

Redis의 명령 원자성에 대한 자세한 분석

이 기사에서는 동시 처리 솔루션, 프로그래밍 모델, 다중 IO 스레드 및 단일 명령을 포함하여 원자성 작업에서 명령의 원자성과 관련된 문제를 주로 소개하는 Redis에 대한 관련 지식을 제공합니다. 아래 내용을 살펴보겠습니다. . 모든 사람에게 도움이 되기를 바랍니다.

추천 학습: Redis 동영상 튜토리얼
Redis가 동시 액세스에 대처하는 방법
Redis의 동시 처리 솔루션
비즈니스에서는 때때로 Redis를 사용하여 동시성이 높은 일부 비즈니스를 처리합니다. 반짝 세일 사업, 재고 운영 등의 시나리오. . .
먼저 동시성 시나리오에서 어떤 문제가 발생할지 분석해 보겠습니다
동시성 문제는 주로 데이터 수정 시 발생합니다. 클라이언트가 데이터를 수정하는 경우 일반적으로 다음 두 단계로 나뉩니다.
1. 데이터 로컬로 이동하여 로컬로 수정합니다.
2. 클라이언트가 데이터를 수정한 후 다시 Redis에 씁니다.
이 프로세스를 읽기-수정-쓰기 작업(읽기-수정-쓰기, RMW 작업이라고도 함)이라고 부릅니다. 클라이언트가 RMW 작업을 동시에 수행하는 경우 read-modify-write-back이 원자성 작업인지 확인해야 합니다. 명령 작업을 수행할 때 다른 클라이언트가 현재 데이터를 작업할 수 없습니다. 读取-修改-写回操作(Read-Modify-Write,简称为 RMW 操作)。如果客户端并发进行 RMW 操作的时候,就需要保证 读取-修改-写回是一个原子操作,进行命令操作的时候,其他客户端不能对当前的数据进行操作。
错误的栗子:
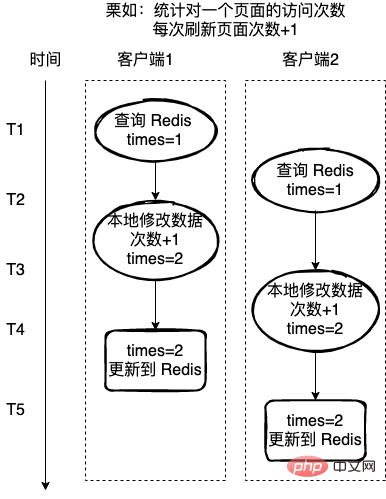
统计一个页面的访问次数,每次刷新页面访问次数+1,这里使用 Redis 来记录访问次数。
如果每次的读取-修改-写回操作不是一个原子操作,那么就可能存在下图的问题,客户端2在客户端1操作的中途,也获取 Redis 的值,也对值进行+1,操作,这样就导致最终数据的错误。
对于上面的这种情况,一般会有两种方式解决:
1、使用 Redis 实现一把分布式锁,通过锁来保护每次只有一个线程来操作临界资源;
2、实现操作命令的原子性。
- 栗如,对于上面的错误栗子,如果
读取-修改-写回잘못된 밤:
페이지 방문 횟수를 계산하고, 페이지가 새로 고쳐질 때마다 방문 횟수가 +1됩니다. 여기서는 방문 횟수를 기록하는 데 Redis가 사용됩니다.
각 read-modify-write-back 작업이 원자적 작업이 아닌 경우 클라이언트 1의 작업 도중에 클라이언트 2도 Redis를 획득하는 경우 아래와 같은 문제가 발생할 수 있습니다. 값에 대해 +1 연산을 수행하므로 최종 데이터에 오류가 발생합니다. 
위 상황의 경우 일반적으로 두 가지가 있습니다. 해결 방법:
1. Redis를 사용하여 분산 잠금을 구현하고 잠금을 사용하여 한 번에 하나의 스레드만 보호하여 중요한 리소스를 작동합니다.
2.
Li Ru, 위의 오류 예에서read-modify-writeback이 원자성 명령인 경우 이 명령은 작업 중에 다른 스레드에서 동시에 읽혀지지 않습니다. 위의 밤의 문제를 피할 수 있습니다. 다음은 원자성과 잠금의 두 가지 측면에서 동시 접근 문제 처리를 자세히 분석한 것입니다.
원자성동시성 제어에 필요한 임계 섹션 코드의 상호 배제를 달성하기 위해 다음을 사용하면 Redis Atomicity의 명령은 다음 두 가지 방법으로 처리할 수 있습니다.
1. Redis에서 원자 단일 명령을 사용합니다.
2. Lua 스크립트에 여러 작업을 작성하고 단일 Lua 스크립트를 원자적으로 실행합니다.
Redis의 원자성을 논할 때 먼저 Redis에서 사용되는 프로그래밍 모델을 논해보자
Redis의 프로그래밍 모델- Reactor 모델은 Redis에서 사용되는 Non-Blocking I/O 모델이다. Unix의 I/O 모델을 살펴보세요.
- Unix의 I/O 모델
- 운영 체제의 I/O는 사용자 공간과 커널 공간 간의 데이터 상호 작용이므로 I/O 작업에는 일반적으로 다음 두 단계가 포함됩니다.
