오라클의 저장 프로시저란 무엇인가요?

Oracle에서 저장 프로시저는 특정 기능을 완료하는 데 사용되는 SQL 문 집합입니다. 첫 번째 컴파일 후에는 사용자가 다시 호출할 때 다시 컴파일할 필요가 없습니다. 저장 프로시저의 이름을 지정하고 저장 프로시저를 호출하기 위한 출력 매개변수를 제공합니다.

이 튜토리얼의 운영 환경: Windows 7 시스템, Oracle 11g 버전, Dell G3 컴퓨터.
1. 저장 프로시저란 무엇입니까? 특정 기능을 완료하기 위한 일련의
SQL 문이 데이터베이스에 저장됩니다. 처음 컴파일한 후 다시 호출할 때 다시 컴파일할 필요가 없습니다. 저장 프로시저의 이름을 지정하고 저장 프로시저를 호출하기 위한 매개변수(저장 프로시저에 매개변수가 있는 경우)를 제공합니다. 간단히 말하면, 구체적으로 한 가지 일을 하는 SQL 문입니다. 데이터베이스 자체에서 호출할 수도 있고 Java 프로그램에서 호출할 수도 있습니다. 저장 프로시저는 Oracle 데이터베이스의 프로시저입니다. 2. 저장 프로시저를 작성하는 이유 1. 효율성이 높다 저장 프로시저가 한 번 컴파일되면 데이터베이스에 저장되고 호출될 때마다 직접 실행됩니다. 일반 SQL 문을 다른 위치(예: 메모장)에 저장하려면 실행 전에 분석하고 컴파일해야 합니다. 그래서 저장 프로시저가 더 효율적이라고 생각합니다. 2. 네트워크 트래픽 감소 컴파일된 저장 프로시저는 원격으로 호출할 때 많은 수의 문자열 유형 SQL 문을 전송하지 않습니다. 3. 높은 재사용성
저장 프로시저는 특정 기능을 위해 작성되는 경우가 많습니다. 이 특정 기능을 완료해야 할 경우 저장 프로시저를 다시 호출할 수 있습니다.
4. 높은 유지 관리 가능성
기능 요구 사항에 작은 변화가 있는 경우 이전 저장 프로시저를 수정하는 것이 더 쉽고 노력도 덜 듭니다.
5. 높은 보안
특정 기능을 완성하는 저장 프로시저는 일반적으로 특정 사용자만 사용할 수 있으며 사용 ID 제한이 있어 더욱 안전합니다.
3. 저장 프로시저의 기본
1. 저장 프로시저 구조
(1), 기본 구조 Oracle 저장 프로시저에는 프로세스 선언, 실행 프로세스 부분, 저장 프로시저 예외( 쓰기 가능 여부) 쓰기, 스크립트의 내결함성 및 디버깅 편의성을 높이고 싶다면 예외 처리 쓰기) (2), no-parameter Stored ProcedureCREATE OR REPLACE PROCEDURE demo AS/IS 变量2 DATE; 变量3 NUMBER; BEGIN --要处理的业务逻辑 EXCEPTION --存储过程异常 END
다음 중 하나 선택 여기와 현재에는 차이가 없습니다. 여기서 데모는 저장 프로시저 이름입니다.
(3), 매개변수가 있는 저장 프로시저a. 매개변수가 있는 저장 프로시저
CREATE OR REPLACE PROCEDURE 存储过程名称(param1 student.id%TYPE) AS/IS name student.name%TYPE; age number :=20; BEGIN --业务处理..... END
위 스크립트에서 라인 1: param1은 매개변수이고 해당 유형은 id 필드와 동일합니다. 학생 테이블의 모습입니다.
3행: 변수 이름을 선언합니다. 유형은 학생 테이블의 이름 필드 유형입니다(위와 동일).
4번째 줄: 변수 age를 선언하고 숫자를 입력하며 20
b로 초기화됨 매개변수와 할당이 포함된 저장 프로시저
CREATE OR REPLACE PROCEDURE 存储过程名称(
s_no in varchar,
s_name out varchar,
s_age number) AS
total NUMBER := 0;
BEGIN
SELECT COUNT(1) INTO total FROM student s WHERE s.age=s_age;
dbms_output.put_line('符合该年龄的学生有'||total||'人');
EXCEPTION
WHEN too_many_rows THEN
DBMS_OUTPUT.PUT_LINE('返回值多于1行');
ENDIN 매개변수는 입력 매개변수를 나타내며 매개변수의 기본 모드입니다.
