

SQL Server의 페이징 방법은 무엇입니까?

이 문서에서는 SQL Server 2012 버전을 사용하여 SQL Server의 페이징 방법에 대해 설명합니다. 다음에서 pageIndex는 페이지 수를 나타내고, pageSize는 한 페이지에 포함된 레코드를 나타냅니다. 다음은 특정 예를 포함하며 쿼리 페이지 2를 설정하고 각 페이지에는 10개의 레코드가 포함됩니다.
먼저 SQL Server의 페이징과 MySQL의 페이징의 차이점에 대해 이야기해 보겠습니다. MySQL의 페이징은 Limit(pageIndex-1) 및 pageSize를 사용하여 직접 완료할 수 있습니다. 그러나 SQL Server에는 Limit 키워드가 없고 top만 있습니다. 제한과 유사한 키워드입니다. 그래서 페이징이 더 번거롭습니다.
내가 아는 SQL 서버 페이징 유형은 4가지뿐입니다. 삼중 루프, max(기본 키) 사용, row_number 키워드 사용, 다음 키워드 오프셋/가져오기(인터넷에서 다른 사람들의 메소드를 수집하여 요약) 이 네 가지 방법의 아이디어만, 다른 방법은 이 변형을 기반으로 합니다.
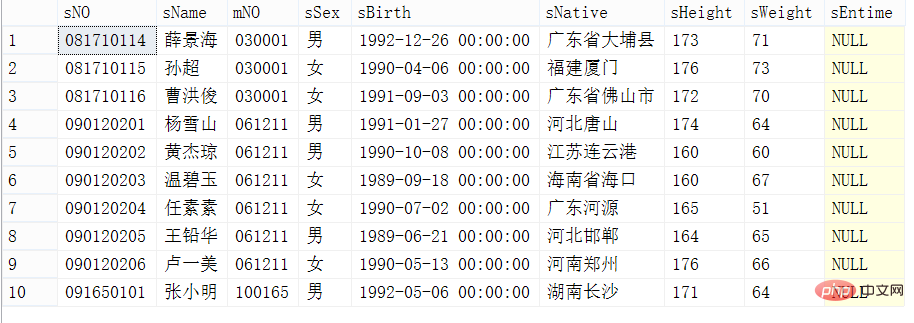
학생 테이블의 레코드 중 쿼리할 부분
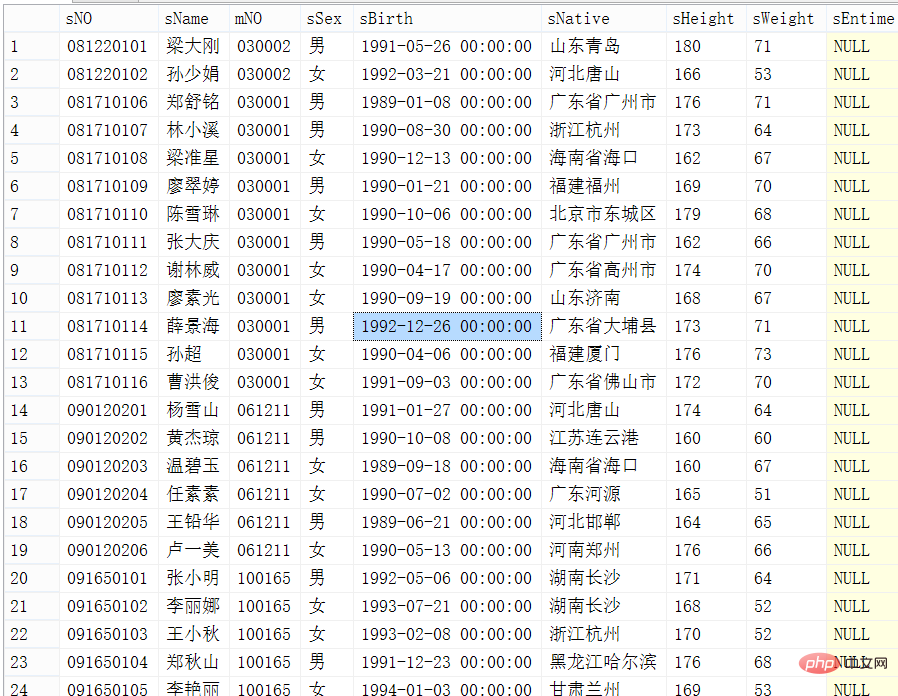
방법 1: 삼중 루프
Idea
먼저 처음 20페이지를 가져온 다음 역순으로, 처음 10개의 레코드를 역순으로 가져오므로 페이징에 필요한 데이터를 얻을 수 있지만 순서가 반대가 됩니다. 그런 다음 다시 순서를 바꾸거나 정렬을 중지하고 정렬을 위해 프런트 엔드에 직접 전달할 수 있습니다.
