이 기사는 mysql에 대한 관련 지식을 제공합니다. 주로 일반적인 문제를 포함하여 몇 가지 일반적인 문제를 요약하고 해결하며, 인덱스 클래스, 원칙 클래스 및 프레임워크 클래스에 대한 관련 내용도 제공됩니다. 모두가 도움이 됩니다.

추천 학습: mysql 동영상 튜토리얼
정규편
1. 데이터베이스의 세 가지 주요 패러다임에 대해 이야기해 보세요.
첫 번째 정규형: 필드 원자성, 두 번째 정규형: 행은 고유하고 기본 키 열을 가집니다. 세 번째 정규형: 각 열은 기본 키 열과 관련됩니다.
실제 응용에서는 관련 테이블 수를 줄이고 쿼리 효율성을 높이기 위해 소수의 중복 필드를 사용합니다.
2. 하나의 데이터만 쿼리되는데 실행이 매우 느린 이유는 무엇입니까?
- MySQL 데이터베이스 자체가 차단되었습니다. 예를 들어 시스템 또는 네트워크 리소스가 부족합니다.
- SQL 문이 차단되었습니다. 예: 테이블 잠금, 행 잠금 등으로 인해 스토리지 엔진이 해당 SQL 문을 실행하지 못하게 됩니다
- 인덱스 사용이 잘못된 것입니다. 테이블의 데이터 특성상 인덱싱을 사용하지만 테이블 반환 횟수가 많습니다. 3. count(*), count 구현 방식의 차이가 있습니다. (0), 그리고 count(id) ?
-
count(*),
count(constant),
count(primary key) 형식의 카운트 함수에 대해 최적화 프로그램은 쿼리 실행 효율을 높이기 위해 스캔 비용이 가장 적은 인덱스를 선택할 수 있습니다.
count(비인덱스 열)의 경우 최적화 프로그램은 전체 테이블 스캔을 선택합니다. 이는 클러스터형 인덱스의 리프 노드만 순차적으로 스캔할 수 있음을 의미합니다.
count(보조 인덱스 열)는 쿼리 실행을 위해 지정한 열이 포함된 인덱스만 선택할 수 있기 때문에 옵티마이저가 선택한 인덱스 실행 비용이 가장 적게 들지 않을 수 있습니다.
-
count(*)、count(常数)、count(主键)形式的count函数来说,优化器可以选择扫描成本最小的索引执行查询,从而提升效率,它们的执行过程是一样的。
- 而对于
count(非索引列)来说,优化器选择全表扫描,说明只能在聚集索引的叶子结点顺序扫描。
count(二级索引列)
4. 실수로 데이터를 삭제한 경우 어떻게 해야 하나요?
1) 데이터 양이 상대적으로 많은 경우 물리적 백업 xtrabackup을 사용하세요. 데이터베이스 전체 백업을 정기적으로 수행하며, 증분 백업도 수행할 수 있습니다.
2) 데이터 양이 적은 경우 mysqldump 또는 mysqldumper를 사용한 후 binlog를 사용하여 복구하거나 마스터-슬레이브 방식을 설정하여 데이터를 복구할 수 있습니다.
- DML 오작동 설명: 플래시백을 사용하여 먼저 binlog 이벤트를 구문 분석한 다음 되돌릴 수 있습니다.
- DDL 문 오작동: 전체 백업 + binlog 적용을 통해서만 데이터 복원이 가능합니다. 데이터 양이 상대적으로 많으면 복구 시간이 특히 길어집니다.
- rm 삭제: 백업을 사용하여 컴퓨터실 전체에 저장하거나 도시 전체에 저장하는 것이 좋습니다.
5. 삭제, 자르기, 삭제의 차이점
- DELETE 문에 의한 삭제 과정은 테이블에서 한 행씩 삭제하는 동시에 해당 행의 삭제 작업은 다음과 같습니다. 추가 처리를 위해 트랜잭션 기록으로 로그에 저장됩니다.
- TRUNCATE TABLE은 테이블의 모든 데이터를 한꺼번에 삭제하며, 개별 삭제 작업 기록을 로그에 기록하지 않습니다. 삭제된 행은 복구할 수 없습니다. 그리고 삭제 중에는 테이블과 관련된 삭제 트리거가 활성화되지 않으며 실행 속도가 빠릅니다.
- drop 문은 테이블이 차지하는 모든 공간을 해제합니다.
6. MySQL 대형 테이블 쿼리가 메모리를 버스트하지 않는 이유는 무엇입니까?
- MySQL은 "읽으면서 보내기"입니다. 이는 클라이언트가 느리게 수신하면 MySQL 서버가 결과를 보낼 수 없게 되어 트랜잭션 실행 시간이 길어진다는 의미입니다.
- 서버는 전체 결과 세트를 저장할 필요가 없습니다. 데이터를 가져오고 보내는 과정은 모두 next_buffer를 통해 수행됩니다.
- 메모리 데이터 페이지는 버퍼 풀(BP)에서 관리됩니다.
- InnoDB는 연결된 목록을 사용하여 구현된 향상된 LRU 알고리즘을 사용하여 버퍼 풀을 관리합니다. InnoDB 구현에서는 전체 LRU 링크 리스트를 5:3 비율로 Young 영역과 Old 영역으로 나누어 Cold 데이터를 대량으로 로드할 때 Hot 데이터가 씻겨 나가지 않도록 합니다.
