

Python 데이터 이상값 감지 및 처리(자세한 예)

이 글에서는 데이터 분석에서 이상값과 관련된 문제를 주로 소개하는 python에 대한 관련 지식을 제공합니다. 일반적으로 이상값 탐지 방법에는 통계적 방법, 클러스터링 기반 방법, 이상값을 탐지하는 몇 가지 특수 방법 등이 있습니다. 아래에 이러한 방법을 소개합니다. 모든 분들께 도움이 되기를 바랍니다.

추천 학습: Python 학습 튜토리얼
1 이상치란 무엇인가요?
기계 학습에서 이상 탐지 및 처리는 비교적 작은 분야, 즉 기계 학습의 부산물입니다. 왜냐하면 일반적인 예측 문제에서 모델은 일반적으로 전체 샘플 데이터 구조를 분석하기 때문입니다. 이 표현식은 일반적으로 전체 샘플의 일반적인 속성을 포착하며 이러한 속성 측면에서 전체 샘플과 완전히 일치하지 않는 점을 이상값이라고 합니다 일반적으로 예측은 개발자들 사이에서 인기가 없습니다. 문제는 일반적으로 전체 샘플의 속성에 초점을 맞추고 이상값의 생성 메커니즘은 전체 샘플과 완전히 일치하지 않습니다. 알고리즘이 이상값에 민감한 경우 생성된 모델은 전체 샘플을 예측할 수 없으므로 더 나은 표현이 됩니다. 예측은 부정확할 것입니다. 반면, 질병 예측과 같은 특정 시나리오에서 분석가는 비정상적인 점에 큰 관심을 가집니다. 일반적으로 건강한 사람의 신체적 지표는 일부 차원에서 유사합니다. 물론, 이러한 변화가 반드시 질병으로 인해 발생하는 것은 아니지만(종종 노이즈 포인트라고 함), 이상 발생 및 감지는 질병 예측의 중요한 출발점입니다. 신용 사기, 사이버 공격 등에 대해서도 유사한 시나리오가 적용될 수 있습니다.
2 이상값 탐지 방법 일반적인 이상값 탐지 방법에는 통계적 방법, 클러스터링 기반 방법, 이상값 탐지에 특화된 몇 가지 방법이 있습니다. 1. 간단한 통계pandas를 사용하는 경우 describe()를 직접 사용하여 데이터의 통계적 설명을 관찰할 수 있습니다(일부 통계만 대략적으로 관찰). 그러나 통계는 다음과 같이 연속적입니다.
df.describe()
pandas,我们可以直接使用describe()来观察数据的统计性描述(只是粗略的观察一些统计量),不过统计数据为连续型的,如下:Percentile = np.percentile(df['length'],[0,25,50,75,100]) IQR = Percentile[3] - Percentile[1] UpLimit = Percentile[3]+ageIQR*1.5 DownLimit = Percentile[1]-ageIQR*1.5

或者简单使用散点图也能很清晰的观察到异常值的存在。如下所示:

2. 3∂原则
这个原则有个条件:数据需要服从正态分布。在3∂原则下,异常值如超过3倍标准差,那么可以将其视为异常值。正负3∂的概率是99.7%,那么距离平均值3∂之外的值出现的概率为P(|x-u| > 3∂)

红色箭头所指就是异常值。
3. 箱型图
这种方法是利用箱型图的四分位距(IQR)对异常值进行检测,也叫Tukey‘s test。箱型图的定义如下:

四分位距(IQR)就是上四分位与下四分位的差值。而我们通过IQR的1.5倍为标准,规定:超过上四分位+1.5倍IQR距离,或者下四分位-1.5倍IQR距离的点为异常值。下面是Python中的代码实现,主要使用了numpy的percentile方法。
f,ax=plt.subplots(figsize=(10,8)) sns.boxplot(y='length',data=df,ax=ax) plt.show()
也可以使用seaborn的可视化方法boxplot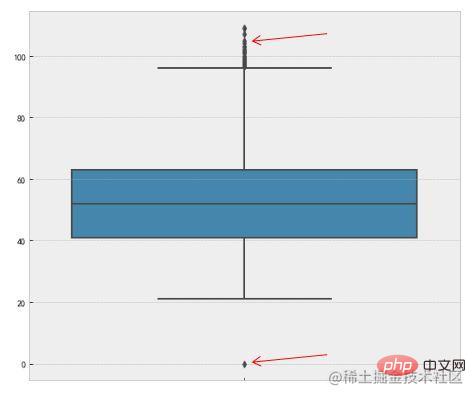
