

 무료 학습 권장 사항: sMysql 비디오 자습서
무료 학습 권장 사항: sMysql 비디오 자습서
복제 시 복제 중인 테이블에 대한 모든 업데이트는 마스터 서버에서 이루어져야 한다는 점에 유의하세요. 그렇지 않으면 마스터 서버의 테이블에 대한 사용자 업데이트와 슬레이브 서버의 테이블 업데이트 간에 충돌이 발생하지 않도록 주의해야 합니다.복사 개요 MySQL에 내장된 복사 기능은 대규모 고성능 응용 프로그램을 구축하기 위한 기반입니다. MySQL 데이터를 여러 시스템에 배포합니다. 이 배포 메커니즘은 특정 MySQL 호스트의 데이터를 다른 호스트(슬레이브)에 복사하고 다시 실행함으로써 달성됩니다. 복제 중에 하나의 서버는 마스터 서버 역할을 하고 하나 이상의 다른 서버는 슬레이브 서버 역할을 합니다. 마스터 서버는 바이너리 로그 파일에 업데이트를 기록하고 파일 인덱스를 유지하여 로그 회전을 추적합니다. 이러한 로그는 슬레이브 서버로 전송된 업데이트를 기록합니다. 슬레이브가 마스터에 연결되면 슬레이브가 로그에서 읽은 마지막 성공적인 업데이트 위치를 마스터에 알립니다. 슬레이브는 그 이후 발생한 모든 업데이트를 수신한 다음 마스터가 새 업데이트에 대한 알림을 받을 때까지 차단하고 기다립니다.
1.1 mysql에서 지원하는 복제 유형:
(1): 명령문 기반 복제: 마스터 서버에서 실행되는 SQL 문이며, 슬레이브 서버에서도 동일한 명령문이 실행됩니다. MySQL은 기본적으로 명령문 기반 복제를 사용하는데, 이는 상대적으로 효율적입니다.确 정확하게 복사할 수 없다고 판단되면 자동으로 라인 기반 복사를 선택하게 됩니다.
(2): 행 기반 복제: 슬레이브 서버에서 명령을 실행하는 대신 변경된 내용을 복사합니다. mysql5.0부터 지원(3): 혼합형 복제: 일단 SQL문 기반 복제를 기본으로 사용합니다. 명령문 기반 복제가 정확할 수 없는 경우 행 기반 복제가 사용됩니다.
1.2. 복제로 해결되는 문제
MySQL 복제 기술은 다음과 같은 특징을 가지고 있습니다. 백업
( 4) 고가용성 및 장애 조치
전반적으로 복제에는 3단계가 있습니다.
( 1) 마스터는 바이너리 로그에 변경 사항을 기록합니다(이러한 레코드를 바이너리 로그 이벤트, 바이너리 로그 이벤트라고 함). 자체 데이터를 반영합니다.
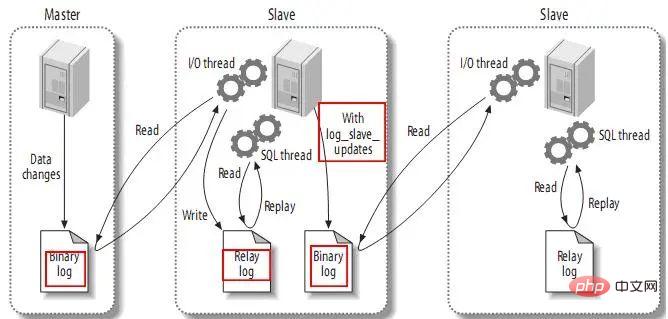
아래 그림은 복사 과정을 설명합니다.
프로세스의 첫 번째 부분은 마스터가 바이너리 로그를 기록하는 것입니다. 각 트랜잭션이 데이터 업데이트를 완료하기 전에 마스터는 이러한 변경 사항을 보조 로그에 기록합니다. MySQL은 트랜잭션의 명령문이 인터리브된 경우에도 바이너리 로그에 트랜잭션을 직렬로 기록합니다. 이벤트가 바이너리 로그에 기록된 후 마스터는 스토리지 엔진에 트랜잭션을 커밋하도록 알립니다.
