

Python 다중 프로세스 지식 포인트 요약

이 기사에서는 다중 프로세스란 무엇인지, 프로세스 생성, 프로세스 간 동기화, 프로세스 풀 등 다중 프로세스에 대한 관련 내용을 주로 소개하는 python에 대한 관련 지식을 제공합니다. 보세요, 모두에게 도움이 되길 바랍니다.

추천 학습: python 비디오 튜토리얼
1. 다중 프로세스란 무엇입니까?
1. Process
Program: 예를 들어 xxx.py는 정적
Process인 프로그램입니다. 프로그램이 실행된 후 사용된 코드와 리소스를 프로세스라고 합니다. 운영 시스템 자원 할당의 기본 단위입니다. 스레드를 통해 멀티태스킹을 완료할 수 있을 뿐만 아니라 프로세스도 사용할 수 있습니다
2. 프로세스 상태
작업 중에는 작업 수가 CPU 코어 수보다 많은 경우가 많습니다. 즉, 일부 작업을 실행해야 합니다. , 다른 작업은 CPU가 실행되기를 기다리고 있으므로 상태가 달라집니다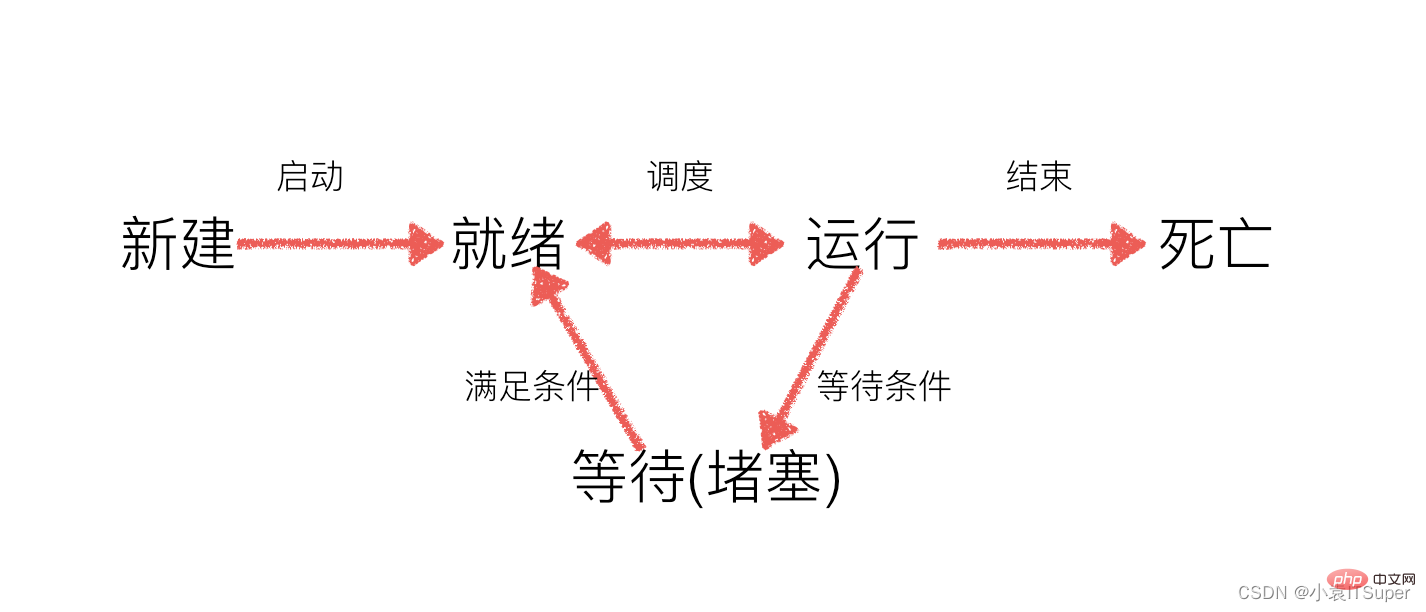
- Ready state: 실행 조건이 느려지고 CPU가 실행되기를 기다리고 있습니다
- Execution state: CPU가 기능을 실행 중입니다
- Waiting state : 프로그램이 Sleeping되는 등 특정 조건이 충족되기를 기다리는 중입니다. 현재는 대기 상태입니다.