- 1. 네트워크 카드 도착(읽기 준비)/네트워크 카드가 쓰기 가능해질 때까지 대기(쓰기 준비) –> 커널 버퍼에 읽기/쓰기
2. 사용자 공간(읽기) /사용자 공간에서 복사-> 커널 버퍼(쓰기) 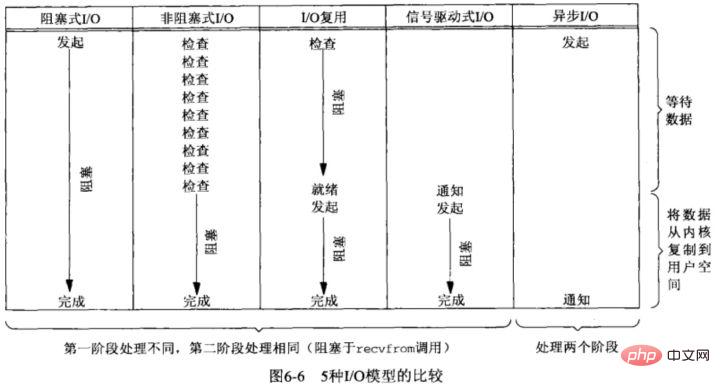
- 신호를 사용하여 I/O를 구동합니다.
 I/O 모델이 동기식인지 비동기식인지 확인하려면 주로 두 번째 단계에 따라 달라집니다. 커널 공간 현재 프로세스를 차단합니까? 그렇다면 동기 I/O이고, 그렇지 않으면 비동기 I/O입니다.
I/O 모델이 동기식인지 비동기식인지 확인하려면 주로 두 번째 단계에 따라 달라집니다. 커널 공간 현재 프로세스를 차단합니까? 그렇다면 동기 I/O이고, 그렇지 않으면 비동기 I/O입니다.
여기서는 주로 다음 세 가지 I/O 모델로 나뉩니다.
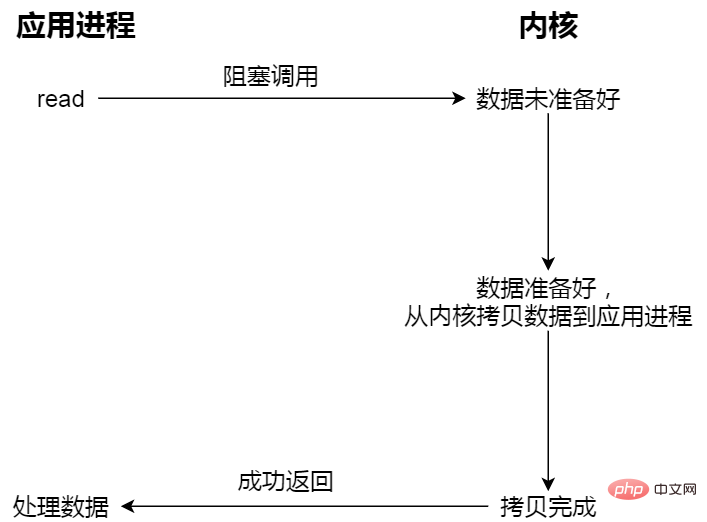
🎜🎜Blocking I/O; 🎜🎜🎜사용자 프로그램이 읽기를 실행하면 커널 데이터가 준비되고 데이터가 커널 버퍼 응용 프로그램의 버퍼에 복사합니다. 복사 프로세스가 완료되면 read가 반환됩니다. 🎜🎜🎜🎜🎜차단과 대기는 "커널 데이터 준비 완료"와 "커널 모드에서 사용자 모드로 데이터 복사"의 두 가지 프로세스입니다. 🎜- 비 차단 동기 I/O;
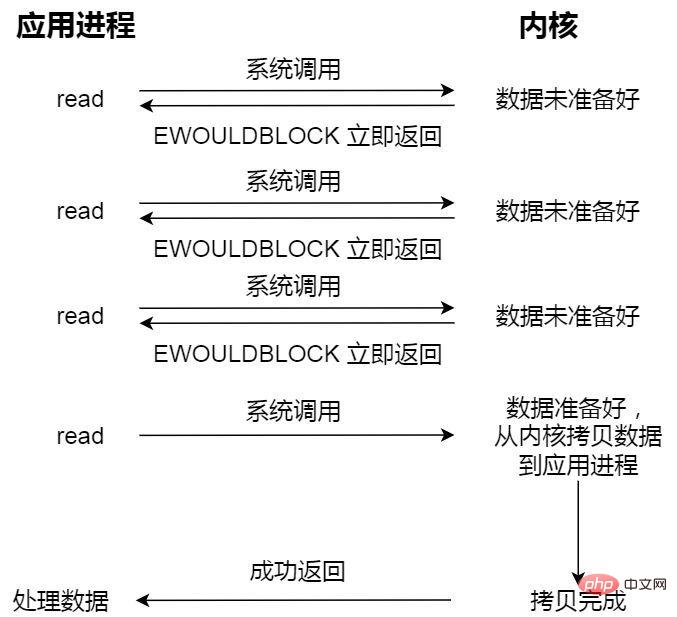
비 차단 읽기 요청은 데이터가 준비되지 않은 경우 즉시 반환되며 계속 실행할 수 있습니다. 이때 애플리케이션은 데이터가 준비될 때까지 커널을 지속적으로 폴링합니다. 커널은 데이터를 애플리케이션 버퍼에 복사하고, read를 호출하여 결과를 얻을 수 있습니다.
여기서 마지막 읽기 호출인 데이터를 얻는 과정은 동기식 과정이자 대기가 필요한 과정입니다. 여기서 동기화란 커널 상태 데이터를 사용자 프로그램의 캐시 영역에 복사하는 과정을 의미합니다.
