

멀티스레드 크롤러 및 일반 검색 알고리즘에 대한 Python 상세 분석

이 글은 멀티스레드 크롤러 개발 및 일반적인 검색 알고리즘과 관련된 문제를 주로 소개하는 python에 대한 관련 지식을 제공합니다. 모두에게 도움이 되기를 바랍니다.

추천 학습: python 동영상 튜토리얼
멀티 스레드 크롤러
멀티 스레딩의 장점
요청과 정규 표현식을 마스터한 후에는 실제로 간단한 URL 크롤링을 시작할 수 있습니다.
하지만 이때의 크롤러는 프로세스와 스레드가 하나만 있으므로 단일 스레드 크롤러 라고 합니다. 단일 스레드 크롤러는 한 번에 한 페이지만 방문하며 컴퓨터의 네트워크 대역폭을 완전히 활용할 수 없습니다. 페이지는 최대 수백 KB에 불과하므로 크롤러가 페이지를 크롤링할 때 추가 네트워크 속도와 요청 시작부터 소스 코드 가져오기까지의 시간이 낭비됩니다. 크롤러가 동시에 10페이지에 접근할 수 있다면 크롤링 속도를 10배 높이는 것과 같습니다. 이러한 목적을 달성하기 위해서는 멀티스레딩 기술을 활용하는 것이 필요하다.
Python 언어에는 GIL(Global Interpreter Lock)이 있습니다. 이로 인해 Python의 멀티스레딩은 의사 멀티스레딩이 됩니다. 즉, 본질적으로 스레드이지만 이 스레드는 몇 밀리초 동안만 각 작업을 수행하며 몇 밀리초 후에 장면을 저장하고 다른 작업으로 변경합니다. 몇 밀리초 후에 다른 작업을 다시 수행합니다. 한 라운드가 지나면 처음으로 돌아가서 장면을 다시 시작하고 몇 밀리초 동안 작업한 다음 계속 변경합니다. 마이크로 규모의 단일 스레드는 여러 작업을 수행하는 것과 같습니다. 동시에 거시적인 규모로. 이 메커니즘은 I/O(입력/출력, 입력/출력) 집약적인 작업에는 거의 영향을 미치지 않지만 CPU 계산 집약적인 작업에서는 CPU 코어 하나만 사용할 수 있으므로 성능에 큰 영향을 미칩니다. 영향. 따라서 계산 집약적인 프로그램에 참여하는 경우 여러 프로세스를 사용해야 합니다. Python의 다중 프로세스는 GIL의 영향을 받지 않습니다. 크롤러는 I/O 집약적인 프로그램이므로 멀티스레딩을 사용하면 크롤링 효율성을 크게 향상시킬 수 있습니다.
멀티프로세스 라이브러리: 멀티프로세싱
멀티프로세싱 자체는 멀티프로세스와 관련된 작업을 처리하는 데 사용되는 Python의 멀티프로세스 라이브러리입니다. 그러나 프로세스 간에 메모리와 스택 리소스를 직접 공유할 수 없고, 새로운 프로세스를 시작하는 데 드는 비용이 스레드보다 훨씬 크기 때문에 멀티 스레드를 사용하여 크롤링하는 것은 여러 프로세스를 사용하는 것보다 더 많은 장점이 있습니다.
멀티프로세싱 아래에는 Python 스레드가 다양한 멀티프로세싱 방법을 사용할 수 있도록 하는 더미 모듈이 있습니다.
스레드 풀을 구현하는 데 사용되는 dummy 아래에 Pool 클래스가 있습니다.
이 스레드 풀에는 스레드 풀의 모든 스레드가 "동시에" 기능을 실행할 수 있도록 하는 map() 메서드가 있습니다.
예:
for 루프를 학습한 후
for i in range(10): print(i*i)
물론 이 작성 방법으로 결과를 얻을 수 있지만 코드가 하나씩 계산되므로 그다지 효율적이지 않습니다. 코드가 동시에 여러 숫자의 제곱을 계산할 수 있도록 멀티스레딩 기술을 사용하는 경우 이를 달성하려면 multiprocessing.dummy를 사용해야 합니다.