7. 딥 페이징(매우 큰 페이징)을 처리하는 방법은 무엇입니까?
- ID 최적화 사용: 먼저 마지막 페이징의 최대 ID를 찾은 다음 선택과 유사하게 ID에 대한 인덱스를 사용하여 쿼리합니다. * id>1000000이 100인 사용자로부터.
- 커버링 인덱스로 최적화: MySQL 쿼리가 인덱스에 완전히 도달하면 쿼리가 인덱스에서만 검색하면 테이블로 돌아가지 않고 직접 반환할 수 있기 때문에 이를 커버링 인덱스라고 합니다. 이는 매우 빠릅니다. 따라서 먼저 인덱스의 ID를 알아낸 다음 해당 ID를 기반으로 데이터를 가져올 수 있습니다.
- 업무상 허용되는 경우 페이지 수를 제한하세요
8. 일상적인 개발에서 SQL을 어떻게 최적화하시나요?
- 적절한 인덱스 추가: 쿼리 조건으로 사용되는 필드에 인덱스를 생성하고 정렬 기준을 정하고, 여러 쿼리 필드를 고려하여 결합된 인덱스를 만들고, 결합된 인덱스 필드의 순서에 주의하고, 가장 일반적으로 사용되는 열을 배치합니다. 끝에서 제한 조건으로 왼쪽에서 내림차순으로 인덱스가 너무 많지 않아야 하며 일반적으로 5 이내입니다.
- 테이블 구조 최적화: 숫자 필드는 문자열 유형보다 낫고, 작은 데이터 유형은 일반적으로 더 좋습니다. NOT NULL을 사용해 보세요
- 쿼리 문 최적화: SQL 실행 계획 분석, 인덱스에 도달하는지 여부 등. 복잡하고, SQL 구조를 최적화하고, 테이블의 데이터 양이 너무 많으면 테이블 분할을 고려해보세요
9. MySQL에서 동시 연결과 동시 쿼리의 차이점은 무엇입니까?
- show processlist를 실행한 결과 수천 개의 연결이 보였습니다. 이는 동시 연결을 의미합니다.
- "현재 실행 중" 문은 동시 쿼리입니다.
- 동시 연결 수가 많으면 메모리에 영향을 미칩니다.
- 동시 쿼리가 너무 높으면 CPU에 좋지 않습니다. 머신에는 제한된 수의 CPU 코어가 있으며 모든 스레드가 돌진하면 컨텍스트 전환 비용이 너무 높아집니다.
- 스레드가 잠금 대기에 들어간 후에는 동시 스레드 수가 1개 감소하므로 행 잠금이나 간격 잠금을 기다리는 스레드는 계산 범위에 포함되지 않습니다. 즉, 잠금을 기다리는 스레드는 CPU를 소비하지 않으므로 전체 시스템이 잠기는 것을 방지할 수 있습니다.
10. MySQL은 어떻게 필드 값을 원래 값으로 업데이트하나요?
- 동일한 데이터에 대해서는 업데이트가 진행되지 않습니다.
- 그러나 binlog 형식마다 로그 처리 방법이 다릅니다.
- 1) 행 모드를 기반으로 하는 경우 서버 계층은 업데이트할 레코드를 일치시키고 새 값이 이전 값과 일치하는지 확인하고 업데이트하지 않고 직접 반환합니다. . , binlog도 기록하지 않습니다.
- 2) 명령문 기반 또는 혼합 형식을 기반으로 하는 경우 MySQL은 업데이트 명령문을 실행하고 업데이트 명령문을 binlog에 기록합니다.
11. 날짜시간과 타임스탬프의 차이점은 무엇인가요?
- datetime의 날짜 범위는 1001-9999입니다. 타임스탬프의 시간 범위는 1970-2038입니다.
- datetime 저장 시간은 시간대와 관련이 없으며 표시되는 값도 마찬가지입니다. 시간대에 따라 다름
- datetime의 저장 공간은 8바이트이고, timestamp의 저장 공간은 4바이트입니다.
- datetime의 기본값은 null입니다. 기본적으로 timestamp 필드는 비어 있지 않습니다. 기본값은 현재 시간(current_timestamp)입니다
12. 트랜잭션의 격리 수준은 무엇입니까?
- "Read Uncommitted"는 가장 낮은 수준이며 어떤 상황에서도 보장할 수 없습니다.
- "Read Committed"는 더티 읽기 발생을 방지할 수 있습니다.
- "반복 읽기"는 더티 읽기 및 반복 불가능 읽기의 발생을 방지할 수 있습니다.
- "직렬화 가능"은 더티 읽기, 반복 불가능 읽기 및 팬텀 읽기의 발생을 방지할 수 있습니다.
- Mysql의 기본 트랜잭션 격리 수준은 "반복 읽기"입니다.
13 MySQL에는 두 가지 종료 명령이 있습니다
- kill 쿼리 + 이 스레드에서 실행 중인 문을 종료한다는 의미의 스레드 ID
- kill 연결 + 기본 연결이 될 수 있는 스레드 ID, 즉 연결 끊김을 의미 이 스레드의 연결
색인 장
1 .지수 카테고리란 무엇입니까?