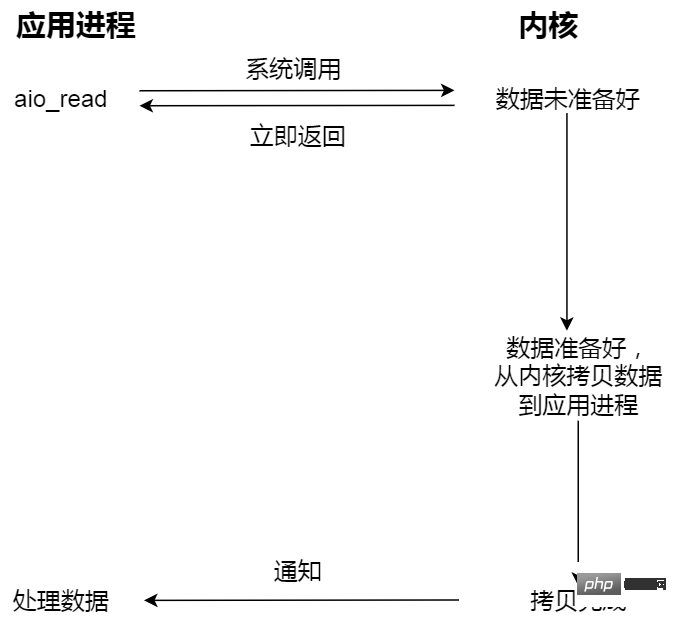
- 비차단 비동기 I/O;
비동기 I/O를 시작하고 즉시 반환합니다. 커널은 자동으로 커널 공간에서 사용자 공간으로 데이터를 복사합니다. 이전과 마찬가지로 동기화 작업과 달리 애플리케이션은 복사 작업을 적극적으로 시작할 필요가 없습니다.
예를 들어 매점에 밥을 먹으러 가면 당신은 애플리케이션과 같고, 매점은 운영체제와 같습니다.
Blocking I/O 예를 들어 매점에 밥을 먹으러 갔는데, 매점의 음식이 아직 준비되지 않은 상태에서 계속 기다리다 보면, 매점에 계신 이모님이 드디어 오십니다. (데이터 준비 과정) 이모가 음식(커널 공간)을 도시락(사용자 공간)에 넣을 때까지 기다려야 합니다.
Non-blocking I/O 예를 들어 매점에 가서 이모에게 음식이 준비되었는지 물었고, 이모가 음식이 준비되었는지 말하여 몇 분 후에 매점으로 왔습니다. 다시 이모님께 물어보니 준비됐다고 하셔서 이모님이 도시락에 음식 담는 걸 도와주십니다.
비동기 I/O 예를 들어 매점 이모에게 요리를 준비하고 도시락에 접시를 담은 다음 도시락을 전달하는 전체 과정을 기다릴 필요가 없습니다.
웹 서비스에는 일반적으로 웹 요청을 처리하는 두 가지 아키텍처가 있습니다. 즉, 스레드 기반 아키텍처(스레드 기반 아키텍처), 이벤트 기반 아키텍처(이벤트- 기반 모델) thread-based architecture(基于线程的架构)、event-driven architecture(事件驱动模型)
thread-based architecture(基于线程的架构)
thread-based architecture(基于线程的架构):这种比较容易理解,就是多线程并发模式,服务端在处理请求的时候,一个请求分配一个独立的线程来处理。
因为每个请求分配一个独立的线程,所以单个线程的阻塞不会影响到其他的线程,能够提高程序的响应速度。
不足的是,连接和线程之间始终保持一对一的关系,如果是一直处于 Keep-Alive 状态的长连接将会导致大量工作线程在空闲状态下等待,例如,文件系统访问,网络等。此外,成百上千的连接还可能会导致并发线程浪费大量内存的堆栈空间。
event-driven architecture(事件驱动模型)
事件驱动的体系结构由事件生产者和事件消费者组,是一种松耦合、分布式的驱动架构,生产者收集到某应用产生的事件后实时对事件采取必要的处理后路由至下游系统,无需等待系统响应,下游的事件消费者组收到是事件消息,异步的处理。
事件驱动架构具有以下优势:
- 降低耦合;
降低事件生产者和订阅者的耦合性。事件生产者只需关注事件的发生,无需关注事件如何处理以及被分发给哪些订阅者。任何一个环节出现故障,不会影响其他业务正常运行。
- 异步执行;
事件驱动架构适用于异步场景,即便是需求高峰期,收集各种来源的事件后保留在事件总线中,然后逐步分发传递事件,不会造成系统拥塞或资源过剩的情况。
- 可扩展性;
事件驱动架构中路由和过滤能力支持划分服务,便于扩展和路由分发。
Reactor 模式和 Proactor 模式都是 event-driven architecture
스레드 기반 아키텍처(스레드 기반 아키텍처)
스레드 기반 아키텍처(스레드 기반 아키텍처): 이는 이해하기 더 쉽습니다. 멀티스레드 동시성 모드이며, 서버가 request , 요청은 처리를 위해 독립 스레드에 할당됩니다. 각 요청에는 독립적인 스레드가 할당되므로 단일 스레드를 차단해도 다른 스레드에 영향을 미치지 않으므로 프로그램의 응답 속도가 향상될 수 있습니다. 단점은 연결과 스레드 사이에 항상 일대일 관계가 있다는 것입니다. 항상 연결 유지 상태에 있는 긴 연결은 다음과 같은 유휴 상태에서 많은 수의 작업자 스레드를 대기하게 합니다. 파일 시스템 액세스, 네트워크 등. 또한 수백 또는 수천 개의 연결로 인해 동시 스레드가 많은 양의 메모리 스택 공간을 낭비할 수 있습니다.- 이벤트 중심 아키텍처(이벤트 중심 모델)
- 이벤트 중심 아키텍처는 이벤트 생산자와 이벤트 소비자 그룹으로 구성됩니다. 이는 느슨하게 결합되고 분산된 드라이버 아키텍처입니다. 이벤트가 발생한 후에는 해당 이벤트에 대해 실시간으로 필요한 처리가 수행된 후 시스템 응답을 기다리지 않고 다운스트림 이벤트 소비자 그룹이 이벤트 메시지를 수신하여 비동기적으로 처리합니다.
