

Redis의 6가지 기본 데이터 구조를 요약하고 구성합니다.

이 기사는 간단한 동적 문자열, 연결된 목록, 사전, 점프 테이블, 정수 집합 및 압축 목록을 포함한 6가지 기본 데이터 구조와 관련된 문제를 주로 소개하는 Redis에 대한 관련 지식을 제공합니다.

추천 학습: Redis Tutorial
1. Simple Dynamic String (SDS)
Redis C 언어로 작성되었지만 Redis는 C 언어의 전통적인 문자열 표현(널 문자 ')을 직접 사용하지 않습니다.
(6)总结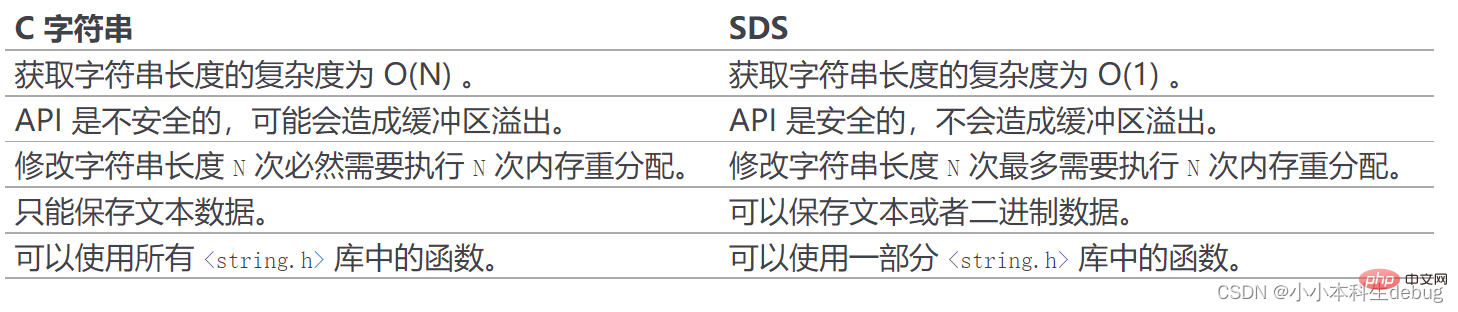
2、链表
作为一种常用数据结构,链表内置在很多高级的编程语言里面,因为Redis使用的 C 语言并没有内置这种数据结构,所以 Redis 构建了自己的链表结构。
每个链表节点使用一个 adlist.h/listNode 结构来表示:
typedef struct listNode {
// 前置节点
struct listNode *prev;
// 后置节点
struct listNode *next;
// 节点的值
void *value;} listNode;多个 listNode 可以通过 prev 和 next 指针组成双端链表, 如图 3-1 所示。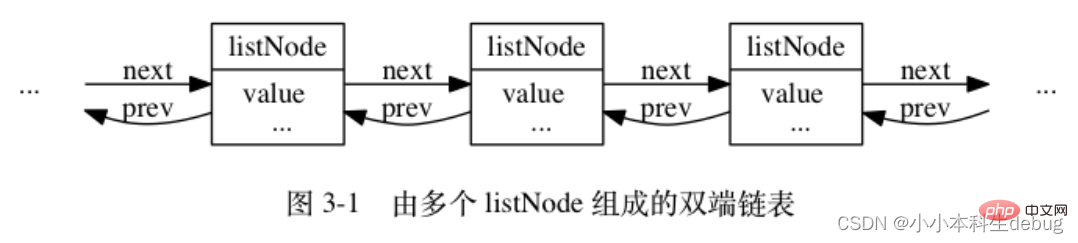
虽然仅仅使用多个 listNode 结构就可以组成链表, 但使用 adlist.h/list 来持有链表的话, 操作起来会更方便:
typedef struct list {
// 表头节点
listNode *head;
// 表尾节点
listNode *tail;
// 链表所包含的节点数量
unsigned long len;
// 节点值复制函数
void *(*dup)(void *ptr);
// 节点值释放函数
void (*free)(void *ptr);
// 节点值对比函数
int (*match)(void *ptr, void *key);} list;list 结构为链表提供了表头指针 head 、表尾指针 tail , 以及链表长度计数器 len , 而 dup 、 free 和 match 成员则是用于实现多态链表所需的类型特定函数:
① dup 函数用于复制链表节点所保存的值;
② free 函数用于释放链表节点所保存的值;
③ match 函数则用于对比链表节点所保存的值和另一个输入值是否相等。
图 3-2 是由一个 list 结构和三个 listNode 结构组成的链表: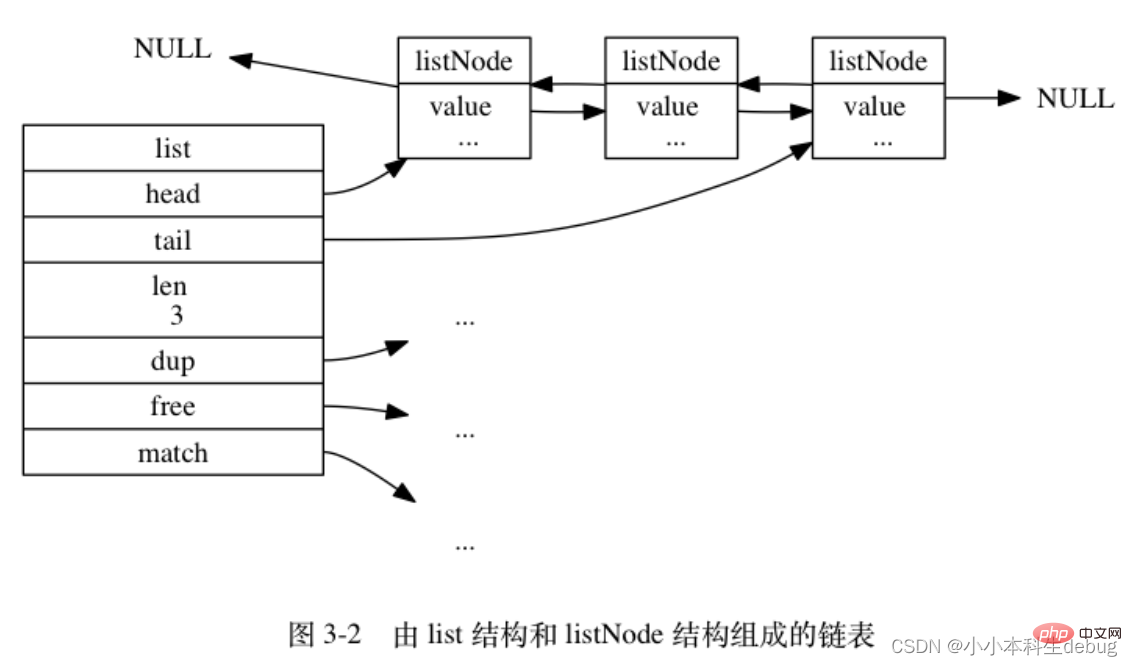