2. 프로세스 생성 - 다중 처리
1. 구문 설명
다중 처리모듈 통과Process객체를 생성하고 해당start()메서드를 호출하여 프로세스Process와 <code>threading.Thread API는 동일합니다.multiprocessing模块通过创建一个Process对象然后调用它的start()方法来生成进程,Process与threading.Thread API相同。
语法格式:multiprocessing.Process(group=None, target=None, name=None, args=(), kwargs={}, *, daemon=None)
参数说明:
-
group:指定进程组,大多数情况下用不到 -
target:如果传递了函数的引用,可以任务这个子进程就执行这里的代码 -
name:给进程设定一个名字,可以不设定 -
args:给target指定的函数传递的参数,以元组的方式传递 -
kwargs:给target指定的函数传递命名参数
multiprocessing.Process 对象具有如下方法和属性:
| 方法名/属性 | 说明 |
|---|---|
run() |
进程具体执行的方法 |
start() |
启动子进程实例(创建子进程) |
join([timeout]) |
如果可选参数 timeout 是默认值 None,则将阻塞至调用 join() 方法的进程终止;如果 timeout 是一个正数,则最多会阻塞 timeout 秒 |
name |
当前进程的别名,默认为Process-N,N为从1开始递增的整数 |
pid |
当前进程的pid(进程号) |
is_alive() |
判断进程子进程是否还在活着 |
exitcode |
子进程的退出代码 |
daemon |
进程的守护标志,是一个布尔值。 |
authkey |
进程的身份验证密钥。 |
sentinel |
系统对象的数字句柄,当进程结束时将变为 ready。 |
terminate() |
不管任务是否完成,立即终止子进程 |
kill() |
与 terminate() 相同,但在 Unix 上使用 SIGKILL 信号。 |
close() |
구문 형식 | :
group: 대부분의 경우 사용되지 않는 프로세스 그룹을 지정합니다. 🎜🎜target: 함수 참조가 전달되면 작업은 다음과 같습니다. 이 하위 프로세스는 여기에서 코드를 실행합니다🎜🎜name: 프로세스의 이름을 설정합니다. 설정할 필요가 없습니다.🎜🎜args: 전달된 매개변수 대상이 지정한 함수에 튜플로 전달됨 🎜🎜kwargs: 대상 🎜🎜🎜🎜multiprocessing.Process 객체가 지정한 함수에 명명된 매개변수 전달에는 다음과 같은 메서드와 속성이 있습니다. 🎜🎜 | 메서드 이름/속성 | 설명 | 🎜||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 方法名 | 说明 |