다음 단계는 슬레이브가 마스터의 바이너리 로그를 자신의 릴레이 로그에 복사하는 것입니다. 먼저 슬레이브는 작업자 스레드(I/O 스레드)를 시작합니다. I/O 스레드는 마스터에서 일반 연결을 연 다음 binlog 덤프 프로세스를 시작합니다. Binlog 덤프 프로세스는 마스터의 바이너리 로그에서 이벤트를 읽습니다. 마스터를 따라잡으면 마스터가 새 이벤트를 생성할 때까지 기다립니다. I/O 스레드는 이러한 이벤트를 릴레이 로그에 기록합니다.
SQL 슬레이브 스레드는 프로세스의 마지막 단계를 처리합니다. SQL 스레드는 릴레이 로그에서 이벤트를 읽고 이벤트를 재생하여 슬레이브의 데이터를 마스터의 데이터와 일치하도록 업데이트합니다. 스레드가 I/O 스레드와 일치하는 한 릴레이 로그는 일반적으로 OS 캐시에 있으므로 릴레이 로그의 오버헤드는 매우 작습니다.
또한 마스터에도 작업 스레드가 있습니다. 다른 MySQL 연결과 마찬가지로 슬레이브가 마스터에서 연결을 열면 마스터가 스레드를 시작하게 됩니다. 복제 프로세스에는 중요한 제한 사항이 있습니다. 복제는 슬레이브에서 직렬화됩니다. 이는 마스터의 병렬 업데이트 작업이 슬레이브에서 병렬로 수행될 수 없음을 의미합니다.
2. 마스터-슬레이브 복제 구성
MySQL 데이터베이스 서버는 마스터와 슬레이브 두 개가 있는데, 마스터는 마스터 서버이고 슬레이브는 슬레이브 서버입니다. 초기 상태에서는 마스터와 슬레이브의 데이터 정보가 있습니다. 데이터가 변경되면 슬레이브도 그에 따라 변경되므로 마스터와 슬레이브의 데이터 정보가 동기화되어 백업 목적을 달성합니다.
핵심 포인트:
마스터 서버와 슬레이브 서버 간에 다양한 수정 작업을 전송하는 역할을 담당하는 매체는 마스터 서버의 바이너리 변경 로그입니다. 이 로그는 슬레이브 서버에 전송해야 하는 다양한 수정 작업을 기록합니다. 따라서 마스터 서버에서는 바이너리 로깅 기능을 활성화해야 합니다. 슬레이브 서버는 마스터 서버에 연결하고 마스터 서버에 바이너리 변경 로그를 전송하도록 요청할 수 있는 충분한 권한이 있어야 합니다. ㅋㅋㅋ
마스터와 슬레이브의 MySQL 데이터베이스 버전은 모두 5.0.18입니다.
IP 주소: 10.100.0.100 각 슬레이브는 표준 MySQL 사용자 이름과 비밀번호를 사용하여 마스터에 연결합니다. 복제 작업을 수행하는 사용자에게는 REPLICATION SLAVE 권한이 부여됩니다. 사용자 이름과 비밀번호는 텍스트 파일 master.info에 저장됩니다. 명령은 다음과 같습니다: mysql > GRANT REPLICATION SLAVE,RELOAD,SUPER ON *.* TO backup@’10.100.0.200’ IDENTIFIED BY ‘1234’;
계정 백업을 생성하고 주소 10.100.0.200에서만 로그인을 허용합니다.
(mysql 버전의 새 비밀번호 알고리즘과 이전 비밀번호 알고리즘이 다른 경우 다음을 설정할 수 있습니다. 'backup'@'10.100.0.200'=old_password('1234')에 대한 비밀번호 설정)
2.2 데이터 복사(완전히 새로 설치된 mysql 마스터-슬레이브 서버라면 새로 설치된 마스터와 슬레이브의 데이터가 동일하므로 이 단계는 필요하지 않습니다.)
마스터 서버를 종료하고 마스터에 있는 데이터를 B 서버에 복사하고, 마스터와 슬레이브의 데이터를 동기화하고 모든 설정 작업이 완료되기 전에 마스터와 슬레이브 서버에서 쓰기 작업이 금지되도록 하여 두 데이터베이스의 데이터가 동일해야 합니다!
2.3. 마스터 구성다음으로 바이너리 로그 열기 및 고유한 서버 ID 지정을 포함하여 마스터를 구성합니다. 예를 들어 구성 파일에 다음 값을 추가합니다.
server-id=1log-bin=mysql-binserver-id:为主服务器A的ID值log-bin:二进制变更日值
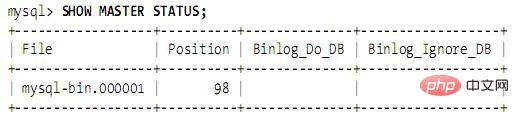
마스터를 다시 시작하고 SHOW MASTER STATUS를 실행하면 출력은 다음과 같습니다.
