 사진이 속한 영웅을 어떻게 구별할 수 있을까요? 브라우저 상단의 주소를 살펴보겠습니다. 🎜🎜 주소에 속성값 id가 있어서 스킨 사진 URL의 big1000.jpg가 히어로 아이디와 스킨 아이디로 구성되어 있는지 짐작할 수 있죠? 🎜🎜우리의 추측을 증명하려면 다른 영웅 스킨도 이 조건을 충족하는지 확인해야 합니다. 🎜🎜 ID가 202인 진의 상세정보 페이지를 엽니다. 따라서 진의 스킨 사진 URL 마지막 부분은 big ' + 202 + '스킨번호.jpg 여야 합니다. code>이므로 해당 URL은 다음과 같아야 합니다. 🎜<div class="code" style="position:relative; padding:0px; margin:0px;"><div class="code" style="position:relative; padding:0px; margin:0px;"><pre class="brush:php;toolbar:false">https://game.gtimg.cn/images/lol/act/img/skin/big202000.jpg
https://game.gtimg.cn/images/lol/act/img/skin/big202001.jpg
https://game.gtimg.cn/images/lol/act/img/skin/big202002.jpg
https://game.gtimg.cn/images/lol/act/img/skin/big202003.jpg
https://game.gtimg.cn/images/lol/act/img/skin/big202004.jpg
https://game.gtimg.cn/images/lol/act/img/skin/big202005.jpg</pre><div class="contentsignin">로그인 후 복사</div></div><div class="contentsignin">로그인 후 복사</div></div>
