

리눅스에 하둡을 설치하는 방법

Linux에 Hadoop을 설치하는 방법: 1. SSH 서비스를 설치합니다. 2. 비밀번호 인증 없이 로그인하려면 3. Hadoop 설치 패키지를 다운로드합니다. 5. 다음에서 해당 파일을 구성합니다. 하둡.

이 기사의 운영 환경: ubuntu 16.04 시스템, Hadoop 버전 2.7.1, Dell G3 컴퓨터.
Linux에 hadoop을 설치하는 방법은 무엇입니까?
[빅데이터] Linux에서 Hadoop(2.7.1) 설치 및 WordCount 실행에 대한 자세한 설명
1. 소개
Storm의 환경 구성을 완료한 후 Hadoop 설치를 만져보고 싶은데, 인터넷에 튜토리얼이 많이 있지만 특별히 적합한 것이 없어서 설치 과정에서 여전히 많은 어려움을 겪었습니다. 계속해서 정보를 확인한 후 마침내 문제를 해결했습니다. , 요점을 살펴 보겠습니다.
이 머신의 구성 환경은 다음과 같습니다.
Hadoop(2.7.1)
Ubuntu Linux (64-bit system)
구성 프로세스는 아래 여러 단계에서 자세히 설명됩니다.
2. SSH 서비스 설치
쉘 명령을 입력하고 다음 명령을 입력하여 SSH 서비스가 설치되어 있는지 확인합니다.
sudo apt- get install ssh openssh- serversudo apt-get install ssh openssh-server
安装过程还是比较轻松加愉快的。
三、使用ssh进行无密码验证登录
1.创建ssh-key,这里我们采用rsa方式,使用如下命令:
ssh-keygen -t rsa -P ""
2.出现一个图形,出现的图形就是密码,不用管它
cat ~/.ssh/id_rsa.pub >> authorized_keys(好像是可以省略的)
3.然后即可无密码验证登录了,如下:
ssh localhost
成功截图如下:

四、下载Hadoop安装包
下载Hadoop安装也有两种方式
1.直接上官网进行下载,http://mirrors.hust.edu.cn/apache/hadoop/core/stable/hadoop-2.7.1.tar.gz
2.使用shell进行下载,命令如下:
wget http://mirrors.hust.edu.cn/apache/hadoop/core/stable/hadoop-2.7.1.tar.gz
貌似第二种的方法要快点,经过漫长的等待,终于下载完成。
五、解压缩Hadoop安装包
使用如下命令解压缩Hadoop安装包
tar -zxvf hadoop-2.7.1.tar.gz
解压缩完成后出现hadoop2.7.1的文件夹
六、配置Hadoop中相应的文件
需要配置的文件如下,hadoop-env.sh,core-site.xml,mapred-site.xml.template,hdfs-site.xml,所有的文件均位于hadoop2.7.1/etc/hadoop下面,具体需要的配置如下:
1.core-site.xml 配置如下:
<configuration> <property> <name>hadoop.tmp.dir</name> <value>file:/home/leesf/program/hadoop/tmp</value> <description>Abase for other temporary directories.</description> </property> <property> <name>fs.defaultFS</name> <value>hdfs://localhost:9000</value> </property> </configuration>
其中的hadoop.tmp.dir的路径可以根据自己的习惯进行设置。
2.mapred-site.xml.template配置如下:
<configuration> <property> <name>mapred.job.tracker</name> <value>localhost:9001</value> </property> </configuration>
3.hdfs-site.xml配置如下:
<configuration> <property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>file:/home/leesf/program/hadoop/tmp/dfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:/home/leesf/program/hadoop/tmp/dfs/data</value> </property> </configuration>
其中dfs.namenode.name.dir和dfs.datanode.data.dir的路径可以自由设置,最好在hadoop.tmp.dir的目录下面。
