

실행 계획을 확인하기 위해 Oracle 고급 학습을 완전히 마스터하세요.

이 기사는 Oracle에 대한 관련 지식을 제공하며, 실행 계획 보기와 관련된 문제를 주로 소개합니다. 모든 분들께 도움이 되기를 바랍니다.

추천 튜토리얼: "Oracle Video Tutorial"
오늘은 오라클이 실행 계획을 보는 방법과 실행 계획을 보는 방법에 대해 이야기하겠습니다.
1. 실행계획 보는 방법
1.1. Autotrace 설정
autotrace 명령은 다음과 같습니다
일련번호 |
명령 | 설명 |
1 |
SET AUTOTRACE OFF |
기본값으로 Autotrace를 끕니다 |
2 |
SET AUTOTRACE ON EXPLAIN |
실행만 표시 계획 |
|
3 |
SET AUTOTRACE ON STATISTICS |
실행 통계만 표시 |
4 |
SET AUTOTRACE ON |
두 개의 항목이 포함되어 있습니다. |
| 5 |
SET AUTOTRACE TRACEONLY |
ON과 유사하지만 문의 실행 결과를 표시하지 않습니다 |
1.2. PL/SQL 개발의 설명 창과 같은 타사 도구
를 사용하세요. , 하지만 아직 파악하지 못했습니다. 나중에
 예를 추가하세요.
예를 추가하세요.
SQL> EXPLAIN PLAN FOR SELECT * FROM EMP;
가 설명되었습니다.
SQL> SELECT plan_table_output FROM TABLE(DBMS_XPLAN.DISPLAY('PLAN_TABLE'));
또는: SQL> select * from table(dbms_xplan.display);
왜냐하면 sql이 실행될 때 sql 실행 계획, 디스크에서 읽은 데이터베이스 및 기타 정보가 일정 기간 동안 SGA의 일부 캐시에 저장되기 때문입니다. 명령문 번호를 보려면 한 번의 실행으로 인해 이러한 캐시를 지워야 합니다.
ALTER SYSTEM FLUSH SHARED_POOL; ALTER SYSTEM FLUSH BUFFER_CACHE; ALTER SYSTEM FLUSH GLOBAL CONTEXT;
3. 실행 계획 분석
3.1. 테스트 테이블 생성
cust_info 및 cst_tran이라는 두 개의 새 테이블을 생성합니다(테스트용으로만 사용되며 실질적인 의미는 없음)
CREATE TABLE CUST_INFO (CST_NO NUMBER, CST_NAME VARCHAR2(50), AGE SMALLINT); CREATE TABLE CST_TRAN ( CST_NO NUMBER, TRAN_DATE VARCHAR2(8), TRAN_AMT NUMBER(19,3) );
일부 데이터 삽입, CUST_INFO 테이블 10,000, CST_TRAN 테이블 100만 .
INSERT INTO CUST_INFO
SELECT 100000+LEVEL,
'test'||LEVEL,
ROUND(DBMS_RANDOM.VALUE(1,100))
FROM DUAL
CONNECT BY LEVEL<=10000;
INSERT INTO CST_TRAN
WITH AA AS
(SELECT LEVEL FROM DUAL CONNECT BY LEVEL<=100)
SELECT T.CST_NO,
TO_CHAR(SYSDATE - DBMS_RANDOM.VALUE(1,1000),'yyyymmdd'),
ROUND(DBMS_RANDOM.VALUE(1,999999999),3)
FROM CUST_INFO T
INNER JOIN AA
ON 1=1;3.2. 실행 계획 보기
이 두 테이블과 관련된 실행 계획 보기
SQL> SELECT T.CST_NO, T.CST_NAME, G.TRAN_DATE, G.TRAN_AMT FROM CUST_INFO T INNER JOIN CST_TRAN G ON G.CST_NO = T.CST_NO;
1000000 rows selected.