또는 단순히 산점도를 사용하여 이상값의 존재를 명확하게 관찰할 수도 있습니다. 아래와 같이:
데이터는 정규 분포
를 따라야 합니다. 3∂ 원칙에 따라 이상값이 표준편차의 3배를 초과하면 이상값으로 간주될 수 있습니다. 양수 또는 음수 3∂ 확률은 99.7%이므로 평균값에서 3∂ 이외의 값이 나타날 확률은 P(|x-u|>3∂)빨간색 화살표는 이상값을 가리킵니다. 3. 상자 그림
이 방법은 상자 그림의 🎜사분위수 범위(IQR)🎜를 사용하여 🎜Tukey 테스트🎜라고도 하는 이상값을 감지합니다. 상자 그림의 정의는 다음과 같습니다. 🎜🎜🎜🎜 4점 IQR은 상위 사분위수와 하위 사분위수 간의 차이입니다. 우리는 IQR의 1.5배를 표준으로 사용하며 상위 사분위수 + IQR 거리의 1.5배 또는 하위 사분위수 - IQR 거리의 1.5배🎜를 초과하는 지점이 이상값이라고 규정합니다. 다음은 주로 numpy의 percentile 메서드를 사용하는 Python의 코드 구현입니다. 🎜rrreee🎜seaborn의 시각화 방법인 boxplot을 사용하여 이를 달성할 수도 있습니다. 🎜rrreee🎜🎜🎜🎜빨간색 화살표는 이상값을 가리킵니다. 🎜🎜위는 이상값을 결정하는 데 일반적으로 사용되는 간단한 방법입니다. 좀 더 복잡한 이상값 탐지 알고리즘을 소개하겠습니다. 내용이 많기 때문에 관심 있는 친구들이 스스로 깊이 공부할 수 있도록 하겠습니다. 🎜🎜4. 모델 탐지 기반🎜🎜이 방법은 일반적으로 🎜확률 분포 모델🎜을 구축하고 개체가 모델을 준수할 확률을 계산하며 확률이 낮은 개체를 이상값으로 처리합니다. 모델이 클러스터 모음인 경우 이상은 어떤 클러스터에도 크게 속하지 않는 개체이고, 모델이 회귀인 경우 이상은 예측된 값에서 상대적으로 멀리 있는 개체입니다. 🎜🎜이상치의 확률 정의: 🎜이상치는 데이터의 확률 분포 모델과 관련하여 확률이 낮은 🎜 개체입니다. 이 상황의 전제 조건은 데이터 세트가 어떤 분포를 따르는지 아는 것입니다. 추정이 잘못된 경우 두꺼운 꼬리 분포가 발생합니다. 🎜예를 들어, 특성 엔지니어링의 RobustScaler 방법은 데이터 특성 값을 확장할 때 데이터 특성의 분위수 분포를 사용하여 분위수를 기준으로 데이터를 여러 세그먼트로 나누고 중간 세그먼트만 가져옵니다. 예를 들어 스케일링을 수행하려면 스케일링을 위해 25% 분위수에서 75% 분위수까지만 데이터를 가져옵니다. 이렇게 하면 비정상적인 데이터의 영향이 줄어듭니다. RobustScaler方法,在做数据特征值缩放的时候,它会利用数据特征的分位数分布,将数据根据分位数划分为多段,只取中间段来做缩放,比如只取25%分位数到75%分位数的数据做缩放。这样减小了异常数据的影响。
优缺点:(1)有坚实的统计学理论基础,当存在充分的数据和所用的检验类型的知识时,这些检验可能非常有效;(2)对于多元数据,可用的选择少一些,并且对于高维数据,这些检测可能性很差。
5. 基于近邻度的离群点检测
统计方法是利用数据的分布来观察异常值,一些方法甚至需要一些分布条件,而在实际中数据的分布很难达到一些假设条件,在使用上有一定的局限性。
确定数据集的有意义的邻近性度量比确定它的统计分布更容易。这种方法比统计学方法更一般、更容易使用,因为一个对象的离群点得分由到它的k-最近邻(KNN)的距离给定。
需要注意的是:离群点得分对k的取值高度敏感。如果k太小,则少量的邻近离群点可能导致较低的离群点得分;如果K太大,则点数少于k的簇中所有的对象可能都成了离群点。为了使该方案对于k的选取更具有鲁棒性,可以使用k个最近邻的平均距离。