|---|---|
q=Queue() |
初始化Queue()对象,若括号中没有指定最大可接收的消息数量,或数量为负值,那么就代表可接受的消息数量没有上限(直到内存的尽头) |
Queue.qsize() |
返回当前队列包含的消息数量 |
Queue.empty() |
如果队列为空,返回True,反之False |
Queue.full() |
如果队列满了,返回True,反之False |
Queue.get([block[, timeout]]) |
获取队列中的一条消息,然后将其从列队中移除,block默认值为True。1、如果block使用默认值,且没有设置timeout(单位秒),消息列队如果为空,此时程序将被阻塞(停在读取状态),直到从消息列队读到消息为止,如果设置了timeout,则会等待timeout秒,若还没读取到任何消息,则抛出"Queue.Empty"异常。2、如果block值为False,消息列队如果为空,则会立刻抛出"Queue.Empty"异常 |
Queue.get_nowait() |
相当Queue.get(False) |
Queue.put(item,[block[, timeout]]) |
将item消息写入队列,block默认值为True。1、如果block使用默认值,且没有设置timeout(单位秒),消息列队如果已经没有空间可写入,此时程序将被阻塞(停在写入状态),直到从消息列队腾出空间为止,如果设置了timeout,则会等待timeout秒,若还没空间,则抛出"Queue.Full"异常。 2、如果block值为False,消息列队如果没有空间可写入,则会立刻抛出"Queue.Full"异常 |
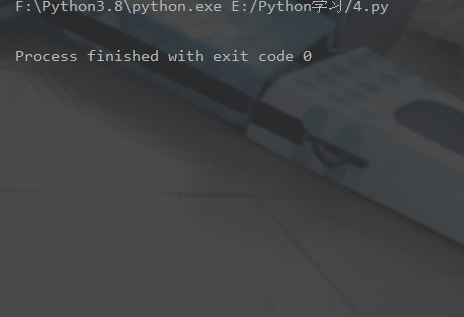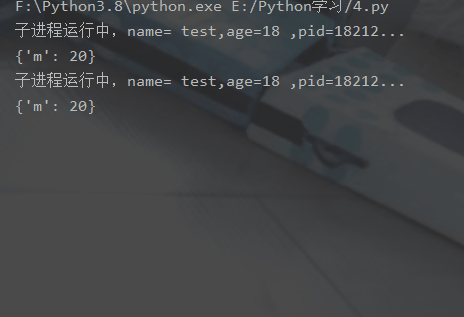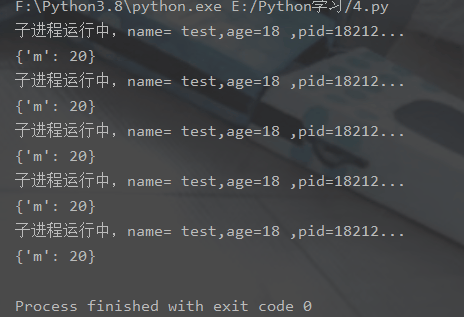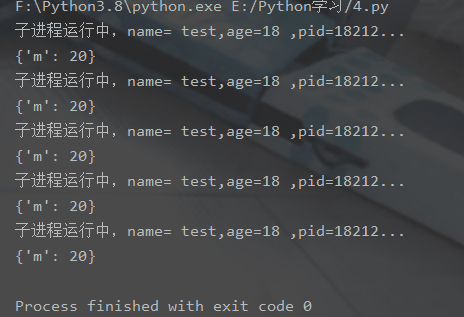
Queue.put_nowait(item)3. 프로세스 pid |
실행 결과: |
 🎜5 . 전역 변수는 프로세스 간에 공유되지 않습니다🎜
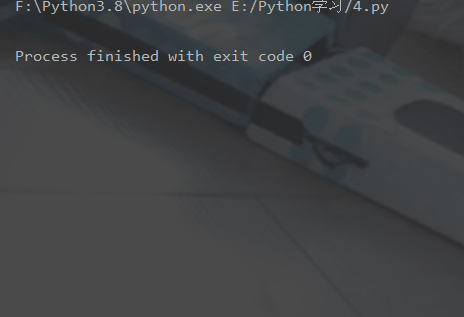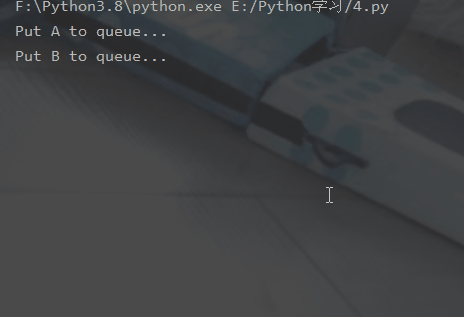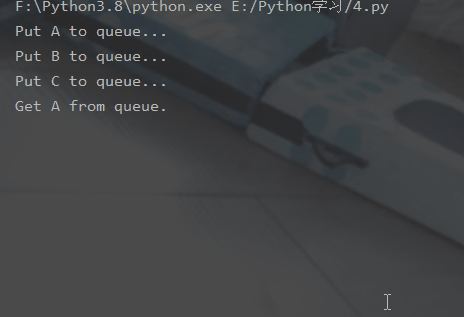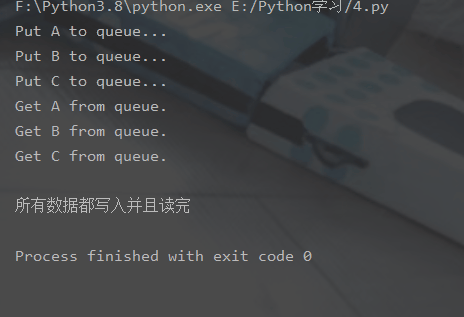