OUT은 반환 값 매개 변수를 나타내며 해당 유형은 Oracle에서 합법적인 모든 유형을 사용할 수 있습니다.
OUT 모드에서 정의된 매개변수는 프로세스 본문 내에서만 할당될 수 있습니다. 이는 매개변수가 이를 호출한 프로세스에 특정 값을 다시 전달할 수 있음을 의미합니다.
IN OUT은 매개변수가 프로세스에 값을 전달할 수 있음을 의미합니다. 또는 특정 값이 전달될 수 있습니다.7행: s_age 매개변수를 필터 조건으로 사용하고 INTO 키워드를 사용하여 찾은 결과를 total 변수에 할당하는 쿼리 문입니다.
8행: 쿼리 결과 출력, "||"는 데이터베이스의 문자열을 연결하는 데 사용됩니다.
9-11행: 예외 처리 수행
2. 저장 프로시저 문법
(1), 연산자
여기서 s, m, n은 변수이고 유형은 숫자입니다.
의미
예제 표현식
산술 연산자
+플러스
s := 2 + 2;
-
마이너스
s : = 3 – 1;
*
회
s := 2 * 3;
/
제외
s := 6 / 2; mod(,)
틀은 취하고 나머지는 가져가세요
m : = mod(3,2) **
Power
10 **2 =100 관계 연산자
=
은
s = 2
과 같습니다. <>또는!=또는~=
은
s != 2
<
은
보다 작습니다.s < 3
>
보다 큼
<= 이하
>= 보다 크거나 같음
비교 연산자가 true를 반환합니다
BETWEEN true를 반환
IN true를 반환합니다
IS NULL 논리 연산자
AND
논리 AND
s=3이고 c는 null
또는 ㅋㅋㅋ기타
:=
Assignment
s := 0; ..
범위
1..9
, 즉 1~9 범위||
문자열 연결
'안녕하세요' ||'세계'
(2)、SELECT INTO STATEMENT语句
该语句将select到的结果赋值给一个或多个变量,例如:
CREATE OR REPLACE PROCEDURE DEMO_CDD1 IS s_name VARCHAR2; --学生名称 s_age NUMBER; --学生年龄 s_address VARCHAR2; --学生籍贯 BEGIN --给单个变量赋值 SELECT student_address INTO s_address FROM student where student_grade=100; --给多个变量赋值 SELECT student_name,student_age INTO s_name,s_age FROM student where student_grade=100; --输出成绩为100分的那个学生信息 dbms_output.put_line('姓名:'||s_name||',年龄:'||s_age||',籍贯:'||s_address); END
로그인 후 복사上面脚本中:
存储过程名称:DEMO_CDD1, student是学生表,要求查出成绩为100分的那个学生的姓名,年龄,籍贯
(3)、选择语句
a、IF..END IF
学生表的sex字段:1-男生;0-女生
IF s_sex=1 THEN dbms_output.put_line('这个学生是男生'); END IF
로그인 후 복사b、IF..ELSE..END IF
IF s_sex=1 THEN dbms_output.put_line('这个学生是男生'); ELSE dbms_output.put_line('这个学生是女生'); END IF
로그인 후 복사(4)、循环语句
a、基本循环
LOOP IF 表达式 THEN EXIT; END IF END LOOP;로그인 후 복사b、while循环
WHILE 表达式 LOOP dbms_output.put_line('haha'); END LOOP;
로그인 후 복사c、for循环
FOR a in 10 .. 20 LOOP dbms_output.put_line('value of a: ' || a); END LOOP;
로그인 후 복사(5)、游标
Oracle会创建一个存储区域,被称为上下文区域,用于处理SQL语句,其中包含需要处理的语句,例如所有的信息,行数处理,等等。
游标是指向这一上下文的区域。 PL/SQL通过控制光标在上下文区域。游标持有的行(一个或多个)由SQL语句返回。行集合光标保持的被称为活动集合。
a、下表是常用的游标属性:
属性
描述
%FOUND