优缺点:(1)简单;(2)缺点:基于邻近度的方法需要O(m2)时间,大数据集不适用;(3)该方法对参数的选择也是敏感的;(4)不能处理具有不同密度区域的数据集,因为它使用全局阈值,不能考虑这种密度的变化。
5. 基于密度的离群点检测
从基于密度的观点来说,离群点是在低密度区域中的对象。基于密度的离群点检测与基于邻近度的离群点检测密切相关,因为密度通常用邻近度定义。一种常用的定义密度的方法是,定义密度为到k个最近邻的平均距离的倒数。如果该距离小,则密度高,反之亦然。另一种密度定义是使用DBSCAN聚类算法使用的密度定义,即一个对象周围的密度等于该对象指定距离d内对象的个数。
优缺点:(1)给出了对象是离群点的定量度量,并且即使数据具有不同的区域也能够很好的处理;(2)与基于距离的方法一样,这些方法必然具有O(m2)的时间复杂度。对于低维数据使用特定的数据结构可以达到O(mlogm);(3)参数选择是困难的。虽然LOF算法通过观察不同的k值,然后取得最大离群点得分来处理该问题,但是,仍然需要选择这些值的上下界。
6. 基于聚类的方法来做异常点检测
基于聚类的离群点:一个对象是基于聚类的离群点,如果该对象不强属于任何簇,那么该对象属于离群点。
离群点对初始聚类的影响:如果通过聚类检测离群点,则由于离群点影响聚类,存在一个问题:结构是否有效。这也是k-means算法的缺点,对离群点敏感。为了处理该问题,可以使用如下方法:对象聚类,删除离群点,对象再次聚类(这个不能保证产生最优结果)。
优缺点:(1)基于线性和接近线性复杂度(k均值)的聚类技术来发现离群点可能是高度有效的;(2)簇的定义通常是离群点的补,因此可能同时发现簇和离群点;(3)产生的离群点集和它们的得分可能非常依赖所用的簇的个数和数据中离群点的存在性;(4)聚类算法产生的簇的质量对该算法产生的离群点的质量影响非常大。
7. 专门的离群点检测
其实以上说到聚类方法的本意是是无监督分类,并不是为了寻找离群点的,只是恰好它的功能可以实现离群点的检测,算是一个衍生的功能。
除了以上提及的方法,还有两个专门用于检测异常点的方法比较常用:One Class SVM和Isolation Forest
5. 근접성을 기반으로 한 이상값 감지
통계적 방법은 이상값을 관찰하기 위해 데이터 분포를 사용합니다. 실제로는 일부 분포 조건이 필요합니다. 사용에 특정 제한이 있습니다. 통계적 분포를 결정하는 것보다 데이터 세트의 근접성에 대한 의미 있는 측정을 결정하는 것이 더 쉽습니다. 이 방법은 개체의 이상점 점수가 k-최근접 이웃(KNN)까지의 거리로 주어지기 때문에 통계 방법보다 더 일반적이고 사용하기 쉽습니다. 🎜🎜아웃라이어 점수는 k 값에 매우 민감하다는 점에 유의해야 합니다. k가 너무 작으면 근처에 있는 소수의 이상값으로 인해 이상값 점수가 낮아질 수 있습니다. K가 너무 크면 k개 미만의 포인트가 있는 클러스터의 모든 개체가 이상값이 될 수 있습니다. 이 방식을 k 선택에 더욱 견고하게 만들기 위해 가장 가까운 이웃 k개의 평균 거리를 사용할 수 있습니다. 🎜🎜장점과 단점: (1) 단순함, (2) 단점: 근접성 기반 방법은 O(m2) 시간이 필요하며 대규모 데이터 세트에는 적합하지 않습니다. 이 방법은 다음과 같은 경우에 적합합니다. 매개변수 선택도 민감합니다. (4) 전역 임계값을 사용하고 이러한 밀도 변화를 설명할 수 없기 때문에 밀도가 다른 영역이 있는 데이터 세트를 처리할 수 없습니다. 🎜
5. 밀도 기반 이상값 감지
