

이 기사에서는 언두 로그를 통해 트랜잭션의 원자성을 달성하고, 리두를 통해 트랜잭션의 지속성을 달성하는 등 트랜잭션 워크플로의 원칙과 관련된 문제를 주로 소개하는 mysql에 대한 관련 지식을 제공합니다. 로그 등의 구현이 모든 사람에게 도움이 되기를 바랍니다.

추천 학습: mysql 비디오 튜토리얼
질문 1: 왜 redo 로그가 필요한가요?
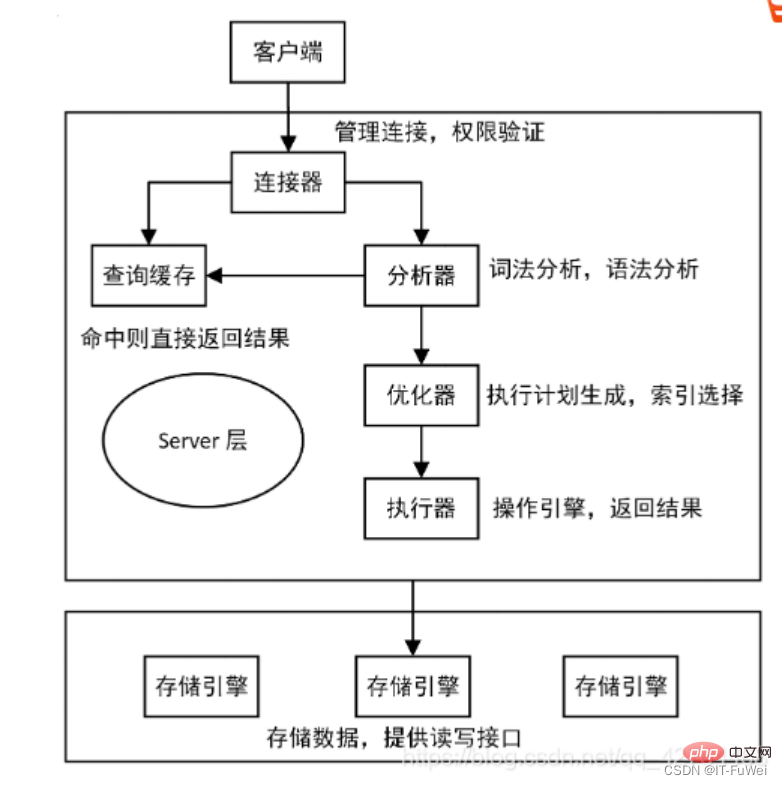
InnoDB는 MySQL의 스토리지 엔진입니다. 데이터는 디스크에 저장되지만 데이터를 읽고 쓸 때마다 디스크 IO가 필요하면 효율성이 매우 낮습니다. 이를 위해 InnoDB는 데이터베이스에 접근하기 위한 버퍼로 캐시(Buffer Pool)를 제공한다. 데이터베이스에서 데이터를 읽을 때 버퍼 풀이 없으면 먼저 버퍼 풀에서 읽어온다. 데이터베이스에 데이터를 쓸 때 먼저 버퍼 풀에 기록되고 버퍼 풀의 수정된 데이터가 정기적으로 디스크에 새로 고쳐집니다.
버퍼 풀을 사용하면 데이터 읽기 및 쓰기 효율성이 크게 향상되지만 새로운 문제도 발생합니다. MySQL이 다운되고 버퍼 풀의 수정된 데이터가 디스크에 플러시되지 않으면 데이터 손실이 발생합니다. 거래 내구성은 보장되지 않습니다.
질문 2: 리두 로그는 어떻게 트랜잭션의 내구성을 보장하나요?
Redo 로그는 간단히 다음 두 부분으로 나눌 수 있습니다.
첫 번째는 휘발성이고 메모리에 있는 인메모리 리두 로그 버퍼(redo log buffer)입니다.
두 번째는 redo입니다. 로그 파일(redo 로그 파일)은 영구적이며 디스크에 저장됩니다
여기서 Redo를 작성하는 타이밍에 대해 자세히 설명합니다.
