

MySQL의 트랜잭션 격리에 대해 이야기해 보겠습니다.

이 기사에서는 MySQL의 트랜잭션 격리를 이해하고 트랜잭션의 특성, 격리 수준, 트랜잭션 시작 방법 등을 소개합니다. 모두에게 도움이 되기를 바랍니다!

트랜잭션은 일련의 데이터베이스 작업이 모두 성공하거나 모두 실패하도록 보장하는 것입니다. MySQL에서는 트랜잭션 지원이 엔진 계층에서 구현되지만 모든 엔진이 트랜잭션을 지원하는 것은 아닙니다. 예를 들어 MySQL의 기본 MyISAM 엔진은 트랜잭션을 지원하지 않습니다. [관련 권장 사항: mysql 튜토리얼(동영상)]
1. 트랜잭션의 특성
- 원자성: 트랜잭션의 모든 작업은 완전히 완료되거나 완료되지 않으며 중간 링크 어디에서 끝나지 않습니다. 트랜잭션 실행 중 오류가 발생하면 트랜잭션이 한 번도 실행되지 않은 것처럼 트랜잭션이 시작되기 전 상태로 롤백됩니다. 일관성: 트랜잭션 시작 전과 트랜잭션 종료 후 데이터베이스의 무결성. 격리: 데이터베이스는 여러 동시 트랜잭션이 동시에 데이터를 읽고, 쓰고, 수정할 수 있도록 합니다. 격리는 여러 트랜잭션이 동시에 실행될 때 교차 실행으로 인한 데이터 불일치를 방지할 수 있습니다. 2. 격리 수준 1. 데이터베이스에서 여러 트랜잭션이 동시에 실행되면 더티 읽기, 반복 불가능한 읽기 및 팬텀 읽기 문제가 발생할 수 있습니다.
- 더티 읽기: 트랜잭션 B가 트랜잭션 A의 커밋되지 않은 데이터를 읽습니다.
- 비반복 읽기: 한 트랜잭션이 다른 트랜잭션에 제출된 업데이트 데이터를 읽습니다.
2. 트랜잭션의 격리 수준에는 커밋되지 않은 읽기, 커밋된 읽기, 반복 가능한 읽기 및 직렬화가 포함됩니다.
커밋되지 않은 읽기: 트랜잭션이 아직 제출되지 않은 경우 변경 사항은 다른 트랜잭션에서 볼 수 있습니다.- 커밋 읽기 : 트랜잭션이 제출된 후 변경 사항은 다른 트랜잭션에서 볼 수 있습니다(더티 읽기 해결, Oracle의 기본 격리 수준)
- 반복 읽기 : 트랜잭션 실행 중에 표시되는 데이터는 항상 트랜잭션 실행 시 표시되는 데이터와 일치합니다. 트랜잭션이 시작되고 커밋되지 않은 변경 사항도 다른 트랜잭션에 표시되지 않습니다(더티 읽기 및 반복 불가능한 읽기를 해결하기 위해 MySQL 기본 격리 수준)
- 직렬화: 동일한 레코드 행에 대해 쓰기는 쓰기 잠금을 추가하고 읽기는 읽기-쓰기 잠금 충돌이 발생하면 나중에 액세스되는 트랜잭션은 계속 실행되기 전에 이전 트랜잭션이 완료될 때까지 기다려야 합니다. (더티 읽기, 반복 불가능한 읽기 및 팬텀 읽기에 대한 솔루션)
보안은 순서대로 제출되고 성능은 순서대로 저하됩니다
- 3. 데이터 테이블 T에 컬럼이 하나만 있고, 한 행의 값이 1
create table T(c int) engine=InnoDB; insert into T(c) values(1);
로그인 후 복사이라고 가정하면 다음과 같이 시간순으로 실행됩니다. 두 트랜잭션: 격리 수준이 커밋되지 않은 상태로 읽혀지면 V1은 2입니다. 이때 거래 B는 아직 제출되지 않았지만 A는 그 결과를 확인했습니다. V2와 V3는 모두 2
격리 수준이 읽기-커밋인 경우 V1은 1이고 V2는 2입니다. 트랜잭션 B의 업데이트는 커밋된 후에만 A에서만 볼 수 있습니다. V3도 2
격리 수준이 반복 읽기이면 V1과 V2는 1이고 V3은 2입니다. V2가 1인 이유는 트랜잭션 실행 중에 보이는 데이터가 일관성이 있어야 하기 때문이다. 격리 수준이 직렬화인 경우 V1과 V2의 값은 1, V3의 값은 2이다. 데이터베이스 내부에 뷰가 생성되고 액세스 시 뷰의 논리적 결과가 우선 적용됩니다. 반복 읽기 격리 수준에서 이 뷰는 트랜잭션이 시작될 때 생성되고 트랜잭션 전체에서 사용됩니다. 읽기-커밋 격리 수준에서 이 뷰는 각 SQL 문의 시작 부분에 생성됩니다. 읽기 커밋되지 않은 격리 수준에서는 뷰 개념 없이 레코드의 최신 값을 직접 반환하고, 직렬화된 격리 수준에서는 병렬 액세스를 방지하기 위해 잠금을 직접 사용합니다.