이 유형으로 간주될 수 있는 또 다른 방법이 있습니다. 여기에는 코드를 넣지 않겠습니다. 먼저 처음 10개의 레코드를 쿼리한 다음 not in을 사용하여 이 10개를 제외하는 것입니다. 기록하고 다시 쿼리하세요.
코드 구현
-- 设置执行时间开始,用来查看性能的 set statistics time on ; -- 分页查询(通用型) select * from (select top pageSize * from (select top (pageIndex*pageSize) * from student order by sNo asc ) -- 其中里面这层,必须指定按照升序排序,省略的话,查询出的结果是错误的。 as temp_sum_student order by sNo desc ) temp_order order by sNo asc -- 分页查询第2页,每页有10条记录 select * from (select top 10 * from (select top 20 * from student order by sNo asc ) -- 其中里面这层,必须指定按照升序排序,省略的话,查询出的结果是错误的。 as temp_sum_student order by sNo desc ) temp_order order by sNo asc ;
쿼리 결과 및 시간
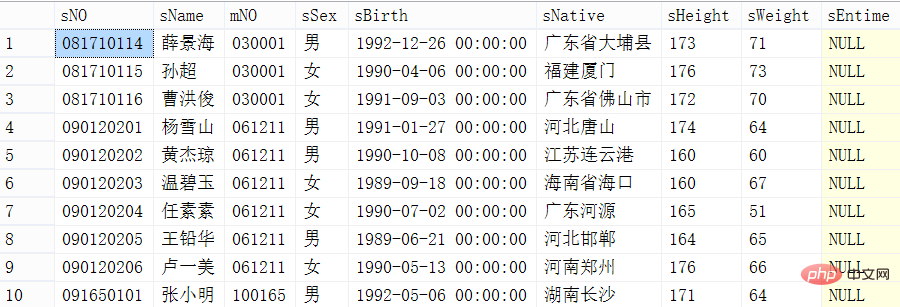

방법 2: max(기본 키) 사용
먼저 레코드의 처음 11행을 맨 위에 놓고 max(id)를 사용하여 가장 큰 값을 얻습니다. 그런 다음 이 테이블의 처음 10개 항목을 다시 쿼리하되 id>max(id)라는 조건을 추가합니다.
코드 구현
set statistics time on; -- 分页查询(通用型) select top pageSize * from student where sNo>= (select max(sNo) from (select top ((pageIndex-1)*pageSize+1) sNo from student order by sNo asc) temp_max_ids) order by sNo; -- 分页查询第2页,每页有10条记录 select top 10 * from student where sNo>= (select max(sNo) from (select top 11 sNo from student order by sNo asc) temp_max_ids) order by sNo;
쿼리 결과 및 시간
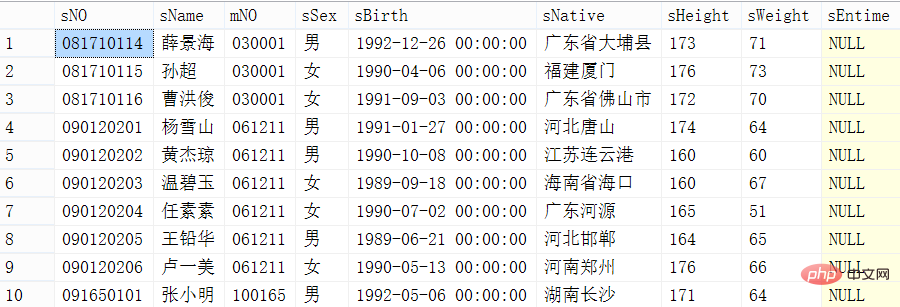

방법 3: row_number 키워드 사용
row_number() over(order by id) 함수를 직접 사용하여 행 수를 계산하고 선택 해당 행 숫자만 반환하지만 이 키워드는 SQL Server 2005 이상에서만 사용할 수 있습니다.
