

MySQL Essence One: DQL 데이터 쿼리 문

추천 무료 학습: mysql 비디오 튜토리얼
목차
- 1. 기본 쿼리
- 2. 조건부 쿼리
- 3. 정렬 쿼리
- 4 . 공통 함수
- 5. 그룹 쿼리
- 6. 조인 쿼리
- 7. 서브 쿼리
- 8. 페이지네이션 쿼리
- 9. 유니온 쿼리
샘플 데이터 준비
쿼리문 실험 , 먼저 해당 데이터를 쿼리용 샘플로 준비합니다.
SQLyog를 사용하여 SQL 스크립트를 가져오면 준비된 샘플 테이블을 볼 수 있습니다. 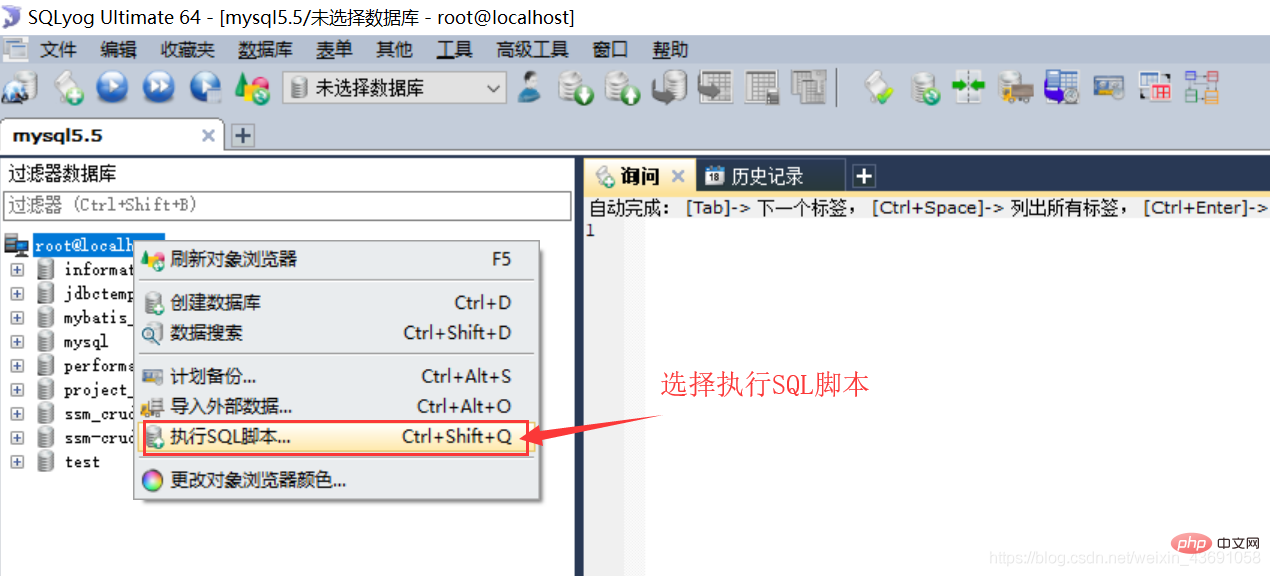
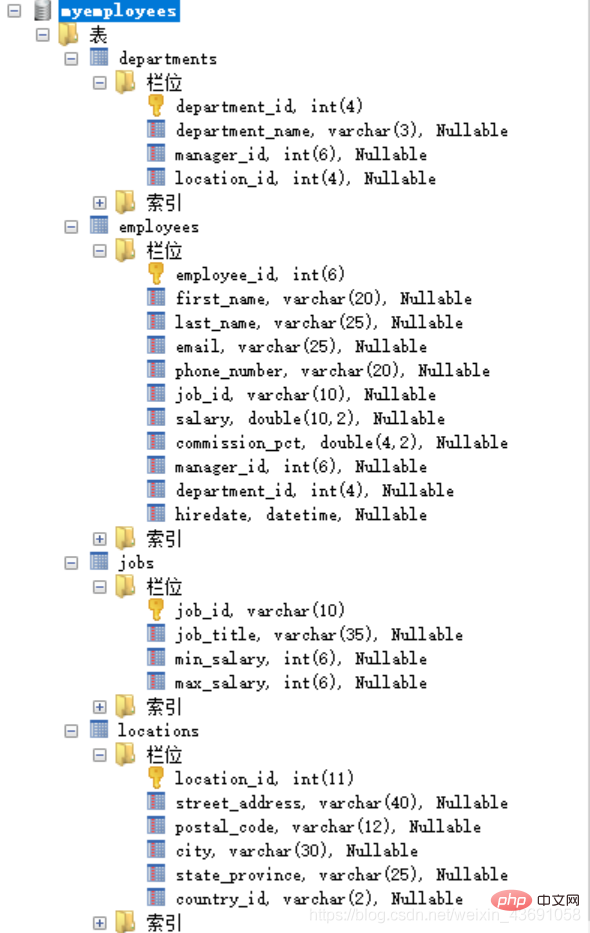
이 샘플은 아래 다국적 기업의 직원이 관리하는 4개의 테이블입니다. 그림은 각 테이블의 각 필드를 소개합니다: 
1. 기본 쿼리
구문: 테이블 이름에서 쿼리 목록 선택 select 查询列表 from 表名;
特点:
查询列表可以是:表中的字段、常量值、表达式、函数。
查询的结果是一个虚拟的表格。
执行顺序:from > select (先找到表,再开始查询)
注意:`是着重号,当某张表中的字段与关键字冲突时,可以在该字段两边加上着重号,以标明其是一个字段,而不是关键字(如`name`)。
【基础查询】# 选中样本库USER myemployees;# 1.查询表中的单个字段SELECT last_name FROM employees;# 2.查询表中的多个字段SELECT last_name,salary,email FROM employees;# 3.查询表中所有的字段SELECT * FROM employees;# 4. 查询常量值SELECT 'Tom';# 5.查询表达式SELECT 7%6;# 6. 查询函数SELECT VERSION();# 7.起别名(mysql中建议将起别名使用双引号引起来"别名")/* 优点:便于理解;连接查询时,如果要查询的字段有重名情况,可以使用起别名来区分 */# 方式一,使用asSELECT 7%6 AS 结果;SELECT last_name AS 姓,first_name AS 名 FROM employees;# 方式二,使用空格SELECT 7%6 结果;SELECT last_name 姓,first_name 名 FROM employees;# 查询员工号为176的员工的姓名、部门、nianxinSELECT last_name,department_id,salary*12*(1+IFNULL(commission_pct,0)) AS 年薪 FROM employees; # 8.去重SELECT DISTINCT department_id FROM employees;# 9.+号的作用/* select 13+21; 两个操作数都是数值型,自动做加法运算 其中一个为字符型,则将字符型转换为数值型 select '13'+1; 转换成功,做加法运算 select 'hello'+1; 转换失败,将字符型转换为0 select null+10; 只要其中一方为null,结果就为null 补充ifnull函数:SELECT IFNULL(commission_pct,0) AS 奖金率,commission_pct FROM employees; mysql中用来拼接的不是+号,而是concat函数 */SELECT CONCAT(last_name,first_name) AS "姓名" FROM employees;
| 基础查询总结 | 说明 |
|---|---|
| 1.查询表中的单个字段 | select 字段1 from 表; |
| 2.查询表中的多个字段 | select 字段1,字段2,...字段n from 表; |
| 3.查询表中的所有字段 | select * from 表; |
| 4.查询常量值 | select '常量值;' |
| 5.查询表达式 | select 数值1 表达式 数值2; |
| 6.查询函数 | select f(); |
| 7.起别名 | as |
| 8.去重 | distinct |
| 9.拼接使用concat函数,而不是"+" | concat(last_name,first_name) |
学完了基础查询,尝试完成下面的练习题
答案:
1.正确
2.正确
3.应在英文状态下使用引号
4.DESC departments;;SELECT * FROM departments;
5.SELECT CONCAT(first_name,',',last_name,',',IFNULL(email,0)) AS "out_put" FROM employees;