<p>事实是不是如此呢?检查一下便知:<br><img src="/static/imghw/default1.png" data-src="https://img.php.cn/upload/article/000/000/052/8a088b8b7801a5dcd55ff7ec017d4383-8.png" class="lazy" alt="리그 오브 레전드의 모든 영웅 스킨을 크롤링하는 30줄의 Python 코드가 훌륭합니다."><br> 规律已经找到,但是我们还面临着诸多问题,比如每个英雄对应的id是多少呢?每个英雄又分别有多少个皮肤呢?</p>
<h1>查询英雄id</h1>
<p>先来解决第一个问题,每个英雄对应的id是多少?我们只能从官网首页中找找线索,在首页位置打开网络调试台:<br><img src="/static/imghw/default1.png" data-src="https://img.php.cn/upload/article/000/000/052/3a07d9090037be97ac4ae898f01fc048-9.png" class="lazy" alt="리그 오브 레전드의 모든 영웅 스킨을 크롤링하는 30줄의 Python 코드가 훌륭합니다."><br> 点击Network,并选中XHR,XHR是浏览器与服务器请求数据所依赖的对象,所以通过它便能筛选出一些服务器的响应数据。<br> 此时我们刷新页面,在筛选出的内容发现了这么一个东西:<br><img src="/static/imghw/default1.png" data-src="https://img.php.cn/upload/article/000/000/052/3a07d9090037be97ac4ae898f01fc048-10.png" class="lazy" alt="리그 오브 레전드의 모든 영웅 스킨을 크롤링하는 30줄의 Python 코드가 훌륭합니다."><br><code>hero_list,英雄列表?这里面会不会存储着所有英雄的信息呢?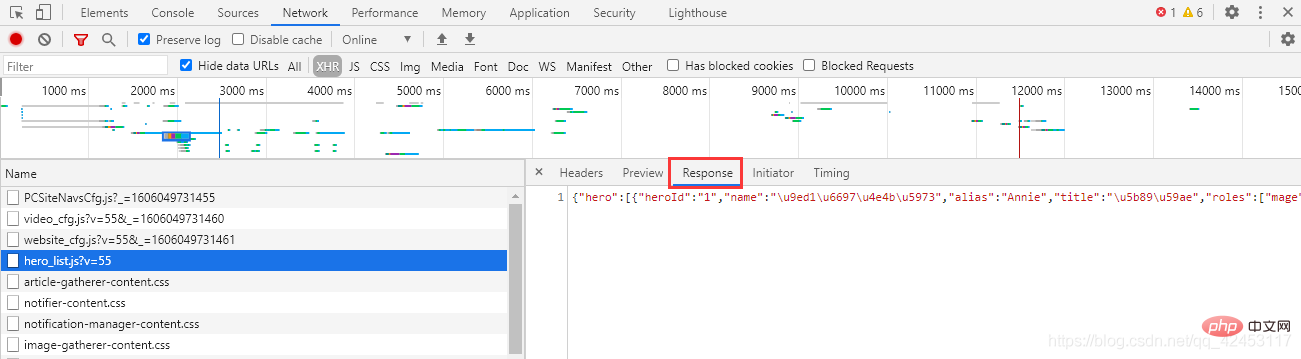