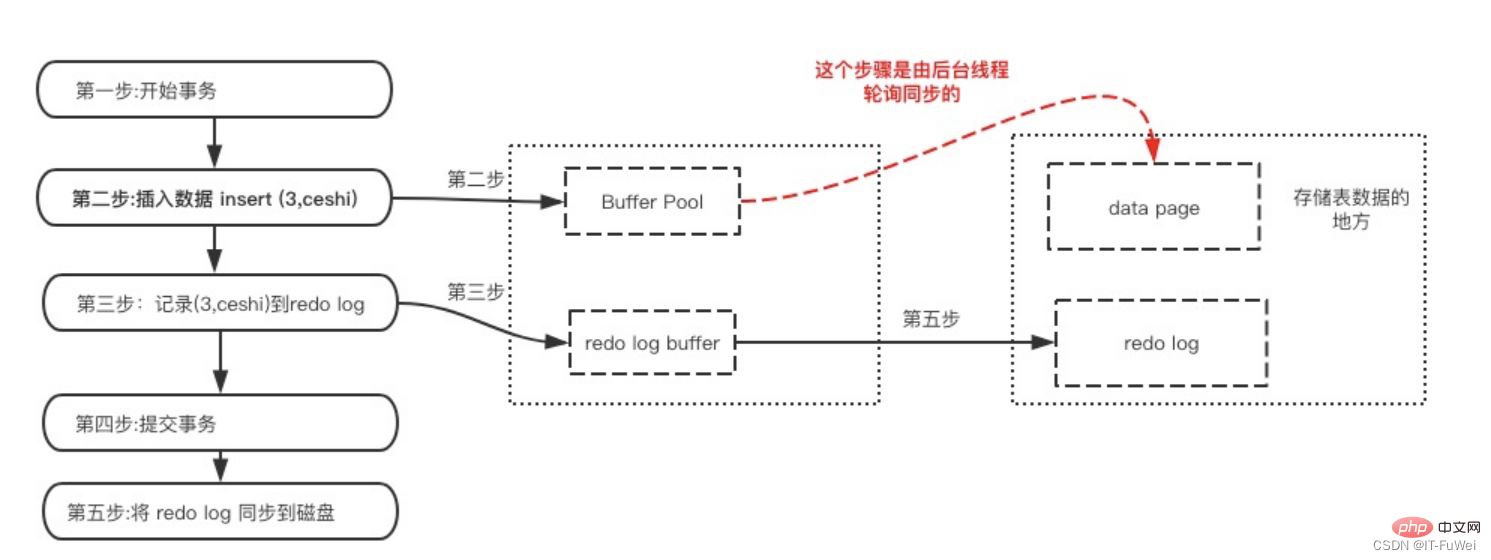
데이터 페이지 수정이 완료된 후 더티 페이지가 디스크에서 플러시되기 전 , 리두 로그가 기록됩니다. 데이터가 먼저 수정되고 로그가 나중에 기록된다는 점에 유의하세요
리두 로그는 데이터 페이지 전에 디스크에 다시 기록됩니다
클러스터드 인덱스, 보조 인덱스, 실행 취소 페이지의 수정 사항은 모두 Redo에 기록되어야 합니다. log
MySQL에서 모든 업데이트 작업을 디스크에 기록해야 하고 디스크가 업데이트 전에 해당 레코드를 찾아야 하는 경우 전체 프로세스의 IO 비용과 검색 비용이 매우 높아집니다. 이 문제를 해결하기 위해 MySQL 설계자들은 업데이트 효율성을 높이기 위해 로그(redo log)를 사용했습니다.
트랜잭션이 커밋되면 지속성을 위해 먼저 리두 로그 버퍼가 리두 로그 파일에 기록되며, 트랜잭션의 커밋 작업이 완료될 때까지 완료되지 않습니다. 이 접근 방식은 미리 쓰기 로그(사전 로그 지속성)라고도 합니다. 데이터 페이지를 유지하기 전에 메모리의 해당 로그 페이지가 유지됩니다.
구체적으로, 레코드를 업데이트해야 하는 경우 InnoDB 엔진은 먼저 해당 레코드를 리두 로그(리두 로그 버퍼)에 기록하고 메모리(버퍼 풀)를 업데이트합니다. 동시에 InnoDB 엔진은 적절한 시간(예: 시스템이 유휴 상태일 때)에 이 작업 기록을 디스크에 업데이트합니다(더티 페이지 플러시).
하나의 트랜잭션에서 여러 페이지를 수정할 수 있습니다. 미리 쓰기 로그는 단일 데이터 페이지의 일관성을 보장할 수 있지만 트랜잭션의 내구성을 보장할 수는 없습니다. 로그 플러시가 완료된 후 버퍼 풀의 페이지가 영구 저장 장치로 플러시되기 전에 데이터베이스가 충돌하면 데이터베이스가 다시 시작될 때 무결성이 모두 생성됩니다. 로그를 통해 데이터를 확인할 수 있습니다.
질문 3: 로그를 다시 작성하는 과정은 무엇인가요?