멀티스레딩 사용 예:
from multiprocessing.dummy import Pooldef cal_pow(num):
return num*num
pool=Pool(3)num=[x for x in range(10)]result=pool.map(cal_pow,num)print('{}'.format(result))위 코드에서 , 먼저 제곱을 계산하는 데 사용되는 함수를 정의한 다음 3개의 스레드로 스레드 풀을 초기화했습니다. 이 세 스레드는 10개 숫자의 제곱을 계산하는 역할을 합니다. 먼저 숫자 계산을 마친 사람이 다음 숫자를 가져와서 모든 숫자가 계산될 때까지 계산을 계속합니다.
이 예에서 스레드 풀의 map() 메서드는 두 개의 매개변수를 받습니다. 첫 번째 매개변수는 함수 이름이고 두 번째 매개변수는 목록입니다. 참고: 첫 번째 매개변수는 함수 이름일 뿐이며 괄호를 사용할 수 없습니다. 두 번째 매개변수는 반복 가능한 객체입니다. 이 반복 가능한 객체의 각 요소는 clac_power2() 함수에 의해 매개 변수로 수신됩니다. 리스트 외에도 튜플, 세트 또는 사전을 map()의 두 번째 매개변수로 사용할 수 있습니다.
멀티 스레드 크롤러 개발
크롤러는 I/O 집약적인 작업이므로, 특히 웹 페이지 소스 코드를 요청할 때 단일 스레드를 사용하여 개발하면 웹 페이지가 반환될 때까지 기다리는 데 많은 시간을 낭비하게 됩니다. , 그래서 멀티스레딩 크롤러에 기술을 적용하면 크롤러의 운영 효율성을 크게 향상시킬 수 있습니다. 예를 들어보세요. 세탁기로 빨래하는 데 50분, 주전자에 물을 끓이는 데 15분, 단어를 외우는데 1시간이 걸린다. 세탁기가 빨래를 먼저 하고, 빨래를 한 후 물을 끓이고, 물이 끓은 후 단어를 외우면 총 125분이 소요됩니다.
하지만 다르게 말하면 전체적으로 세 가지가 동시에 실행될 수 있습니다. 갑자기 두 사람이 다른 사람에게 옷을 넣고 기다리는 일을 맡게 되었다고 가정해 보세요. 세탁기를 끝내고, 상대방이 물을 끓이고 끓기를 기다리는 것은 당신의 책임이고, 단어만 외우면 됩니다. 물이 끓으면 물을 끓이는 역할을 맡은 클론이 먼저 사라진다. 세탁기가 옷 세탁을 마치면 옷 세탁을 담당하는 클론은 사라진다. 마지막으로 단어를 직접 외워보세요. 동시에 3가지 일을 완료하는 데 60분밖에 걸리지 않습니다.
물론 위의 예가 실제 생활 상황이 아니라는 점을 분명히 알게 되실 것입니다. 실제로는 누구도 분리되지 않습니다. 실생활에서 일어나는 일은 사람들이 단어를 외울 때 단어를 외우는 데 집중한다는 것입니다. 물을 끓인 후에는 옷을 세탁할 때 주전자에서 소리가 나고 세탁기에서는 '디디' 소리가 납니다. . 그러니 알림이 오면 해당 조치를 취하기만 하면 됩니다. 매 순간 확인할 필요가 없습니다. 위의 두 가지 차이점은 실제로 멀티스레딩과 이벤트 기반 비동기 모델 간의 차이점입니다. 이 섹션에서는 다중 스레드 작업에 대해 설명하고 나중에 비동기 작업을 사용하는 크롤러 프레임워크에 대해 설명하겠습니다. 이제 연산해야 할 액션의 개수가 많지 않을 때는 두 방법의 성능에는 차이가 없지만, 액션의 개수가 크게 늘어나면 멀티스레딩의 효율성이 향상된다는 점만 기억하시면 됩니다. 줄어들고 단일 스레딩보다 더 나빠집니다. 그리고 그때까지는 비동기 작업만이 문제에 대한 해결책이 됩니다.
