

MySQL 데이터베이스가 무엇인지 알아봅시다(3)

무료 학습 권장 사항: mysql 비디오 튜토리얼
Directory
- 퍼지 쿼리
- 테이블 제약 조건
- Re 테이블 간의 관계
- 다대일 연관
- 다대다 연관
- 일대일 연관
퍼지 쿼리
대략 제공되는 내용을 기반으로 원하는 데이터를 찾을 수 있는 = 쿼리와는 다릅니다. char 유형을 취하는 데이터 및 varchar 유형 데이터의 예:
create table c1(x char(10));create table c2(x varchar(10));insert c1 values('io');insert c2 values('io');Fuzzy 쿼리는 like
select * from c1 where x like 'io';select * from c2 where x like 'io';
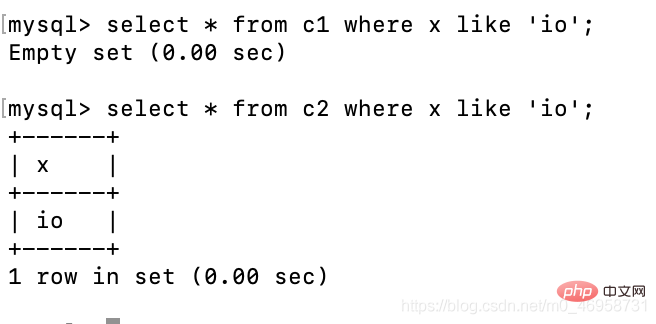
를 사용합니다. c1의 x는 char 유형임을 알 수 있습니다. 우리는 io 데이터가 있는지 확인하기 위해 퍼지 쿼리를 사용합니다. 표시할 수 없지만 통과함 = 그러나 쿼리할 수 있음

퍼지 쿼리가 더 정확합니다. 이러한 방식으로 쿼리하려면 쿼리하기 전에 이 필드의 전체 내용을 입력해야 합니다. 여기서 char 유형은 길이가 10자 미만이므로 공백을 사용합니다. 보충, 쿼리할 때는 공백을 가져와야 합니다. 
퍼지 쿼리에서 제공하는 쿼리 방법을 사용할 수도 있습니다. %는 0개 이상의 문자를 나타냅니다.
select * from c1 where x like 'io%';

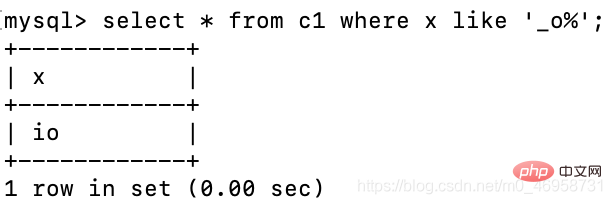
두 번째 숫자가 o라는 것만 알고 시작과 끝을 모르는 경우 다음을 사용할 수 있습니다. _를 사용하여 단일 문자를 나타내고 %를 사용하여 다음 문자를 일치시킵니다.
select * from c1 where x like '_o%';
SQL 퍼지 쿼리 구문
"SELECT 열 FROM 테이블 WHERE 열 LIKE ';패턴';"의 경우.
SQL은 네 가지 일치 모드를 제공합니다.
- %는 0개 이상의 bai 문자를 나타냅니다. 다음 명령문:
SELECT * FROM user WHERE name LIKE ';%三%';
는 "Zhang San", "Three-legged Cat", "Tang Sanzang"과 같이 이름에 "3"이 포함된 모든 이름을 찾습니다. 등;- _은 단일 문자를 나타냅니다. 명령문:
SELECT * FROM user WHERE name LIKE ';三';
이름이 세 글자이고 가운데 글자가 "三"인 "Tang Sanzang"만 찾습니다.
SELECT * FROM user WHERE name LIKE ' ;三_ _';
이름이 세 글자이고 첫 글자가 "三"인 "세발 달린 고양이"만 찾습니다.- []는 괄호 안에 나열된 문자 중 하나를 나타냅니다(정규 표현식과 유사). 명령문:
[^ ]은 괄호 안에 나열되지 않은 단일 문자를 나타냅니다. 명령문:
SELECT * FROM user WHERE name LIKE ';[张李王]三';
는 "Zhang San", "Li San", "Wang San"("Zhang Li Wang San" 대신)을 찾습니다. [ ]에는 일련의 문자(01234, abcde 등)가 포함되어 있으며 "0-4", "a-e"로 축약할 수 있습니다.
