

ThinkPHP 데이터베이스 작업 저장 프로시저, 데이터 세트, 분산 데이터베이스

다음 튜토리얼 칼럼인 thinkphp에서는 ThinkPHP 데이터베이스 작업의 저장 프로시저, 데이터 세트, 분산 데이터베이스에 대해 소개하겠습니다. 도움이 필요한 친구들에게 도움이 되길 바랍니다!

저장 프로시저
5.0은 저장 프로시저 sp_query를 정의하는 경우 다음과 같은 방법으로 호출할 수 있습니다.
$result = Db::query('call sp_query(8)');2차원 배열을 반환합니다. 예를 들어 매개변수 바인딩을 사용할 수 있습니다.
$result = Db::query('call sp_query(?)',[8]);
// 或者命名绑定$result = Db::query('call sp_query(:id)',['id'=>8]);dataset
데이터베이스의 쿼리 결과도 데이터 세트입니다. 기본 구성에서 데이터 세트 유형은 2차원 배열입니다. 이를 데이터 세트 클래스로 구성할 수 있으며 데이터 세트에 대해 더 많은 객체 기반 작업을 지원할 수 있습니다. 데이터 세트 클래스 함수를 사용해야 합니다. 다음과 같이 데이터베이스의 resultset_type 매개변수를 구성할 수 있습니다. 데이터셋 객체는 thinkCollection으로 배열과 동일한 사용법을 제공하며, 추가적으로 몇 가지 메소드가 캡슐화되어 있습니다. 배열을 사용하여 데이터 세트 객체를 직접 조작할 수 있습니다. 예:
return [ // 数据库类型 'type' => 'mysql', // 数据库连接DSN配置 'dsn' => '', // 服务器地址 'hostname' => '127.0.0.1', // 数据库名 'database' => 'thinkphp', // 数据库用户名 'username' => 'root', // 数据库密码 'password' => '', // 数据库连接端口 'hostport' => '', // 数据库连接参数 'params' => [], // 数据库编码默认采用utf8 'charset' => 'utf8', // 数据库表前缀 'prefix' => 'think_', // 数据集返回类型 'resultset_type' => 'collection',];
// 获取数据集
$users = Db::name('user')->select();
// 直接操作第一个元素
$item = $users[0];
// 获取数据集记录数
$count = count($users);
// 遍历数据集
foreach($users as $user){ echo $user['name']; echo $user['id'];
}
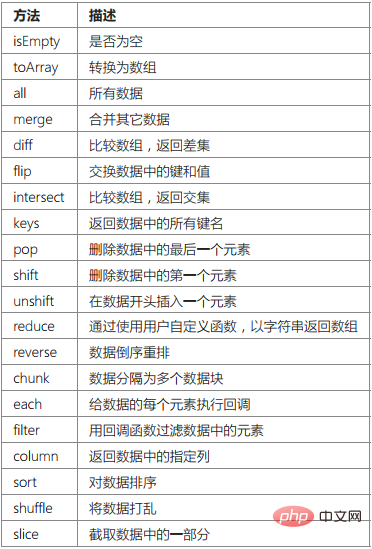 개별 데이터만 쿼리하여 데이터 세트 객체를 반환해야 하는 경우
개별 데이터만 쿼리하여 데이터 세트 객체를 반환해야 하는 경우
$users = Db::name('user')->select();if($users->isEmpty()){ echo '数据集为空';
}분산 데이터베이스ThinkPHP에는 마스터-슬레이브 데이터베이스의 읽기-쓰기 분리를 포함하여 분산 데이터베이스에 대한 배포 지원이 내장되어 있지만 분산 데이터베이스는 데이터베이스 유형이 동일해야 합니다.
