

mysql 읽기 및 쓰기 분리 구현 방법은 무엇입니까?

mysql에서는 "mysql-proxy"를 사용하여 읽기-쓰기 분리를 달성할 수 있습니다. "mysql-proxy"는 미들웨어라고도 불리는 읽기-쓰기 분리를 달성하기 위해 mysql에서 공식적으로 제공하는 소프트웨어입니다. 쓰기 작업. 데이터베이스에서 쿼리를 처리할 때 마스터-슬레이브 복제를 통해 데이터베이스 일관성이 달성됩니다.

이 튜토리얼의 운영 환경: windows10 시스템, mysql8.0.22 버전, Dell G3 컴퓨터.
mysql 읽기 및 쓰기 분리 구현 방법은 무엇인가요?
읽기 및 쓰기 분리를 구현할 수 있는 Mysql 플러그인에는 mysql-proxy / Mycat / Amoeba와 함께 제공되는 플러그인이 있습니다. 이 실험은 이를 달성하기 위해 주로 사용됩니다. 읽기/쓰기 분할
mysql-proxy는 "읽기/쓰기 분할"(MySQL에서 공식적으로 제공, 미들웨어라고도 함)을 구현하는 소프트웨어입니다. 데이터베이스는 쓰기 작업(삽입, 업데이트, 삭제)을 처리하고 데이터베이스에서 쿼리 작업(선택)을 처리합니다. 데이터베이스의 일관성은 마스터-슬레이브 복제를 통해 달성됩니다
MySQL-프록시는 주로 내부 Lua 스크립트(읽기 및 쓰기 문 판단을 실현할 수 있음)에 의존하여 읽기 및 쓰기 문 간의 구별을 실현할 수 있습니다
만약 그렇다면 메인 서버에서만(쓰기 서버에서 데이터 쓰기 작업이 완료됨) 이때 슬레이브 서버에서는 쓰기 작업이 수행되지 않으며, 이 때 다른 기술을 사용해야 합니다. 마스터-슬레이브 복제 기술이라 불리는 이 기술은 읽기-쓰기 분리의 기본입니다.
읽기-쓰기 분리(MySQL-Proxy) 마스터는 쓰기 작업을 처리하고 슬레이브는 읽기 작업을 처리하게 합니다. 상대적으로 읽기 작업량이 많은 시나리오에 매우 적합하며 마스터의 작업량을 줄일 수 있습니다.
mysql-proxy를 사용하여 읽기와 쓰기의 분리를 실현하세요. mysql.mysql-proxy는 실제로 백엔드 mysql 마스터-슬레이브 서버의 프록시 역할을 하며 클라이언트의 요청을 직접 받아들이고 SQL 문을 분석하여 읽기 작업인지 쓰기 작업인지 결정합니다. 해당 mysql 서버에 배포
데이터베이스 쓰기 작업은 읽기 작업보다 시간이 많이 걸리기 때문에 데이터베이스 읽기와 쓰기를 분리하면 데이터베이스에 쓰기 문제가 해결되어 쿼리 효율성에 영향을 미칩니다.