3. 트랜잭션 격리 구현(반복 가능) 예시로 읽기)
- 현재 값은 4이지만 이 레코드를 쿼리할 때 서로 다른 시간에 시작된 트랜잭션은 읽기 보기가 달라집니다. 그림에서 볼 수 있듯이 A, B, C 뷰에서 이 레코드의 값은 각각 1, 2, 4입니다. 동일한 레코드가 시스템 내 여러 버전으로 존재할 수 있습니다. 데이터베이스의 버전 동시성 제어(MVCC). read-viewA의 경우 1을 얻으려면 현재 값에 대해 그림의 모든 롤백 작업을 한 번에 수행해야
- 4를 5로 변경하는 또 다른 트랜잭션이 있어도 이 트랜잭션은 읽기 뷰와 동일합니다. A, B, C에 해당하는 거래는 충돌하지 않습니다
- 显示启动事务语句,begin或start transaction。提交语句是commit,回滚语句是rollback
- set autocommit=0,这个命令将这个线程的自动提交关掉。意味着如果只执行一个select语句,这个事务就启动了,而且不会自动提交事务。这个事务持续存在直到主动执行commit或rollback语句,或者断开连接
- 若row trx_id在数组中,表示这个版本是由还没提交的事务生成的,不可见
- 若row trx_id不在数组中,表示这个版本是已经提交了的事务生成的,可见
- 더 찾아보니 결국 ( 1,1), 저수위보다 작은 행 trx_id=90이 녹색 영역에 있음을 알 수 있습니다. 트랜잭션 A 쿼리에서는 이 데이터 행을 본 결과가 일관적이라고 합니다. 트랜잭션 보기의 경우 자체 업데이트가 항상 표시되는 것 외에도 다음과 같은 세 가지 상황이 있습니다.
- 버전 은(는) 제출되지 않았으며, visible
- 버전이 제출되었지만 뷰가 생성된 후에 제출되었으며, visible
- (1,2)이 제출되었지만 케이스 2에 속하는 뷰 배열이 생성된 후에 제출됨, visible
- (1,1)이 뷰 배열이 생성되기 전에 제출됨, visible
- 트랜잭션 B가 데이터를 업데이트하려고 하면 더 이상 과거 버전을 업데이트할 수 없습니다. 그렇지 않으면 트랜잭션 C의 업데이트가 손실됩니다. 따라서 이때 트랜잭션 B의 집합 k=k+1은 (1,2)
- 에 기초한 연산입니다. 업데이트된 데이터를 먼저 읽고 쓴 후 이 읽기는 현재 값만 읽을 수 있습니다. 읽다. update 문과 더불어 select 문이 잠겨 있는 경우에도 현재 읽기입니다. 트랜잭션 C가 즉시 제출되지 않고 다음 트랜잭션 C'가 된다고 가정하면 어떻게 될까요?