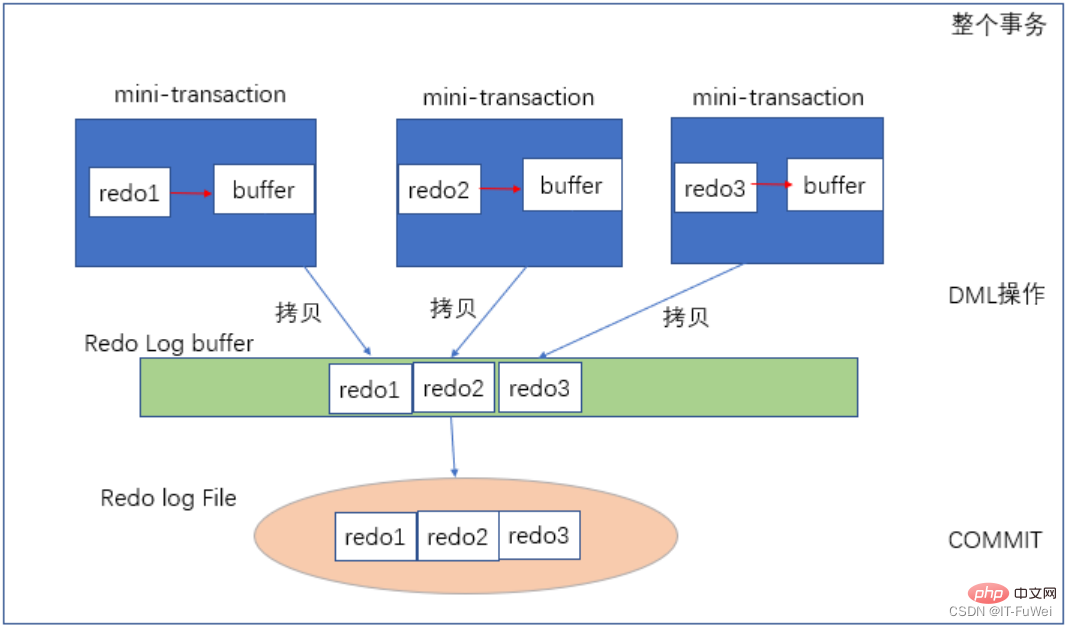
위 그림은 리두 로그 작성 과정을 보여줍니다. 각 미니 트랜잭션은 업데이트 문과 같은 각 DML 작업에 해당하며, 이는 데이터가 수정된 후 먼저 redo1이 생성됩니다. 업데이트 문이 끝난 후 프라이빗 버퍼에서 퍼블릭 로그 버퍼로 redo1을 복사합니다. 전체 외부 트랜잭션이 커밋되면 리두 로그 버퍼가 리두 로그 파일로 플러시됩니다. (리두 로그는 순차적으로 기록되며, 디스크의 순차적 읽기 및 쓰기는 무작위 읽기 및 쓰기보다 훨씬 빠릅니다.)
질문 4: 데이터 기록 후 최종 디스크 배치가 리두 로그에서 업데이트됩니까? 버퍼 풀에서 업데이트되면 어떻게 되나요?
사실 리두 로그는 데이터 페이지의 전체 데이터를 기록하지 않기 때문에 자체적으로 디스크 데이터 페이지를 업데이트하는 기능도 없고, 데이터가 업데이트되는 상황도 없습니다. 리두 로그는 최종적으로 디스크에 저장됩니다.
① 데이터 페이지가 수정된 후 디스크의 데이터 페이지와 일치하지 않는 현상을 더티 페이지라고 합니다. 최종 데이터 플러시는 메모리의 데이터 페이지를 디스크에 쓰는 것입니다. 이 프로세스는 REDO 로그와는 아무런 관련이 없습니다.
② 충돌 복구 시나리오에서 InnoDB는 충돌 복구 중에 데이터 페이지의 업데이트가 손실되었을 수 있다고 판단하면 이를 메모리로 읽은 다음 리두 로그가 메모리 내용을 업데이트하도록 합니다. 업데이트가 완료되면 메모리 페이지는 더티 페이지가 되어 처음 상황의 상태로 돌아갑니다
질문 5: 리두 로그 버퍼란 무엇인가요? 메모리를 먼저 수정해야 할까요, 아니면 리두 로그 파일을 먼저 작성해야 할까요?
트랜잭션 업데이트 과정에서 로그를 여러 번 작성해야 합니다. 예를 들어 다음 트랜잭션은
Copybegin;
INSERT INTO T1 VALUES ('1', '1');
INSERT INTO T2 VALUES ('1', '1');
commit;
This 트랜잭션에는 두 개의 테이블에 레코드를 삽입해야 합니다. 데이터를 삽입하는 과정에서 생성된 로그를 먼저 저장해야 하지만 커밋하기 전에 리두 로그 파일에 직접 쓸 수는 없습니다.
그래서 리두 로그 버퍼가 필요합니다. 리두 로그를 먼저 저장하는 데 사용되는 메모리 조각입니다. 즉, 첫 번째 insert가 실행되면 데이터 메모리가 수정되고 redo log buffer도 로그에 기록됩니다.
그러나 실제 로그가 REDO 로그 파일에 기록되는 것은 커밋 문이 실행될 때 이루어집니다.
redo 로그 버퍼는 본질적으로 바이트 배열이지만, 이 버퍼를 유지하려면 다른 많은 메타 데이터를 설정해야 하며, 모두 log_t 구조에 캡슐화되어 있습니다.