🎜밀도 기반 관점에서 이상값은 밀도가 낮은 영역에 있는 개체입니다. 밀도 기반 이상값 감지는 근접성 기반 이상값 감지와 밀접한 관련이 있습니다. 밀도는 근접성 측면에서 정의되는 경우가 많기 때문입니다. 밀도를 정의하는 일반적인 방법은 k개의 가장 가까운 이웃까지의 평균 거리의 역수로 밀도를 정의하는 것입니다. 이 거리가 작으면 밀도가 높고 그 반대도 마찬가지입니다. 밀도의 또 다른 정의는 DBSCAN 클러스터링 알고리즘에서 사용하는 밀도 정의입니다. 즉, 개체 주변의 밀도는 개체로부터 지정된 거리 d 내에 있는 개체의 수와 같습니다. 🎜🎜장점 및 단점: (1) 개체가 이상치라는 정량적 측정을 제공하며 데이터의 영역이 다르더라도 잘 처리할 수 있습니다. 거리법은 동일하며, 이들 방법은 O(m2)의 시간 복잡도를 가져야 합니다. 저차원 데이터의 경우 특정 데이터 구조를 사용하면O(mlogm)를 달성할 수 있습니다. (3) 매개변수 선택이 어렵습니다. LOF 알고리즘은 다양한 k 값을 관찰한 다음 최대 이상값 점수를 획득하여 이 문제를 처리하지만 여전히 이러한 값에 대한 상한과 하한을 선택해야 합니다. 🎜6. 이상치 감지를 위한 클러스터링 기반 방법
🎜클러스터링 기반 이상치:객체가 어떤 클러스터에도 강력하게 속하지 않는 경우 객체는 클러스터링 기반 이상치입니다. 이상치. 🎜🎜초기 클러스터링에 대한 이상값의 영향: 클러스터링을 통해 이상값이 감지되면 이상값이 클러스터링에 영향을 주기 때문에 구조가 유효한지 의문이 듭니다. 이는 이상값에 민감한k-평균 알고리즘의 단점이기도 합니다. 이 문제를 해결하기 위해 다음과 같은 방법을 사용할 수 있습니다: 개체 클러스터링, 이상값 삭제, 개체 다시 클러스터링(이 방법은 최적의 결과를 보장하지 않습니다). 🎜🎜장점 및 단점: (1) 선형 및 선형에 가까운 복잡성(k-평균)을 기반으로 하는 클러스터링 기술은 이상값을 발견하는 데 매우 효과적일 수 있습니다. (2) 클러스터의 정의는 일반적으로 이상값입니다. 클러스터 포인트를 보완하여 클러스터와 이상값을 동시에 발견할 수 있습니다. (3) 결과적인 이상값 세트와 해당 점수는 사용된 클러스터 수와 데이터의 이상값 존재 여부에 따라 크게 달라질 수 있습니다. 클러스터링 알고리즘에 의해 생성된 클러스터의 개수는 알고리즘에 의해 생성된 이상값의 품질에 큰 영향을 미칩니다. 🎜7. 전문적인 이상값 탐지
🎜 사실 위에서 언급한 클러스터링 방법의 원래 의도는 비지도 분류이며, 이상값을 찾는 것이 아니라 그 기능이 이상값을 실현할 수 있다는 것입니다. 점 탐지는 파생된 함수입니다. 🎜🎜위에 언급된 방법 외에도 특히 이상값을 감지하기 위해 일반적으로 사용되는 두 가지 방법이 있습니다:One Class SVM 및 Isolation Forest. 자세한 내용은 여기서 다루지 않습니다. 깊이. 🎜🎜3 이상값 처리 방법🎜🎜이상값이 감지되었으므로 이를 어느 정도 처리해야 합니다. 이상값을 처리하는 일반적인 방법은 대략 다음 범주로 나눌 수 있습니다. 🎜- 이상치가 포함된 레코드 삭제: 이상치가 포함된 레코드를 직접 삭제합니다.
- 결측값으로 처리: 이상치를 결측값으로 처리하고 결측값 처리 방법을 사용하여 처리합니다.
- 평균값 수정: 이전과 이후의 두 관찰 값의 평균값을 사용하여 이상값을 수정할 수 있습니다.
- 처리 없음: 이상값이 있는 데이터 세트에 대해 데이터 마이닝을 직접 수행합니다.
이상값을 삭제할지 여부는 실제 상황을 고려하십시오. 일부 모델은 이상값에 그다지 민감하지 않기 때문에 이상값이 있어도 모델 효과는 영향을 받지 않습니다. 그러나 로지스틱 회귀 LR과 같은 일부 모델은 이상값에 매우 민감합니다. 처리하지 않으면 과적합과 같은 효과가 매우 열악할 수 있습니다. 발생하다.