二、条件查询
语法:select 查询列表 from 表名 where 筛选条件;
执行顺序:from > where > select (先定位到表,然后开始筛选,最后走查询)
分类:
(1)按条件运算符筛选
条件运算符有: > = )
(2)按逻辑表达式筛选
支持&& || !,但推荐使用and or not 逻辑表达式作用:用于连接条件表达式 &&或and: 两个都为true,结果为true,反之为false ||或or : 只要有一个条件为true,结果即为true,反之为false !或not : 取反
(3)模糊查询
模糊查关键字:like、between and、in、is null (1)like关键字 可以判断字符型或数值型 like一般和通配符搭配使用,通配符有 %:代表任意多个字符,包含0个 _:代表任意单个字符 (2)between...and关键字 可以提高语句简洁度 包含临界值 两个临界值不能调换顺序 (3)in关键字 可以提高语句简洁度 in列表的值类型必须一致 (4)is null 取反是 is not null
【条件查询】(1)按条件运算符筛选# 1.查询工资>12000的员工SELECT * FROM employees WHERE salary > 12000 ;# 2.查询部门编号不等于90的员工名和部门编号SELECT department_name, department_id FROM departments WHERE department_id90;---------------------------------------------------------------------------------------------------------------------(2)按逻辑表达式筛选# 1.查询工资在10000到20000之间的员工名、工资以及奖金率SELECT last_name,salary,commission_pct FROM employees WHERE salary>=10000 AND salary=90 AND department_id15000;---------------------------------------------------------------------------------------------------------------------(3)模糊查询# (1)like关键字# 1.查询员工名中包含字符a的员工的信息SELECT * FROM employees WHERE last_name LIKE '%a%';# 2.查询员工名中第三个字符为n,第五个字符为l的员工名和工资SELECT last_name,salary FROM employees WHERE last_name LIKE '__n_l%';# 3.查询员工名中第二个字符为_的员工名(转义)SELECT last_name FROM employees WHERE last_name LIKE '_$_%' ESCAPE '$';# (2)between...and关键字# 1.查询员工编号在100到120的员工信息SELECT * FROM employees WHERE employee_id BETWEEN 100 AND 120;# (3)in关键字# 1.查询员工的工种编号是IT_PROG、AD_VP、AD_PRES中的员工名和工种编号SELECT last_name,job_id FROM employees WHERE job_id IN('IT_PROG','AD_VP','AD_PRES');# (4)is null# 1.查询没有奖金的员工名和奖金率SELECT last_name,commission_pct FROM employees WHERE commission_pct IS NULL;# is null仅仅可以用来判断null值;安全等于既可以用来判断null值,又可以用来判断普通值# is null的可读性高于,建议使用is nullSELECT last_name,commission_pct FROM employees WHERE commission_pct NULL;| 条件查询总结 | 说明 |
|---|---|
| (1)按条件运算符筛选 | > = ) |
| (2)按逻辑表达式筛选 | && || !或and or not |
| (3)模糊查询 | 关键字:like、between...and、in、is null | 특징:
from > select(먼저 테이블을 찾은 다음 쿼리 시작)🎜【排序查询】# 1.查询员工信息,要求工资从高到低排序SELECT * FROM employees ORDER BY salary DESC;# 2.查询部门编号>=90的员工信息,按入职时间的先后进行排序【添加筛选条件】SELECT * FROM employees WHERE department_id>=90 ORDER BY hiredate ASC;# 3.按照年薪的高低显示员工的信息和年薪【添加表达式排序】SELECT * ,salary*12*(1+IFNULL(commission_pct,0)) AS 年薪 FROM employees ORDER BY salary*12*(1+IFNULL(commission_pct,0)) DESC;SELECT * ,salary*12*(1+IFNULL(commission_pct,0)) AS 年薪 FROM employees ORDER BY 年薪 DESC; # ORDER BY后支持别名# 4.按照姓名的长度,显示员工的姓名和工资【按函数排序】SELECT LENGTH(last_name) AS 字节长度, last_name,salary FROM employees ORDER BY 字节长度 DESC;# 5.查询员工信息,先按工资升序,再按员工编号降序SELECT * FROM employees ORDER BY salary ASC ,employee_id DESC;
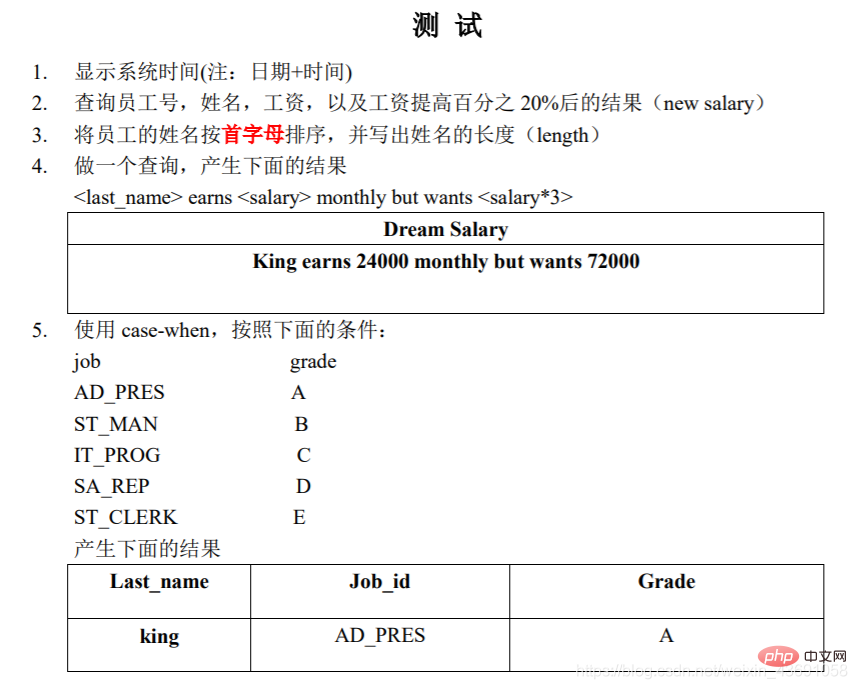
【单行函数】# (1)字符函数-[参数类型为字符型]# 1.length 获取参数值的字节个数SELECT LENGTH('john');SELECT LENGTH('张三丰');SHOW VARIABLES LIKE '%char%' # 查看字符集# 2.concat拼接字符串SELECT CONCAT(last_name,'_',first_name) 姓名 from employees;# 3.upper、lower 大小写转换SELECT UPPER('tom');SELECT LOWER('TOM')# 将姓变大写,名变小写,然后拼接SELECT CONCAT(UPPER(last_name),LOWER(first_name))姓名 FROM employees;# 4.substr 拼接函数# mysql中的索引从1开始SELECT SUBSTR('若负平生意,何名作莫愁',7) AS out_put;SELECT SUBSTR('若负平生意,何名作莫愁',1,3) AS out_put;# 案例:姓名中首字符大写,其他字符小写,用_拼接并显示出来SELECT CONCAT(UPPER(SUBSTR(last_name,1,1)),'_',LOWER(SUBSTR(last_name,2))) oup_put FROM employees; # 5.instr 字符查找函数# 返回子串在主串中的起始索引,没有返回零SELECT INSTR('凡尘阿凉','阿凉') AS out_put;# 6.trim 清除空格函数# 将字符两边的空格移除SELECT LENGTH(TRIM(' 凡尘 ')) AS out_put;SELECT TRIM('a' FROM 'aaaaaa凡aaa尘aaaa') AS out_put;# 7.lpad 左填充函数# 用指定的字符实现左填充指定长度SELECT LPAD('凡尘',10,'*') AS out_put;# 8.rpad 右填充函数# 用指定的字符实现右填充指定长度SELECT RPAD('凡尘',10,'*') AS out_put;# 9.replace 替换函数SELECT REPLACE('我的偶像是鲁迅','鲁迅','周冬雨') AS oup_put;---------------------------------------------------------------------------------------------------------# (2)数学函数-[参数类型为数值]# 1.round 四舍五入函数SELECT ROUND(1.65);SELECT ROUND(1.567,2);# 2.ceil 向上取整函数# 返回>=该参数的最小整数SELECT CEIL(1.00);# 3.floor 向下取整函数# 返回5,'大于','小于');SELECT last_name,commission_pct, IF(commission_pct IS NULL,'没奖金','有奖金') AS out_put FROM employees;# 2.MySQL Essence One: DQL 데이터 쿼리 문函数/*
方式一:类似于Java中的switch-MySQL Essence One: DQL 데이터 쿼리 문:
案例:查询员工工资,要求
部门号=30,显示的工资为1.1倍
部门号=40,显示的工资为1.2倍