如果DML语句执行后影响有数据被更新或DQL查到了结果,返回true。否则,返回false。
%NOTFOUND
如果DML语句执行后影响有数据被更新或DQL查到了结果,返回false。否则,返回true。
%ISOPEN
游标打开时返回true,反之,返回false。
%ROWCOUNT
返回DML执行后影响的行数。
b、使用游标
声明游标定义游标的名称和相关的SELECT语句:
CURSOR cur_cdd IS SELECT s_id, s_name FROM student;
로그인 후 복사打开游标游标分配内存,使得它准备取的SQL语句转换成它返回的行:
OPEN cur_cdd;
로그인 후 복사抓取游标中的数据,可用LIMIT关键字来限制条数,如果没有默认每次抓取一条:
FETCH cur_cdd INTO id, name ;
로그인 후 복사关闭游标来释放分配的内存:
CLOSE cur_cdd;
로그인 후 복사3、pl/sql处理存储过程
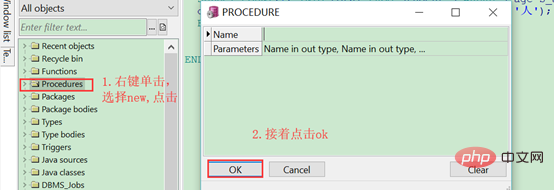
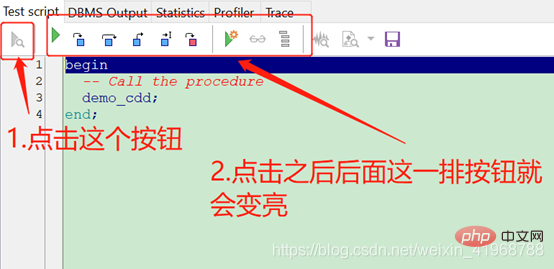
(1)、新建存储过程:右键procedures,点击new,弹出PROCEDURE框,再点击OK,如下图:

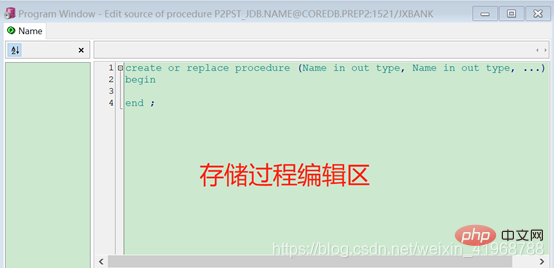
(2)、在下面的编辑区,编写存储过程脚本
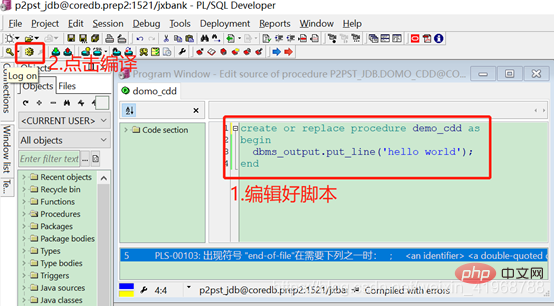
(3)、在这里我们编写一个demo_cdd存储过程,要求输出“hello world”,如下图:
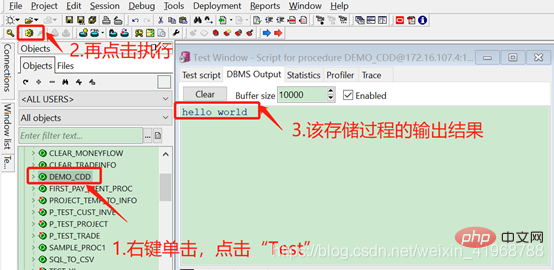
(4)、右键刚才新建的存储过程名称,点击“Test”,在点击执行按钮
4.案例实战
场景:
有表student(s_no, s_name, s_age, s_grade),其中s_no-学号,也是主键,是从1开始向上排的(例如:第一个学生学号是1,第二个是2,一次类推);s_name-学生姓名;s_age-学生年龄;s_grade-年级;这张表的数据量有几千万甚至上亿。一个学年结束了,我要让这些学生全部升一年级,即,让s_grade字段加1。
这条sql,写出来如下:
update student set s_grade=s_grade+1
로그인 후 복사分析:
如果我们直接运行运行这条sql,因数据量太大会把数据库undo表空间撑爆,从而发生异常。那我们来写个存储过程,进行批量更新,我们每10万条提交一次。
CREATE OR REPLACE PROCEDURE process_student is total NUMBER := 0; i NUMBER := 0; BEGIN SELECT COUNT(1) INTO total FROM student; WHILE i<=total LOOP UPDATE student SET grade=grade+1 WHERE s_no=i; i := i + 1; IF i >= 100000 THEN COMMIT; END IF; END LOOP; dbms_output.put_line('finished!'); END;로그인 후 복사上面案例中存在问题,应粉丝要求,把改后的案例sql更新到原文中,如下案例,方便大家阅读。
CREATE OR REPLACE PROCEDURE process_student is total NUMBER := 0; i NUMBER := 0; BEGIN SELECT COUNT(1) INTO total FROM student; WHILE i<=total LOOP UPDATE student SET grade=grade+1 WHERE s_no=i; i := i + 1; IF mod(i,100000) = 0 THEN -- 每10万条提交一次 COMMIT; END IF; END LOOP; COMMIT; -- 最后一批不够10万条的提交一次 dbms_output.put_line('finished!'); END;로그인 후 복사四、存储过程进阶
在上面的案例中,我们的存储过程处理完所有数据要多长时间呢?事实我没有等到它执行完,在我可接受的时间范围内它没有完成。那么对于处理这种千万级数据量的情况,存储过程是不是束手无策呢?答案是否定的,接下来我们看看其他绝招。