- 리프 노드의 내용에 따라 인덱스 유형은 기본 키 인덱스와 비기본 키 인덱스로 구분됩니다.
- 기본 키 인덱스의 리프 노드는 전체 데이터 행을 저장합니다. InnoDB에서는 기본 키 인덱스를 클러스터형 인덱스라고도 합니다.
- 기본 키가 아닌 인덱스의 리프 노드 내용은 기본 키 값입니다. InnoDB에서는 기본 키가 아닌 인덱스를 보조 인덱스라고도 합니다.
2. 클러스터형 인덱스와 비클러스터형 인덱스의 차이점은 무엇인가요?
-
클러스터형 인덱스: 클러스터형 인덱스는 기본 키로 생성된 인덱스입니다. 클러스터형 인덱스는 테이블의 리프 노드에 데이터를 저장합니다.
-
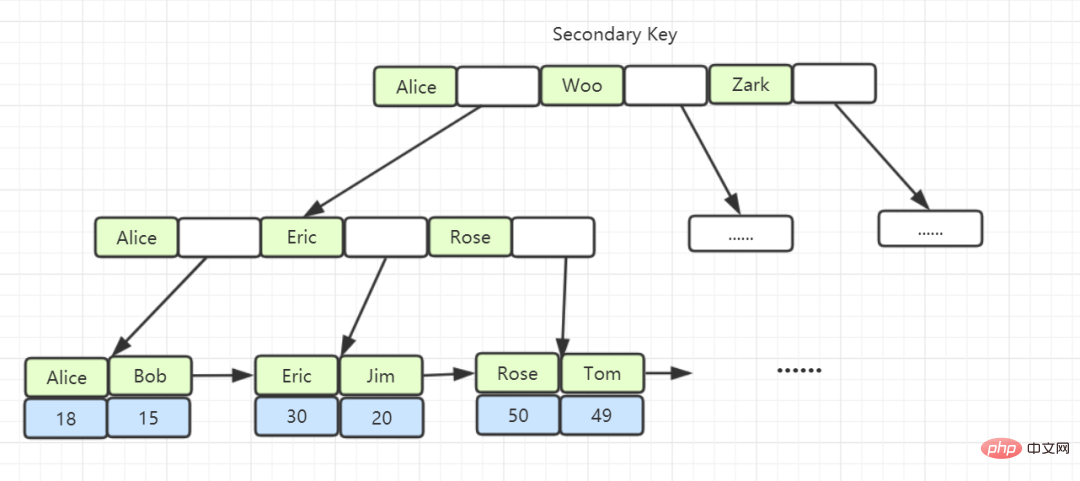
비클러스터형 인덱스: 비기본 키로 생성된 인덱스는 리프 노드에 기본 키와 인덱스 열을 저장하여 데이터를 쿼리할 때 기본 키를 가져올 수 있습니다. 리프에 키를 누른 다음 찾고 싶은 데이터를 찾으세요. (기본 키를 가져온 다음 검색하는 과정을 테이블 반환이라고 합니다.)
커버링 인덱스: 쿼리되는 열이 인덱스에 해당하는 열이고 조회하기 위해 테이블로 돌아갈 필요가 없다고 가정하면 이 인덱스 열을 커버링 인덱스라고 합니다. .
3. InnoDB는 왜 B-Tree, Hash, Binary Tree, Red-Black Tree 대신 B+ Tree를 설계합니까?
4. 클러스터형 인덱스와 비클러스터형 인덱스에 대해 이야기해볼까요?
- InnoDB에서 인덱스 B+ 트리의 리프 노드는 데이터 저장소와 인덱스를 함께 묶는 기본 키 인덱스(클러스터형 인덱스라고도 함)를 사용하여 데이터의 전체 행을 저장합니다. 데이터를 찾아보세요.
- 인덱스 B+Tree의 리프 노드에는 비클러스터형 인덱스 또는 보조 인덱스라고도 불리는 비기본 키 인덱스인 기본 키 값이 저장됩니다.
-
첫번째 인덱스는 보통 순차 IO이고, 테이블로 돌아가는 동작은 랜덤 IO입니다. 테이블로 돌아가야 하는 횟수, 즉 Random IO가 필요한 횟수가 많을수록 전체 테이블 스캔을 더 많이 사용하는 경향이 있습니다.
5. 비클러스터형 인덱스는 확실히 테이블 쿼리를 반환하나요?
- 반드시 그런 것은 아닙니다. 쿼리 문에 필요한 모든 필드가 인덱스에 도달하는지 여부가 관련됩니다. 모든 필드가 인덱스에 도달하면 테이블에 다시 쿼리를 수행할 필요가 없습니다. 인덱스는 쿼리해야 하는 모든 필드의 값을 포함(포함)하며, "커버링 인덱스"라고 합니다.
6. MySQL의 가장 왼쪽 접두사 원리에 대해 알려주세요.
- 가장 왼쪽 접두사 원칙은 다중 열 인덱스를 생성할 때 비즈니스 요구에 따라 where 절에서 가장 자주 사용되는 열을 가장 왼쪽에 배치합니다.
