
Divide and Conquer(pide&Conquer), Reference빅데이터 알고리즘: 5억 데이터 정렬
이 total.txt를 500,000,000줄로 정렬합니다. 파일 크기는 4.6G입니다.
10,000줄을 읽을 때마다 정렬하고 새 하위 파일에 씁니다(여기서는 quick sort를 사용합니다).
#!/usr/bin/python2.7
import time
def readline_by_yield(bfile):
with open(bfile, 'r') as rf:
for line in rf:
yield line
def quick_sort(lst):
if len(lst) < 2:
return lst
pivot = lst[0]
left = [ ele for ele in lst[1:] if ele < pivot ]
right = [ ele for ele in lst[1:] if ele >= pivot ]
return quick_sort(left) + [pivot,] + quick_sort(right)
def split_bfile(bfile):
count = 0
nums = []
for line in readline_by_yield(bfile):
num = int(line)
if num not in nums:
nums.append(num)
if 10000 == len(nums):
nums = quick_sort(nums)
with open('subfile/subfile{}.txt'.format(count+1),'w') as wf:
wf.write('\n'.join([ str(i) for i in nums ]))
nums[:] = []
count += 1
print count
now = time.time()
split_bfile('total.txt')
run_t = time.time()-now
print 'Runtime : {}'.format(run_t)은 50,000개의 작은 파일을 생성하며 각 작은 파일의 크기는 약 96K입니다.
프로그램 실행 중 메모리 사용량은 5424kB around

전체 파일 분할을 완료하는 데 94146 초가 걸렸습니다.
#!/usr/bin/python2.7
# -*- coding: utf-8 -*-
import os
import time
testdir = '/ssd/subfile'
now = time.time()
# Step 1 : 获取全部文件描述符
fds = []
for f in os.listdir(testdir):
ff = os.path.join(testdir,f)
fds.append(open(ff,'r'))
# Step 2 : 每个文件获取第一行,即当前文件最小值
nums = []
tmp_nums = []
for fd in fds:
num = int(fd.readline())
tmp_nums.append(num)
# Step 3 : 获取当前最小值放入暂存区,并读取对应文件的下一行;循环遍历。
count = 0
while 1:
val = min(tmp_nums)
nums.append(val)
idx = tmp_nums.index(val)
next = fds[idx].readline()
# 文件读完了
if not next:
del fds[idx]
del tmp_nums[idx]
else:
tmp_nums[idx] = int(next)
# 暂存区保存1000个数,一次性写入硬盘,然后清空继续读。
if 1000 == len(nums):
with open('final_sorted.txt','a') as wf:
wf.write('\n'.join([ str(i) for i in nums ]) + '\n')
nums[:] = []
if 499999999 == count:
break
count += 1
with open('runtime.txt','w') as wf:
wf.write('Runtime : {}'.format(time.time()-now))프로그램 실행 중 메모리 사용량은 약 240M
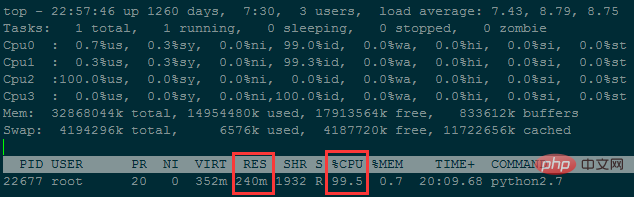