server1에서 server2로 gtid 마스터-슬레이브 복제를 먼저 구성하세요
gtid 마스터-슬레이브 복제는 이전 블로그에서 설명했기 때문에 여기서는 자세히 설명하지 않고 최종 효과만 보여드리겠습니다
westos라는 것을 알 수 있습니다 server1에 데이터베이스가 구축되고 해당 server2가 동기화됩니다

 server3 프록시 구성(mysql-proxy)
server3 프록시 구성(mysql-proxy)
server3에 mysql-proxy 프록시 서버 구축(클라이언트가 server1에 쓰고 server2에서 데이터를 읽을 수 있음) )
(1) 물리적 머신 패키지에서 server3
에 대한 mysql-proxy 설치를 가져옵니다. (2) server3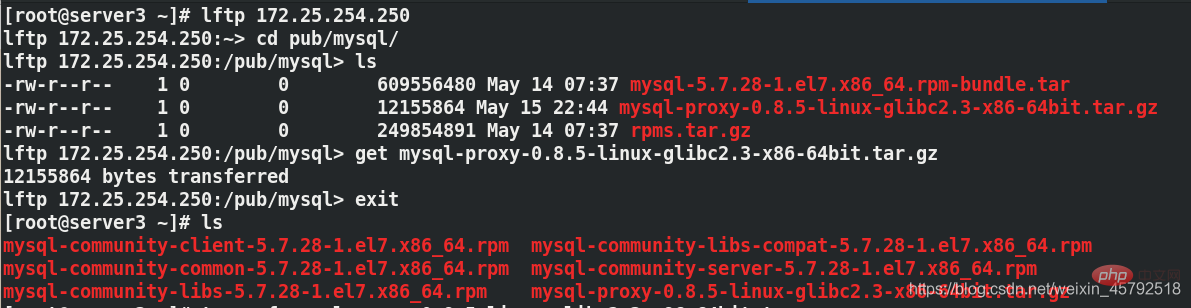
[root@server3 ~]# systemctl status mysqld ##查看mysqld服务状态 [root@server3 ~]# systemctl stop mysqld ##关闭mysqld服务,因为代理服务器要用3306端口 [root@server3 ~]# tar zxf mysql-proxy-0.8.5-linux-glibc2-x86-64bit.tar.gz -C /usr/local/ ##解压到/usr/local/目录下
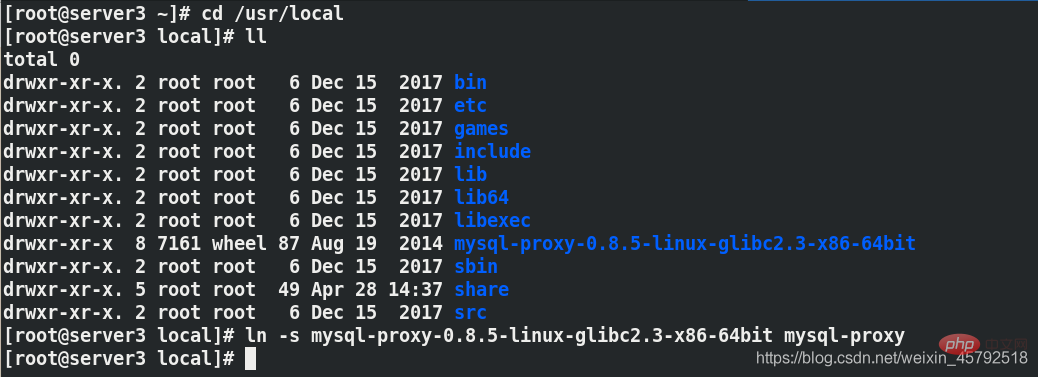
에서 구성 관리를 위한 소프트 연결 만들기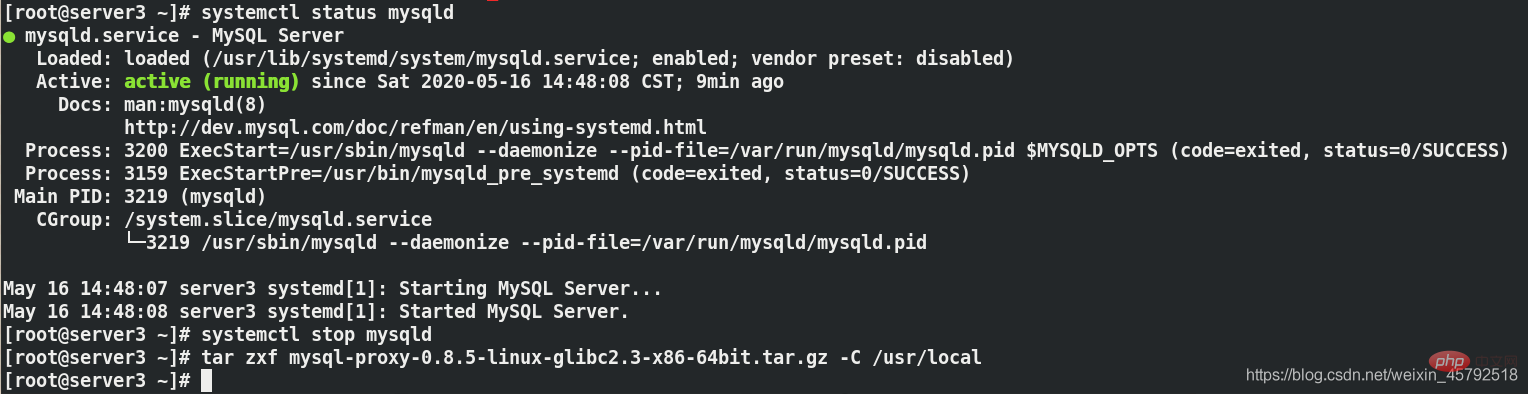
ln -s mysql-proxy-0.8.5-linux-glibc2-x86-64bit mysql-proxy
 구성 파일이 없습니다. mysql-proxy 디렉터리이므로 직접 구성 파일을 생성해야 합니다. Directory, 구성 파일을 생성하세요
