

이 기사에서는 MySQL의 마스터-슬레이브, 마스터-슬레이브 및 읽기-쓰기 분리에 대해 설명합니다. 도움이 되기를 바랍니다.
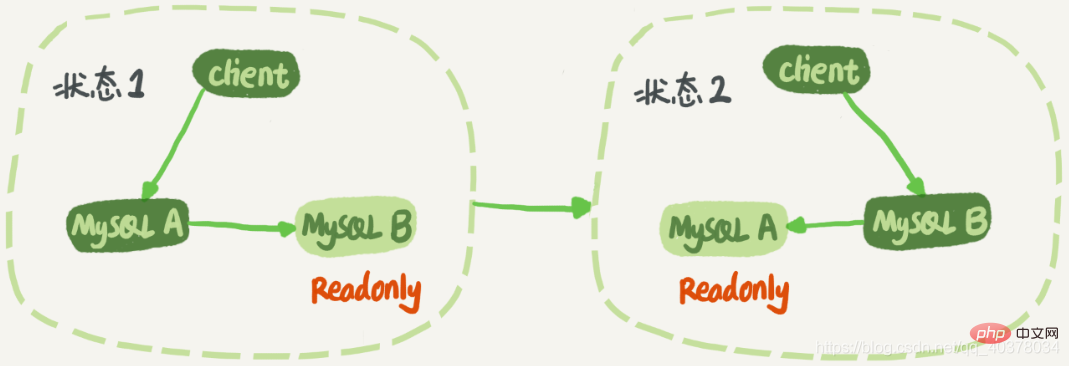
상태 1에서 클라이언트는 읽기 및 쓰기를 위해 노드 A에 직접 액세스하고 노드 B는 A의 백업 데이터베이스입니다. A의 업데이트를 동기화할 뿐입니다. 로컬로 실행됩니다. 이는 노드 B와 A의 데이터를 동일하게 유지합니다. 전환이 필요한 경우 상태 2로 전환합니다. 이때 클라이언트는 노드 B에 읽고 쓰는데, 노드 A는 B의 대기 데이터베이스이다. [관련 권장 사항: mysql 동영상 튜토리얼]
상태 1에서는 노드 B에 직접 접속하지 않지만 대기 노드 B를 읽기 전용 모드로 설정하는 것이 좋습니다. 몇 가지 이유가 있습니다:
1. 일부 작동 쿼리 문은 확인을 위해 대기 데이터베이스에 저장됩니다. 이를 읽기 전용으로 설정하면 오작동을 방지할 수 있습니다.
2. 전환 논리의 버그를 방지할 수 있습니다. 노드의 역할을 결정하려면 읽기 전용 상태를 사용하세요
대기 데이터베이스가 읽기 전용으로 설정된 경우 어떻게 기본 데이터베이스와 동기식으로 업데이트할 수 있나요?
최고 권한이 있는 사용자에게는 읽기 전용 설정이 유효하지 않으며 동기화 업데이트에 사용되는 스레드에는 최고 권한이 있습니다
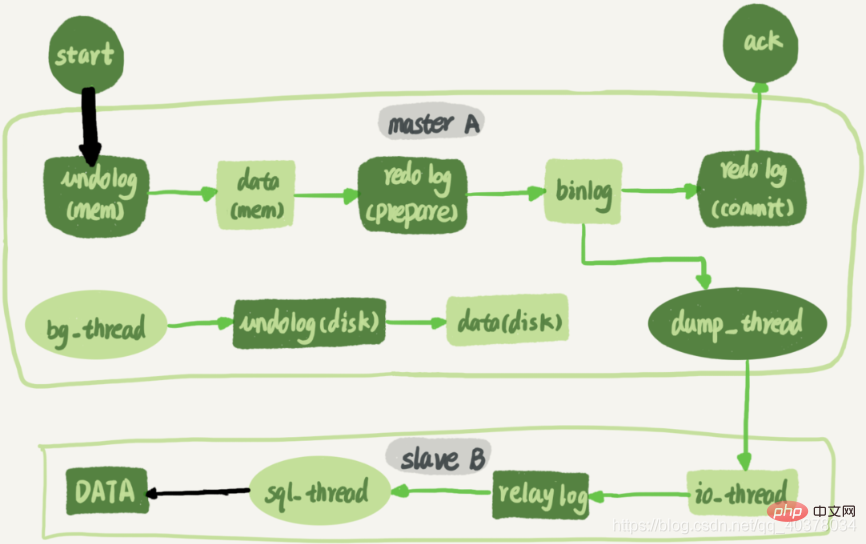
다음 그림은 노드 A에서 실행된 후 노드 B에 동기화되는 업데이트 문의 전체 흐름도입니다.
대기 데이터베이스 B와 기본 데이터베이스 A 간에 긴 연결이 유지됩니다. 기본 라이브러리 A 내부에는 대기 라이브러리 B의 긴 연결을 제공하는 전용 스레드가 있습니다. 트랜잭션 로그 동기화의 전체 프로세스는 다음과 같습니다. 
1. 대기 데이터베이스 B에서 마스터 변경 명령을 사용하여 기본 데이터베이스 A의 IP, 포트, 사용자 이름, 비밀번호 및 binlog를 요청할 위치를 설정합니다. 위치에는 파일 이름과 로그 오프셋이 포함됩니다
2. 대기 데이터베이스 B에서 start 슬레이브 명령을 실행합니다. 이때 대기 데이터베이스는 그림의 io_thread 및 sql_thread라는 두 개의 스레드를 시작합니다. 그 중 io_thread는 메인 라이브러리와의 연결을 담당합니다
3. 메인 라이브러리 A가 사용자 이름과 비밀번호를 확인한 후 대기 라이브러리 B가 전달한 위치에 따라 로컬에서 binlog를 읽기 시작합니다. B
4. binlog를 가져온 후 전송 로그라는 로컬 파일에 씁니다
5.sql_thread는 전송 로그를 읽고 로그에 있는 명령을 구문 분석하고 실행합니다
멀티 스레드 복제 방식의 도입으로 sql_thread는 다중 스레드로 진화했습니다.
