

Python 정규식에 대한 참고 사항


기사 디렉토리
- 0, 서문
- 1, 정규식 패턴
- 2, 정규식 수정자 - 선택적 플래그
- 2.1, `re.IGNORECASE`(`re.I`)
- 2.2, `re.ASCII`(`re.A`)
- 2.3, `re.DOTALL`(`re.S`)
- 2.4, `re.MULTILINE`(`re.M` )
- 2.5 ,`re.verbose` (re. 3.1.1
- example 3.1.2 xexample 3.1.3
- 3.2. 여러 매치를 찾는 기능
-
- example 3.2.1
- 3.3. 분할.
- 예제 3.3.1
-
import re
로그인 후 복사- 0. 서문
이 노트는 초보자 튜토리얼과 Zhihu 튜토리얼을 기반으로 하며 내 자신의 학습 경험을 일부 포함합니다. - 1. 정규식 패턴
여기서는 좀 게을러서 직접 캡쳐한 사진입니다 초보자 튜토리얼 중.
2. 정규식 수정자 - 선택적 플래그
2.1. re.IGNORECASE(re.I)
 섹션 1은 상수이지만
섹션 1은 상수이지만 re.findall 함수는 이 섹션 전체에서 사용되는 함수이므로 먼저 간단히 언급해야 합니다.
re.findall(pattern, string, flag=0): 문자열의 아무 곳이나 검색하고 목록을 반환합니다. pattern은 일치시킬 문자(문자열), string은 검색 소스, flag는 수정자, 기본값은 0
re .I의 기능은 문자의 대소문자를 무시하는 것입니다. 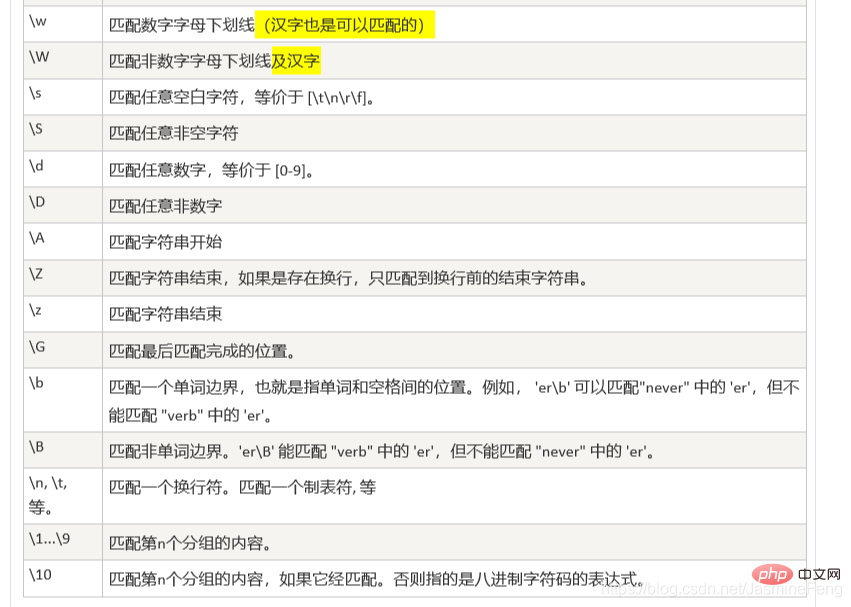
text = "I'm Jasmine-Feng. My student number is No. 321432"pattern = r"Jasmine-FENG"print('Default: ', re.findall(pattern,text))print('Ignore upper/lower case: ', re.findall(pattern,text,flags=re.I))r 문자열
이 할당됩니다. 이 r 문자열의 기능은 이스케이프를 방지하는 것입니다. r은 그대로 유지한다는 뜻입니다. 이 블로그 게시물을 참조하세요. 일반적으로 이 r 문자열은 정규식을 사용할 때 사용됩니다.Default: []Ignore upper/lower case: ['Jasmine-Feng']Process finished with exit code 0
2.2, re.ASCII(re.A)re.IGNORECASE(re.I)
虽然第1节是常量,但我们必须先简要提一下re.findall这个函数,因为它是贯穿这一节的函数。re.findall(pattern, string, flag=0): 从字符串任意位置查找,返回一个列表。pattern是欲匹配的字符(串),string是查找源,flag是修饰符,默认是0
re.I的作用是忽略字符大小写
text = "我是Jasmine-Feng. 我的学号是No. 321432"pattern = r"\w+"print('Default: ', re.findall(pattern,text))print('ASCII: ', re.findall(pattern,text,flags=re.A))N.B. pattern被赋了一个r字符串,这个r字符串的作用是避免转义,r是raw的缩写,也就是保持原样的意思。可看这篇博文。一般来说,使用正则表达式都会用到这个r字符串。