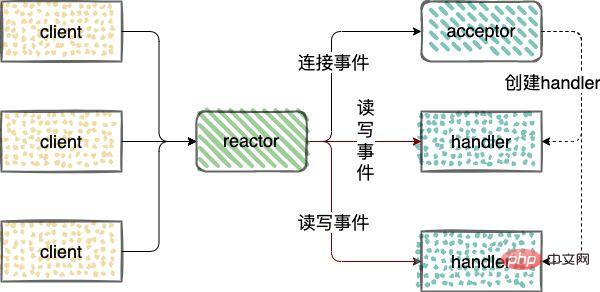
이벤트 중심 아키텍처(이벤트 중심 모델)의 구현 방법입니다. 🎜🎜🎜Reactor 모드🎜🎜🎜Reactor 모드에 대한 자세한 분석은 다음과 같습니다. 입력이 서비스 프로세서에 동시에 전달되는 서비스 요청에 대한 이벤트 기반 처리 모델입니다. 🎜🎜네트워크 IO 연결 이벤트를 처리하고, 이벤트를 읽고, 이벤트를 씁니다. Reactor🎜🎜🎜Reactor에는 세 가지 유형의 역할이 도입되었습니다. 이벤트를 모니터링 및 배포하고, 이벤트를 Acceptor에 연결하고, 이벤트를 읽고 핸들러에 씁니다. 🎜🎜acceptor: 연결 요청을 받고, 연결을 받은 후 처리할 핸들러가 생성됩니다. 네트워크 연결은 후속 읽기 및 쓰기 이벤트를 처리합니다. 🎜🎜핸들러: 읽기 및 쓰기 이벤트를 처리합니다. 🎜🎜🎜🎜🎜🎜Reactor 모델은 3가지 범주로 나뉩니다. 🎜- 단일 스레드 Reactor 모드;
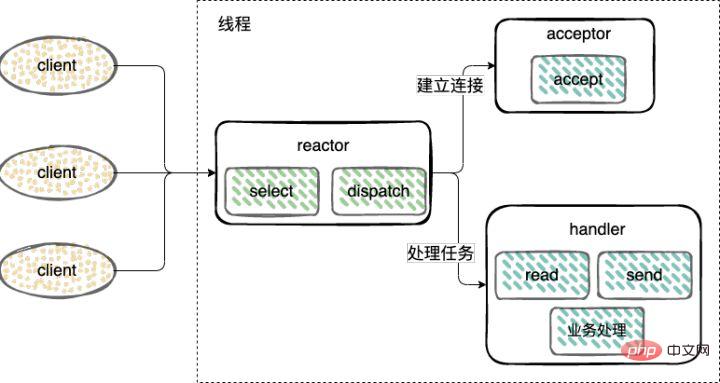
연결 설정(Acceptor), 이벤트 수락, 읽기, 쓰기(Reactor) 및 이벤트 처리(Handler)는 모두 단일 스레드만 사용합니다.
싱글 스레드 모드와 다르게 작업자 스레드 풀이 추가되고 I/O 이외의 작업이 Reactor 스레드에서 제거되어 작업자 스레드로 전송됩니다. pool(Thread Pool))을 실행합니다. 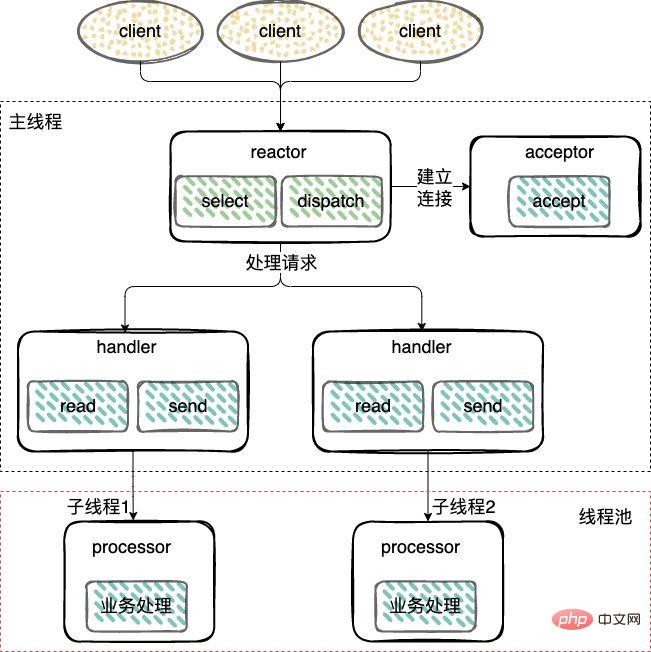
I/O 操作从 Reactor 线程中移出转交给工作者线程池(Thread Pool)来执行。
建立连接(Acceptor)和 监听accept、read、write事件(Reactor),复用一个线程。
工作线程池:处理事件(Handler),由一个工作线程池来执行业务逻辑,包括数据就绪后,用户态的数据读写。
- 主从 Reactor 模式;
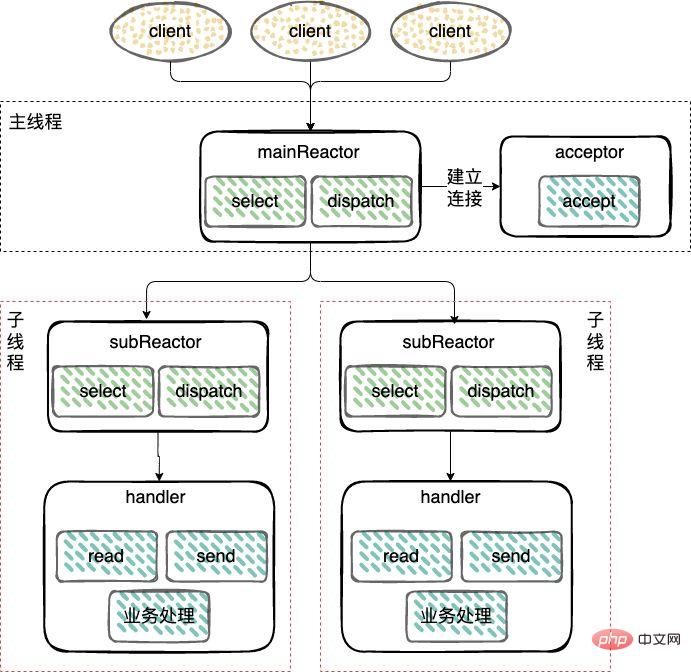
对于多个CPU的机器,为充分利用系统资源,将 Reactor 拆分为两部分:mainReactor 和 subReactor。
mainReactor:负责监听server socket,用来处理网络新连接的建立,将建立的socketChannel指定注册给subReactor,通常一个线程就可以处理;
subReactor:监听accept、read、write事件(Reactor),包括等待数据就绪时,内核态的数据读写,通常使用多线程。
工作线程:处理事件(Handler)可以和 subReactor 共同使用同一个线程,也可以做成线程池,类似上面多线程 Reactor 模式下的工作线程池的处理方式。
Proactor 模式
reactor 流程与 Reactor 模式类似
不同点就是
- Reactor 是非阻塞同步网络模式,感知的是就绪可读写事件。
在每次感知到有事件发生(比如可读就绪事件)后,就需要应用进程主动调用 read 方法来完成数据的读取,也就是要应用进程主动将 socket 接收缓存中的数据读到应用进程内存中,这个过程是同步的,读取完数据后应用进程才能处理数据。
- Proactor 是异步网络模式,感知的是已完成的读写事件。
在发起异步读写请求时,需要传入数据缓冲区的地址(用来存放结果数据)等信息,这样系统内核才可以自动帮我们把数据的读写工作完成,这里的读写工作全程由操作系统来做,并不需要像 Reactor 那样还需要应用进程主动发起 read/write 来读写数据,操作系统完成读写工作后,就会通知应用进程直接处理数据。
因此,Reactor 可以理解为「来了事件操作系统通知应用进程,让应用进程来处理」,而 Proactor 可以理解为「来了事件操作系统来处理,处理完再通知应用进程」。
举个实际生活中的例子,Reactor 模式就是快递员在楼下,给你打电话告诉你快递到你家小区了,你需要自己下楼来拿快递。而在 Proactor 模式下,快递员直接将快递送到你家门口,然后通知你。
为什么 Redis 选择单线程
