

버블정렬, 퀵정렬, 힙정렬의 시간복잡도는 어떻게 되나요?

버블 정렬의 시간 복잡도: 최선의 경우는 "O(n)"이고 최악의 경우는 "O(n2)"입니다. 퀵 정렬의 시간 복잡도: 최선의 경우는 "O(nlogn)"이고 최악의 경우는 "O(n2)"입니다. 힙 정렬의 시간 복잡도는 "O(nlogn)"입니다.

이 튜토리얼의 운영 환경: Windows 7 시스템, Dell G3 컴퓨터.
버블 정렬
시간 복잡성
최상의 사례: 배열 자체는 순차적이며 외부 루프는 O(n)O(n)
最坏的情况:数组本身是逆序的,内外层遍历O(n2)
空间复杂度
开辟一个空间交换顺序O(1)
稳定性稳定,因为if判断不成立,就不会交换顺序,不会交换相同元素
冒泡排序它在所有排序算法中最简单。然而, 从运行时间的角度来看,冒泡排序是最差的一个,它的复杂度是O(n2)。
冒泡排序比较任何两个相邻的项,如果第一个比第二个大,则交换它们。元素项向上移动至正确的顺序,就好像气泡升至表面一样,冒泡排序因此得名。
交换时,我们用一个中间值来存储某一交换项的值。其他排序法也会用到这个方法,因此我 们声明一个方法放置这段交换代码以便重用。使用ES6(ECMAScript 2015)**增强的对象属性——对象数组的解构赋值语法,**这个函数可以写成下面 这样:
[array[index1], array[index2]] = [array[index2], array[index1]];
具体实现:
function bubbleSort(arr) {
for (let i = 0; i < arr.length; i++) {//外循环(行{2})会从数组的第一位迭代 至最后一位,它控制了在数组中经过多少轮排序
for (let j = 0; j < arr.length - i; j++) {//内循环将从第一位迭代至length - i位,因为后i位已经是排好序的,不用重新迭代
if (arr[j] > arr[j + 1]) {//如果前一位大于后一位
[arr[j], arr[j + 1]] = [arr[j + 1], arr[j]];//交换位置
}
}
}
return arr;
}快速排序
时间复杂度
最好的情况:每一次base值都刚好平分整个数组,O(nlogn)
最坏的情况:每一次base值都是数组中的最大/最小值,O(n2)
空间复杂度
快速排序是递归的,需要借助栈来保存每一层递归的调用信息,所以空间复杂度和递归树的深度一致
最好的情况:每一次base值都刚好平分整个数组,递归树的深度O(logn)
最坏的情况:每一次base值都是数组中的最大/最小值,递归树的深度O(n)
稳定性
快速排序是不稳定的,因为可能会交换相同的关键字。
快速排序是递归的,
特殊情况:left>right,直接退出。
步骤:
(1) 首先,从数组中选择中间一项作为主元base,一般取第一个值。
(2) 创建两个指针,左边一个指向数组第一个项,右边一个指向数组最后一个项。移动右指针直到找到一个比主元小的元素,接着,移动左指 针直到我们找到一个比主元大的元素,然后交 换它们,重复这个过程,直到左指针遇见了右指针。这个过程将使得比主元小的值都排在主元之前,而比主元大的值都排在主元之后。这一步叫作划分操作。
(3)然后交换主元和指针停下来的位置的元素(等于说是把这个元素归位,这个元素左边的都比他小,右边的都比他大,这个位置就是他最终的位置)
(4) 接着,算法对划分后的小数组(较主元小的值组成的子数组,以及较主元大的值组成的 子数组)重复之前的两个步骤(递归方法),
递归的出口为left/right=i을 완료하기 위해 한 번 순회됩니다.