- MySQL은 범위 쿼리(>, <, between, like)를 만날 때까지 오른쪽으로 일치를 유지한 다음 a = 1 및 b = 2 및 c > 3 및 d = 4와 같은 일치를 중지합니다. (a, b, c, d 순서의 인덱스)인 경우 d는 인덱스에 사용되지 않습니다. (a, b, d, c)의 인덱스를 생성하면 a, b, d는 임의로 조정될 수 있습니다.
- = 그리고 in은 a = 1, b = 2, c = 3과 같이 순서가 틀릴 수 있습니다. (a, b, c) 인덱스는 어떤 순서로든 설정할 수 있으며 MySQL의 쿼리 최적화 프로그램은 이를 최적화하는 데 도움이 됩니다. 인덱스가 인식할 수 있는 형식입니다.
7. 인덱스 푸시다운이란 무엇인가요?
- 가장 왼쪽 접두사 원칙이 충족되면 가장 왼쪽 접두사를 사용하여 인덱스에서 레코드를 찾을 수 있습니다.
- MySQL 5.6 이전에는 ID부터 시작하여 테이블을 하나씩만 반환할 수 있었습니다. 기본 키 인덱스에서 데이터 행을 찾은 다음 필드 값을 비교합니다.
- MySQL 5.6에 도입된 인덱스 푸시다운 최적화(인덱스 조건 푸시다운)는 인덱스 순회 과정에서 인덱스에 포함된 필드를 먼저 판단하고 조건에 맞지 않는 레코드를 직접 필터링하여 테이블 반환 횟수를 줄일 수 있습니다.
8. Innodb는 왜 자동 증가 ID를 기본 키로 사용합니까?
- 테이블이 자동 증가 기본 키를 사용하는 경우 새 레코드가 삽입될 때마다 레코드는 현재 인덱스 노드의 후속 위치에 순차적으로 추가됩니다. 페이지가 가득 차면 새 페이지가 추가됩니다. 자동으로 열리게 됩니다. 자동 증가하지 않는 기본 키(예: 학번, 학번 등)를 사용하는 경우 매번 삽입되는 기본 키의 값은 대략 무작위이므로 각각의 새 레코드는 중간에 삽입되어야 합니다. 기존 인덱스 페이지 이동 및 페이징 작업으로 인해 대량의 조각화가 발생하고 인덱스 구조가 충분히 압축되지 않았습니다. 결과적으로 테이블을 다시 작성하고 채워진 페이지를 최적화하기 위해 OPTIMIZE TABLE(테이블 최적화)을 사용해야 했습니다.
9. 거래 ACID 기능은 어떻게 구현되나요?
- "Atomicity": 트랜잭션 실행 중 오류가 발생하거나 사용자가 롤백을 실행하면 시스템은 언두 로그를 통해 트랜잭션 시작 상태를 반환합니다.
- "지속성": 이를 달성하려면 리두 로그를 사용하세요. 리두 로그가 지속되는 한 시스템이 충돌할 때 리두 로그를 통해 데이터를 복구할 수 있습니다.
- "격리": 잠금 및 MVCC를 사용하여 트랜잭션을 서로 격리합니다.
- "일관성": 동시 상황에서 롤백, 복구 및 격리를 통해 일관성이 달성됩니다.
10. MyISAM과 InnoDB의 B-tree 인덱스 구현 방식의 차이점은 무엇인가요?
11. 인덱스의 카테고리는 무엇인가요?
- 리프 노드의 내용에 따라 인덱스 유형은 기본 키 인덱스와 비기본 키 인덱스로 구분됩니다.
- 기본 키 인덱스의 리프 노드는 전체 데이터 행을 저장합니다. InnoDB에서는 기본 키 인덱스를 클러스터형 인덱스라고도 합니다.
- 기본 키가 아닌 인덱스의 리프 노드 내용은 기본 키 값입니다. InnoDB에서는 기본 키가 아닌 인덱스를 보조 인덱스라고도 합니다.
12. 인덱스 오류가 발생하는 시나리오는 무엇인가요?
배경: B+ 트리가 제공하는 빠른 위치 지정 기능은 동일한 레이어에 있는 형제 노드의 질서에서 비롯됩니다. 따라서 이 질서가 파괴되면 구체적인 상황은 다음과 같습니다.
인덱스에 왼쪽 또는 왼쪽 퍼지 일치를 사용합니다. 즉, %xx 또는 %xx%와 같은 두 가지 방법 모두 인덱스 오류를 발생시킵니다. 그 이유는 쿼리 결과가 "Chen Lin, Zhang Lin, Zhou Lin" 등이 될 수 있어서 어떤 인덱스 값으로 비교를 시작해야 할지 모르기 때문에 전체 테이블 스캔을 통해서만 쿼리할 수 있기 때문입니다.
인덱스에 함수 사용/인덱스에 대한 계산 표현식: 인덱스는 함수에 의해 계산된 값이 아닌 인덱스 필드의 원래 값을 저장하기 때문에 당연히 인덱스를 사용할 방법이 없습니다.
인덱스에 대한 암시적 유형 변환: 새로운 함수를 사용하는 것과 같습니다.
WHERE 절에서 OR의 의미는 두 조건 중 하나만 만족한다는 의미이므로 조건 열이 하나만 있으면 의미가 없습니다. 인덱스 컬럼 예, 조건 컬럼이 인덱스 컬럼이 아닌 한 전체 테이블 스캔이 수행됩니다.
