

기사 디렉토리
(무료 학습 권장 사항: python 비디오 튜토리얼 )
1. 머리말
크롤링을 많이 했어요 of static before 웹페이지의 내용에는 소설, 사진 등이 포함됩니다. 오늘은 동적 웹페이지를 크롤링해 보겠습니다. 우리 모두 알고 있듯이 Baidu Pictures는 동적 웹페이지입니다. 그럼 서두르세요! 서두르다! ! 서두르다! ! !
2. 임포트가 필요한 라이브러리
import requestsimport jsonimport os
3. 구현 과정
먼저 바이두를 열고 검색해 보세요(). 자신)—— Eddie Peng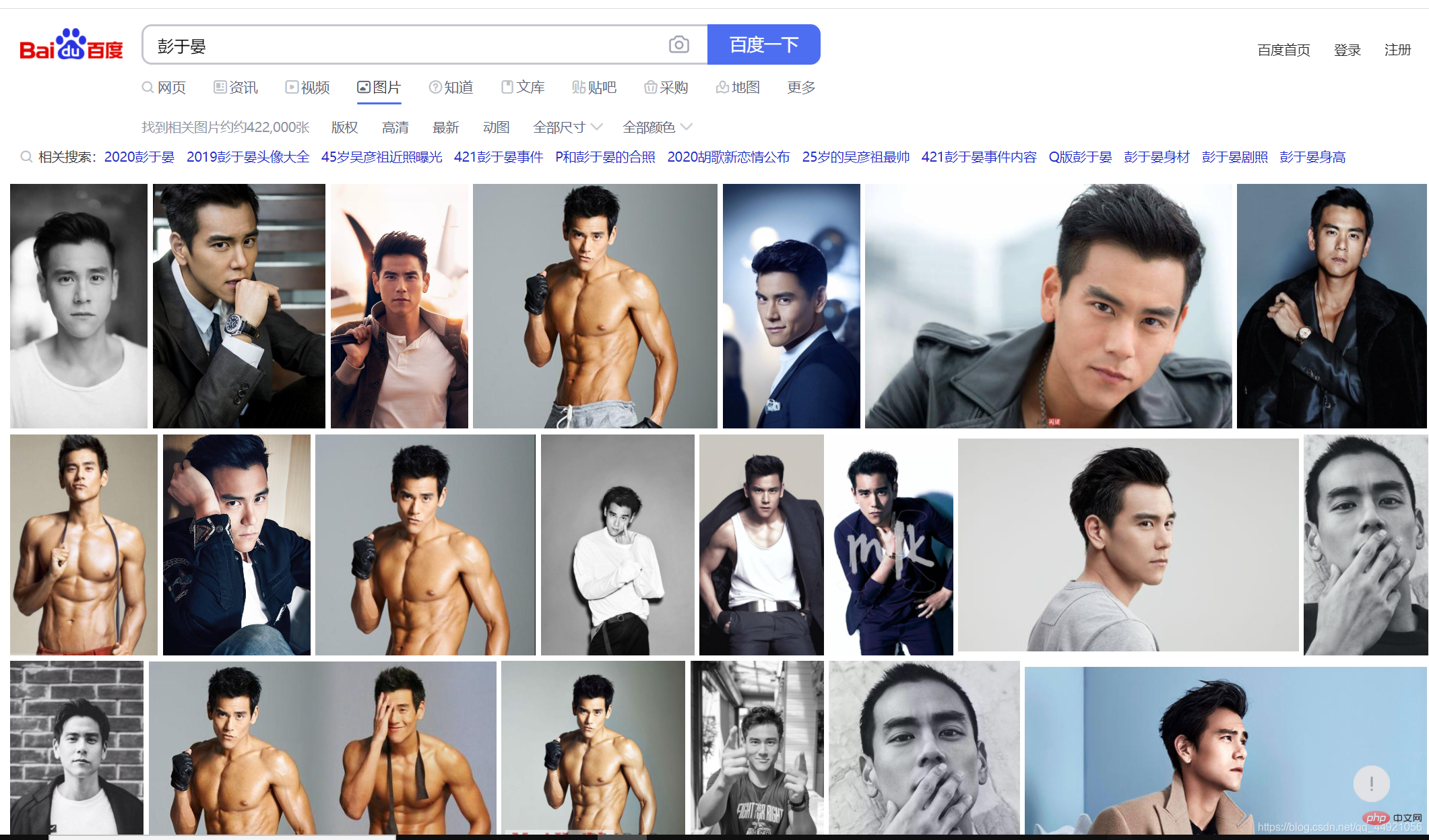
그런 다음 패킷 캡처 도구를 열고 XHR 옵션을 선택한 다음 Ctrl+R을 