Default: ['我是Jasmine', 'Feng', '我的学号是No', '321432']ASCII: ['Jasmine', 'Feng', 'No', '321432']Process finished with exit code 0
在默认情况下,区分大小写,找不到ENG;若不区分,则可以找到eng。
2.2、re.ASCII(re.A)
re.A的作用是只匹配ASCII码支持的字符,那么具体指哪些字符呢?下图来自百度百科。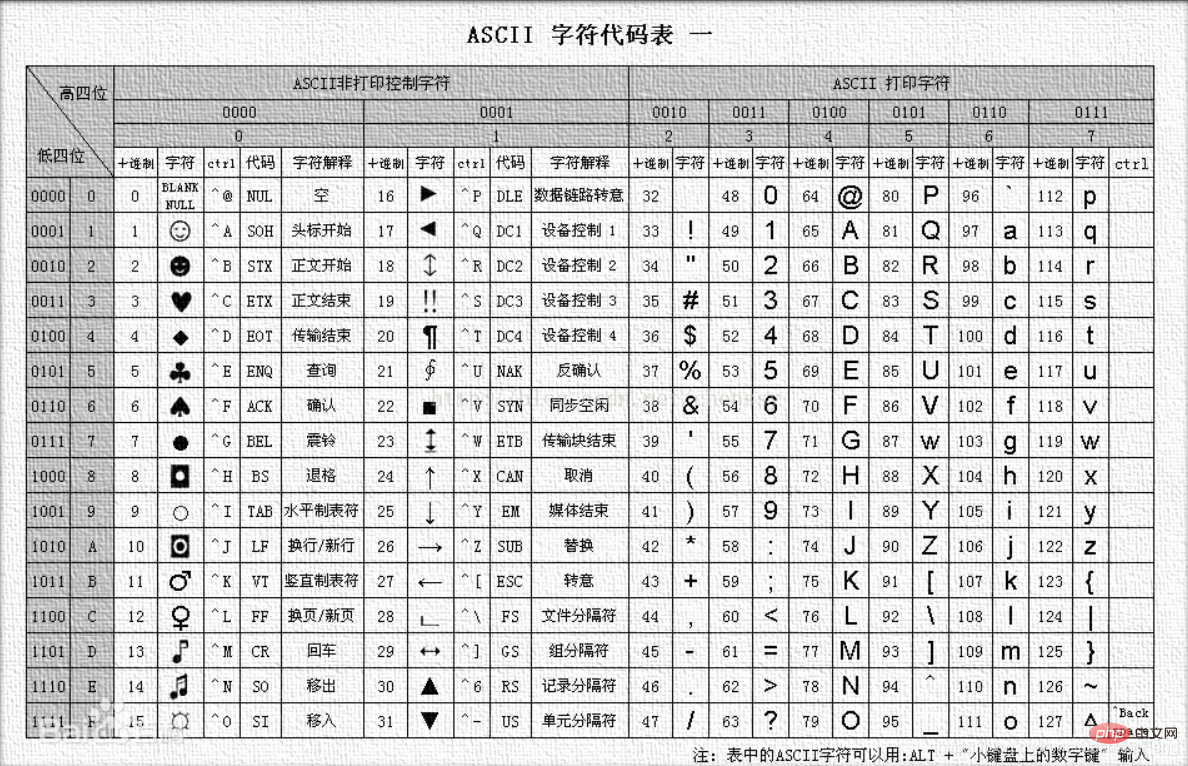
汉字是不在这个里面的,所以如果修饰符是re.A的话就匹配不了汉字了哈~
text = "我\t是Jasmine-F\neng. 我%的◉学号是No. 321432"pattern = r'.*'print('Default: ', re.findall(pattern,text))print('DOTALL: ', re.findall(pattern,text,re.S))w+的作用是匹配一个或多个字母数字下划线汉字
Default: ['我\t是Jasmine-F', '', 'eng. 我%的◉学号是No. 321432', '']DOTALL: ['我\t是Jasmine-F\neng. 我%的◉学号是No. 321432', '']Process finished with exit code 0
2.3、re.DOTALL(re.S)
在正则表达式模式中,.是用来
text = "我\t是Jasmine-F\neng. 我%的◉\n学号是No. 321432"pattern = r'.$'pattern2 = r'^.'print('Default, end: ', re.findall(pattern, text))print('MULTILINE, end: ', re.findall(pattern, text, re.M))print('Default, start: ', re.findall(pattern2, text))print('MULTILINE, start: ', re.findall(pattern2, text, re.M)).*的作用是匹配长度至少为0的字符(串),emmm,好像是句废话?事实上,只要整段话不被换行符截断,就可以得到整个字符串(外加一个空字符串)。
Default, end: ['2']MULTILINE, end: ['F', '◉', '2']Default, start: ['我']MULTILINE, start: ['我', 'e', '学']Process finished with exit code 0
2.4、re.MULTILINE(re.M)
$匹配定位到字符串末尾,^定位到字符串开头,默认情况下,如果换行,是不能定位到新一行的行头/尾的,而用re.M修饰则可以,也就是多行模式。
text = '朋友们好啊!我是xxxxxx拳掌门人xxx~'pattern = r'''朋友们 # 主语 好啊! # 谓语 '''print(re.findall(pattern, text,re.VERBOSE))
['朋友们好啊!']Process finished with exit code 0
2.5、re.VERBOSE(re.X)