补充,如果运行Hadoop的时候发现找不到jdk,可以直接将jdk的路径放置在hadoop.env.sh里面,具体如下:
export JAVA_HOME="/home/leesf/program/java/jdk1.8.0_60"
七、运行Hadoop
在配置完成后,运行hadoop。
1.初始化HDFS系统
在hadop2.7.1目录下使用如下命令:
bin/hdfs namenode -format
截图如下:

过程需要进行ssh验证,之前已经登录了,所以初始化过程之间键入y即可。
成功的截图如下:

表示已经初始化完成。
2.开启NameNode和DataNode守护进程
使用如下命令开启:
sbin/start-dfs.sh,成功的截图如下:
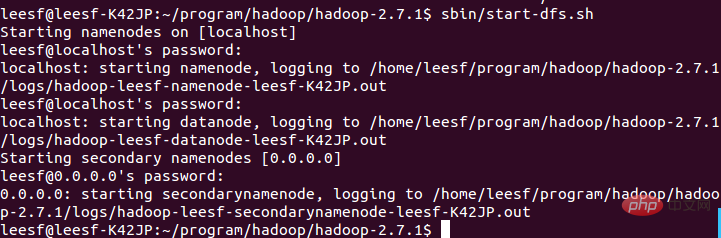
1. 여기서는 ssh-key를 생성하고 다음 명령을 사용합니다:
ssh-keygen -t rsa -P ""
2. 나오는 그래픽은 비밀번호이니 걱정하지 마세요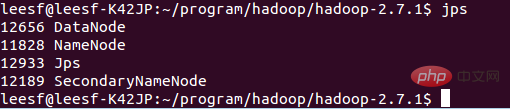
cat ~/.ssh/id_rsa.pub >> 3. 그러면 다음과 같이 비밀번호 확인 없이 로그인할 수 있습니다: 🎜🎜 ssh localhost🎜🎜 성공적인 스크린샷은 다음과 같습니다: 🎜🎜  🎜🎜🎜네. Hadoop 설치 패키지 다운로드🎜🎜🎜Hadoop 설치를 다운로드하는 방법은 두 가지가 있습니다. 🎜🎜 1. 다운로드하려면 공식 웹사이트(http://mirrors.hust.edu.cn/apache/hadoop/core/stable/hadoop-2.7.1.tar.gz🎜🎜 2)로 직접 이동하세요. 셸을 사용하여 다운로드하세요. , 명령은 다음과 같습니다: 🎜🎜
🎜🎜🎜네. Hadoop 설치 패키지 다운로드🎜🎜🎜Hadoop 설치를 다운로드하는 방법은 두 가지가 있습니다. 🎜🎜 1. 다운로드하려면 공식 웹사이트(http://mirrors.hust.edu.cn/apache/hadoop/core/stable/hadoop-2.7.1.tar.gz🎜🎜 2)로 직접 이동하세요. 셸을 사용하여 다운로드하세요. , 명령은 다음과 같습니다: 🎜🎜 wget http://mirrors .hust.edu.cn/apache/hadoop/core/stable/hadoop-2.7.1.tar.gz🎜🎜 것 같습니다 두 번째 방법이 더 빠르다는 것을 알고 오랜 기다림 끝에 마침내 다운로드가 완료되었습니다. 🎜🎜🎜 5. Hadoop 설치 패키지 압축 해제 🎜🎜🎜 다음 명령을 사용하여 Hadoop 설치 패키지 압축 해제 🎜🎜 tar -zxvf hadoop-2.7.1.tar.gz 🎜🎜 압축 해제가 완료되면 hadoop2.7.1 폴더 🎜🎜 🎜6. Hadoop에서 해당 파일을 구성합니다🎜🎜🎜 구성해야 하는 파일은 hadoop-env.sh, core-site.xml, mapred-site.xml.template, hdfs-site 입니다. .xml, 모든 파일은 hadoop2 .7.1/etc/hadoop에 있으며, 구체적인 필수 구성은 다음과 같습니다. 🎜🎜 1.core-site.xml 구성은 다음과 같습니다. 🎜rrreee🎜 hadoop.tmp.dir의 경로는 다음과 같습니다. 자신의 습관에 따라 설정하십시오. 🎜🎜 2.mapred-site.xml.template는 다음과 같이 구성됩니다. 🎜rrreee🎜 3.hdfs-site.xml은 다음과 같이 구성됩니다. 🎜rrreee🎜 dfs.namenode.name.dir 및 dfs.datanode.data의 경로 .dir은 무료 설정일 수 있으며 가급적이면 hadoop.tmp.dir 디렉토리 아래에 있어야 합니다. 🎜🎜 또한 Hadoop 실행 시 jdk를 찾을 수 없는 경우 다음과 같이 hadoop.env.sh에 jdk 경로를 직접 배치할 수 있습니다. 🎜🎜 Export JAVA_HOME="/home/leesf/program/java/ jdk1.8.0_60"🎜🎜🎜7. Hadoop 실행🎜🎜🎜 구성이 완료되면 hadoop을 실행합니다. 🎜🎜 1. HDFS 시스템 초기화🎜🎜 hadop2.7.1 디렉터리에서 다음 명령을 사용하세요: 🎜rrreee🎜 스크린샷은 다음과 같습니다:🎜🎜  🎜🎜 해당 과정은 ssh 인증이 필요합니다. 이전에 이미 로그인한 상태이므로 초기화 과정 사이에 y만 입력하시면 됩니다. 🎜🎜 성공한 스크린샷은 다음과 같습니다.🎜🎜 🎜🎜 초기화가 완료되었음을 나타냅니다. 🎜🎜 2.