누르면 마우스가 슬라이드되면서 데이터 패킷이 하나씩 하나씩 발견됩니다. 오른쪽에 나타납니다. 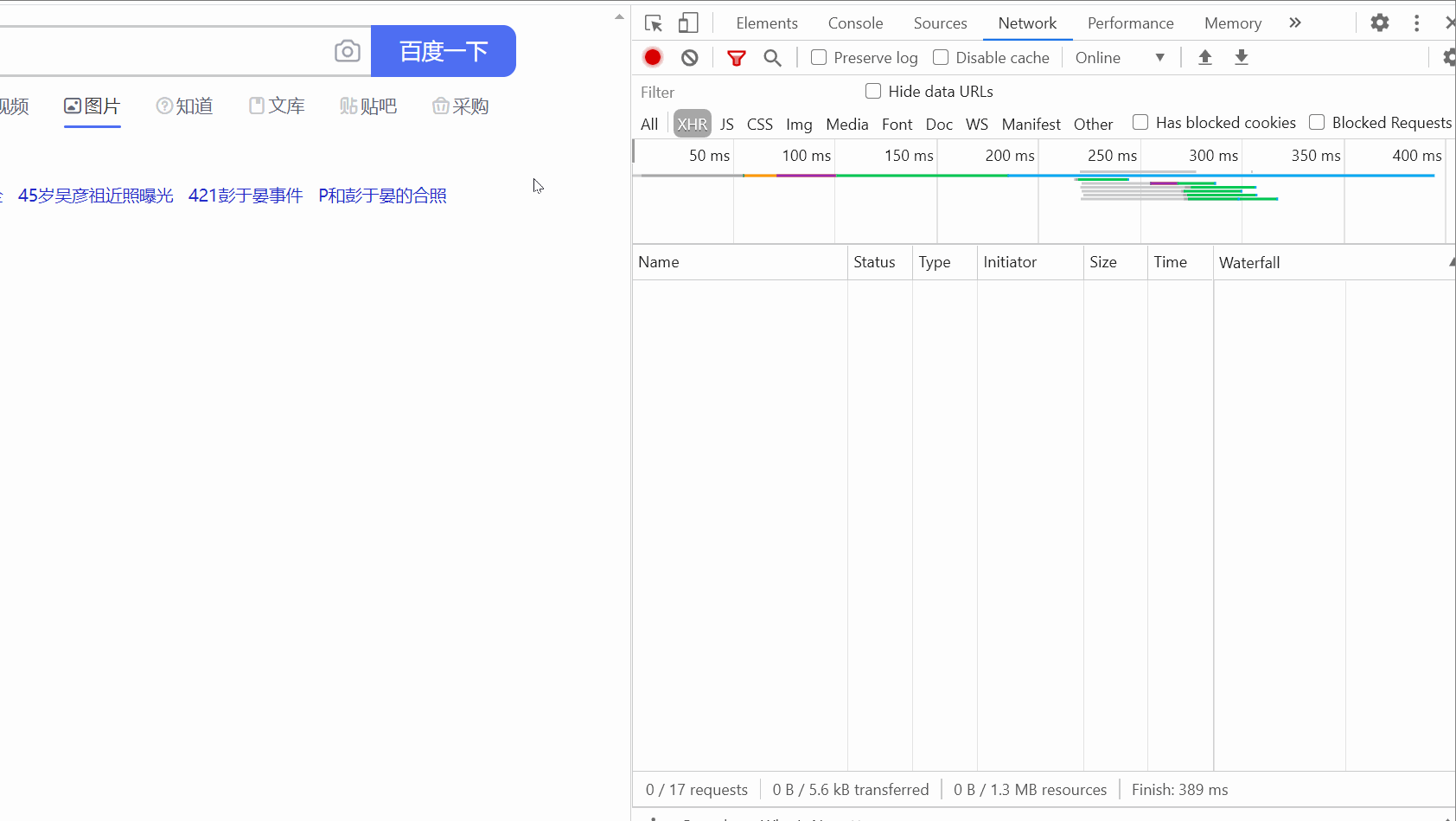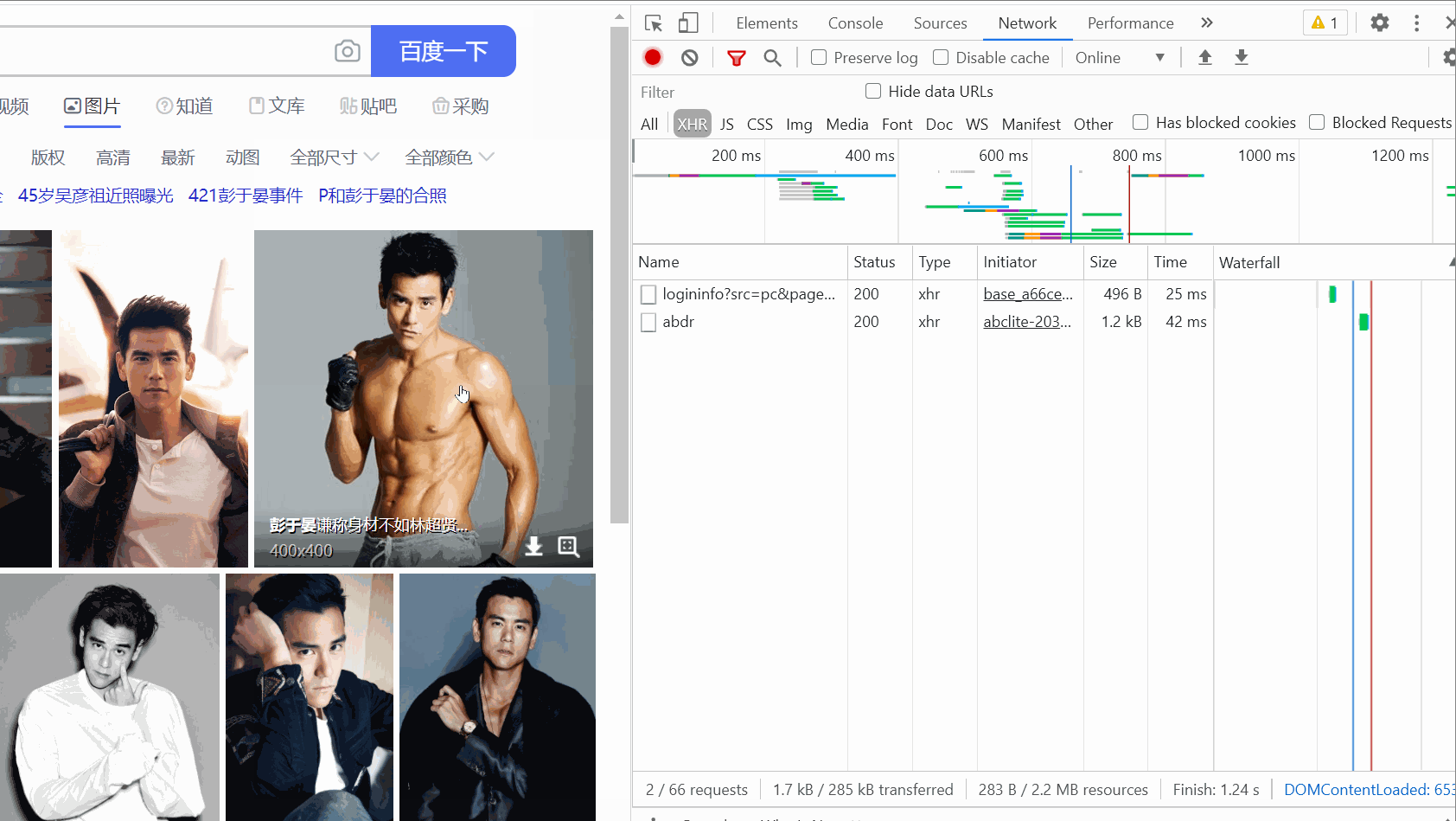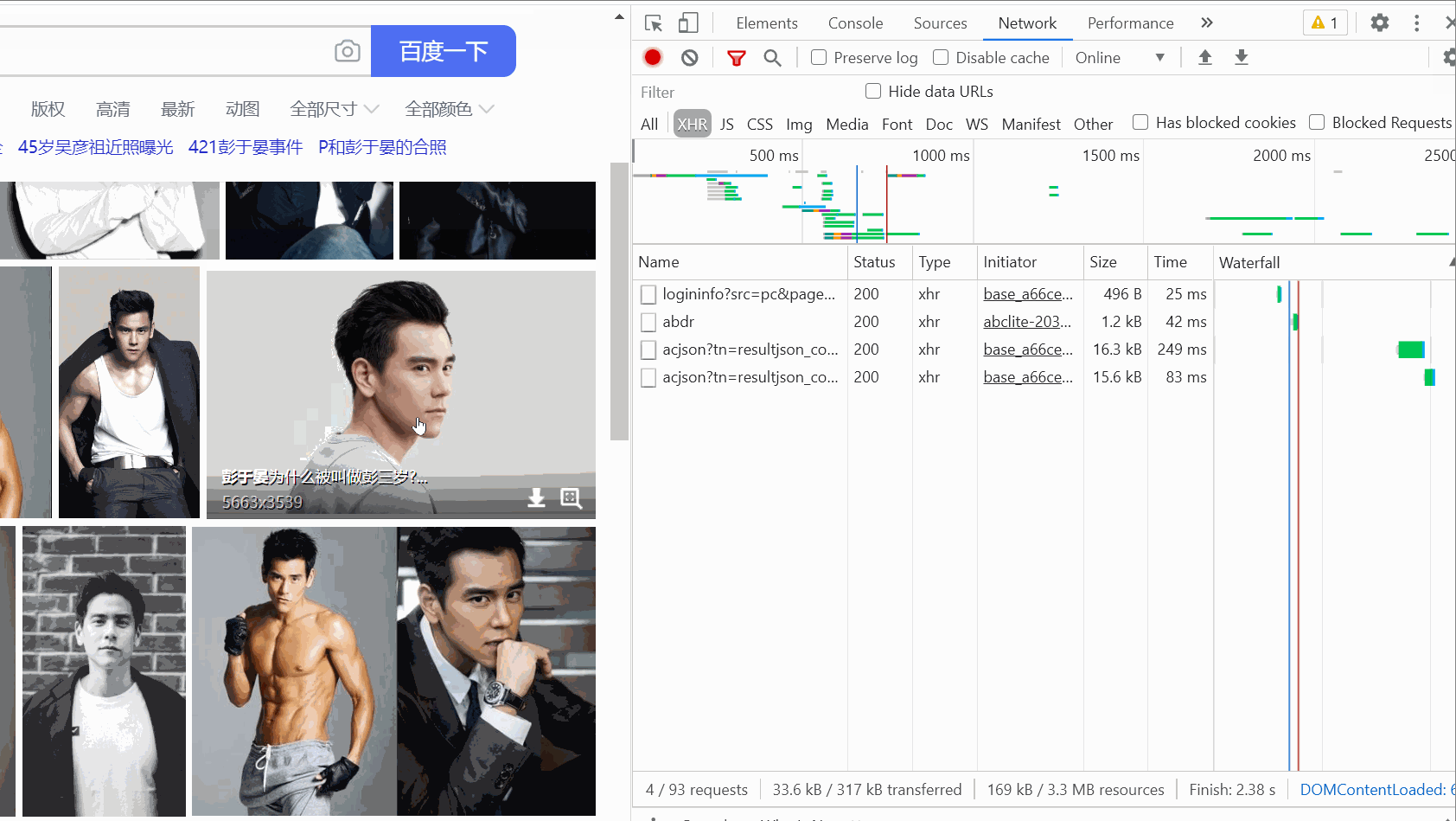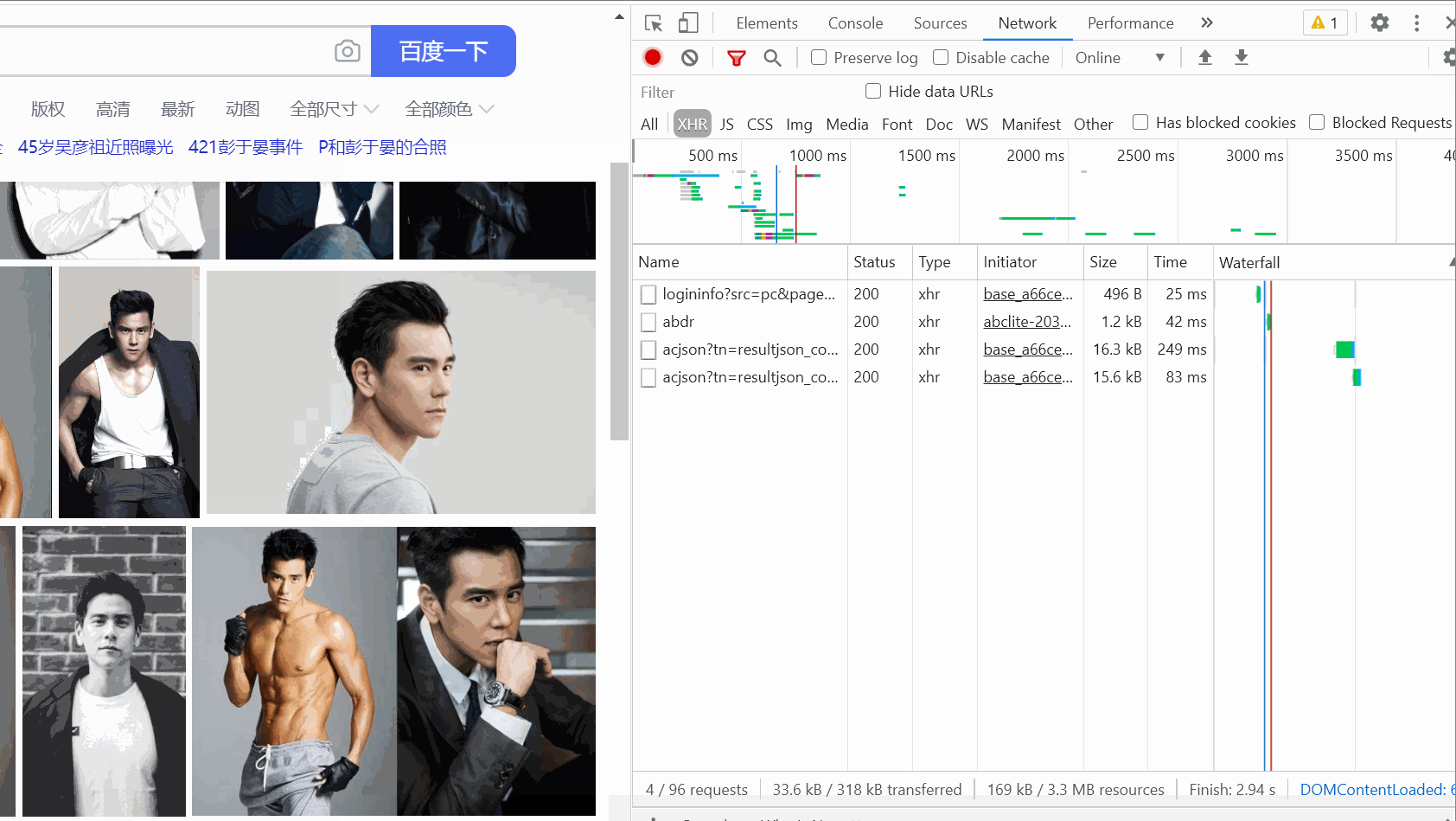