질문 6: 리두 로그가 디스크에 순차적으로 기록되나요?
redo 로그는 파일을 순차적으로 작성합니다. 모든 파일이 가득 차면 각 트랜잭션이 제출된 후 해당 작업 로그가 첫 번째 파일의 해당 시작 위치로 돌아갑니다. 이는 Redo 로그 파일이며 파일 끝에 추가됩니다. 이는 순차 I/O
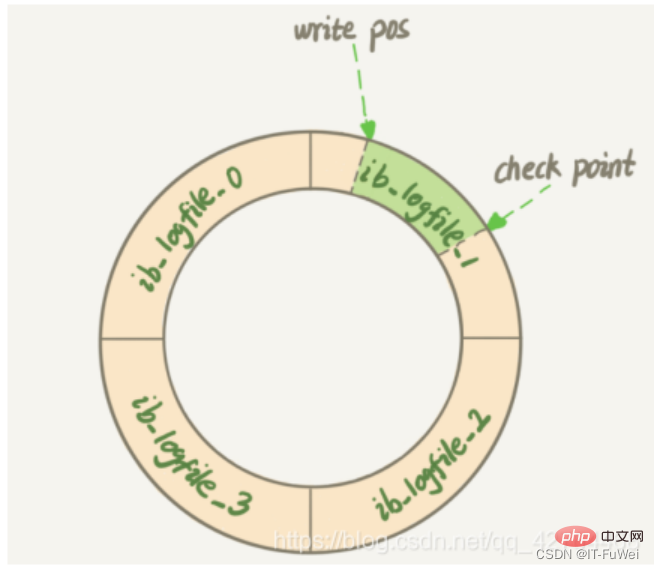
사진은 4개 파일의 Redo 로그 로그 세트를 보여주며 현재 체크포인트가 삭제될 예정입니다. 레코드를 삭제하기 전에 해당 데이터를 디스크에 기록해야 합니다(메모리 페이지를 업데이트하고 더티 페이지가 플러시될 때까지 기다림). write pos와 checkpoint 사이의 부분은 새로운 작업을 기록하는 데 사용될 수 있습니다. write pos와 checkpoint가 일치하면 이 때 데이터베이스는 데이터베이스 업데이트 문 실행을 중지하고 대신 redo 로그를 동기화한다는 의미입니다. 디스크. 체크포인트와 쓰기 위치 사이의 부분은 디스크가 쓰기를 기다리고 있습니다(먼저 메모리 페이지를 업데이트한 다음 더티 페이지가 플러시될 때까지 기다립니다).
리두 로그를 이용하면 데이터베이스가 비정상적으로 재시작할 때, 크래시로부터 안전한 리두 로그를 기반으로 복원이 가능합니다.
redo 로그는 충돌 방지 기능을 보장하는 데 사용됩니다. innodb_flush_log_at_trx_commit 매개변수가 1로 설정되면 각 트랜잭션의 리두 로그가 디스크에 직접 유지된다는 의미입니다. MySQL이 비정상적으로 다시 시작된 후 데이터가 손실되지 않도록 이 매개변수를 1로 설정하는 것이 좋습니다
MySQL은 실제로 두 부분으로 구성됩니다. 하나는 주로 MySQL 기능 계층 작업을 수행하는 서버 계층입니다. ; 스토리지와 관련된 특정 문제를 담당하는 엔진 레이어도 있습니다. 위에서 이야기한 redo 로그는 InnoDB 엔진 고유의 로그이고, Server 계층에도 binlog(아카이브 로그)라는 자체 로그가 있습니다.
왜 로그가 2개인가요?
처음에는 MySQL에 InnoDB 엔진이 없었거든요. MySQL의 자체 엔진은 MyISAM이지만 MyISAM에는 충돌 방지 기능이 없으며 binlog 로그는 보관에만 사용할 수 있습니다. InnoDB는 다른 회사에서 플러그인 형태로 MySQL에 도입했습니다. binlog에만 의존하면 충돌 방지 기능이 없으므로 InnoDB는 충돌 방지 기능을 달성하기 위해 다른 로그 시스템, 즉 redo 로그를 사용합니다.
이 두 로그에는 다음 세 가지 차이점이 있습니다.
① redo 로그는 InnoDB 엔진에 고유하며, binlog는 MySQL의 서버 계층에서 구현되며 모든 엔진에서 사용할 수 있습니다.
② redo 로그는 "특정 데이터 페이지에서 어떤 수정이 이루어졌는지"를 기록하는 물리적 로그입니다. binlog는 "행의 c 필드를 다음과 같이 제공"과 같은 이 문의 원래 논리를 기록하는 논리적 로그입니다. ID=2” 1”을 추가합니다.
3 Redo 로그는 루프로 작성되며 공간은 항상 사용됩니다. binlog를 추가로 작성할 수 있습니다. "쓰기 추가"는 binlog 파일이 특정 크기에 도달한 후 다음 파일로 전환하고 이전 로그를 덮어쓰지 않음을 의미합니다.