SELECT * FROM user WHERE name LIKE ';老[1-9]';
Will 출력 "Old 1", "Old 2", ..., "Old 9" 찾기
"-" 문자를 찾으려면 먼저 ';张三[-1-9]'를 입력하세요.
- SELECT * FROM user WHERE name LIKE ';[^Zhang Liwang]三';
는 "Zhang", "Li", "Wang"이라는 성이 아닌 "Zhao San", "Sun San" 등을 찾습니다. ;
SELECT * FROM user WHERE name LIKE ';老[^1-4]';
는 "old 1"에서 "old 4"를 제외하고 "old 5", "old 6", ..., "를 찾습니다. 오래된 9".
테이블 제약 조건
소개:
- 데이터 유형의 너비와 같은 제약 조건은 선택적 매개 변수입니다.
- 기능: 데이터의 무결성과 일관성을 보장하는 데 사용됩니다
PRIMARY KEY (PK) 标识该字段为该表的主键,可以唯一的标识记录FOREIGN KEY (FK) 标识该字段为该表的外键NOT NULL 标识该字段不能为空UNIQUE KEY (UK) 标识该字段的值是唯一的AUTO_INCREMENT 标识该字段的值自动增长(整数类型,而且为主键)DEFAULT 为该字段设置默认值UNSIGNED 无符号 ZEROFILL 使用0填充
기본 키는 레코드를 결정할 수 있는 고유 식별자입니다.
AUTO_INCREMENT: 설정 후 이 필드는 테이블에 값이 삽입될 때마다 자동으로 숫자만큼 증가하지만 이 필드는 정수 유형이어야 하며 또한 기본 키가 됩니다FOREIGN KEY: 이 테이블의 필드를 다른 테이블의 필드와 연결하는 외래 키입니다. 연결 후 이 필드의 값은 연결된 필드의 값과 일치해야 합니다.我们创建表,通常会有一个id字段作为索引标识作用,并且会将它设置为主键和自增。 实例: 这个时候,我们进行两部操作就可以解决这个问题。 删除id字段,再重新设置。 还需要注意的是:我们使用delete删除一条记录时,并不会影响自增 效果演示:delete删除整个表记录 联合主键 确保设置为主键的某几个字段的数据相同 主键的一个目的就是确定数据的唯一性,它跟唯一约束的区别就是,唯一约束可以有一个NULL值,但是主键不能有NULL值,再说联合主键,联合主键就是说,当一个字段可能存在重复值,无法确定这条数据的唯一性时,再加上一个字,两个字段联合起来确定这条数据的唯一性。比如你提到的id和name为联合主键,在插入数据时,当id相同,name不同,或者id不同,name相同时数据是允许被插入的,但是当id和name都相同时,数据是不允许被插入的。 实例: 外键的话,我们在表之间的关联进行演示 表之间的关联 我们这里先介绍表之间的关联,后面再学习联表查询 通过某一个字段,或者通过某一张表,将多个表关联起来。 我们一张表处理好不行吗,为什么要关联,像这样? 那么我们需要将部门单独使用一张表,再将员工这个使用一个字段关联到另一个表内,我们可以使用外键,也可以不使用外键,先来演示外键的好处吧 多对一关联 如:多个员工对应一个部门。 员工表,先别急着创建,请向下看 上面外键的作用就是: dep_id字段关联了dep表的id字段: 注意:必须是外键已存在,所以需要先创建部门表,再创建员工表 部门表 emp表的dep_id字段设置的数据必须是dep表已存在的id 所以我们需要先向dep表插入记录 员工表插入记录 注意:如果我们emp表的dep_id字段插入的数据,在dep表中的id字段不存在该数据时,就会报错。 查询我们创建后的效果 我们再来看一下同步更新以及删除,外键的改动被关联表会受到影响 多对多关联 多张表互相关联 如:一个作者可以写多本书,一本书也可以有多个作者,双向的一对多,即多对多 这时使用外键会出现一个弊端,那就是先创建哪张表呢?它们都互相对应,是不是很矛盾呢?