

DQL을 사용하여 데이터를 쿼리하는 방법

이 글에서는 DQL을 사용하여 데이터를 쿼리하는 방법을 소개합니다. 도움이 필요한 친구들이 모두 참고할 수 있기를 바랍니다.

DQL을 사용하여 데이터 쿼리
DQL 언어
DQL(Data Query Language)
데이터베이스 데이터 쿼리(예: SELECT 문)
간단한 단일 테이블 쿼리 또는 매우 복잡한 쿼리 및 테이블의 중첩 쿼리
는 데이터베이스 언어에서 핵심이자 가장 중요한 문입니다
가장 자주 사용되는 문
SELECT 구문
SELECT [ALL | DISTINCT]
{* | table.* | [table.field1[as alias1][,table.field2[as alias2]][,...]]}
FROM table_name [as table_alias]
[left | right | inner join table_name2] -- 联合查询
[WHERE ...] -- 指定结果需满足的条件
[GROUP BY ...] -- 指定结果按照哪几个字段来分组
[HAVING] -- 过滤分组的记录必须满足的次要条件
[ORDER BY ...] -- 指定查询记录按一个或多个条件排序
[LIMIT {[offset,]row_count | row_countOFFSET offset}];
-- 指定查询的记录从哪条至哪条참고: [ ] 대괄호는 선택 사항, { } 대괄호를 나타냅니다. 필수
지정된 쿼리 필드
-- 查询表中所有的数据列结果 , 采用 **" \* "** 符号; 但是效率低,不推荐 . -- 查询所有学生信息 SELECT * FROM student; -- 查询指定列(学号 , 姓名) SELECT studentno,studentname FROM student;
AS 절을 별칭으로 표시
기능:
데이터 열에 새 별칭을 제공할 수 있습니다
테이블에 새 별칭을 제공할 수 있습니다
계산되거나 요약된 결과를 다른 새로운 이름으로 바꿀 수 있습니다
-- 这里是为列取别名(当然as关键词可以省略) SELECT studentno AS 学号,studentname AS 姓名 FROM student; -- 使用as也可以为表取别名 SELECT studentno AS 学号,studentname AS 姓名 FROM student AS s; -- 使用as,为查询结果取一个新名字 -- CONCAT()函数拼接字符串 SELECT CONCAT('姓名:',studentname) AS 新姓名 FROM student;
DISTINCT 키워드 사용
기능: SELECT 쿼리로 반환된 레코드 결과에서 중복된 레코드를 제거합니다(모든 열의 값이 모두 반환됨). 동일), 표현식을 사용하여
-- # 查看哪些同学参加了考试(学号) 去除重复项 SELECT * FROM result; -- 查看考试成绩 SELECT studentno FROM result; -- 查看哪些同学参加了考试 SELECT DISTINCT studentno FROM result; -- 了解:DISTINCT 去除重复项 , (默认是ALL)
열만 반환합니다
데이터베이스의 표현식: 일반적으로 텍스트 값, 열 값, NULL, 함수 및 연산자 등으로 구성됩니다.