2.4,configureslave
Slave 구성은 다음과 유사합니다. 마스터인 경우 슬레이브 MySQL도 다시 시작해야 합니다. 다음과 같습니다:log_bin = mysql-binserver_id = 2relay_log = mysql-relay-binlog_slave_updates = 1read_only = 1
 log_bin: 슬레이브가 바이너리 로그 bin_log를 활성화할 필요는 없지만 설정해야 하는 경우가 있습니다. 예를 들어 슬레이브가 다른 슬레이브의 마스터인 경우 bin_log를 설정해야 합니다. 여기서는 바이너리 로깅을 활성화하고 이름을 표시합니다(기본 이름은 호스트 이름이지만 호스트 이름을 변경하면 문제가 발생합니다).
log_bin: 슬레이브가 바이너리 로그 bin_log를 활성화할 필요는 없지만 설정해야 하는 경우가 있습니다. 예를 들어 슬레이브가 다른 슬레이브의 마스터인 경우 bin_log를 설정해야 합니다. 여기서는 바이너리 로깅을 활성화하고 이름을 표시합니다(기본 이름은 호스트 이름이지만 호스트 이름을 변경하면 문제가 발생합니다).
어떤 사람들은 슬레이브 바이너리 로그를 활성화했지만 log_slave_updates를 설정하지 않은 다음 슬레이브 데이터가 변경되었는지 확인합니다. 이는 잘못된 구성입니다.
read_only: 데이터가 변경되는 것을 방지하는 read_only를 사용해 보세요(특수 스레드 제외). 그러나 read_only는 특히 슬레이브에 테이블을 생성해야 하는 애플리케이션의 경우 그다지 실용적이지 않습니다.
2.5, 슬레이브 시작接下来就是让slave连接master,并开始重做master二进制日志中的事件。你不应该用配置文件进行该操作,而应该使用CHANGE MASTER TO语句,该语句可以完全取代对配置文件的修改,而且它可以为slave指定不同的master,而不需要停止服务器。如下:
mysql> CHANGE MASTER TO MASTER_HOST='server1', -> MASTER_USER='repl', -> MASTER_PASSWORD='p4ssword', -> MASTER_LOG_FILE='mysql-bin.000001', -> MASTER_LOG_POS=0;
MASTER_LOG_POS的值为0,因为它是日志的开始位置。
你可以用SHOW SLAVE STATUS语句查看slave的设置是否正确:
mysql> SHOW SLAVE STATUS\G*************************** 1. row *************************** Slave_IO_State: Master_Host: server1 Master_User: repl Master_Port: 3306 Connect_Retry: 60 Master_Log_File: mysql-bin.000001 Read_Master_Log_Pos: 4 Relay_Log_File: mysql-relay-bin.000001 Relay_Log_Pos: 4 Relay_Master_Log_File: mysql-bin.000001 Slave_IO_Running: No Slave_SQL_Running: No ...omitted... Seconds_Behind_Master: NULLSlave_IO_State, Slave_IO_Running, 和Slave_SQL_Running是No
表明slave还没有开始复制过程。日志的位置为4而不是0,这是因为0只是日志文件的开始位置,并不是日志位置。实际上,MySQL知道的第一个事件的位置是4。
为了开始复制,你可以运行:
mysql> START SLAVE;运行SHOW SLAVE STATUS查看输出结果:mysql> SHOW SLAVE STATUS\G*************************** 1. row *************************** Slave_IO_State: Waiting for master to send event Master_Host: server1 Master_User: repl Master_Port: 3306 Connect_Retry: 60 Master_Log_File: mysql-bin.000001 Read_Master_Log_Pos: 164 Relay_Log_File: mysql-relay-bin.000001 Relay_Log_Pos: 164 Relay_Master_Log_File: mysql-bin.000001 Slave_IO_Running: Yes Slave_SQL_Running: Yes ...omitted... Seconds_Behind_Master: 0
在这里主要是看:
Slave_IO_Running=Yes Slave_SQL_Running=Yes
slave的I/O和SQL线程都已经开始运行,而且Seconds_Behind_Master不再是NULL。日志的位置增加了,意味着一些事件被获取并执行了。如果你在master上进行修改,你可以在slave上看到各种日志文件的位置的变化,同样,你也可以看到数据库中数据的变化。
你可查看master和slave上线程的状态。在master上,你可以看到slave的I/O线程创建的连接:
在master上输入show processlist\G;
|
mysql> show processlist \G *************************** 1. row *************************** Id: 1 User: root Host: localhost:2096 db: test Command: Query Time: 0 State: NULL Info: show processlist *************************** 2. row *************************** Id: 2 User: repl Host: localhost:2144 db: NULL Command: Binlog Dump Time: 1838 State: Has sent all binlog to slave; waiting for binlog to be updated Info: NULL 2 rows in set (0.00 sec) |