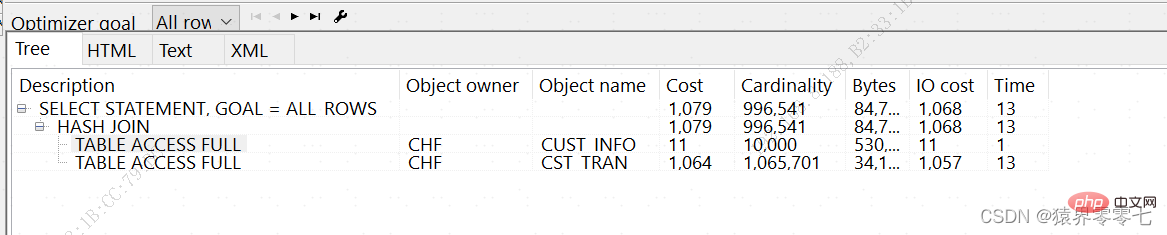
Execution Plan
----------------------------------------------------------
Plan hash value: 2290587575
--------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 996K| 68M| 1079 (2)| 00:00:13 |
|* 1 | HASH JOIN | | 996K| 68M| 1079 (2)| 00:00:13 |
| 2 | TABLE ACCESS FULL | CUST_INFO | 10000 | 390K| 11 (0)| 00:00:01 |
| 3 | TABLE ACCESS FULL | CST_TRAN | 1065K| 32M| 1064 (1)| 00:00:13 |
--------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - access("G"."CST_NO"="T"."CST_NO")
Note
-----
- dynamic sampling used for this statement (level=2)
Statistics
----------------------------------------------------------
561 recursive calls
0 db block gets
70483 consistent gets
4389 physical reads
0 redo size
45078003 bytes sent via SQL*Net to client
733845 bytes received via SQL*Net from client
66668 SQL*Net roundtrips to/from client
10 sorts (memory)
0 sorts (disk)
1000000 rows processed3.2.1. 실행 계획
첫 번째 부분을 살펴보겠습니다.
-------------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | -------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 996K| 68M| 1079 (2)| 00:00:13 | |* 1 | HASH JOIN | | 996K| 68M| 1079 (2)| 00:00:13 | | 2 | TABLE ACCESS FULL | CUST_INFO | 10000 | 390K| 11 (0)| 00:00:01 | | 3 | TABLE ACCESS FULL | CST_TRAN | 1065K| 32M| 1064 (1)| 00:00:13 | --------------------------------------------------------------------------------
필드 설명 실행 계획에서:
ID: 일련 번호이지만 실행 순서는 아닙니다. 실행 순서는 들여쓰기를 기준으로 판단됩니다.작업: 현재 작업의 내용입니다. 행: 현재 작업의 카디널리티로 Oracle은 현재 작업의 반환 결과 집합을 추정합니다.
비용(CPU): SQL 실행 비용을 설명하기 위해 Oracle에서 계산한 숫자 값(비용)입니다.- 시간: Oracle은 현재 작업의 시간을 추정합니다.
- 지침: 1. 작업각 단계의 작업을 기록하고 들여쓰기 정도에 따라 실행 순서를 판단하세요.
OLAP 데이터베이스에는 HASH JOIN 연결이 많이 있으며, 특히 반환된 데이터 세트가 큰 경우 기본적으로 HASH JOIN입니다. 2. 행
행 값은 CBO가 행 소스에서 반환할 것으로 예상하는 레코드 수를 나타냅니다. 이 행 소스는 테이블, 인덱스 또는 하위 쿼리일 수 있습니다. Oracle 9i의 실행 계획에서 Cardinality는 Card로 축약됩니다. 10g에서는 카드 값이 행으로 대체됩니다.
rows가치는 CBO가 올바른 실행 계획을 세우는 데 매우 중요합니다.CBO가 얻은 행 값이 충분히 정확하지 않은 경우(일반적으로 분석 부족 또는 오래된 분석 데이터로 인해) 실행 계획 비용 계산에 편차가 발생하여 CBO가 실행 계획을 잘못 수립하게 됩니다.
SQL에 다중 테이블 관련 쿼리나 하위 쿼리가 있는 경우, 각 관련 테이블이나 하위 쿼리의 행 값이 메인 쿼리에 큰 영향을 미칩니다. 심지어 CBO는 각 관련 테이블의 행에 따라 달라집니다. 또는 하위 쿼리 값을 사용하여 최종 실행 계획을 계산합니다. 다중 테이블 쿼리의 경우 CBO는 연결된 각 테이블에서 반환된 행(행) 수를 사용하여 테이블 연결에 사용할 액세스 방법(예: 중첩 루프 조인 또는 해시 조인)을 결정합니다. 3, 비용(CPU) and Time 실행 계획에 중요한 참고 값입니다
3.2.2. 술어 설명:술어 정보(작업 ID로 식별):
--------------- ----------- --------------------- 1 - 접속 ("G"."CST_NO"="T"." CST_NO")Note -----
- 이 명령문에 사용된 동적 샘플링(레벨=2)
액세스: 이 술어의 값이 조건은 데이터(테이블 또는 인덱스)의 액세스 경로에 영향을 미칩니다.