2. 순환 복제 문제 노드 A와 노드 B는 서로 마스터-대기 관계를 갖습니다. 이렇게 하면 전환 중에 활성-대기 관계를 수정할 필요가 없습니다. 이중 M 구조에서는 해결해야 할 문제가 있습니다. 비즈니스 로직은 노드 A의 명령문을 업데이트한 후 생성된 binlog를 노드 B. 노드 B가 실행된 후 이 Binlog는 업데이트 문 후에도 생성됩니다. 그러면 노드 A가 노드 B의 대기 데이터베이스이기도 하면 새로 생성된 노드 B의 binlog를 가져와서 한 번 실행하는 것과 같습니다. 그러면 노드 A와 B 사이의 루프에서 업데이트 문이 계속 실행됩니다. 즉, 루프 복제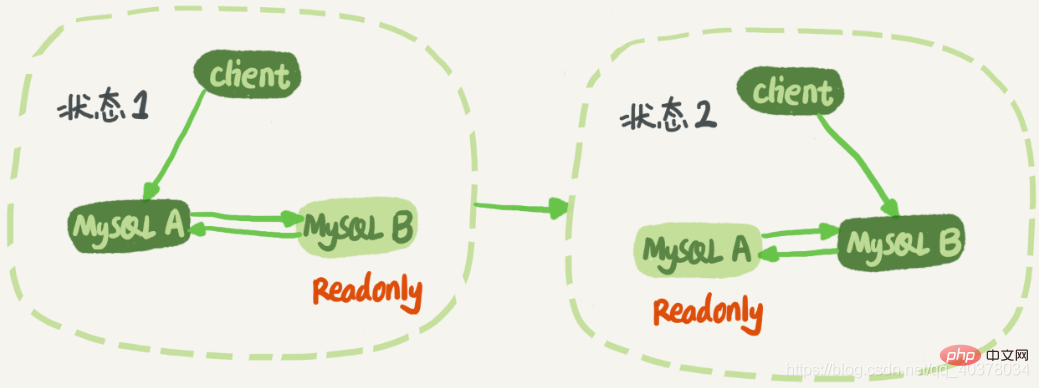
MySQL은 이 명령이 처음 실행된 인스턴스의 서버 ID를 binlog에 기록합니다. 따라서 두 노드 간의 순환 복제 문제를 해결하려면 다음 논리를 사용할 수 있습니다.
1. 두 라이브러리의 서버 ID가 서로 달라야 하며, 마스터로 설정할 수 없습니다. -백업 관계
2 .대기 데이터베이스는 binlog를 수신하고 재생 프로세스 중에 원본 binlog
3와 동일한 서버 ID로 새 binlog를 생성합니다. 각 데이터베이스는 기본 데이터베이스에서 전송된 로그를 수신한 후 먼저 서버 아이디가 자신의 것과 동일하다면 로그가 직접 생성된 것이므로 로그를 직접 폐기하세요
이중 M 구조 로그의 실행 흐름은 다음과 같습니다.
1. 업데이트된 트랜잭션은 다음과 같습니다. A 노드에서 생성된 binlog는 A의 서버 id
2에 기록됩니다. B 노드로 한 번 전송된 후 B 노드에서 생성된 binlog의 서버 ID는 A의 서버 id
3으로 다시 전송됩니다. 노드 A와 A는 서버 ID가 자신의 것과 동일하다고 판단합니다. 이 로그는 다시 처리되지 않습니다. 따라서 여기서 무한 루프가 깨졌습니다
3. 1차 및 2차 지연 1. 1차 및 2차 지연이란 무엇입니까? 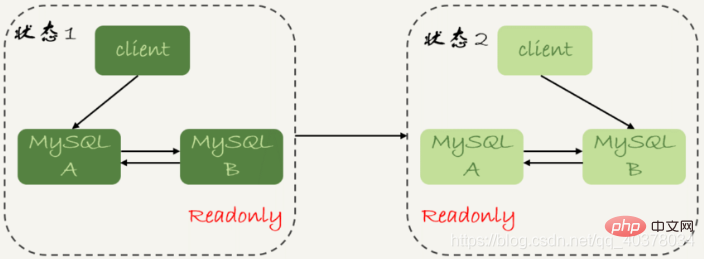
2로 기록됩니다. B가 이 binlog 수신을 완료하는 순간을 T2
3으로 기록합니다. 대기 데이터베이스 B가 이 트랜잭션을 실행한 후 그 순간을 T3
으로 기록합니다. 소위 마스터-대기 지연을 의미합니다. Standby Database가 실행되는 시점과 Master Database가 실행되는 시점 사이에 동일한 트랜잭션이 완료된다는 것을 의미한다. 실행 완료 시점의 차이, 즉 T3-T1
Standby Database에서 showslave status 명령을 실행할 수 있으며, 반환 결과에는 현재 대기 데이터베이스가 몇 초 동안 지연되었는지 나타내는 데 사용되는 second_behind_master가 표시됩니다.
seconds_behind_master 계산 방법은 다음과 같습니다.
1. 각 트랜잭션의 binlog에는 시간 필드가 있으며, 이는 기본 데이터베이스에 기록된 시간을 기록하는 데 사용됩니다.
2. 대기 데이터베이스는 현재 실행 중인 트랜잭션의 시간 필드 값을 가져와서 계산합니다. 현재 시스템 시간과의 차이입니다. 차이점, gets_behind_master
마스터 및 백업 데이터베이스 머신의 시스템 시간 설정이 일치하지 않더라도 마스터 및 백업 지연 값이 부정확해지는 원인은 아닙니다. 스탠바이 데이터베이스가 메인 데이터베이스에 접속되면 SELECTUNIX_TIMESTAMP() 함수를 통해 현재 메인 데이터베이스의 시스템 시간을 얻어온다. 이때 기본 데이터베이스의 시스템 시간이 자체 시간과 일치하지 않는 것으로 확인되면 대기 데이터베이스는 second_behind_master 계산을 실행할 때 이 차이를 자동으로 차감합니다.
정상적인 네트워크 조건에서 활성 데이터베이스와 대기 데이터베이스 간의 지연의 주요 원인은 데이터베이스는 대기 데이터베이스가 binlog를 수신하고 실행을 완료한 후의 시간입니다. 이 트랜잭션 간의 시간 차이
마스터-백업 지연의 가장 직접적인 징후는 백업 데이터베이스가 전송 로그를 사용하는 속도가 전송 로그보다 느리다는 것입니다. 기본 데이터베이스가 binlog를 생성하는 속도
1. 일부 배포 조건에서 대기 데이터베이스가 위치한 머신의 성능이 머신보다 떨어집니다. 2. 대기 데이터베이스는 큰 압박을 받고 있습니다. 기본 데이터베이스는 쓰기 기능을 제공하고 대기 데이터베이스는 일부 읽기 기능을 제공합니다. 대기 데이터베이스의 압력 제어를 무시하면 대기 데이터베이스에 대한 쿼리는 CPU 리소스를 많이 소비하고 동기화 속도에 영향을 미치며 마스터 및 백업 지연을 유발합니다.