解决办法:第三张表,关联书的id与作者的id book表 author表 中间表:负责将两张表进行关联 多名作者关联一本书,或者一名作者关联多本书,书也要体现出谁关联了它 book表插入数据: author表插入数据: 关联表插入数据: 目前的对应关系就是: jack:斗破苍穹、斗罗大陆、武动乾坤 一个作者可以产于多本书的编写,同时,每本书都会标明产于的作者 一对一关联 路人有可能变成某个学校的学生,即一对一关系。 在这之前,路人不属于学校。 原理就是:学校通过广告,或者通过电话邀请,将路人变成了学生。 路人表 学校表 数据存储的设计,需要提前设计好表的关联 关系,将关系全部设计好以后,剩下的只是往里存数据了,后续我们会了解到联表查询相关内容,将有关联性的内容,以虚拟表的形式查询出来,查询出来的数据可能来自多个表。 表的关联,建议使用以下方式 相关免费学习推荐:mysql数据库(视频)create table test(
id int primary key auto_increment,
identity varchar(18) not null unique key, --身份证必须唯一
gender varchar(18) default '男');insert test(identity) values('123456789012345678');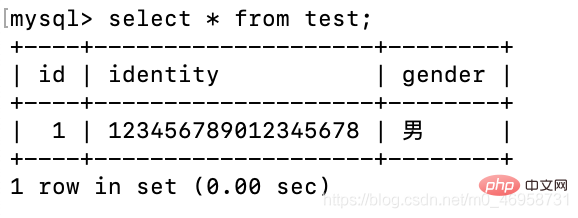
当身份字段插入相同值,则会报错,因为字段设置了唯一值
insert test(identity,gender) values('0123456789012345678','女');
我们会发现,id不对劲啊,那是因为笔者之前进行两次插入值操作,但是值并没有成功插入进去,但是这个自增却受到了影响.alter table test drop id;alter table test add id int primary key auto_increment first;
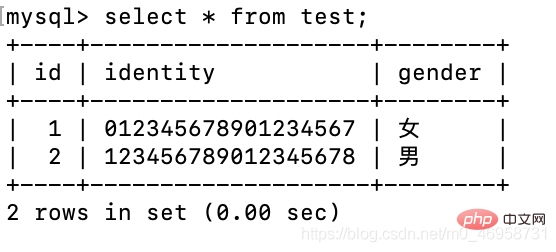
很神奇是不是,这个MySQL的底层机制。vary 良心delete from test where id = 2;insert test(identity,gender) values('111111111111111111','男');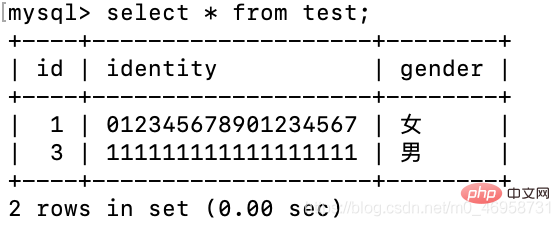
关于这个操作,如果我们只是删除单条记录的话,可以使用上序提供的方法还调整自增的值,而如果是删除整个表记录的话,使用以下方法:truncate test;

效果演示:truncate删除整个表记录
create table test(
id int,
name varchar(10),
primary key(id,name));
insert test values(1,1);

如果再次插入两个主键相同的数据,则会报错
只要设置主键的两个字段,在一条记录内,数据不完全相同就没有问题。
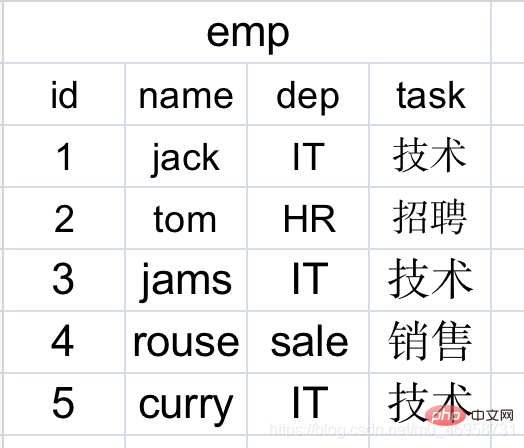
有没有发现一个问题,有些员工它们对应的是相同部门,一张表就重复了很多次记录,随着员工数量的增加,就会出现越来越多个重复记录,相对更占用空间了。
create table emp(
id int primary key auto_increment,
name varchar(10) not null,
dep_id int,
foreign key(dep_id) references dep(id)
on update cascade # 级联更新
on delete cascade); # 级联删除
当dep表的id字段值修改后,该表的dep_id字段下面如果有和dep表id相同值的则会一起更改。
如果dep表删除了某一条记录,当emp表的dep_id与dep表删除记录的id值对上以后,emp表这条记录也会被随之删除。create table dep(
id int primary key auto_increment,