제안
1. 데이터베이스와 테이블로 구분되지 않는 시스템이 있는데, 시스템이 데이터베이스와 테이블로 동적으로 전환될 수 있도록 설계하는 방법은 무엇입니까?
- 확장 중지(권장하지 않음)
- 이중 쓰기 마이그레이션 계획: 확장된 테이블 구조 계획을 설계한 후 단일 데이터베이스와 하위 데이터베이스에 대해 일주일 동안 문제가 없는지 관찰한 후 이중 쓰기를 구현합니다. , 단일 데이터베이스의 읽기 트래픽을 잠시 관찰한 후, 단일 데이터베이스의 쓰기 트래픽을 닫고 하위 데이터베이스 및 하위 테이블로 원활하게 전환합니다.
2. 용량을 동적으로 확장 및 축소할 수 있는 하위 데이터베이스 및 테이블 구성표를 설계하는 방법은 무엇입니까?
Principles
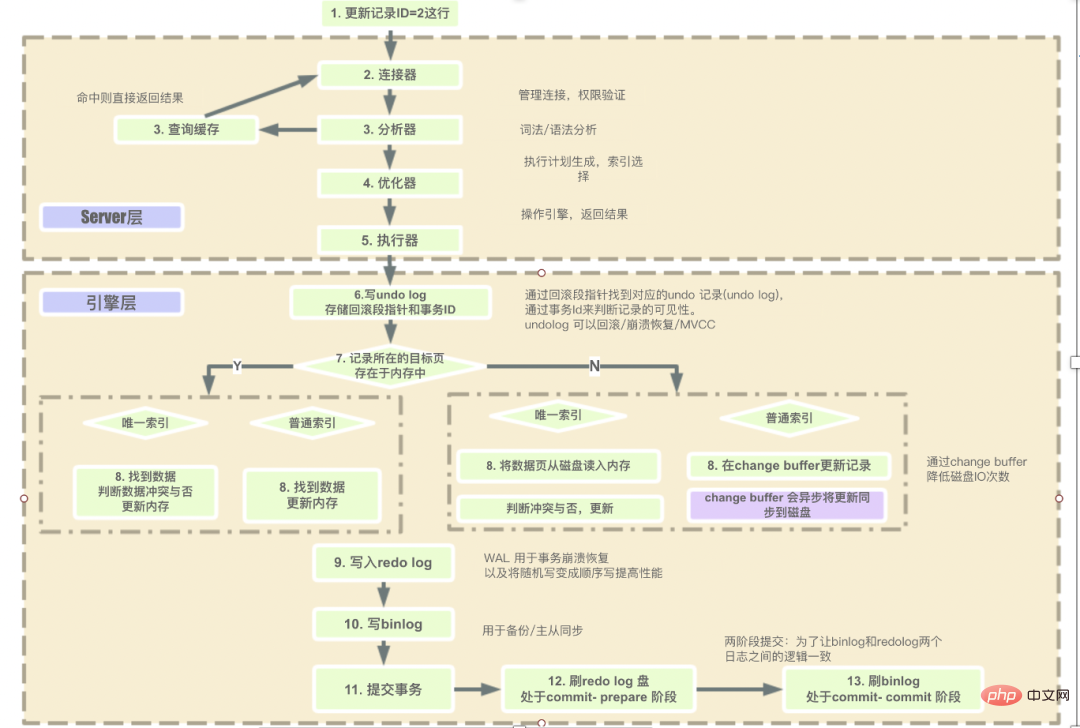
1. MySQL 문을 실행하는 단계는 무엇인가요?
- 서버 계층이 SQL을 순차적으로 실행하는 단계는 다음과 같습니다.
- 클라이언트 요청 -> 커넥터(사용자 신원 확인, 권한 부여) -> 캐시가 있으면 직접 반환하고, 캐시가 없으면 후속 작업을 수행합니다. 존재) - > 분석기(SQL의 어휘 분석 및 구문 분석) -> 최적화 프로그램(주로 SQL 최적화 실행을 위한 최상의 실행 계획 방법 선택) -> 실행기(실행 중에 사용자가 권한을 실행했는지 여부를 먼저 확인합니다. 그래야만 이 엔진에서 제공하는 인터페이스를 사용할 수 있습니다.) -> 엔진 레이어로 이동하여 데이터 반환을 얻습니다(쿼리 캐싱이 활성화된 경우 쿼리 결과가 캐시됩니다).
2. 정렬별 정렬의 내부 원리는 무엇인가요?
- MySQL은 정렬을 위해 각 스레드에 메모리(sort_buffer)를 할당합니다. 메모리 크기는 sort_buffer_size입니다.
- 정렬할 데이터의 양이 sort_buffer_size보다 작으면 메모리에서 정렬이 완료됩니다.
- 정렬된 데이터의 양이 커서 메모리에 저장할 수 없는 경우 디스크의 임시 파일을 사용하여 정렬을 지원합니다(외부 정렬이라고도 함).
- 외부 정렬을 사용하면 MySQL은 정렬된 데이터를 저장하기 위해 여러 개의 개별 임시 파일로 분할된 다음 이러한 파일을 하나의 큰 파일로 병합합니다.