4 이상값 요약
위는 이상값 탐지 및 처리 방법을 요약한 것입니다.
일부 탐지 방법을 통해 이상치를 찾을 수 있지만, 얻은 결과가 절대적으로 정확하지는 않습니다. 구체적인 상황은 비즈니스에 대한 이해를 바탕으로 판단해야 합니다. 마찬가지로, 이상치를 어떻게 처리해야 할지, 삭제해야 할지, 수정해야 할지, 처리하지 말아야 할지 등도 실제 상황에 따라 고려해야 할 것이지 고정되지는 않습니다.
추천 학습: python 튜토리얼
위 내용은 Python 데이터 이상값 감지 및 처리(자세한 예)의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7319
7319
 9
1625
14
1349
46
1261
25
1209
29
9
1625
14
1349
46
1261
25
1209
29

 DeepSeek Xiaomi를 다운로드하는 방법
Feb 19, 2025 pm 05:27 PM
DeepSeek Xiaomi를 다운로드하는 방법
Feb 19, 2025 pm 05:27 PM
DeepSeek Xiaomi를 다운로드하는 방법? Xiaomi App Store에서 "Deepseek"을 검색하십시오. 요구 사항 (검색 파일, 데이터 분석)을 식별하고 DeepSeek 기능이 포함 된 해당 도구 (예 : 파일 관리자, 데이터 분석 소프트웨어)를 찾으십시오.
 DeepSeek을 프로그래밍하는 방법
Feb 19, 2025 pm 05:36 PM
DeepSeek을 프로그래밍하는 방법
Feb 19, 2025 pm 05:36 PM
DeepSeek은 프로그래밍 언어가 아니라 깊은 검색 개념입니다. DeepSeek을 구현하려면 기존 언어를 기반으로 선택해야합니다. 다양한 응용 프로그램 시나리오의 경우 적절한 언어 및 알고리즘을 선택하고 기계 학습 기술을 결합해야합니다. 코드 품질, 유지 관리 및 테스트가 중요합니다. 귀하의 요구에 따라 올바른 프로그래밍 언어, 알고리즘 및 도구를 선택하고 고품질 코드를 작성하면 성공적으로 구현할 수 있습니다.
 DeepSeekapi에 액세스하는 방법 -Deepseekapi Access Call Tutorial
Mar 12, 2025 pm 12:24 PM
DeepSeekapi에 액세스하는 방법 -Deepseekapi Access Call Tutorial
Mar 12, 2025 pm 12:24 PM
DeepSeekapi Access and Call에 대한 자세한 설명 : 빠른 시작 안내서이 기사는 DeepSeekapi에 액세스하고 전화하는 방법에 대해 자세히 안내하여 강력한 AI 모델을 쉽게 사용할 수 있도록 도와줍니다. 1 단계 : API 키를 가져와 DeepSeek 공식 웹 사이트에 액세스하고 오른쪽 상단의 "오픈 플랫폼"을 클릭하십시오. 특정 수의 무료 토큰을 얻게됩니다 (API 사용량을 측정하는 데 사용됨). 왼쪽의 메뉴에서 "Apikeys"를 클릭 한 다음 "Apikey 만들기"를 클릭하십시오. Apikey (예 : "테스트")의 이름을 지정하고 생성 된 키를 즉시 복사하십시오. 한 번만 표시 되므로이 키를 올바르게 저장하십시오.
 Pi Coin의 주요 업데이트 : Pi Bank가오고 있습니다!
Mar 03, 2025 pm 06:18 PM
Pi Coin의 주요 업데이트 : Pi Bank가오고 있습니다!