하나의 마스터와 백업을 수행할 수 있습니다. 여러 노예. 대기 데이터베이스 외에도 여러 개의 슬레이브 라이브러리를 연결하여 읽기 압력을 공유할 수 있습니다Hadoop 등 binlog를 통해 외부 시스템에 출력하여 외부 시스템에서 통계 쿼리 기능을 제공할 수 있습니다3. 이 값이 0
4이 될 때까지 대기 라이브러리 B의 second_behind_master 값을 결정합니다. 대기 데이터베이스 B를 읽기-쓰기 상태로 변경합니다. 즉, 읽기 전용을 false로 설정합니다
5. 업무요청을 대기데이터베이스 B
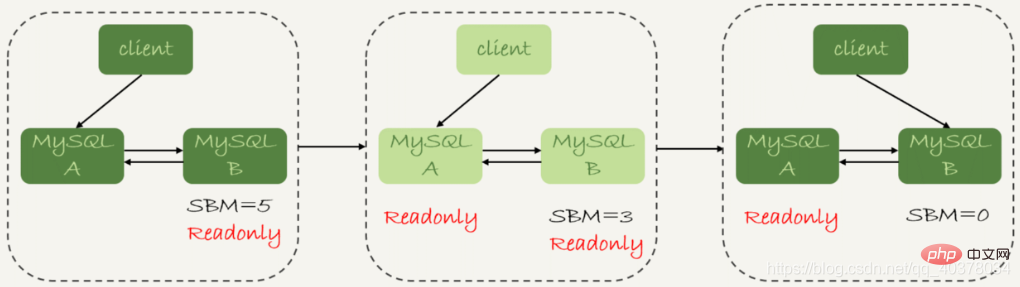
로 전환합니다. 이 전환과정에서 이용불가가 발생하나요? 2단계 이후에는 메인 데이터베이스 A와 스탠바이 데이터베이스 B가 모두 읽기 전용 상태입니다. 이는 현재 시스템이 쓰기 불가능한 상태이며 5단계가 완료될 때까지 복원할 수 없음을 의미합니다. 이 사용할 수 없는 상태에서 시간이 더 많이 걸리는 단계는 3단계로, 몇 초 정도 걸릴 수 있습니다. 그렇기 때문에 1단계에서 second_behind_master의 값이 충분히 작은지 확인해야 합니다
이 데이터 신뢰성 우선 전략에 따라 시스템의 비가용 시간이 결정됩니다
 2. 가용성 우선 전략
2. 가용성 우선 전략
가용성 우선 전략: 맨 처음에 실행할 신뢰성 우선 전략의 4, 5단계를 강제로 조정하는 경우, 즉 메인 데이터와 백업 데이터의 동기화를 기다리지 않고 대기 데이터베이스 B로 직접 연결 전환 , 대기 데이터베이스 B에 읽기 및 쓰기를 허용하면 시스템 사용 시간에 거의 문제가 없습니다. 이 전환 프로세스의 비용은 데이터 불일치가 발생할 수 있다는 것입니다.
mysql> CREATE TABLE `t` ( `id` int(11) unsigned NOT NULL AUTO_INCREMENT, `c` int(11) unsigned DEFAULT NULL, PRIMARY KEY (`id`)) ENGINE=InnoDB;insert into t(c) values(1),(2),(3);
insert into t(c) values(4);insert into t(c) values(5);
다음 그림은 binlog_format=mixed
일 때 가용성 우선순위 전략과 전환 과정 및 데이터 결과입니다 1. 2단계에서 메인 라이브러리 A가 완료됩니다. insert 문, 데이터 행(4,4) 삽입 후 활성-대기 스위치 시작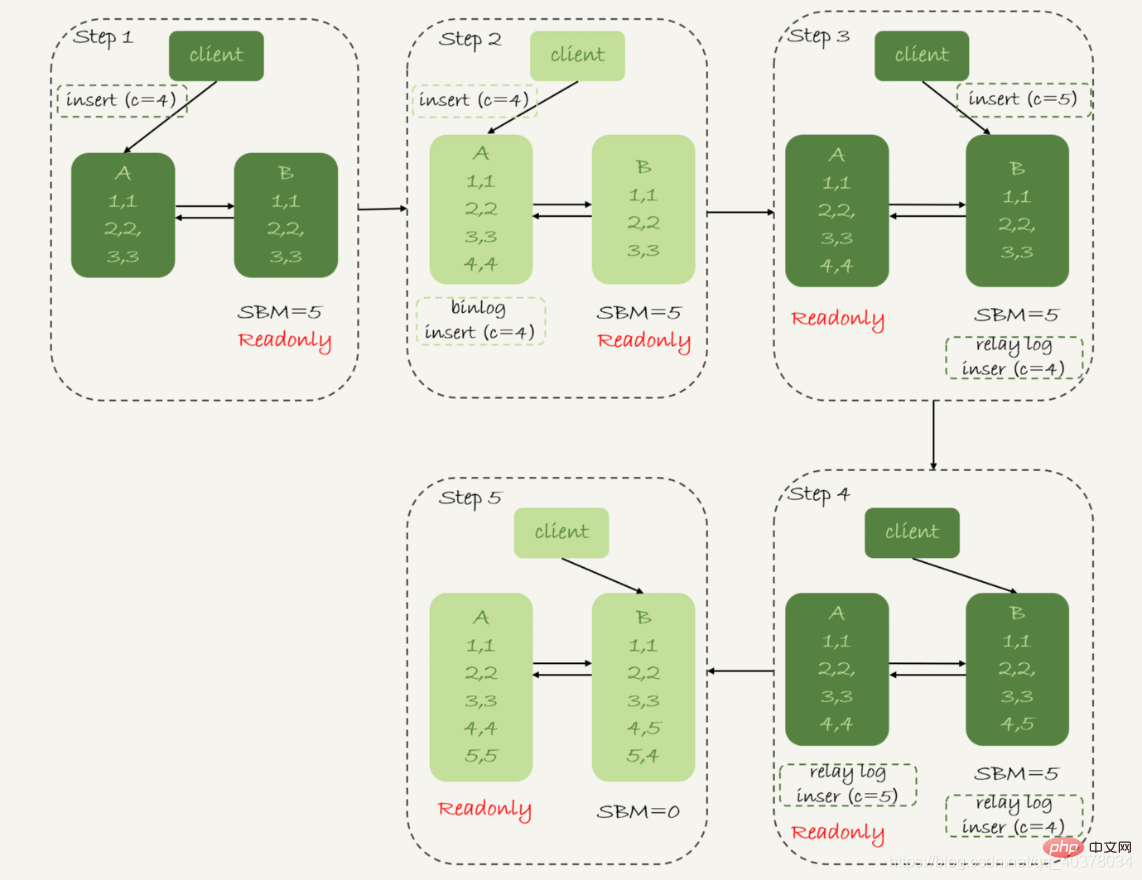 2. 3단계에서 활성 데이터베이스와 대기 데이터베이스 사이의 5초 지연으로 인해 대기 데이터베이스 B는 c=4 삽입 적용 시간 로그 전송 후 c=5
2. 3단계에서 활성 데이터베이스와 대기 데이터베이스 사이의 5초 지연으로 인해 대기 데이터베이스 B는 c=4 삽입 적용 시간 로그 전송 후 c=5
가용성 우선순위 전략, set binlog_format=row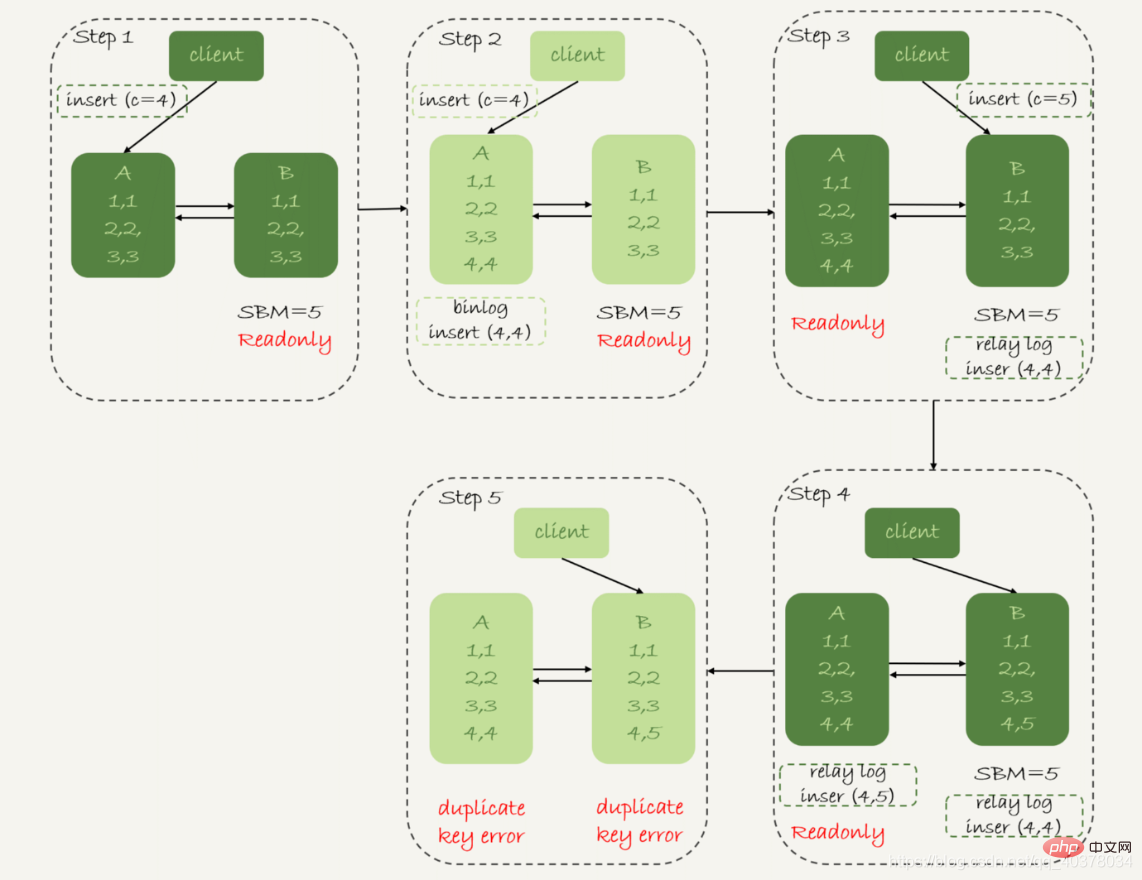
따라서 행 형식이 binlog를 기록할 때 새로 삽입된 행의 모든 필드 값을 기록하므로 결국 일치하지 않는 행은 하나만 남게 됩니다. . 또한 양쪽의 활성 및 대기 동기화 애플리케이션 스레드는 중복 키 오류를 보고하고 중지됩니다. 즉, 이 경우 대기 데이터베이스 B의 두 행(5,4)과 기본 데이터베이스 A의 데이터(5,5)는 상대방에 의해 실행되지 않습니다