(여기서는 슬라이딩이 별로 없습니다. 처음에는 슬라이딩이 너무 많아서 녹화된 GIF가 5M를 넘었습니다.)
그런 다음 그림과 같이 패키지를 선택하고 헤더를 확인하세요. 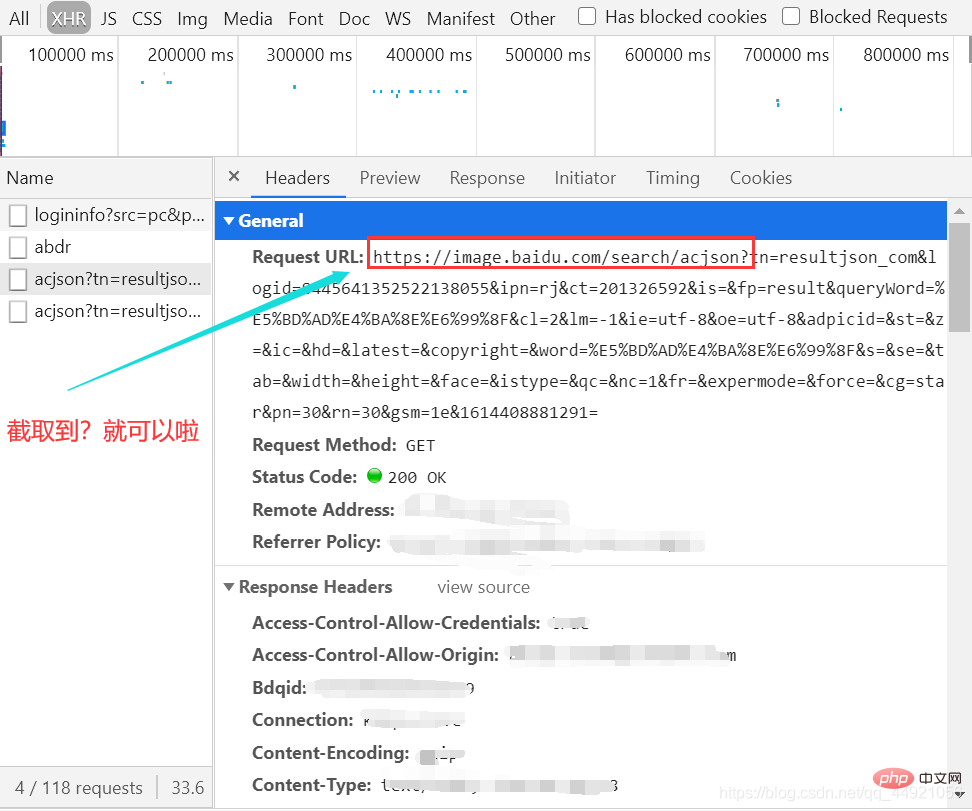
차단 후 나중에 사용할 URL을 메모장에 붙여넣으세요. 
