
Python 웹 크롤러 단계: 먼저 필요한 라이브러리를 준비하고 크롤러 스케줄러를 작성한 다음 URL 관리자와 웹 페이지 다운로더를 작성한 다음 웹 페이지 파서를 작성하고 마지막으로 웹 페이지 출력기를 작성합니다.

이 튜토리얼의 운영 환경: Windows 7 시스템, Python 버전 3.9, DELL G3 컴퓨터.
Python 웹 크롤러 단계
(1) 필요한 라이브러리 준비
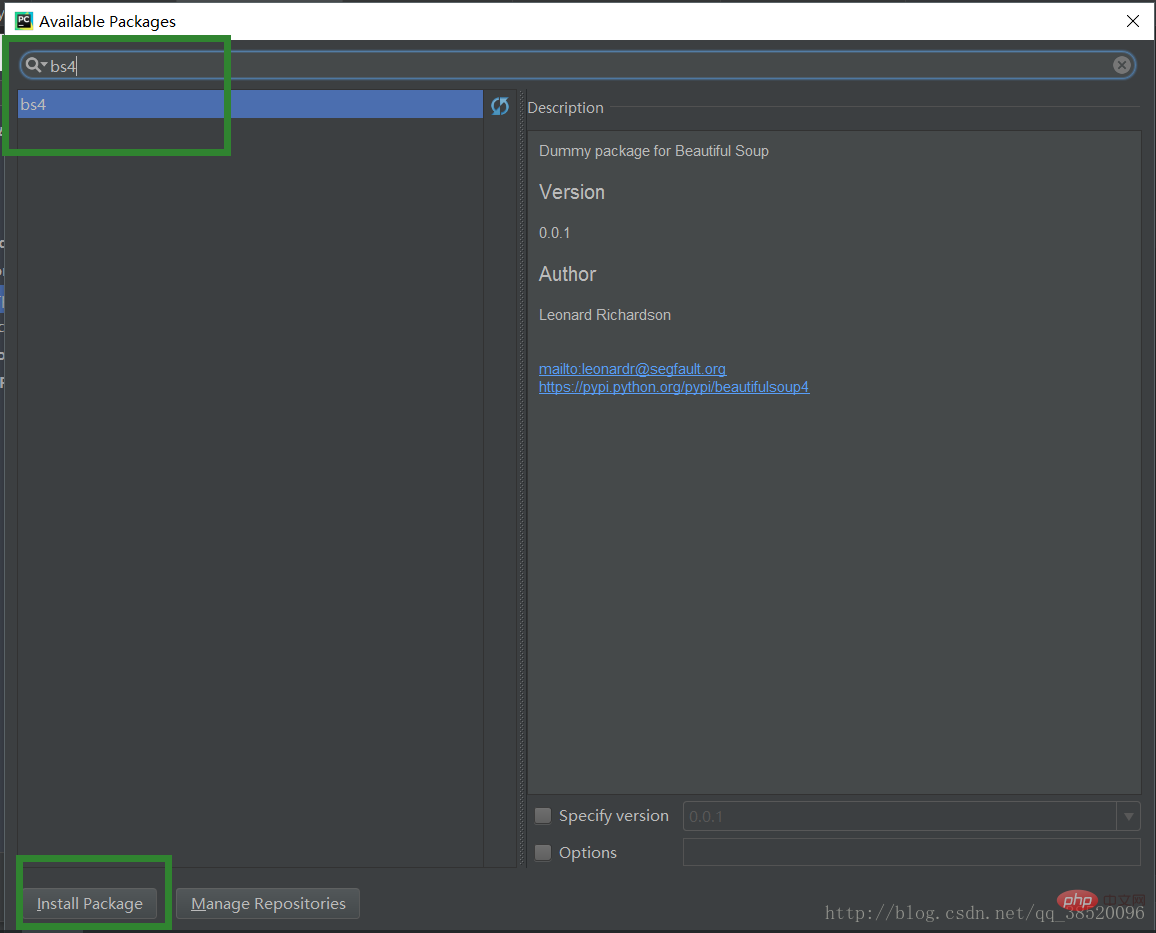
다운로드한 웹 페이지를 구문 분석하기 위해 BeautifulSoup(웹 페이지 구문 분석)이라는 오픈 소스 라이브러리를 준비해야 합니다. 이는 PyCharm 컴파일 환경입니다. , 오픈 소스 라이브러리를 직접 다운로드할 수 있습니다.