1. 행 형식으로 binlog를 사용하면 데이터 불일치 문제를 더 쉽게 찾을 수 있습니다. 혼합 또는 명령문 형식의 binlog를 사용하는 경우 데이터 불일치 문제를 발견하는 데 오랜 시간이 걸릴 수 있습니다
2. 활성/대기 전환의 가용성 우선 전략은 데이터 불일치로 이어질 것입니다. 따라서 대부분의 경우 신뢰성 우선 전략을 채택하는 것이 좋습니다
주목해야 할 것은 위 그림의 병렬 복제에 대한 두 개의 검은 색 화살표입니다. 기본 및 보조 서버의 복제 기능. 하나는 메인 데이터베이스에 쓰는 클라이언트를 나타내고, 다른 하나는 스탠바이 데이터베이스의 sql_thread 실행 전송 로그를 나타냅니다. MySQL 버전 5.6 이전에는 MySQL이 단일 스레드 복제만 지원했기 때문에 메인 데이터베이스 동시성 및 TPS가 높을 때 심각한 문제가 발생했습니다. . 기본 및 백업 지연 문제
다중 스레드 복제 메커니즘은 하나의 스레드만 있는 sql_thread를 여러 스레드로 분할하며 이는 다음 모델을 따릅니다.
코디네이터는 원래 sql_thread이지만 이제는 더 이상 직접적으로 사용되지 않습니다. 데이터 업데이트, 전송 로그 읽기 및 트랜잭션 배포만 담당합니다. 실제로 로그를 업데이트하는 것이 작업자 스레드가 됩니다. 작업자 스레드 수는 Slave_parallel_workers 매개변수에 의해 결정됩니다. 배포 시 코디네이터는 다음 두 가지 기본 요구 사항을 충족해야 합니다. 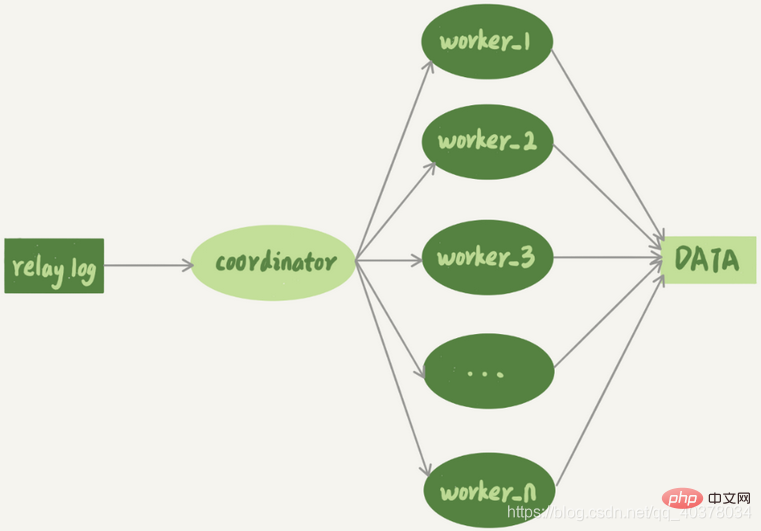
이 전략의 두 가지 장점:
해시 값 구성이 매우 빠르며, 라이브러리 이름이 필요합니다binlog 형식은 필요하지 않습니다. 왜냐하면 명령문 형식의 binlog도 쉽게 라이브러리 이름을 얻을 수 있기 때문입니다
대기 중 라이브러리에서 실행될 때 두 번째 트랜잭션 그룹은 두 번째 트랜잭션 그룹이 실행을 시작하기 전에 첫 번째 트랜잭션 그룹이 완전히 실행될 때까지 기다려야 합니다. 이런 방식으로 시스템의 처리량이 충분하지 않습니다.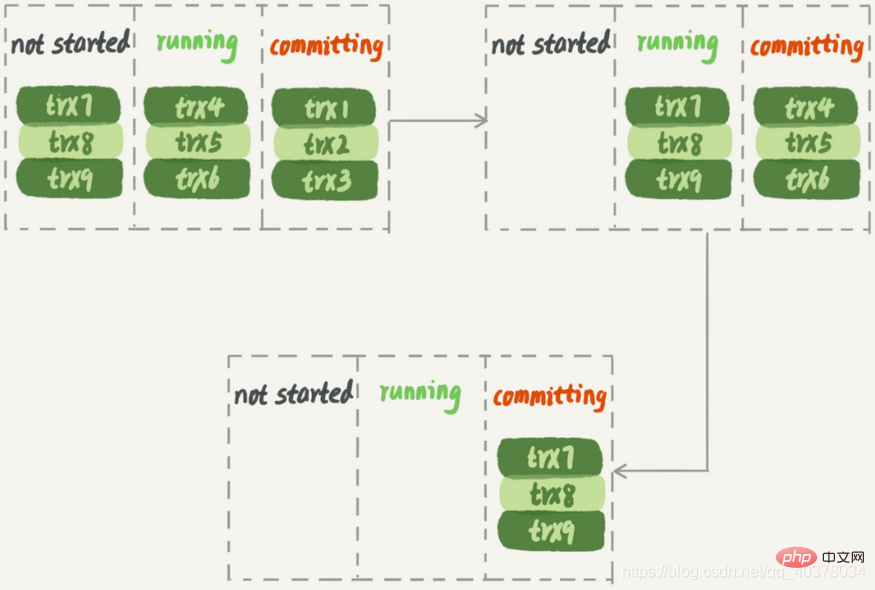
In 또한 이 솔루션은 대규모 트랜잭션으로 인해 쉽게 방해를 받습니다. trx2가 매우 큰 트랜잭션이라고 가정하면, Standby Database가 적용되면 trx1, trx3의 실행이 완료된 후 다음 그룹이 실행을 시작할 수 있다. 하나의 작업자 스레드만 작동하며 이는 리소스 낭비입니다
3. MySQL5.7 버전의 병렬 복제 전략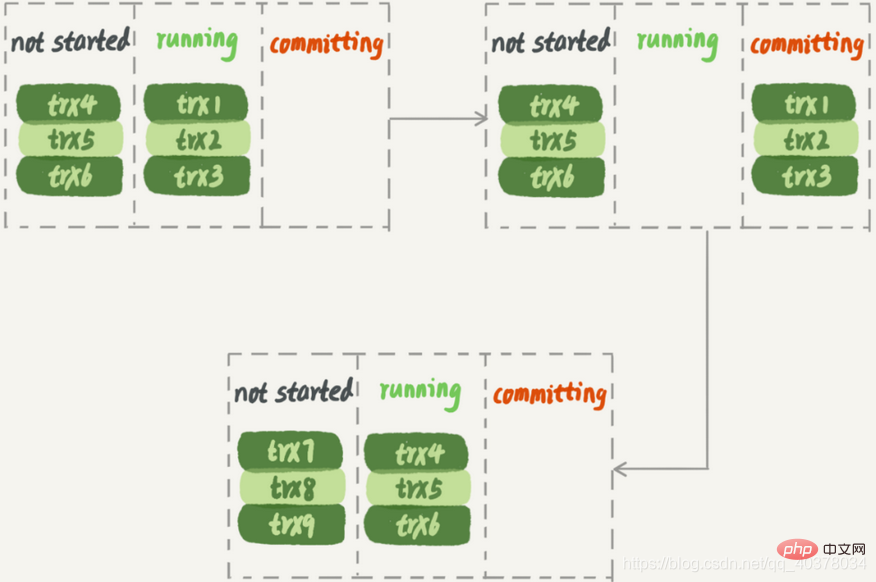
不可以,因为这里面可能有由于锁冲突而处于锁等待状态的事务。如果这些事务在备库上被分配到不同的worker,就会出现备库跟主库不一致的情况
而MariaDB这个策略的核心是所有处于commit状态的事务可以并行。事务处于commit状态表示已经通过了锁冲突的检验了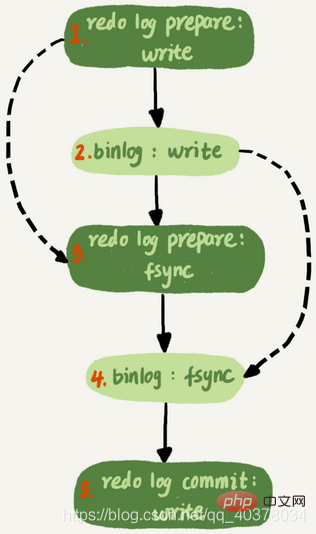
其实只要能够达到redo log prepare阶段就表示事务已经通过锁冲突的检验了
因此,MySQL5.7并行复制策略的思想是:
1.同时处于prepare状态的事务,在备库执行时是可以并行的
2.处于prepare状态的事务,与处于commit状态的事务之间,在备库执行时也是可以并行的
binlog组提交的时候有两个参数:
这两个参数是用于故意拉长binlog从write到fsync的时间,以此减少binlog的写盘次数。在MySQL5.7的并行复制策略里,它们可以用来制造更多的同时处于prepare阶段的事务。这样就增加了备库复制的并行度。也就是说,这两个参数既可以故意让主库提交得慢些,又可以让备库执行得快些
MySQL5.7.22增加了一个新的并行复制策略,基于WRITESET的并行复制,新增了一个参数binlog-transaction-dependency-tracking用来控制是否启用这个新策略。这个参数的可选值有以下三种:
为了唯一标识,hash值是通过库名+表名+索引名+值计算出来的。如果一个表上除了有主键索引外,还有其他唯一索引,那么对于每个唯一索引,insert语句对应的writeset就要多增加一个hash值
1.writeset是在主库生成后直接写入到binlog里面的,这样在备库执行的时候不需要解析binlog内容
2.不需要把整个事务的binlog都扫一遍才能决定分发到哪个worker,更省内存
3.由于备库的分发策略不依赖于binlog内容,索引binlog是statement格式也是可以的
对于表上没主键和外键约束的场景,WRITESET策略也是没法并行的,会暂时退化为单线程模型
下图是一个基本的一主多从结构
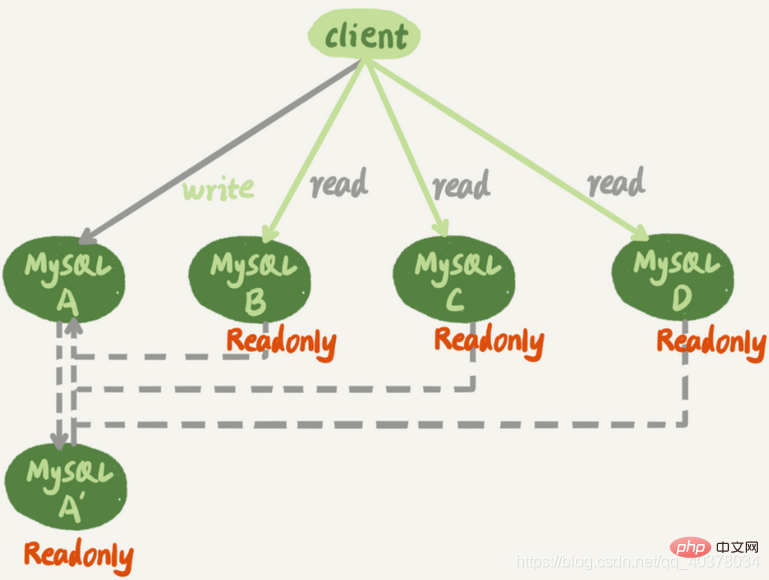
图中,虚线箭头表示的是主备关系,也就是A和A’互为主备,从库B、C、D指向的是主库A。一主多从的设置,一般用于读写分离,主库负责所有的写入和一部分读,其他的读请求则由从库分担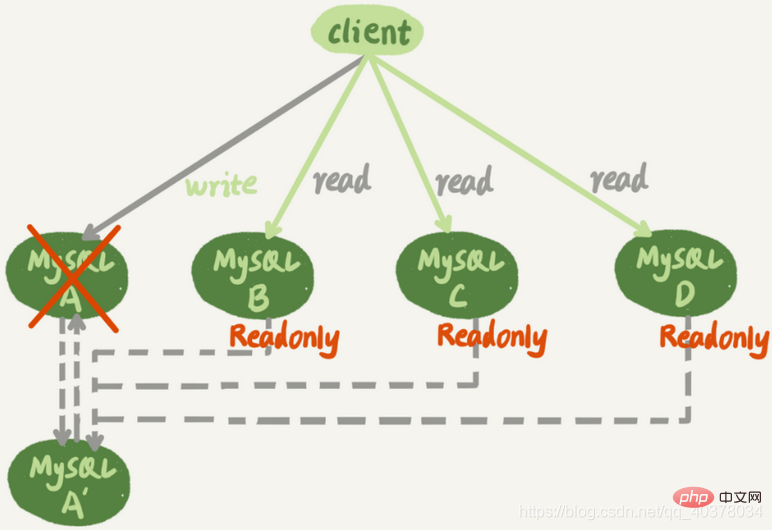
一主多从结构在切换完成后,A’会成为新的主库,从库B、C、D也要改接到A’
当我们把节点B设置成节点A’的从库的时候,需要执行一条change master命令:
CHANGE MASTER TO MASTER_HOST=$host_name MASTER_PORT=$port MASTER_USER=$user_name MASTER_PASSWORD=$password MASTER_LOG_FILE=$master_log_name MASTER_LOG_POS=$master_log_pos
找同步位点很难精确取到,只能取一个大概位置。一种去同步位点的方法是这样的:
1.等待新主库A’把中转日志全部同步完成
2.在A’上执行show master status命令,得到当前A’上最新的File和Position
3.取原主库A故障的时刻T
4.用mysqlbinlog工具解析A’的File,得到T时刻的位点,这个值就可以作为$master_log_pos
这个值并不精确,有这么一种情况,假设在T这个时刻,主库A已经执行完成了一个insert语句插入了一行数据R,并且已经将binlog传给了A’和B,然后在传完的瞬间主库A的主机就掉电了。那么,这时候系统的状态是这样的:
1.在从库B上,由于同步了binlog,R这一行已经存在
2.在新主库A’上,R这一行也已经存在,日志是写在master_log_pos这个位置之后的
3.在从库B上执行change master命令,指向A’的File文件的master_log_pos位置,就会把插入R这一行数据的binlog又同步到从库B去执行,造成主键冲突,然后停止tongue
通常情况下,切换任务的时候,要先主动跳过这些错误,有两种常用的方法
一种是,主动跳过一个事务
set global sql_slave_skip_counter=1;start slave;