我们先来分析下执行过程的执行过程:一个存储过程编译后,在一条语句一条语句的执行时,如果遇到pl/sql语句就拿去给pl/sql引擎执行,如果遇到sql语句就送到sql引擎执行,然后把执行结果再返回给pl/sql引擎。遇到一个大数据量的更新,则执行焦点(正在执行的,状态处于ACTIVE)会不断的来回切换。
Pl/SQL与SQL引擎之间的通信则称之为上下文切换,过多的上下文切换将带来过量的性能负载。最终导致效率降低,处理速度缓慢。
从Oracle8i开始PL/SQL引入了两个新的数据操纵语句:FORALL、BUIK COLLECT,这些语句大大滴减少了上下文切换次数(一次切换多次执行),同时提高DML性能,因此运用了这些语句的存储过程在处理大量数据时速度简直和飞一样。
1、BUIK COLLECT
Oracle8i中首次引入了Bulk Collect特性,Bulk Collect会能进行批量检索,会将检索结果结果一次性绑定到一个集合变量中,而不是通过游标cursor一条一条的检索处理。可以在SELECT INTO、FETCH INTO、RETURNING INTO语句中使用BULK COLLECT,接下来我们一起看看这些语句中是如何使用BULK COLLECT的。
(1)、SELECT INTO
查出来一个结果集合赋值给一个集合变量。
语法结构是:
SELECT field BULK COLLECT INTO var_conllect FROM table where colStatement;
로그인 후 복사说明:
field:要查询的字段,可以是一个或多个(要保证和后面的集合变量要向对应)。
var_collect:集合变量(联合数组等),用来存放查到的结果。
table:表名,要查询的表。
colStatement:后面过滤条件语句。比如s_age < 10;
例子:查出年龄小于10岁的学生姓名赋值给数组arr_name变量
SELECT s_name BULK COLLECT INTO arr_name FROM s_age < 10;
로그인 후 복사(2)、FETCH INTO
从一个集合中抓取一部分数据赋值给一个集合变量。
语法结构如下:
FETCH cur1 BULK COLLECT INTO var_collect [LIMIT rows]
로그인 후 복사说明:
cur1:是个数据集合,例如是个游标。
var_collect:含义同上。
[LIMIT rows]:可有可无,限制每次抓取的数据量。不写的话,默认每次一条数据。
例子:给年龄小于10岁的学生的年级降一级。
--查询年龄小于10岁的学生的学号放在游标cur_no里 CURSOR cur_no IS SELECT s_no FROM student WHERE s_age < 10; --声明了一个联合数组类型,元素类型和游标cur_no每个元素的类型一致 TYPE ARR_NO IS VARRAY(10) OF cur_no%ROWTYPE; --声明一个该数组类型的变量no no ARR_NO; BEGIN FETCH cur_no BULK COLLECT INTO no LIMIT 100; FORALL i IN 1..no.count SAVE EXCEPTONS UPDATE student SET s_grade=s_grade-1 WHERE no(i); END;
로그인 후 복사说明:先查出年龄小于10岁的学生的学号放在游标里,再每次从游标里拿出100个学号,进行更新,给他们的年级降一级。
(3)、RETURNING
BULK COLLECT除了与SELECT,FETCH进行批量绑定之外,还可以与INSERT,DELETE,UPDATE语句结合使用,可以返回这些DML语句执行后所影响的记录内容(某些字段)。
再看一眼学生表的字段情况:student(s_no, s_name, s_age, s_grade)
语法结构如下:
DMLStatement RETURNING field BULK COLLECT INTO var_field;로그인 후 복사说明:
DMLStatement:是一个DML语句。
field:是这个表的某个字段,当然也可以写多个逗号隔开(field1,field2, field3)。
var_field:一个类型为该字段类型的集合,多个的话用逗号隔开,如下:
(var_field1, var_field2, var_field3)
例子:获取那些因为年龄小于10岁而年级被将一级的学生的姓名集合。