응용 시나리오:
SELECT 문 사용
반환된 결과 열의 ORDER BY 및 HAVING 절에서- where를 사용하여 조건문
-- selcet查询中可以使用表达式 SELECT @@auto_increment_increment; -- 查询自增步长 SELECT VERSION(); -- 查询版本号 SELECT 100*3-1 AS 计算结果; -- 表达式 -- 学员考试成绩集体提分一分查看 SELECT studentno,StudentResult+1 AS '提分后' FROM result;
로그인 후 복사
- where 조건문
Test
-- 满足条件的查询(where) SELECT Studentno,StudentResult FROM result; -- 查询考试成绩在95-100之间的 SELECT Studentno,StudentResult FROM result WHERE StudentResult>=95 AND StudentResult<=100; -- AND也可以写成 && SELECT Studentno,StudentResult FROM result WHERE StudentResult>=95 && StudentResult<=100; -- 模糊查询(对应的词:精确查询) SELECT Studentno,StudentResult FROM result WHERE StudentResult BETWEEN 95 AND 100; -- 除了1000号同学,要其他同学的成绩 SELECT studentno,studentresult FROM result WHERE studentno!=1000; -- 使用NOT SELECT studentno,studentresult FROM result WHERE NOT studentno=1000;
참고: 산술 연산은 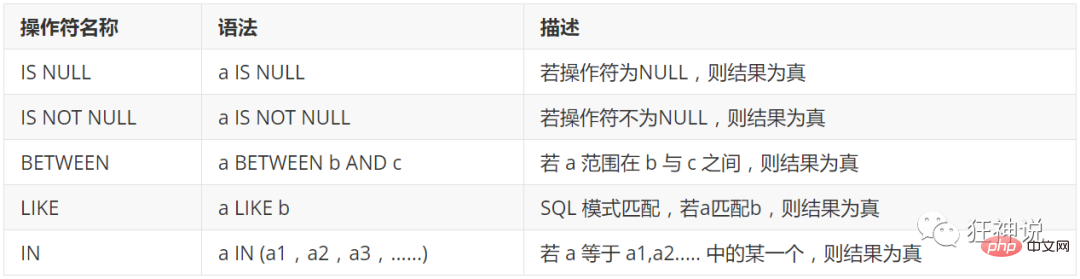
- 데이터만 동일한 데이터 유형을 비교할 수 있습니다.
- Test:
-- 模糊查询 between and \ like \ in \ null -- ============================================= -- LIKE -- ============================================= -- 查询姓刘的同学的学号及姓名 -- like结合使用的通配符 : % (代表0到任意个字符) _ (一个字符) SELECT studentno,studentname FROM student WHERE studentname LIKE '刘%'; -- 查询姓刘的同学,后面只有一个字的 SELECT studentno,studentname FROM student WHERE studentname LIKE '刘_'; -- 查询姓刘的同学,后面只有两个字的 SELECT studentno,studentname FROM student WHERE studentname LIKE '刘__'; -- 查询姓名中含有 嘉 字的 SELECT studentno,studentname FROM student WHERE studentname LIKE '%嘉%'; -- 查询姓名中含有特殊字符的需要使用转义符号 '\' -- 自定义转义符关键字: ESCAPE ':' -- ============================================= -- IN -- ============================================= -- 查询学号为1000,1001,1002的学生姓名 SELECT studentno,studentname FROM student WHERE studentno IN (1000,1001,1002); -- 查询地址在北京,南京,河南洛阳的学生 SELECT studentno,studentname,address FROM student WHERE address IN ('北京','南京','河南洛阳'); -- ============================================= -- NULL 