另一种方式是,通过设置slave_skip_errors参数,直接设置跳过指定的错误。这个背景是,我们很清楚在主备切换过程中,直接跳过这些错误是无损的,所以才可以设置slave_skip_errors参数。等到主备间的同步关系建立完成,并稳定执行一段时间之后,还需要把这个参数设置为空,以免之后真的出现了主从数据不一致,也跳过了
MySQL5.6引入了GTID,是一个全局事务ID,是一个事务提交的时候生成的,是这个事务的唯一标识。它的格式是:
GTID=source_id:transaction_id
GTID模式的启动只需要在启动一个MySQL实例的时候,加上参数gtid_mode=on和enforce_gtid_consistency=on就可以了
在GTID模式下,每个事务都会跟一个GTID一一对应。这个GTID有两种生成方式,而使用哪种方式取决于session变量gtid_next的值
1.如果gtid_next=automatic,代表使用默认值。这时,MySQL就把GTID分配给这个事务。记录binlog的时候,先记录一行SET@@SESSION.GTID_NEXT=‘GTID’。把这个GTID加入本实例的GTID集合
2.如果gtid_next是一个指定的GTID的值,比如通过set gtid_next=‘current_gtid’,那么就有两种可能:
一个current_gtid只能给一个事务使用。这个事务提交后,如果要执行下一个事务,就要执行set命令,把gtid_next设置成另外一个gtid或者automatic
这样每个MySQL实例都维护了一个GTID集合,用来对应这个实例执行过的所有事务
在GTID模式下,备库B要设置为新主库A’的从库的语法如下:
CHANGE MASTER TO MASTER_HOST=$host_name MASTER_PORT=$port MASTER_USER=$user_name MASTER_PASSWORD=$password master_auto_position=1
其中master_auto_position=1就表示这个主备关系使用的是GTID协议
实例A’的GTID集合记为set_a,实例B的GTID集合记为set_b。我们在实例B上执行start slave命令,取binlog的逻辑是这样的:
1.实例B指定主库A’,基于主备协议建立连接
2.实例B把set_b发给主库A’
3.实例A’算出set_a与set_b的差集,也就是所有存在于set_a,但是不存在于set_b的GTID的集合,判断A’本地是否包含了这个差集需要的所有binlog事务
4.之后从这个事务开始,往后读文件,按顺序取binlog发给B去执行
如果是由于索引缺失引起的性能问题,可以在线加索引来解决。但是,考虑到要避免新增索引对主库性能造成的影响,可以先在备库加索引,然后再切换,在双M结构下,备库执行的DDL语句也会传给主库,为了避免传回后对主库造成影响,要通过set sql_log_bin=off关掉binlog,但是操作可能会导致数据和日志不一致
两个互为主备关系的库实例X和实例Y,且当前主库是X,并且都打开了GTID模式。这时的主备切换流程可以变成下面这样:
set GTID_NEXT="source_id_of_Y:transaction_id";begin;commit;set gtid_next=automatic;start slave;
这样做的目的在于,既可以让实例Y的更新有binlog记录,同时也可以确保不会在实例X上执行这条更新
读写分离的基本结构如下图:
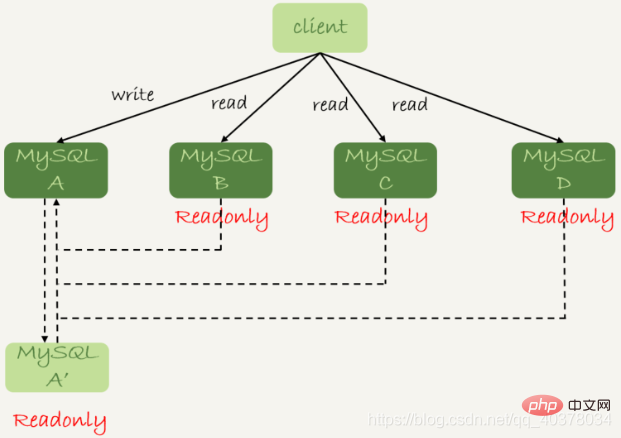
读写分离的主要目的就是分摊主库的压力。上图中的结构是客户端主动做负载均衡,这种模式下一般会把数据库的连接信息放在客户端的连接层。由客户端来选择后端数据库进行查询
还有一种架构就是在MySQL和客户端之间有一个中间代理层proxy,客户端只连接proxy,由proxy根据请求类型和上下文决定请求的分发路由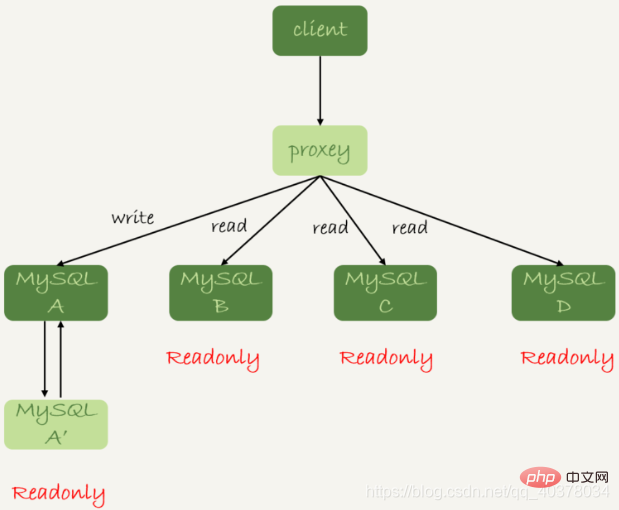