여기에는 매우 많은 매개변수가 있는데 어떤 매개변수를 무시해도 되는지 모르겠습니다. 자세한 내용은 다음 문서에서 모두 복사하겠습니다.
이쯤 되면 직접 관찰할 수 있는 콘텐츠는 끝났습니다. 다음으로, 코드의 도움으로 또 다른 세계의 문을 열 수 있도록 도와주세요
그만하면 됩니다!
첫 번째: 위의 "기타 매개변수"를 그룹화합니다.
직접 할 경우 자신이 만든 "다른 매개변수"를 복사하는 것이 가장 좋습니다.
그 후에 먼저 추출을 시도하고 인코딩 형식을 'utf-8'로 변경할 수 있습니다'utf-8'
url = 'https://image.baidu.com/search/acjson?'
param = {
'tn': 'resultjson_com',
'logid': ' 7517080705015306512',
'ipn': 'rj',
'ct': '201326592',
'is': '',
'fp': 'result',
'queryWord': '彭于晏',
'cl': '2',
'lm': '-1',
'ie': 'utf-8',
'oe': 'utf-8',
'adpicid': '',
'st': '',
'z': '',
'ic': '',
'hd': '',
'latest': '',
'copyright': '',
'word': '彭于晏',
's': '',
'se': '',
'tab': '',
'width': '',
'height': '',
'face': '',
'istype': '',
'qc': '',
'nc': '1',
'fr': '',
'expermode': '',
'force': '',
'cg': 'star',
'pn': '30',
'rn': '30',
'gsm': '1e',
}
# 将编码形式转换为utf-8
response = requests.get(url=url, headers=header, params=param)
response.encoding = 'utf-8'
response = response.text print(response)运行结果如下:
看上去挺乱的哈,没事,我们给包装一下!
在上面的基础上加上:
# 把字符串转换成json数据 data_s = json.loads(response) print(data_s)
运行结果如下:
和上面相比,已经明晰很多了,但依旧不够明确,为什么呢?因为它打印的格式不方便我们观看!
对此,有两种解决办法。
①导入pprint库,接着输入pprint.pprint(data_s),就能打印啦,如下图
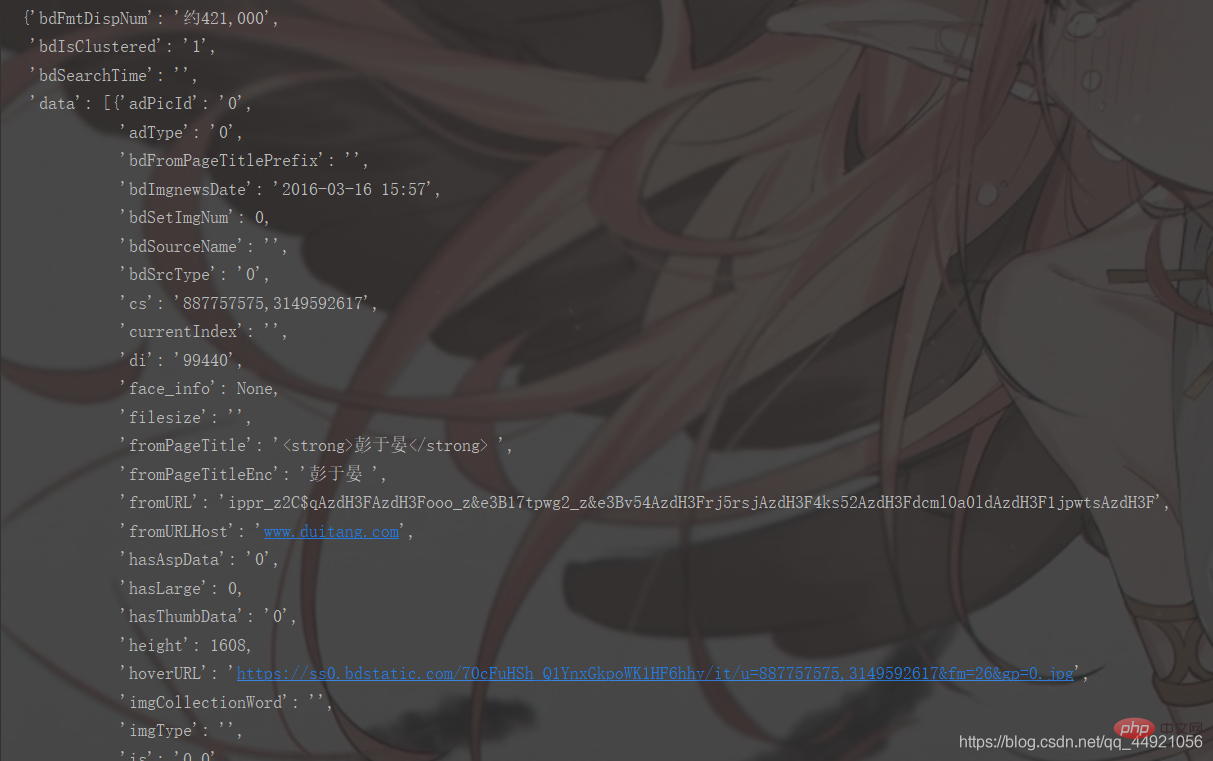
②使用json在线解析器(自行百度),结果如下:
解决掉上一步,我们会发现,想要的数据都在data
a = data_s["data"]
for i in range(len(a)-1): # -1是为了去掉上面那个空数据
data = a[i].get("thumbURL", "not exist")
print(data)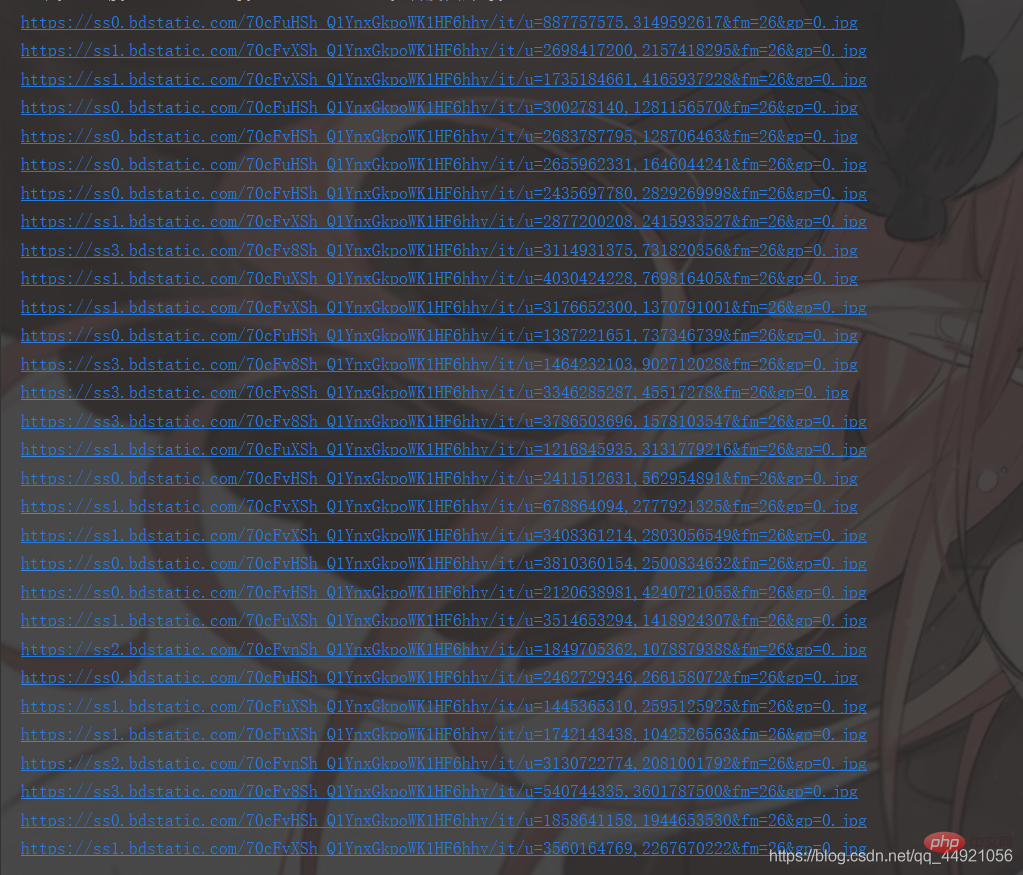
위 내용을 바탕으로 추가:
# -*- coding: UTF-8 -*-"""
@Author :远方的星
@Time : 2021/2/27 17:49
@CSDN :https://blog.csdn.net/qq_44921056
@腾讯云 : https://cloud.tencent.com/developer/user/8320044