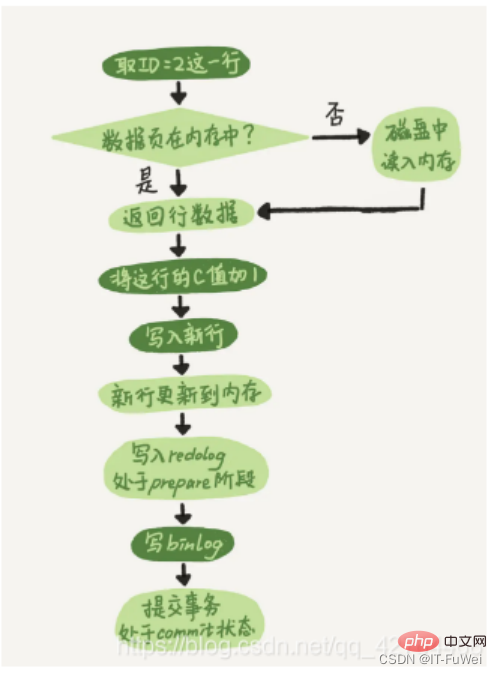
이 두 로그에 대한 개념적 이해를 바탕으로, 이 업데이트 문을 실행할 때 실행기와 InnoDB 엔진의 내부 프로세스를 살펴보겠습니다.
① 실행자는 먼저 라인 ID=2를 얻기 위해 엔진을 찾습니다. ID는 기본 키이며 엔진은 이 행을 찾기 위해 트리 검색을 직접 사용합니다. ID=2 행이 있는 데이터 페이지가 이미 메모리에 있으면 실행기로 직접 반환됩니다. 그렇지 않으면 디스크에서 메모리로 읽어온 다음 반환해야 합니다.
② 실행자는 엔진에서 제공한 행 데이터를 가져오고 이 값에 1을 더합니다. 예를 들어 이전에는 N이었지만 지금은 N+1이며 새 데이터 행을 가져온 다음 엔진 인터페이스를 호출합니다. 이 새로운 데이터 행을 작성합니다.
3 엔진은 이 새로운 데이터 행을 메모리(InnoDB 버퍼 풀)에 업데이트하고 업데이트 작업을 리두 로그에 기록합니다. 이때 리두 로그는 준비 상태입니다. 그런 다음 실행이 완료되었으며 언제든지 트랜잭션을 제출할 수 있음을 실행자에게 알립니다.
4 실행자는 이 작업의 binlog를 생성하고 binlog를 디스크에 씁니다.
⑤ Executor는 엔진의 커밋 트랜잭션 인터페이스를 호출하고 엔진은 방금 작성된 Redo 로그를 커밋 상태로 변경하고 업데이트가 완료됩니다.
리두 로그 작성은 준비와 준비 두 단계로 나누어집니다. 커밋, 이것이 2단계 커밋입니다(2PC)
질문 1: 2단계 커밋의 원리는 무엇인가요?
MySQL은 주로 binlog와 redo 로그 간의 데이터 일관성 문제를 해결하기 위해 2단계 커밋을 사용합니다.
2단계 커밋 원리 설명:
① redo 로그가 디스크에 기록되고 InnoDB 트랜잭션이 준비 상태로 들어갑니다.
② 이전 준비가 성공하고 binlog가 디스크에 기록되면 계속해서 binlog에 트랜잭션 로그를 유지합니다. 지속성이 성공하면 InnoDB 트랜잭션이 커밋 상태로 들어갑니다.
redo 로그와 binlog에는 XID라는 공통 데이터 필드가 있습니다. 크래시 복구 중에 리두 로그는 다음 순서대로 스캔됩니다.
① 준비와 커밋이 모두 포함된 리두 로그가 있는 경우 직접 제출하세요.
② 커밋이 없고 파레파레만 있는 리두 로그가 있는 경우 직접 제출하세요. . XID를 가져와서 binlog로 이동하여 해당 트랜잭션을 찾으세요.
Binlog에 기록이 없음, 트랜잭션 롤백
binlog에 기록이 있음, 트랜잭션 커밋
질문 2: "2단계 커밋"이 필요한 이유는 무엇입니까?
2단계 커밋을 사용하지 않는 경우 ID=2인 현재 행의 c 필드 값이 0이라고 가정하고 업데이트 문 실행 중에 첫 번째 로그가 작성된 후라고 가정합니다. , 두 번째 로그는 여전히 쓰기가 완료되기 전에 충돌이 발생하면 어떻게 되나요?
**리두 로그를 먼저 작성한 다음 binlog를 작성하세요. **redo 로그가 기록될 때 binlog가 기록되기 전에 MySQL 프로세스가 비정상적으로 다시 시작된다고 가정합니다. 앞에서 말했듯이 리두 로그가 작성된 후에는 시스템이 충돌하더라도 데이터를 복구할 수 있으므로 복구 후 이 줄의 c 값은 1입니다.
그러나 binlog가 완료되기 전에 충돌이 발생했기 때문에 현재 이 명령문은 binlog에 기록되지 않았습니다. 따라서 나중에 로그를 백업할 때 저장된 binlog에는 이 문장이 포함되지 않습니다.