구성 파일이 없습니다. mysql-proxy 디렉터리이므로 직접 구성 파일을 생성해야 합니다. Directory, 구성 파일을 생성하세요
다음 두 명령을 사용하여 구성 파일에 적힌 매개변수를 확인하세요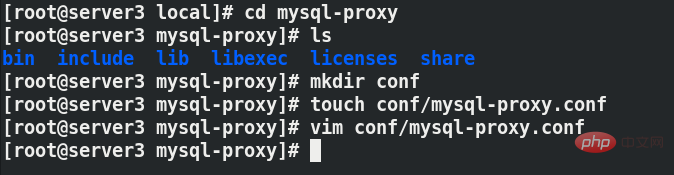
[root@server3 bin]# ./mysql-proxy --help [root@server3 bin]# ./mysql-proxy --help-proxy
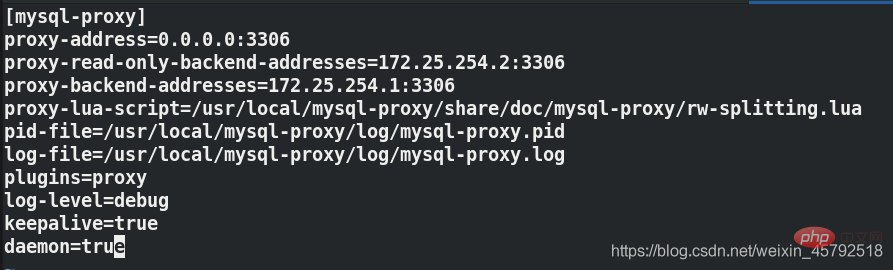
[mysql-proxy] ##指定语句块 proxy-address=0.0.0.0:3306 ##指定proxy访问的主机和端口,3306是一个对外的通用端口 proxy-read-only-backend-addresses=172.25.254.2:3306 ##读主机的ip和端口 proxy-backend-addresses=172.25.254.1:3306 ##执行写主机的ip和端口 proxy-lua-script=/usr/local/mysql-proxy/share/doc/mysql-proxy/rw-splitting.lua ##指定读写分离操作使用的lua文件路径 pid-file=/usr/local/mysql-proxy/log/mysql-proxy.pid ##pid存放路径 log-file=/usr/local/mysql-proxy/log/mysql-proxy.log ##日志存放路径 plugins=proxy ##指定使用的插件 log-level=debug ##日志的等级 keepalive=true ##开启守护进程 daemon=true ##使用后台方式运行
 저장 후, 구성 파일의 권한을 660으로 변경하고 로그 디렉터리를 생성해야 합니다