空 -- ============================================= -- 查询出生日期没有填写的同学 -- 不能直接写=NULL , 这是代表错误的 , 用 is null SELECT studentname FROM student WHERE BornDate IS NULL; -- 查询出生日期填写的同学 SELECT studentname FROM student WHERE BornDate IS NOT NULL; -- 查询没有写家庭住址的同学(空字符串不等于null) SELECT studentname FROM student WHERE Address='' OR Address IS NULL;
로그인 후 복사Connection query
JOIN Comparison

/*
连接查询
如需要多张数据表的数据进行查询,则可通过连接运算符实现多个查询
内连接 inner join
查询两个表中的结果集中的交集
外连接 outer join
左外连接 left join
(以左表作为基准,右边表来一一匹配,匹配不上的,返回左表的记录,右表以NULL填充)
右外连接 right join
(以右表作为基准,左边表来一一匹配,匹配不上的,返回右表的记录,左表以NULL填充)
等值连接和非等值连接
自连接
*/
-- 查询参加了考试的同学信息(学号,学生姓名,科目编号,分数)
SELECT * FROM student;
SELECT * FROM result;
/*思路:
(1):分析需求,确定查询的列来源于两个类,student result,连接查询
(2):确定使用哪种连接查询?(内连接)
*/
SELECT s.studentno,studentname,subjectno,StudentResult
FROM student s
INNER JOIN result r
ON r.studentno = s.studentno
-- 右连接(也可实现)
SELECT s.studentno,studentname,subjectno,StudentResult
FROM student s
RIGHT JOIN result r
ON r.studentno = s.studentno
-- 等值连接
SELECT s.studentno,studentname,subjectno,StudentResult
FROM student s , result r
WHERE r.studentno = s.studentno
-- 左连接 (查询了所有同学,不考试的也会查出来)
SELECT s.studentno,studentname,subjectno,StudentResult
FROM student s
LEFT JOIN result r
ON r.studentno = s.studentno
-- 查一下缺考的同学(左连接应用场景)
SELECT s.studentno,studentname,subjectno,StudentResult
FROM student s
LEFT JOIN result r
ON r.studentno = s.studentno
WHERE StudentResult IS NULL
-- 思考题:查询参加了考试的同学信息(学号,学生姓名,科目名,分数)
SELECT s.studentno,studentname,subjectname,StudentResult
FROM student s
INNER JOIN result r
ON r.studentno = s.studentno
INNER JOIN `subject` sub
ON sub.subjectno = r.subjectnorreee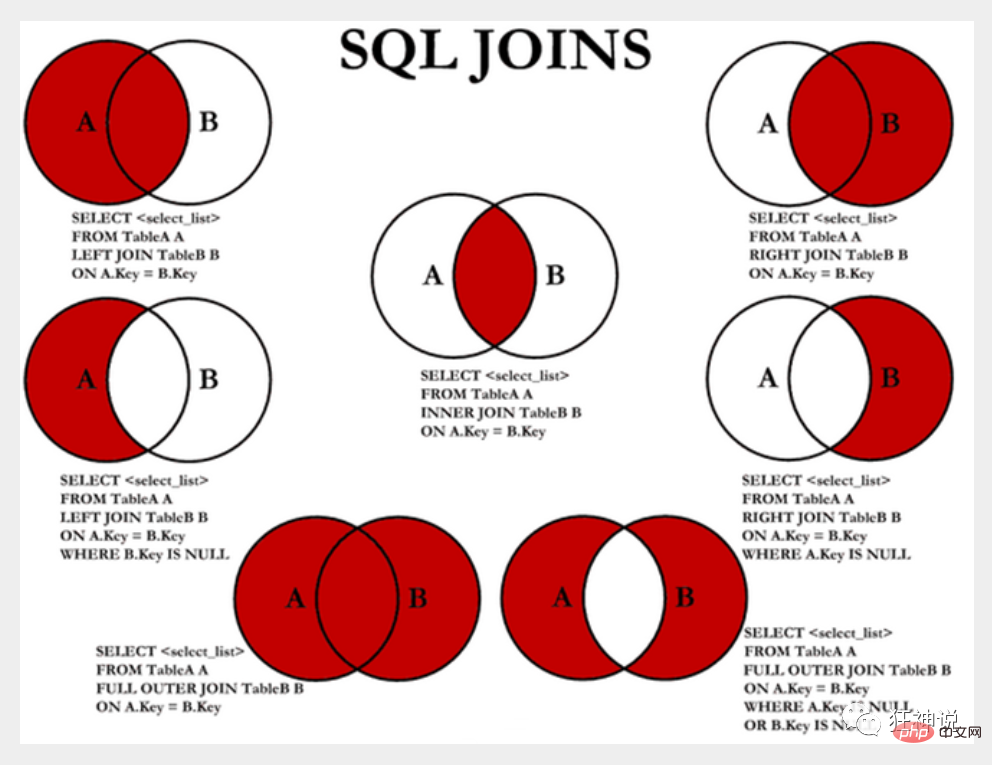 정렬 및 페이징
정렬 및 페이징
Test
/*
自连接
数据表与自身进行连接
需求:从一个包含栏目ID , 栏目名称和父栏目ID的表中
查询父栏目名称和其他子栏目名称
*/
-- 创建一个表
CREATE TABLE `category` (
`categoryid` INT(10) UNSIGNED NOT NULL AUTO_INCREMENT COMMENT '主题id',
`pid` INT(10) NOT NULL COMMENT '父id',