🎜5 . 전역 변수는 프로세스 간에 공유되지 않습니다🎜 from multiprocessing import Process, Queueimport os, time, random# 写数据进程执行的代码:def write(q):
for value in ['A', 'B', 'C']:
print('Put %s to queue...' % value)
q.put(value)
time.sleep(random.random())# 读数据进程执行的代码:def read(q):
while True:
if not q.empty():
value = q.get(True)
print('Get %s from queue.' % value)
time.sleep(random.random())
else:
breakif __name__=='__main__':
# 父进程创建Queue,并传给各个子进程:
q = Queue()
pw = Process(target=write, args=(q,))
pr = Process(target=read, args=(q,))
# 启动子进程pw,写入:
pw.start()
# 等待pw结束:
pw.join()
# 启动子进程pr,读取:
pr.start()
pr.join()
# pr进程里是死循环,无法等待其结束,只能强行终止:
print('')
print('所有数据都写入并且读完')import multiprocessingimport timedef add(num, value):
print('add{0}:num={1}'.format(value, num))
for i in range(0, 2):
num += value print('add{0}:num={1}'.format(value, num))
time.sleep(1)if __name__ == '__main__':
lock = multiprocessing.Lock()
num = 0
p1 = multiprocessing.Process(target=add, args=(num, 1))
p2 = multiprocessing.Process(target=add, args=(num, 2))
p1.start()
p2.start()🎜프로세스는 때때로 프로세스 간 통신을 위해 많은 메커니즘을 제공해야 합니다. 의사소통.🎜1. 큐 클래스 구문 설명🎜
| 메서드 이름 | 설명 | 🎜 thead>||||||
|---|---|---|---|---|---|---|---|
| 方法名 | 说明 |
|---|---|
close() |
关闭Pool,使其不再接受新的任务 |
terminate() |
不管任务是否完成,立即终止 |
join() |
主进程阻塞,等待子进程的退出, 必须在close或terminate之后使用 |
2. Pool实例