필터: 술어 조건의 값이 데이터의 접근 경로에 영향을 주지 않고 필터링 역할만 한다는 것을 나타냅니다. (이 예에서는 아님)
참고: 조건자의
3.2.3、统计信息
Statistics
----------------------------------------------------------
561 recursive calls
0 db block gets
70483 consistent gets
4389 physical reads
0 redo size
45078003 bytes sent via SQL*Net to client
733845 bytes received via SQL*Net from client
66668 SQL*Net roundtrips to/from client
10 sorts (memory)
0 sorts (disk)
1000000 rows processed参数说明:
- recursive calls :递归调用。一般原因:dictionary cache未命中;动态存储扩展;PL/SQL语句
- db block gets :bufer中读取的block数量,用于insert,update,delete,selectfor update
- consistent gets :这里是一致读次数(一个block可能会被读多次),bufer中读取的用于查询(除掉select forupdate)的block数量。
- physical reads :从磁盘上读取的block数量,敬请关注每周五晚免费网络公开课。
- redo size :bytes,写到redo logs的数据量
- bytes sent via SQL*Net to client :发送给客户端的字节数
- bytes received via SQL*Net from client :从客户端接收的字节数
- SQL*Net roundtrips to/from client :与客户端的交互次数(个人理解接收一条SQL语句,执行结果分多次发送给客户端,如有问题请指正)
- sorts (memory) :内存排序次数
- sorts (disk) :磁盘排序次数;与sort_area_size有关
- rows processed :执行完SQL后返回结果集的行数
四、部分信息解释
4.1、SQL*Net roundtrips to/from client的计算方式
这个指标的计算方式和一个参数息息相关,arraysize。
arraysize是什么呢?
请查阅大牛博文:Oracle arraysize 和 fetch size 参数 与 性能优化 说明
arraysize定义了一次返回到客户端的行数,取值范围【1-5000】,默认15。
使用命令在数据库中查看arraysize的值。
show arraysize
还可以修改这个值
set arraysize 5000;
明白了arraysize这个参数就可以计算SQL*Net roundtrips to/from client的值了。上例中,返回客户端结果集的行数是1000000,默认arraysize值是15,1000000/15向上取整等于66667。
为啥要向上取整?
举个栗子,如果有10个苹果,一个只能拿3个,几次可以拿完,3次可以拿9个,还剩1个,所以还需要再拿一次,共4次。
统计分析中的值是66668,为什么我们计算的值是66667?
就要看这个指标本身了,再粘贴一次:SQL*Net roundtrips to/from client 重点看from,意思是我们还要接受一次客户端发来的SQL语句,因此是:66667+1,本问题纯属个人臆断,无真凭实据,受限于本人的知识水平,如有误,请指出。
将arraysize的值修改为5000后,再观察SQL*Net roundtrips to/from client的变化,结果为201。
前面提到 arraysize的取值范围是【1-5000】,我们可以试一下改为不在这个区间的值,比如改为0,结果报错了
SQL> set arraysize 0; SP2-0267: arraysize option 0 out of range (1 through 5000)
4.2、consistent gets
译为中文就是:一致性读, 好抽象的一个指标,啥叫一致性读,心中无数羊驼驼在大海中狂奔。
官网对consistent gets 的解释:
consistent gets:Number of times a consistent read wasrequested for a block.
通常我们执行SQL查询时涉及的每一block都是Consistent Read, 只是有些CR(Consistent Read)需要使用undo 来进行构造, 大部分CR(Consistent Read)并不涉及到undo block的读.
还有就是每次读这个block都是一次CR(可能每个block上有多个数据row), 也就是如果某个block被读了10次, 系统会记录10个Consistent Read.
如果想深入学习,请参考大佬博文:Oracle 有关 Consistent gets 的测试 -- cnDBA.cn_中国DBA社区
接来下测试下, consistent gets是从哪来的,需要使用有sysdba权限的用户,因为oradebug工具需要sysdba权限。
oradebug工具介绍:oracle实用工具:oradebug
使用10046对同一条数据跟踪两次,注意观察 consistent gets的不同
为了不影响测试结果,首先清空缓存
SQL> ALTER SYSTEM FLUSH SHARED_POOL; System altered. SQL> ALTER SYSTEM FLUSH BUFFER_CACHE; System altered. SQL> ALTER SYSTEM FLUSH GLOBAL CONTEXT; System altered.
