

PHP8 기본 커널 소스 코드 구문 분석 - 배열 (4)

本篇文章给大家介绍《解析PHP8底层内核源码-数组(四)》。有一定的参考价值,有需要的朋友可以参考一下,希望对大家有所帮助。
相关文章推荐:《解析PHP8底层内核源码-数组(一)》《解析PHP8底层内核源码-数组(二)》《解析PHP8底层内核源码-数组(三)》
在Runningprocess 里已经知道代码需要经过词法分析 语法分析 编译 执行 四大步骤
PHP 8会在编译阶段(将AST抽象语法树编译成opcode时)就创建一个数组常量。这个数组常量和数字常量、字符串常量一样,是在编译阶段就确定并分配内存的。因此数组的初始化发生在编译阶段。
PHP的数组初始化代码 部分如下
//如果开启zend_debug
#if !ZEND_DEBUG && defined(HAVE_BUILTIN_CONSTANT_P)
# define zend_new_array(size) \
(__builtin_constant_p(size) ? \
((((uint32_t)(size)) <= HT_MIN_SIZE) ? \
_zend_new_array_0() \
//走 _zend_new_array_0
: \
_zend_new_array((size)) \
) \
: \
_zend_new_array((size)) \
)
#else
//没有开启 也就是一般模式 走 _zend_new_array
# define zend_new_array(size) \
_zend_new_array(size)
#endif
ZEND_API void ZEND_FASTCALL _zend_hash_init(HashTable *ht, uint32_t nSize, dtor_func_t pDestructor, zend_bool persistent)
{
_zend_hash_init_int(ht, nSize, pDestructor, persistent);
}
ZEND_API HashTable* ZEND_FASTCALL _zend_new_array_0(void)
{ //分配内存空间
HashTable *ht = emalloc(sizeof(HashTable));
//初始化
_zend_hash_init_int(ht, HT_MIN_SIZE, ZVAL_PTR_DTOR, 0);
return ht;
}
//初始化方法
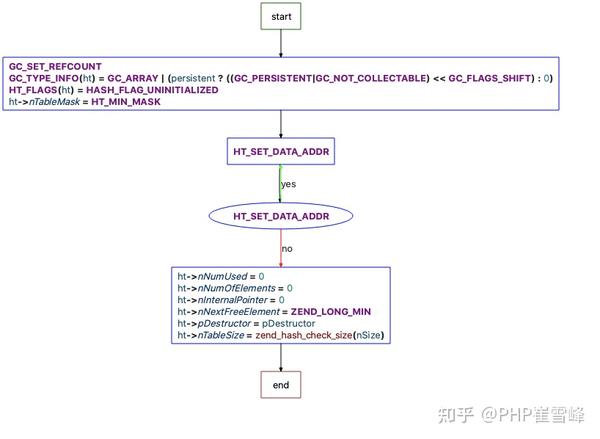
static zend_always_inline void _zend_hash_init_int(HashTable *ht, uint32_t nSize, dtor_func_t pDestructor, zend_bool persistent)
{
GC_SET_REFCOUNT(ht, 1);
GC_TYPE_INFO(ht) = GC_ARRAY | (persistent ? ((GC_PERSISTENT|GC_NOT_COLLECTABLE) << GC_FLAGS_SHIFT) : 0);
HT_FLAGS(ht) = HASH_FLAG_UNINITIALIZED;
ht->nTableMask = HT_MIN_MASK;
HT_SET_DATA_ADDR(ht, &uninitialized_bucket);
ht->nNumUsed = 0;
ht->nNumOfElements = 0;
ht->nInternalPointer = 0;