初始化Pool时,可以指定一个最大进程数,当有新的请求提交到Pool中时,如果池还没有满,那么就会创建一个新的进程用来执行该请求;但如果池中的进程数已经达到指定的最大值,那么该请求就会等待,直到池中有进程结束,才会用之前的进程来执行新的任务,请看下面的实例:
# -*- coding:utf-8 -*-from multiprocessing import Poolimport os, time, randomdef worker(msg):
t_start = time.time()
print("%s开始执行,进程号为%d" % (msg,os.getpid()))
# random.random()随机生成0~1之间的浮点数
time.sleep(random.random()*2)
t_stop = time.time()
print(msg,"执行完毕,耗时%0.2f" % (t_stop-t_start))po = Pool(3) # 定义一个进程池,最大进程数3for i in range(0,10):
# Pool().apply_async(要调用的目标,(传递给目标的参数元祖,))
# 每次循环将会用空闲出来的子进程去调用目标
po.apply_async(worker,(i,))print("----start----")po.close()
# 关闭进程池,关闭后po不再接收新的请求po.join()
# 等待po中所有子进程执行完成,必须放在close语句之后print("-----end-----")运行结果:
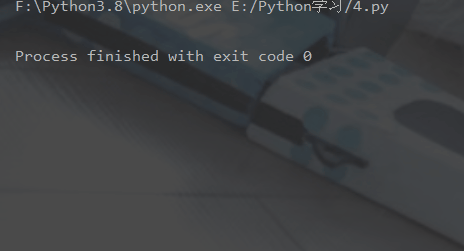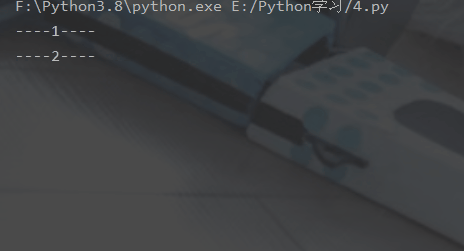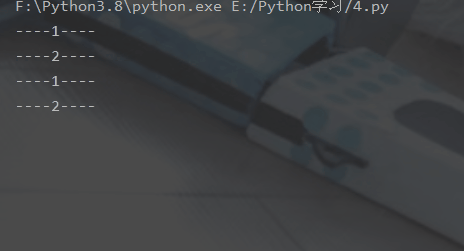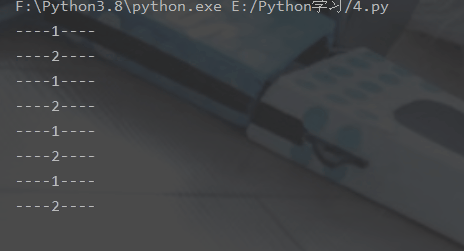
----start---- 0开始执行,进程号为21466 1开始执行,进程号为21468 2开始执行,进程号为21467 0 执行完毕,耗时1.01 3开始执行,进程号为21466 2 执行完毕,耗时1.24 4开始执行,进程号为21467 3 执行完毕,耗时0.56 5开始执行,进程号为21466 1 执行完毕,耗时1.68 6开始执行,进程号为21468 4 执行完毕,耗时0.67 7开始执行,进程号为21467 5 执行完毕,耗时0.83 8开始执行,进程号为21466 6 执行完毕,耗时0.75 9开始执行,进程号为21468 7 执行完毕,耗时1.03 8 执行完毕,耗时1.05 9 执行完毕,耗时1.69 -----end-----
3. 进程池中的Queue
如果要使用Pool创建进程,就需要使用multiprocessing.Manager()中的Queue()