忘了告诉你们了,这个文件的url在这里可以找到: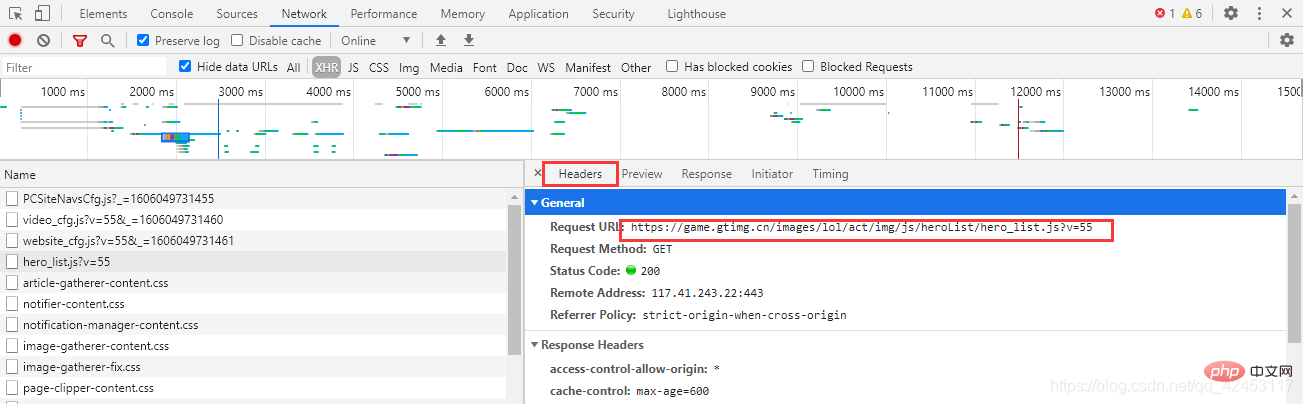
接下来开始写代码:
import jsonimport requests# 定义一个列表,用于存放英雄名称和对应的idhero_id = []url = 'https://game.gtimg.cn/images/lol/act/img/js/heroList/hero_list.js?v=20'response = requests.get(url)text = response.text# 将json字符串转为列表hero_list = json.loads(text)['hero']# 遍历列表for hero in hero_list:
# 定义一个字典
hero_dict = {'name': hero['name'], 'id': hero['heroId']}
# 将列表加入字典
hero_id.append(hero_dict)print(hero_id)首先通过requests模块请求该url,就能够获取到一个json字符串,然后使用json模块将该字符串转为Python中的列表,最后循环取出每个英雄的name和heroid属性,放入新定义的列表中,这个程序就完成了英雄id的提取。
接下来解决第二个问题,如何知晓某个英雄究竟有多少个皮肤,按照刚才的思路,我们可以猜测一下,对于皮肤也应该会有一个文件存储着皮肤信息,在某个英雄的皮肤页面打开网络调试台,并选中XHR,刷新页面,找找线索: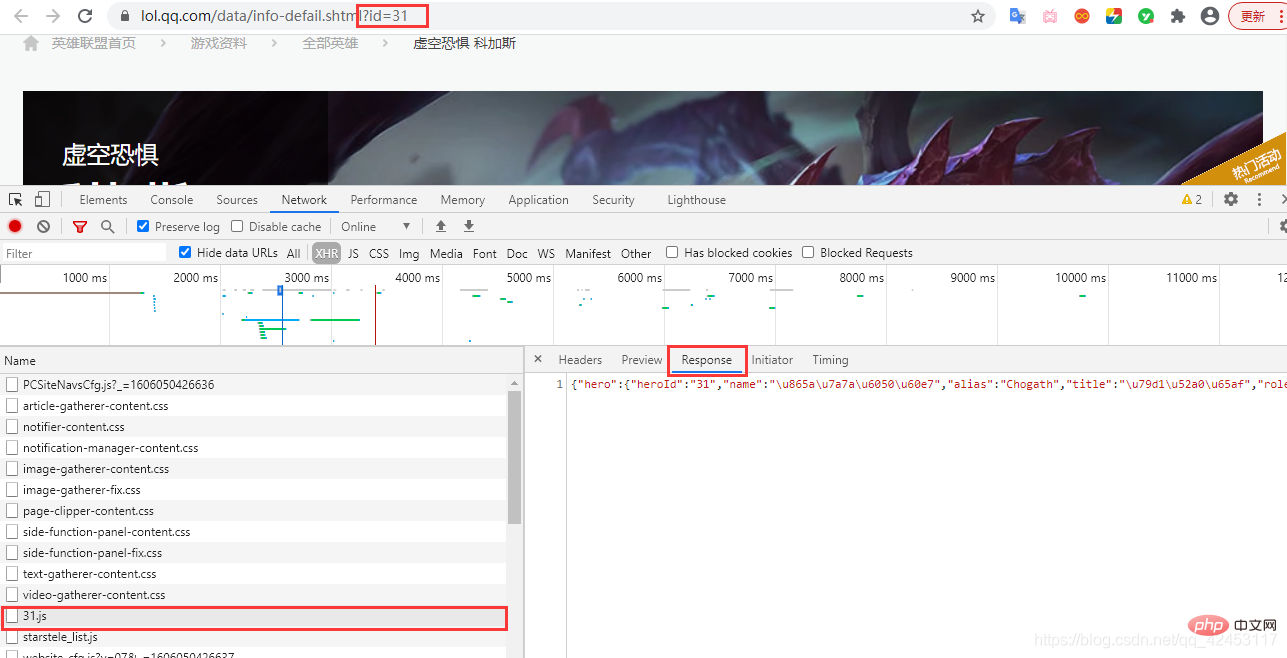
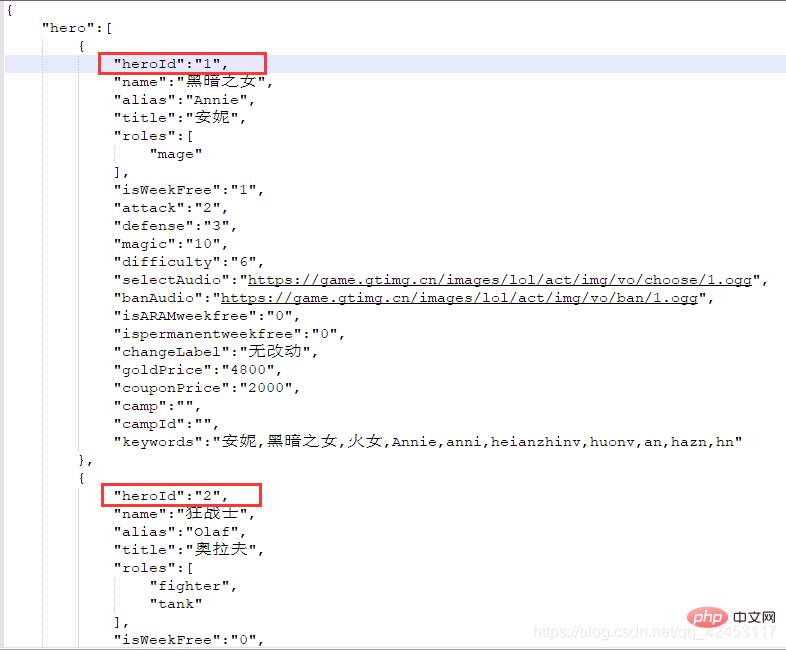
找来找去确实找不到有哪个文件是跟皮肤有关系的,但是这里发现了一个31.js文件,而当前英雄的id也为31,这真的是巧合吗?我们将右边的json字符串解析一下: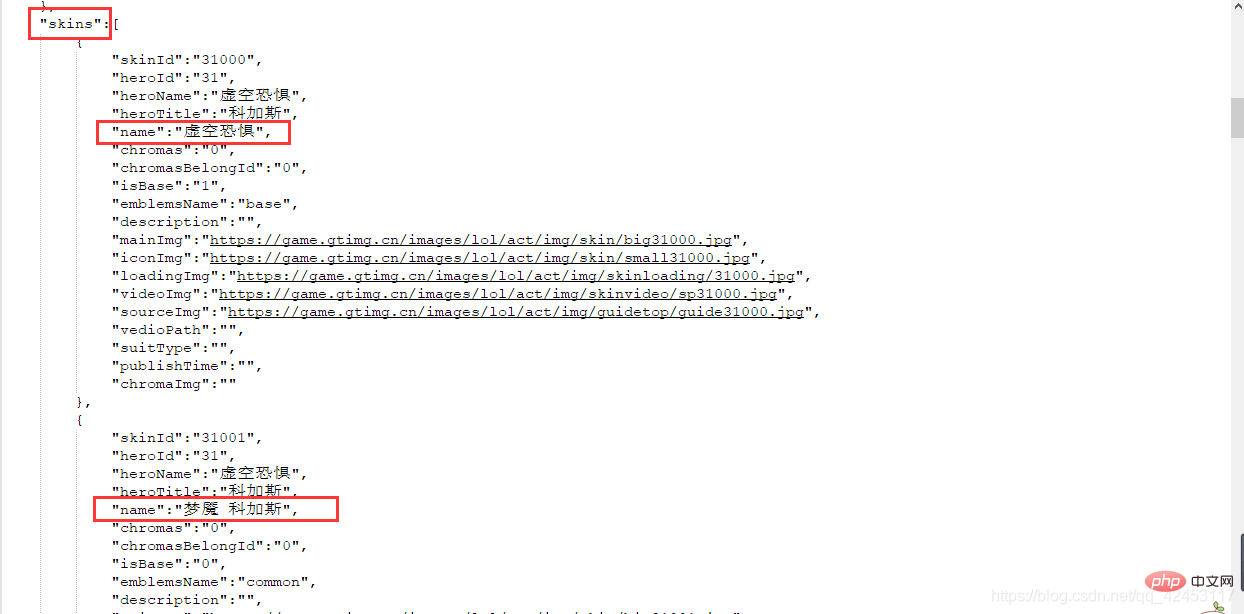
该json数据中有一个skins属性,该属性值即为当前英雄的皮肤信息,既然找到了数据,那接下来就好办了,开始写代码:
import jsonimport requests url = 'https://game.gtimg.cn/images/lol/act/img/js/hero/31.js'response = requests.get(url)text = response.text# 将json字符串转为列表skins_list = json.loads(text)['skins']skin_num = len(skins_list)
准备工作已经完成了我们所有的前置任务,接下来就是在此基础上编写代码了:
import requestsimport jsonimport osimport tracebackfrom tqdm import tqdmdef spider_lol():
# 定义一个列表,用于存放英雄名称和对应的id
hero_id = []
skins = []
url = 'https://game.gtimg.cn/images/lol/act/img/js/heroList/hero_list.js?v=20'
response = requests.get(url)
text = response.text # 将json字符串转为列表
hero_list = json.loads(text)['hero']
# 遍历列表
for hero in hero_list:
# 定义一个字典
hero_dict = {'name': hero['name'], 'id': hero['heroId']}
# 将列表加入字典
hero_id.append(hero_dict)
# 得到每个英雄对应的id后,即可获得英雄对应皮肤的url
# 英雄id + 001
# 遍历列表
for hero in hero_id:
# 得到英雄名字
hero_name = hero['name']
# 得到英雄id
hero_id = hero['id']
# 创建文件夹
os.mkdir('C:/Users/Administrator/Desktop/lol/' + hero_name)
# 进入文件夹
os.chdir('C:/Users/Administrator/Desktop/lol/' + hero_name)