Redis 的链表实现的特性可以总结如下:
①双端: 链表节点带有 prev 和 next 指针, 获取某个节点的前置节点和后置节点的复杂度都是 O(1) 。
②无环: 表头节点的 prev 指针和表尾节点的 next 指针都指向 NULL , 对链表的访问以 NULL 为终点。
③带表头指针和表尾指针: 通过 list 结构的 head 指针和 tail 指针, 程序获取链表的表头节点和表尾节点的复杂度为 O(1) 。
④带链表长度计数器: 程序使用 list 结构的 len 属性来对 list 持有的链表节点进行计数, 程序获取链表中节点数量的复杂度为 O(1) 。
⑤多态: 链表节点使用 void* 指针来保存节点值, 并且可以通过 list 结构的 dup 、 free 、 match 三个属性为节点值设置类型特定函数, 所以链表可以用于保存各种不同类型的值。
3、字典
字典又称为符号表或者关联数组、或映射(map),是一种用于保存键值对的抽象数据结构。字典中的每一个键 key 都是唯一的,通过 key 可以对值来进行查找或修改。C 语言中没有内置这种数据结构的实现,所以字典依然是 Redis 自己构建的。
Redis 的字典使用哈希表作为底层实现, 一个哈希表里面可以有多个哈希表节点, 而每个哈希表节点就保存了字典中的一个键值对。
哈希表
Redis 字典所使用的哈希表由 dict.h/dictht 结构定义:
typedef struct dictht {
// 哈希表数组
dictEntry **table;
// 哈希表大小
unsigned long size;
// 哈希表大小掩码,用于计算索引值
// 总是等于 size - 1
unsigned long sizemask;
// 该哈希表已有节点的数量
unsigned long used;} dictht;图 4-1 展示了一个大小为 4 的空哈希表 (没有包含任何键值对)。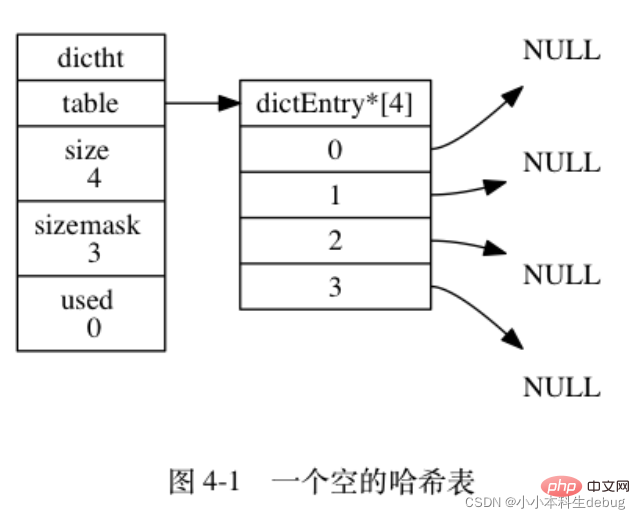
哈希表节点
哈希表节点使用 dictEntry 结构表示, 每个 dictEntry 结构都保存着一个键值对:
typedef struct dictEntry {
// 键
void *key;
// 值
union {
void *val;
uint64_t u64;
int64_t s64;
} v;
// 指向下个哈希表节点,形成链表
struct dictEntry *next;} dictEntry;key 用来保存键,val 属性用来保存值,值可以是一个指针,也可以是uint64_t 整数,也可以是 int64_t 整数。