而不是multiprocessing.Queue(),否则会得到一条如下的错误信息:RuntimeError: Queue objects should only be shared between processes through inheritance.
下面的实例演示了进程池中的进程如何通信:
# -*- coding:utf-8 -*-# 修改import中的Queue为Managerfrom multiprocessing import Manager,Poolimport os,time,randomdef reader(q):
print("reader启动(%s),父进程为(%s)" % (os.getpid(), os.getppid()))
for i in range(q.qsize()):
print("reader从Queue获取到消息:%s" % q.get(True))def writer(q):
print("writer启动(%s),父进程为(%s)" % (os.getpid(), os.getppid()))
for i in "itcast":
q.put(i)if __name__=="__main__":
print("(%s) start" % os.getpid())
q = Manager().Queue() # 使用Manager中的Queue
po = Pool()
po.apply_async(writer, (q,))
time.sleep(1) # 先让上面的任务向Queue存入数据,然后再让下面的任务开始从中取数据
po.apply_async(reader, (q,))
po.close()
po.join()
print("(%s) End" % os.getpid())运行结果:
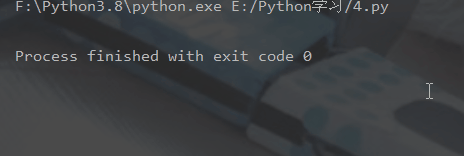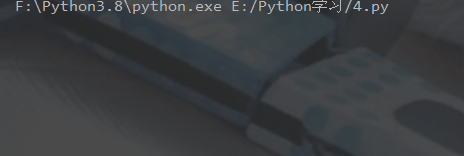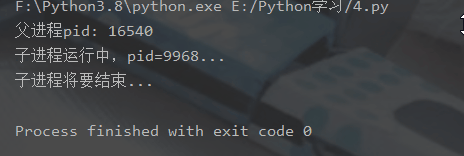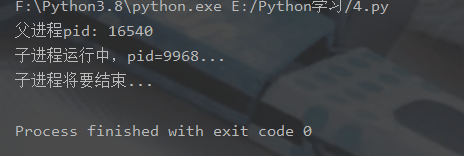
(11095) start writer启动(11097),父进程为(11095)reader启动(11098),父进程为(11095)reader从Queue获取到消息:i reader从Queue获取到消息:t reader从Queue获取到消息:c reader从Queue获取到消息:a reader从Queue获取到消息:s reader从Queue获取到消息:t(11095) End
六、进程、线程对比
1. 功能
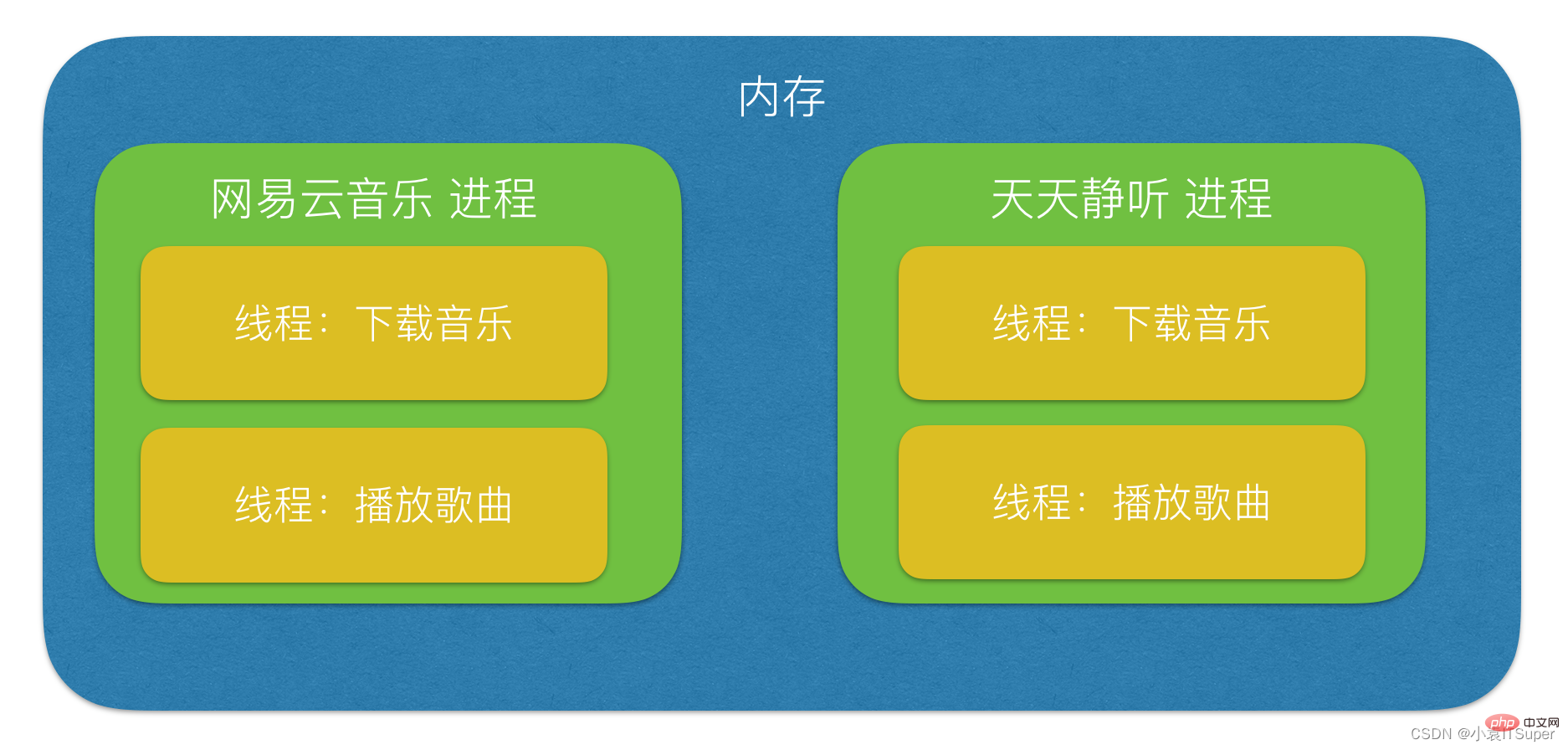
进程:能够完成多任务,比如 在一台电脑上能够同时运行多个QQ
线程:能够完成多任务,比如 一个QQ中的多个聊天窗口
定义的不同
进程是系统进行资源分配和调度的一个独立单位.