系统会判断,当没有事务再需要用到这些回滚日志时,回滚日志会被删除
四、事务启动的方式
MySQL的事务启动方式有以下几种:
建议使用set autocommit=1,通过显示语句的方式来启动事务
可以在information_schema库中的innodb_trx这个表中查询长事务,如下语句查询持续时间超过60s的事务
select * from information_schema.innodb_trx where TIME_TO_SEC(timediff(now(),trx_started))>60
五、事务隔离还是不隔离
下面是一个只有两行的表的初始化语句:
mysql> CREATE TABLE `t` ( `id` int(11) NOT NULL, `k` int(11) DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB; insert into t(id, k) values(1,1),(2,2);
事务A、B、C的执行流程如下,采用可重复读隔离级别
begin/start transaction命令:不是一个事务的起点,在执行到它们之后的第一个操作InnoDB表的语句,事务才真正启动,一致性视图是在执行第一个快照读语句时创建的
start transaction with consistent snapshot命令:马上启动一个事务,一致性视图是在执行这条命令时创建的
按照上图的流程执行,事务B查到的k的值是3,而事务A查到的k的值是1
1、快照在MVCC里是怎么工作的?
在可重复读隔离级别下,事务启动的时候拍了个快照。这个快照是基于整个库的,那么这个快照是如何实现的?
InnoDB里面每个事务有一个唯一的事务ID,叫做transaction id。它在事务开始的时候向InnoDB的事务系统申请,是按申请顺序严格递增的
每行数据也都是有多个版本的。每次事务更新数据的时候,都会生成一个新的数据版本,并且把transaction id赋值给这个数据版本的事务ID,记作row trx_id。同时,旧的数据版本要保留,并且在新的数据版本中,能够有信息可以直接拿到它。也就是说,数据表中的一行记录,其实可能有多个版本,每个版本有自己的row trx_id
下图是一个记录被多个事务连续更新后的状态:
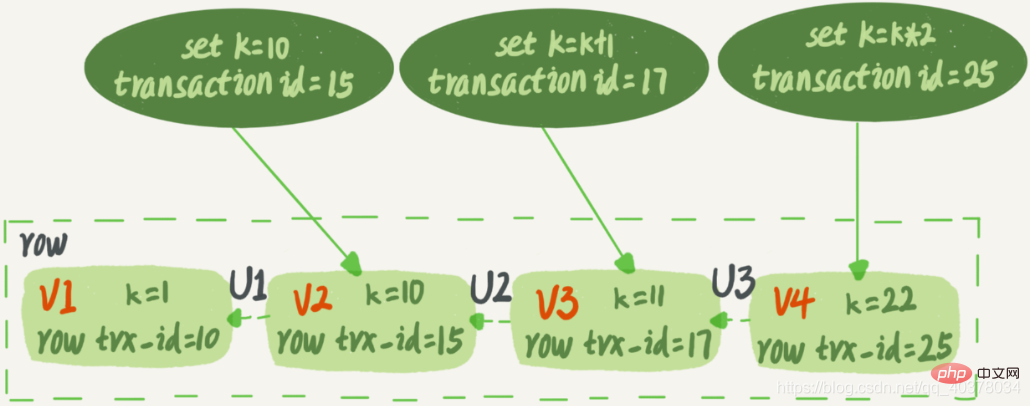
语句更新生成的undo log(回滚日志)就是上图中的是哪个虚线箭头,而V1、V2、V3并不是物理上真实存在的,而是每次需要的时候根据当前版本和undo log计算出来的。比如,需要V2的时候,就是通过V4依次执行U3、U2算出来的
按照可重复读的定义,一个事务启动的时候,能够看到所以已经提交的事务结果。但是之后,这个事务执行期间,其他事务的更新对它不可见。在实现上,InnoDB为每个事务构造了一个数组,用来保存这个事务启动瞬间,当前在启动了但还没提交的所有事务ID。数组里面事务ID的最小值记为低水位,当前系统里面已经创建过的事务ID的最大值加1记为高水位。这个视图数组和高水位就组成了当前事务的一致性视图。而数据的可见性规则,就是基于数据的row trx_id和这个一致性视图的对比结果得到的
这个视图数组把所有的row trx_id分成了几种不同的情况
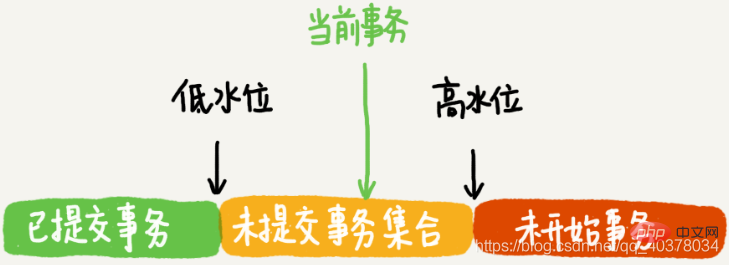
对于当前事务的启动瞬间来说,一个数据版本的row trx_id,有以下几种可能:
1)如果落在绿色部分,表示这个版本是已提交的事务或者是当前事务自己生成的,这个数据是可见的
2)如果落在红色部分,表示这个版本是由将来启动的事务生成的,肯定不可见
3)如果落在黄色部分,那就包括两种情况
InnoDB利用了所有数据都有多个版本的这个特性,实现了秒级创建快照的能力
2、为什么事务A的查询语句返回的结果是k=1?