단계는 다음과 같습니다.
파일->설정 선택
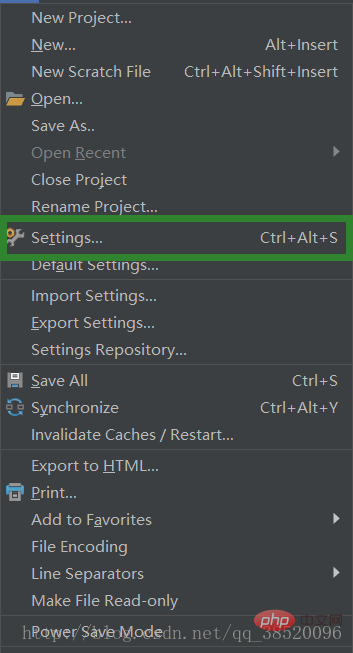
프로젝트:PythonProject
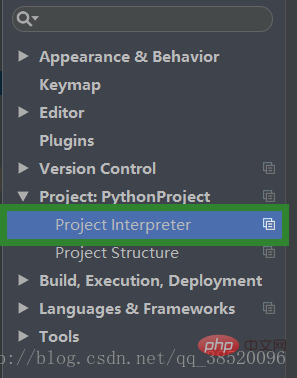
새 라이브러리를 추가하려면 더하기 기호를 클릭하세요.
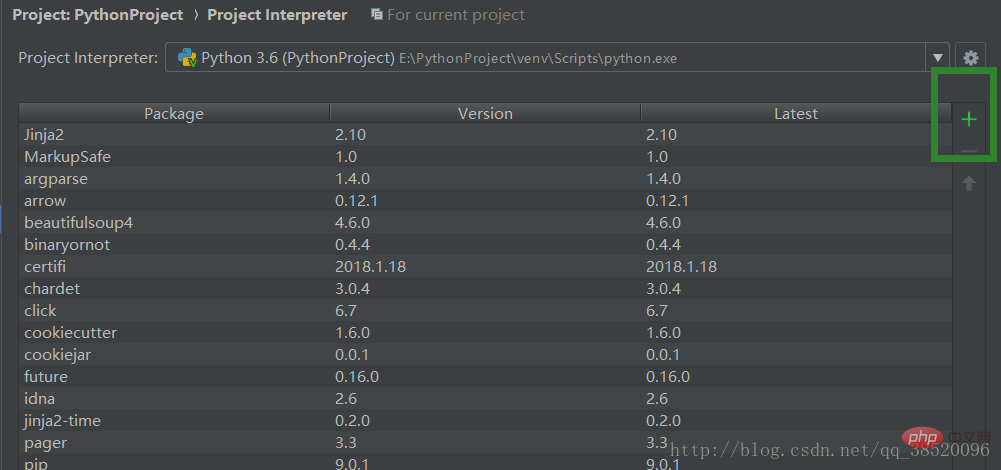
bs4 입력 bs4 선택 Install Packge Download
(2) 크롤러 스케줄러 작성
여기서 bike_spider는 프로젝트 이름으로 소개된 4개의 클래스로, 코드 url 관리자, url 다운로더, url의 네 가지 섹션에 해당합니다. 파서, URL 출력 장치.
# 爬虫调度程序
from bike_spider import url_manager, html_downloader, html_parser, html_outputer
# 爬虫初始化
class SpiderMain(object):
def __init__(self):
self.urls = url_manager.UrlManager()
self.downloader = html_downloader.HtmlDownloader()
self.parser = html_parser.HtmlParser()
self.outputer = html_outputer.HtmlOutputer()
def craw(self, my_root_url):
count = 1
self.urls.add_new_url(my_root_url)
while self.urls.has_new_url():
try:
new_url = self.urls.get_new_url()
print("craw %d : %s" % (count, new_url))
# 下载网页
html_cont = self.downloader.download(new_url)
# 解析网页
new_urls, new_data = self.parser.parse(new_url, html_cont)
self.urls.add_new_urls(new_urls)
# 网页输出器收集数据
self.outputer.collect_data(new_data)
if count == 10:
break
count += 1
except:
print("craw failed")
self.outputer.output_html()
if __name__ == "__main__":
root_url = "http://baike.baidu.com/item/Python/407313"
obj_spider = SpiderMain()
obj_spider.craw(root_url)(3) URL 관리자 작성
이미 크롤링된 특정 웹페이지를 반복적으로 크롤링하지 않도록 크롤링된 URL과 크롤링되지 않은 URL을 별도로 저장합니다.