线程是进程的一个实体,是CPU调度和分派的基本单位,它是比进程更小的能独立运行的基本单位.线程自己基本上不拥有系统资源,只拥有一点在运行中必不可少的资源(如程序计数器,一组寄存器和栈),但是它可与同属一个进程的其他的线程共享进程所拥有的全部资源.
2. 区别
- 一个程序至少有一个进程,一个进程至少有一个线程.
-线程的划分尺度小于进程(资源比进程少),使得多线程程序的并发性高。
-进程在执行过程中拥有独立的内存单元,而多个线程共享内存,从而极大地提高了程序的运行效率
- 线线程不能够独立执行,必须依存在进程中
- 可以将进程理解为工厂中的一条流水线,而其中的线程就是这个流水线上的工人
3. 优缺点
- 线程:线程执行开销小,但不利于资源的管理和保护
- 进程:进程执行开销大,但利于资源的管理和保护
推荐学习:python视频教程
위 내용은 Python 다중 프로세스 지식 포인트 요약의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

Video Face Swap
완전히 무료인 AI 얼굴 교환 도구를 사용하여 모든 비디오의 얼굴을 쉽게 바꾸세요!

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7677
7677
 15
1393
52
1207
24
91
11
73
19
15
1393
52
1207
24
91
11
73
19

 PHP와 Python : 다른 패러다임이 설명되었습니다
Apr 18, 2025 am 12:26 AM
PHP와 Python : 다른 패러다임이 설명되었습니다
Apr 18, 2025 am 12:26 AM
PHP는 주로 절차 적 프로그래밍이지만 객체 지향 프로그래밍 (OOP)도 지원합니다. Python은 OOP, 기능 및 절차 프로그래밍을 포함한 다양한 패러다임을 지원합니다. PHP는 웹 개발에 적합하며 Python은 데이터 분석 및 기계 학습과 같은 다양한 응용 프로그램에 적합합니다.
 PHP와 Python 중에서 선택 : 가이드
Apr 18, 2025 am 12:24 AM
PHP와 Python 중에서 선택 : 가이드
Apr 18, 2025 am 12:24 AM
PHP는 웹 개발 및 빠른 프로토 타이핑에 적합하며 Python은 데이터 과학 및 기계 학습에 적합합니다. 1.PHP는 간단한 구문과 함께 동적 웹 개발에 사용되며 빠른 개발에 적합합니다. 2. Python은 간결한 구문을 가지고 있으며 여러 분야에 적합하며 강력한 라이브러리 생태계가 있습니다.
 Python vs. JavaScript : 학습 곡선 및 사용 편의성
Apr 16, 2025 am 12:12 AM
Python vs. JavaScript : 학습 곡선 및 사용 편의성
Apr 16, 2025 am 12:12 AM
Python은 부드러운 학습 곡선과 간결한 구문으로 초보자에게 더 적합합니다. JavaScript는 가파른 학습 곡선과 유연한 구문으로 프론트 엔드 개발에 적합합니다. 1. Python Syntax는 직관적이며 데이터 과학 및 백엔드 개발에 적합합니다. 2. JavaScript는 유연하며 프론트 엔드 및 서버 측 프로그래밍에서 널리 사용됩니다.