部门号=50,显示的工资为1.3倍
其他部门,显示的工资为原工资
*/SELECT salary 原始工资,department_id,CASE department_idWHEN 30 THEN salary*1.1WHEN 40 THEN salary*1.2WHEN 50 THEN salary*1.3ELSE salaryEND AS 新工资FROM employees;/*
方式二:类似于Java中的多重if:
案例:查询员工的工资情况
工资>20000,显示A级别
工资>15000,显示B级别
工资>10000,显示C级别
否则,显示D级别
*/SELECT salary,CASEWHEN salary>20000 THEN 'A'WHEN salary>15000 THEN 'B'WHEN salary>10000 THEN 'C'ELSE 'D'END AS 工资级别FROM employees;| 기본 쿼리 요약 | 지침 | 🎜|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 🎜1. 테이블의 단일 필드를 쿼리합니다🎜🎜 | 테이블에서 필드 1을 선택합니다. 🎜🎜<tr>
<td>🎜2. 테이블의 여러 필드를 쿼리합니다🎜🎜</td>
<td>
<code>테이블에서 필드 1, 필드 2,...필드 n을 선택합니다.🎜🎜 |
🎜3. 테이블의 모든 필드를 쿼리합니다🎜🎜 |
테이블에서 *를 선택합니다.🎜🎜 |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
🎜4. 상수 값을 쿼리합니다. '상수 값 선택'🎜🎜 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 🎜5. 쿼리 표현식🎜🎜 |
값 1 표현식 값 2 선택;🎜🎜 |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 🎜6. 쿼리 기능 🎜🎜 |
f() 선택;🎜🎜 |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 🎜7. 별칭 🎜🎜 | as code >🎜🎜<tr>
<td>🎜8. 중복 제거🎜🎜</td>
<td>
<code>고유🎜🎜 |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
🎜9. "+" 대신 연결 기능을 사용하세요🎜🎜 concat(last_name,first_name)🎜🎜🎜🎜🎜🎜기본 쿼리를 학습한 후 다음 연습을 완료해 보세요🎜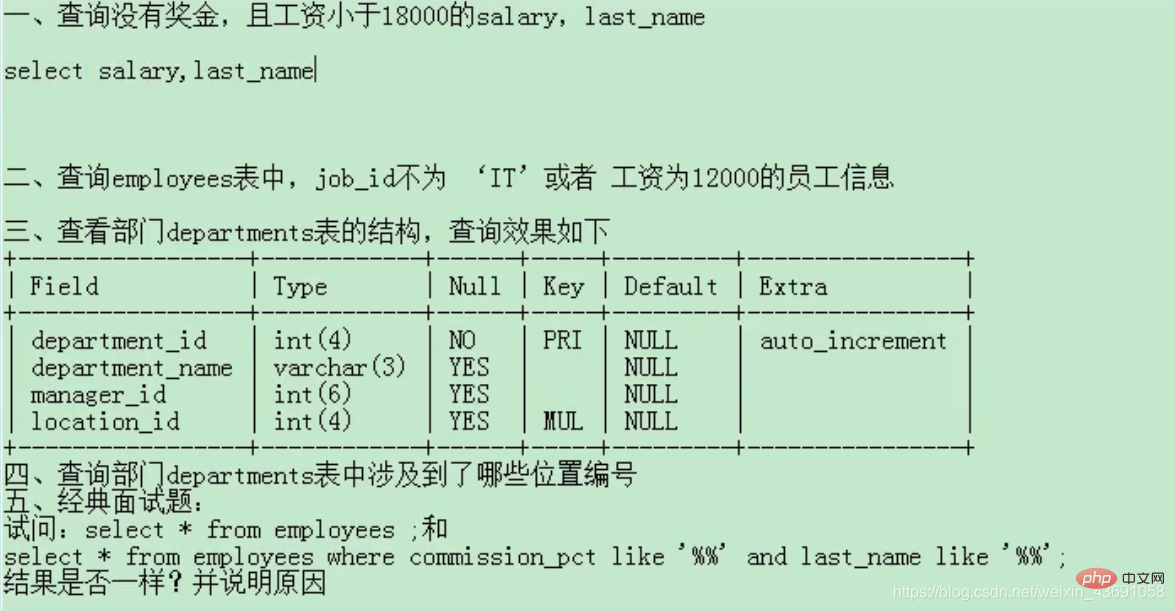 🎜🎜답변: 🎜 1. 🎜🎜답변: 🎜 1.올바름🎜 2.올바름 code >🎜 3.<code>따옴표는 영어로 사용해야 합니다.🎜 4.DESC Departments;;SELECT * FROM Departments;🎜 5. SELECT CONCAT(first_name,',',last_name,',',IFNULL(email,0)) AS "out_put" FROM 직원;🎜🎜🎜🎜🎜2. 조건부 쿼리🎜🎜🎜 구문: 필터 조건이 있는 테이블 이름에서 쿼리 목록 선택;🎜🎜실행 순서: from > 선택(먼저 테이블을 찾은 다음 필터링을 시작한 다음 마지막으로 쿼리)🎜🎜 :🎜🎜(1) 조건부 연산자로 필터링🎜【分组函数】/* SUM 求和 AVG 平均值 MAX 最大值 MIN 最小值 COUNT 计算个数 */# 综合使用SELECT SUM(salary) "和",AVG(salary) "平均数",MAX(salary) "最大值",MIN(salary) "最小值",COUNT(salary) "总个数" FROM employees;/* 分组函数的特点: 1.sum、avg一般用于处理数值型;max、min、count可以处理任何类型 2.分组函数都忽略null值,都可以和distinct搭配去重 3.和分组函数一同查询的字段要求是group by后的字段 4.count函数经常用来统计行数,使用count(*)或count(1)或count(常量) 效率问题: MYISAM存储引擎下,count(*)效率高 INNODB存储引擎下,count(*)和count(1)效率差不多,但比count(字段)要高 */ 로그인 후 복사 로그인 후 복사 # 1.查询每个工种的最高工资SELECT MAX(salary) "最高工资",job_id "工种" FROM employees GROUP BY job_id;# 2.