假设:
1.事务A开始时,系统里面只有一个活跃事务ID是99
2.事务A、B、C的版本号分别是100、101、102
3.三个事务开始前,(1,1)这一行数据的row trx_id是90
이렇게 하면 트랜잭션 A의 배열은 [99,100], 트랜잭션 B의 뷰 배열은 [99,100,101], 트랜잭션 C의 뷰 배열은 [99,100,101,102]
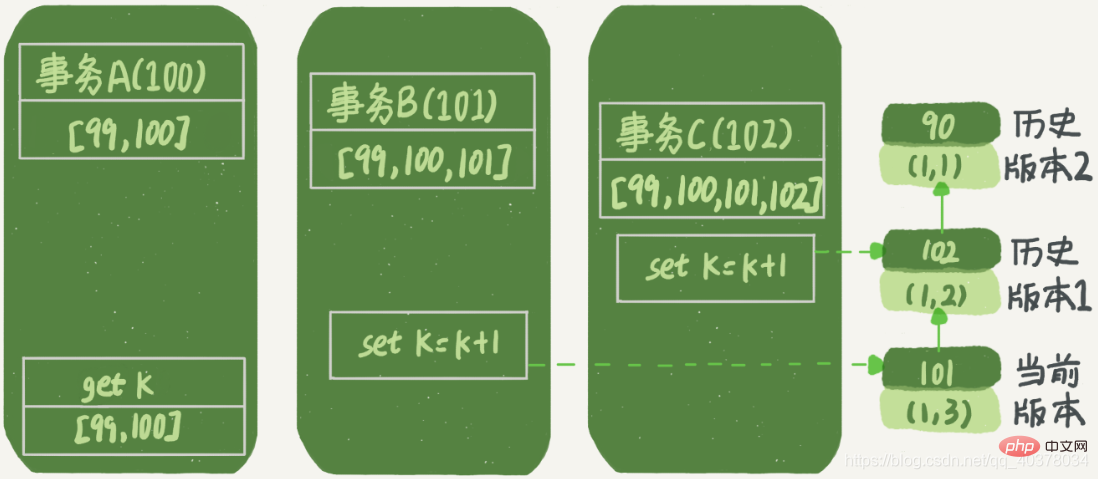
위 그림에서 볼 수 있듯이 , 첫 번째 유효 업데이트는 트랜잭션 C이며 데이터가 (1,1)에서 (1,2)로 변경되었습니다. 이때 이 데이터의 최신 버전의 trx_id 행은 102이고, 버전 90이 과거 버전이 되었습니다
두 번째 유효 업데이트는 트랜잭션 B로, 데이터를 (1,2)에서 (1,3)으로 변경합니다. ) . 이때 이 데이터의 최신 버전은 101이며, 102가 과거 버전이 되었습니다. 트랜잭션 A가 쿼리할 때 트랜잭션 B는 아직 제출되지 않았지만 생성된 버전(1,3)이 현재 버전이 되었습니다. . 하지만 이 버전은 트랜잭션 A에 표시되지 않아야 합니다. 그렇지 않으면 더티 읽기가 됩니다. 이제 트랜잭션 A는 데이터를 읽으려고 하며 해당 뷰 배열은 [99,100]입니다. 데이터 읽기는 현재 버전부터 시작됩니다. 따라서 트랜잭션 A 쿼리문의 데이터 읽기 과정은 다음과 같다.