3. MVCC 구현 원리는?
- MVCC(다중 버전 동시성 제어)는 동일한 데이터의 여러 버전을 유지하여 동시성 제어를 달성하는 방법입니다. 쿼리 시 읽기 뷰와 버전 체인을 통해 해당 버전의 데이터를 찾습니다.
- 기능: 동시성 성능을 향상시킵니다. 동시성이 높은 시나리오의 경우 MVCC는 행 수준 잠금보다 비용이 저렴합니다.
- MVCC의 구현은 테이블의 세 가지 숨겨진 필드를 통해 구현되는 버전 체인에 의존합니다.
- 1) DB_TRX_ID: 현재 트랜잭션 ID, 트랜잭션의 시간 순서는 트랜잭션 ID의 크기로 판단됩니다.
- 2) DB_ROLL_PRT: 롤백 포인터는 현재 행 레코드의 이전 버전을 가리킵니다. 이 포인터를 통해 여러 버전의 데이터가 함께 연결되어 실행 취소 로그 버전 체인을 형성합니다.
- 3) DB_ROLL_ID: 기본 키. 데이터 테이블에 기본 키가 없으면 InnoDB가 자동으로 기본 키를 생성합니다.
4. 체인지 버퍼란 무엇이며 그 기능은 무엇인가요?
5. MySQL은 데이터가 손실되지 않도록 어떻게 보장합니까?
- redolog 및 binlog가 영구 디스크를 보장하는 한, binlog 쓰기 메커니즘은 MySQL이 비정상적으로 다시 시작된 후 데이터 복구를 보장할 수 있습니다.
- redolog는 시스템 예외 발생 후 손실된 데이터를 다시 실행할 수 있도록 보장하고, binlog는 손실된 데이터를 복구할 수 있도록 데이터를 보관합니다.
- 트랜잭션 실행 전에 리두로그를 작성하세요. 트랜잭션이 실행되는 동안 로그는 먼저 binlog 캐시에 기록됩니다. 트랜잭션이 제출되면 binlog 캐시가 binlog 파일에 기록됩니다.
6. 테이블을 삭제해도 테이블 파일의 크기가 변하지 않는 이유는 무엇인가요?
- 데이터 항목을 삭제한 후 InnoDB는 페이지 A를 재사용 가능으로 표시합니다.
- 테이블 전체 데이터를 삭제하는 삭제 명령은 어떻습니까? 결과적으로 모든 데이터 페이지는 재사용 가능으로 표시됩니다. 그러나 디스크에서는 파일이 작아지지 않습니다.
- 많은 추가, 삭제, 수정을 거친 테이블에는 구멍이 있을 수 있습니다. 이 구멍도 공간을 차지하기 때문에 이 구멍을 제거하면 테이블 공간을 축소하려는 목적을 달성할 수 있습니다.
- 테이블을 다시 구성하면 이 목적을 달성할 수 있습니다. alter table Aengine=InnoDB 명령을 사용하여 테이블을 다시 빌드할 수 있습니다.
7. 세 가지 binlog 형식 비교
- 행 형식 binlog는 작업 행의 기본 키 ID와 각 필드의 실제 값을 기록하므로 기본 및 백업 작업 데이터에 불일치가 없습니다.
- statement: 기록된 원본 SQL 문
- mixed: 처음 두 개가 혼합되어 있는데 왜 혼합 형식 파일이 필요한가요? 일부 명령문 형식 binlog는 기본 및 백업 간에 불일치를 일으킬 수 있으므로 행 형식을 사용합니다. 하지만 행 형식의 단점은 공간을 많이 차지한다는 것입니다. MySQL은 타협을 취했습니다. MySQL 자체는 이 SQL 문이 기본 서버와 보조 서버 사이에 불일치를 일으킬 수 있는지 여부를 판단합니다. 가능하면 행 형식을 사용하고, 그렇지 않으면 명령문 형식을 사용합니다.
8. MySQL 잠금 규칙
- 원칙 1: 잠금의 기본 단위는 다음 키 잠금이고, 다음 키 잠금은 전면 열기 및 후면 닫기 간격입니다.
- 원칙 2: 검색 프로세스 중에 액세스된 개체만 잠깁니다.
- 최적화 1: 인덱스에 대한 동등한 쿼리의 경우 고유 인덱스를 잠그면 다음 키 잠금이 행 잠금으로 변질됩니다.
- 최적화 2: 인덱스에 대한 동등한 쿼리의 경우 오른쪽으로 순회하고 마지막 값이 동등 조건을 충족하지 않으면 다음 키 잠금이 간격 잠금으로 변질됩니다.
- 버그: 고유에 대한 범위 쿼리 인덱스는 조건을 만족하지 않는 첫 번째 값까지 액세스합니다.
9. 더티 읽기, 반복 불가능 읽기, 팬텀 읽기란 무엇인가요?
- "더티 읽기": 더티 읽기는 다른 트랜잭션에서 커밋되지 않은 데이터를 읽는 것을 의미합니다. 데이터가 존재하지 않습니다. 결국에는 존재하지 않을 수도 있는 데이터를 읽는 것을 더티 읽기(dirty reading)라고 합니다.
- "반복 불가능한 읽기": 반복 불가능한 읽기는 트랜잭션 내에서 처음에 읽은 데이터가 트랜잭션이 끝나기 전 언제든지 읽은 동일한 데이터 배치와 일치하지 않는 상황을 나타냅니다.