name varchar(16) not null unique key,
task varchar(16) not null);
insert dep(name,task) values('IT','技术'),('HR','招聘'),('sale','销售');insert emp(name,dep_id) values
('jack',1),
('tom',2),
('jams',1),
('rouse',3),
('curry',2);
# ('go',4) 报错,在关联外键的id字段中找不到
这样就把这两个表关联起来了,目前我们先不了解多表查询,这个先了解的是,表之间的关联。update dep set id=33333 where id = 3;
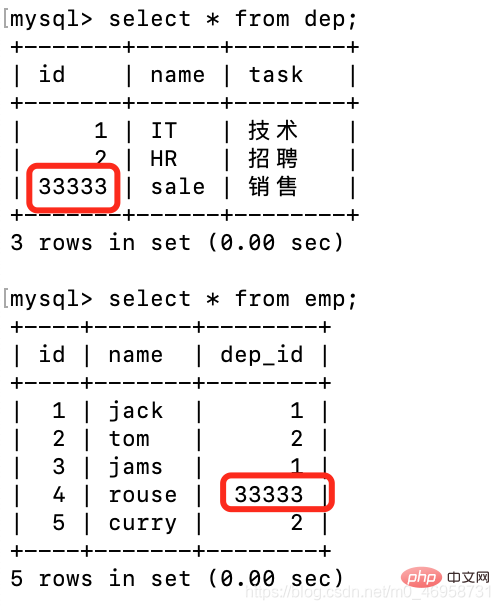
再来体验一下同步删除delete from dep where id = 33333;

这就是外键带给我们的效果,有利也有弊:
create table book(
id int primary key auto_increment,
name varchar(30));
create table author(
id int primary key auto_increment,
name varchar(30));
create table authorRbook(
id int primary key auto_increment,
author_id int,
book_id int,
foreign key(book_id) references book(id)
on update cascade
on delete cascade,
foreign key(author_id) references author(id)
on update cascade
on delete cascade);
insert book(name) values
('斗破苍穹'),
('斗罗大陆'),
('武动乾坤');insert author(name) values
('jack'),
('tom'),
('jams'),
('rouse'),
('curry'),
('john');insert authorRbook(author_id,book_id) values
(1,1),
(1,2),
(1,3),
(2,1),
(2,3),
(3,2),
(4,1),
(5,1),
(5,3),
(6,2);
tom:斗破苍穹、武动乾坤
jams:斗罗大陆
rouse:斗破苍穹
curry:斗破苍穹、武动乾坤
jhon:斗罗大陆
create table passers_by(
id int primary key auto_increment,
name varchar(10),
age int);
insert passers_by(name,age) values
('jack',18),
('tom',19),
('jams',23);create table school(
id int primary key auto_increment,
class varchar(10),
student_id int unique key,
foreign key(student_id) references passers_by(id)
on update cascade
on delete cascade);insert school(class,student_id) values
('Mysql入门到放弃',1),
('Python入门到运维',3),
('Java从入门到音乐',2);
위 내용은 MySQL 데이터베이스가 무엇인지 알아봅시다(3)의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

Video Face Swap
완전히 무료인 AI 얼굴 교환 도구를 사용하여 모든 비디오의 얼굴을 쉽게 바꾸세요!