ht->nNextFreeElement = ZEND_LONG_MIN;
ht->pDestructor = pDestructor;
ht->nTableSize = zend_hash_check_size(nSize);
}
//初始化 bucket 也就是 ardata
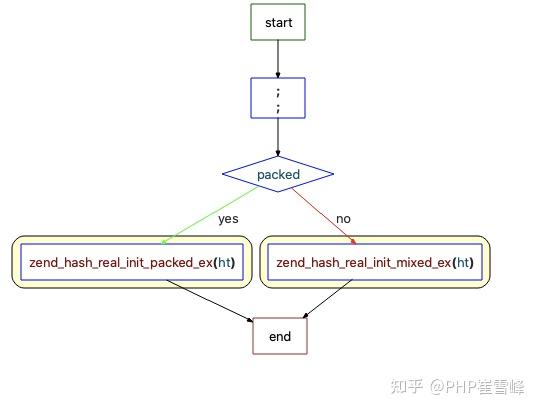
ZEND_API void ZEND_FASTCALL zend_hash_real_init(HashTable *ht, zend_bool packed)
{
IS_CONSISTENT(ht);
HT_ASSERT_RC1(ht);
//调用 zend_hash_real_init_ex方法
zend_hash_real_init_ex(ht, packed);
}
//zend_hash_real_init_ex方法
static zend_always_inline void zend_hash_real_init_ex(HashTable *ht, bool packed)
{
HT_ASSERT_RC1(ht);
ZEND_ASSERT(HT_FLAGS(ht) & HASH_FLAG_UNINITIALIZED);
if (packed) {
//如果是packed_array
zend_hash_real_init_packed_ex(ht);
} else {
//如果是 hash_array
zend_hash_real_init_mixed_ex(ht);
}
}
//paced_array 初始化bucket 的代码
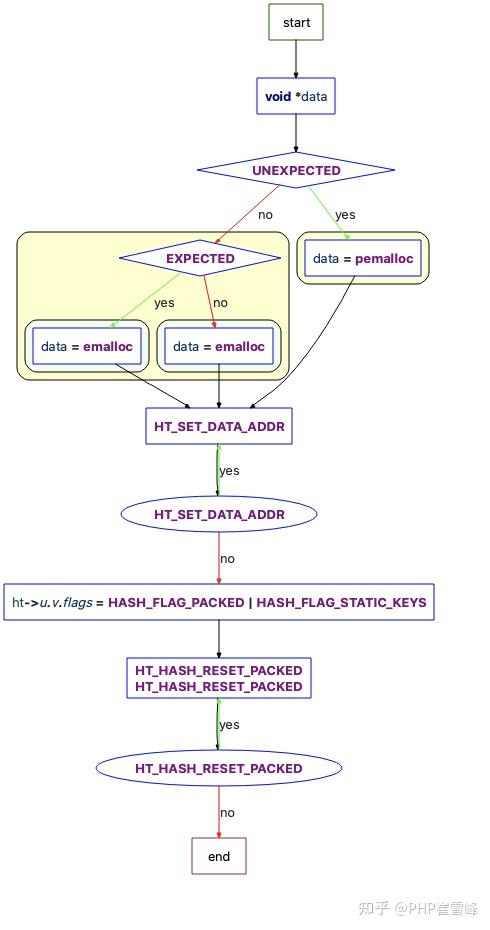
static zend_always_inline void zend_hash_real_init_packed_ex(HashTable *ht)
{
void *data;
if (UNEXPECTED(GC_FLAGS(ht) & IS_ARRAY_PERSISTENT)) {
data = pemalloc(HT_SIZE_EX(ht->nTableSize, HT_MIN_MASK), 1);
} else if (EXPECTED(ht->nTableSize == HT_MIN_SIZE)) {
data = emalloc(HT_SIZE_EX(HT_MIN_SIZE, HT_MIN_MASK));
} else {
data = emalloc(HT_SIZE_EX(ht->nTableSize, HT_MIN_MASK));
}
HT_SET_DATA_ADDR(ht, data);
/* Don't overwrite iterator count. */
ht->u.v.flags = HASH_FLAG_PACKED | HASH_FLAG_STATIC_KEYS;
HT_HASH_RESET_PACKED(ht);
}
//hash_array 初始化bucket的代码
static zend_always_inline void zend_hash_real_init_mixed_ex(HashTable *ht)
{
void *data;
uint32_t nSize = ht->nTableSize;
if (UNEXPECTED(GC_FLAGS(ht) & IS_ARRAY_PERSISTENT)) {
data = pemalloc(HT_SIZE_EX(nSize, HT_SIZE_TO_MASK(nSize)), 1);