行2为处理slave的I/O线程的连接。
在slave服务器上运行该语句:
|
mysql> show processlist \G *************************** 1. row *************************** Id: 1 User: system user Host: db: NULL Command: Connect Time: 2291 State: Waiting for master to send event Info: NULL *************************** 2. row *************************** Id: 2 User: system user Host: db: NULL Command: Connect Time: 1852 State: Has read all relay log; waiting for the slave I/O thread to update it Info: NULL *************************** 3. row *************************** Id: 5 User: root Host: localhost:2152 db: test Command: Query Time: 0 State: NULL Info: show processlist 3 rows in set (0.00 sec) |
行1为I/O线程状态,行2为SQL线程状态。
2.5、添加新slave服务器
假如master已经运行很久了,想对新安装的slave进行数据同步,甚至它没有master的数据。
此时,有几种方法可以使slave从另一个服务开始,例如,从master拷贝数据,从另一个slave克隆,从最近的备份开始一个slave。Slave与master同步时,需要三样东西:
(1)master的某个时刻的数据快照;
(2)master当前的日志文件、以及生成快照时的字节偏移。这两个值可以叫做日志文件坐标(log file coordinate),因为它们确定了一个二进制日志的位置,你可以用SHOW MASTER STATUS命令找到日志文件的坐标;
(3)master的二进制日志文件。
可以通过以下几中方法来克隆一个slave:
(1) 冷拷贝(cold copy)
停止master,将master的文件拷贝到slave;然后重启master。缺点很明显。
(2) 热拷贝(warm copy)
如果你仅使用MyISAM表,你可以使用mysqlhotcopy拷贝,即使服务器正在运行。
(3) 使用mysqldump
使用mysqldump来得到一个数据快照可分为以下几步:
锁表:如果你还没有锁表,你应该对表加锁,防止其它连接修改数据库,否则,你得到的数据可以是不一致的。如下:
mysql> FLUSH TABLES WITH READ LOCK;
在另一个连接用mysqldump创建一个你想进行复制的数据库的转储:
shell> mysqldump --all-databases --lock-all-tables >dbdump.db
对表释放锁。
mysql> UNLOCK TABLES;
3、深入了解复制
已经讨论了关于复制的一些基本东西,下面深入讨论一下复制。
3.1、基于语句的复制(Statement-Based Replication)
MySQL 5.0及之前的版本仅支持基于语句的复制(也叫做逻辑复制,logical replication),这在数据库并不常见。master记录下改变数据的查询,然后,slave从中继日志中读取事件,并执行它,这些SQL语句与master执行的语句一样。
这种方式的优点就是实现简单。此外,基于语句的复制的二进制日志可以很好的进行压缩,而且日志的数据量也较小,占用带宽少——例如,一个更新GB的数据的查询仅需要几十个字节的二进制日志。而mysqlbinlog对于基于语句的日志处理十分方便。
但是,基于语句的复制并不是像它看起来那么简单,因为一些查询语句依赖于master的特定条件,例如,master与slave可能有不同的时间。所以,MySQL的二进制日志的格式不仅仅是查询语句,还包括一些元数据信息,例如,当前的时间戳。即使如此,还是有一些语句,比如,CURRENT USER函数,不能正确的进行复制。此外,存储过程和触发器也是一个问题。
另外一个问题就是基于语句的复制必须是串行化的。这要求大量特殊的代码,配置,例如InnoDB的next-key锁等。并不是所有的存储引擎都支持基于语句的复制。
3.2、基于记录的复制(Row-Based Replication)
MySQL增加基于记录的复制,在二进制日志中记录下实际数据的改变,这与其它一些DBMS的实现方式类似。这种方式有优点,也有缺点。优点就是可以对任何语句都能正确工作,一些语句的效率更高。主要的缺点就是二进制日志可能会很大,而且不直观,所以,你不能使用mysqlbinlog来查看二进制日志。
对于一些语句,基于记录的复制能够更有效的工作,如:
mysql> INSERT INTO summary_table(col1, col2, sum_col3) -> SELECT col1, col2, sum(col3) -> FROM enormous_table -> GROUP BY col1, col2;
假设,只有三种唯一的col1和col2的组合,但是,该查询会扫描原表的许多行,却仅返回三条记录。此时,基于记录的复制效率更高。
另一方面,下面的语句,基于语句的复制更有效:
mysql> UPDATE enormous_table SET col1 = 0;
此时使用基于记录的复制代价会非常高。由于两种方式不能对所有情况都能很好的处理,所以,MySQL 5.1支持在基于语句的复制和基于记录的复制之前动态交换。你可以通过设置session变量binlog_format来进行控制。
3.3、复制相关的文件
除了二进制日志和中继日志文件外,还有其它一些与复制相关的文件。如下:
(1)mysql-bin.index
서버가 바이너리 로그를 켜면 두 번째 로그 파일과 이름은 같지만 .index로 끝나는 파일을 생성합니다. 디스크에 존재하는 바이너리 로그 파일을 추적하는 데 사용됩니다. MySQL은 이를 사용하여 바이너리 로그 파일을 찾습니다. 내용은 다음과 같습니다. . 내용은 다음과 같습니다.