注意这里还有一个指向下一个哈希表节点的指针,我们知道哈希表最大的问题是存在哈希冲突,如何解决哈希冲突,有开放地址法和链地址法。这里采用的便是链地址法,通过 next 这个指针可以将多个哈希值相同的键值对连接在一起,用来解决哈希冲突。
(因为 dictEntry 节点组成的链表没有指向链表表尾的指针, 所以为了速度考虑, 程序总是将新节点添加到链表的表头位置(复杂度为 O(1)), 排在其他已有节点的前面。)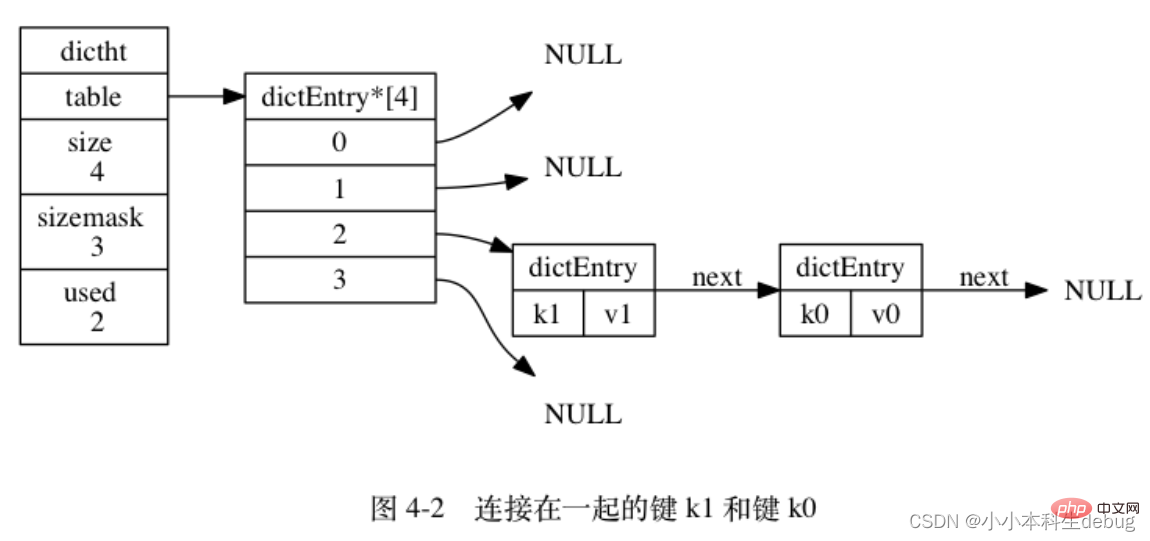
字典
Redis 中的字典由 dict.h/dict 结构表示:
typedef struct dict {
// 类型特定函数
dictType *type;
// 私有数据
void *privdata;
// 哈希表
dictht ht[2];
// rehash 索引
// 当 rehash 不在进行时,值为 -1
int rehashidx;
/* rehashing not in progress if rehashidx == -1 */} dict;type 属性和 privdata 属性是针对不同类型的键值对, 为创建多态字典而设置的:
● type 属性是一个指向 dictType 结构的指针, 每个 dictType 结构保存了一簇用于操作特定类型键值对的函数, Redis 会为用途不同的字典设置不同的类型特定函数。
● 而 privdata 属性则保存了需要传给那些类型特定函数的可选参数。
typedef struct dictType {
// 计算哈希值的函数
unsigned int (*hashFunction)(const void *key);
// 复制键的函数
void *(*keyDup)(void *privdata, const void *key);
// 复制值的函数
void *(*valDup)(void *privdata, const void *obj);
// 对比键的函数
int (*keyCompare)(void *privdata, const void *key1, const void *key2);
// 销毁键的函数
void (*keyDestructor)(void *privdata, void *key);
// 销毁值的函数
void (*valDestructor)(void *privdata, void *obj);} dictType;ht 属性是一个包含两个项的数组, 数组中的每个项都是一个 dictht 哈希表, 一般情况下, 字典只使用 ht[0] 哈希表, ht[1] 哈希表只会在对 ht[0] 哈希表进行 rehash 时使用。
除了 ht[1] 之外, 另一个和 rehash 有关的属性就是 rehashidx : 它记录了 rehash 目前的进度, 如果目前没有在进行 rehash , 那么它的值为 -1 。