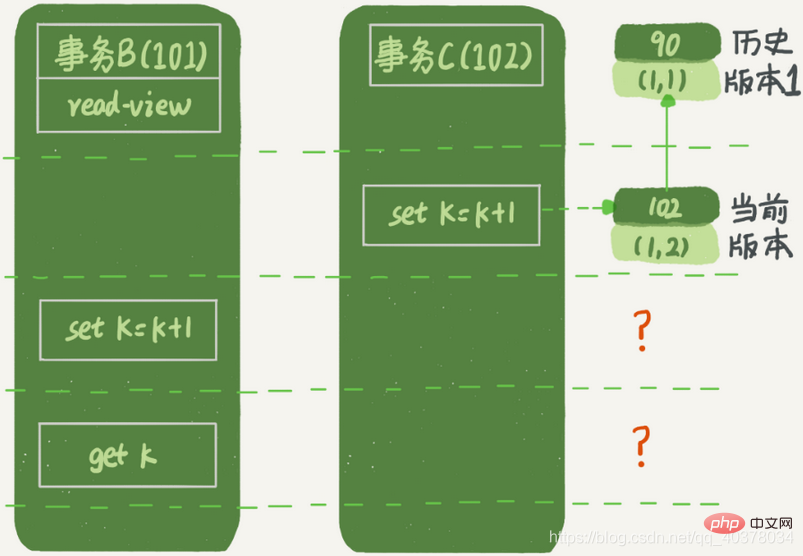
(1,3)을 찾아보면 최고 수위보다 큰 행 trx_id=101이 빨간색 영역에 있다고 판단하고, 그리고 보이지 않음그러다가 위쪽 A 역사적 버전을 찾으면 얼핏 보면 고수위보다 큰 행 trx_id=102가 빨간색 영역에 있고 보이지 않음버전이 제출되었으며, 뷰가 생성되기 전에 제출되었음을 알 수 있습니다. 트랜잭션 A가 시작될 때 트랜잭션 A의 쿼리문이 생성되었습니다. 이때
(1,3)은 아직 제출되지 않았으며 Case 1에 속하며, visible위 그림에서는 트랜잭션 C가 업데이트된 후 즉시 제출되지 않았습니다. 제출되기 전에 트랜잭션 B의 업데이트 명세서가 먼저 시작되었습니다. 트랜잭션 C는 아직 제출되지 않았지만 버전 (1,2)이 생성되어 최신 버전입니다. 이때 2단계 잠금 프로토콜이 포함되어 있어 트랜잭션 C가 제출되지 않았습니다. (1,2) 이 버전의 쓰기 잠금은 아직 해제되지 않았습니다. 그리고 트랜잭션 B는 현재 읽기이므로 최신 버전을 읽어야 하며 잠겨 있어야 하므로 현재 읽기를 계속하려면 트랜잭션 C가 잠금을 해제할 때까지 기다려야 합니다.
7. 트랜잭션 가용성 반복 읽기 기능은 어떻게 달성됩니까?
반복 읽기의 핵심은 일관된 읽기입니다. 트랜잭션이 데이터를 업데이트하면 현재 읽기만 사용할 수 있습니다. 현재 레코드의 행 잠금이 다른 트랜잭션에 의해 점유된 경우 잠금 대기를 입력해야 합니다.
읽기 커밋 논리는 반복 읽기 논리와 유사합니다. 주요 차이점은 다음과 같습니다. 반복 가능 아래에 있습니다. 읽기 격리 수준에서는 트랜잭션 시작 시 일관된 뷰만 생성하면 트랜잭션의 다른 쿼리가 이 일관된 뷰를 공유합니다.
반복 가능 아래에 있습니다. 읽기 격리 수준에서는 트랜잭션 시작 시 일관된 뷰만 생성하면 트랜잭션의 다른 쿼리가 이 일관된 뷰를 공유합니다.