第一次执行
SQL> set tim on timing on
00:42:30 SQL> set autot trace stat
00:42:36 SQL> oradebug setmypid
Statement processed.
00:42:42 SQL> alter session set tracefile_identifier='chf1';
Session altered.
Elapsed: 00:00:00.01
00:42:50 SQL> oradebug event 10046 trace name context forever,level 12;
Statement processed.
00:42:57 SQL> SELECT T.CST_NO, T.CST_NAME, G.TRAN_DATE, G.TRAN_AMT FROM CHF.CUST_INFO T INNER JOIN CHF.CST_TRAN G ON G.CST_NO = T.CST_NO;
1000000 rows selected.
Elapsed: 00:00:22.71
Statistics
----------------------------------------------------------
547 recursive calls
0 db block gets
70368 consistent gets
3898 physical reads
0 redo size
45078003 bytes sent via SQL*Net to client
733845 bytes received via SQL*Net from client
66668 SQL*Net roundtrips to/from client
10 sorts (memory)
0 sorts (disk)
1000000 rows processed
00:44:24 SQL> oradebug event 10046 trace name context off;
Statement processed.
00:45:54 SQL> oradebug tracefile_name
/u01/app/oracle/diag/rdbms/orcl/bpas/trace/bpas_ora_7715_chf1.trc第二次执行
00:46:04 SQL> alter session set tracefile_identifier='chf2';
Session altered.
Elapsed: 00:00:00.00
00:46:35 SQL> oradebug event 10046 trace name context forever,level 12;
Statement processed.
00:46:43 SQL> SELECT T.CST_NO, T.CST_NAME, G.TRAN_DATE, G.TRAN_AMT FROM CHF.CUST_INFO T INNER JOIN CHF.CST_TRAN G ON G.CST_NO = T.CST_NO;
1000000 rows selected.
Elapsed: 00:00:21.62
Statistics
----------------------------------------------------------
0 recursive calls
0 db block gets
70301 consistent gets
3850 physical reads
0 redo size
45078003 bytes sent via SQL*Net to client
733845 bytes received via SQL*Net from client
66668 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
1000000 rows processed
00:47:11 SQL> oradebug event 10046 trace name context off;
Statement processed.
00:49:03 SQL> oradebug tracefile_name
/u01/app/oracle/diag/rdbms/orcl/bpas/trace/bpas_ora_7715_chf2.trc通过对比两次执行,发现consistent gets、physical reads、sorts (memory)都有变化,这是因为SGA中已经缓存了部分数据块。
再对比下我们刚才生产的两个跟踪日志,为方便查看,先将其格式转换以下
[oracle@localhost ~]$ tkprof /u01/app/oracle/diag/rdbms/orcl/bpas/trace/bpas_ora_7715_chf1.trc /u01/chf1.trc TKPROF: Release 11.2.0.1.0 - Development on Wed Dec 8 00:53:37 2021 Copyright (c) 1982, 2009, Oracle and/or its affiliates. All rights reserved. [oracle@localhost ~]$ tkprof /u01/app/oracle/diag/rdbms/orcl/bpas/trace/bpas_ora_7715_chf2.trc /u01/chf2.trc TKPROF: Release 11.2.0.1.0 - Development on Wed Dec 8 00:53:48 2021 Copyright (c) 1982, 2009, Oracle and/or its affiliates. All rights reserved.