TYPE NAME_COLLECT IS TABLE OF student.s_name%TYPE; names NAME_COLLECT; BEGIN UPDATE student SET s_grade=s_grade-1 WHERE s_age < 10 RETURNING s_name BULK COLLECT INTO names; END;
로그인 후 복사说明:
NAME_COLLECT:是一个集合类型,类型是student表的name字段的类型。
names:定义了一个NAME_COLLECT类型的变量。
(4)、注意事项
a.不能对使用字符串类型作键的关联数组使用BULK COLLECT 子句。
b.只能在服务器端的程序中使用BULK COLLECT,如果在客户端使用,就会产生一个不支持这个特性的错误。
c.BULK COLLECT INTO 的目标对象必须是集合类型。
d.复合目标(如对象类型)不能在RETURNING INTO 子句中使用。
e.如果有多个隐式的数据类型转换的情况存在,多重复合目标就不能在BULK COLLECT INTO 子句中使用。
f.如果有一个隐式的数据类型转换,复合目标的集合(如对象类型集合)就不能用于BULK COLLECTINTO 子句中。
2、FORALL
(1)、语法
FORALL index IN bounds [SAVE EXCEPTIONS] sqlStatement;로그인 후 복사说明:
index是指下标;
bounds是一个边界,形式是start..end
[SAVE EXCEPTIONS] 可写可不写,这个下面介绍;
sqlStatement是一个DML语句,这里有且仅有一个sql语句;
例子:
--例子1:移除年级是5到10之间的学生 FORALL i IN 5..10 DELETE FROM student where s_grade=i;로그인 후 복사--例子:2,arr是一个数组,存着要升高一年级的学生名称 FORALL s IN 1..arr.count SAVE EXCEPTIONS UPDATE student SET s_grade=s_grade+1 WHERE s_name=arr(i);로그인 후 복사(2)、SAVE EXCEPTIONS
通常情况写我们在执行DML语句时,可能会遇到异常,可能致使某个语句或整个事务回滚。如果我们写FORALL语句时没有用SAVE EXCEPTIONS语句,那么DML语句会在执行到一半的时候停下来。
如果我们的FORALL语句后使用了SAVE EXCEPTIONS语句,当在执行过程中如果遇到异常,数据处理会继续向下进行,发生的异常信息会保存到SQL%BULK_EXCEPTONS的游标属性中,该游标属性是个记录集合,每条记录有两个字段,例如:(1, 02300);
ERROR_INDEX:该字段会存储发生异常的FORALL语句的迭代编号;
ERROR_CODE:存储对应异常的,oracle错误代码;
SQL%BULK_EXCEPTONS这个异常信息总是存储着最近一次执行的FORALL语句可能发生的异常。而这个异常记录集合异常的个数则由它的COUNT属性表示,即:
SQL%BULK_EXCEPTONS.COUNT,SQL%BULK_EXCEPTIONS有效的下标索引范围在1到%BULK_EXCEPTIONS.COUNT之间。
(3)、INDICES OF
在Oracle数据库10g之前有一个重要的限制,该数据库从IN范围子句中的第一行到最后一行,依次读取集合的内容,如果在该范围内遇到一个未定义的行,Oracle数据库将引发ORA-22160异常事件:ORA-22160: element at index [N] does not exist。针对这一问题,Oracle后续又提供了两个新语句:INDICES OF 和 VALUES OF。
接下来我们来看看这个INDICES OF语句,用于处理稀疏数组或包含有间隙的数组(例如:一个集合的某些元素被删除了)。
该语句语法结构是:
FORALL i INDICES OF collection [SAVE EXCEPTIONS] sqlStatement;로그인 후 복사说明:
i:集合(嵌套表或联合数组)下标。
collection:是这个集合。
[SAVE EXCEPTIONS]和sqlStatement上面已经解释过。
例子:arr_std是一个联合数组,每个元素包含(name,age,grade),现在要向student表插入数据。
FORALL i IN INDICES OF arr_stu INSERT INTO student VALUES( arr_stu(i).name, arr_stu(i).age, arr_stu(i).grade );로그인 후 복사(4)、VALUES OF