약 38시간 정도 걸렸습니다. ..
메모리 사용량은 줄어들지만 시간 복잡도가 너무 높습니다. 파일 수를 줄이면 메모리 사용량을 더욱 줄일 수 있습니다(각 작은 파일에 저장되는 행 수가 늘어납니다).
# 方法一:手动计算
In [62]: ip
Out[62]: '10.3.81.150'
In [63]: ip.split('.')[::-1]
Out[63]: ['150', '81', '3', '10']
In [64]: [ '{}-{}'.format(idx,num) for idx,num in enumerate(ip.split('.')[::-1]) ]
Out[64]: ['0-150', '1-81', '2-3', '3-10']
In [65]: [256**idx*int(num) for idx,num in enumerate(ip.split('.')[::-1])]
Out[65]: [150, 20736, 196608, 167772160]
In [66]: sum([256**idx*int(num) for idx,num in enumerate(ip.split('.')[::-1])])
Out[66]: 167989654
In [67]:
# 方法二:使用C扩展库来计算
In [71]: import socket,struct
In [72]: socket.inet_aton(ip)
Out[72]: b'\n\x03Q\x96'
In [73]: struct.unpack("!I", socket.inet_aton(ip))
# !表示使用网络字节顺序解析, 后面的I表示unsigned int, 对应Python里的integer or long
Out[73]: (167989654,)
In [74]: struct.unpack("!I", socket.inet_aton(ip))[0]
Out[74]: 167989654
In [75]: socket.inet_ntoa(struct.pack("!I", 167989654))
Out[75]: '10.3.81.150'
In [76]:기본 아이디어: 대용량 파일을 반복적으로 읽고, 대용량 파일을 여러 개의 작은 파일로 분할하고, 마지막으로 이러한 작은 파일을 병합합니다.
분할 규칙:
대용량 파일을 반복적으로 읽고 메모리에 사전을 유지합니다. 키는 문자열이고 값은 문자열의 발생 횟수입니다.
사전에 유지되는 문자열 유형의 수입니다. 10,000에 도달하면(정의할 때 맞춤설정 가능) 사전을 키별로 작은 것부터 큰 것까지 정렬한 다음 작은 파일에 씁니다. 각 줄은 키 값입니다.
그런 다음 사전을 지우고 큰 파일이 나올 때까지 계속 읽으세요. 끝났습니다.
병합 규칙:
먼저 모든 작은 파일의 파일 설명자를 가져온 다음 비교를 위해 첫 번째 줄(즉, 각 작은 파일 문자열 중 가장 작은 ASCII 값을 가진 문자열)을 읽어보세요.
아스키 값이 가장 작은 문자열을 찾아 중복된 경우 발생 횟수를 더한 다음 현재 문자열과 총 횟수를 메모리 목록에 저장합니다.
그런 다음 가장 작은 문자열이 있는 파일의 읽기 포인터를 아래쪽으로 이동합니다. 즉, 다음 비교 라운드를 위해 해당 작은 파일에서 다른 줄을 읽습니다.
메모리에 있는 목록의 개수가 10,000개에 도달하면 목록의 내용이 최종 파일에 기록되어 하드디스크에 한번에 저장됩니다. 동시에 후속 비교를 위해 목록을 지웁니다.
작은 파일을 모두 읽을 때까지 최종 파일은 문자열 ASCII 값에 따라 오름차순으로 정렬된 큰 파일입니다. 각 줄의 내용은 문자열 t의 반복 횟수,
최종 반복입니다. 이 최종 파일의 경우 가장 많이 반복된 파일을 찾으세요.
def readline_by_yield(bfile):
with open(bfile, 'r') as rf:
for line in rf:
yield line
def split_bfile(bfile):
count = 0
d = {}
for line in readline_by_yield(bfile):
line = line.strip()
if line not in d:
d[line] = 0
d[line] += 1
if 10000 == len(d):
text = ''
for string in sorted(d):
text += '{}\t{}\n'.format(string,d[string])
with open('subfile/subfile{}.txt'.format(count+1),'w') as wf:
wf.write(text.strip())
d.clear()
count += 1
text = ''
for string in sorted(d):
text += '{}\t{}\n'.format(string,d[string])
with open('subfile/subfile_end.txt','w') as wf:
wf.write(text.strip())
split_bfile('bigfile.txt')import os
import json
import time
import traceback
testdir = '/ssd/subfile'
now = time.time()
# Step 1 : 获取全部文件描述符
fds = []
for f in os.listdir(testdir):
ff = os.path.join(testdir,f)
fds.append(open(ff,'r'))
# Step 2 : 每个文件获取第一行
tmp_strings = []
tmp_count = []
for fd in fds:
line = fd.readline()
string,count = line.strip().split('\t')
tmp_strings.append(string)
tmp_count.append(int(count))
# Step 3 : 获取当前最小值放入暂存区,并读取对应文件的下一行;循环遍历。
result = []
need2del = []
while True:
min_str = min(tmp_strings)
str_idx = [i for i,v in enumerate(tmp_strings) if v==min_str]
str_count = sum([ int(tmp_count[idx]) for idx in str_idx ])
result.append('{}\t{}\n'.format(min_str,str_count))
for idx in str_idx:
next = fds[idx].readline() # IndexError: list index out of range
# 文件读完了
if not next:
need2del.append(idx)
else:
next_string,next_count = next.strip().split('\t')
tmp_strings[idx] = next_string
tmp_count[idx] = next_count
# 暂存区保存10000个记录,一次性写入硬盘,然后清空继续读。
if 10000 == len(result):
with open('merged.txt','a') as wf:
wf.write(''.join(result))
result[:] = []
# 注意: 文件读完需要删除文件描述符的时候, 需要逆序删除
need2del.reverse()
for idx in need2del:
del fds[idx]
del tmp_strings[idx]
del tmp_count[idx]
need2del[:] = []
if 0 == len(fds):
break
with open('merged.txt','a') as wf:
wf.write(''.join(result))
result[:] = []병합 결과 분석:
| 분할 시 메모리에 유지되는 사전 크기 | 분할할 작은 파일 수 | 병합 시 유지할 파일 설명 기호 수 | 병합 중 메모리 사용량 | 병합 시간 | |
| 처음 | 10000 | 9000 | 9000 ~ 0 | 200M | 병합 속도가 느리고 완료 시간이 계산되지 않았습니다. 아직 |
| 두 번째 | 100000 | 900 | 900 ~ 0 | 27m | 은 2572초로 빠릅니다. |
3. 초 수
import time
def read_line(filepath):
with open(filepath,'r') as rf:
for line in rf:
yield line
start_ts = time.time()
max_str = None
max_count = 0
for line in read_line('merged.txt'):
string,count = line.strip().split('\t')
if int(count) > max_count:
max_count = int(count)
max_str = string
print(max_str,max_count)
print('Runtime {}'.format(time.time()-start_ts))그리고 반환됩니다. 최종 파일은 총 9999788라인이고 크기는 256M입니다. 검색을 수행하는 데 27초가 걸리고 6480KB의 메모리를 차지합니다.
위 내용은 대용량 파일 정렬/외장 메모리 정렬 문제를 이해하기 위한 기사 1개의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!


















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