 Python에서 비주얼 스튜디오 코드를 사용할 수 있습니다
Apr 15, 2025 pm 08:18 PM
Python에서 비주얼 스튜디오 코드를 사용할 수 있습니다
Apr 15, 2025 pm 08:18 PM
VS 코드는 파이썬을 작성하는 데 사용될 수 있으며 파이썬 애플리케이션을 개발하기에 이상적인 도구가되는 많은 기능을 제공합니다. 사용자는 다음을 수행 할 수 있습니다. Python 확장 기능을 설치하여 코드 완료, 구문 강조 및 디버깅과 같은 기능을 얻습니다. 디버거를 사용하여 코드를 단계별로 추적하고 오류를 찾아 수정하십시오. 버전 제어를 위해 git을 통합합니다. 코드 서식 도구를 사용하여 코드 일관성을 유지하십시오. 라인 도구를 사용하여 잠재적 인 문제를 미리 발견하십시오.
 Windows 8에서 코드를 실행할 수 있습니다
Apr 15, 2025 pm 07:24 PM
Windows 8에서 코드를 실행할 수 있습니다
Apr 15, 2025 pm 07:24 PM
VS 코드는 Windows 8에서 실행될 수 있지만 경험은 크지 않을 수 있습니다. 먼저 시스템이 최신 패치로 업데이트되었는지 확인한 다음 시스템 아키텍처와 일치하는 VS 코드 설치 패키지를 다운로드하여 프롬프트대로 설치하십시오. 설치 후 일부 확장은 Windows 8과 호환되지 않을 수 있으며 대체 확장을 찾거나 가상 시스템에서 새로운 Windows 시스템을 사용해야합니다. 필요한 연장을 설치하여 제대로 작동하는지 확인하십시오. Windows 8에서는 VS 코드가 가능하지만 더 나은 개발 경험과 보안을 위해 새로운 Windows 시스템으로 업그레이드하는 것이 좋습니다.
 VScode 확장자가 악의적입니까?
Apr 15, 2025 pm 07:57 PM
VScode 확장자가 악의적입니까?
Apr 15, 2025 pm 07:57 PM
VS 코드 확장은 악의적 인 코드 숨기기, 취약성 악용 및 합법적 인 확장으로 자위하는 등 악성 위험을 초래합니다. 악의적 인 확장을 식별하는 방법에는 게시자 확인, 주석 읽기, 코드 확인 및주의해서 설치가 포함됩니다. 보안 조치에는 보안 인식, 좋은 습관, 정기적 인 업데이트 및 바이러스 백신 소프트웨어도 포함됩니다.
 PHP와 Python : 그들의 역사에 깊은 다이빙
Apr 18, 2025 am 12:25 AM
PHP와 Python : 그들의 역사에 깊은 다이빙
Apr 18, 2025 am 12:25 AM
PHP는 1994 년에 시작되었으며 Rasmuslerdorf에 의해 개발되었습니다. 원래 웹 사이트 방문자를 추적하는 데 사용되었으며 점차 서버 측 스크립팅 언어로 진화했으며 웹 개발에 널리 사용되었습니다. Python은 1980 년대 후반 Guidovan Rossum에 의해 개발되었으며 1991 년에 처음 출시되었습니다. 코드 가독성과 단순성을 강조하며 과학 컴퓨팅, 데이터 분석 및 기타 분야에 적합합니다.
 터미널 VSCODE에서 프로그램을 실행하는 방법
Apr 15, 2025 pm 06:42 PM
터미널 VSCODE에서 프로그램을 실행하는 방법
Apr 15, 2025 pm 06:42 PM
vs 코드에서는 다음 단계를 통해 터미널에서 프로그램을 실행할 수 있습니다. 코드를 준비하고 통합 터미널을 열어 코드 디렉토리가 터미널 작업 디렉토리와 일치하는지 확인하십시오. 프로그래밍 언어 (예 : Python의 Python Your_file_name.py)에 따라 실행 명령을 선택하여 성공적으로 실행되는지 여부를 확인하고 오류를 해결하십시오. 디버거를 사용하여 디버깅 효율을 향상시킵니다.