저장 후, 구성 파일의 권한을 660으로 변경하고 로그 디렉터리를 생성해야 합니다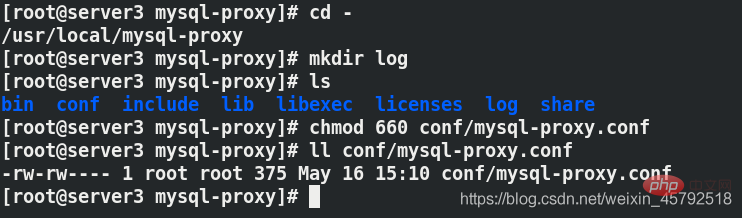 데이터베이스에서 읽기-쓰기 분리가 발생할 때 최대 및 최소 연결 수를 수정합니다
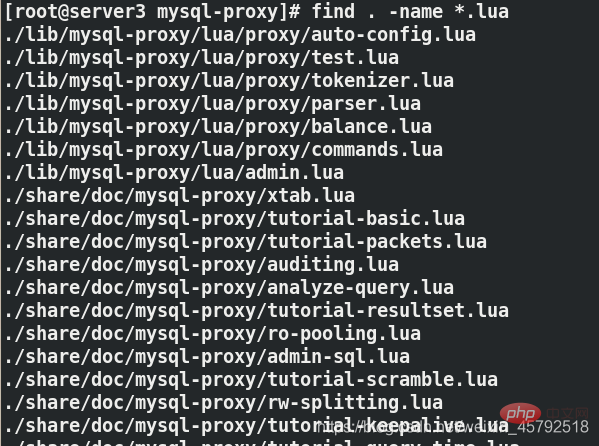
데이터베이스에서 읽기-쓰기 분리가 발생할 때 최대 및 최소 연결 수를 수정합니다[root@server3 mysql-proxy]# find . -name *.lua
./share/doc/mysql-proxy/rw-splitting.lua
[root@server3 mysql-proxy]# cd share/doc/mysql-proxy
[root@server3 mysql-proxy]# ls
[root@server3 mysql-proxy]# vim rw-splitting.lua ##将lua脚本里原本启动机制的最小4个最大8个连接,改为1和2
min_idle_connections = 1, 最小连接数
max_idle_connections = 2, 最大连接数

(3 ) mysql-proxy 시작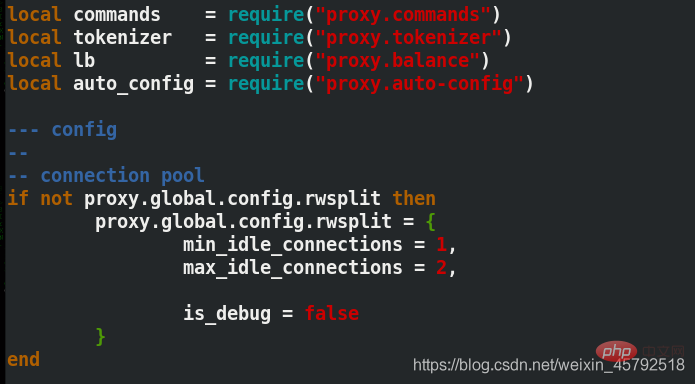
/usr/local/mysql-proxy/bin/mysql-proxy --defaults-file=/usr/local/mysql-proxy/conf/mysql-proxy.conf ##启动 cat /usr/local/mysql-proxy/log/mysql-proxy.log ##查看日志
 읽기-쓰기 분리 테스트
읽기-쓰기 분리 테스트
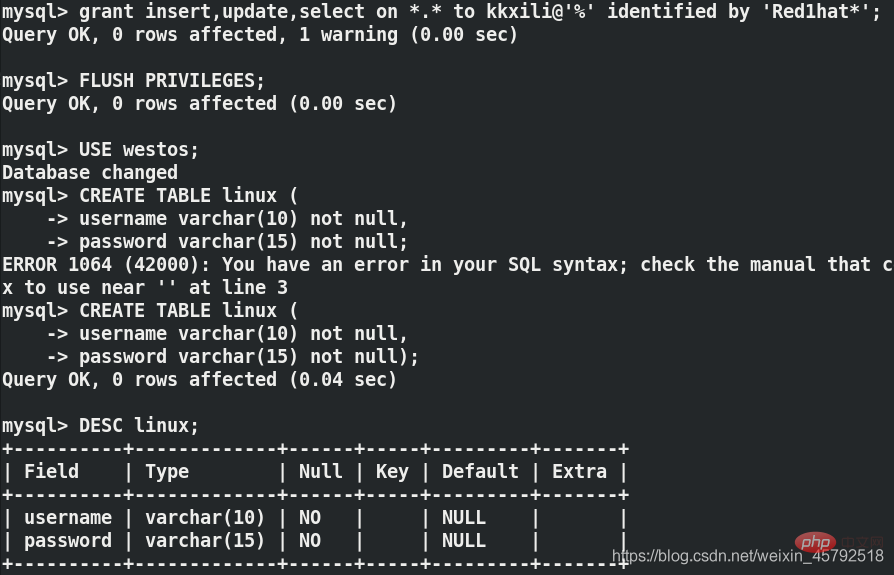
(1) server1에 새 서버를 생성하고 권한을 부여받은 사용자