O(n2)Space Complexity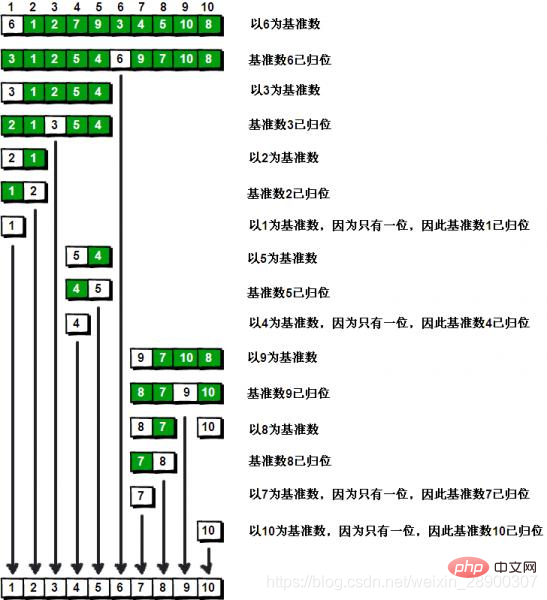 공간 교환 시퀀스
공간 교환 시퀀스 O(1) 생성
안정성
안정적, 판단이 사실이 아닐 경우 순서가 바뀌지 않고, 같은 요소도 바뀌지 않기 때문입니다
-
버블 정렬은 모든 정렬 알고리즘 중 가장 간단한 정렬 알고리즘입니다. 그러나 실행 시간 관점에서 볼 때 버블 정렬은 최악이며 복잡도는 O(n2)입니다.
- 버블 정렬은 인접한 두 항목을 비교하고 첫 번째 항목이 두 번째 항목보다 크면 서로 바꿉니다. 마치
거품이 표면으로 떠오르는
것처럼 항목이 올바른 순서로 위로 이동하므로 이름이 버블 정렬입니다. 🎜 - 🎜교환 시 특정 교환 아이템의 가치를 저장하기 위해 중간 가치를 사용합니다. 다른 정렬 방법도 이 방법을 사용하므로 재사용을 위해 이 교환 코드를 배치하는 방법을 선언합니다. ES6(ECMAScript 2015) 사용 ** 향상된 객체 속성 - 객체 배열의 구조 분해 할당 구문 ** 이 함수는 다음과 같이 작성할 수 있습니다: 🎜
left>i-1 / i+1>right
function quicksort(arr, left, right) {
if (left > right) {
return;
}
var i = left,
j = right,
base = arr[left]; //基准总是取序列开头的元素
// var [base, i, j] = [arr[left], left, right]; //以left指针元素为base
while (i != j) {
//i=j,两个指针相遇时,一次排序完成,跳出循环
// 因为每次大循环里面的操作都会改变i和j的值,所以每次循环/操作前都要判断是否满足i<j
while (i < j && arr[j] >= base) {
//寻找小于base的右指针元素a,跳出循环,否则左移一位
j--;
}
while (i < j && arr[i] <= base) {
//寻找大于base的左指针元素b,跳出循环,否则右移一位
i++;
}
if (i < j) {
[arr[i], arr[j]] = [arr[j], arr[i]]; //交换a和b
}
}
[arr[left], arr[j]] = [arr[j], arr[left]]; //交换相遇位置元素和base,base归位
// let k = i;
quicksort(arr, left, i - 1); //对base左边的元素递归排序
quicksort(arr, i + 1, right); //对base右边的元素递归排序
return arr;
}O(nlogn)🎜 최악의 경우: 기본 값이 배열의 최대값일 때마다 / 최소값, O(n2)🎜🎜🎜공간 복잡도🎜🎜 퀵 정렬은 재귀적이며 각 재귀 수준의 호출 정보를 저장하기 위해 스택을 사용해야 하므로 공간 복잡도와 깊이가 🎜 최선의 경우: 기본 값이 전체 배열과 정확히 동일할 때마다 재귀 트리의 깊이는 O(logn)🎜 최악의 경우: 기본 값이 항상 는 배열 값의 최대/최소이고 재귀 트리의 깊이는 O(n)🎜🎜🎜stability🎜🎜입니다. 빠른 정렬은 불안정합니다. 교환됩니다. 🎜 퀵 정렬은 재귀적입니다. 