자세히 프로그래밍 관련 지식을 보려면 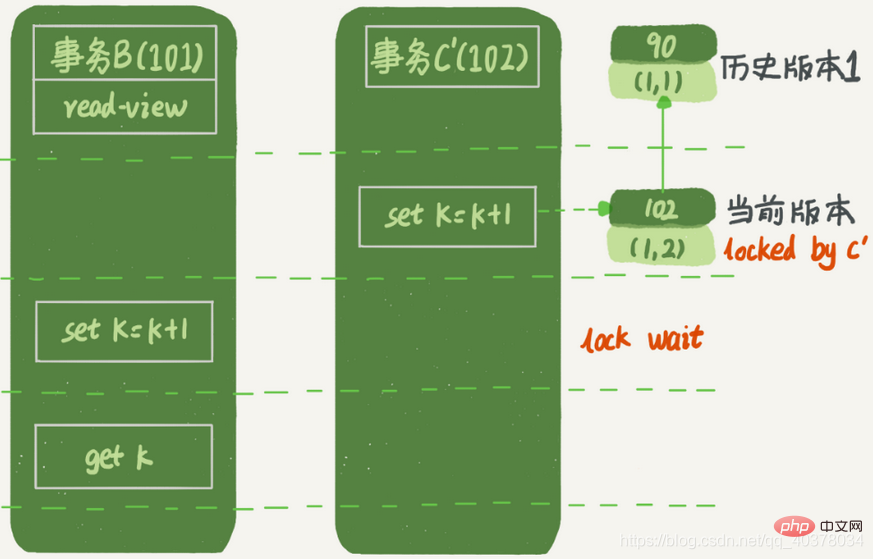 프로그래밍 비디오
프로그래밍 비디오
위 내용은 MySQL의 트랜잭션 격리에 대해 이야기해 보겠습니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

Video Face Swap
완전히 무료인 AI 얼굴 교환 도구를 사용하여 모든 비디오의 얼굴을 쉽게 바꾸세요!

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7677
7677
 15
1393
52
1207
24
91
11
73
19
15
1393
52
1207
24
91
11
73
19

 phpmyadmin을 여는 방법
Apr 10, 2025 pm 10:51 PM
phpmyadmin을 여는 방법
Apr 10, 2025 pm 10:51 PM
다음 단계를 통해 phpmyadmin을 열 수 있습니다. 1. 웹 사이트 제어판에 로그인; 2. phpmyadmin 아이콘을 찾고 클릭하십시오. 3. MySQL 자격 증명을 입력하십시오. 4. "로그인"을 클릭하십시오.
 MySQL : 세계에서 가장 인기있는 데이터베이스 소개
Apr 12, 2025 am 12:18 AM
MySQL : 세계에서 가장 인기있는 데이터베이스 소개
Apr 12, 2025 am 12:18 AM
MySQL은 오픈 소스 관계형 데이터베이스 관리 시스템으로, 주로 데이터를 신속하고 안정적으로 저장하고 검색하는 데 사용됩니다. 작업 원칙에는 클라이언트 요청, 쿼리 해상도, 쿼리 실행 및 반환 결과가 포함됩니다. 사용의 예로는 테이블 작성, 데이터 삽입 및 쿼리 및 조인 작업과 같은 고급 기능이 포함됩니다. 일반적인 오류에는 SQL 구문, 데이터 유형 및 권한이 포함되며 최적화 제안에는 인덱스 사용, 최적화 된 쿼리 및 테이블 분할이 포함됩니다.