mysql> grant insert,update,select on *.* to kkxili@'%' identified by 'Red1hat*'; mysql> FLUSH PRIVILEGES; ##刷新授权表 mysql> USE westos; Database changed mysql> CREATE TABLE linux ( -> username varchar(10) not null, -> password varchar(15) not null); mysql>DESC linux;
(2)server3安装lsof

(3)在用户端虚拟机server4上第一次连接数据库代理server3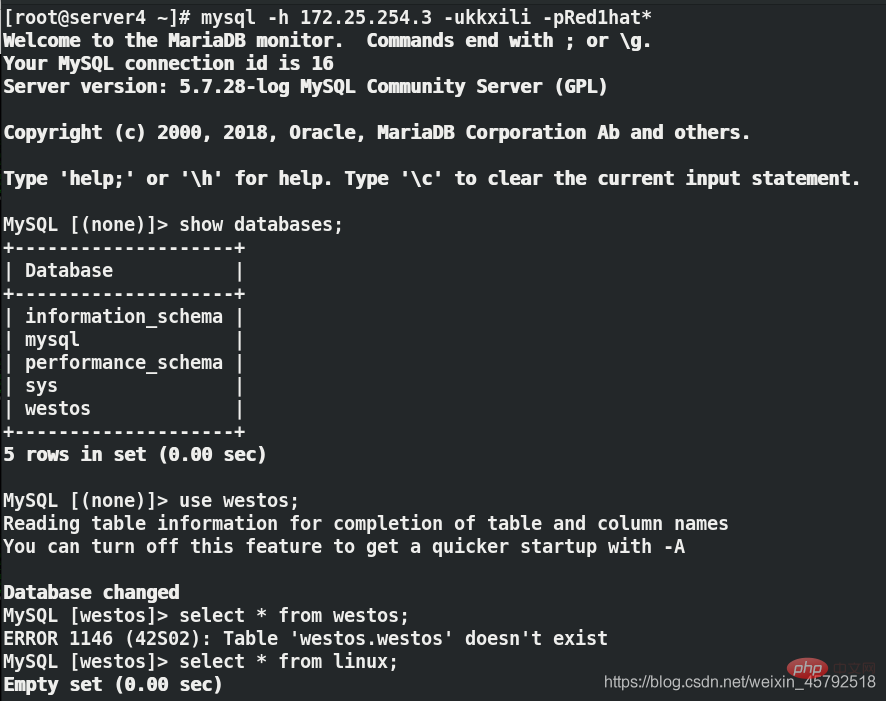
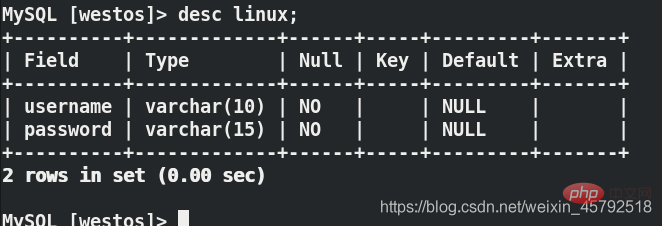
在server3上面:lsof -i:3306

(4)在用户端虚拟机server4上第二次连接数据库代理server3
在server3上面:lsof -i:3306

(5)在用户端虚拟机server4上第三次连接数据库代理server3
在server3上面:lsof -i:3306
开始读写分离
 上面是读写分离的读访问测试
上面是读写分离的读访问测试
写测试
在用户端插入数据
use westos;
insert into linux values('user1','123');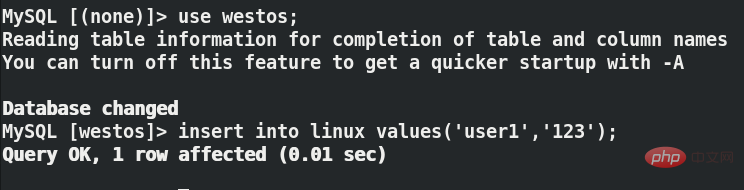
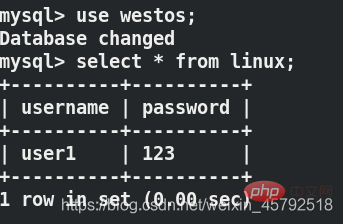
server1和server2都可以看到插入的数据
在server2中关闭主从复制
用户端再次写入数据,看不到刚刚写的数据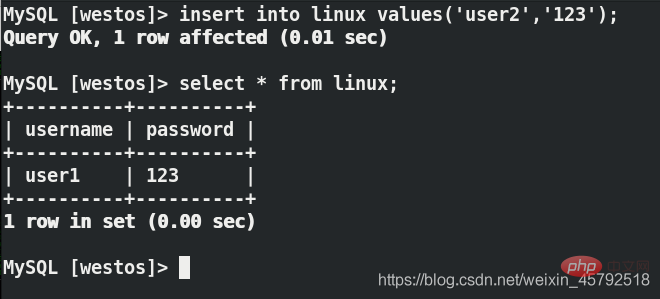
写在server1上,可以查看到数据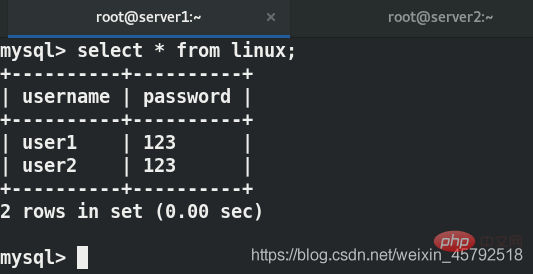