查询每个位置上的部门个数SELECT COUNT(*) "部门个数",location_id "位置id" FROM departments GROUP BY location_id;# 3.查询邮箱中包含a字符的,每个部门的平均工资SELECT AVG(salary) "平均工资",department_id "部门id" FROM employees WHERE email LIKE '%a%' GROUP BY department_id;# 4.查询每个领导手下的有奖金的员工的最高工资SELECT MAX(salary) "最高工资",manager_id "领导编号" FROM employees WHERE NOT ISNULL(commission_pct) GROUP BY manager_id;# 5.查询哪个部门的员工个数>2# 思路:查询每个部门的个数,再根据结果哪个部门的员工个数>2SELECT COUNT(*),department_id FROM employees GROUP BY department_id HAVING COUNT(*)>2;# 6.查询每个工种有奖金的员工的最高工资>12000的工种编号和最高工资SELECT MAX(salary) "最高工资",job_id "工种" FROM employees WHERE NOT ISNULL(commission_pct) GROUP BY job_id HAVING MAX(salary)>12000;# 7.查询领导编号>102的每个领导手下员工的最低工资>5000的领导编号是哪个,以及其最低工资SELECT MIN(salary) "最低工资",manager_id "领导编号" FROM employees WHERE manager_id>102 GROUP BY manager_id HAVING MIN(salary)>5000;# 8.按员工姓名的长度分组,查询每一组的员工个数,筛选员工个数>5的有哪些SELECT COUNT(*) "员工个数",LENGTH(last_name) "姓名长度" FROM employees GROUP BY LENGTH (last_name) HAVING COUNT(*)>5;# 9.查询每个部门每个工种的员工的平均工资SELECT AVG(salary) "平均工资",department_id "部门",job_id "工种" FROM employees GROUP BY department_id,job_id; # 10.查询每个部门每个工种的员工的平均工资,并按平均工资的高低显示SELECT AVG(salary) "平均工资",department_id "部门",job_id "工种" FROM employees GROUP BY department_id,job_id ORDER BY AVG(salary) DESC; 로그인 후 복사 로그인 후 복사 【sql92标准】# 1.等值连接# 查询女神名和对应的男朋友名# SELECT NAME,boyName FROM boys,beauty WHERE beauty.boyfriend_id=boys.id;# 1.查询员工名和对应的部门名SELECT last_name "员工名",department_name "部门名" FROM employees,departments
WHERE employees.department_id=departments.department_id;# 2.查询员工名、工种号、工种名SELECT last_name,e.job_id,job_title FROM employees e,jobs j WHERE e.`job_id`=j.`job_id`;# 3.查询有奖金的员工名、部门名SELECT last_name,department_name,commission_pct FROM employees e,departments d
WHERE e.`department_id`=d.`department_id` AND e.`commission_pct` IS NOT NULL;# 等值连接+筛选# 4.查询城市中第二个字符为o的部门名和城市名SELECT department_name "部门名",city "城市名" FROM departments d,locations l
WHERE d.`location_id`=l.`location_id` AND city LIKE '_o%'; # 等值连接+分组# 5.查询每个城市的部门个数SELECT COUNT(*) "部门个数",city "城市" FROM departments d,locations l