🎜 특별한 경우: 왼쪽>오른쪽, 직접 종료합니다. 🎜🎜🎜단계: 🎜🎜🎜(1) 먼저 배열에서 중간 항목을 🎜pivot🎜 베이스로 선택하고 일반적으로 🎜첫 번째 값🎜을 사용합니다. 🎜🎜(2) 🎜두 개의 포인터🎜를 만듭니다. 왼쪽 포인터는 배열의 첫 번째 항목을 가리키고 오른쪽 포인터는 배열의 마지막 항목을 가리킵니다. 🎜피벗보다 작은 요소🎜를 찾을 때까지 오른쪽 포인터를 이동한 다음 피벗보다 큰 요소🎜를 찾을 때까지 🎜왼쪽 포인터를 이동한 다음 🎜교체🎜하고 왼쪽 포인터가 오른쪽과 만날 때까지 이 과정을 반복합니다. 포인터. 이 프로세스를 수행하면 피벗보다 작은 값이 피벗 앞에 정렬되고 피벗보다 큰 값이 피벗 뒤에 정렬됩니다. 이 단계를 🎜파티션 작업🎜이라고 합니다. 🎜🎜(3) 그런 다음 🎜 피벗 요소와 포인터가 멈춘 위치에서 요소 🎜를 교환합니다(이는 이 요소 🎜를 해당 위치 🎜로 되돌리는 것과 같습니다. 이 요소의 왼쪽에 있는 요소는 그것보다 작습니다. 오른쪽에 있는 요소가 그것보다 큽니다. 이 위치가 그의 최종 위치입니다.🎜🎜(4) 그런 다음 알고리즘은 이전 두 단계를 반복합니다( 🎜재귀 방법🎜), 🎜🎜재귀 종료는 <코드>왼쪽/오른쪽입니다. =i, 즉: 🎜// 建立大顶堆
function buildHeap(arr) {
//从最后一个非叶子节点开始,向前遍历,
for (let i = Math.floor(arr.length / 2 - 1); i >= 0; i--) {
headAdjust(arr, i, arr.length); //对每一个节点都调整堆,使其满足大顶堆规则
}
}//从输入节点处调整堆
function headAdjust(arr, cur, len) {
let intialCur = arr[cur]; //存放最初始的
let childMax = 2 * cur + 1; //指向子树中较大的位置,初始值为左子树的索引
//子树存在(索引没超过数组长度)而且子树值大于根时,此时不符合大顶堆结构,进入循环,调整堆的结构
while (childMax < len) {
//判断左右子树大小,如果右子树更大,而且右子树存在,childMax指针指向右子树
if (arr[childMax] < arr[childMax + 1] && childMax + 1 < len) childMax++;
//子树值小于根节点,不需要调整,退出循环
if (arr[childMax] < arr[cur]) break;
//子树值大于根节点,需要调整,先交换根节点和子节点
swap(arr, childMax, cur);
cur = childMax; //根节点指针指向子节点,检查子节点是否满足大顶堆规则
childMax = 2 * cur + 1; //子节点指针指向新的子节点
}
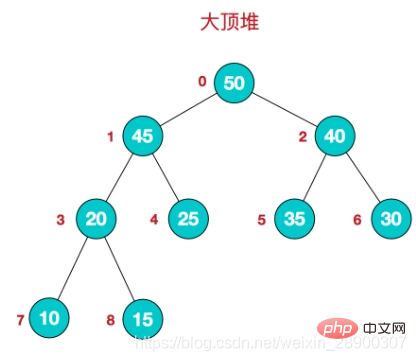
}- 堆是一个完全二叉树。
- 完全二叉树: 二叉树除开最后一层,其他层结点数都达到最大,最后一层的所有结点都集中在左边(左边结点排列满的情况下,右边才能缺失结点)。
- 大顶堆:根结点为最大值,每个结点的值大于或等于其孩子结点的值。
- 小顶堆:根结点为最小值,每个结点的值小于或等于其孩子结点的值。