다음 두 코드는 bd 홈페이지 크롤링에 대한 단일 스레드 크롤러와 멀티 스레드 크롤러의 성능 차이를 비교하는 데 사용됩니다. 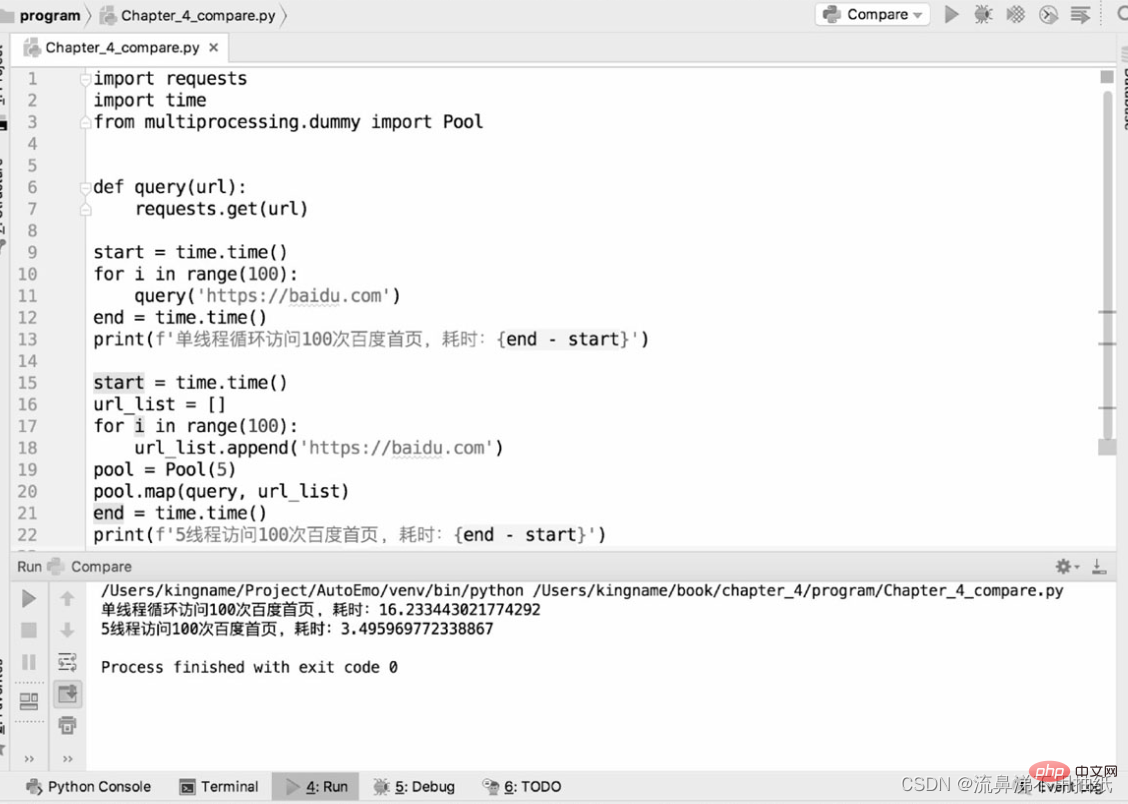
실행 결과에서 하나의 스레드가 약 16.2초가 걸리는 것을 볼 수 있으며, 5개의 스레드는 약 3.5초가 소요됩니다. 시간은 단일 스레드의 약 1/5입니다. 또한 시간 관점에서 "동시에 실행되는" 5개 스레드의 효과를 확인할 수도 있습니다. 그러나 스레드 풀이 클수록 좋다는 의미는 아닙니다. 또한 위 결과를 보면 5개 스레드의 실행 시간이 실제로는 1개 스레드 실행 시간의 1/5보다 조금 더 길다는 것을 알 수 있습니다. 추가 지점은 실제로 스레드 전환 시간입니다. 이는 또한 Python의 멀티스레딩이 여전히 마이크로 수준에서 직렬이라는 측면을 반영합니다. 따라서 스레드 풀을 너무 크게 설정하면 스레드 전환으로 인한 오버헤드가 멀티스레딩으로 인한 성능 향상을 상쇄할 수 있습니다. 스레드 풀의 크기는 실제 상황에 따라 결정해야 하며 정확한 데이터는 없습니다. 독자는 가장 적합한 데이터를 찾기 위해 특정 응용 프로그램 시나리오에서 테스트 및 비교를 위해 다양한 크기를 설정할 수 있습니다.