verbose是“详实的、冗长的”意思,通过该修饰符可以在正则表达式中加入注释。注意,是往pattern里面加,不是往text加!我一开始以为是可以往text加注释,然后调试半天都得不到结果。。。
text = 'Hello everybody!\n我是xxxxxx拳掌门人xxx~'pattern = r'BODY.*$'print(re.findall(pattern, text, re.I))print(re.findall(pattern, text, re.M))print(re.findall(pattern, text, re.M | re.I))
[][]['body!']Process finished with exit code 0
2.6、修饰符的叠加
使用|可以叠加修饰。
3、正则表达式函数
3.1、查找单个匹配项的函数
| 函数 | 功能 |
|---|---|
search |
从任意位置开始搜索 |
match |
从开头搜索,不用完全匹配 |
fullmatch |
| 한자는 포함되지 않습니다. 이므로 수식어가
🎜 2.3, re.DOTALL (re.S) 🎜🎜🎜정규 표현식 모드에서는 .가  🎜rrreee🎜
🎜rrreee🎜.* 기능은 다음과 같습니다. 길이가 0 이상인 문자(문자열)를 일치시키세요. 음, 말도 안되는 것 같나요? 실제로 전체 단락이 개행 문자로 잘리지 않는 한 전체 문자열(및 빈 문자열)을 얻을 수 있습니다. 🎜rrreee🎜🎜2.4, re.MULTILINE(re.M)🎜🎜🎜$는 문자열의 끝인 와 일치합니다. ^ 문자열의 시작 위치를 찾습니다. 기본적으로 새 줄을 바꾸면 새 줄의 시작/끝을 찾을 수 없습니다. 그러나 re.M을 사용할 수 있습니다. 이를 수정하려면 여러 줄 모드입니다. 🎜rrreeerrreee🎜🎜2.5, re.VERBOSE(re. 텍스트가 아닌 패턴에 추가한다는 점에 유의하세요! 처음에는 text에 주석을 추가할 수 있을 거라 생각했는데, 오랫동안 디버깅을 했더니 아무런 결과도 나오지 않았습니다. . . 🎜rrreeerrree🎜🎜2.6. 수정자의 중첩🎜🎜🎜수정사항을 중첩하려면 |를 사용하세요. 🎜rrreeerrreee🎜🎜3. 정규 표현식 함수🎜🎜🎜🎜3.1. 단일 일치 항목을 찾는 함수🎜🎜
| 함수 | 함수 🎜 |
|---|---|
위 내용은 Python 정규식에 대한 참고 사항의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

Video Face Swap
완전히 무료인 AI 얼굴 교환 도구를 사용하여 모든 비디오의 얼굴을 쉽게 바꾸세요!

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)



 PHP와 Python : 다른 패러다임이 설명되었습니다
Apr 18, 2025 am 12:26 AM
PHP와 Python : 다른 패러다임이 설명되었습니다
Apr 18, 2025 am 12:26 AM
PHP는 주로 절차 적 프로그래밍이지만 객체 지향 프로그래밍 (OOP)도 지원합니다. Python은 OOP, 기능 및 절차 프로그래밍을 포함한 다양한 패러다임을 지원합니다. PHP는 웹 개발에 적합하며 Python은 데이터 분석 및 기계 학습과 같은 다양한 응용 프로그램에 적합합니다.