🎜🎜 해당 과정은 ssh 인증이 필요합니다. 이전에 이미 로그인한 상태이므로 초기화 과정 사이에 y만 입력하시면 됩니다. 🎜🎜 성공한 스크린샷은 다음과 같습니다.🎜🎜 🎜🎜 초기화가 완료되었음을 나타냅니다. 🎜🎜 2. NameNode 및 DataNode 데몬을 시작합니다. 🎜🎜 다음 명령을 사용하여 시작합니다. 🎜🎜 sbin/start-dfs.sh, 성공적인 스크린샷은 다음과 같습니다. 🎜🎜 🎜🎜🎜 3. 프로세스 정보 보기🎜🎜 프로세스 정보를 보려면 다음 명령을 사용하세요🎜🎜 jps, 스크린샷은 다음과 같습니다. 🎜🎜 🎜🎜🎜 이는 DataNode와 NameNode가 시작되었습니다🎜<p> 4. 웹 UI 보기</p>
<p> 관련 정보를 보려면 브라우저에 http://localhost:50070 을 입력하세요. 스크린샷은 다음과 같습니다. </p>
<p><img src="/static/imghw/default1.png" data-src="https://img.php.cn/upload/article/000/000/020/bfb5bc22f461fcb2beb87197aa100a4e-5.png" class="lazy" alt=""></p>
<p> 이제 hadoop 환경이 설정되었습니다. Hadoop을 사용하여 WordCount 예제를 실행해 보겠습니다. </p>
<p><strong> 8. WordCount 데모 실행 </strong></p>
<p> 1. 로컬에서 새 파일을 만듭니다. 작성자가 home/leesf 디렉터리에 새 단어 문서를 만들었습니다. 원하는 대로 내용을 채울 수 있습니다. </p>
<p> 2. 로컬 단어 문서를 업로드하기 위해 HDFS에 새 폴더를 만듭니다. hadoop2.7.1 디렉터리에 다음 명령을 입력합니다: </p>
<p> bin/hdfs dfs -mkdir /test, 이는 hdfs A의 루트 디렉터리에 생성됨을 의미합니다. 테스트 디렉터리</p>
<p> 다음 명령을 사용하여 HDFS 루트 디렉터리 아래 디렉터리 구조를 확인하세요</p>
<p> bin/hdfs dfs -ls /</p>
<p> 구체적인 스크린샷은 다음과 같습니다.</p>
<p> <img src="/static/imghw/default1.png" data-src="https://img.php.cn/upload/article/000/000/020/2d6b7ed9c222079a563098cea81e4d89-6.png" class="lazy" alt=""></p>
<p> 테스트 디렉터리가 생성되었음을 의미합니다. HDFS의 루트 디렉토리 </p>
<p> 3. 로컬 단어 문서를 테스트 디렉토리에 업로드</p>
<p> 업로드하려면 다음 명령을 사용하십시오: </p>
<p> bin/hdfs dfs -put /home/leesf/words /test/</p>
<p> 나 안으로 in in for the next words /test/</p>
<p> hdfs dfs -ls /test/</p>
<p> 결과 스크린샷은 다음과 같습니다. </p>
<p> <img src="/static/imghw/default1.png" data-src="https://img.php.cn/upload/article/000/000/020/2d6b7ed9c222079a563098cea81e4d89-7.png" class="lazy" alt=""></p>
<p> 로컬 단어 문서가 테스트 디렉토리에 업로드되었습니다. </p>
<p> 4. wordcount 실행</p>
<p> wordcount를 실행하려면 다음 명령을 사용하세요.</p>
<p> bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.1.jar wordcount /test/words /test/out</p>
<p> 스크린샷은 다음과 같습니다. </p>
<p> <img src="/static/imghw/default1.png" data-src="https://img.php.cn/upload/article/000/000/020/2d6b7ed9c222079a563098cea81e4d89-8.png" class="lazy" alt=""></p>