크롤러의 공통 검색 알고리즘
깊이 우선 검색
온라인 교육 사이트의 강좌 분류에서는 위 강좌 정보를 크롤링해야 합니다. 홈페이지부터 시작하여 언어에 따라 Python, Node.js, Golang 등 여러 주요 카테고리로 강좌가 나누어져 있습니다. Python 아래에는 크롤러, Django, 머신러닝 등 각 주요 카테고리별로 다양한 강좌가 있습니다. 각 코스는 여러 수업 시간으로 나누어져 있습니다.
깊이 우선 검색의 경우 크롤링 경로는 그림과 같습니다(일련 번호가 작은 것부터 큰 것까지) 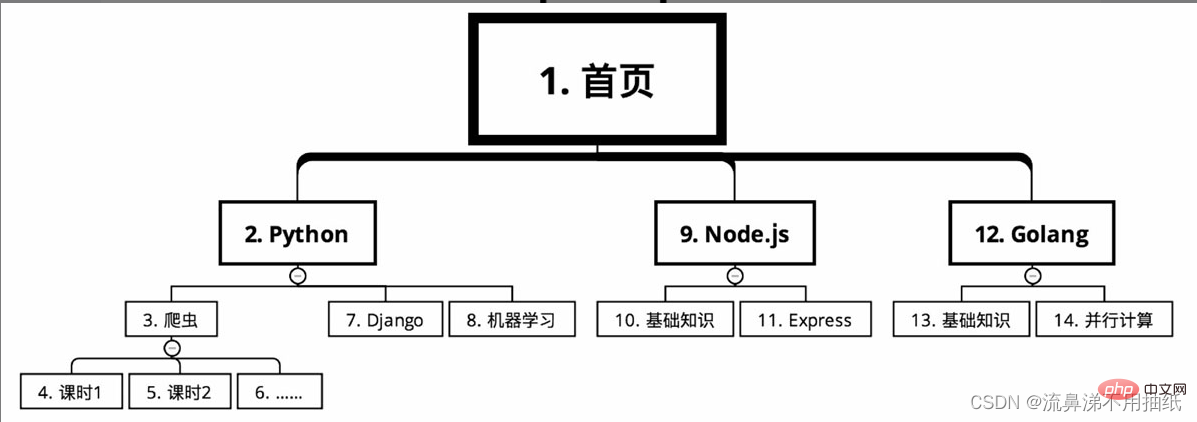
너비 우선 검색
순서는 다음과 같습니다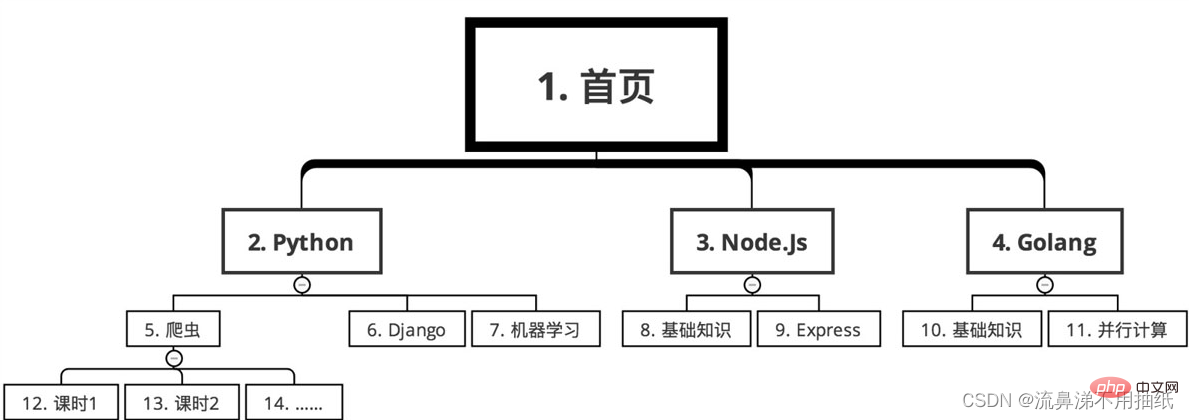
알고리즘 선택
예를 들어 전국 웹사이트를 크롤링하려는 경우 각 레스토랑의 모든 레스토랑 정보와 주문 정보를 제공합니다. 깊이 우선 알고리즘을 사용한다고 가정하면 먼저 특정 링크에서 A 레스토랑으로 크롤링한 후 즉시 A 레스토랑의 주문 정보를 크롤링합니다. 전국에 수십만 개의 레스토랑이 있기 때문에 모두 오르려면 12시간이 걸릴 수도 있습니다. 이로 인해 발생하는 문제는 A 레스토랑의 주문량이 오전 8시에 도달하는 반면, B 레스토랑의 주문량이 저녁 8시에 도달할 수 있다는 것입니다. 주문량은 12시간마다 다릅니다. 인기 레스토랑의 경우 12시간이면 수백만 달러의 수익 격차가 발생할 수 있습니다. 이처럼 데이터 분석을 하게 되면 12시간의 시차로 인해 A 레스토랑과 B 레스토랑의 매출 실적을 비교하기가 어려워지게 됩니다. 주문량에 비해 레스토랑의 볼륨 변화는 훨씬 작습니다. 따라서 너비 우선 검색을 사용한다면 먼저 심야 0시부터 다음날 낮 12시까지 모든 레스토랑을 크롤링하고, 이후 14시부터 20시까지 각 레스토랑의 주문량을 크롤링하는데 집중한다. 다음날:00. 이로써 주문 크롤링 작업을 완료하는 데 6시간밖에 걸리지 않아 시차로 인한 주문량 차이를 줄일 수 있었습니다. 동시에 상점이 며칠에 한 번씩 크롤링하는 것은 거의 영향을 미치지 않기 때문에 요청 수도 줄어들어 웹사이트에서 크롤러를 발견하기가 더 어려워졌습니다.