- "팬텀 리딩": 팬텀 리딩은 두 번의 읽기로 얻은 결과 세트가 다르다는 것을 의미하지 않습니다. 팬텀 리딩의 초점은 특정 선택 작업으로 얻은 결과의 데이터 상태가 후속 비즈니스 작업을 지원할 수 없다는 것입니다. 보다 구체적으로 말하면, 특정 레코드가 존재하는지 여부를 선택하고, 존재하지 않는 경우 레코드를 삽입할 준비를 합니다. 그러나 삽입 실행 시 해당 레코드가 이미 존재하므로 이때는 팬텀 읽기를 수행할 수 없습니다. 발생합니다.
10. MySQL에는 어떤 종류의 잠금이 있나요? 위와 같은 잠금은 동시성 효율성을 저해하지 않나요?
프레임워크
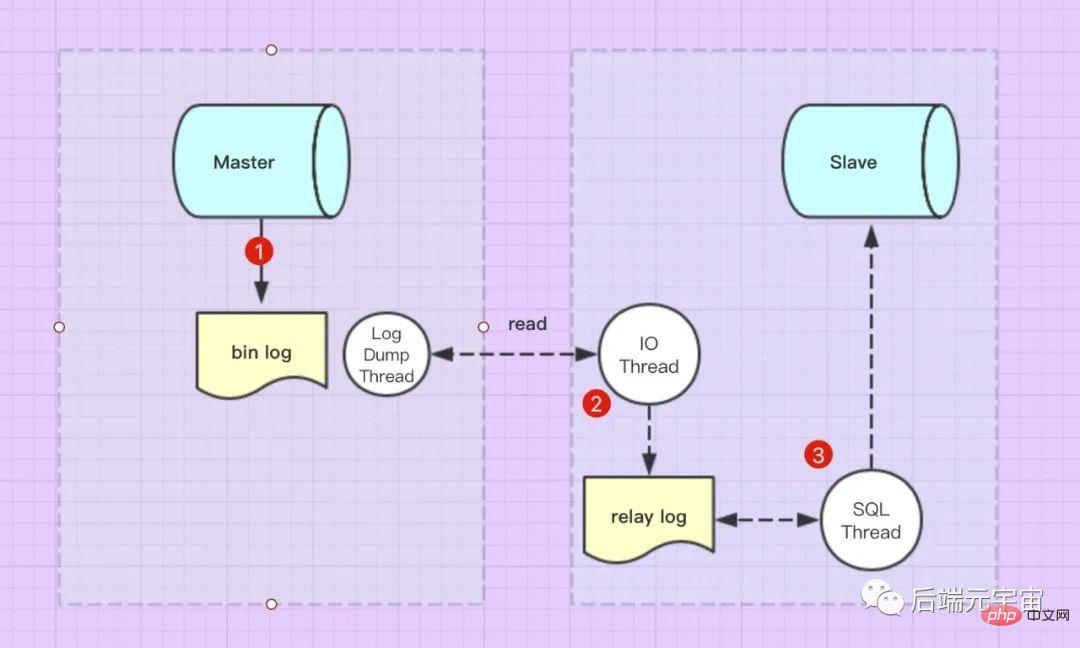
1. MySQL 마스터-슬레이브 복제의 원리는 무엇인가요?
- Master의 업데이트 이벤트(업데이트, 삽입, 삭제)가
bin-log에 순서대로 기록됩니다. 슬레이브가 마스터에 연결되면 마스터 머신은 슬레이브에 대한 binlog dump 스레드를 열고 스레드는 bin-log 로그를 읽습니다. bin-log中。当Slave连接到Master的后,Master机器会为Slave开启binlog dump线程,该线程会去读取bin-log日志。
- Slave连接到Master后,Slave库有一个
I/O线程 通过请求binlog dump thread读取bin-log日志,然后写入从库的relay log日志中。
- Slave还有一个
SQL线程
슬레이브가 마스터에 연결된 후 슬레이브 라이브러리에는 binlog 덤프 스레드를 요청하여 bin-log 로그를 읽은 다음 이를 슬레이브 라이브러리의 I/O 스레드가 있습니다. code>릴레이 로그를 로그에 추가하세요.
Slave에는 업데이트를 위해 릴레이 로그 로그 내용을 실시간으로 모니터링하고, 파일의 SQL 문을 구문 분석하고, 이를 슬레이브 데이터베이스에서 실행하는 SQL 스레드도 있습니다.
2. MySQL의 마스터-슬레이브 복제 동기화 방법은 무엇입니까? - 비동기 복제: Mysql 마스터-슬레이브 동기화는 기본적으로 비동기 복제됩니다. 즉, 위의 세 단계 중 첫 번째 단계만 동기식입니다(즉, Mater가 bin 로그 로그를 작성합니다). 즉, 마스터 라이브러리는 binlog 로그를 작성한 후 binlog를 기다리지 않고 클라이언트에 성공적으로 반환할 수 있습니다. 슬레이브 라이브러리로 전송할 로그입니다.