`categoryName` VARCHAR(50) NOT NULL COMMENT '主题名字',
PRIMARY KEY (`categoryid`)
) ENGINE=INNODB AUTO_INCREMENT=9 DEFAULT CHARSET=utf8
-- 插入数据
INSERT INTO `category` (`categoryid`, `pid`, `categoryName`)
VALUES('2','1','信息技术'),
('3','1','软件开发'),
('4','3','数据库'),
('5','1','美术设计'),
('6','3','web开发'),
('7','5','ps技术'),
('8','2','办公信息');
-- 编写SQL语句,将栏目的父子关系呈现出来 (父栏目名称,子栏目名称)
-- 核心思想:把一张表看成两张一模一样的表,然后将这两张表连接查询(自连接)
SELECT a.categoryName AS '父栏目',b.categoryName AS '子栏目'
FROM category AS a,category AS b
WHERE a.`categoryid`=b.`pid`
-- 思考题:查询参加了考试的同学信息(学号,学生姓名,科目名,分数)
SELECT s.studentno,studentname,subjectname,StudentResult
FROM student s
INNER JOIN result r
ON r.studentno = s.studentno
INNER JOIN `subject` sub
ON sub.subjectno = r.subjectno
-- 查询学员及所属的年级(学号,学生姓名,年级名)
SELECT studentno AS 学号,studentname AS 学生姓名,gradename AS 年级名称
FROM student s
INNER JOIN grade g
ON s.`GradeId` = g.`GradeID`
-- 查询科目及所属的年级(科目名称,年级名称)
SELECT subjectname AS 科目名称,gradename AS 年级名称
FROM SUBJECT sub
INNER JOIN grade g
ON sub.gradeid = g.gradeid
-- 查询 数据库结构-1 的所有考试结果(学号 学生姓名 科目名称 成绩)
SELECT s.studentno,studentname,subjectname,StudentResult
FROM student s
INNER JOIN result r
ON r.studentno = s.studentno
INNER JOIN `subject` sub
ON r.subjectno = sub.subjectno
WHERE subjectname='数据库结构-1'Subquery
/*============== 排序 ================
语法 : ORDER BY
ORDER BY 语句用于根据指定的列对结果集进行排序。
ORDER BY 语句默认按照ASC升序对记录进行排序。
如果您希望按照降序对记录进行排序,可以使用 DESC 关键字。
*/
-- 查询 数据库结构-1 的所有考试结果(学号 学生姓名 科目名称 成绩)
-- 按成绩降序排序
SELECT s.studentno,studentname,subjectname,StudentResult
FROM student s
INNER JOIN result r
ON r.studentno = s.studentno
INNER JOIN `subject` sub
ON r.subjectno = sub.subjectno
WHERE subjectname='数据库结构-1'
ORDER BY StudentResult DESC
/*============== 分页 ================
语法 : SELECT * FROM table LIMIT [offset,] rows | rows OFFSET offset
好处 : (用户体验,网络传输,查询压力)
推导:
第一页 : limit 0,5
第二页 : limit 5,5
第三页 : limit 10,5
......