그러면 이 binlog를 사용하여 임시 라이브러리를 복원해야 하는 경우 이 명령문의 binlog가 손실되므로 임시 라이브러리가 이 업데이트를 놓치고 복원된 줄의 c 값이 0이라는 것을 알게 됩니다. 원본 라이브러리와 동일하지만 값이 다릅니다.
**binlog를 먼저 작성한 다음 로그를 다시 실행하세요. **binlog를 작성한 후 crash가 발생하면 redo log가 아직 작성되지 않았으므로 crash 복구 후 트랜잭션이 유효하지 않으므로 이 줄의 c 값은 0입니다. 그러나 "Change c from 0 to 1" 로그가 binlog에 기록되었습니다. 따라서 나중에 binlog를 사용하여 복원하면 트랜잭션이 하나 더 나오게 되는데, 복원된 행의 c 값은 1로 원래 데이터베이스의 값과 다릅니다.
"2단계 커밋"을 사용하지 않으면 데이터베이스의 상태가 해당 로그를 사용하여 복원된 라이브러리의 상태와 일치하지 않을 수 있음을 알 수 있습니다.
간단히 말하면 redo log와 binlog는 모두 트랜잭션의 커밋 상태를 나타내는 데 사용될 수 있으며, 2단계 커밋은 두 상태를 논리적으로 일관되게 유지하는 것입니다.
undo 로그에는 롤백 및 다중 버전 제어(MVCC) 제공
데이터가 수정되면 Redo만 기록되는 것이 아니라 Undo 로그는 주로 데이터의 논리적 변경 사항을 기록합니다. 오류 발생 시 이전 작업을 롤백하기 위해서는 이전 작업을 모두 기록한 다음 오류 발생 시 롤백해야 합니다.
undo 로그는 데이터베이스를 원래 상태로 논리적으로 복원합니다. 예를 들어 INSERT는 DELETE에 해당하고, 각 UPDATE에 대해 반대 UPDATE를 다시 수행합니다. 수정 전 줄. 실행 취소 로그는 트랜잭션의 원자성을 보장하기 위해 트랜잭션 롤백 작업에 사용됩니다.
원자성을 달성하는 핵심은 트랜잭션이 롤백될 때 성공적으로 실행된 모든 SQL 문을 실행 취소할 수 있다는 것입니다. InnoDB는 실행 취소 로그를 사용하여 롤백을 구현합니다. 트랜잭션이 데이터베이스를 수정하면 InnoDB는 해당 실행 취소 로그를 생성하여 트랜잭션 실행이 실패하거나 롤백이 호출되어 트랜잭션이 롤백될 수 있습니다. 데이터는 수정 전의 상태로 롤백됩니다.
InnoDB 스토리지 엔진에서 undo 로그는 다음과 같이 구분됩니다.
insert undo log
update undo log
insert undo log는 insert 작업에서 생성된 undo 로그를 말합니다. insert 작업의 기록만 볼 수 있기 때문입니다. 다른 거래에는 보이지 않으며 거래 자체에는 표시되지 않습니다. 따라서 트랜잭션이 제출된 후 실행 취소 로그를 직접 삭제할 수 있으며 제거 작업이 필요하지 않습니다.
업데이트 실행 취소 로그는 삭제 및 업데이트 작업으로 생성된 실행 취소 로그를 기록합니다. 실행 취소 로그는 MVCC 메커니즘을 제공해야 할 수 있으므로 트랜잭션이 커밋될 때 삭제할 수 없습니다. 제출할 때 실행 취소 로그 목록에 넣고 퍼지 스레드가 최종 삭제를 수행할 때까지 기다립니다.
보충 사항: 제거 스레드의 두 가지 주요 기능은 실행 취소 페이지를 정리하고 페이지에서 Delete_Bit 플래그를 사용하여 데이터 행을 지우는 것입니다. InnoDB에서 트랜잭션의 삭제 작업은 실제로 데이터 행을 삭제하는 것이 아니라 레코드를 삭제하지 않고 레코드에 Delete_Bit를 표시하는 삭제 표시 작업입니다. 일종의 '가짜 삭제'로 표시만 한 것인데 실제 삭제 작업은 백그라운드 퍼지 스레드에서 완료해야 한다.
Innodb는 B+ 트리를 인덱스 데이터 구조로 사용하며 기본 키가 위치한 인덱스는 ClusterIndex(클러스터형 인덱스)이며 해당 데이터 내용은 ClusterIndex의 리프 노드에 저장됩니다. 테이블에는 기본 키가 하나만 있을 수 있으므로 클러스터형 인덱스는 하나만 있을 수 있습니다. 테이블에 기본 키가 정의되어 있지 않으면 NULL이 아닌 첫 번째 고유 인덱스가 없으면 숨겨진 인덱스로 선택됩니다. id 열은 클러스터형 인덱스로 생성됩니다.