SQL 구현
set statistics time on; -- 分页查询(通用型) select top pageSize * from (select row_number() over(order by sno asc) as rownumber,* from student) temp_row where rownumber>((pageIndex-1)*pageSize); set statistics time on; -- 分页查询第2页,每页有10条记录 select top 10 * from (select row_number() over(order by sno asc) as rownumber,* from student) temp_row where rownumber>10;
쿼리 결과 및 시간
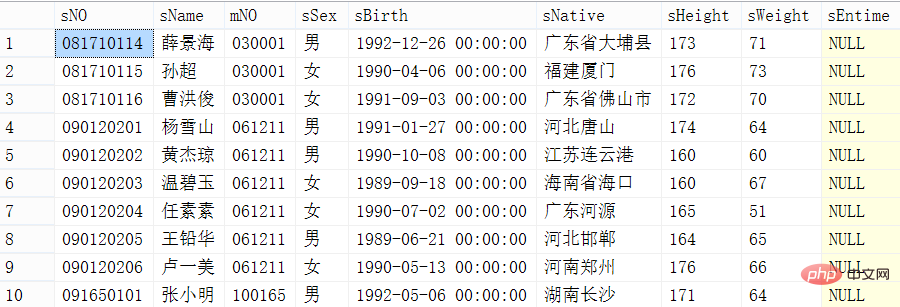

네 번째 방법: offset /fetch next(2012 버전 이상에서만 사용 가능)
코드 구현
set statistics time on; -- 分页查询(通用型) select * from student order by sno offset ((@pageIndex-1)*@pageSize) rows fetch next @pageSize rows only; -- 分页查询第2页,每页有10条记录 select * from student order by sno offset 10 rows fetch next 10 rows only ;
offset A 행, 첫 번째 A 레코드 삭제되고 다음 B 행만 가져오고 B 데이터는 뒤로 읽혀집니다.
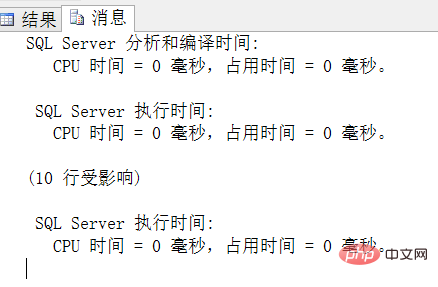
결과 및 실행 시간
캡슐화된 저장 프로시저
마지막으로 모든 사람의 편의를 위해 페이징 저장 프로시저를 캡슐화하여 페이징을 작성할 때가 오면 이 저장 프로시저를 직접 호출할 수 있습니다. .
Paging Stored Procedure
create procedure paging_procedure ( @pageIndex int, -- 第几页 @pageSize int -- 每页包含的记录数 ) as begin select top (select @pageSize) * -- 这里注意一下,不能直接把变量放在这里,要用select from (select row_number() over(order by sno) as rownumber,* from student) temp_row where rownumber>(@pageIndex-1)*@pageSize; end -- 到时候直接调用就可以了,执行如下的语句进行调用分页的存储过程 exec paging_procedure @pageIndex=2,@pageSize=10;
Summary
위 4가지 페이징 방법의 실행 시간을 기준으로 보면 위 4가지 페이징 방법 중 두 번째, 세 번째, 세 번째 방법의 성능이 거의 동일하다는 것을 알 수 있으며, 그러나 세 번째와 네 번째 페이징 방법의 성능은 비슷하며 성능이 좋지 않아 권장되지 않습니다. 또한 이 블로그에서는 소량의 데이터를 테스트 중이고 많은 양의 데이터를 페이징하지 않았기 때문에 많은 양의 데이터를 페이징해야 할 때 어떤 방법이 더 나은 성능을 발휘하는지 명확하지 않습니다. 여기서는 네 번째 방법을 추천합니다. 결국 네 번째 방법은 SQL Server 회사에서 업그레이드한 후 도입한 새로운 방법이므로 이론적으로 성능과 가독성이 더 좋아야 합니다.
관련 추천: "mysql 튜토리얼"
위 내용은 SQL Server의 페이징 방법은 무엇입니까?의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7478
7478
 15
1377
52
77
11
50
19
19
33
15
1377
52
77
11
50
19
19
33

 SQL (수평, 수직)의 다른 유형의 데이터 파티셔닝은 무엇입니까?
Mar 13, 2025 pm 02:01 PM
SQL (수평, 수직)의 다른 유형의 데이터 파티셔닝은 무엇입니까?