WHERE d.`location_id`=l.`location_id` GROUP BY city;# 6.查询有奖金的每个部门的部门名、部门的领导编号、该部门最低工资SELECT department_name,d.manager_id,MIN(salary) FROM departments d,employees e
WHERE d.`department_id`=e.`department_id` AND commission_pct IS NOT NULL GROUP BY department_name,d.manager_id;# 7.查询每个工种的工种名、员工的个数并按员工的个数降序SELECT job_title,COUNT(*) FROM employees e,jobs j WHERE e.`job_id`=j.`job_id` GOUP BY job_title ORDER BY COUNT(*) DESC;# 8.支持三表连接# 查询员工名、部门名、所在的城市SELECT last_name,department_name,city FROM employees e,departments d,locations l
WHERE e.`department_id`=d.`department_id` AND d.`location_id`=l.`location_id`;# (2)非等值连接/*
先执行下面的语句,在myemployees数据库中创建新的job_grades表。
CREATE TABLE job_grades
(grade_level VARCHAR(3),
lowest_sal INT,
highest_sal INT);
INSERT INTO job_grades
VALUES ('A', 1000, 2999);
INSERT INTO job_grades
VALUES ('B', 3000, 5999);
INSERT INTO job_grades
VALUES('C', 6000, 9999);
INSERT INTO job_grades
VALUES('D', 10000, 14999);
INSERT INTO job_grades
VALUES('E', 15000, 24999);
INSERT INTO job_grades
VALUES('F', 25000, 40000);
*/# 1.查询员工的工资和工资级别SELECT salary,grade_level FROM employees e,job_grades j WHERE salary BETWEEN j.`lowest_sal` AND j.`highest_sal`;# (3)自连接# 1.查询员工名和其上级的名称.SELECT e.employee_id "员工id",e.last_name "员工姓名",m.employee_id "经理id",m.last_name "经理姓名" FROM employees e,employees m WHERE e.`manager_id`=m.`employee_id`;로그인 후 복사 로그인 후 복사 【sql99标准】# (1)等值连接# 1.查询员工名,部门名SELECT last_name,department_name FROM employees eINNER JOIN departments dON e.department_id=d.department_id;# 2.查询名字中包含e的员工名和工种名(添加筛选)SELECT last_name,job_titleFROM employees eINNER JOIN jobs jON e.job_id=j.job_idWHERE last_name LIKE '%e%' OR job_title LIKE '%e%';# 3.查询部门个数>3的城市名和部门个数(分组+筛选)SELECT city,COUNT(*) "部门个数"FROM departments dINNER JOIN locations lON d.location_id=l.location_idGROUP BY cityHAVING COUNT(*)>3;# 4.查询哪个部门的部门员工个数>3的部门名和员工个数,并按个数降序(排序)SELECT department_name "部门名",COUNT(*) "员工个数"FROM departments dINNER JOIN employees eON d.department_id=e.department_idGROUP BY department_nameHAVING COUNT(*)>3ORDER BY COUNT(*) DESC;# 5.