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7663
7663
 15
1393
52
1205
24
91
11
73
19
15
1393
52
1205
24
91
11
73
19

 PHP 개발 실습: PHPMailer를 사용하여 MySQL 데이터베이스의 사용자에게 이메일 보내기
Aug 05, 2023 pm 06:21 PM
PHP 개발 실습: PHPMailer를 사용하여 MySQL 데이터베이스의 사용자에게 이메일 보내기
Aug 05, 2023 pm 06:21 PM
PHP 개발 실습: PHPMailer를 사용하여 MySQL 데이터베이스의 사용자에게 이메일 보내기 소개: 현대 인터넷 구축에서 이메일은 중요한 통신 도구입니다. 전자상거래에서 회원가입, 비밀번호 재설정, 주문확인 등 이메일 발송은 필수적인 기능입니다. 이 기사에서는 PHPMailer를 사용하여 이메일을 보내고 이메일 정보를 MySQL 데이터베이스의 사용자 정보 테이블에 저장하는 방법을 소개합니다. 1. PHPMailer 라이브러리를 설치하십시오. PHPMailer는
 Go 언어와 MySQL 데이터베이스: 핫 데이터와 콜드 데이터를 분리하는 방법은 무엇입니까?
Jun 18, 2023 am 08:26 AM
Go 언어와 MySQL 데이터베이스: 핫 데이터와 콜드 데이터를 분리하는 방법은 무엇입니까?
Jun 18, 2023 am 08:26 AM
데이터의 양이 지속적으로 증가함에 따라 데이터베이스 성능이 점점 더 중요한 문제로 대두되고 있습니다. 핫 데이터와 콜드 데이터 분리 처리는 핫 데이터와 콜드 데이터를 분리하여 시스템 성능과 효율성을 향상시킬 수 있는 효과적인 솔루션입니다. 이 기사에서는 Go 언어와 MySQL 데이터베이스를 사용하여 핫 데이터와 콜드 데이터를 분리하는 방법을 소개합니다. 1. 핫 데이터와 콜드 데이터 분리 처리란 무엇입니까? 핫 데이터와 콜드 데이터 분리 처리는 핫 데이터와 콜드 데이터를 분류하는 방법입니다. 핫 데이터는 액세스 빈도가 높고 성능 요구 사항이 높은 데이터를 말합니다.
 성공적으로 취업하려면 MySQL 데이터베이스 기술을 어느 정도 개발할 수 있습니까?
Sep 12, 2023 pm 06:42 PM
성공적으로 취업하려면 MySQL 데이터베이스 기술을 어느 정도 개발할 수 있습니까?
Sep 12, 2023 pm 06:42 PM
성공적으로 취업하려면 MySQL 데이터베이스 기술을 어느 정도 개발할 수 있습니까? 정보화 시대의 급속한 발전으로 인해 데이터베이스 관리 시스템은 사회 각계각층에서 없어서는 안 될 중요한 구성 요소가 되었습니다. 일반적으로 사용되는 관계형 데이터베이스 관리 시스템인 MySQL은 다양한 응용 분야와 취업 기회를 제공합니다. 그렇다면, 성공적으로 채용되려면 MySQL 데이터베이스 기술을 어느 정도 개발해야 할까요? 우선, MySQL의 기본 원리와 기본 지식을 익히는 것이 가장 기본적인 요구 사항입니다. MySQL은 오픈 소스 관계형 데이터베이스 관리입니다.
 Go 언어를 사용하여 MySQL 데이터베이스의 증분 데이터 백업을 수행하는 방법
Jun 17, 2023 pm 02:28 PM
Go 언어를 사용하여 MySQL 데이터베이스의 증분 데이터 백업을 수행하는 방법
Jun 17, 2023 pm 02:28 PM
데이터 양이 증가함에 따라 데이터베이스 백업이 점점 더 중요해지고 있습니다. MySQL 데이터베이스의 경우 Go 언어를 사용하여 자동 증분 백업을 달성할 수 있습니다. 이 기사에서는 Go 언어를 사용하여 MySQL 데이터베이스 데이터의 증분 백업을 수행하는 방법을 간략하게 소개합니다. 1. Go 언어 환경 설치 먼저 Go 언어 환경을 로컬에 설치해야 합니다. 공식 웹사이트로 이동하여 해당 설치 패키지를 다운로드하고 설치할 수 있습니다. 2. 해당 라이브러리를 설치합니다. Go 언어는 MySQL 데이터베이스에 액세스하기 위한 많은 타사 라이브러리를 제공하며 그 중 가장 일반적으로 사용되는 라이브러리는 다음과 같습니다.
 시계열 분석을 위해 MySQL 데이터베이스를 사용하는 방법은 무엇입니까?