또 다른 예로 실시간 여론을 분석하려면 Baidu Tieba를 크롤링해야 합니다. 인기 있는 포럼에는 가장 초기 게시물이 2010년으로 거슬러 올라간다고 가정할 때 수만 페이지의 게시물이 있을 수 있습니다. 너비 우선 검색을 사용하는 경우 먼저 이 티에바에 있는 모든 게시물의 제목과 URL을 얻은 다음, 이 URL을 기반으로 각 게시물을 입력하여 각 층의 정보를 얻습니다. 하지만 실시간 여론이기 때문에 7년 전 게시물은 현재 분석에 큰 의미가 없기 때문에 새로운 게시물이 먼저 포착되어야 한다. 과거 콘텐츠에 비해 실시간 콘텐츠가 가장 중요하다. 따라서 Tieba 콘텐츠를 크롤링하려면 깊이 우선 검색을 사용해야 합니다. 게시물이 보이면 빠르게 들어가 각 층의 정보를 크롤링하시면 한 게시물을 크롤링하신 후 다음 게시물로 크롤링하실 수 있습니다. 물론, 이 두 가지 검색 알고리즘은 둘 중 하나가 아니며 실제 상황에 따라 유연하게 선택할 필요가 있으며 동시에 사용할 수도 있습니다.
추천 학습: python 비디오 튜토리얼
위 내용은 멀티스레드 크롤러 및 일반 검색 알고리즘에 대한 Python 상세 분석의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7322
7322
 9
1625
14
1350
46
1262
25
1209
29
9
1625
14
1350
46
1262
25
1209
29

 램프 아키텍처에서 Node.js 또는 Python 서비스를 효율적으로 통합하는 방법은 무엇입니까?
Apr 01, 2025 pm 02:48 PM
램프 아키텍처에서 Node.js 또는 Python 서비스를 효율적으로 통합하는 방법은 무엇입니까?