} else if (EXPECTED(nSize == HT_MIN_SIZE)) {
data = emalloc(HT_SIZE_EX(HT_MIN_SIZE, HT_SIZE_TO_MASK(HT_MIN_SIZE)));
ht->nTableMask = HT_SIZE_TO_MASK(HT_MIN_SIZE);
HT_SET_DATA_ADDR(ht, data);
/* Don't overwrite iterator count. */
ht->u.v.flags = HASH_FLAG_STATIC_KEYS;
#ifdef __SSE2__
do {
__m128i xmm0 = _mm_setzero_si128();
xmm0 = _mm_cmpeq_epi8(xmm0, xmm0);
_mm_storeu_si128((__m128i*)&HT_HASH_EX(data, 0), xmm0);
_mm_storeu_si128((__m128i*)&HT_HASH_EX(data, 4), xmm0);
_mm_storeu_si128((__m128i*)&HT_HASH_EX(data, 8), xmm0);
_mm_storeu_si128((__m128i*)&HT_HASH_EX(data, 12), xmm0);
} while (0);
#elif defined(__aarch64__)
do {
int32x4_t t = vdupq_n_s32(-1);
vst1q_s32((int32_t*)&HT_HASH_EX(data, 0), t);
vst1q_s32((int32_t*)&HT_HASH_EX(data, 4), t);
vst1q_s32((int32_t*)&HT_HASH_EX(data, 8), t);
vst1q_s32((int32_t*)&HT_HASH_EX(data, 12), t);
} while (0);
#else
HT_HASH_EX(data, 0) = -1;
HT_HASH_EX(data, 1) = -1;
HT_HASH_EX(data, 2) = -1;
HT_HASH_EX(data, 3) = -1;
HT_HASH_EX(data, 4) = -1;
HT_HASH_EX(data, 5) = -1;
HT_HASH_EX(data, 6) = -1;
HT_HASH_EX(data, 7) = -1;
HT_HASH_EX(data, 8) = -1;
HT_HASH_EX(data, 9) = -1;
HT_HASH_EX(data, 10) = -1;
HT_HASH_EX(data, 11) = -1;
HT_HASH_EX(data, 12) = -1;
HT_HASH_EX(data, 13) = -1;
HT_HASH_EX(data, 14) = -1;
HT_HASH_EX(data, 15) = -1;
#endif
return;
} else {
data = emalloc(HT_SIZE_EX(nSize, HT_SIZE_TO_MASK(nSize)));
}
ht->nTableMask = HT_SIZE_TO_MASK(nSize);
HT_SET_DATA_ADDR(ht, data);
HT_FLAGS(ht) = HASH_FLAG_STATIC_KEYS;
HT_HASH_RESET(ht);
}
//数组赋值和更新值
static zend_always_inline zval *_zend_hash_index_add_or_update_i(HashTable *ht, zend_ulong h, zval *pData, uint32_t flag)