- 堆的存储: 堆由数组来实现,相当于对二叉树做层序遍历。如下图:


时间复杂度
总时间为建堆时间+n次调整堆 —— O(n)+O(nlogn)=O(nlogn)建堆时间:从最后一个非叶子节点遍历到根节点,复杂度为O(n)n次调整堆:每一次调整堆最长的路径是从树的根节点到叶子结点,也就是树的高度logn,所以每一次调整时间复杂度是O(logn),一共是O(nlogn)
空间复杂度
堆排序只需要在交换元素的时候申请一个空间暂存元素,其他操作都是在原数组操作,空间复杂度为O(1)
稳定性
堆排序是不稳定的,因为可能会交换相同的子结点。
步骤一:建堆
- 以升序遍历为例子,需要先将将初始二叉树转换成大顶堆,要求满足:
树中任一非叶子结点大于其左右孩子。 - 实质上是调整数组元素的位置,不断比较,做交换操作。
- 找到第一个非叶子结点——
Math.floor(arr.length / 2 - 1),从后往前依次遍历 - 对每一个结点,检查结点和子结点的大小关系,调整成大根堆
// 建立大顶堆
function buildHeap(arr) {
//从最后一个非叶子节点开始,向前遍历,
for (let i = Math.floor(arr.length / 2 - 1); i >= 0; i--) {
headAdjust(arr, i, arr.length); //对每一个节点都调整堆,使其满足大顶堆规则
}
}步骤二:调整指定结点形成大根堆
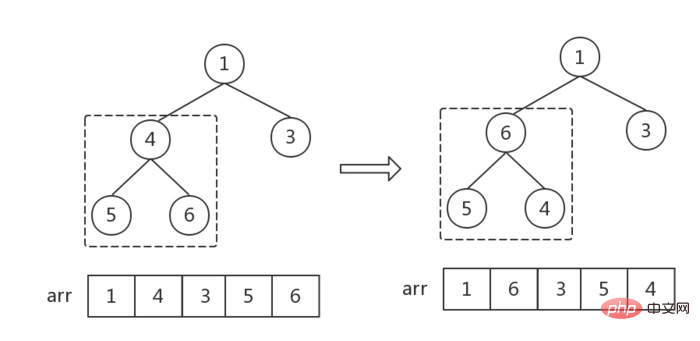
- 建立
childMax指针指向child最大值节点,初始值为2 * cur + 1,指向左节点 - 当左节点存在时(左节点索引小于数组
length),进入循环,递归调整所有节点位置,直到没有左节点为止(cur指向一个叶结点为止),跳出循环,遍历结束 - 每次循环,先判断右节点存在时,右节点是否大于左节点,是则改变childMax的指向
- 然后判断cur根节点是否大于childMax,
- 大于的话,说明满足大顶堆规律,不需要再调整,跳出循环,结束遍历
- 小于的话,说明不满足大顶堆规律,交换根节点和子结点,
- 因为交换了节点位置,子结点可能会不满足大顶堆顺序,所以还要判断子结点然后,改变
cur和childMax指向子结点,继续循环判断。
//从输入节点处调整堆
function headAdjust(arr, cur, len) {
let intialCur = arr[cur]; //存放最初始的
let childMax = 2 * cur + 1; //指向子树中较大的位置,初始值为左子树的索引
//子树存在(索引没超过数组长度)而且子树值大于根时,此时不符合大顶堆结构,进入循环,调整堆的结构
while (childMax < len) {
//判断左右子树大小,如果右子树更大,而且右子树存在,childMax指针指向右子树
if (arr[childMax] < arr[childMax + 1] && childMax + 1 < len) childMax++;
//子树值小于根节点,不需要调整,退出循环
if (arr[childMax] < arr[cur]) break;
//子树值大于根节点,需要调整,先交换根节点和子节点
swap(arr, childMax, cur);
cur = childMax; //根节点指针指向子节点,检查子节点是否满足大顶堆规则
childMax = 2 * cur + 1; //子节点指针指向新的子节点