图 4-3 展示了一个普通状态下(没有进行 rehash)的字典: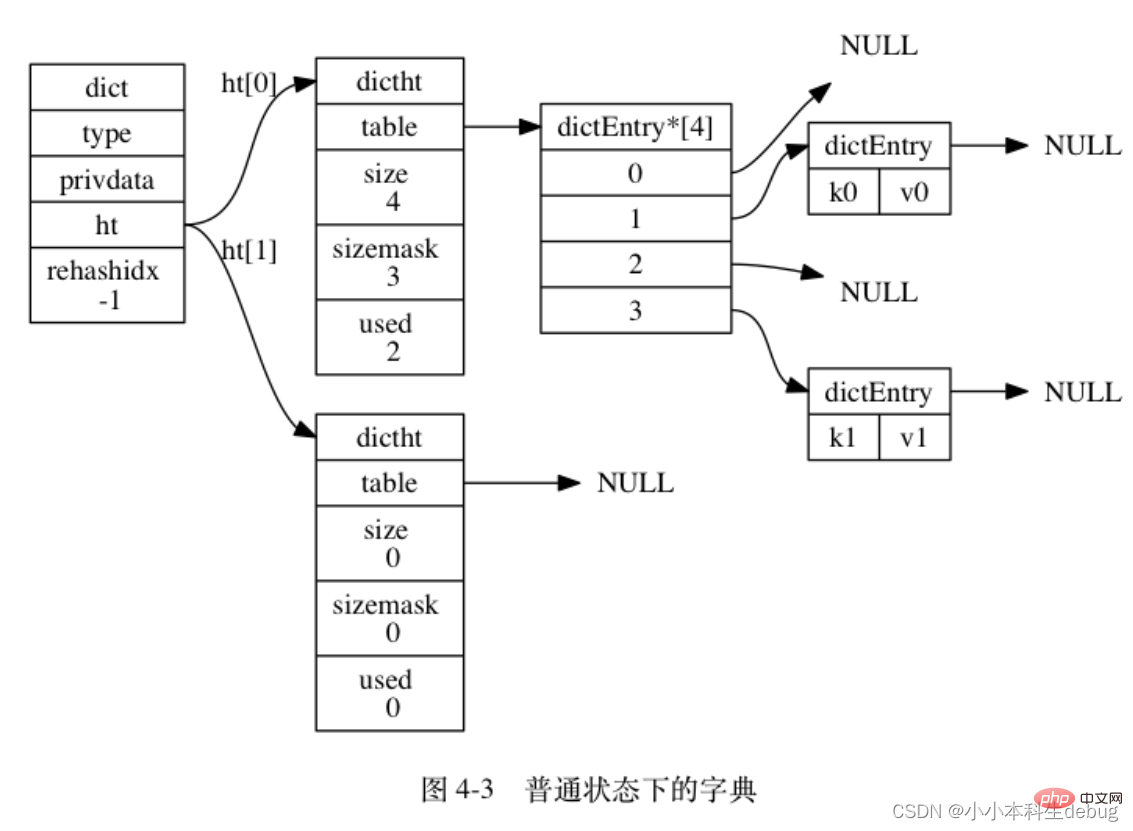
① 哈希算法:Redis计算哈希值和索引值方法如下:
# 使用字典设置的哈希函数,计算键 key 的哈希值 hash = dict->type->hashFunction(key);# 使用哈希表的 sizemask 属性和哈希值,计算出索引值 # 根据情况不同, ht[x] 可以是 ht[0] 或者 ht[1]index = hash & dict->ht[x].sizemask;
②解决哈希冲突:这个问题上面我们介绍了,方法是链地址法。通过字典里面的 *next 指针指向下一个具有相同索引值的哈希表节点。
③扩容和收缩(rehash):当哈希表保存的键值对太多或者太少时,就要通过 rerehash(重新散列)来对哈希表进行相应的扩展或者收缩。具体步骤:
1、为字典的 ht[1] 哈希表分配空间, 这个哈希表的空间大小取决于要执行的操作, 以及 ht[0] 当前包含的键值对数量 (也即是 ht[0].used 属性的值)
● 如果执行的是扩展操作, 那么 ht[1] 的大小为第一个大于等于 ht[0].used * 2n; (也就是每次扩展都是根据原哈希表已使用的空间扩大一倍创建另一个哈希表)
● 如果执行的是收缩操作, 每次收缩是根据已使用空间缩小一倍创建一个新的哈希表。
2、将保存在 ht[0] 中的所有键值对 rehash 到 ht[1] 上面: rehash 指的是重新计算键的哈希值和索引值, 然后将键值对放置到 ht[1] 哈希表的指定位置上。
3、当 ht[0] 包含的所有键值对都迁移到了 ht[1] 之后 (ht[0] 变为空表), 释放 ht[0] , 将 ht[1] 设置为 ht[0] , 并在 ht[1] 新创建一个空白哈希表, 为下一次 rehash 做准备。
④触发扩容与收缩的条件:
1、服务器目前没有执行 BGSAVE 命令或者 BGREWRITEAOF 命令,并且负载因子大于等于1。
2、服务器目前正在执行 BGSAVE 命令或者 BGREWRITEAOF 命令,并且负载因子大于等于5。
ps:负载因子 = 哈希表已保存节点数量 / 哈希表大小。
3、另一方面, 当哈希表的负载因子小于 0.1 时, 程序自动开始对哈希表执行收缩操作。
⑤渐近式 rehash
什么叫渐进式 rehash?也就是说扩容和收缩操作不是一次性、集中式完成的,而是分多次、渐进式完成的。如果保存在Redis中的键值对只有几个几十个,那么 rehash 操作可以瞬间完成,但是如果键值对有几百万,几千万甚至几亿,那么要一次性的进行 rehash,势必会造成Redis一段时间内不能进行别的操作。所以Redis采用渐进式 rehash,这样在进行渐进式rehash期间,字典的删除查找更新等操作可能会在两个哈希表上进行,第一个哈希表没有找到,就会去第二个哈希表上进行查找。但是进行增加操作,一定是在新的哈希表上进行的。