{
uint32_t nIndex;
uint32_t idx;
Bucket *p;
IS_CONSISTENT(ht);
HT_ASSERT_RC1(ht);
if ((flag & HASH_ADD_NEXT) && h == ZEND_LONG_MIN) {
h = 0;
}
if (HT_FLAGS(ht) & HASH_FLAG_PACKED) {
if (h < ht->nNumUsed) {
p = ht->arData + h;
if (Z_TYPE(p->val) != IS_UNDEF) {
replace:
if (flag & HASH_ADD) {
return NULL;
}
if (ht->pDestructor) {
ht->pDestructor(&p->val);
}
ZVAL_COPY_VALUE(&p->val, pData);
return &p->val;
} else { /* we have to keep the order :( */
goto convert_to_hash;
}
} else if (EXPECTED(h < ht->nTableSize)) {
add_to_packed:
p = ht->arData + h;
/* incremental initialization of empty Buckets */
if ((flag & (HASH_ADD_NEW|HASH_ADD_NEXT)) != (HASH_ADD_NEW|HASH_ADD_NEXT)) {
if (h > ht->nNumUsed) {
Bucket *q = ht->arData + ht->nNumUsed;
while (q != p) {
ZVAL_UNDEF(&q->val);
q++;
}
}
}
ht->nNextFreeElement = ht->nNumUsed = h + 1;
goto add;
} else if ((h >> 1) < ht->nTableSize &&
(ht->nTableSize >> 1) < ht->nNumOfElements) {
zend_hash_packed_grow(ht);
goto add_to_packed;
} else {
if (ht->nNumUsed >= ht->nTableSize) {
ht->nTableSize += ht->nTableSize;
}
convert_to_hash:
zend_hash_packed_to_hash(ht);
}
} else if (HT_FLAGS(ht) & HASH_FLAG_UNINITIALIZED) {
if (h < ht->nTableSize) {
zend_hash_real_init_packed_ex(ht);
goto add_to_packed;
}
zend_hash_real_init_mixed(ht);
} else {
if ((flag & HASH_ADD_NEW) == 0 || ZEND_DEBUG) {
p = zend_hash_index_find_bucket(ht, h);
if (p) {
ZEND_ASSERT((flag & HASH_ADD_NEW) == 0);
goto replace;
}
}
ZEND_HASH_IF_FULL_DO_RESIZE(ht);/* If the Hash table is full, resize it */