Redis 中使用是单线程,可能处于以下几方面的考虑
1、Redis 是纯内存的操作,执行速度是非常快的,因此这部分操作通常不会是性能瓶颈,性能瓶颈在于网络 I/O;
2、避免过多的上下文切换开销,单线程则可以规避进程内频繁的线程切换开销;
3、避免同步机制的开销,多线程必然会面临对于共享资源的访问,这时候通常的做法就是加锁,虽然是多线程,这时候就会变成串行的访问。也就是多线程编程模式会面临的共享资源的并发访问控制问题;
4、简单可维护,多线程也会引入同步原语来保护共享资源的并发访问,代码的可维护性和易读性将会下降。
Redis 在 v6.0 版本之前,Redis 的核心网络模型一直是一个典型的单 Reactor 模型:利用 epoll/select/kqueue작업자 스레드 풀: 이벤트 처리(Handler), 작업자 스레드 풀은 데이터가 준비된 후 사용자 모드 데이터 읽기 및 쓰기를 포함한 비즈니스 로직을 실행합니다.
다중 CPU가 있는 기계의 경우 시스템 리소스를 최대한 활용하기 위해 Reactor는 mainReactor와 subReactor의 두 부분으로 나뉩니다.
mainReactor: 새로운 네트워크 연결 설정을 처리하고 설정된 소켓 채널을 subReactor에 등록하는 데 사용되는서버 소켓 모니터링을 담당합니다. 일반적으로 하나의 스레드가 이를 처리할 수 있습니다. subReactor: 모니터링 일반적으로 멀티스레딩을 사용하여 데이터가 준비될 때까지 커널 모드에서 데이터 읽기 및 쓰기를 포함하여 , 읽기, 쓰기 이벤트(Reactor)를 허용합니다. Worker 스레드: 이벤트 처리(Handler)는 subReactor와 동일한 스레드를 사용하거나 위의 멀티 스레드 Reactor 모드에서 작업자 스레드 풀의 처리 방법과 유사하게 스레드 풀로 만들 수 있습니다. 🎜🎜🎜프로액터 모드🎜🎜🎜리액터 프로세스는 리액터 모드와 유사합니다🎜🎜차이점은 🎜🎜🎜Reactor는 비차단 동기 네트워크 모드이며 준비된 읽기 및 쓰기 이벤트를 감지한다는 것입니다. 🎜🎜🎜이벤트(예: 읽기 가능 준비 이벤트)가 감지될 때마다 애플리케이션 프로세스는 읽기 메서드를 적극적으로 호출하여 데이터 읽기를 완료해야 합니다. 즉, 애플리케이션 프로세스는 소켓 수신에서 데이터를 적극적으로 읽어야 합니다. 캐시 애플리케이션 프로세스의 메모리에서 이 프로세스는 동기식이며 애플리케이션 프로세스는 데이터를 읽은 후에만 데이터를 처리할 수 있습니다. 🎜🎜🎜Proactor는 완료된 읽기 및 쓰기 이벤트를 감지하는 비동기 네트워크 모드입니다. 🎜🎜🎜비동기 읽기 및 쓰기 요청을 시작할 때 데이터 버퍼의 주소(결과 데이터를 저장하는 데 사용됨) 및 기타 정보를 전달해야 시스템 커널이 자동으로 읽기 및 쓰기를 완료하는 데 도움을 줄 수 있습니다. 여기에서 데이터 읽기 및 쓰기 작업은 운영 체제에 의해 수행됩니다. 운영 체제 이후에 데이터를 읽고 쓰기 위해 애플리케이션 프로세스가 적극적으로 read/write를 시작할 필요는 없습니다. 읽기 및 쓰기 작업이 완료되면 애플리케이션 프로세스에 데이터를 직접 처리하도록 알립니다. 🎜🎜따라서 Reactor는 "이벤트가 오면 운영 체제가 응용 프로그램 프로세스에 알리고 응용 프로그램 프로세스가 이를 처리하도록 합니다"로 이해하고, Proactor는 "이벤트가 오면 운영 체제가 이벤트를 처리하고, 처리 후 신청 절차에 통보합니다." 🎜🎜실생활에서 예를 들자면, 리액터 모델은 택배가 아래층에 있다는 의미이며, 택배가 커뮤니티에 도착했음을 알리기 위해 전화를 걸어 택배를 직접 픽업해야 합니다. Proactor 모드에서는 택배사가 패키지를 집까지 직접 배달한 후 알려드립니다. 🎜🎜🎜Redis가 단일 스레드를 선택하는 이유🎜🎜🎜Redis에서 단일 스레드를 사용하는 이유는 다음과 같습니다.