}
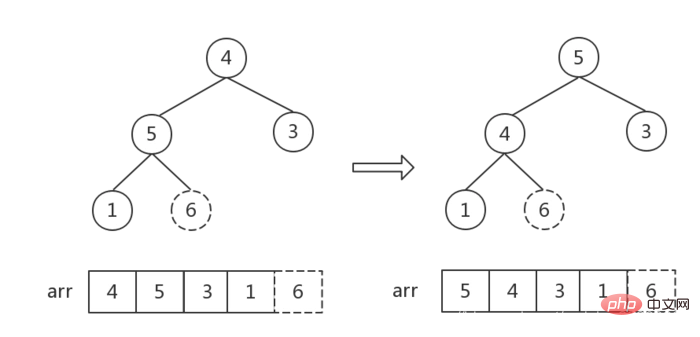
}步骤三:利用堆进行排序
- 从后往前遍历大顶堆(数组),交换堆顶元素
a[0]和当前元素a[i]的位置,将最大值依次放入数组末尾。 - 每交换一次,就要重新调整一下堆,从根节点开始,调整
根节点~i-1个节点(数组长度为i),重新生成大顶堆
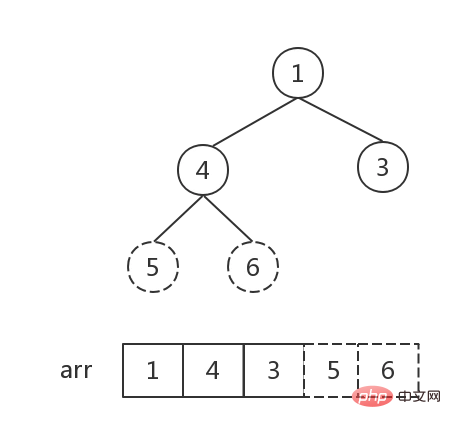
// 堆排序
function heapSort(arr) {
if (arr.length <= 1) return arr;
//构建大顶堆
buildHeap(arr);
//从后往前遍历,
for (let i = arr.length - 1; i >= 0; i--) {
swap(arr, i, 0); //交换最后位置和第一个位置(堆顶最大值)的位置
headAdjust(arr, 0, i); //调整根节点~i-1个节点,重新生成大顶堆
}
return arr;
}完整代码:
// 交换数组元素
function swap(a, i, j) {
[a[i], a[j]] = [a[j], a[i]];
}
//从输入节点处调整堆
function headAdjust(arr, cur, len) {
let intialCur = arr[cur]; //存放最初始的
let childMax = 2 * cur + 1; //指向子树中较大的位置,初始值为左子树的索引
//子树存在(索引没超过数组长度)而且子树值大于根时,此时不符合大顶堆结构,进入循环,调整堆的结构
while (childMax < len) {
//判断左右子树大小,如果右子树更大,而且右子树存在,childMax指针指向右子树
if (arr[childMax] < arr[childMax + 1] && childMax + 1 < len) childMax++;
//子树值小于根节点,不需要调整,退出循环
if (arr[childMax] < arr[cur]) break;
//子树值大于根节点,需要调整,先交换根节点和子节点
swap(arr, childMax, cur);
cur = childMax; //根节点指针指向子节点,检查子节点是否满足大顶堆规则
childMax = 2 * cur + 1; //子节点指针指向新的子节点
}
}
// 建立大顶堆
function buildHeap(arr) {
//从最后一个非叶子节点开始,向前遍历,
for (let i = Math.floor(arr.length / 2 - 1); i >= 0; i--) {
headAdjust(arr, i, arr.length); //对每一个节点都调整堆,使其满足大顶堆规则
}
}
// 堆排序
function heapSort(arr) {
if (arr.length <= 1) return arr;
//构建大顶堆
buildHeap(arr);
//从后往前遍历,
for (let i = arr.length - 1; i >= 0; i--) {
swap(arr, i, 0); //交换最后位置和第一个位置(堆顶最大值)的位置
headAdjust(arr, 0, i); //调整根节点~i-1个节点,重新生成大顶堆
}
return arr;
}更多编程相关知识,请访问:编程视频!!