.mysql-02-relay-bin.000017 .mysql-02-relay-bin.000018
.mysql-02-relay-bin.000018
(3)master.info
마스터 관련 정보를 저장합니다. 삭제하지 마십시오. 그렇지 않으면 슬레이브를 다시 시작한 후 마스터에 연결할 수 없습니다. 내용은 다음과 같습니다(내 컴퓨터에서):
I/O 스레드는 master.info 파일을 업데이트하며, 내용은 다음과 같습니다(내 컴퓨터에서): 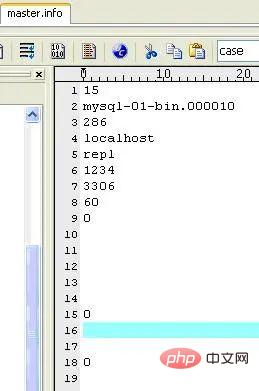
.mysql- 02-릴레이-빈.000019
|
286 0 52813
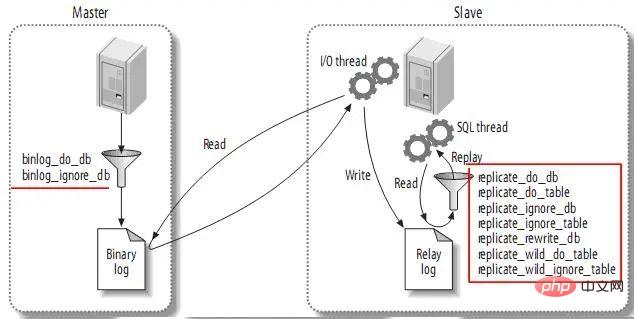
현재 바이너리 로그와 슬레이브의 릴레이 로그에 대한 정보를 담고 있습니다. 3.4. 다른 슬레이브에게 복제 이벤트 보내기 log_slave_updates를 설정할 때 슬레이브가 다른 슬레이브의 마스터 역할을 하도록 할 수 있습니다. 이때 슬레이브는 SQL 스레드에 의해 실행된 이벤트를 자신의 바이너리 로그(바이너리 로그)에 기록합니다. 그러면 슬레이브는 이러한 이벤트를 획득하여 실행할 수 있습니다. 다음과 같습니다: 3.5. 복제 필터복제 필터링을 사용하면 서버에 있는 데이터의 일부만 복사할 수 있습니다. 복제 필터에는 슬레이브의 바이너리 로그에 있는 이벤트 필터링이 있습니다. . 로그의 다음 이벤트.
4. 복제에 일반적으로 사용되는 토폴로지 복제 아키텍처에는 다음과 같은 기본 원칙이 있습니다. MySQL은 멀티마스터 복제(멀티마스터 복제)를 지원하지 않습니다. 즉, 슬레이브는 여러 마스터를 가질 수 있습니다. 그러나 몇 가지 간단한 조합을 통해 유연하고 강력한 복제 아키텍처를 구축할 수 있습니다.
