


무료 학습 권장 사항: mysql 데이터베이스 (비디오)
Background
Alibaba Cloud RDS FOR MySQL(MySQL 버전 5.7) 비즈니스 테이블은 매달 추가됩니다. 데이터 양이 수천만 개를 초과합니다. 데이터 양이 계속 증가함에 따라 우리 비즈니스는 대규모 테이블에 대한 쿼리가 가장 많은 시간 동안 주요 비즈니스 테이블에 대한 느린 쿼리에 수십 초가 소요되어 비즈니스에 심각한 영향을 미칩니다
솔루션 개요
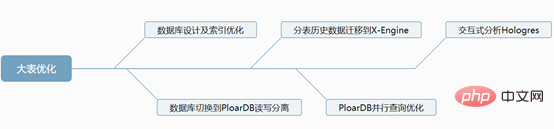
1. 데이터베이스 설계 및 인덱스 최적화
MySQL 데이터베이스 자체는 유연성이 높아 성능이 부족하고 개발자의 테이블 설계 능력 및 인덱스 최적화 능력에 크게 의존합니다. 최적화 제안
이름에서 알 수 있듯이 가장 왼쪽 우선순위를 의미합니다. 결합 인덱스를 생성할 때 비즈니스 요구에 따라 where 절에서 가장 자주 사용되는 열이 가장 왼쪽에 배치됩니다. 복합 인덱스에서 매우 중요한 문제는 열의 순서를 어떻게 정렬하느냐 하는 것입니다. 예를 들어 where 뒤에 c1과 c2라는 두 필드를 사용하면 인덱스의 순서는 (c1, c2) 또는 (c2, c1)이 됩니다. 올바른 접근 방식은 반복하는 것입니다. 예를 들어 열에 있는 값의 95%가 반복되지 않으면 이 열은 일반적으로 복합 지수 인덱스( a, b, c)
PolarDB는 Alibaba Cloud가 개발한 차세대 관계형 클라우드 데이터베이스로, MySQL과 100% 호환됩니다. 단일 데이터베이스는 최대 100TB에 달합니다. 최대 16개 노드까지 확장 가능하며 기업의 다양한 데이터베이스 애플리케이션 시나리오에 적합합니다. PolarDB는 스토리지와 컴퓨팅을 분리하는 아키텍처를 채택하여 모든 컴퓨팅 노드가 데이터 사본을 공유하고 분 단위 구성 업그레이드 및 다운그레이드, 2단계 오류 복구, 글로벌 데이터 일관성, 무료 데이터 백업 및 재해 복구 서비스를 제공합니다.
클러스터 아키텍처, 컴퓨팅과 스토리지의 분리
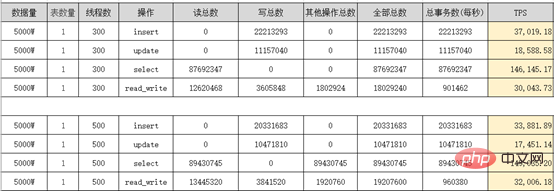
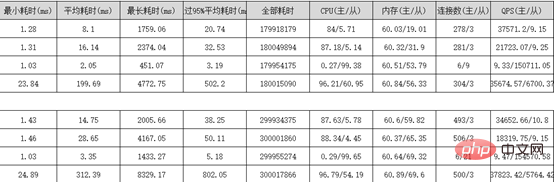
PolarDB는 클러스터에 Writer 노드(마스터 노드)와 여러 개의 Reader 노드(읽기 전용 노드)가 있는 다중 노드 클러스터 아키텍처를 채택합니다. 시스템(PolarFileSystem) 공유 기본 스토리지(PolarStore)Sysbench 성능 스트레스 테스트 보고서: 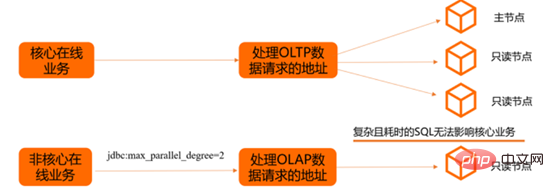
PloarDB 4코어 16G 2개 유닛
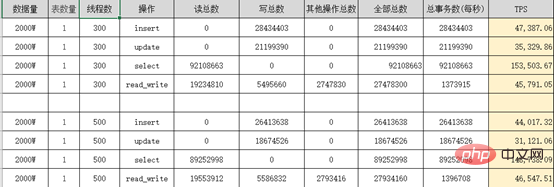
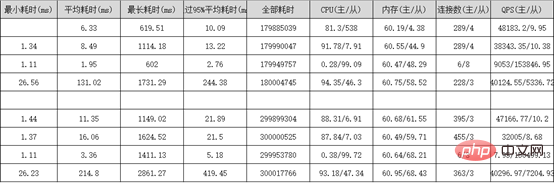 PloarDB 8코어 32G 2유닛
PloarDB 8코어 32G 2유닛
 3. 하위 테이블의 기록 데이터를 MySQL8.0 X-Engine 스토리지 엔진으로 마이그레이션합니다
3. 하위 테이블의 기록 데이터를 MySQL8.0 X-Engine 스토리지 엔진으로 마이그레이션합니다
분할된 비즈니스 테이블은 3개월분의 데이터를 보관하며(회사 요구에 따라), 과거 데이터는 월 단위로 과거 데이터베이스 X-Engine 스토리지 엔진 테이블로 분할됩니다. 장점은?