- 동기 복제: 동기 복제의 경우 마스터 호스트가 슬레이브 호스트에 이벤트를 보낸 후 모든 슬레이브 노드(슬레이브가 여러 개인 경우)가 성공적인 데이터 복제에 대한 정보를 마스터에 반환할 때까지 대기합니다. 반동기 복제:
반동기 복제의 경우 마스터 호스트가 슬레이브 호스트에 이벤트를 보낸 후
슬레이브 노드 중 하나
(슬레이브가 여러 개인 경우)가 정보를 반환할 때까지 대기가 시작됩니다. 마스터로의 성공적인 데이터 복제에 대해
3. Mysql 마스터-슬레이브 동기화 지연의 원인은 무엇입니까? - 마스터 노드가 대규모 트랜잭션을 실행하면 마스터-슬레이브 지연에 더 큰 영향을 미치게 됩니다
- 네트워크 지연, 대용량 로그, 너무 많은 슬레이브
- 마스터의 다중 스레드 쓰기, 슬레이브 노드에는 단일 스레드 동기화만 있습니다
- 머신 성능 문제, 슬레이브 노드가 "잘못된 머신"을 사용하는지 여부🎜🎜잠금 충돌 문제로 인해 슬레이브의 SQL 스레드가 느리게 실행될 수도 있습니다🎜
4. Mysql 마스터-슬레이브 동기화 지연의 원인은 무엇입니까?
- 대규모 트랜잭션: 대규모 트랜잭션을 작은 트랜잭션으로 나누고 데이터를 일괄 업데이트합니다.
- 슬레이브 수를 5개 이하로 줄이고 단일 트랜잭션의 크기를 줄입니다.
- Mysql 5.7 이후에는 멀티 스레드를 사용할 수 있습니다. 복제, MGR 복제 아키텍처를 사용하세요
- 디스크, RAID 카드 또는 스케줄링 전략에 문제가 있는 경우 단일 IO 지연이 매우 높을 수 있습니다. iostat 명령을 사용하여 DB 데이터 디스크의 IO 상황을 확인할 수 있습니다. 그런 다음 추가 판단을 하세요
- 잠금 문제의 경우 Grab processlist를 전달하고 information_schema에서 잠금 및 트랜잭션과 관련된 테이블을 확인할 수 있습니다.
6. bin 로그/redo 로그/undo 로그란 무엇인가요?
- bin 로그는 Mysql 데이터베이스 수준의 파일입니다. Select 및 show 문은 기록되지 않습니다.
- 업데이트되는 데이터는 리두 로그에 기록됩니다. 예를 들어 데이터가 성공적으로 제출되면 즉시 디스크에 동기화되지 않고 먼저 리두 로그에 기록됩니다. 거래 성의 지속성을 달성하기 위해 디스크를 플러시하기 전에 적절한 시간을 기다리십시오.
- 실행 취소 로그는 데이터 회수 작업에 사용되며 기록이 수정되기 전의 내용을 유지합니다. Undo 로그를 통해 트랜잭션 롤백이 가능하며, Undo 로그를 기반으로 특정 버전의 데이터를 추적하여 MVCC를 구현할 수 있습니다.
추천 학습: mysql 비디오 튜토리얼
위 내용은 MySQL 기반 강화를 위한 이슈 요약의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!



 4. 실수로 데이터를 삭제한 경우 어떻게 해야 하나요?
4. 실수로 데이터를 삭제한 경우 어떻게 해야 하나요? 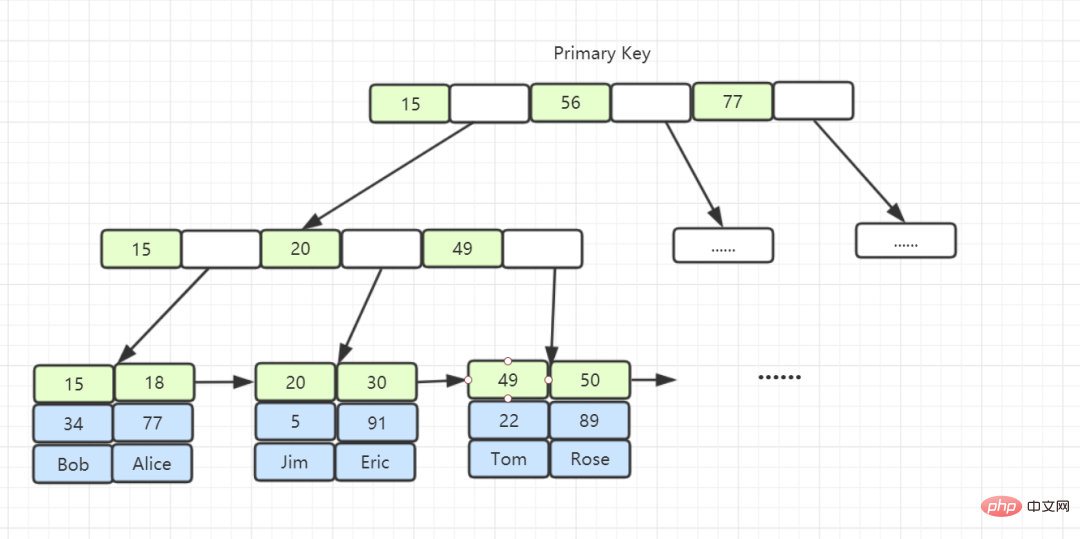
















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