在server2上实现了读写分离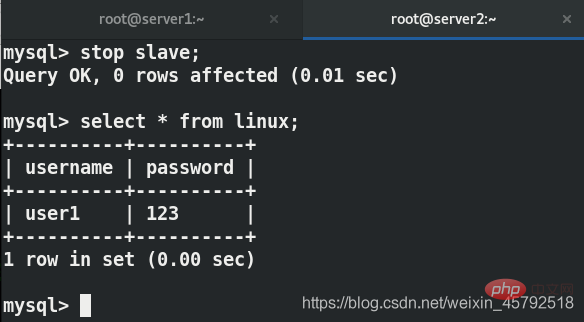
server2重新开启主从复制可以看到数据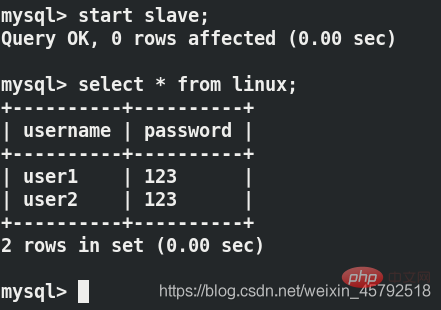
客户端读的是server2,server2只能读,不能写,因此看不到刚才写进去的东西,server1可以看到
实现了客户端(虚拟机)对server1的写,对server2的读
当访问数据库的用户数量很多时,数据库的代理就把后端的数据库实现读写分离
server1是写的数据库、server2是读的数据库
当server1和server2满足gtid的主从复制时,用户往数据库写入的数据其实是写入了server1,并没有写入server2,server2上面的数据是复制过去的,因此server1、server2、客户机上面都能查到刚刚写进去的数据,其实客户机查的是server2(读)
当关闭server1和server2的异步复制时,客户机往数据库写入的数据只写进了server1,没有写进去server2,server2也没有复制一份
因此server1可以查看到,server2和客户机上面都查不到刚刚写进去的数据,此时的客户机读的是server2
推荐学习:mysql视频教程
위 내용은 mysql 읽기 및 쓰기 분리 구현 방법은 무엇입니까?의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7491
7491
 15
1377
52
77
11
52
19
19
41
15
1377
52
77
11
52
19
19
41

 MySQL : 초보자를위한 데이터 관리의 용이성
Apr 09, 2025 am 12:07 AM
MySQL : 초보자를위한 데이터 관리의 용이성
Apr 09, 2025 am 12:07 AM