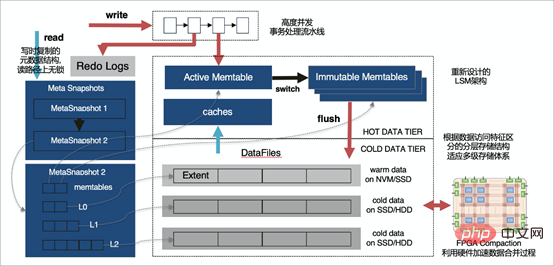
X-Engine은 Alibaba Cloud 데이터베이스 제품 부문에서 독자적으로 개발한 온라인 트랜잭션 처리 OLTP(On-Line Transaction Process) 데이터베이스 스토리지 엔진입니다.
X-Engine 스토리지 엔진은 MySQL과 원활하게 호환될 뿐만 아니라(MySQL 플러그인 가능 스토리지 엔진 기능 덕분에) X-Engine은 계층형 스토리지 아키텍처도 사용합니다. 대규모의 대용량 데이터를 저장하고, 높은 동시 트랜잭션 처리 능력을 제공하며, 저장 비용을 줄이는 것이 목표이기 때문에 대부분의 대용량 데이터 볼륨 시나리오에서는 데이터에 액세스할 수 있는 기회가 고르지 않으며 실제로 자주 액세스되는 핫 데이터가 차지합니다. 아주 드물게, X-Engine은 데이터 액세스 빈도에 따라 데이터를 여러 레벨로 나누며, 각 데이터 레벨의 액세스 특성에 따라 해당 저장 구조를 설계하고 적절한 저장 장치에 씁니다
4. Alibaba Cloud PloarDB MySQL8.0 버전의 병렬 쿼리
테이블을 분할한 후에도 데이터 볼륨이 여전히 매우 커서 느린 쿼리 문제가 완전히 해결되지는 않지만 크기만 줄어듭니다. 느린 쿼리의 이 부분에서는 PolarDB의 병렬 쿼리 최적화를 사용해야 합니다.
PolarDB MySQL 8.0은 쿼리 데이터의 양이 특정 임계값에 도달하면 병렬 쿼리 프레임워크를 시작합니다. 자동으로 시작되어 쿼리에 시간이 많이 걸립니다.
스토리지 계층에서 데이터는 여러 스레드로 분할되어 병렬로 계산되고 결과 파이프라인은 기본 스레드로 요약됩니다. 쿼리 효율성을 높이기 위해 간단한 병합을 수행하고 사용자에게 반환합니다.
병렬 쿼리는 멀티 코어 CPU의 병렬 처리 기능을 활용합니다. 8코어 32GB 구성을 예로 들면 다음과 같습니다.
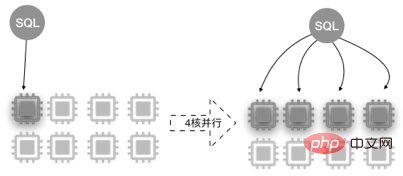
병렬 쿼리는 대규모 테이블 쿼리, 다중 테이블 조인 쿼리, 계산 부하가 큰 쿼리 등 대부분의 SELECT 문에 적합합니다. 매우 짧은 쿼리의 경우 효과가 눈에 띄지 않습니다.