위 내용은 버블정렬, 퀵정렬, 힙정렬의 시간복잡도는 어떻게 되나요?의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

Video Face Swap
완전히 무료인 AI 얼굴 교환 도구를 사용하여 모든 비디오의 얼굴을 쉽게 바꾸세요!

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7675
7675
 15
1393
52
1207
24
91
11
73
19
15
1393
52
1207
24
91
11
73
19

 Java 데이터 구조 및 알고리즘: 심층 설명
May 08, 2024 pm 10:12 PM
Java 데이터 구조 및 알고리즘: 심층 설명
May 08, 2024 pm 10:12 PM
데이터 구조와 알고리즘은 Java 개발의 기초입니다. 이 기사에서는 Java의 주요 데이터 구조(예: 배열, 연결 목록, 트리 등)와 알고리즘(예: 정렬, 검색, 그래프 알고리즘 등)을 자세히 살펴봅니다. 이러한 구조는 배열을 사용하여 점수를 저장하고, 연결된 목록을 사용하여 쇼핑 목록을 관리하고, 스택을 사용하여 재귀를 구현하고, 대기열을 사용하여 스레드를 동기화하고, 트리 및 해시 테이블을 사용하여 빠른 검색 및 인증을 저장하는 등 실제 사례를 통해 설명됩니다. 이러한 개념을 이해하면 효율적이고 유지 관리가 가능한 Java 코드를 작성할 수 있습니다.
 C++ 함수 포인터로 코드 변환: 효율성과 재사용성 향상
Apr 29, 2024 pm 06:45 PM
C++ 함수 포인터로 코드 변환: 효율성과 재사용성 향상
Apr 29, 2024 pm 06:45 PM
함수 포인터 기술은 특히 다음과 같이 코드 효율성과 재사용성을 향상시킬 수 있습니다. 효율성 향상: 함수 포인터를 사용하면 중복 코드를 줄이고 호출 프로세스를 최적화할 수 있습니다. 재사용성 향상: 함수 포인터를 사용하면 공통 함수를 사용하여 다양한 데이터를 처리할 수 있으므로 프로그램 재사용성이 향상됩니다.
 C#에서 버블 정렬 알고리즘을 구현하는 방법
Sep 19, 2023 am 11:10 AM
C#에서 버블 정렬 알고리즘을 구현하는 방법
Sep 19, 2023 am 11:10 AM
C#에서 버블 정렬 알고리즘 구현 방법 버블 정렬은 인접한 요소를 여러 번 비교하고 위치를 교환하여 배열을 정렬하는 간단하지만 효과적인 정렬 알고리즘입니다. 이번 글에서는 C# 언어를 사용하여 버블 정렬 알고리즘을 구현하는 방법을 소개하고 구체적인 코드 예제를 제공하겠습니다. 먼저 버블정렬의 기본원리를 이해해보자. 알고리즘은 배열의 첫 번째 요소부터 시작하여 이를 다음 요소와 비교합니다. 현재 요소가 다음 요소보다 크면 위치를 바꾸고, 현재 요소가 다음 요소보다 작으면 그대로 유지합니다.