🎜🎜1. Redis는 순수 메모리 작업이고 실행 속도가 매우 빠르기 때문에 일반적으로 이 부분의 작업이 수행됩니다. 그렇지 않습니다. 성능 병목 현상은 네트워크 I/O에 있습니다. 🎜🎜2. 과도한 컨텍스트 전환 오버헤드를 방지합니다. 단일 스레딩은 프로세스 내에서 빈번한 스레드 전환 오버헤드를 방지할 수 있습니다. 메커니즘에서는 멀티스레딩이 불가피합니다. 공유 리소스에 액세스할 때 일반적인 접근 방식은 잠금입니다. 멀티스레딩이지만 이때는 직렬 액세스가 됩니다. 즉, 멀티스레드 프로그래밍 모드가 직면하게 될 공유 리소스의 동시 액세스 제어 문제는 간단하고 유지 관리가 용이합니다. 읽을 수 있습니다. 🎜🎜Redis 버전 v6.0 이전에 Redis의 핵심 네트워크 모델은 항상 전형적인 단일 Reactor 모델이었습니다. 단일 스레드 이벤트 루프에서 epoll/select/kqueue와 같은 멀티플렉싱 기술을 사용하여 지속적으로 이벤트(클라이언트 요청)를 처리하고 마지막으로 클라이언트에 응답 데이터를 다시 작성합니다. 🎜🎜Redis가 단일 스레드를 사용하여 작업을 처리하는 방법을 살펴보겠습니다.🎜🎜🎜🎜🎜🎜이벤트 기반 프레임워크가 이벤트를 캡처하고 배포합니다🎜🎜 🎜 Redis의 네트워크 프레임워크는 Reactor 모델을 구현하고 자체적으로 이벤트 중심 프레임워크를 개발 및 구현합니다. 🎜🎜이벤트 중심 프레임워크의 논리는 간단합니다. 🎜- 이벤트 초기화;
- 이벤트 캡처; 배포 및 메인 루프 처리.
 Redis의 이벤트 중심 프레임워크로 구현된 몇 가지 주요 기능을 살펴보겠습니다.
Redis의 이벤트 중심 프레임워크로 구현된 몇 가지 주요 기능을 살펴보겠습니다.
// 执行事件捕获,分发和处理循环 void aeMain(aeEventLoop *eventLoop); // 用来注册监听的事件和事件对应的处理函数。只有对事件和处理函数进行了注册,才能在事件发生时调用相应的函数进行处理。 int aeCreateFileEvent(aeEventLoop *eventLoop, int fd, int mask, aeFileProc *proc, void *clientData); // aeProcessEvents 函数实现的主要功能,包括捕获事件、判断事件类型和调用具体的事件处理函数,从而实现事件的处理 int aeProcessEvents(aeEventLoop *eventLoop, int flags);
aeMain을 메인 루프로 사용하여 이벤트를 지속적으로 모니터링하고 캡처합니다. 여기서 aeProcessEvents 함수는 이벤트를 구현하기 위해 호출됩니다. 이벤트 유형을 캡처 및 결정하고 특정 이벤트 처리 함수를 호출하여 이벤트 처리를 구현합니다.
// https://github.com/redis/redis/blob/5.0/src/ae.c#L496
void aeMain(aeEventLoop *eventLoop) {
eventLoop->stop = 0;
while (!eventLoop->stop) {
if (eventLoop->beforesleep != NULL)
eventLoop->beforesleep(eventLoop);
aeProcessEvents(eventLoop, AE_ALL_EVENTS|AE_CALL_AFTER_SLEEP);
}
}
// https://github.com/redis/redis/blob/5.0/src/ae.c#L358
int aeProcessEvents(aeEventLoop *eventLoop, int flags)
{
...
if (eventLoop->maxfd != -1 || ((flags & AE_TIME_EVENTS) && !(flags & AE_DONT_WAIT))) {
...
//调用aeApiPoll函数捕获事件
numevents = aeApiPoll(eventLoop, tvp);
...
}
...