병렬 쿼리 사용, 힌트 구문을 사용하여 단일 문을 제어할 수 있습니다. 예를 들어 시스템이 기본적으로 병렬 쿼리를 해제하지만 빈도가 높은 느린 SQL 쿼리의 속도를 높여야 하는 경우 힌트를 사용하여 속도를 높일 수 있습니다. 특정 SQL.
SELECT /+PARALLEL(x)/ … FROM …; – x >0
SELECT /*+ SET_VAR(max_parallel_degree=n) */ * FROM … // n > 16코어, 32G로 구성하면 단일 테이블의 데이터 볼륨이 3천만을 초과합니다
병렬 쿼리 추가 전 4326ms, 추가 후 525ms로 성능이 8.24배 향상되었습니다
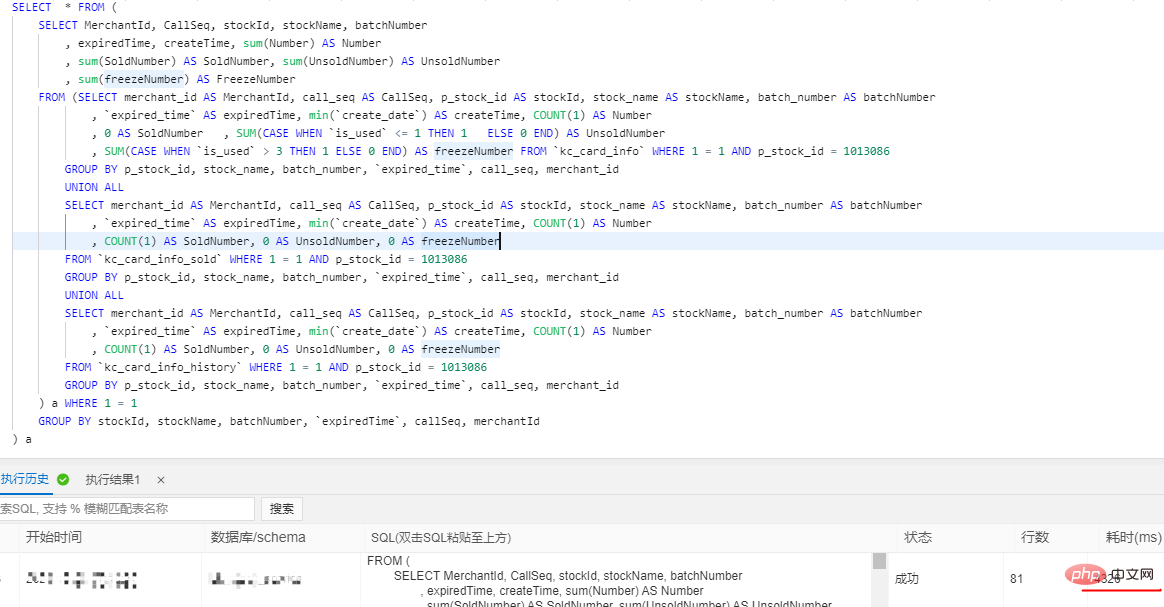
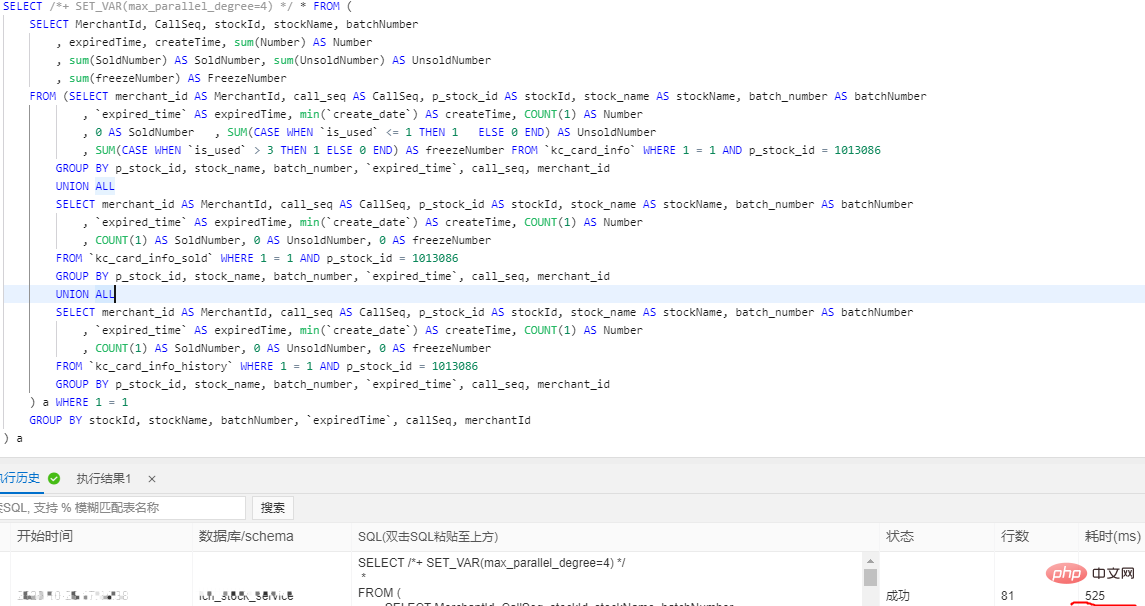
대규모 테이블에서 느린 쿼리의 효율성을 높이기 위해 병렬 쿼리 최적화를 사용하지만 여전히 실시간 보고서 및 실시간 대형 화면에 대한 일부 특정 요구 사항을 달성할 수 없으며 의존할 수밖에 없습니다. 빅데이터를 활용해 처리합니다.