분산 데이터베이스 지원을 사용하려면 Database.deploy를 1로 구성하세요. 분산 데이터베이스를 사용하는 경우 데이터베이스 구성 정보를 정의하는 방법은 다음과 같습니다.
Db::name('user') ->fetchClass('\think\Collection') ->select();연결된 데이터베이스 수는 호스트 이름 정의 수에 따라 달라지므로 동일한 IP 2개라도 반복적으로 정의해야 하지만 다른 매개변수가 있는 경우 동일합니다. 정의를 반복할 필요가 없습니다. 예를 들어
//分布式数据库配置定义 return [ // 启用分布式数据库 'deploy' => 1, // 数据库类型 'type' => 'mysql', // 服务器地址 'hostname' => '192.168.1.1,192.168.1.2', // 数据库名 'database' => 'demo', // 数据库用户名 'username' => 'root', // 数据库密码 'password' => '', // 数据库连接端口 'hostport' => '',]
와
'hostport'=>'3306,3306'
는 동일합니다.
'hostport'=>'3306'
와
'username'=>'user1', 'password'=>'pwd1',
는 동일합니다.
분산 데이터베이스의 읽기와 쓰기가 분리되어 있는지도 설정할 수 있습니다. 기본적으로 읽기와 쓰기가 분리되지 않습니다. 즉, 마스터-슬레이브 데이터베이스의 경우 각 서버에서 읽기 및 쓰기 작업을 수행할 수 있어야 합니다. 읽기 및 쓰기 분리를 설정하려면 다음 설정으로 충분합니다.
'username'=>'user1,user1', 'password'=>'pwd1,pwd1',
읽기-쓰기 분리의 경우 기본 첫 번째 데이터베이스 구성은 데이터 쓰기를 담당하는 메인 서버의 구성 정보입니다. master_num 매개변수가 설정되면 여러 주 서버에 쓰기가 지원될 수 있습니다. 다른 사람은 데이터베이스의 구성 정보에서 데이터를 읽는 역할을 담당하며 그 수에는 제한이 없습니다. 슬레이브 서버에 연결하고 읽기 작업을 수행할 때마다 시스템은 슬레이브 서버에서 무작위로 선택합니다.
slave_no를 설정하여 읽기 작업을 위한 서버를 지정할 수도 있습니다.
슬레이브 데이터베이스 연결에 오류가 있으면 자동으로 메인 데이터베이스 연결로 전환됩니다.
모델의 CURD 작업을 호출하면 시스템은 현재 실행되는 메서드가 읽기 작업인지 쓰기 작업인지 자동으로 결정합니다. 기본 SQL을 사용하는 경우 시스템의 기본 규칙에 주의해야 합니다.
쓰기 작업은 모델의 실행 메서드를 사용해야 하고, 읽기 작업은 모델의 쿼리 메서드를 사용해야 합니다. 그렇지 않으면 마스터-슬레이브 읽기 및 쓰기 혼란이 발생합니다.
참고: 마스터-슬레이브 데이터베이스의 데이터 동기화 작업은 프레임워크에서 구현되지 않으며 데이터베이스는 자체 동기화 또는 복제 메커니즘을 고려해야 합니다.위 내용은 ThinkPHP 데이터베이스 작업 저장 프로시저, 데이터 세트, 분산 데이터베이스의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