"""import requestsimport jsonimport osimport pprint# 创建一个文件夹path = 'D:/百度图片'if not os.path.exists(path):
os.mkdir(path)# 导入一个请求头header = {
'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 11_1_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36'}# 用户(自己)输入信息指令keyword = input('请输入你想下载的内容:')page = input('请输入你想爬取的页数:')page = int(page) + 1n = 0pn = 1# pn代表从第几张图片开始获取,百度图片下滑时默认一次性显示30张for m in range(1, page):
url = 'https://image.baidu.com/search/acjson?'
param = {
'tn': 'resultjson_com',
'logid': ' 7517080705015306512',
'ipn': 'rj',
'ct': '201326592',
'is': '',
'fp': 'result',
'queryWord': keyword,
'cl': '2',
'lm': '-1',
'ie': 'utf-8',
'oe': 'utf-8',
'adpicid': '',
'st': '',
'z': '',
'ic': '',
'hd': '',
'latest': '',
'copyright': '',
'word': keyword,
's': '',
'se': '',
'tab': '',
'width': '',
'height': '',
'face': '',
'istype': '',
'qc': '',
'nc': '1',
'fr': '',
'expermode': '',
'force': '',
'cg': 'star',
'pn': pn,
'rn': '30',
'gsm': '1e',
}
# 定义一个空列表,用于存放图片的URL
image_url = list()
# 将编码形式转换为utf-8
response = requests.get(url=url, headers=header, params=param)
response.encoding = 'utf-8'
response = response.text # 把字符串转换成json数据
data_s = json.loads(response)
a = data_s["data"] # 提取data里的数据
for i in range(len(a)-1): # 去掉最后一个空数据
data = a[i].get("thumbURL", "not exist") # 防止报错key error
image_url.append(data)
for image_src in image_url:
image_data = requests.get(url=image_src, headers=header).content # 提取图片内容数据
image_name = '{}'.format(n+1) + '.jpg' # 图片名
image_path = path + '/' + image_name # 图片保存路径
with open(image_path, 'wb') as f: # 保存数据
f.write(image_data)
print(image_name, '下载成功啦!!!')