Jul 12, 2023 am 08:39 AM
시계열 분석을 위해 MySQL 데이터베이스를 사용하는 방법은 무엇입니까?
Jul 12, 2023 am 08:39 AM
시계열 분석을 위해 MySQL 데이터베이스를 사용하는 방법은 무엇입니까? 시계열 데이터(Time series data)란 시간적 연속성과 상관성을 갖는 시간순으로 배열된 데이터의 집합을 말한다. 시계열 분석은 미래 추세 예측, 순환 변화 발견, 이상값 탐지 등에 사용할 수 있는 중요한 데이터 분석 방법입니다. 이 기사에서는 코드 예제와 함께 시계열 분석을 위해 MySQL 데이터베이스를 사용하는 방법을 소개합니다. 데이터 테이블 생성 먼저 시계열 데이터를 저장할 데이터 테이블을 생성해야 합니다. 숫자를 분석하고 싶다고 가정해 보겠습니다.
 이미지 처리에 MySQL 데이터베이스를 사용하는 방법은 무엇입니까?
Jul 14, 2023 pm 12:21 PM
이미지 처리에 MySQL 데이터베이스를 사용하는 방법은 무엇입니까?
Jul 14, 2023 pm 12:21 PM
이미지 처리에 MySQL 데이터베이스를 사용하는 방법은 무엇입니까? MySQL은 데이터를 저장하고 관리하는 것 외에도 이미지 처리에도 사용할 수 있는 강력한 관계형 데이터베이스 관리 시스템입니다. 이 기사에서는 이미지 처리를 위해 MySQL 데이터베이스를 사용하는 방법을 소개하고 몇 가지 코드 예제를 제공합니다. 시작하기 전에 MySQL 데이터베이스를 설치했고 기본 SQL 문에 대해 잘 알고 있는지 확인하세요. 데이터베이스 테이블 생성 먼저 이미지 데이터를 저장할 새 데이터베이스 테이블을 생성합니다. 테이블의 구조는 다음과 같습니다.
 Go 언어를 사용하여 안정적인 MySQL 데이터베이스 연결을 만드는 방법은 무엇입니까?
Jun 17, 2023 pm 07:18 PM
Go 언어를 사용하여 안정적인 MySQL 데이터베이스 연결을 만드는 방법은 무엇입니까?
Jun 17, 2023 pm 07:18 PM
저장 및 처리가 필요한 대용량 데이터로 인해 MySQL은 애플리케이션 개발에서 가장 일반적으로 사용되는 관계형 데이터베이스 중 하나가 되었습니다. Go 언어는 효율적인 동시성 처리와 간결한 구문으로 인해 개발자들 사이에서 점점 더 인기를 얻고 있습니다. 이 기사에서는 독자가 Go 언어를 통해 안정적인 MySQL 데이터베이스 연결을 구현하여 개발자가 데이터를 보다 효율적으로 쿼리하고 저장할 수 있도록 안내합니다. 1. Go 언어로 MySQL 데이터베이스에 연결하는 여러 가지 방법 Go 언어로 MySQL 데이터베이스에 연결하는 방법에는 일반적으로 다음 세 가지가 있습니다. 1. 타사 라이브러리
 MySQL 데이터베이스와 Go 언어: 데이터 캐싱을 수행하는 방법은 무엇입니까?
Jun 17, 2023 am 10:05 AM
MySQL 데이터베이스와 Go 언어: 데이터 캐싱을 수행하는 방법은 무엇입니까?
Jun 17, 2023 am 10:05 AM
최근 몇 년 동안 Go 언어는 개발자들 사이에서 점점 인기가 높아지고 있으며 고성능 웹 애플리케이션 개발에 선호되는 언어 중 하나가 되었습니다. MySQL은 널리 사용되는 인기 있는 데이터베이스이기도 합니다. 이 두 기술을 결합하는 과정에서 캐싱은 매우 중요한 부분입니다. 다음은 Go 언어를 사용하여 MySQL 데이터베이스의 캐시를 처리하는 방법을 소개합니다. 캐싱의 개념 웹 애플리케이션에서 캐싱은 데이터 액세스 속도를 높이기 위해 만들어진 중간 계층입니다. 주로 자주 요청되는 데이터를 저장하는 데 사용됩니다.