Apr 01, 2025 pm 02:48 PM
많은 웹 사이트 개발자는 램프 아키텍처에서 Node.js 또는 Python 서비스를 통합하는 문제에 직면 해 있습니다. 기존 램프 (Linux Apache MySQL PHP) 아키텍처 웹 사이트 요구 사항 ...
 Linux 터미널에서 Python 버전을 볼 때 발생하는 권한 문제를 해결하는 방법은 무엇입니까?
Apr 01, 2025 pm 05:09 PM
Linux 터미널에서 Python 버전을 볼 때 발생하는 권한 문제를 해결하는 방법은 무엇입니까?
Apr 01, 2025 pm 05:09 PM
Linux 터미널에서 Python 버전을 보려고 할 때 Linux 터미널에서 Python 버전을 볼 때 권한 문제에 대한 솔루션 ... Python을 입력하십시오 ...
 SCAPY 크롤러를 사용할 때 파이프 라인 영구 스토리지 파일을 작성할 수없는 이유는 무엇입니까?
Apr 01, 2025 pm 04:03 PM
SCAPY 크롤러를 사용할 때 파이프 라인 영구 스토리지 파일을 작성할 수없는 이유는 무엇입니까?
Apr 01, 2025 pm 04:03 PM
SCAPY 크롤러를 사용할 때 파이프 라인 영구 스토리지 파일을 작성할 수없는 이유는 무엇입니까? 토론 Data Crawler에 Scapy Crawler를 사용하는 법을 배울 때 종종 ...
 Python Process Pool이 동시 TCP 요청을 처리하고 클라이언트가 막히게하는 이유는 무엇입니까?
Apr 01, 2025 pm 04:09 PM
Python Process Pool이 동시 TCP 요청을 처리하고 클라이언트가 막히게하는 이유는 무엇입니까?
Apr 01, 2025 pm 04:09 PM
Python Process Pool은 클라이언트가 갇히게하는 동시 TCP 요청을 처리합니다. 네트워크 프로그래밍에 Python을 사용하는 경우 동시 TCP 요청을 효율적으로 처리하는 것이 중요합니다. ...
 Python functools.partial 객체가 내부적으로 캡슐화 한 원래 함수를 보는 방법?
Apr 01, 2025 pm 04:15 PM
Python functools.partial 객체가 내부적으로 캡슐화 한 원래 함수를 보는 방법?
Apr 01, 2025 pm 04:15 PM
functools.partial in Python의 파이썬 funcTools.partial 객체의 시청 방법을 깊이 탐구하십시오 ...
 Python Cross-Platform 데스크탑 응용 프로그램 개발 : 어떤 GUI 라이브러리가 가장 적합합니까?
Apr 01, 2025 pm 05:24 PM
Python Cross-Platform 데스크탑 응용 프로그램 개발 : 어떤 GUI 라이브러리가 가장 적합합니까?
Apr 01, 2025 pm 05:24 PM
Python 크로스 플랫폼 데스크톱 응용 프로그램 개발 라이브러리 선택 많은 Python 개발자가 Windows 및 Linux 시스템 모두에서 실행할 수있는 데스크탑 응용 프로그램을 개발하고자합니다 ...
 파이썬 모래시 그래프 그리기 : 가변적 인 정의되지 않은 오류를 피하는 방법?
Apr 01, 2025 pm 06:27 PM
파이썬 모래시 그래프 그리기 : 가변적 인 정의되지 않은 오류를 피하는 방법?
Apr 01, 2025 pm 06:27 PM
Python : 모래 시계 그래픽 도면 및 입력 검증을 시작 하기이 기사는 모래 시계 그래픽 드로잉 프로그램에서 Python 초보자가 발생하는 변수 정의 문제를 해결합니다. 암호...
 Google과 AWS는 공개 PYPI 이미지 소스를 제공합니까?
Apr 01, 2025 pm 05:15 PM
Google과 AWS는 공개 PYPI 이미지 소스를 제공합니까?
Apr 01, 2025 pm 05:15 PM
많은 개발자들이 PYPI (PythonPackageIndex)에 의존합니다 ...