MySQL은 설치가 간단하고 강력하며 데이터를 쉽게 관리하기 쉽기 때문에 초보자에게 적합합니다. 1. 다양한 운영 체제에 적합한 간단한 설치 및 구성. 2. 데이터베이스 및 테이블 작성, 삽입, 쿼리, 업데이트 및 삭제와 같은 기본 작업을 지원합니다. 3. 조인 작업 및 하위 쿼리와 같은 고급 기능을 제공합니다. 4. 인덱싱, 쿼리 최적화 및 테이블 파티셔닝을 통해 성능을 향상시킬 수 있습니다. 5. 데이터 보안 및 일관성을 보장하기위한 지원 백업, 복구 및 보안 조치.
 Navicat Premium을 만드는 방법
Apr 09, 2025 am 07:09 AM
Navicat Premium을 만드는 방법
Apr 09, 2025 am 07:09 AM
Navicat Premium을 사용하여 데이터베이스 생성 : 데이터베이스 서버에 연결하고 연결 매개 변수를 입력하십시오. 서버를 마우스 오른쪽 버튼으로 클릭하고 데이터베이스 생성을 선택하십시오. 새 데이터베이스의 이름과 지정된 문자 세트 및 Collation의 이름을 입력하십시오. 새 데이터베이스에 연결하고 객체 브라우저에서 테이블을 만듭니다. 테이블을 마우스 오른쪽 버튼으로 클릭하고 데이터 삽입을 선택하여 데이터를 삽입하십시오.
 Navicat에서 데이터베이스 비밀번호를 검색 할 수 있습니까?
Apr 08, 2025 pm 09:51 PM
Navicat에서 데이터베이스 비밀번호를 검색 할 수 있습니까?
Apr 08, 2025 pm 09:51 PM
Navicat 자체는 데이터베이스 비밀번호를 저장하지 않으며 암호화 된 암호 만 검색 할 수 있습니다. 솔루션 : 1. 비밀번호 관리자를 확인하십시오. 2. Navicat의 "비밀번호 기억"기능을 확인하십시오. 3. 데이터베이스 비밀번호를 재설정합니다. 4. 데이터베이스 관리자에게 문의하십시오.