클러스터 인덱스 이외의 인덱스는 보조 인덱스(보조 인덱스)입니다. 보조 인덱스의 리프 노드에는 클러스터형 인덱스의 리프 노드 값이 저장됩니다.
방금 언급한 rowid 외에도 InnoDB 행 레코드에는 trx_id 및 db_roll_ptr도 포함됩니다. trx_id는 최근 수정된 트랜잭션의 ID를 나타내고 db_roll_ptr은 실행 취소 세그먼트의 실행 취소 로그를 가리킵니다.
새 거래가 추가되면 거래 ID가 증가하며, trx_id는 거래가 시작되는 순서를 나타낼 수 있습니다.
Undo 로그는 삽입과 업데이트의 두 가지 유형으로 구분됩니다. 삭제는 기록의 삭제 표시를 수정하는 특별한 업데이트로 간주될 수 있습니다.
update undo log는 이전 데이터 정보를 기록하며, 이를 통해 이전 버전의 상태를 복원할 수 있습니다.
삽입 작업을 수행할 때 생성된 삽입 실행 취소 로그는 트랜잭션이 커밋된 후 삭제될 수 있습니다. 다른 트랜잭션에는 이 실행 취소 로그가 필요하지 않기 때문입니다.
작업을 삭제하고 수정하면 해당 실행 취소 로그가 생성되고 현재 데이터 레코드의 db_roll_ptr은 새로운 실행 취소 로그를 가리킵니다.
MVCC(MultiVersion Concurrency Control)가 호출됩니다. 다중 버전 동시성 제어.
InnoDB의 MVCC는 각 레코드 행 뒤에 두 개의 숨겨진 열을 저장하여 구현됩니다. 이 두 열 중 하나는 행의 생성 시간을 저장하고, 다른 하나는 행의 만료 시간을 저장합니다. 물론 저장되는 것은 실제 시간 값이 아니라 시스템 버전 번호입니다.
주요 구현 아이디어는 여러 버전의 데이터를 통해 읽기와 쓰기를 분리하는 것입니다. 이를 통해 잠금 해제된 읽기와 병렬 읽기 및 쓰기가 가능합니다.
mysql에서 MVCC 구현은 실행 취소 로그 및 읽기 보기에 의존합니다
그리고 각 데이터 행에도 여러 버전이 있습니다. 트랜잭션이 데이터를 업데이트할 때마다 새로운 데이터 버전이 생성되고 트랜잭션 ID가 이 데이터 버전의 trx_id 행에 할당됩니다. 동시에 이전 데이터 버전을 유지해야 하며, 새 데이터 버전에서는 직접 얻을 수 있는 정보가 있을 수 있습니다.InnoDB는 MVCC를 구현할 때 일관된 읽기 뷰, 즉 일관된 읽기를 사용합니다. view - RC(Read Committed, Read Committed) 및 RR(Repeatable Read, Repeatable Read) 격리 수준의 구현을 지원하는 데 사용됩니다.
반복 읽기 격리 수준에서 트랜잭션은 시작될 때 "스냅샷을 찍습니다".
MySQL의 MVCC 스냅샷은 트랜잭션이 들어올 때마다 데이터베이스 정보의 복사본을 복사하지 않고, 데이터 테이블의 각 정보 행 뒤에 저장된 시스템 버전 번호를 기반으로 구현됩니다. 아래 그림에 표시된 것처럼 정보 행의 여러 버전이 공존하며 각 트랜잭션은 서로 다른 버전을 읽을 수 있습니다. InnoDB의 각 트랜잭션에는 고유한 트랜잭션 ID가 있습니다. 트랜잭션 시작 시 InnoDB 트랜잭션 시스템에 적용되며 적용 순서에 따라 엄격하게 증분됩니다.
 데이터 테이블의 레코드 행에는 실제로 여러 버전(행)이 있을 수 있으며 각 버전에는 자체 행 trx_id가 있습니다. 여러 트랜잭션에 의해 레코드가 지속적으로 업데이트된 후의 상태입니다.
데이터 테이블의 레코드 행에는 실제로 여러 버전(행)이 있을 수 있으며 각 버전에는 자체 행 trx_id가 있습니다. 여러 트랜잭션에 의해 레코드가 지속적으로 업데이트된 후의 상태입니다.
그림의 점선 상자에는 동일한 데이터 행의 4가지 버전이 있습니다. 최신 버전은 V4이고 k 값은 22입니다. 트랜잭션 ID가 25인 트랜잭션에 의해 업데이트되었으므로 해당 행 trx_id 또한 25입니다. 문 업데이트 시 실행 취소 로그(롤백 로그)가 생성되나요? 그럼 실행 취소 로그는 어디에 있나요?
사실 그림 2의 점선 세 개 화살표는 V1, V2, V3이 물리적으로 존재하지 않는 실행 취소 로그이며, 필요할 때마다 실행 취소 로그와 현재 버전을 기반으로 계산됩니다. 예를 들어 V2가 필요한 경우 V4를 거쳐 U3, U2를 순차적으로 실행하여 계산한다.