Mar 03, 2025 pm 06:18 PM
Pinetwork는 혁신적인 모바일 뱅킹 플랫폼 인 Pibank를 출시하려고합니다! Pinetwork는 오늘 Pibank라고 불리는 Elmahrosa (Face) Pimisrbank에 대한 주요 업데이트를 발표했습니다. Pibank는 Pinetwork Cryptocurrency 기능을 완벽하게 통합하여 화폐 통화 및 암호 화폐의 원자 교환을 실현합니다 (US Dollar, Indones rupiah, indensian rupiah and with rupiah and and indensian rupiah and rupiah and and Indones rupiah and rupiahh and rupiah and rupiah and rupiah and rupiah and rupiah and rupiah and rupiah cherrenciance) ). Pibank의 매력은 무엇입니까? 알아 보자! Pibank의 주요 기능 : 은행 계좌 및 암호 화폐 자산의 원 스톱 관리. 실시간 거래를 지원하고 생물학을 채택하십시오
 정량적 통화 거래 소프트웨어
Mar 19, 2025 pm 04:06 PM
정량적 통화 거래 소프트웨어
Mar 19, 2025 pm 04:06 PM
이 기사는 정량적 거래자가 올바른 플랫폼을 선택할 수 있도록 돕기 위해 세 가지 주요 거래소 인 Binance, Okx 및 Gate.io의 정량적 거래 기능을 탐구합니다. 이 기사는 먼저 정량적 거래의 개념, 장점 및 과제를 소개하고 API 지원, 데이터 소스, 백 테스트 도구 및 위험 제어 기능과 같은 우수한 정량적 거래 소프트웨어가 가져야하는 기능을 설명합니다. 그 후, 3 개의 거래소의 정량적 거래 기능을 비교하고 세부적으로 분석하여 각각 장점과 단점을 지적하고, 마침내 다른 수준의 경험을 가진 정량적 거래자에게 플랫폼 선택 제안을 제공하고, 위험 평가 및 전략적 백 테스트의 중요성을 강조했습니다. 당신이 초보자이든 숙련 된 정량적 거래자이든,이 기사는 귀중한 참조를 제공합니다.
 DeepSeek R1 모델을 로컬로 배포하는 방법 - DeepSeek 로컬 로컬 설치 R1 모델 자습서
Mar 12, 2025 pm 12:15 PM
DeepSeek R1 모델을 로컬로 배포하는 방법 - DeepSeek 로컬 로컬 설치 R1 모델 자습서
Mar 12, 2025 pm 12:15 PM
DeepSeekr1 모델 로컬 배포 안내서 : 데이터 분석 및 예측 잠금 해제 잠재력 DeepSeek는 강력한 데이터 분석 및 예측 도구이며 R1 모델은 다양한 응용 프로그램 시나리오에 효율적이고 정확한 모델 지원을 제공 할 수 있습니다. 이 안내서는 온 프레미스 환경에 DeepSeekR1 모델을 배포하는 방법에 대한 자세한 지침을 제공하여 신속하게 시작하고 힘을 활용할 수 있도록 도와줍니다. 지역 배포 단계 준비 단계 DeepSeekR1 모델의 시스템 요구 사항 : 지역 시스템이 DeepSeek의 최소 시스템 구성 요구 사항을 충족하는지 확인하십시오 (특정 요구 사항은 공식 DeepSeek 문서를 참조하십시오). 소프트웨어 설치 : DeepSeek에서 제공 한 설치 패키지를 다운로드하여 설치하고 설치 안내서를 따르십시오.
 Python으로 통화를 구현하는 방법 -Deepseek Python Call Method Guide
Mar 12, 2025 pm 12:51 PM
Python으로 통화를 구현하는 방법 -Deepseek Python Call Method Guide
Mar 12, 2025 pm 12:51 PM
DeepSeek 딥 러닝 라이브러리 Python Call Guide DeepSeek은 다양한 신경망 모델을 구축하고 훈련시키는 데 사용할 수있는 강력한 딥 러닝 라이브러리입니다. 이 기사는 Python을 사용하여 딥 러닝 개발을 위해 DeepSeek에게 전화하는 방법을 자세히 소개합니다. Python 1으로 DeepSeek을 호출하는 단계. DeepSeek 설치 Python 환경 및 PIP 도구가 설치되어 있는지 확인하십시오. 다음 명령으로 DeepSeek를 설치하십시오. PipinstallDeepSeek2. DeepSeek Library 가져 오기 Python 스크립트 또는 Jupyternotebook에서 DeepSeek 라이브러리를 가져옵니다.
 Binance Alpha는 무엇입니까?
Mar 25, 2025 pm 03:39 PM
Binance Alpha는 무엇입니까?
Mar 25, 2025 pm 03:39 PM
Anbi Alpha는 Binance 플랫폼의 전문 거래자 및 투자자를위한 도구 및 서비스 집계 플랫폼입니다. 그 핵심 기능에는 다음이 포함됩니다. 1. 전략 광장, 다른 거래 전략을 함께 제공합니다. 2. 맞춤형 거래 전략을 허용하는 전략 건축업자; 3. 시장 분석 도구 제공, 고급 데이터 분석; 4. 전문 투자자의 요구를 충족시키기위한 기관 차원의 서비스.