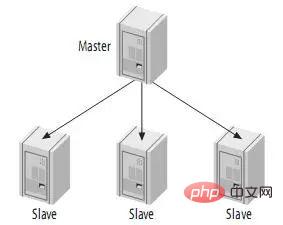
4.1. 단일 마스터와 다중 슬레이브하나의 마스터와 하나의 슬레이브로 구성된 복제 시스템이 가장 간단한 경우입니다. 슬레이브는 서로 통신하지 않고 마스터하고만 통신할 수 있습니다. 실제 애플리케이션 시나리오에서 MySQL 복제의 90% 이상이 하나의 마스터가 하나 이상의 슬레이브에 복제되는 아키텍처 패턴입니다. 읽기 부담이 높은 애플리케이션을 위한 데이터베이스 측의 저렴한 확장 솔루션으로 주로 사용됩니다. 마스터와 슬레이브에 대한 압력이 너무 크지 않은 한(특히 슬레이브 측에 대한 압력) 비동기 복제 지연은 일반적으로 매우 작습니다. 특히, Slave 측의 복제 방식을 Two Thread 처리로 변경하여 Slave 측의 지연 문제를 줄였습니다. 특히 중요한 데이터 실시간 요구 사항이 없는 애플리케이션의 경우 저렴한 pcserver를 통해 슬레이브 수를 늘리고 읽기 압력을 여러 슬레이브 시스템에 분산시키기만 하면 된다는 이점이 있습니다. 읽기 압력을 단일 데이터베이스 서버에 분산시킬 수 있습니다. 결국 대부분의 데이터베이스 애플리케이션 시스템의 읽기 압력은 쓰기 압력보다 훨씬 높습니다. 이를 통해 현재 많은 중소 규모 웹 사이트의 데이터베이스 압력 병목 현상 문제가 크게 해결되었으며 일부 대형 웹 사이트에서도 유사한 솔루션을 사용하여 데이터베이스 병목 현상을 해결하고 있습니다. 다음과 같습니다. 하나의 마스터 노드에서 여러 슬레이브 노드를 복사할 수 있다는 사실을 누구나 알아야 합니다. 어떤 사람들은 하나의 슬레이브 노드를 여러 마스터 노드에서 복사할 수 있습니까? 적어도 현재로서는 MySQL이 이를 할 수 없고, 향후 지원될지도 불분명하다. MySQL은 슬레이브 노드가 여러 마스터 노드에서 복제하는 아키텍처를 지원하지 않습니다. 이는 주로 충돌 문제를 방지하고 여러 데이터 소스 간의 데이터 충돌로 인해 최종 데이터의 불일치가 발생하는 것을 방지하기 위한 것입니다. 그러나 MySQL이 여러 마스터 노드에서 데이터 소스로 복제할 수 있는 슬레이브 노드를 지원할 수 있도록 누군가 관련 패치를 개발했다고 들었습니다. 이는 MySQL의 오픈 소스 특성이 가져오는 이점이기도 합니다.
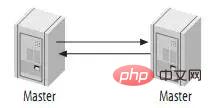
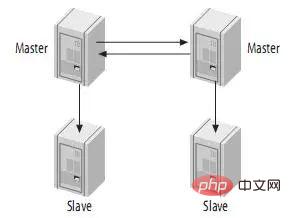
4.2.Active-Active 모드의 Master-Master(Active-Active 모드의 Master-Master)Master-Master에 의해 복제된 두 서버는 모두 다른 서버의 마스터이자 슬레이브입니다. 이러한 방식으로 한쪽 당사자의 변경 사항은 복제를 통해 상대방의 데이터베이스에 적용됩니다. 可能有些读者朋友会有一个担心,这样搭建复制环境之后,难道不会造成两台MySQL之间的循环复制么?实际上MySQL自己早就想到了这一点,所以在MySQL的BinaryLog中记录了当前MySQL的server-id,而且这个参数也是我们搭建MySQLReplication的时候必须明确指定,而且Master和Slave的server-id参数值比需要不一致才能使MySQLReplication搭建成功。一旦有了server-id的值之后,MySQL就很容易判断某个变更是从哪一个MySQLServer最初产生的,所以就很容易避免出现循环复制的情况。而且,如果我们不打开记录Slave的BinaryLog的选项(--log-slave-update)的时候,MySQL根本就不会记录复制过程中的变更到BinaryLog中,就更不用担心可能会出现循环复制的情形了。
如图:
主动的Master-Master复制有一些特殊的用处。例如,地理上分布的两个部分都需要自己的可写的数据副本。这种结构最大的问题就是更新冲突。假设一个表只有一行(一列)的数据,其值为1,如果两个服务器分别同时执行如下语句: mysql> UPDATE tbl SET col=col + 1; 로그인 후 복사 在第二个服务器上执行: mysql> UPDATE tbl SET col=col * 2; 로그인 후 복사 那么结果是多少呢?一台服务器是4,另一个服务器是3,但是,这并不会产生错误。
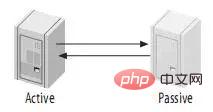