}aeApiPoll을 호출하면 aeProcessEvents의 IO 이벤트 캡처가 완료된 것을 확인할 수 있습니다.
aeApiPoll은 epoll_wait/select/kevent와 같은 시스템 호출의 캡슐화를 기반으로 하는 I/O 다중화 API입니다. 이는 읽기 및 쓰기 이벤트가 트리거될 때까지 대기합니다. 이를 처리하는 것이 이벤트 루프(Event Loop)이며 이벤트 기반 작업의 기초입니다.
Redis는 기본 운영 체제에서 제공하는 IO 멀티플렉싱 메커니즘을 사용하여 이벤트 캡처를 구현하고 새로운 연결, 읽기 및 쓰기 이벤트가 발생하는지 확인합니다. 다양한 운영 체제에 적응하기 위해 Redis는 다양한 운영 체제에서 구현되는 네트워크 IO 다중화 기능을 균일하게 캡슐화합니다. epoll_wait/select/kevent 等系统调用的封装,监听等待读写事件触发,然后处理,它是事件循环(Event Loop)中的核心函数,是事件驱动得以运行的基础。
Redis 是依赖于操作系统底层提供的 IO 多路复用机制,来实现事件捕获,检查是否有新的连接、读写事件发生。为了适配不同的操作系统,Redis 对不同操作系统实现的网络 IO 多路复用函数,都进行了统一的封装。
// https://github.com/redis/redis/blob/5.0/src/ae.c#L49 #ifdef HAVE_EVPORT #include "ae_evport.c" // Solaris #else #ifdef HAVE_EPOLL #include "ae_epoll.c" // Linux #else #ifdef HAVE_KQUEUE #include "ae_kqueue.c" // MacOS #else #include "ae_select.c" // Windows #endif #endif #endif
ae_epoll.c:对应 Linux 上的 IO 复用函数 epoll;
ae_evport.c:对应 Solaris 上的 IO 复用函数 evport;
ae_kqueue.c:对应 macOS 或 FreeBSD 上的 IO 复用函数 kqueue;
ae_select.c:对应 Linux(或 Windows)的 IO 复用函数 select。
客户端连接应答
监听 socket 的读事件,当有客户端连接请求过来,使用函数 acceptTcpHandler 和客户端建立连接
当 Redis 启动后,服务器程序的 main 函数会调用 initSever 函数来进行初始化,而在初始化的过程中,aeCreateFileEvent 就会被 initServer 函数调用,用于注册要监听的事件,以及相应的事件处理函数。
// https://github.com/redis/redis/blob/5.0/src/server.c#L2036
void initServer(void) {
...
// 创建一个事件处理程序以接受 TCP 和 Unix 中的新连接
for (j = 0; j < server.ipfd_count; j++) {
if (aeCreateFileEvent(server.el, server.ipfd[j], AE_READABLE,
acceptTcpHandler,NULL) == AE_ERR)
{
serverPanic(
"Unrecoverable error creating server.ipfd file event.");
}
}
...
}可以看到 initServer 中会根据启用的 IP 端口个数,为每个 IP 端口上的网络事件,调用 aeCreateFileEvent,创建对 AE_READABLE 事件的监听,并且注册 AE_READABLE 事件的处理 handler,也就是 acceptTcpHandler 函数。
然后看下 acceptTcpHandler 的实现
// https://github.com/redis/redis/blob/5.0/src/networking.c#L734
void acceptTcpHandler(aeEventLoop *el, int fd, void *privdata, int mask) {
int cport, cfd, max = MAX_ACCEPTS_PER_CALL;
char cip[NET_IP_STR_LEN];
UNUSED(el);
UNUSED(mask);
UNUSED(privdata);
while(max--) {
// 用于accept客户端的连接,其返回值是客户端对应的socket
cfd = anetTcpAccept(server.neterr, fd, cip, sizeof(cip), &cport);
if (cfd == ANET_ERR) {
if (errno != EWOULDBLOCK)
serverLog(LL_WARNING,
"Accepting client connection: %s", server.neterr);
return;
}
serverLog(LL_VERBOSE,"Accepted %s:%d", cip, cport);
// 会调用acceptCommonHandler对连接以及客户端进行初始化
acceptCommonHandler(cfd,0,cip);
}
}
// https://github.com/redis/redis/blob/5.0/src/networking.c#L664
static void acceptCommonHandler(int fd, int flags, char *ip) {
client *c;
// 分配并初始化新客户端
if ((c = createClient(fd)) == NULL) {
serverLog(LL_WARNING,
"Error registering fd event for the new client: %s (fd=%d)",
strerror(errno),fd);
close(fd); /* May be already closed, just ignore errors */
return;
}
// 判断当前连接的客户端是否超过最大值,如果超过的话,会拒绝这次连接。否则,更新客户端连接数的计数
if (listLength(server.clients) > server.maxclients) {
char *err = "-ERR max number of clients reached\r\n";
/* That's a best effort error message, don't check write errors */
if (write(c->fd,err,strlen(err)) == -1) {
/* Nothing to do, Just to avoid the warning... */
}
server.stat_rejected_conn++;
freeClient(c);
return;
}
...