<p> 작업이 완료되면 out이라는 파일이 /test 디렉터리에 생성됩니다. 다음 명령을 사용하여 /test 디렉터리의 파일을 확인하세요</p>
<p> bin/hdfs dfs - ls /test</p>
<p> 스크린샷은 다음과 같습니다.</p>
<p> <img src="/static/imghw/default1.png" data-src="https://img.php.cn/upload/article/000/000/020/9e4e133c94861b62bd546dbeb0c3b6b4-9.png" class="lazy" alt=""> </p>
<p> 테스트 디렉터리에 Out이라는 파일 디렉터리가 이미 있음을 나타냅니다</p>
<p> out 디렉터리의 파일을 보려면 다음 명령을 입력하세요. </p>
<p> bin/hdf 초 dfs -ls /test/out, 결과 스크린샷은 다음과 같습니다. </p>
<p> <img src="/static/imghw/default1.png" data-src="https://img.php.cn/upload/article/000/000/020/9e4e133c94861b62bd546dbeb0c3b6b4-10.png" class="lazy" alt=""></p> <p> 성공적으로 실행되었으며 결과가 part-r-00000에 저장되었음을 나타냅니다. </p>
<p> 5. 실행 결과 확인</p>
<p> 실행 결과를 확인하려면 다음 명령어를 사용하세요.</p>
<p> bin/hadoop fs -cat /test/out/part-r-00000</p>
<p> 결과 스크린샷은 다음과 같습니다</p>
<p> <img src="/static/imghw/default1.png" data-src="https://img.php.cn/upload/article/000/000/020/9e4e133c94861b62bd546dbeb0c3b6b4-11.png" class="lazy" alt=""> </p>
<p> 이 시점에서 실행 프로세스가 완료되었습니다. </p>
<p><strong>9. 요약</strong></p>
<p> 이번 hadoop 구성 과정에서 많은 문제가 발생했습니다. hadoop1.x와 2.x의 명령은 여전히 구성 과정에서 문제가 하나씩 해결되었습니다. , 많은 것을 얻었습니다. hadoop 환경을 구성하려는 정원사들의 편의를 위해 이 구성에 대한 경험을 공유하고 싶습니다. 구성 과정에서 궁금한 점이 있으면 언제든지 토론해 주세요. 시청하세요~</p>
<p> 추천 학습 : "<a href="https://www.php.cn/course/list/33.html" target="_blank">linux 비디오 튜토리얼</a>"</p>위 내용은 리눅스에 하둡을 설치하는 방법의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7433
7433
 15
1359
52
76
11
29
19
15
1359
52
76
11
29
19

 DeepSeek 웹 버전 입구 DeepSeek 공식 웹 사이트 입구
Feb 19, 2025 pm 04:54 PM
DeepSeek 웹 버전 입구 DeepSeek 공식 웹 사이트 입구
Feb 19, 2025 pm 04:54 PM
DeepSeek은 웹 버전과 공식 웹 사이트의 두 가지 액세스 방법을 제공하는 강력한 지능형 검색 및 분석 도구입니다. 웹 버전은 편리하고 효율적이며 설치없이 사용할 수 있습니다. 개인이든 회사 사용자이든, DeepSeek를 통해 대규모 데이터를 쉽게 얻고 분석하여 업무 효율성을 향상시키고 의사 결정을 지원하며 혁신을 촉진 할 수 있습니다.
 DeepSeek을 설치하는 방법
Feb 19, 2025 pm 05:48 PM
DeepSeek을 설치하는 방법
Feb 19, 2025 pm 05:48 PM
Docker 컨테이너를 사용하여 사전 컴파일 된 패키지 (Windows 사용자의 경우)를 사용하여 소스 (숙련 된 개발자)를 컴파일하는 것을 포함하여 DeepSeek를 설치하는 방법에는 여러 가지가 있습니다. 공식 문서는 신중하게 문서를 작성하고 불필요한 문제를 피하기 위해 완전히 준비합니다.
 Linux 터미널에서 Python 버전을 볼 때 발생하는 권한 문제를 해결하는 방법은 무엇입니까?