查询员工名、部门名、工种名、并按部门名排序SELECT last_name "员工名",department_name "部门名",job_title "工种名"FROM employees eINNER JOIN departments d ON d.department_id=e.department_idINNER JOIN jobs j ON e.job_id=j.job_idORDER BY department_name ;# (2)非等值连接# 查询员工工资级别SELECT salary,grade_levelFROM employees eJOIN job_grades j ON e.`salary` BETWEEN j.lowest_sal AND j.highest_sal;# 查询每个工资级别的个数>20的个数,并且按照工资级别降序排列SELECT COUNT(*),grade_levelFROM employees eJOIN job_grades j ON e.`salary` BETWEEN j.lowest_sal AND j.highest_salGROUP BY grade_levelHAVING COUNT(*)>20ORDER BY grade_level DESC;# (3)自连接# 查询员工的名字、上级的名字SELECT e1.last_name "员工名",e2.last_name "上级名"FROM employees e1JOIN employees e2 ON e1.manager_id=e2.employee_id;--------------------------------------------------------------------------------------------------------------# 二、外连接# 1.查询男朋友不在男神表的女神名# 左外连接SELECT NAME FROM beauty LEFT OUTER JOIN boys ON beauty.boyfriend_id=boys.idWHERE boys.id IS NULL;# 右外连接SELECT NAMEFROM boys RIGHT OUTER JOIN beauty ON beauty.boyfriend_id=boys.idWHERE boys.id IS NULL;# 2.查询没有员工的部门SELECT d.department_name,e.employee_idFROM departments d LEFT JOIN employees e ON d.department_id=e.department_idWHERE e.manager_id IS NULL;SELECT * FROM employees WHERE employee_id=100;# 3.全外连接(不支持)# 全外连接就是就并集USE girls;SELECT b.*,bo.*FROM beauty bFULL JOIN boys boON b.boyfriend_id=bo.id;# 三.交叉连接# 使用99标准实现的笛卡尔乘积,使用cross代替了92中的,SELECT b.*,bo.*FROM beauty bCROSS JOIN boys bo 로그인 후 복사 로그인 후 복사
|



 🎜🎜🎜🎜
🎜🎜🎜🎜






위 내용은 MySQL Essence One: DQL 데이터 쿼리 문의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7536
7536
 15
1379
52
82
11
55
19
21
86
15
1379
52
82
11
55
19
21
86

 MySQL : 쉽게 학습하기위한 간단한 개념
Apr 10, 2025 am 09:29 AM
MySQL : 쉽게 학습하기위한 간단한 개념
Apr 10, 2025 am 09:29 AM
MySQL은 오픈 소스 관계형 데이터베이스 관리 시스템입니다. 1) 데이터베이스 및 테이블 작성 : CreateAbase 및 CreateTable 명령을 사용하십시오. 2) 기본 작업 : 삽입, 업데이트, 삭제 및 선택. 3) 고급 운영 : 가입, 하위 쿼리 및 거래 처리. 4) 디버깅 기술 : 확인, 데이터 유형 및 권한을 확인하십시오. 5) 최적화 제안 : 인덱스 사용, 선택을 피하고 거래를 사용하십시오.
 phpmyadmin을 여는 방법
Apr 10, 2025 pm 10:51 PM
phpmyadmin을 여는 방법
Apr 10, 2025 pm 10:51 PM
다음 단계를 통해 phpmyadmin을 열 수 있습니다. 1. 웹 사이트 제어판에 로그인; 2. phpmyadmin 아이콘을 찾고 클릭하십시오. 3. MySQL 자격 증명을 입력하십시오. 4. "로그인"을 클릭하십시오.