4、跳跃表
跳跃表(skiplist)是一种有序数据结构,它通过在每个节点中维持多个指向其它节点的指针,从而达到快速访问节点的目的。
具有如下性质:
1、由很多层结构组成;
2、每一层都是一个有序的链表,排列顺序为由高层到底层,都至少包含两个链表节点,分别是前面的head节点和后面的nil节点;
3、最底层的链表包含了所有的元素;
4、如果一个元素出现在某一层的链表中,那么在该层之下的链表也全都会出现(上一层的元素是当前层的元素的子集);
5、链表中的每个节点都包含两个指针,一个指向同一层的下一个链表节点,另一个指向下一层的同一个链表节点;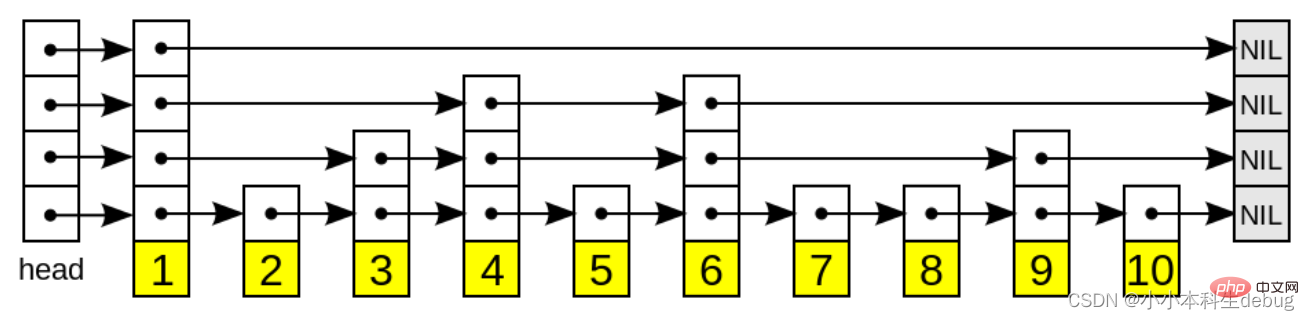
和链表、字典等数据结构被广泛地应用在 Redis 内部不同, Redis 只在两个地方用到了跳跃表, 一个是实现有序集合键, 另一个是在集群节点中用作内部数据结构, 除此之外, 跳跃表在 Redis 里面没有其他用途。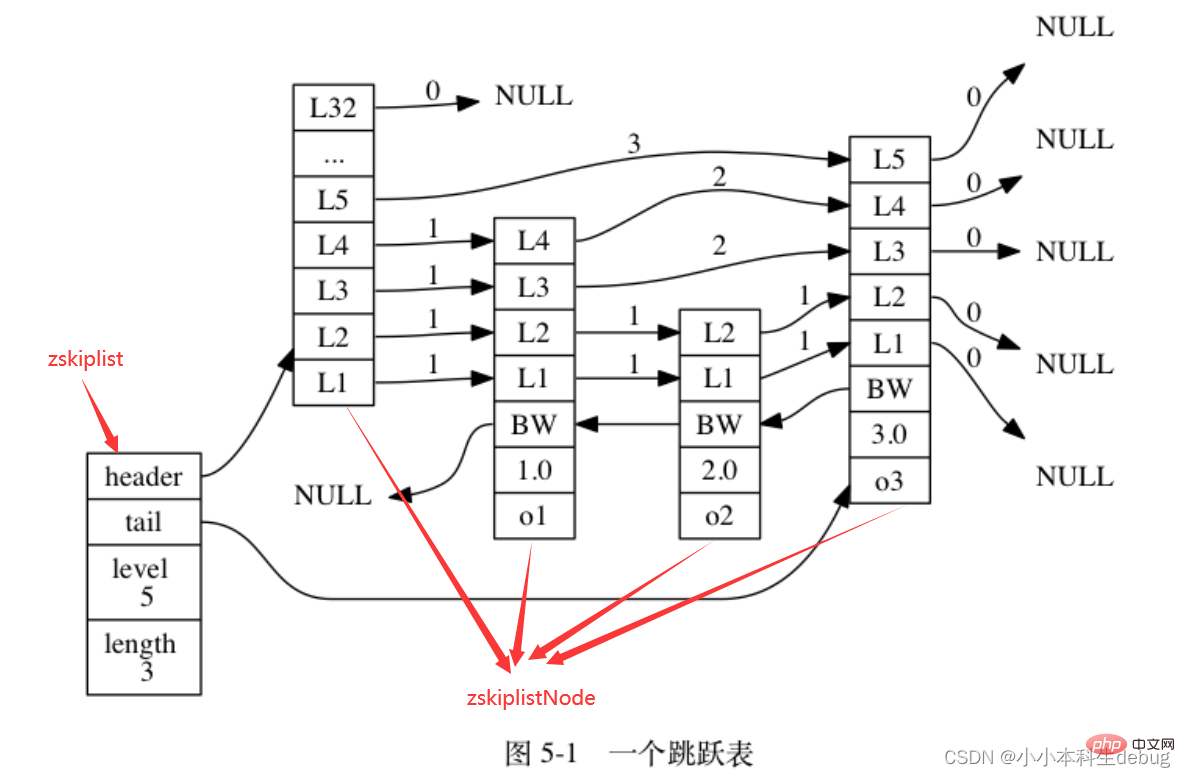
跳跃表节点(zskiplistNode)
该结构包含以下属性:
①层(level):节点中用 L1 、 L2 、 L3 等字样标记节点的各个层, L1 代表第一层, L2 代表第二层,以此类推。每个层都带有两个属性:前进指针和跨度。前进指针用于访问位于表尾方向的其他节点,而跨度则记录了前进指针所指向节点和当前节点的距离。在上面的图片中,连线上带有数字的箭头就代表前进指针,而那个数字就是跨度。当程序从表头向表尾进行遍历时,访问会沿着层的前进指针进行。
每次创建一个新跳跃表节点的时候, 程序都根据幂次定律 (power law,越大的数出现的概率越小) 随机生成一个介于 1 和 32 之间的值作为 level 数组的大小, 这个大小就是层的“高度”。(所以说表头节点的高度就是32)
②后退(backward)指针:节点中用 BW 字样标记节点的后退指针,它指向位于当前节点的前一个节点。后退指针在程序从表尾向表头遍历时使用。
③分值(score):各个节点中的 1.0 、 2.0 和 3.0 是节点所保存的分值。在跳跃表中,节点按各自所保存的分值从小到大排列。
④成员对象(obj):各个节点中的 o1 、 o2 和 o3 是节点所保存的成员对象。
注意表头节点和其他节点的构造是一样的: 表头节点也有后退指针、分值和成员对象, 不过表头节点的这些属性都不会被用到, 所以图中省略了这些部分, 只显示了表头节点的各个层。