VALUES OF适用情况:绑定数组可以是稀疏数组,也可以不是,但我只想使用该数组中元素的一个子集。VALUES OF选项可以指定FORALL语句中循环计数器的值来自于指定集合中元素的值。但是,VALUES OF在使用时有一些限制:
如果VALUES OF子句中所使用的集合是联合数组,则必须使用PLS_INTEGER和BINARY_INTEGER进行索引,VALUES OF 子句中所使用的元素必须是PLS_INTEGER或BINARY_INTEGER;
当VALUES OF 子句所引用的集合为空,则FORALL语句会导致异常;
该语句的语法结构是:
FORALL i IN VALUES OF collection [SAVE EXCEPTIONS] sqlStatement;로그인 후 복사说明:i和collection含义如上
联合数组请看文章(或自行百度):PL/SQL 联合数组与嵌套表_乐沙弥的世界-CSDN博客
3、pl/sql调试存储过程
首先,当前这个用户得有能调试存储过程的权限,如果没有的话,以数据库管理员身份给你这个用户授权:
--userName是你要拿到调试存储过程权限的用户名 GRANT DEBUG ANY PROCEDURE,DEBUG CONNECT SESSION TO username;
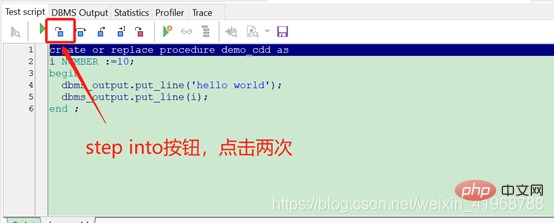
로그인 후 복사(1)、右键一个存储过程名称,点击测试,如下图:
这里我用的pl/sql是12.0.4版本的,下面截图中与低版本的pl/sql按钮位置都相同,只是图标不一样。
(2).点击两次step into按钮,进入语句调试,如下图:
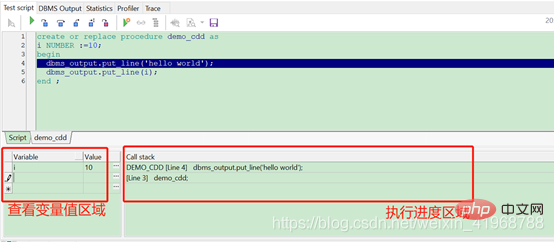
(3).每点击一次step into按钮,会想下执行一条语句,也可以查看变量和表达式的值,如下图:
查看变量值:在查看变量区域,在Variable列输入变量i,在Value列点击下,该变量的值就显示出来了。
4、案例实战
场景和上面的案例实战是同一个,如下:
有表student(s_no, s_name, s_age, s_grade),其中s_no-学号,也是主键,是从1开始向上排的(例如:第一个学生学号是1,第二个是2,一次类推);s_name-学生姓名;s_age-学生年龄;s_grade-年级;这张表的数据量有几千万甚至上亿。一个学年结束了,我要让这些学生全部升一年级,即,让s_grade字段加1。
这条sql,写出来如下:
update student set s_grade=s_grade+1
编写存储过程:
(1)、存储过程1
名称为:process_student1,student表的s_no字段类型为varchar2(16)。
CREATE OR REPLACE PROCEDURE process_student1 AS CURSOR CUR_STUDENT IS SELECT s_no FROM student; TYPE REC_STUDENT IS VARRAY(100000) OF VARCHAR2(16); students REC_STUDENT; BEGIN OPEN CUR_STUDENT; WHILE (TRUE) LOOP FETCH CUR_STUDENT BULK COLLECT INTO students LIMIT 100000; FORALL i IN 1..students.count SAVE EXCEPTIONS UPDATE student SET s_grade=s_grade+1 WHERE s_no=students(i); COMMIT; EXIT WHEN CUR_STUDENT%NOTFOUND OR CUR_STUDENT%NOTFOUND IS NULL; END LOO; dbms_output.put_line('finished'); END;로그인 후 복사说明:
把student表中要更新的记录的学号拿出来放在游标CUR_STUDENT,每次从这个游标里抓取10万条数据赋值给数组students,每次更新这10万条记录。循环进行直到游标里的数据全部抓取完。
FETCH .. BULK COLLECT INTO .. LIMIT rows语句中:这个rows我测试目前最大可以为10万条。
(2)、存储过程2(ROWID)
如果我们这个student表没有主键,也没有索引呢,该怎么来做呢?