반복 읽기의 정의에 따르면 트랜잭션이 시작되면 제출된 모든 트랜잭션 결과를 볼 수 있습니다. 그러나 이 트랜잭션이 실행되는 동안에는 다른 트랜잭션의 업데이트가 표시되지 않습니다. 따라서 트랜잭션은 시작 시에만 "시작한 순간을 기준으로 시작하기 전에 데이터 버전이 생성되면 인식되고, 시작한 후에 생성되면 인식되지 않습니다"라고 선언하면 됩니다. 인식합니다.", 이전 버전을 찾아야 합니다." 물론, "이전 버전"도 보이지 않는다면 계속해서 기대해야 합니다. 또한 트랜잭션 자체에 의해 데이터가 업데이트되는 경우에도 이를 인식해야 합니다.
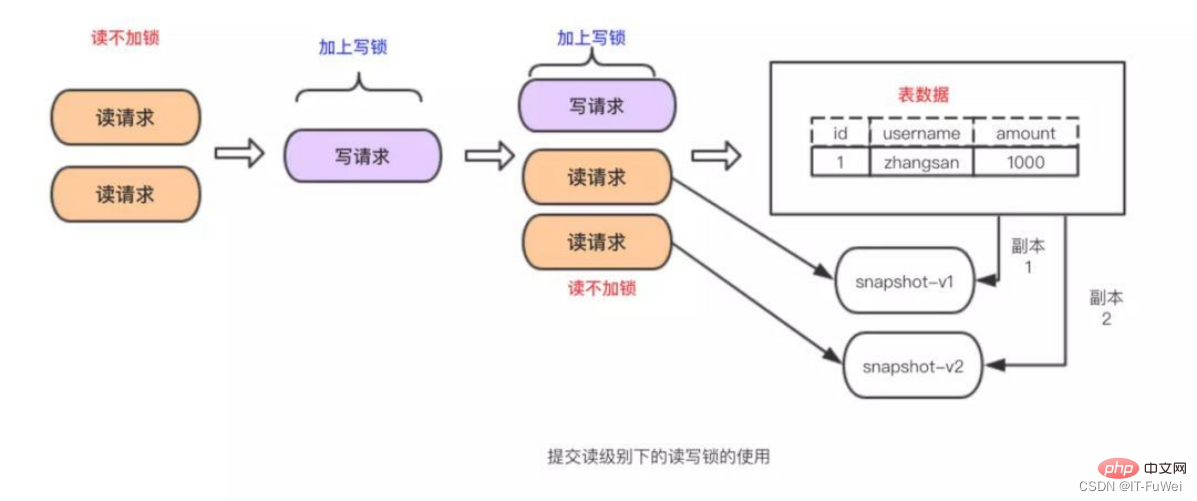
5. MySQL 잠금 기술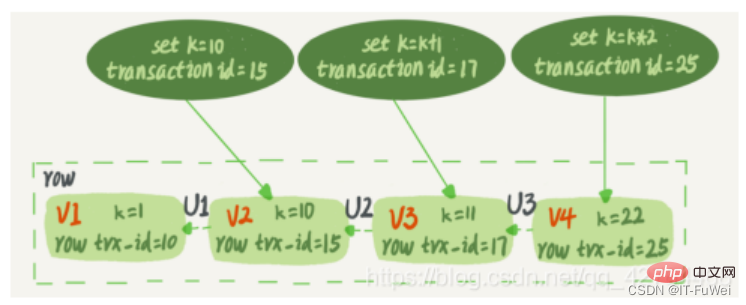
테이블의 데이터 읽기 요청이 여러 개 있을 경우 아무런 조치를 취할 수 없지만, 여러 요청 중 읽기 요청과 수정 요청이 있는 경우 이에 대한 대책이 있어야 합니다. 동시성 제어. 그렇지 않으면 불일치가 발생할 가능성이 높습니다. 읽기-쓰기 잠금으로 위의 문제를 해결하는 것은 매우 간단합니다. 읽기 및 쓰기 요청을 제어하려면 두 잠금의 조합만 사용하면 됩니다. 이 두 잠금을배타적 잠금공유 잠금
(공유 잠금)이라고 합니다. , "읽기 잠금"이라고도 함 읽기 잠금을 공유할 수 있거나 여러 읽기 요청이 차단을 유발하지 않고 데이터를 읽기 위해 잠금을 공유할 수 있습니다.
요약: 읽기-쓰기 잠금을 통해 읽기와 읽기는 병렬로 수행될 수 있지만 쓰기와 읽기는 병렬로 수행될 수 없습니다. 읽기-쓰기 잠금을 기반으로 트랜잭션 격리가 이루어집니다. ! !
추천 학습: mysql 비디오 튜토리얼
위 내용은 MySQL 트랜잭션 워크플로의 원리를 함께 분석해 보겠습니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