跳跃表(zskiplist)
① header :指向跳跃表的表头节点。
② tail :指向跳跃表的表尾节点。
③ level :记录目前跳跃表内,层数最大的那个节点的层数(表头节点的层数不计算在内)。
④ length :记录跳跃表的长度,也即是,跳跃表目前包含节点的数量(表头节点不计算在内)。
5、整数集合
整数集合(intset)是集合键的底层实现之一,当一个集合只包含整数值元素,并且这个集合的元素数量不多时,Redis就会使用集合作为集合键的底层实现。
整数集合(intset)是Redis用于保存整数值的集合抽象数据类型,它可以保存类型为int16_t、int32_t 或者int64_t 的整数值,并且保证集合中不会出现重复元素。
每个 intset.h/intset 结构表示一个整数集合:
typedef struct intset {
// 编码方式
uint32_t encoding;
// 集合包含的元素数量
uint32_t length;
// 保存元素的数组
int8_t contents[];} intset;整数集合的每个元素都是 contents 数组的一个数据项,它们按照从小到大的顺序排列,并且不包含任何重复项。
length 属性记录了 contents 数组的大小。
需要注意的是虽然 contents 数组声明为 int8_t 类型,但是实际上contents 数组并不保存任何 int8_t 类型的值,其真正类型有 encoding 来决定。
① 升级(encoding int16_t -> int32_t -> int64_t)
当我们新增的元素类型比原集合元素类型的长度要大时,需要对整数集合进行升级,才能将新元素放入整数集合中。具体步骤:
1、根据新元素类型,扩展整数集合底层数组的大小,并为新元素分配空间。
2、将底层数组现有的所有元素都转成与新元素相同类型的元素,并将转换后的元素放到正确的位置,放置过程中,维持整个元素顺序都是有序的。
3、将新元素添加到整数集合中(保证有序)。
升级能极大地节省内存。
② 降级
整数集合不支持降级操作,一旦对数组进行了升级,编码就会一直保持升级后的状态。
6、压缩列表
压缩列表(ziplist)是列表键和哈希键的底层实现之一。
当一个列表键只包含少量列表项, 并且每个列表项要么就是小整数值, 要么就是长度比较短的字符串, 那么 Redis 就会使用压缩列表来做列表键的底层实现。
因为哈希键里面包含的所有键和值都是小整数值或者短字符串。
压缩列表是 Redis 为了节约内存而开发的, 由一系列特殊编码的连续内存块组成的顺序型(sequential)数据结构。
압축된 목록에는 원하는 수의 노드(항목)가 포함될 수 있으며 각 노드는 바이트 배열 또는 정수 값을 저장할 수 있습니다. 