# url管理器
class UrlManager(object):
def __init__(self):
self.new_urls = set()
self.old_urls = set()
def add_new_url(self, url):
if url is None:
return
if url not in self.new_urls and url not in self.old_urls:
self.new_urls.add(url)
def add_new_urls(self, urls):
if urls is None or len(urls) == 0:
return
for url in urls:
self.new_urls.add(url)
def get_new_url(self):
# pop方法会帮我们获取一个url并且移除它
new_url = self.new_urls.pop()
self.old_urls.add(new_url)
return new_url
def has_new_url(self):
return len(self.new_urls) != 0(4) 웹페이지 다운로더 작성
네트워크 요청을 통해 페이지 다운로드
# 网页下载器
import urllib.request
class HtmlDownloader(object):
def download(self, url):
if url is None:
return None
response = urllib.request.urlopen(url)
# code不为200则请求失败
if response.getcode() != 200:
return None
return response.read()(5) 웹페이지 파서 작성
웹페이지를 파싱할 때 어떤 내용이 있는지 알아야 합니다. 어떤 특성에 대해 쿼리하고 싶습니까? 웹 페이지를 열고 요소를 마우스 오른쪽 버튼으로 클릭하여 검사하여 우리가 찾고 있는 콘텐츠의 공통점이 무엇인지 이해할 수 있습니다.
# 网页解析器
import re
from bs4 import BeautifulSoup
from urllib.parse import urljoin
class HtmlParser(object):
def parse(self, page_url, html_cont):
if page_url is None or html_cont is None:
return
soup = BeautifulSoup(html_cont, "html.parser", from_encoding="utf-8")
new_urls = self._get_new_urls(page_url, soup)
new_data = self._get_new_data(page_url, soup)
return new_urls, new_data
def _get_new_data(self, page_url, soup):
res_data = {"url": page_url}
# 获取标题
title_node = soup.find("dd", class_="lemmaWgt-lemmaTitle-title").find("h1")
res_data["title"] = title_node.get_text()
summary_node = soup.find("p", class_="lemma-summary")
res_data["summary"] = summary_node.get_text()
return res_data
def _get_new_urls(self, page_url, soup):
new_urls = set()
# 查找出所有符合下列条件的url
links = soup.find_all("a", href=re.compile(r"/item/"))
for link in links:
new_url = link['href']
# 获取到的url不完整,学要拼接
new_full_url = urljoin(page_url, new_url)
new_urls.add(new_full_url)
return new_urls(6) 웹 페이지 출력기 작성
출력 형식은 다양하므로 html 페이지를 얻을 수 있도록 html 형식으로 출력하도록 선택합니다.
# 网页输出器
class HtmlOutputer(object):
def __init__(self):
self.datas = []
def collect_data(self, data):
if data is None:
return
self.datas.append(data)
# 我们以html表格形式进行输出
def output_html(self):
fout = open("output.html", "w", encoding='utf-8')
fout.write("<html>")
fout.write("<meta charset='utf-8'>")
fout.write("<body>")
# 以表格输出
fout.write("<table>")
for data in self.datas:
# 一行
fout.write("<tr>")
# 每个单元行的内容
fout.write("<td>%s</td>" % data["url"])
fout.write("<td>%s</td>" % data["title"])
fout.write("<td>%s</td>" % data["summary"])
fout.write("</tr>")
fout.write("</table>")
fout.write("</body>")
fout.write("</html>")
# 输出完毕后一定要关闭输出器
fout.close()관련 무료 학습 권장사항: python 비디오 튜토리얼
위 내용은 Python 웹 크롤러의 단계는 무엇입니까?의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