 PHP와 Python 중에서 선택 : 가이드
Apr 18, 2025 am 12:24 AM
PHP와 Python 중에서 선택 : 가이드
Apr 18, 2025 am 12:24 AM
PHP는 웹 개발 및 빠른 프로토 타이핑에 적합하며 Python은 데이터 과학 및 기계 학습에 적합합니다. 1.PHP는 간단한 구문과 함께 동적 웹 개발에 사용되며 빠른 개발에 적합합니다. 2. Python은 간결한 구문을 가지고 있으며 여러 분야에 적합하며 강력한 라이브러리 생태계가 있습니다.
 PHP와 Python : 그들의 역사에 깊은 다이빙
Apr 18, 2025 am 12:25 AM
PHP와 Python : 그들의 역사에 깊은 다이빙
Apr 18, 2025 am 12:25 AM
PHP는 1994 년에 시작되었으며 Rasmuslerdorf에 의해 개발되었습니다. 원래 웹 사이트 방문자를 추적하는 데 사용되었으며 점차 서버 측 스크립팅 언어로 진화했으며 웹 개발에 널리 사용되었습니다. Python은 1980 년대 후반 Guidovan Rossum에 의해 개발되었으며 1991 년에 처음 출시되었습니다. 코드 가독성과 단순성을 강조하며 과학 컴퓨팅, 데이터 분석 및 기타 분야에 적합합니다.
 Python vs. JavaScript : 학습 곡선 및 사용 편의성
Apr 16, 2025 am 12:12 AM
Python vs. JavaScript : 학습 곡선 및 사용 편의성
Apr 16, 2025 am 12:12 AM
Python은 부드러운 학습 곡선과 간결한 구문으로 초보자에게 더 적합합니다. JavaScript는 가파른 학습 곡선과 유연한 구문으로 프론트 엔드 개발에 적합합니다. 1. Python Syntax는 직관적이며 데이터 과학 및 백엔드 개발에 적합합니다. 2. JavaScript는 유연하며 프론트 엔드 및 서버 측 프로그래밍에서 널리 사용됩니다.
 숭고한 코드 파이썬을 실행하는 방법
Apr 16, 2025 am 08:48 AM
숭고한 코드 파이썬을 실행하는 방법
Apr 16, 2025 am 08:48 AM
Sublime 텍스트로 Python 코드를 실행하려면 먼저 Python 플러그인을 설치 한 다음 .py 파일을 작성하고 코드를 작성한 다음 CTRL B를 눌러 코드를 실행하면 콘솔에 출력이 표시됩니다.
 vscode에서 코드를 작성하는 위치
Apr 15, 2025 pm 09:54 PM
vscode에서 코드를 작성하는 위치
Apr 15, 2025 pm 09:54 PM
Visual Studio Code (VSCODE)에서 코드를 작성하는 것은 간단하고 사용하기 쉽습니다. vscode를 설치하고, 프로젝트를 만들고, 언어를 선택하고, 파일을 만들고, 코드를 작성하고, 저장하고 실행합니다. VSCODE의 장점에는 크로스 플랫폼, 무료 및 오픈 소스, 강력한 기능, 풍부한 확장 및 경량 및 빠른가 포함됩니다.
 Python에서 비주얼 스튜디오 코드를 사용할 수 있습니다
Apr 15, 2025 pm 08:18 PM
Python에서 비주얼 스튜디오 코드를 사용할 수 있습니다
Apr 15, 2025 pm 08:18 PM
VS 코드는 파이썬을 작성하는 데 사용될 수 있으며 파이썬 애플리케이션을 개발하기에 이상적인 도구가되는 많은 기능을 제공합니다. 사용자는 다음을 수행 할 수 있습니다. Python 확장 기능을 설치하여 코드 완료, 구문 강조 및 디버깅과 같은 기능을 얻습니다. 디버거를 사용하여 코드를 단계별로 추적하고 오류를 찾아 수정하십시오. 버전 제어를 위해 git을 통합합니다. 코드 서식 도구를 사용하여 코드 일관성을 유지하십시오. 라인 도구를 사용하여 잠재적 인 문제를 미리 발견하십시오.
 메모장으로 파이썬을 실행하는 방법
Apr 16, 2025 pm 07:33 PM
메모장으로 파이썬을 실행하는 방법
Apr 16, 2025 pm 07:33 PM
메모장에서 Python 코드를 실행하려면 Python 실행 파일 및 NPPEXEC 플러그인을 설치해야합니다. Python을 설치하고 경로를 추가 한 후 nppexec 플러그인의 명령 "Python"및 매개 변수 "{current_directory} {file_name}"을 구성하여 Notepad의 단축키 "F6"을 통해 Python 코드를 실행하십시오.