4.3、主动-被动模式的Master-Master(Master-Master in Active-Passive Mode) 这是master-master结构变化而来的,它避免了M-M的缺点,实际上,这是一种具有容错和高可用性的系统。它的不同点在于其中一个服务只能进行只读操作。如图:
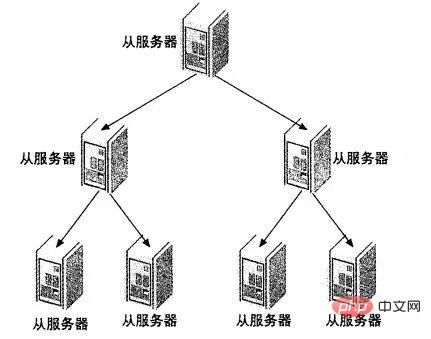
4.4 级联复制架构 Master –Slaves - Slaves 在有些应用场景中,可能读写压力差别比较大,读压力特别的大,一个Master可能需要上10台甚至更多的Slave才能够支撑注读的压力。这时候,Master就会比较吃力了,因为仅仅连上来的SlaveIO线程就比较多了,这样写的压力稍微大一点的时候,Master端因为复制就会消耗较多的资源,很容易造成复制的延时。 遇到这种情况如何解决呢?这时候我们就可以利用MySQL可以在Slave端记录复制所产生变更的BinaryLog信息的功能,也就是打开—log-slave-update选项。然后,通过二级(或者是更多级别)复制来减少Master端因为复制所带来的压力。也就是说,我们首先通过少数几台MySQL从Master来进行复制,这几台机器我们姑且称之为第一级Slave集群,然后其他的Slave再从第一级Slave集群来进行复制。从第一级Slave进行复制的Slave,我称之为第二级Slave集群。如果有需要,我们可以继续往下增加更多层次的复制。这样,我们很容易就控制了每一台MySQL上面所附属Slave的数量。这种架构我称之为Master-Slaves-Slaves架构 这种多层级联复制的架构,很容易就解决了Master端因为附属Slave太多而成为瓶颈的风险。下图展示了多层级联复制的Replication架构。
当然,如果条件允许,我更倾向于建议大家通过拆分成多个Replication集群来解决 上述瓶颈问题。毕竟Slave并没有减少写的量,所有Slave实际上仍然还是应用了所有的数据变更操作,没有减少任何写IO。相反,Slave越多,整个集群的写IO总量也就会越多,我们没有非常明显的感觉,仅仅只是因为分散到了多台机器上面,所以不是很容易表现出来。 此外,增加复制的级联层次,同一个变更传到最底层的Slave所需要经过的MySQL也会更多,同样可能造成延时较长的风险。 而如果我们通过分拆集群的方式来解决的话,可能就会要好很多了,当然,分拆集群也需要更复杂的技术和更复杂的应用系统架构。
4.5、带从服务器的Master-Master结构(Master-Master with Slaves) 这种结构的优点就是提供了冗余。在地理上分布的复制结构,它不存在单一节点故障问题,而且还可以将读密集型的请求放到slave上。 级联复制在一定程度上面确实解决了Master因为所附属的Slave过多而成为瓶颈的问题,但是他并不能解决人工维护和出现异常需要切换后可能存在重新搭建Replication的问题。这样就很自然的引申出了DualMaster与级联复制结合的Replication架构,我称之为Master-Master-Slaves架构 和Master-Slaves-Slaves架构相比,区别仅仅只是将第一级Slave集群换成了一台单独的Master,作为备用Master,然后再从这个备用的Master进行复制到一个Slave集群。 这种DualMaster与级联复制结合的架构,最大的好处就是既可以避免主Master的写入操作不会受到Slave集群的复制所带来的影响,同时主Master需要切换的时候也基本上不会出现重搭Replication的情况。但是,这个架构也有一个弊端,那就是备用的Master有可能成为瓶颈,因为如果后面的Slave集群比较大的话,备用Master可能会因为过多的SlaveIO线程请求而成为瓶颈。当然,该备用Master不提供任何的读服务的时候,瓶颈出现的可能性并不是特别高,如果出现瓶颈,也可以在备用Master后面再次进行级联复制,架设多层Slave集群。当然,级联复制的级别越多,Slave集群可能出现的数据延时也会更为明显,所以考虑使用多层级联复制之前,也需要评估数据延时对应用系统的影响。
5、复制的常见问题 错误一:change master导致的: 错误二:在没有解锁的情况下停止slave进程: mysql> stop slave; 로그인 후 복사 ERROR 1192 (HY000): Can't execute the given command because you have active locked tables or an active transaction