 Navicat Premium을 만드는 방법
Apr 09, 2025 am 07:09 AM
Navicat Premium을 만드는 방법
Apr 09, 2025 am 07:09 AM
Navicat Premium을 사용하여 데이터베이스 생성 : 데이터베이스 서버에 연결하고 연결 매개 변수를 입력하십시오. 서버를 마우스 오른쪽 버튼으로 클릭하고 데이터베이스 생성을 선택하십시오. 새 데이터베이스의 이름과 지정된 문자 세트 및 Collation의 이름을 입력하십시오. 새 데이터베이스에 연결하고 객체 브라우저에서 테이블을 만듭니다. 테이블을 마우스 오른쪽 버튼으로 클릭하고 데이터 삽입을 선택하여 데이터를 삽입하십시오.
 MySQL : 세계에서 가장 인기있는 데이터베이스 소개
Apr 12, 2025 am 12:18 AM
MySQL : 세계에서 가장 인기있는 데이터베이스 소개
Apr 12, 2025 am 12:18 AM
MySQL은 오픈 소스 관계형 데이터베이스 관리 시스템으로, 주로 데이터를 신속하고 안정적으로 저장하고 검색하는 데 사용됩니다. 작업 원칙에는 클라이언트 요청, 쿼리 해상도, 쿼리 실행 및 반환 결과가 포함됩니다. 사용의 예로는 테이블 작성, 데이터 삽입 및 쿼리 및 조인 작업과 같은 고급 기능이 포함됩니다. 일반적인 오류에는 SQL 구문, 데이터 유형 및 권한이 포함되며 최적화 제안에는 인덱스 사용, 최적화 된 쿼리 및 테이블 분할이 포함됩니다.
 MySQL을 사용하는 이유는 무엇입니까? 혜택과 장점
Apr 12, 2025 am 12:17 AM
MySQL을 사용하는 이유는 무엇입니까? 혜택과 장점
Apr 12, 2025 am 12:17 AM
MySQL은 성능, 신뢰성, 사용 편의성 및 커뮤니티 지원을 위해 선택됩니다. 1.MYSQL은 효율적인 데이터 저장 및 검색 기능을 제공하여 여러 데이터 유형 및 고급 쿼리 작업을 지원합니다. 2. 고객-서버 아키텍처 및 다중 스토리지 엔진을 채택하여 트랜잭션 및 쿼리 최적화를 지원합니다. 3. 사용하기 쉽고 다양한 운영 체제 및 프로그래밍 언어를 지원합니다. 4. 강력한 지역 사회 지원을 받고 풍부한 자원과 솔루션을 제공합니다.
 Navicat에서 MySQL에 새로운 연결을 만드는 방법
Apr 09, 2025 am 07:21 AM
Navicat에서 MySQL에 새로운 연결을 만드는 방법
Apr 09, 2025 am 07:21 AM
응용 프로그램을 열고 새로운 연결 (Ctrl n)을 선택하여 Navicat에서 새로운 MySQL 연결을 만들 수 있습니다. "MySQL"을 연결 유형으로 선택하십시오. 호스트 이름/IP 주소, 포트, 사용자 이름 및 비밀번호를 입력하십시오. (선택 사항) 고급 옵션을 구성합니다. 연결을 저장하고 연결 이름을 입력하십시오.
 단일 스레드 레 디스를 사용하는 방법
Apr 10, 2025 pm 07:12 PM
단일 스레드 레 디스를 사용하는 방법
Apr 10, 2025 pm 07:12 PM
Redis는 단일 스레드 아키텍처를 사용하여 고성능, 단순성 및 일관성을 제공합니다. 동시성을 향상시키기 위해 I/O 멀티플렉싱, 이벤트 루프, 비 블로킹 I/O 및 공유 메모리를 사용하지만 동시성 제한 제한, 단일 고장 지점 및 쓰기 집약적 인 워크로드에 부적합한 제한이 있습니다.
 MySQL 및 SQL : 개발자를위한 필수 기술
Apr 10, 2025 am 09:30 AM
MySQL 및 SQL : 개발자를위한 필수 기술
Apr 10, 2025 am 09:30 AM
MySQL 및 SQL은 개발자에게 필수적인 기술입니다. 1.MySQL은 오픈 소스 관계형 데이터베이스 관리 시스템이며 SQL은 데이터베이스를 관리하고 작동하는 데 사용되는 표준 언어입니다. 2.MYSQL은 효율적인 데이터 저장 및 검색 기능을 통해 여러 스토리지 엔진을 지원하며 SQL은 간단한 문을 통해 복잡한 데이터 작업을 완료합니다. 3. 사용의 예에는 기본 쿼리 및 조건 별 필터링 및 정렬과 같은 고급 쿼리가 포함됩니다. 4. 일반적인 오류에는 구문 오류 및 성능 문제가 포함되며 SQL 문을 확인하고 설명 명령을 사용하여 최적화 할 수 있습니다. 5. 성능 최적화 기술에는 인덱스 사용, 전체 테이블 스캔 피하기, 조인 작업 최적화 및 코드 가독성 향상이 포함됩니다.