 Java 빠른 정렬 팁 및 주의사항
Feb 25, 2024 pm 10:24 PM
Java 빠른 정렬 팁 및 주의사항
Feb 25, 2024 pm 10:24 PM
Java 퀵 정렬(QuickSort)의 핵심 기술과 주의 사항을 숙지하세요. 퀵 정렬(QuickSort)은 일반적으로 사용되는 정렬 알고리즘입니다. 핵심 아이디어는 벤치마크 요소를 선택하여 정렬할 시퀀스를 두 개의 독립적인 부분으로 나누고 하나의 요소를 모두 포함하는 것입니다. 부분이 기본 요소보다 작고 다른 부분의 모든 요소가 기본 요소보다 큰 경우 두 부분이 재귀적으로 정렬되어 최종적으로 순서가 지정된 시퀀스가 얻어집니다. 퀵소트는 평균적으로 O(nlogn)의 시간 복잡도를 가지지만, 최악의 경우에는 O(nlogn)으로 퇴보합니다.
 PHP 배열을 위한 사용자 정의 정렬 알고리즘 작성 가이드
Apr 27, 2024 pm 06:12 PM
PHP 배열을 위한 사용자 정의 정렬 알고리즘 작성 가이드
Apr 27, 2024 pm 06:12 PM
사용자 정의 PHP 배열 정렬 알고리즘을 작성하는 방법은 무엇입니까? 버블 정렬: 인접한 요소를 비교하고 교환하여 배열을 정렬합니다. 선택 정렬: 매번 가장 작거나 가장 큰 요소를 선택하고 현재 위치와 바꿉니다. 삽입 정렬: 순서가 지정된 부품에 요소를 하나씩 삽입합니다.
 Python을 사용하여 빠른 정렬을 구현하는 방법
Dec 18, 2023 pm 03:37 PM
Python을 사용하여 빠른 정렬을 구현하는 방법
Dec 18, 2023 pm 03:37 PM
Python에서 빠른 정렬을 구현하는 방법: 1. Quick_sort라는 함수를 정의하고 재귀적 방법을 사용하여 빠른 정렬을 구현합니다. 2. 배열의 길이가 1보다 작거나 같으면 배열을 직접 반환합니다. 그렇지 않으면 배열을 선택합니다. 첫 번째 요소는 피벗 요소(피벗)로 사용되며, 배열은 피벗 요소보다 작고 피벗 요소보다 큰 두 개의 하위 배열로 나뉩니다. 정렬된 배열을 형성하는 피벗 요소입니다.
 다양한 PHP 배열 정렬 알고리즘의 복잡성 분석
Apr 27, 2024 am 09:03 AM
다양한 PHP 배열 정렬 알고리즘의 복잡성 분석
Apr 27, 2024 am 09:03 AM
PHP 배열 정렬 알고리즘 복잡도: 버블 정렬: O(n^2) 빠른 정렬: O(nlogn) (평균) 병합 정렬: O(nlogn)
 Go 언어의 시간 복잡도와 공간 복잡도 분석
Mar 27, 2024 am 09:24 AM
Go 언어의 시간 복잡도와 공간 복잡도 분석
Mar 27, 2024 am 09:24 AM
Go는 쓰기 쉽고, 읽기 쉽고, 유지 관리하기 쉬우면서도 고급 프로그래밍 개념을 지원하도록 설계된 프로그래밍 언어로 점점 더 인기를 얻고 있습니다. 시간 복잡도와 공간 복잡도는 알고리즘과 데이터 구조 분석에서 중요한 개념으로, 프로그램의 실행 효율성과 메모리 크기를 측정합니다. 이번 글에서는 Go 언어의 시간 복잡도와 공간 복잡도를 분석하는 데 중점을 둘 것입니다. 시간 복잡도(Time Complexity) 시간 복잡도는 알고리즘의 실행 시간과 문제 크기 사이의 관계를 나타냅니다. 시간은 일반적으로 Big O 표기법으로 표현됩니다.