第N页 : limit (pageNo-1)*pageSzie,pageSzie
[pageNo:页码,pageSize:单页面显示条数]
*/
-- 每页显示5条数据
SELECT s.studentno,studentname,subjectname,StudentResult
FROM student s
INNER JOIN result r
ON r.studentno = s.studentno
INNER JOIN `subject` sub
ON r.subjectno = sub.subjectno
WHERE subjectname='数据库结构-1'
ORDER BY StudentResult DESC , studentno
LIMIT 0,5
-- 查询 JAVA第一学年 课程成绩前10名并且分数大于80的学生信息(学号,姓名,课程名,分数)
SELECT s.studentno,studentname,subjectname,StudentResult
FROM student s
INNER JOIN result r
ON r.studentno = s.studentno
INNER JOIN `subject` sub
ON r.subjectno = sub.subjectno
WHERE subjectname='JAVA第一学年'
ORDER BY StudentResult DESC
LIMIT 0,10관련 권장 사항: "
mysql tutorial"
위 내용은 DQL을 사용하여 데이터를 쿼리하는 방법의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7467
7467
 15
1376
52
77
11
46
19
18
20
15
1376
52
77
11
46
19
18
20

 MySQL 사용자와 데이터베이스의 관계
Apr 08, 2025 pm 07:15 PM
MySQL 사용자와 데이터베이스의 관계
Apr 08, 2025 pm 07:15 PM
MySQL 데이터베이스에서 사용자와 데이터베이스 간의 관계는 권한과 테이블로 정의됩니다. 사용자는 데이터베이스에 액세스 할 수있는 사용자 이름과 비밀번호가 있습니다. 권한은 보조금 명령을 통해 부여되며 테이블은 Create Table 명령에 의해 생성됩니다. 사용자와 데이터베이스 간의 관계를 설정하려면 데이터베이스를 작성하고 사용자를 생성 한 다음 권한을 부여해야합니다.
 MySQL : 초보자를위한 데이터 관리의 용이성
Apr 09, 2025 am 12:07 AM
MySQL : 초보자를위한 데이터 관리의 용이성
Apr 09, 2025 am 12:07 AM
MySQL은 설치가 간단하고 강력하며 데이터를 쉽게 관리하기 쉽기 때문에 초보자에게 적합합니다. 1. 다양한 운영 체제에 적합한 간단한 설치 및 구성. 2. 데이터베이스 및 테이블 작성, 삽입, 쿼리, 업데이트 및 삭제와 같은 기본 작업을 지원합니다. 3. 조인 작업 및 하위 쿼리와 같은 고급 기능을 제공합니다. 4. 인덱싱, 쿼리 최적화 및 테이블 파티셔닝을 통해 성능을 향상시킬 수 있습니다. 5. 데이터 보안 및 일관성을 보장하기위한 지원 백업, 복구 및 보안 조치.
 Redshift Zero ETL과의 RDS MySQL 통합
Apr 08, 2025 pm 07:06 PM
Redshift Zero ETL과의 RDS MySQL 통합
Apr 08, 2025 pm 07:06 PM
데이터 통합 단순화 : AmazonRdsMysQL 및 Redshift의 Zero ETL 통합 효율적인 데이터 통합은 데이터 중심 구성의 핵심입니다. 전통적인 ETL (추출, 변환,로드) 프로세스는 특히 데이터베이스 (예 : AmazonRDSMySQL)를 데이터웨어 하우스 (예 : Redshift)와 통합 할 때 복잡하고 시간이 많이 걸립니다. 그러나 AWS는 이러한 상황을 완전히 변경 한 Zero ETL 통합 솔루션을 제공하여 RDSMYSQL에서 Redshift로 데이터 마이그레이션을위한 단순화 된 거의 실시간 솔루션을 제공합니다. 이 기사는 RDSMYSQL ZERL ETL 통합으로 Redshift와 함께 작동하여 데이터 엔지니어 및 개발자에게 제공하는 장점과 장점을 설명합니다.
 MySQL 사용자 이름 및 비밀번호를 작성하는 방법
Apr 08, 2025 pm 07:09 PM
MySQL 사용자 이름 및 비밀번호를 작성하는 방법
Apr 08, 2025 pm 07:09 PM
MySQL 사용자 이름 및 비밀번호를 작성하려면 : 1. 사용자 이름과 비밀번호를 결정합니다. 2. 데이터베이스에 연결; 3. 사용자 이름과 비밀번호를 사용하여 쿼리 및 명령을 실행하십시오.