Mar 13, 2025 pm 02:01 PM
이 기사는 성능 및 확장성에 미치는 영향에 중점을 둔 SQL의 수평 및 수직 데이터 파티셔닝에 대해 설명합니다. 그것은 그들 사이에서 선택에 대한 혜택과 고려 사항을 비교합니다.
 SQL에서 집계 함수를 사용하여 데이터를 요약하려면 어떻게합니까 (Sum, Avg, Count, Min, Max)?
Mar 13, 2025 pm 01:50 PM
SQL에서 집계 함수를 사용하여 데이터를 요약하려면 어떻게합니까 (Sum, Avg, Count, Min, Max)?
Mar 13, 2025 pm 01:50 PM
이 기사는 SQL 집계 함수 (Sum, Avg, Count, Min, Max)를 사용하여 데이터를 요약하고, 용도와 차이점을 자세히 설명하고, 쿼리로 결합하는 방법 : 159
 동적 SQL을 사용하는 보안 위험은 무엇이며 어떻게 완화 할 수 있습니까?
Mar 13, 2025 pm 01:59 PM
동적 SQL을 사용하는 보안 위험은 무엇이며 어떻게 완화 할 수 있습니까?
Mar 13, 2025 pm 01:59 PM
이 기사는 SQL 주입에 중점을 둔 동적 SQL의 보안 위험에 대해 설명하고 매개 변수화 된 쿼리 및 입력 검증과 같은 완화 전략을 제공합니다.
 SQL의 다른 트랜잭션 격리 수준은 무엇입니까 (커밋되지 않은 읽기, 커밋 된, 반복 가능한 읽기, 직렬화 가능)?
Mar 13, 2025 pm 01:56 PM
SQL의 다른 트랜잭션 격리 수준은 무엇입니까 (커밋되지 않은 읽기, 커밋 된, 반복 가능한 읽기, 직렬화 가능)?
Mar 13, 2025 pm 01:56 PM
이 기사에서는 SQL 트랜잭션 격리 수준에 대해 설명합니다. 부드러운 읽기, 커밋 된 읽기, 반복 가능한 읽기 및 직렬화 가능. 데이터 일관성 및 성능에 미치는 영향을 검토하여 분리가 높을수록 일관성이 높지만 MA
 SQL의 트랜잭션의 산성 특성은 무엇입니까?
Mar 13, 2025 pm 01:54 PM
SQL의 트랜잭션의 산성 특성은 무엇입니까?
Mar 13, 2025 pm 01:54 PM
이 기사는 SQL 트랜잭션의 산성 특성 (원자력, 일관성, 분리, 내구성)에 대해 설명하며 데이터 무결성 및 신뢰성을 유지하는 데 중요합니다.
 SQL을 사용하여 데이터 개인 정보 보호 규정 (GDPR, CCPA)을 어떻게 준수합니까?
Mar 18, 2025 am 11:22 AM
SQL을 사용하여 데이터 개인 정보 보호 규정 (GDPR, CCPA)을 어떻게 준수합니까?
Mar 18, 2025 am 11:22 AM
기사는 GDPR 및 CCPA 준수에 SQL 사용, 데이터 익명화, 액세스 요청 및 오래된 데이터의 자동 삭제에 중점을 둔 (159 자)에 대해 논의합니다.
 SQL 주입과 같은 일반적인 취약점에 대해 SQL 데이터베이스를 어떻게 보호합니까?
Mar 18, 2025 am 11:18 AM
SQL 주입과 같은 일반적인 취약점에 대해 SQL 데이터베이스를 어떻게 보호합니까?
Mar 18, 2025 am 11:18 AM
이 기사에서는 SQL 주입과 같은 취약점에 대한 SQL 데이터베이스 보안, 준비된 문, 입력 유효성 검사 및 정기 업데이트를 강조합니다.
 성능 및 확장 성을 위해 SQL에서 데이터 파티셔닝을 구현하려면 어떻게해야합니까?
Mar 18, 2025 am 11:14 AM
성능 및 확장 성을 위해 SQL에서 데이터 파티셔닝을 구현하려면 어떻게해야합니까?
Mar 18, 2025 am 11:14 AM
기사는 성능 및 확장 성, 세부 사항 방법, 모범 사례 및 모니터링 도구를 위해 SQL에서 데이터 파티셔닝 구현에 대해 논의합니다.