分析下:
ROWNUM是伪列,每次获取结果后,然后在结果集里会产生一列,从1开始排,每次都是从1开始排。
ROWID在每个表中,每条记录的ROWID都是唯一的。在这种情况下,我们可以用ROWID。但要注意的是,ROWID是一个类型,注意它和VARCHAR2之间的转换。有两个方法:ROWIDTOCHAR()是把ROWID类型转换为CHAR类型;CHARTOROWID()是把CAHR类型转换为ROWID类型。
接下来我们编写存储过程process_student2,脚本如下:
CREATE OR REPLACE PROCEDURE process_student1 AS CURSOR CUR_STUDENT IS SELECT ROWIDTOCHAR(ROWID) FROM student; TYPE REC_STUDENT IS VARRAY(100000) OF VARCHAR2(16); students REC_STUDENT; BEGIN OPEN CUR_STUDENT; WHILE (TRUE) LOOP FETCH CUR_STUDENT BULK COLLECT INTO students LIMIT 100000; FORALL i IN 1..students.count SAVE EXCEPTIONS UPDATE student SET s_grade=s_grade+1 WHERE ROWID=CHARTOROWID(students(i)); COMMIT; EXIT WHEN CUR_STUDENT%NOTFOUND OR CUR_STUDENT%NOTFOUND IS NULL; END LOO; dbms_output.put_line('finished'); END;로그인 후 복사说明:
我们首先查到记录的ROWID并把它转换为CHAR类型,存放到游标CUR_STUDENT里,
再每次抓取10万条数据赋值给数组进行更新,更新语句的WHERE条件时,又把数组元素是CAHR类型的rowid串转换为ROWID类型。
推荐教程:《Oracle教程》
위 내용은 오라클의 저장 프로시저란 무엇인가요?의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!
본 웹사이트의 성명본 글의 내용은 네티즌들의 자발적인 기여로 작성되었으며, 저작권은 원저작자에게 있습니다. 본 사이트는 이에 상응하는 법적 책임을 지지 않습니다. 표절이나 침해가 의심되는 콘텐츠를 발견한 경우 admin@php.cn으로 문의하세요.
핫 AI 도구
Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱
AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.
Undress AI Tool
무료로 이미지를 벗다
Clothoff.io
AI 옷 제거제
AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
Repo : 팀원을 부활시키는 방법1 몇 달 전 By 尊渡假赌尊渡假赌尊渡假赌R.E.P.O. 에너지 결정과 그들이하는 일 (노란색 크리스탈)2 몇 주 전 By 尊渡假赌尊渡假赌尊渡假赌헬로 키티 아일랜드 어드벤처 : 거대한 씨앗을 얻는 방법1 몇 달 전 By 尊渡假赌尊渡假赌尊渡假赌스플릿 소설을이기는 데 얼마나 걸립니까?4 몇 주 전 By DDDR.E.P.O. 파일 저장 위치 : 어디에 있고 그것을 보호하는 방법은 무엇입니까?4 몇 주 전 By DDD
뜨거운 도구
메모장++7.3.1
사용하기 쉬운 무료 코드 편집기
SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.
스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경
드림위버 CS6
시각적 웹 개발 도구
SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
Gmail 이메일의 로그인 입구는 어디에 있나요? 7366
7366
 15
자바 튜토리얼
1628
14
Cakephp 튜토리얼
1353
52
라라벨 튜토리얼
1266
25
PHP 튜토리얼
1214
29
See all articles
Oracle 데이터베이스 로그는 얼마나 오래 보관됩니까?
May 10, 2024 am 03:27 AM
15
자바 튜토리얼
1628
14
Cakephp 튜토리얼
1353
52
라라벨 튜토리얼
1266
25
PHP 튜토리얼
1214
29
See all articles
Oracle 데이터베이스 로그는 얼마나 오래 보관됩니까?
May 10, 2024 am 03:27 AM
Oracle 데이터베이스 로그의 보존 기간은 다음을 포함한 로그 유형 및 구성에 따라 다릅니다. 재실행 로그: "LOG_ARCHIVE_DEST" 매개변수로 구성된 최대 크기에 의해 결정됩니다. 보관된 리두 로그: "DB_RECOVERY_FILE_DEST_SIZE" 매개변수로 구성된 최대 크기에 따라 결정됩니다. 온라인 리두 로그: 보관되지 않고 데이터베이스를 다시 시작하면 손실되며 보존 기간은 인스턴스 실행 시간과 일치합니다. 감사 로그: "AUDIT_TRAIL" 매개변수로 구성되며 기본적으로 30일 동안 보관됩니다.