Apr 01, 2025 pm 05:09 PM
Linux 터미널에서 Python 버전을 볼 때 발생하는 권한 문제를 해결하는 방법은 무엇입니까?
Apr 01, 2025 pm 05:09 PM
Linux 터미널에서 Python 버전을 보려고 할 때 Linux 터미널에서 Python 버전을 볼 때 권한 문제에 대한 솔루션 ... Python을 입력하십시오 ...
 Bitget 공식 웹 사이트 설치 (2025 초보자 안내서)
Feb 21, 2025 pm 08:42 PM
Bitget 공식 웹 사이트 설치 (2025 초보자 안내서)
Feb 21, 2025 pm 08:42 PM
Bitget은 스팟 거래, 계약 거래 및 파생 상품을 포함한 다양한 거래 서비스를 제공하는 Cryptocurrency 교환입니다. 2018 년에 설립 된이 교환은 싱가포르에 본사를두고 있으며 사용자에게 안전하고 안정적인 거래 플랫폼을 제공하기 위해 노력하고 있습니다. Bitget은 BTC/USDT, ETH/USDT 및 XRP/USDT를 포함한 다양한 거래 쌍을 제공합니다. 또한 Exchange는 보안 및 유동성으로 유명하며 프리미엄 주문 유형, 레버리지 거래 및 24/7 고객 지원과 같은 다양한 기능을 제공합니다.
 Gate.io 설치 패키지를 무료로 받으십시오
Feb 21, 2025 pm 08:21 PM
Gate.io 설치 패키지를 무료로 받으십시오
Feb 21, 2025 pm 08:21 PM
Gate.io는 사용자가 설치 패키지를 다운로드하여 장치에 설치하여 사용할 수있는 인기있는 cryptocurrency 교환입니다. 설치 패키지를 얻는 단계는 다음과 같습니다. Gate.io의 공식 웹 사이트를 방문하고 "다운로드"를 클릭하고 해당 운영 체제 (Windows, Mac 또는 Linux)를 선택하고 컴퓨터에 설치 패키지를 다운로드하십시오. 설치 중에 항 바이러스 소프트웨어 또는 방화벽을 일시적으로 비활성화하여 원활한 설치를 보장하는 것이 좋습니다. 완료 후 사용자는 GATE.IO 계정을 만들려면 사용을 시작해야합니다.
 Ouyi OKX 설치 패키지가 직접 포함되어 있습니다
Feb 21, 2025 pm 08:00 PM
Ouyi OKX 설치 패키지가 직접 포함되어 있습니다
Feb 21, 2025 pm 08:00 PM
세계 최고의 디지털 자산 거래소 인 Ouyi Okx는 이제 안전하고 편리한 거래 경험을 제공하기 위해 공식 설치 패키지를 시작했습니다. OUYI의 OKX 설치 패키지는 브라우저를 통해 액세스 할 필요가 없습니다. 설치 프로세스는 간단하고 이해하기 쉽습니다. 사용자는 최신 버전의 설치 패키지를 다운로드하고 설치를 단계별로 완료하면됩니다.
 시스템 재시작 후 UnixSocket의 권한을 자동으로 설정하는 방법은 무엇입니까?
Mar 31, 2025 pm 11:54 PM
시스템 재시작 후 UnixSocket의 권한을 자동으로 설정하는 방법은 무엇입니까?
Mar 31, 2025 pm 11:54 PM
시스템이 다시 시작된 후 UnixSocket의 권한을 자동으로 설정하는 방법. 시스템이 다시 시작될 때마다 UnixSocket의 권한을 수정하려면 다음 명령을 실행해야합니다.
 Ouyi Exchange 다운로드 공식 포털
Feb 21, 2025 pm 07:51 PM
Ouyi Exchange 다운로드 공식 포털
Feb 21, 2025 pm 07:51 PM
OKX라고도하는 Ouyi는 세계 최고의 암호 화폐 거래 플랫폼입니다. 이 기사는 OUYI의 공식 설치 패키지 용 다운로드 포털을 제공하여 사용자가 다른 장치에 OUYI 클라이언트를 설치할 수 있도록합니다. 이 설치 패키지는 Windows, Mac, Android 및 iOS 시스템을 지원합니다. 설치가 완료되면 사용자는 OUYI 계정에 등록하거나 로그인하고 암호 화폐 거래를 시작하며 플랫폼에서 제공하는 기타 서비스를 즐길 수 있습니다.