}
idx = ht->nNumUsed++;
nIndex = h | ht->nTableMask;
p = ht->arData + idx;
Z_NEXT(p->val) = HT_HASH(ht, nIndex);
HT_HASH(ht, nIndex) = HT_IDX_TO_HASH(idx);
if ((zend_long)h >= ht->nNextFreeElement) {
ht->nNextFreeElement = (zend_long)h < ZEND_LONG_MAX ? h + 1 : ZEND_LONG_MAX;
}
add:
ht->nNumOfElements++;
p->h = h;
p->key = NULL;
ZVAL_COPY_VALUE(&p->val, pData);
return &p->val;
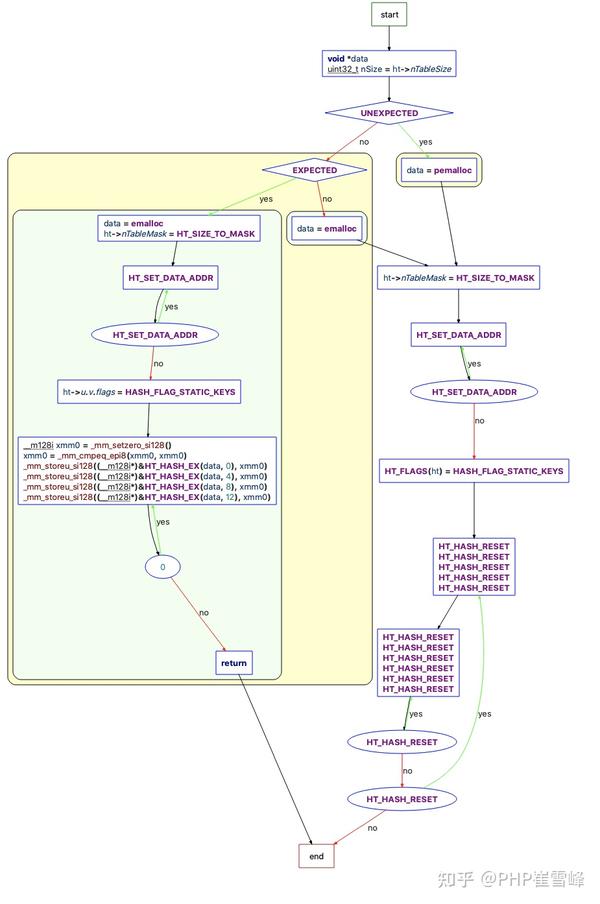
}_zend_hash_init_int 流程图如下


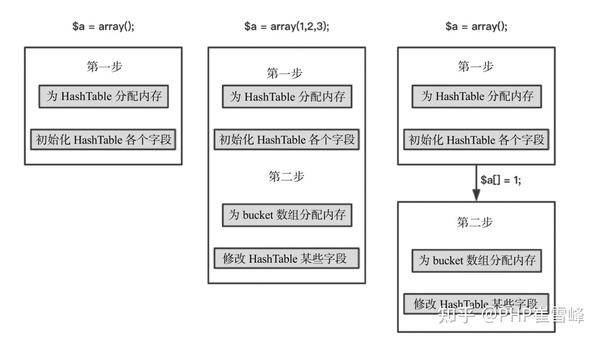
在PHP 8中,数组的初始化其实是分两步的。
第1步:分配HashTable结构体内存
第2步: 初始化HashTable结构体各个字段
第3步:分配bucket数组内存,修改一些字段值。
对于第3步,并不是每次都进行。比如像“$a = array()”这种写法,由于数组为空,PHP 不会额外申请bucket数组内存。而对于“$a = array(1, 2, 3)”这种写法,由于数组非空,因此PHP 需要执行第3步 分配bucket数组内存,修改一些字段值。



▏本文经原作者PHP崔雪峰同意,发布在php中文网,原文地址:https://zhuanlan.zhihu.com/p/361006441
위 내용은 PHP8 기본 커널 소스 코드 구문 분석 - 배열 (4)의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7441
7441
 15
1371
52
76
11
35
19
15
1371
52
76
11
35
19

 foreach 루프를 사용하여 PHP 배열에서 중복 요소를 제거하는 방법은 무엇입니까?
Apr 27, 2024 am 11:33 AM
foreach 루프를 사용하여 PHP 배열에서 중복 요소를 제거하는 방법은 무엇입니까?
Apr 27, 2024 am 11:33 AM
PHP 배열에서 중복 요소를 제거하기 위해 foreach 루프를 사용하는 방법은 다음과 같습니다. 배열을 순회하고 요소가 이미 존재하고 현재 위치가 첫 번째 항목이 아닌 경우 삭제합니다. 예를 들어, 데이터베이스 쿼리 결과에 중복된 레코드가 있는 경우 이 방법을 사용하면 이를 제거하고 중복된 레코드가 없는 결과를 얻을 수 있습니다.
 PHP 배열 키 값 뒤집기: 다양한 방법의 성능 비교 분석
May 03, 2024 pm 09:03 PM
PHP 배열 키 값 뒤집기: 다양한 방법의 성능 비교 분석
May 03, 2024 pm 09:03 PM
PHP 배열 키 값 뒤집기 방법의 성능 비교는 array_flip() 함수가 대규모 배열(100만 개 이상의 요소)에서 for 루프보다 더 나은 성능을 발휘하고 시간이 덜 걸리는 것을 보여줍니다. 키 값을 수동으로 뒤집는 for 루프 방식은 상대적으로 시간이 오래 걸립니다.