오라클에서 두 날짜 사이의 일수를 계산하는 함수
May 08, 2024 pm 07:45 PM
두 날짜 사이의 일수를 계산하는 Oracle의 함수는 DATEDIFF()입니다. 구체적인 사용법은 다음과 같습니다. 시간 간격 단위 지정: 간격(예: 일, 월, 연도) 두 날짜 값 지정: date1 및 date2DATEDIFF(interval, date1, date2) 일 차이를 반환합니다.
Oracle 데이터베이스 시작 단계의 순서는 다음과 같습니다.
May 10, 2024 am 01:48 AM
Oracle 데이터베이스 시작 순서는 다음과 같습니다. 1. 전제 조건을 확인합니다. 3. 데이터베이스 인스턴스를 시작합니다. 5. 데이터베이스에 연결합니다. . 서비스를 활성화합니다(필요한 경우). 8. 연결을 테스트합니다.
오라클에서 간격을 사용하는 방법
May 08, 2024 pm 07:54 PM
Oracle의 INTERVAL 데이터 유형은 시간 간격을 나타내는 데 사용됩니다. 구문은 INTERVAL <precision> <unit>입니다. INTERVAL을 연산하기 위해 덧셈, 뺄셈, 곱셈 및 나눗셈 연산을 사용할 수 있으며 이는 시간 데이터 저장과 같은 시나리오에 적합합니다. 날짜 차이를 계산합니다.
오라클에는 얼마나 많은 메모리가 필요합니까?
May 10, 2024 am 04:12 AM
Oracle에 필요한 메모리 양은 데이터베이스 크기, 활동 수준 및 필요한 성능 수준(데이터 버퍼 저장, 인덱스 버퍼, SQL 문 실행 및 데이터 사전 캐시 관리에 필요)에 따라 다릅니다. 정확한 양은 데이터베이스 크기, 활동 수준 및 필요한 성능 수준에 따라 달라집니다. 모범 사례에는 적절한 SGA 크기 설정, SGA 구성 요소 크기 조정, AMM 사용 및 메모리 사용량 모니터링이 포함됩니다.
Oracle에서 특정 문자의 발생 횟수를 확인하는 방법
May 09, 2024 pm 09:33 PM
Oracle에서 문자 발생 횟수를 찾으려면 다음 단계를 수행하십시오. 문자열의 전체 길이를 얻습니다. 문자가 나타나는 부분 문자열의 길이를 얻습니다. 부분 문자열 길이를 빼서 문자 발생 횟수를 계산합니다. 전체 길이에서.
Oracle 데이터베이스 서버 하드웨어 구성 요구 사항
May 10, 2024 am 04:00 AM
Oracle 데이터베이스 서버 하드웨어 구성 요구 사항: 프로세서: 기본 주파수가 2.5GHz 이상인 멀티 코어, 대규모 데이터베이스의 경우 32개 이상의 코어가 권장됩니다. 메모리: 소규모 데이터베이스의 경우 최소 8GB, 중간 크기의 경우 16~64GB, 대규모 데이터베이스 또는 과도한 작업 부하의 경우 최대 512GB 이상. 스토리지: SSD 또는 NVMe 디스크, 중복성 및 성능을 위한 RAID 어레이. 네트워크: 고속 네트워크(10GbE 이상), 전용 네트워크 카드, 지연 시간이 짧은 네트워크. 기타: 안정적인 전원 공급 장치, 이중 구성 요소, 호환 가능한 운영 체제 및 소프트웨어, 열 방출 및 냉각 시스템.
오라클에서 문자열을 바꾸는 방법
May 08, 2024 pm 07:24 PM
Oracle에서 문자열을 바꾸는 방법은 REPLACE 함수를 사용하는 것입니다. 이 함수의 구문은 REPLACE(string, search_string, replacement_string)입니다. 사용 단계: 1. 대체할 하위 문자열을 식별합니다. 2. 하위 문자열을 대체할 새 문자열을 결정합니다. 3. 대체할 REPLACE 함수를 사용합니다. 고급 사용법에는 여러 대체, 대소문자 구분, 특수 문자 대체 등이 포함됩니다.