 MySQL의 쿼리 최적화는 데이터베이스 성능을 향상시키는 데 필수적입니다. 특히 대규모 데이터 세트를 처리 할 때
Apr 08, 2025 pm 07:12 PM
MySQL의 쿼리 최적화는 데이터베이스 성능을 향상시키는 데 필수적입니다. 특히 대규모 데이터 세트를 처리 할 때
Apr 08, 2025 pm 07:12 PM
1. 올바른 색인을 사용하여 스캔 한 데이터의 양을 줄임으로써 데이터 검색 속도를 높이십시오. 테이블 열을 여러 번 찾으면 해당 열에 대한 인덱스를 만듭니다. 귀하 또는 귀하의 앱이 기준에 따라 여러 열에서 데이터가 필요한 경우 복합 인덱스 2를 만듭니다. 2. 선택을 피하십시오 * 필요한 열만 선택하면 모든 원치 않는 열을 선택하면 더 많은 서버 메모리를 선택하면 서버가 높은 부하 또는 주파수 시간으로 서버가 속도가 느려지며, 예를 들어 Creation_at 및 Updated_at 및 Timestamps와 같은 열이 포함되어 있지 않기 때문에 쿼리가 필요하지 않기 때문에 테이블은 선택을 피할 수 없습니다.
 산성 특성 이해 : 신뢰할 수있는 데이터베이스의 기둥
Apr 08, 2025 pm 06:33 PM
산성 특성 이해 : 신뢰할 수있는 데이터베이스의 기둥
Apr 08, 2025 pm 06:33 PM
데이터베이스 산 속성에 대한 자세한 설명 산 속성은 데이터베이스 트랜잭션의 신뢰성과 일관성을 보장하기위한 일련의 규칙입니다. 데이터베이스 시스템이 트랜잭션을 처리하는 방법을 정의하고 시스템 충돌, 전원 중단 또는 여러 사용자의 동시 액세스가 발생할 경우에도 데이터 무결성 및 정확성을 보장합니다. 산 속성 개요 원자력 : 트랜잭션은 불가분의 단위로 간주됩니다. 모든 부분이 실패하고 전체 트랜잭션이 롤백되며 데이터베이스는 변경 사항을 유지하지 않습니다. 예를 들어, 은행 송금이 한 계정에서 공제되지만 다른 계정으로 인상되지 않은 경우 전체 작업이 취소됩니다. BeginTransaction; updateAccountssetBalance = Balance-100WH
 Navicat에서 데이터베이스 비밀번호를 검색 할 수 있습니까?
Apr 08, 2025 pm 09:51 PM
Navicat에서 데이터베이스 비밀번호를 검색 할 수 있습니까?
Apr 08, 2025 pm 09:51 PM
Navicat 자체는 데이터베이스 비밀번호를 저장하지 않으며 암호화 된 암호 만 검색 할 수 있습니다. 솔루션 : 1. 비밀번호 관리자를 확인하십시오. 2. Navicat의 "비밀번호 기억"기능을 확인하십시오. 3. 데이터베이스 비밀번호를 재설정합니다. 4. 데이터베이스 관리자에게 문의하십시오.
 마스터 SQL 한계 절 항의 : 쿼리의 행 수 제어
Apr 08, 2025 pm 07:00 PM
마스터 SQL 한계 절 항의 : 쿼리의 행 수 제어
Apr 08, 2025 pm 07:00 PM
sqllimit 절 : 쿼리 결과의 행 수를 제어하십시오. SQL의 한계 절은 쿼리에서 반환 된 행 수를 제한하는 데 사용됩니다. 이것은 대규모 데이터 세트, 페이지 진화 디스플레이 및 테스트 데이터를 처리 할 때 매우 유용하며 쿼리 효율성을 효과적으로 향상시킬 수 있습니다. 구문의 기본 구문 : SelectColumn1, Collect2, ... Fromtable_namelimitnumber_of_rows; 번호_of_rows : 반환 된 행 수를 지정하십시오. 오프셋이있는 구문 : SelectColumn1, Column2, ... Fromtable_namelimitOffset, number_of_rows; 오프셋 : skip