 MySQL : 쉽게 학습하기위한 간단한 개념
Apr 10, 2025 am 09:29 AM
MySQL : 쉽게 학습하기위한 간단한 개념
Apr 10, 2025 am 09:29 AM
MySQL은 오픈 소스 관계형 데이터베이스 관리 시스템입니다. 1) 데이터베이스 및 테이블 작성 : CreateAbase 및 CreateTable 명령을 사용하십시오. 2) 기본 작업 : 삽입, 업데이트, 삭제 및 선택. 3) 고급 운영 : 가입, 하위 쿼리 및 거래 처리. 4) 디버깅 기술 : 확인, 데이터 유형 및 권한을 확인하십시오. 5) 최적화 제안 : 인덱스 사용, 선택을 피하고 거래를 사용하십시오.
 MariaDB 용 Navicat에서 데이터베이스 비밀번호를 보는 방법은 무엇입니까?
Apr 08, 2025 pm 09:18 PM
MariaDB 용 Navicat에서 데이터베이스 비밀번호를 보는 방법은 무엇입니까?
Apr 08, 2025 pm 09:18 PM
MariaDB 용 Navicat은 암호가 암호화 된 양식으로 저장되므로 데이터베이스 비밀번호를 직접 볼 수 없습니다. 데이터베이스 보안을 보장하려면 비밀번호를 재설정하는 세 가지 방법이 있습니다. Navicat을 통해 비밀번호를 재설정하고 복잡한 비밀번호를 설정하십시오. 구성 파일을 봅니다 (권장되지 않음, 위험이 높음). 시스템 명령 줄 도구를 사용하십시오 (권장되지 않으면 명령 줄 도구에 능숙해야 함).
 MySQL 및 SQL : 개발자를위한 필수 기술
Apr 10, 2025 am 09:30 AM
MySQL 및 SQL : 개발자를위한 필수 기술
Apr 10, 2025 am 09:30 AM
MySQL 및 SQL은 개발자에게 필수적인 기술입니다. 1.MySQL은 오픈 소스 관계형 데이터베이스 관리 시스템이며 SQL은 데이터베이스를 관리하고 작동하는 데 사용되는 표준 언어입니다. 2.MYSQL은 효율적인 데이터 저장 및 검색 기능을 통해 여러 스토리지 엔진을 지원하며 SQL은 간단한 문을 통해 복잡한 데이터 작업을 완료합니다. 3. 사용의 예에는 기본 쿼리 및 조건 별 필터링 및 정렬과 같은 고급 쿼리가 포함됩니다. 4. 일반적인 오류에는 구문 오류 및 성능 문제가 포함되며 SQL 문을 확인하고 설명 명령을 사용하여 최적화 할 수 있습니다. 5. 성능 최적화 기술에는 인덱스 사용, 전체 테이블 스캔 피하기, 조인 작업 최적화 및 코드 가독성 향상이 포함됩니다.
 Navicat에서 MySQL에 새로운 연결을 만드는 방법
Apr 09, 2025 am 07:21 AM
Navicat에서 MySQL에 새로운 연결을 만드는 방법
Apr 09, 2025 am 07:21 AM
응용 프로그램을 열고 새로운 연결 (Ctrl n)을 선택하여 Navicat에서 새로운 MySQL 연결을 만들 수 있습니다. "MySQL"을 연결 유형으로 선택하십시오. 호스트 이름/IP 주소, 포트, 사용자 이름 및 비밀번호를 입력하십시오. (선택 사항) 고급 옵션을 구성합니다. 연결을 저장하고 연결 이름을 입력하십시오.
 Navicat에서 SQL을 실행하는 방법
Apr 08, 2025 pm 11:42 PM
Navicat에서 SQL을 실행하는 방법
Apr 08, 2025 pm 11:42 PM
Navicat에서 SQL을 수행하는 단계 : 데이터베이스에 연결하십시오. SQL 편집기 창을 만듭니다. SQL 쿼리 또는 스크립트를 작성하십시오. 실행 버튼을 클릭하여 쿼리 또는 스크립트를 실행하십시오. 결과를 봅니다 (쿼리가 실행 된 경우).