 PHP 어레이 딥 카피(Array Deep Copy) 기술: 다양한 방법을 사용하여 완벽한 카피 달성
May 01, 2024 pm 12:30 PM
PHP 어레이 딥 카피(Array Deep Copy) 기술: 다양한 방법을 사용하여 완벽한 카피 달성
May 01, 2024 pm 12:30 PM
PHP에서 배열을 깊게 복사하는 방법에는 json_decode 및 json_encode를 사용한 JSON 인코딩 및 디코딩이 포함됩니다. array_map 및 clone을 사용하여 키와 값의 전체 복사본을 만듭니다. 직렬화 및 역직렬화를 위해 직렬화 및 역직렬화를 사용합니다.
 PHP 배열 다차원 정렬 연습: 간단한 시나리오부터 복잡한 시나리오까지
Apr 29, 2024 pm 09:12 PM
PHP 배열 다차원 정렬 연습: 간단한 시나리오부터 복잡한 시나리오까지
Apr 29, 2024 pm 09:12 PM
다차원 배열 정렬은 단일 열 정렬과 중첩 정렬로 나눌 수 있습니다. 단일 열 정렬은 array_multisort() 함수를 사용하여 열별로 정렬할 수 있습니다. 중첩 정렬에는 배열을 순회하고 정렬하는 재귀 함수가 필요합니다. 실제 사례로는 제품명별 정렬, 판매량 및 가격별 복합 정렬 등이 있습니다.
 PHP 배열 심층 복사 모범 사례: 효율적인 방법 발견
Apr 30, 2024 pm 03:42 PM
PHP 배열 심층 복사 모범 사례: 효율적인 방법 발견
Apr 30, 2024 pm 03:42 PM
PHP에서 배열 전체 복사를 수행하는 가장 좋은 방법은 json_decode(json_encode($arr))를 사용하여 배열을 JSON 문자열로 변환한 다음 다시 배열로 변환하는 것입니다. unserialize(serialize($arr))를 사용하여 배열을 문자열로 직렬화한 다음 새 배열로 역직렬화합니다. RecursiveIteratorIterator를 사용하여 다차원 배열을 재귀적으로 순회합니다.
 데이터 정렬에 PHP 배열 그룹화 기능 적용
May 04, 2024 pm 01:03 PM
데이터 정렬에 PHP 배열 그룹화 기능 적용
May 04, 2024 pm 01:03 PM
PHP의 array_group_by 함수는 키 또는 클로저 함수를 기반으로 배열의 요소를 그룹화하여 키가 그룹 이름이고 값이 그룹에 속한 요소의 배열인 연관 배열을 반환할 수 있습니다.
 PHP 배열 병합 및 중복 제거 알고리즘: 병렬 솔루션
Apr 18, 2024 pm 02:30 PM
PHP 배열 병합 및 중복 제거 알고리즘: 병렬 솔루션
Apr 18, 2024 pm 02:30 PM
PHP 배열 병합 및 중복 제거 알고리즘은 병렬 처리를 위해 원본 배열을 작은 블록으로 나누는 병렬 솔루션을 제공하며, 기본 프로세스는 중복 제거를 위해 블록의 결과를 병합합니다. 알고리즘 단계: 원본 배열을 동일하게 할당된 작은 블록으로 분할합니다. 중복 제거를 위해 각 블록을 병렬로 처리합니다. 차단 결과를 병합하고 다시 중복 제거합니다.
 중복 요소를 찾는 데 있어 PHP 배열 그룹화 기능의 역할
May 05, 2024 am 09:21 AM
중복 요소를 찾는 데 있어 PHP 배열 그룹화 기능의 역할
May 05, 2024 am 09:21 AM
PHP의 array_group() 함수를 사용하면 지정된 키로 배열을 그룹화하여 중복 요소를 찾을 수 있습니다. 이 함수는 다음 단계를 통해 작동합니다. key_callback을 사용하여 그룹화 키를 지정합니다. 선택적으로 value_callback을 사용하여 그룹화 값을 결정합니다. 그룹화된 요소 수를 계산하고 중복 항목을 식별합니다. 따라서 array_group() 함수는 중복된 요소를 찾고 처리하는 데 매우 유용합니다.