打开 /u01/chf1.trc,下面贴出部分重要信息
OVERALL TOTALS FOR ALL NON-RECURSIVE STATEMENTS call count cpu elapsed disk query current rows ------- ------ -------- ---------- ---------- ---------- ---------- ---------- Parse 1 0.03 0.03 8 67 0 0 Execute 1 0.00 0.00 0 0 0 0 Fetch 66668 0.76 3.24 3890 70301 0 1000000 ------- ------ -------- ---------- ---------- ---------- ---------- ---------- total 66670 0.79 3.28 3898 70368 0 1000000 Misses in library cache during parse: 1 Elapsed times include waiting on following events: Event waited on Times Max. Wait Total Waited ---------------------------------------- Waited ---------- ------------ SQL*Net message to client 66670 0.01 0.14 SQL*Net message from client 66670 64.54 79.11 db file sequential read 5 0.00 0.00 Disk file operations I/O 1 0.00 0.00 db file scattered read 5 0.00 0.00 asynch descriptor resize 4 0.00 0.00 direct path read 69 0.00 0.02 OVERALL TOTALS FOR ALL RECURSIVE STATEMENTS call count cpu elapsed disk query current rows ------- ------ -------- ---------- ---------- ---------- ---------- ---------- Parse 12 0.00 0.00 0 0 0 0 Execute 24 0.01 0.01 0 0 0 0 Fetch 30 0.00 0.00 8 67 0 18 ------- ------ -------- ---------- ---------- ---------- ---------- ---------- total 66 0.02 0.02 8 67 0 18
打开 /u01/chf2.trc,下面贴出部分重要信息
OVERALL TOTALS FOR ALL NON-RECURSIVE STATEMENTS call count cpu elapsed disk query current rows ------- ------ -------- ---------- ---------- ---------- ---------- ---------- Parse 1 0.00 0.00 0 0 0 0 Execute 1 0.00 0.00 0 0 0 0 Fetch 66668 1.57 3.73 3850 70301 0 1000000 ------- ------ -------- ---------- ---------- ---------- ---------- ---------- total 66670 1.57 3.73 3850 70301 0 1000000 Misses in library cache during parse: 0 Elapsed times include waiting on following events: Event waited on Times Max. Wait Total Waited ---------------------------------------- Waited ---------- ------------ SQL*Net message to client 66670 0.00 0.10 SQL*Net message from client 66670 6.83 19.93 asynch descriptor resize 4 0.00 0.00 direct path read 69 0.00 0.01 OVERALL TOTALS FOR ALL RECURSIVE STATEMENTS call count cpu elapsed disk query current rows ------- ------ -------- ---------- ---------- ---------- ---------- ---------- Parse 0 0.00 0.00 0 0 0 0 Execute 0 0.00 0.00 0 0 0 0 Fetch 0 0.00 0.00 0 0 0 0 ------- ------ -------- ---------- ---------- ---------- ---------- ---------- total 0 0.00 0.00 0 0 0 0
比较发现,第一次执行解析SQL语句,生产执行计划时,consistent gets发生67次,执行SQL语句时发生70301。第一次执行解析SQL语句,生产执行计划时,因已经有缓存,所以consistent gets发生0次,执行SQL语句时发生70301。
推荐教程:《Oracle视频教程》
위 내용은 실행 계획을 확인하기 위해 Oracle 고급 학습을 완전히 마스터하세요.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

Video Face Swap
완전히 무료인 AI 얼굴 교환 도구를 사용하여 모든 비디오의 얼굴을 쉽게 바꾸세요!

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7692
7692
 15
1639
14
1393
52
1287
25
1229
29
15
1639
14
1393
52
1287
25
1229
29

 오라클을 열 수 없다면해야 할 일
Apr 11, 2025 pm 10:06 PM
오라클을 열 수 없다면해야 할 일
Apr 11, 2025 pm 10:06 PM
Oracle에 대한 솔루션은 개설 할 수 없습니다. 1. 데이터베이스 서비스 시작; 2. 청취자를 시작하십시오. 3. 포트 충돌을 확인하십시오. 4. 환경 변수를 올바르게 설정하십시오. 5. 방화벽이나 바이러스 백신 소프트웨어가 연결을 차단하지 않도록하십시오. 6. 서버가 닫혀 있는지 확인하십시오. 7. RMAN을 사용하여 손상된 파일을 복구하십시오. 8. TNS 서비스 이름이 올바른지 확인하십시오. 9. 네트워크 연결 확인; 10. Oracle 소프트웨어를 다시 설치하십시오.
 Oracle Cursor를 닫는 문제를 해결하는 방법
Apr 11, 2025 pm 10:18 PM
Oracle Cursor를 닫는 문제를 해결하는 방법
Apr 11, 2025 pm 10:18 PM
Oracle Cursor Closure 문제를 해결하는 방법에는 다음이 포함됩니다. Close 문을 사용하여 커서를 명시 적으로 닫습니다. For Update 절에서 커서를 선언하여 범위가 종료 된 후 자동으로 닫히십시오. 연관된 PL/SQL 변수가 닫히면 자동으로 닫히도록 사용 절에서 커서를 선언하십시오. 예외 처리를 사용하여 예외 상황에서 커서가 닫혀 있는지 확인하십시오. 연결 풀을 사용하여 커서를 자동으로 닫습니다. 자동 제출을 비활성화하고 커서 닫기를 지연시킵니다.