1.客户端直连方案,因此少了一层proxy转发,所以查询性能稍微好一点,并且整体架构简单,排查问题更方便。但是这种方案,由于要了解后端部署细节,所以在出现主备切换、库迁移等操作的时候,客户端都会感知到,并且需要调整数据库连接信息。一般采用这样的架构,一定会伴随一个负责管理后端的组件,比如Zookeeper,尽量让业务端只专注于业务逻辑开发
2.带proxy的架构,对客户端比较友好。客户端不需要关注后端细节,连接维护、后端信息维护等工作,都是由proxy完成的。但这样的话,对后端维护团队的要求会更高,而且proxy也需要有高可用架构
在从库上会读到系统的一个过期状态的现象称为过期读
强制走主库方案其实就是将查询请求做分类。通常情况下,可以分为这么两类:
1.对于必须要拿到最新结果的请求,强制将其发到主库上
2.对于可以读到旧数据的请求,才将其发到从库上
这个方案最大的问题在于,有时候可能会遇到所有查询都不能是过期读的需求,比如一些金融类的业务。这样的话,就需要放弃读写分离,所有读写压力都在主库,等同于放弃了扩展性
主库更新后,读从库之前先sleep一下。具体的方案就是,类似于执行一条select sleep(1)命令。这个方案的假设是,大多数情况下主备延迟在1秒之内,做一个sleep可以很大概率拿到最新的数据
以买家发布商品为例,商品发布后,用Ajax直接把客户端输入的内容作为最新商品显示在页面上,而不是真正地去数据库做查询。这样,卖家就可以通过这个显示,来确认产品已经发布成功了。等到卖家再刷新页面,去查看商品的时候,其实已经过了一段时间,也就达到了sleep的目的,进而也就解决了过期读的问题
但这个方案并不精确:
1.如果这个查询请求本来0.5秒就可以在从库上拿到正确结果,也会等1秒
2.如果延迟超过1秒,还是会出现过期读
show slave status结果里的seconds_behind_master参数的值,可以用来衡量主备延迟时间的长短
1.第一种确保主备无延迟的方法是,每次从库执行查询请求前,先判断seconds_behind_master是否已经等于0。如果还不等于0,那就必须等到这个参数变为0才能执行查询请求
show slave status结果的部分截图如下:
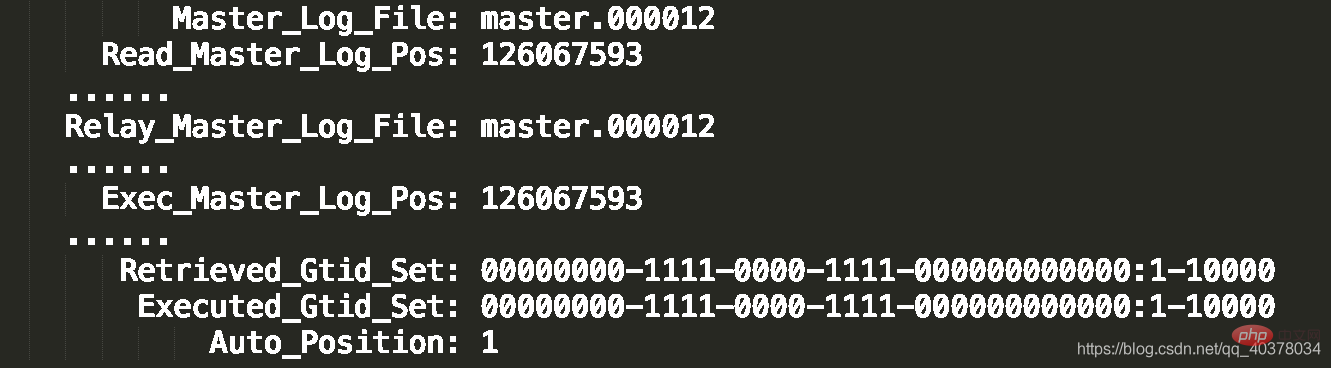
2.第二种方法,对比位点确保主备无延迟:
如果Master_Log_File和Read_Master_Log_Pos和Relay_Master_Log_File和Exec_Master_Log_Pos这两组值完全相同,就表示接收到的日志已经同步完成
3.第三种方法,对比GTID集合确保主备无延迟:
如果这两个集合相同,也表示备库接收到的日志都已经同步完成
4.一个事务的binlog在主备库之间的状态:
1)主库执行完成,写入binlog,并反馈给客户端
2)binlog被从主库发送给备库,备库收到
3)在备库执行binlog完成
上面判断主备无延迟的逻辑是备库收到的日志都执行完成了。但是,从binlog在主备之间状态的分析中,有一部分日志,处于客户端已经收到提交确认,而备库还没收到日志的状态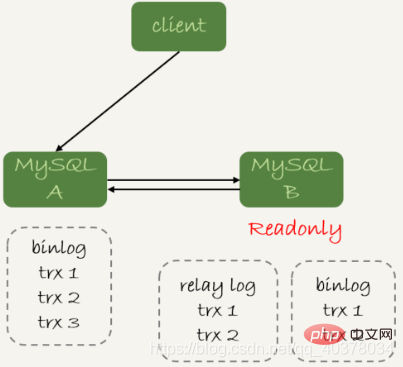
这时,主库上执行完成了三个事务trx1、trx2和trx3,其中:
如果这时候在从库B上执行查询请求,按照上面的逻辑,从库认为已经没有同步延迟,但还是查不到trx3的
要解决上面的问题,就要引入半同步复制。semi-sync做了这样的设计:
1.事务提交的时候,主库把binlog发送给从库
2.从库收到binlog以后,发回给主库一个ack,表示收到了
3.主库收到这个ack以后,才能给客户端返回事务完成的确认