# 得到id后即可拼接存储该英雄信息的url
hero_info_url = 'https://game.gtimg.cn/images/lol/act/img/js/hero/' + hero_id + '.js'
# 通过访问该url获取英雄的皮肤数量
text = requests.get(hero_info_url).text
info_list = json.loads(text)
# 得到皮肤名称
skin_info_list = info_list['skins']
skins.clear()
for skin in skin_info_list:
skins.append(skin['name'])
# 获得皮肤数量
skins_num = len(skin_info_list)
# 获得皮肤数量后,即可拼接皮肤的url,如:安妮的皮肤url为:
# https://game.gtimg.cn/images/lol/act/img/skin/big1000.jpg ~ https://game.gtimg.cn/images/lol/act/img/skin/big1012
s = ''
for i in tqdm(range(skins_num), '正在爬取' + hero_name + '的皮肤'):
if len(str(i)) == 1:
s = '00' + str(i)
elif len(str(i)) == 2:
s = '0' + str(i)
elif len(str(i)) == 3:
pass
try:
# 拼接皮肤url
skin_url = 'https://game.gtimg.cn/images/lol/act/img/skin/big' + hero_id + '' + s + '.jpg'
# 访问当前皮肤url
im = requests.get(skin_url)
except:
# 某些英雄的炫彩皮肤没有url,所以直接终止当前url的爬取,进入下一个
continue
# 保存图片
if im.status_code == 200:
# 判断图片名称中是否带有'/'、'\'
if '/' in skins[i] or '\\' in skins[i]:
skins[i] = skins[i].replace('/', '')
skins[i] = skins[i].replace('\\', '')
with open(skins[i] + '.jpg', 'wb') as f:
f.write(im.content)def main():
try:
spider_lol()
except Exception as e:
# 打印异常信息
print(e)if __name__ == '__main__':
main()运行效果: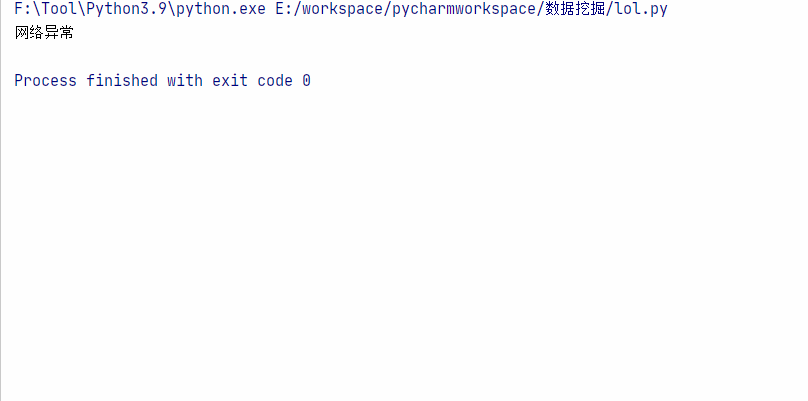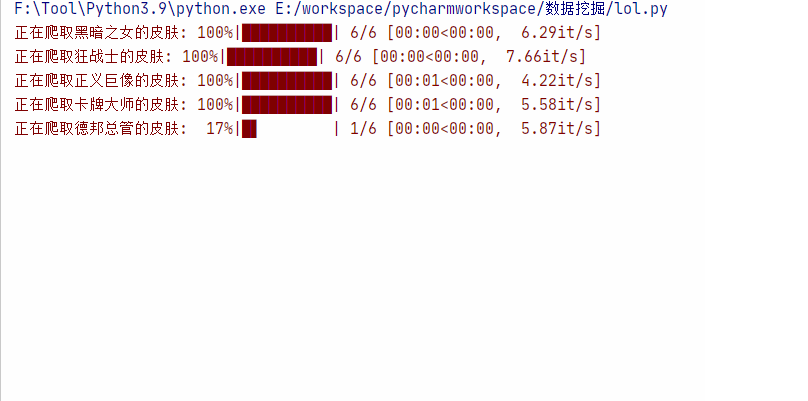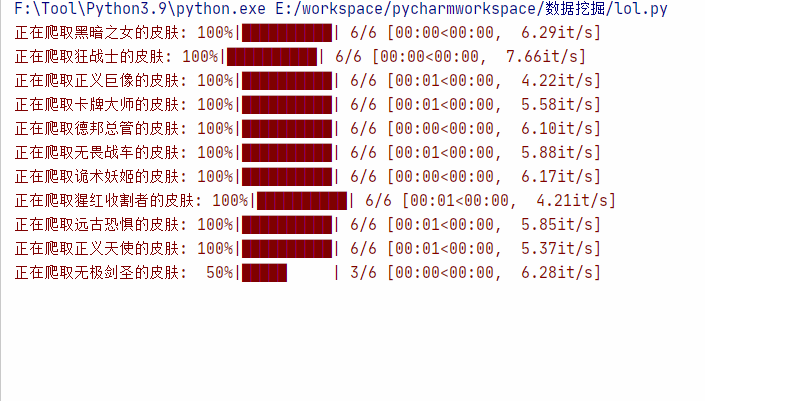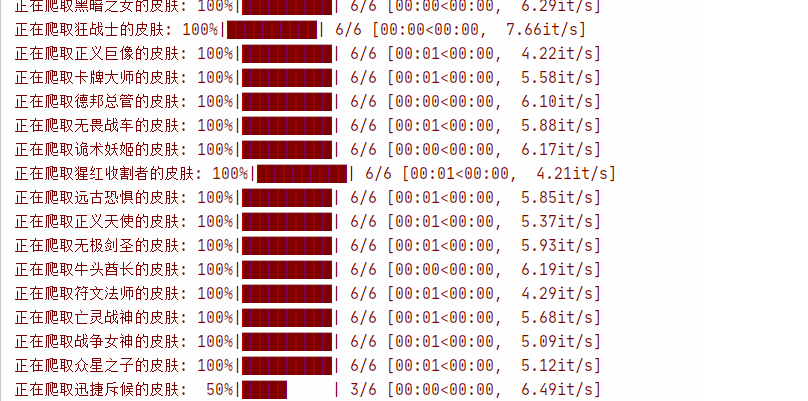
运行之前记得在桌面上创建一个lol文件夹,如果想改动的话也可以修改程序: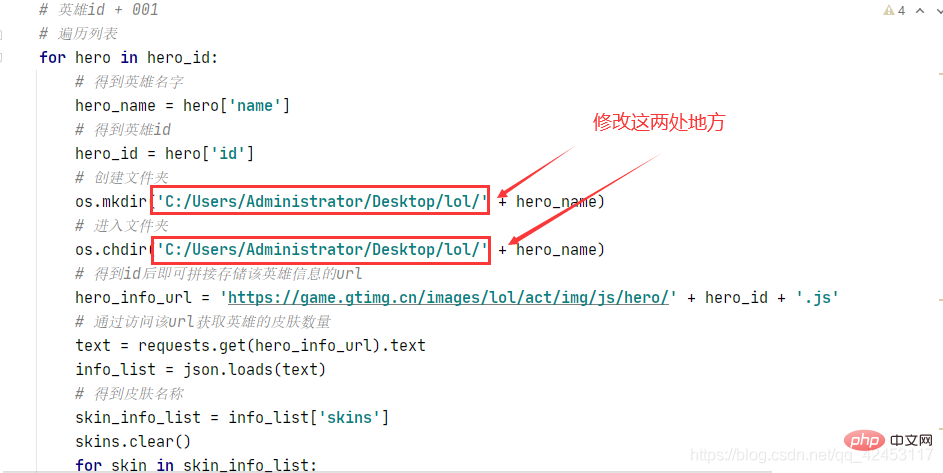
程序中还考虑到了一些其它情况,比如在爬取这个皮肤的时候会出现问题:
因为图片路径是以皮肤名字命名的,然而这个皮肤的名字中竟然有个/,它是会影响到我们的图片保存操作的,所以在保存前将斜杠替换成空字符即可。
还有一个问题就是即使是第一个皮肤,其编号也应该为000而不是0,所以还需要对其进行一个转化,让其始终是三位数。
本篇文章同样继承了上篇文章精简的特点,抛去注释的话总共30行代码左右,程序当然还有一些其它地方可以进一步优化,这就交给大家自由发挥了。
위 내용은 리그 오브 레전드의 모든 영웅 스킨을 크롤링하는 30줄의 Python 코드가 훌륭합니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!



















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