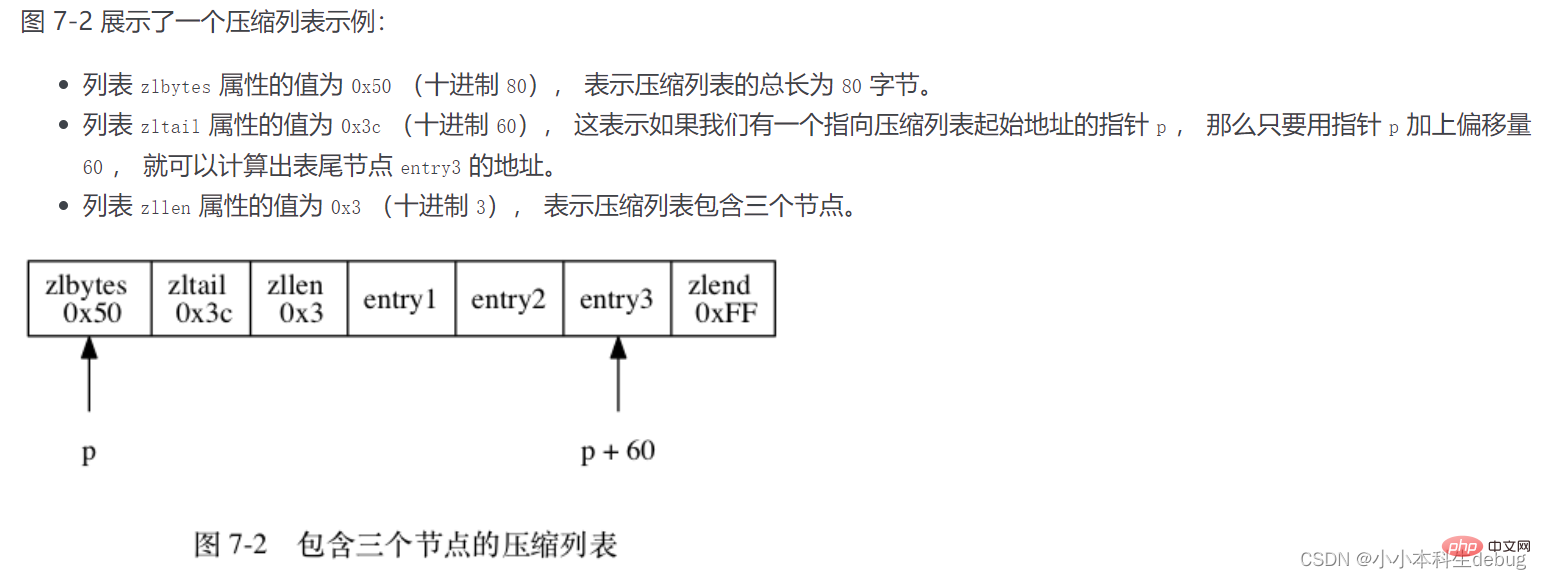
각 압축 목록 노드는 이전_항목 길이, 인코딩, 콘텐츠의 세 부분으로 구성됩니다.
① 이전_항목_ength: 압축 목록의 이전 바이트 길이를 기록합니다. Previous_entry_ength의 길이는 1바이트 또는 5바이트일 수 있습니다. 이전 노드의 길이가 254보다 작은 경우 해당 노드는 이전 노드의 길이를 나타내는 데 1바이트만 필요합니다. 이전 노드의 길이가 254보다 크거나 같으면 속성의 첫 번째 바이트는 254이고 다음 4바이트는 현재 노드의 이전 노드의 길이를 나타냅니다. 이 원리를 사용하면 현재 노드 위치에서 이전 노드의 길이를 빼서 이전 노드의 시작 위치를 구합니다. 압축된 목록은 꼬리에서 머리까지 순회할 수 있습니다. 이렇게 하면 메모리 낭비가 효과적으로 줄어듭니다.
② 인코딩: 노드의 인코딩은 노드의 콘텐츠 유형과 길이를 저장합니다. 인코딩 유형에는 바이트 배열과 정수가 있습니다. 바이트 또는 5바이트 길이입니다. 
③ 콘텐츠: 콘텐츠 영역은 노드의 콘텐츠를 저장하는 데 사용됩니다. 노드 콘텐츠 유형과 길이는 인코딩에 따라 결정됩니다. 
체인 업데이트 문제
최악의 경우 체인 업데이트에는 압축된 목록에서 N개의 공간 재할당 작업이 필요하며, 각 공간 재할당의 최악의 복잡도는 O(N)이므로 체인 업데이트의 최소 비용은 다음과 같습니다. 나쁜 복잡도는 O(N^2)입니다.
체인 업데이트의 복잡성은 높지만 실제로 성능 문제를 일으킬 가능성은 매우 낮다는 점에 유의해야 합니다.
권장 학습: Redis 학습 튜토리얼
위 내용은 Redis의 6가지 기본 데이터 구조를 요약하고 구성합니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

Video Face Swap
완전히 무료인 AI 얼굴 교환 도구를 사용하여 모든 비디오의 얼굴을 쉽게 바꾸세요!

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7695
7695
 15
1640
14
1393
52
1287
25
1229
29
15
1640
14
1393
52
1287
25
1229
29

 Redis 클러스터 모드를 구축하는 방법
Apr 10, 2025 pm 10:15 PM
Redis 클러스터 모드를 구축하는 방법
Apr 10, 2025 pm 10:15 PM
Redis Cluster Mode는 Sharding을 통해 Redis 인스턴스를 여러 서버에 배포하여 확장 성 및 가용성을 향상시킵니다. 시공 단계는 다음과 같습니다. 포트가 다른 홀수 redis 인스턴스를 만듭니다. 3 개의 센티넬 인스턴스를 만들고, Redis 인스턴스 및 장애 조치를 모니터링합니다. Sentinel 구성 파일 구성, Redis 인스턴스 정보 및 장애 조치 설정 모니터링 추가; Redis 인스턴스 구성 파일 구성, 클러스터 모드 활성화 및 클러스터 정보 파일 경로를 지정합니다. 각 redis 인스턴스의 정보를 포함하는 Nodes.conf 파일을 작성합니다. 클러스터를 시작하고 Create 명령을 실행하여 클러스터를 작성하고 복제본 수를 지정하십시오. 클러스터에 로그인하여 클러스터 정보 명령을 실행하여 클러스터 상태를 확인하십시오. 만들다
 Redis 데이터를 지우는 방법
Apr 10, 2025 pm 10:06 PM
Redis 데이터를 지우는 방법
Apr 10, 2025 pm 10:06 PM
Redis 데이터를 지우는 방법 : Flushall 명령을 사용하여 모든 키 값을 지우십시오. FlushDB 명령을 사용하여 현재 선택한 데이터베이스의 키 값을 지우십시오. 선택을 사용하여 데이터베이스를 전환 한 다음 FlushDB를 사용하여 여러 데이터베이스를 지우십시오. del 명령을 사용하여 특정 키를 삭제하십시오. Redis-Cli 도구를 사용하여 데이터를 지우십시오.