Video Face Swap
완전히 무료인 AI 얼굴 교환 도구를 사용하여 모든 비디오의 얼굴을 쉽게 바꾸세요!

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7675
7675
 15
1393
52
1207
24
91
11
73
19
15
1393
52
1207
24
91
11
73
19

 thinkphp 프로젝트를 실행하는 방법
Apr 09, 2024 pm 05:33 PM
thinkphp 프로젝트를 실행하는 방법
Apr 09, 2024 pm 05:33 PM
ThinkPHP 프로젝트를 실행하려면 다음이 필요합니다: Composer를 설치하고, 프로젝트 디렉터리를 입력하고 php bin/console을 실행하고, 시작 페이지를 보려면 http://localhost:8000을 방문하세요.
 thinkphp에는 여러 버전이 있습니다.
Apr 09, 2024 pm 06:09 PM
thinkphp에는 여러 버전이 있습니다.
Apr 09, 2024 pm 06:09 PM
ThinkPHP에는 다양한 PHP 버전용으로 설계된 여러 버전이 있습니다. 메이저 버전에는 3.2, 5.0, 5.1, 6.0이 포함되며, 마이너 버전은 버그를 수정하고 새로운 기능을 제공하는 데 사용됩니다. 최신 안정 버전은 ThinkPHP 6.0.16입니다. 버전을 선택할 때 PHP 버전, 기능 요구 사항 및 커뮤니티 지원을 고려하십시오. 최상의 성능과 지원을 위해서는 최신 안정 버전을 사용하는 것이 좋습니다.
 thinkphp를 실행하는 방법
Apr 09, 2024 pm 05:39 PM
thinkphp를 실행하는 방법
Apr 09, 2024 pm 05:39 PM
ThinkPHP Framework를 로컬에서 실행하는 단계: ThinkPHP Framework를 로컬 디렉터리에 다운로드하고 압축을 풉니다. ThinkPHP 루트 디렉터리를 가리키는 가상 호스트(선택 사항)를 만듭니다. 데이터베이스 연결 매개변수를 구성합니다. 웹 서버를 시작합니다. ThinkPHP 애플리케이션을 초기화합니다. ThinkPHP 애플리케이션 URL에 접속하여 실행하세요.
 개발 제안: ThinkPHP 프레임워크를 사용하여 비동기 작업을 구현하는 방법
Nov 22, 2023 pm 12:01 PM
개발 제안: ThinkPHP 프레임워크를 사용하여 비동기 작업을 구현하는 방법
Nov 22, 2023 pm 12:01 PM
"개발 제안: ThinkPHP 프레임워크를 사용하여 비동기 작업을 구현하는 방법" 인터넷 기술의 급속한 발전으로 인해 웹 응용 프로그램은 많은 수의 동시 요청과 복잡한 비즈니스 논리를 처리하기 위한 요구 사항이 점점 더 높아졌습니다. 시스템 성능과 사용자 경험을 향상시키기 위해 개발자는 이메일 보내기, 파일 업로드 처리, 보고서 생성 등과 같이 시간이 많이 걸리는 작업을 수행하기 위해 비동기 작업을 사용하는 것을 종종 고려합니다. PHP 분야에서 널리 사용되는 개발 프레임워크인 ThinkPHP 프레임워크는 비동기 작업을 구현하는 몇 가지 편리한 방법을 제공합니다.
 laravel과 thinkphp 중 어느 것이 더 낫나요?
Apr 09, 2024 pm 03:18 PM
laravel과 thinkphp 중 어느 것이 더 낫나요?
Apr 09, 2024 pm 03:18 PM
Laravel과 ThinkPHP 프레임워크의 성능 비교: ThinkPHP는 일반적으로 최적화 및 캐싱에 중점을 두고 Laravel보다 성능이 좋습니다. Laravel은 잘 작동하지만 복잡한 애플리케이션의 경우 ThinkPHP가 더 적합할 수 있습니다.
 thinkphp를 설치하는 방법
Apr 09, 2024 pm 05:42 PM
thinkphp를 설치하는 방법
Apr 09, 2024 pm 05:42 PM
ThinkPHP 설치 단계: PHP, Composer 및 MySQL 환경을 준비합니다. Composer를 사용하여 프로젝트를 만듭니다. ThinkPHP 프레임워크와 종속성을 설치합니다. 데이터베이스 연결을 구성합니다. 애플리케이션 코드를 생성합니다. 애플리케이션을 실행하고 http://localhost:8000을 방문하세요.
 thinkphp 성능은 어떤가요?
Apr 09, 2024 pm 05:24 PM
thinkphp 성능은 어떤가요?
Apr 09, 2024 pm 05:24 PM
ThinkPHP는 캐싱 메커니즘, 코드 최적화, 병렬 처리 및 데이터베이스 최적화와 같은 장점을 갖춘 고성능 PHP 프레임워크입니다. 공식 성능 테스트에 따르면 초당 10,000개 이상의 요청을 처리할 수 있으며 JD.com, Ctrip과 같은 대규모 웹 사이트 및 엔터프라이즈 시스템에서 실제 응용 프로그램으로 널리 사용됩니다.
 개발 제안: API 개발을 위해 ThinkPHP 프레임워크를 사용하는 방법
Nov 22, 2023 pm 05:18 PM
개발 제안: API 개발을 위해 ThinkPHP 프레임워크를 사용하는 방법
Nov 22, 2023 pm 05:18 PM
개발 제안: API 개발을 위해 ThinkPHP 프레임워크를 사용하는 방법 인터넷이 지속적으로 발전하면서 API(응용 프로그래밍 인터페이스)의 중요성이 점점 더 커지고 있습니다. API는 데이터 공유, 함수 호출 및 기타 작업을 실현할 수 있으며 개발자에게 비교적 간단하고 빠른 개발 방법을 제공합니다. 뛰어난 PHP 개발 프레임워크인 ThinkPHP 프레임워크는 효율적이고 확장 가능하며 사용하기 쉽습니다.