여기서는 Alibaba Cloud의 대화형 분석 Hologre를 추천합니다( https://help.aliyun.com/product/113622.html)
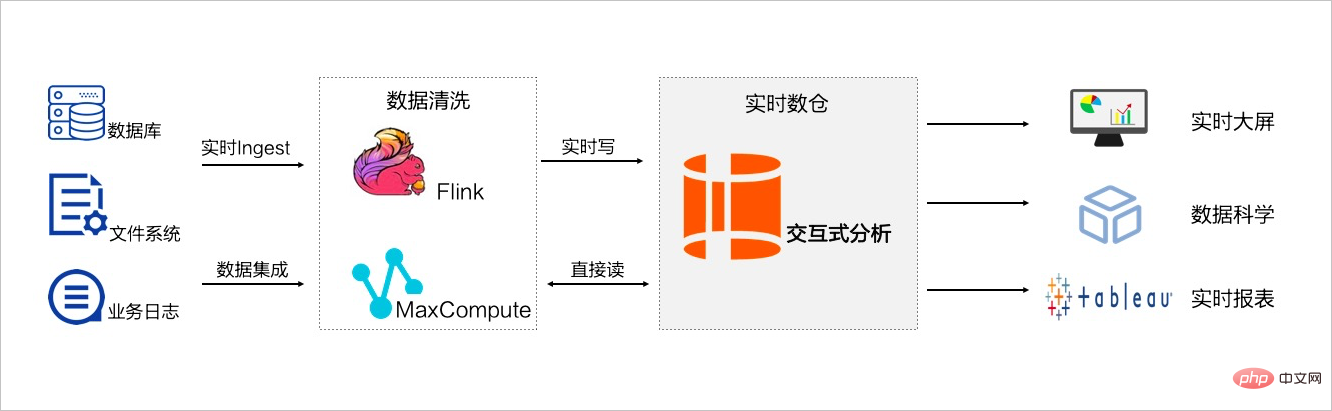
수천만 개의 대형 테이블 최적화는 다음을 기반으로 합니다. 비즈니스 시나리오는 비용을 희생하여 최적화됩니다. 처음부터 데이터베이스를 수평으로 분할하고 확장할 필요는 없습니다. 이는 운영 및 유지 관리에 큰 어려움을 가져올 것이며, 많은 경우 효과가 좋지 않을 수 있습니다. 데이터베이스 설계, 인덱스 최적화, 테이블 파티셔닝 전략이 완료되면 비즈니스 요구 사항에 따라 이를 구현할 수 있는 적절한 기술을 선택해야 합니다.
더 많은 관련 무료 학습 권장 사항: mysql 튜토리얼(동영상)
위 내용은 MySQL 대형 테이블 최적화 솔루션 소개의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