 Oracle에서 모든 데이터를 삭제하는 방법
Apr 11, 2025 pm 08:36 PM
Oracle에서 모든 데이터를 삭제하는 방법
Apr 11, 2025 pm 08:36 PM
Oracle에서 모든 데이터를 삭제하려면 다음 단계가 필요합니다. 1. 연결 설정; 2. 외국의 주요 제약을 비활성화합니다. 3. 테이블 데이터 삭제; 4. 거래 제출; 5. 외국 키 제약 조건을 활성화합니다 (선택 사항). 데이터 손실을 방지하려면 실행하기 전에 데이터베이스를 백업하십시오.
 Oracle 데이터베이스를 이끄는 방법
Apr 11, 2025 pm 08:42 PM
Oracle 데이터베이스를 이끄는 방법
Apr 11, 2025 pm 08:42 PM
Oracle 데이터베이스 페이징은 rownum pseudo-columns 또는 fetch 문을 사용하여 구현합니다. Fetch 문은 지정된 첫 번째 행 수를 얻는 데 사용되며 간단한 쿼리에 적합합니다.
 Oracle Loop에서 커서를 만드는 방법
Apr 12, 2025 am 06:18 AM
Oracle Loop에서 커서를 만드는 방법
Apr 12, 2025 am 06:18 AM
Oracle에서 FOR 루프 루프는 커서를 동적으로 생성 할 수 있습니다. 단계는 다음과 같습니다. 1. 커서 유형을 정의합니다. 2. 루프를 만듭니다. 3. 커서를 동적으로 만듭니다. 4. 커서를 실행하십시오. 5. 커서를 닫습니다. 예 : 커서는 상위 10 명의 직원의 이름과 급여를 표시하기 위해주기별로 만들 수 있습니다.
 Oracle 데이터베이스를 중지하는 방법
Apr 12, 2025 am 06:12 AM
Oracle 데이터베이스를 중지하는 방법
Apr 12, 2025 am 06:12 AM
Oracle 데이터베이스를 중지하려면 다음 단계를 수행하십시오. 1. 데이터베이스에 연결하십시오. 2. 즉시 종료; 3. 셧다운은 완전히 중단됩니다.
 Oracle Dynamic SQL을 만드는 방법
Apr 12, 2025 am 06:06 AM
Oracle Dynamic SQL을 만드는 방법
Apr 12, 2025 am 06:06 AM
SQL 문은 Oracle의 동적 SQL을 사용하여 런타임 입력을 기반으로 작성 및 실행할 수 있습니다. 단계에는 다음이 포함됩니다 : 동적으로 생성 된 SQL 문을 저장할 빈 문자열 변수 준비. 즉시 실행 또는 준비 명령문을 사용하여 동적 SQL 문을 컴파일하고 실행하십시오. 바인드 변수를 사용하여 사용자 입력 또는 기타 동적 값을 동적 SQL로 전달하십시오. 동적 SQL 문을 실행하려면 즉시 실행 또는 실행을 사용하십시오.
 HDFS에서 CentOS를 구성하는 데 어떤 단계가 필요합니까?
Apr 14, 2025 pm 06:42 PM
HDFS에서 CentOS를 구성하는 데 어떤 단계가 필요합니까?
Apr 14, 2025 pm 06:42 PM
Centos 시스템에서 Hadoop 분산 파일 시스템 (HDF)을 구축하려면 여러 단계가 필요합니다. 이 기사는 간단한 구성 안내서를 제공합니다. 1. 초기 단계에서 JDK를 설치할 준비 : 모든 노드에 JavadevelopmentKit (JDK)을 설치하면 버전이 Hadoop과 호환되어야합니다. 설치 패키지는 Oracle 공식 웹 사이트에서 다운로드 할 수 있습니다. 환경 변수 구성 : /etc /프로파일 파일 편집, Java 및 Hadoop 설정 설정 시스템에서 JDK 및 Hadoop의 설치 경로를 찾을 수 있습니다. 2. 보안 구성 : SSH 비밀번호가없는 로그인 SSH 키 : 각 노드에서 ssh-keygen 명령을 사용하십시오.