 Redis 대기열을 읽는 방법
Apr 10, 2025 pm 10:12 PM
Redis 대기열을 읽는 방법
Apr 10, 2025 pm 10:12 PM
Redis의 대기열을 읽으려면 대기열 이름을 얻고 LPOP 명령을 사용하여 요소를 읽고 빈 큐를 처리해야합니다. 특정 단계는 다음과 같습니다. 대기열 이름 가져 오기 : "큐 :"와 같은 "대기열 : my-queue"의 접두사로 이름을 지정하십시오. LPOP 명령을 사용하십시오. 빈 대기열 처리 : 대기열이 비어 있으면 LPOP이 NIL을 반환하고 요소를 읽기 전에 대기열이 존재하는지 확인할 수 있습니다.
 Redis 명령을 사용하는 방법
Apr 10, 2025 pm 08:45 PM
Redis 명령을 사용하는 방법
Apr 10, 2025 pm 08:45 PM
Redis 지시 사항을 사용하려면 다음 단계가 필요합니다. Redis 클라이언트를 엽니 다. 명령 (동사 키 값)을 입력하십시오. 필요한 매개 변수를 제공합니다 (명령어마다 다름). 명령을 실행하려면 Enter를 누르십시오. Redis는 작업 결과를 나타내는 응답을 반환합니다 (일반적으로 OK 또는 -err).
 Redis Lock을 사용하는 방법
Apr 10, 2025 pm 08:39 PM
Redis Lock을 사용하는 방법
Apr 10, 2025 pm 08:39 PM
Redis를 사용하여 잠금 작업을 사용하려면 SetNX 명령을 통해 잠금을 얻은 다음 만료 명령을 사용하여 만료 시간을 설정해야합니다. 특정 단계는 다음과 같습니다. (1) SETNX 명령을 사용하여 키 값 쌍을 설정하십시오. (2) 만료 명령을 사용하여 잠금의 만료 시간을 설정하십시오. (3) DEL 명령을 사용하여 잠금이 더 이상 필요하지 않은 경우 잠금을 삭제하십시오.
 Redis의 소스 코드를 읽는 방법
Apr 10, 2025 pm 08:27 PM
Redis의 소스 코드를 읽는 방법
Apr 10, 2025 pm 08:27 PM
Redis 소스 코드를 이해하는 가장 좋은 방법은 단계별로 이동하는 것입니다. Redis의 기본 사항에 익숙해집니다. 특정 모듈을 선택하거나 시작점으로 기능합니다. 모듈 또는 함수의 진입 점으로 시작하여 코드를 한 줄씩 봅니다. 함수 호출 체인을 통해 코드를 봅니다. Redis가 사용하는 기본 데이터 구조에 익숙해 지십시오. Redis가 사용하는 알고리즘을 식별하십시오.
 Redis 명령 줄을 사용하는 방법
Apr 10, 2025 pm 10:18 PM
Redis 명령 줄을 사용하는 방법
Apr 10, 2025 pm 10:18 PM
Redis Command Line 도구 (Redis-Cli)를 사용하여 다음 단계를 통해 Redis를 관리하고 작동하십시오. 서버에 연결하고 주소와 포트를 지정하십시오. 명령 이름과 매개 변수를 사용하여 서버에 명령을 보냅니다. 도움말 명령을 사용하여 특정 명령에 대한 도움말 정보를 봅니다. 종금 명령을 사용하여 명령 줄 도구를 종료하십시오.
 Centos redis에서 lua 스크립트 실행 시간을 구성하는 방법
Apr 14, 2025 pm 02:12 PM
Centos redis에서 lua 스크립트 실행 시간을 구성하는 방법
Apr 14, 2025 pm 02:12 PM
CentOS 시스템에서는 Redis 구성 파일을 수정하거나 Redis 명령을 사용하여 악의적 인 스크립트가 너무 많은 리소스를 소비하지 못하게하여 LUA 스크립트의 실행 시간을 제한 할 수 있습니다. 방법 1 : Redis 구성 파일을 수정하고 Redis 구성 파일을 찾으십시오. Redis 구성 파일은 일반적으로 /etc/redis/redis.conf에 있습니다. 구성 파일 편집 : 텍스트 편집기 (예 : VI 또는 Nano)를 사용하여 구성 파일을 엽니 다. Sudovi/etc/redis/redis.conf LUA 스크립트 실행 시간 제한을 설정 : 구성 파일에서 다음 줄을 추가 또는 수정하여 LUA 스크립트의 최대 실행 시간을 설정하십시오 (Unit : Milliseconds).