 MySQL의 장소 : 데이터베이스 및 프로그래밍
Apr 13, 2025 am 12:18 AM
MySQL의 장소 : 데이터베이스 및 프로그래밍
Apr 13, 2025 am 12:18 AM
데이터베이스 및 프로그래밍에서 MySQL의 위치는 매우 중요합니다. 다양한 응용 프로그램 시나리오에서 널리 사용되는 오픈 소스 관계형 데이터베이스 관리 시스템입니다. 1) MySQL은 웹, 모바일 및 엔터프라이즈 레벨 시스템을 지원하는 효율적인 데이터 저장, 조직 및 검색 기능을 제공합니다. 2) 클라이언트 서버 아키텍처를 사용하고 여러 스토리지 엔진 및 인덱스 최적화를 지원합니다. 3) 기본 사용에는 테이블 작성 및 데이터 삽입이 포함되며 고급 사용에는 다중 테이블 조인 및 복잡한 쿼리가 포함됩니다. 4) SQL 구문 오류 및 성능 문제와 같은 자주 묻는 질문은 설명 명령 및 느린 쿼리 로그를 통해 디버깅 할 수 있습니다. 5) 성능 최적화 방법에는 인덱스의 합리적인 사용, 최적화 된 쿼리 및 캐시 사용이 포함됩니다. 모범 사례에는 거래 사용 및 준비된 체계가 포함됩니다
 MySQL을 사용하는 이유는 무엇입니까? 혜택과 장점
Apr 12, 2025 am 12:17 AM
MySQL을 사용하는 이유는 무엇입니까? 혜택과 장점
Apr 12, 2025 am 12:17 AM
MySQL은 성능, 신뢰성, 사용 편의성 및 커뮤니티 지원을 위해 선택됩니다. 1.MYSQL은 효율적인 데이터 저장 및 검색 기능을 제공하여 여러 데이터 유형 및 고급 쿼리 작업을 지원합니다. 2. 고객-서버 아키텍처 및 다중 스토리지 엔진을 채택하여 트랜잭션 및 쿼리 최적화를 지원합니다. 3. 사용하기 쉽고 다양한 운영 체제 및 프로그래밍 언어를 지원합니다. 4. 강력한 지역 사회 지원을 받고 풍부한 자원과 솔루션을 제공합니다.
 Apache의 데이터베이스에 연결하는 방법
Apr 13, 2025 pm 01:03 PM
Apache의 데이터베이스에 연결하는 방법
Apr 13, 2025 pm 01:03 PM
Apache는 데이터베이스에 연결하여 다음 단계가 필요합니다. 데이터베이스 드라이버 설치. 연결 풀을 만들려면 Web.xml 파일을 구성하십시오. JDBC 데이터 소스를 작성하고 연결 설정을 지정하십시오. JDBC API를 사용하여 Connections, 명세서 작성, 매개 변수 바인딩, 쿼리 또는 업데이트 실행 및 처리를 포함하여 Java 코드의 데이터베이스에 액세스하십시오.
 Docker의 MySQL을 시작하는 방법
Apr 15, 2025 pm 12:09 PM
Docker의 MySQL을 시작하는 방법
Apr 15, 2025 pm 12:09 PM
Docker에서 MySQL을 시작하는 프로세스는 다음 단계로 구성됩니다. MySQL 이미지를 가져와 컨테이너를 작성하고 시작하고 루트 사용자 암호를 설정하고 포트 확인 연결을 매핑하고 데이터베이스를 작성하고 사용자는 데이터베이스에 모든 권한을 부여합니다.
 Centos 설치 MySQL
Apr 14, 2025 pm 08:09 PM
Centos 설치 MySQL
Apr 14, 2025 pm 08:09 PM
Centos에 MySQL을 설치하려면 다음 단계가 필요합니다. 적절한 MySQL Yum 소스 추가. mysql 서버를 설치하려면 yum install mysql-server 명령을 실행하십시오. mysql_secure_installation 명령을 사용하여 루트 사용자 비밀번호 설정과 같은 보안 설정을 작성하십시오. 필요에 따라 MySQL 구성 파일을 사용자 정의하십시오. MySQL 매개 변수를 조정하고 성능을 위해 데이터베이스를 최적화하십시오.
 CentOS7에 MySQL을 설치하는 방법 7
Apr 14, 2025 pm 08:30 PM
CentOS7에 MySQL을 설치하는 방법 7
Apr 14, 2025 pm 08:30 PM
MySQL을 우아하게 설치하는 열쇠는 공식 MySQL 저장소를 추가하는 것입니다. 특정 단계는 다음과 같습니다. 피싱 공격을 방지하기 위해 MySQL 공식 GPG 키를 다운로드하십시오. MySQL 리포지토리 파일 추가 : rpm -uvh https://dev.mysql.com/get/mysql80-community-release-el7-3.noarch.rpm yum repository cache : yum 업데이트 설치 mysql : yum 설치 mysql-server startup startup mysql 서비스 : systemctl start mysqlctl start mysqlctl.