错误三:在没有停止slave进程的情况下change master mysql> change master to master_host=‘IP', master_user='USER', master_password='PASSWD', master_log_file='mysql-bin.000001',master_log_pos=106; 로그인 후 복사 ERROR 1198 (HY000): This operation cannot be performed with a running slave; run STOP SLAVE first
错误四:A B的server-id相同: 错误五:change master之后,查看slave的状态,发现slave_IO_running 仍为NO
错误六:MySQL主从同步异常Client requested master to start replication from position > file size 字面理解:从库的读取binlog的位置大于主库当前binglog的值 这一般是主库重启导致的问题,主库从参数sync_binlog默认为1000,即主库的数据是先缓存到1000条后统一fsync到磁盘的binlog文件中。
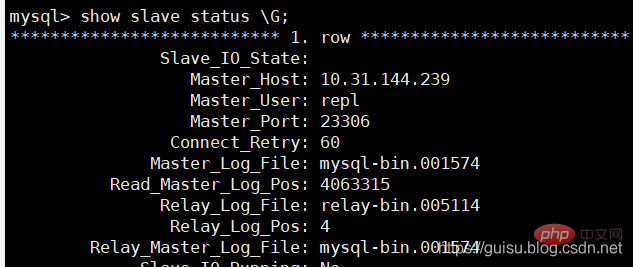
当主库重启的时候,从库直接读取主库接着之前的位点重新拉binlog,但是主库由于没有fsync最后的binlog,所以会返回1236 的错误。 1、在从库检查slave状态: 偏移量为4063315
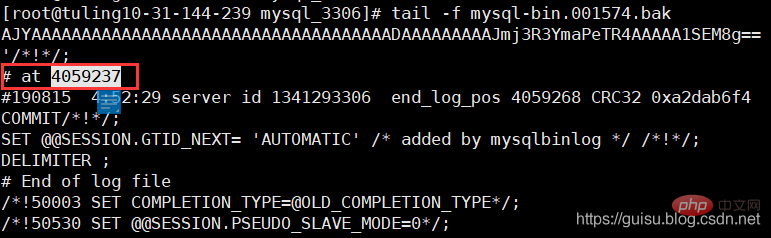
2、在主库检查mysql-bin.001574的偏移量位置 mysqlbinlog mysql-bin.001574 > ./mysql-bin.001574.bak tail -10 ./mysql-bin.001574.bak mysql-bin.001574文件最后几行 发现最后偏移量是4059237,从库偏移量的4063315远大主库的偏移量4059237,也就是参数sync_binlog=1000导致的。
3、重新设置salve mysql> stop slave;mysql> change master to master_log_file='mysql-bin.001574' ,master_log_pos=4059237;mysql> start slave; 로그인 후 복사 错误8:数据同步异常情况
第一种:在master上删除一条记录,而slave上找不到。 Last_Error: Could not execute Delete_rows event on table market_edu.tl_player_task; Can't find record in 'tl_player_task', Error_code: 1032; handler error HA_ERR_KEY_NOT_FOUND; the event's master log mysql-bin.002094, end_log_pos 286434186 解决方法:由于master要删除一条记录,而slave上找不到故报错,这种情况主上都将其删除了,那么从机可以直接跳过。 可用命令:stop slave; set global sql_slave_skip_counter=1; start slave; 第二种:主键重复。在slave已经有该记录,又在master上插入了同一条记录。 Last_SQL_Error: Could not execute Write_rows event on table hcy.t1; 解决方法:在slave删除重复的主键 第三种:在master上更新一条记录,而slave上找不到,丢失了数据。 Last_SQL_Error: Could not execute Update_rows event on table hcy.t1; 解决方法:把丢失的数据在slave上填补,然后跳过报错即可。 insert into t1 values (2,'BTV'); stop slave ;set global sql_slave_skip_counter=1;start slave;
|
위 내용은 고성능 MySQL 마스터-슬레이브 아키텍처의 복제 원리 및 구성에 대한 자세한 설명의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!



















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