f.close()
n += 1
pn += 29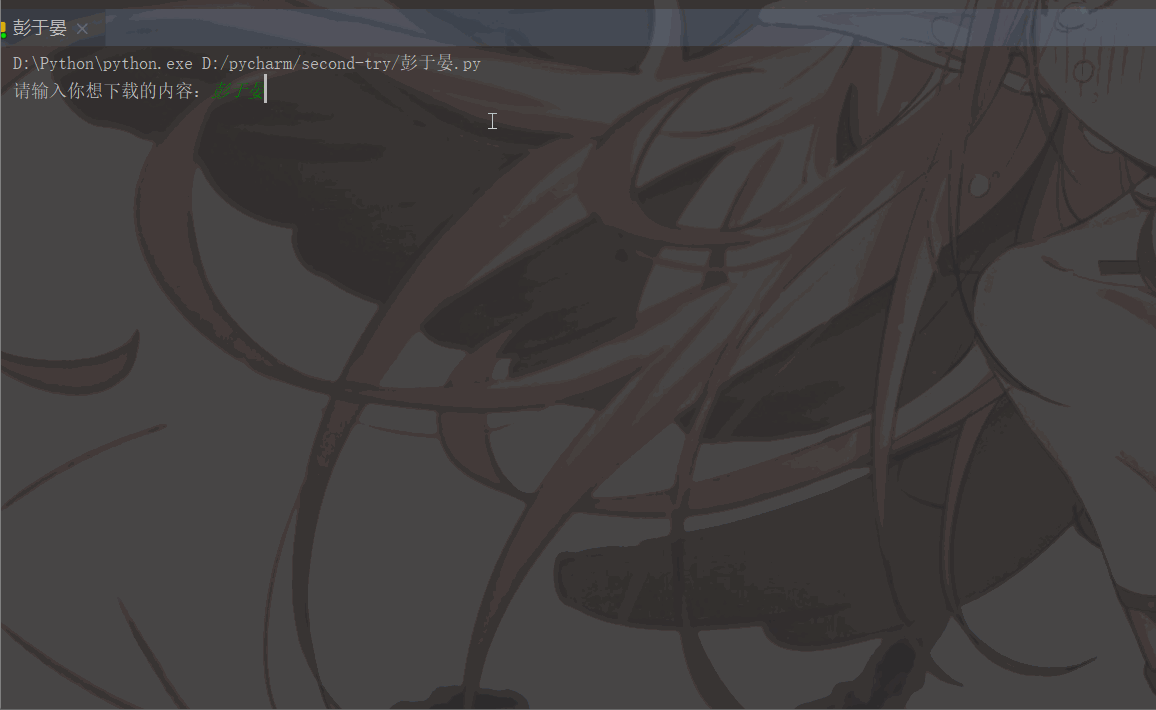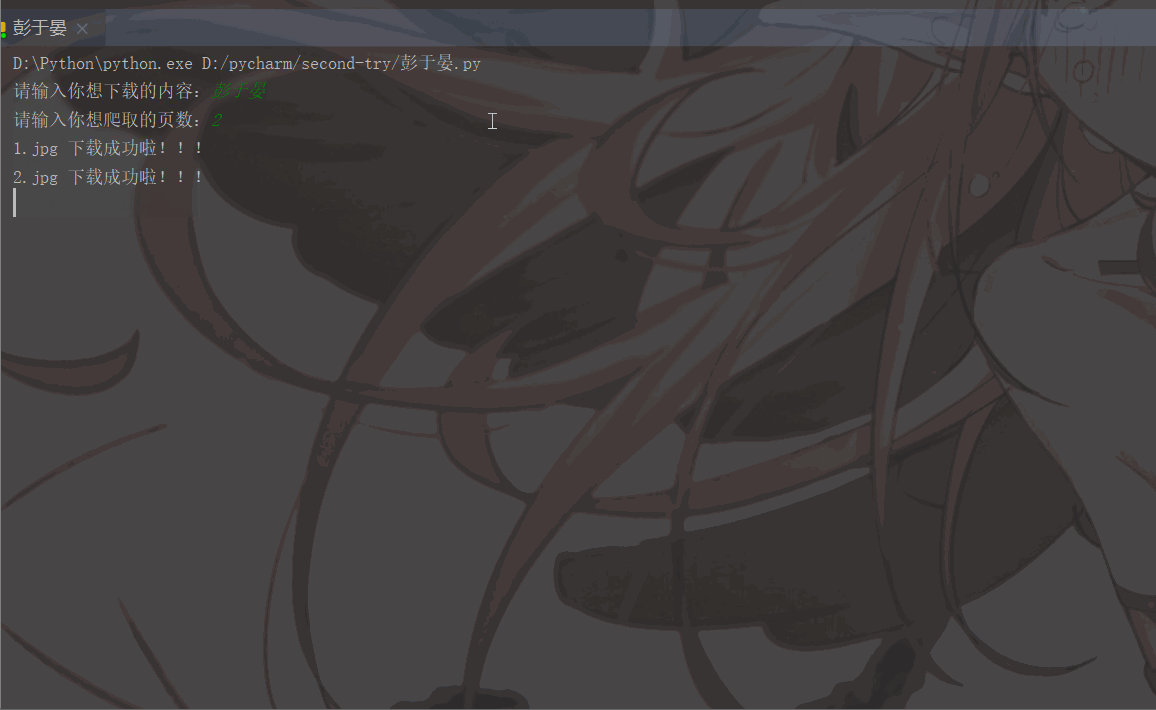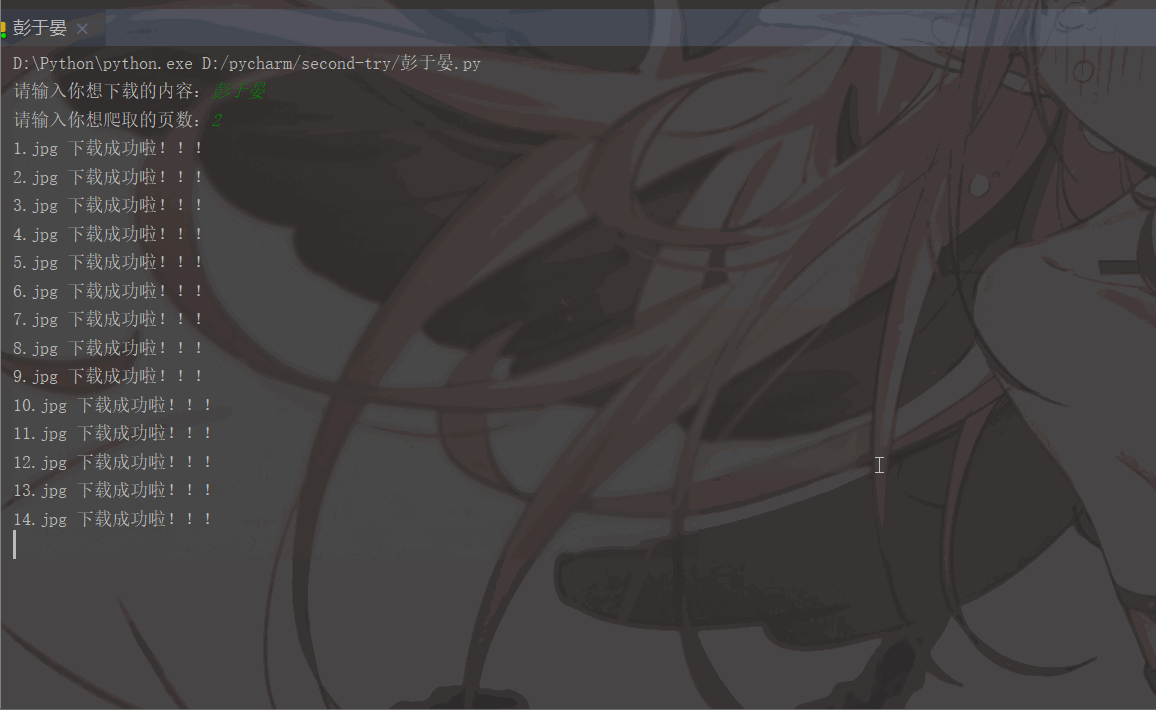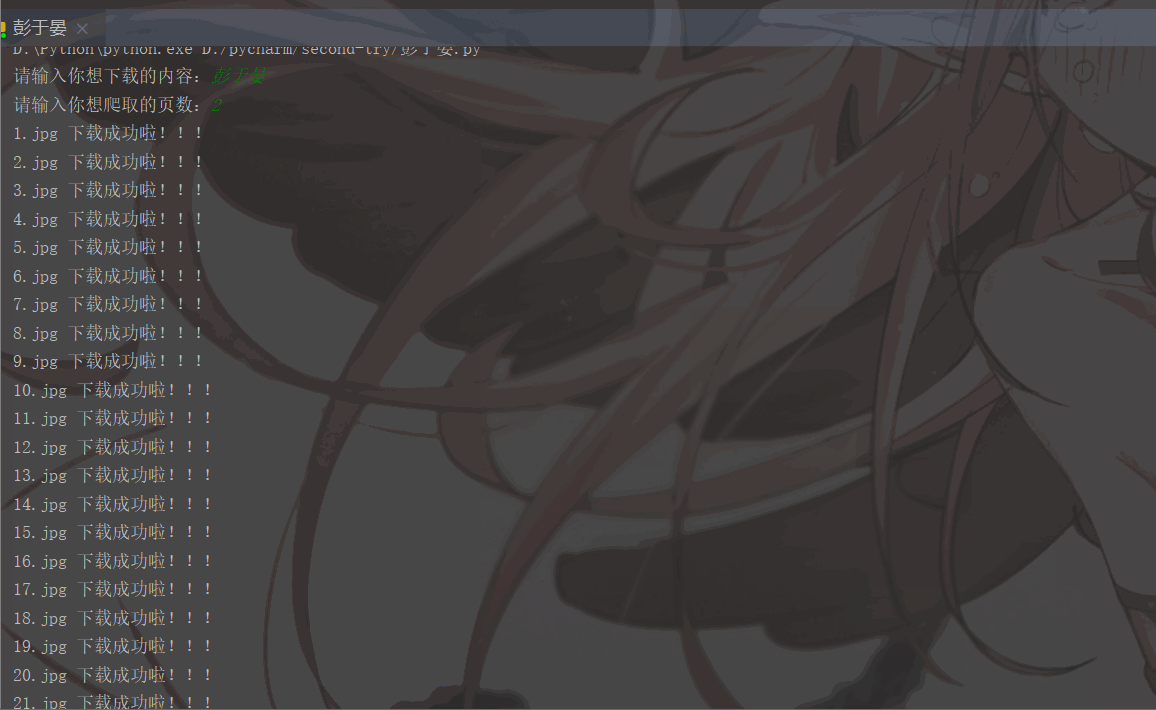
① pprint 라이브러리를 import한 후 pprint.pprint(data_s)를 입력하면 아래와 같이 인쇄할 수 있습니다

②json 온라인 파서(자체 제작 Baidu)를 사용하면 결과는 다음과 같습니다. :
이전 단계를 해결하고, 내가 원했던 모든 데이터가 data에 있다는 것을 알게 될 것입니다!
그럼 압축을 풀어보세요! rrreee결과는 다음과 같습니다.
이제 90% 성공입니다. 남은 것은 코드를 저장하고 최적화하는 것 뿐입니다! 🎜🎜3. 완성된 코드🎜🎜이 부분은 위의 내용과 조금 다른 부분이 있습니다. 🎜rrreee🎜실행 결과는 다음과 같습니다. 🎜🎜🎜🎜🎜🎜알림🎜:🎜 ①: 한 페이지는 30장의 사진입니다🎜 ②: 입력 내용은 다리, 달, 태양, Hu 등 다양한 방식으로 변경될 수 있습니다. 거(Ge), 자오리잉(Zhao Liying) 등 🎜🎜🎜4. 블로거의 소감🎜🎜🎜3번 연속 좋아요, 팔로우, 수집, 응원 부탁드려요! 🎜을 방문하세요.많은 무료 학습 추천이 있으니 python tutorial(동영상)
위 내용은 Python 크롤러: 원하는 대로 Baidu 사진을 크롤링합니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!




















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