如果启用了semi-sync,就表示所有给客户端发送过确认的事务,都确保了备库已经收到了这个日志
semi-sync+位点判断的方案,只对一主一备的场景是成立的。在一主多从场景中,主库只要等到一个从库的ack,就开始给客户端返回确认。这时,在从库上执行查询请求,就有两种情况:
1.如果查询是落在这个响应了ack的从库上,是能够确保读到最新数据
2.但如果查询落到其他从库上,它们可能还没有收到最新的日志,就会产生过期读的问题
判断同步位点的方案还有另外一个潜在的问题,即:如果在业务更新的高峰期,主库的位点或者GTID集合更新很快,那么上面的两个位点等值判断就会一直不成立,很有可能出现从库上迟迟无法响应查询请求的情况
上图从状态1到状态4,一直处于延迟一个事务的状态。但是,其实客户端是在发完trx1更新后发起的select语句,我们只需要确保trx1已经执行完成就可以执行select语句了。也就是说,如果在状态3执行查询请求,得到的就是预期结果了
semi-sync配合主备无延迟的方案,存在两个问题:
1.一主多从的时候,在某些从库执行查询请求会存在过期读的现象
2.在持续延迟的情况下,可能出现过度等待的问题
select master_pos_wait(file, pos[, timeout]);
这条命令的逻辑如下:
1.它是在从库执行的
2.参数file和pos指的是主库上的文件名和位置
3.timeout可选,设置为正整数N表示这个函数最多等待N秒
这个命令正常返回的结果是一个正整数M,表示从命令开始执行,到应用完file和pos表示的binlog位置,执行了多少事务
1.如果执行期间,备库同步线程发生异常,则返回NULL
2.如果等待超过N秒,就返回-1
3.如果刚开始执行的时候,就发现已经执行过这个位置了,则返回0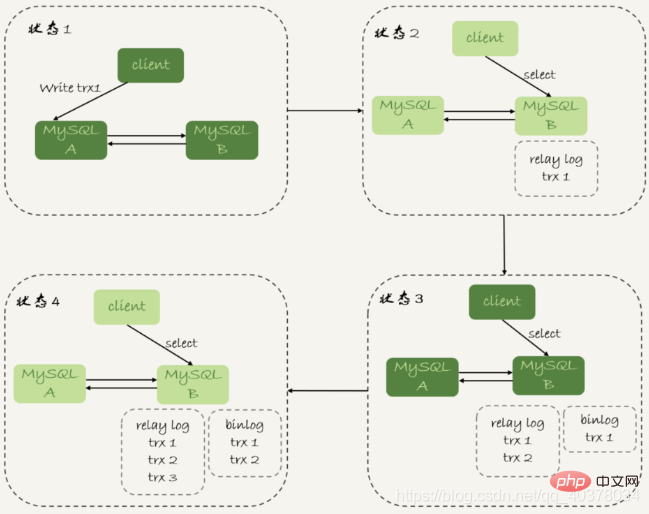
对于上图中先执行trx1,再执行一个查询请求的逻辑,要保证能够查到正确的数据,可以使用这个逻辑:
1.trx1事务更新完成后,马上执行show master status得到当前主库执行到的File和Position
2.选定一个从库执行查询语句
3.在从库上执行select master_pos_wait(file, pos, 1)
4.如果返回值是>=0的正整数,则在这个从库执行查询语句
5.否则,到主库执行查询语句
流程如下:
select wait_for_executed_gtid_set(gtid_set, 1);
这条命令的逻辑如下:
1.等待,直到这个库执行的事务中包含传入的gtid_set,返回0
2.超时返回1
等主库位点方案中,执行完事务后,还要主动去主库执行show master status。而MySQL5.7.6版本开始,允许在执行完更新类事务后,把这个事务的GTID返回给客户端,这样等GTID的方案可以减少一次查询
等GTID的流程如下:
1.trx1事务更新完成后,从返回包直接获取这个事务的GTID,记为gtid1
2.选定一个从库执行查询语句
3. select wait_for_executed_gtid_set(gtid1, 1);
4을 실행합니다. 반환 값이 0이면 이 슬레이브 라이브러리에서 쿼리 문을 실행합니다.
5 그렇지 않으면 메인 라이브러리에서 쿼리 문을 실행합니다. 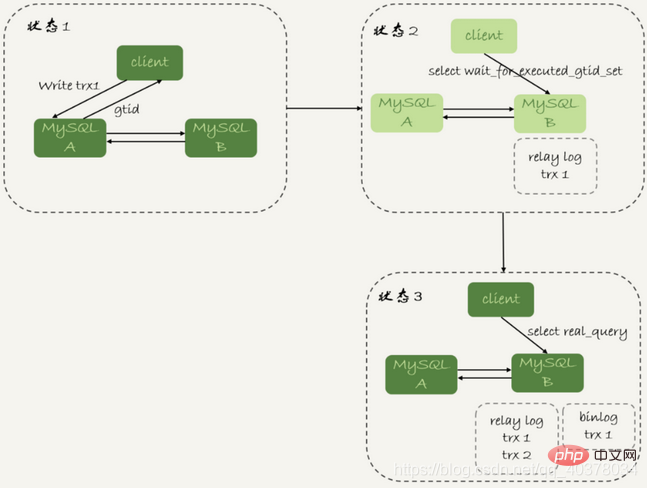
프로그래밍 관련 지식을 더 보려면 프로그래밍 입문을 방문하세요! !
위 내용은 MySQL의 마스터-대기, 마스터-슬레이브 및 읽기-쓰기 분리에 대해 자세히 알아보세요.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