}
// 使用多路复用,需要记录每个客户端的状态,client 之前通过链表保存
typedef struct client {
int fd; // 字段是客户端套接字文件描述符
sds querybuf; // 保存客户端发来命令请求的输入缓冲区。以Redis通信协议的方式保存
int argc; // 当前命令的参数数量
robj **argv; // 当前命令的参数
redisDb *db; // 当前选择的数据库指针
int flags;
list *reply; // 保存命令回复的链表。因为静态缓冲区大小固定,主要保存固定长度的命令回复,当处理一些返回大量回复的命令,则会将命令回复以链表的形式连接起来。
// ... many other fields ...
char buf[PROTO_REPLY_CHUNK_BYTES];
} client;
client *createClient(int fd) {
client *c = zmalloc(sizeof(client));
// 如果fd为-1,表示创建的是一个无网络连接的伪客户端,用于执行lua脚本的时候。
// 如果fd不等于-1,表示创建一个有网络连接的客户端
if (fd != -1) {
// 设置fd为非阻塞模式
anetNonBlock(NULL,fd);
// 禁止使用 Nagle 算法,client向内核递交的每个数据包都会立即发送给server出去,TCP_NODELAY
anetEnableTcpNoDelay(NULL,fd);
// 如果开启了tcpkeepalive,则设置 SO_KEEPALIVE
if (server.tcpkeepalive)
anetKeepAlive(NULL,fd,server.tcpkeepalive);
// 创建一个文件事件状态el,且监听读事件,开始接受命令的输入
if (aeCreateFileEvent(server.el,fd,AE_READABLE,
readQueryFromClient, c) == AE_ERR)
{
close(fd);
zfree(c);
return NULL;
}
}
...
// 初始化client 中的参数
return c;
}1、acceptTcpHandler 主要用于处理和客户端连接的建立;
2、其中会调用函数 anetTcpAccept 用于 accept 客户端的连接,其返回值是客户端对应的 socket;
3、然后调用 acceptCommonHandler 对连接以及客户端进行初始化;
4、初始化客户端的时候,同时使用 aeCreateFileEvent 用来注册监听的事件和事件对应的处理函数,将 readQueryFromClient 命令读取处理器绑定到新连接对应的文件描述符上;
5、服务器会监听该文件描述符的读事件,当客户端发送了命令,触发了 AE_READABLE 事件,那么就会调用回调函数 readQueryFromClient() 来从文件描述符 fd 中读发来的命令,并保存在输入缓冲区中 querybuf。
命令的接收
readQueryFromClient 是请求处理的起点,解析并执行客户端的请求命令。
// https://github.com/redis/redis/blob/5.0/src/networking.c#L1522
// 读取client的输入缓冲区的内容
void readQueryFromClient(aeEventLoop *el, int fd, void *privdata, int mask) {
client *c = (client*) privdata;
int nread, readlen;
size_t qblen;
UNUSED(el);
UNUSED(mask);
...
// 输入缓冲区的长度
qblen = sdslen(c->querybuf);
// 更新缓冲区的峰值
if (c->querybuf_peak < qblen) c->querybuf_peak = qblen;
// 扩展缓冲区的大小
c->querybuf = sdsMakeRoomFor(c->querybuf, readlen);
// 调用read从描述符为fd的客户端socket中读取数据
nread = read(fd, c->querybuf+qblen, readlen);
...
// 处理读取的内容
processInputBufferAndReplicate(c);
}
// https://github.com/redis/redis/blob/5.0/src/networking.c#L1507
void processInputBufferAndReplicate(client *c) {
// 当前客户端不属于主从复制中的Master
// 直接调用 processInputBuffer,对客户端输入缓冲区中的命令和参数进行解析
if (!(c->flags & CLIENT_MASTER)) {
processInputBuffer(c);
// 客户端属于主从复制中的Master
// 调用processInputBuffer函数,解析客户端命令,
// 调用replicationFeedSlavesFromMasterStream 函数,将主节点接收到的命令同步给从节点
} else {
size_t prev_offset = c->reploff;
processInputBuffer(c);
size_t applied = c->reploff - prev_offset;
if (applied) {
replicationFeedSlavesFromMasterStream(server.slaves,
c->pending_querybuf, applied);
sdsrange(c->pending_querybuf,applied,-1);
}
}
}
// https://github.com/redis/redis/blob/5.0/src/networking.c#L1428
void processInputBuffer(client *c) {
server.current_client = c;
/* Keep processing while there is something in the input buffer */
// 持续读取缓冲区的内容
while(c->qb_pos < sdslen(c->querybuf)) {
...
/* Multibulk processing could see a <= 0 length. */
// 如果参数为0,则重置client
if (c->argc == 0) {
resetClient(c);
} else {
/* Only reset the client when the command was executed. */
// 执行命令成功后重置client
if (processCommand(c) == C_OK) {
if (c->flags & CLIENT_MASTER && !(c->flags & CLIENT_MULTI)) {
/* Update the applied replication offset of our master. */
c->reploff = c->read_reploff - sdslen(c->querybuf) + c->qb_pos;
}
// 命令处于阻塞状态中的客户端,不需要进行重置
if (!(c->flags & CLIENT_BLOCKED) || c->btype != BLOCKED_MODULE)
resetClient(c);
}
/* freeMemoryIfNeeded may flush slave output buffers. This may
* result into a slave, that may be the active client, to be
* freed. */
if (server.current_client == NULL) break;
}
}
/* Trim to pos */
if (server.current_client != NULL && c->qb_pos) {
sdsrange(c->querybuf,c->qb_pos,-1);
c->qb_pos = 0;
}
server.current_client = NULL;
}1、readQueryFromClient(),从文件描述符 fd 中读出数据到输入缓冲区 querybuf 中;
2、使用 processInputBuffer 函数完成对命令的解析,在其中使用 processInlineBuffer 或者 processMultibulkBuffer 根据 Redis 协议解析命令;
3、完成对一个命令的解析,就使用 processCommand 对命令就行执行;
4、命令执行完成,最后调用 addReply 函数族的一系列函数将响应数据写入到对应 client 的写出缓冲区:client->buf 或者 client->reply ,client->buf 是首选的写出缓冲区,固定大小 16KB,一般来说可以缓冲足够多的响应数据,但是如果客户端在时间窗口内需要响应的数据非常大,那么则会自动切换到 client->reply 链表上去,使用链表理论上能够保存无限大的数据(受限于机器的物理内存),最后把 client 添加进一个 LIFO 队列 clients_pending_write;
命令的回复
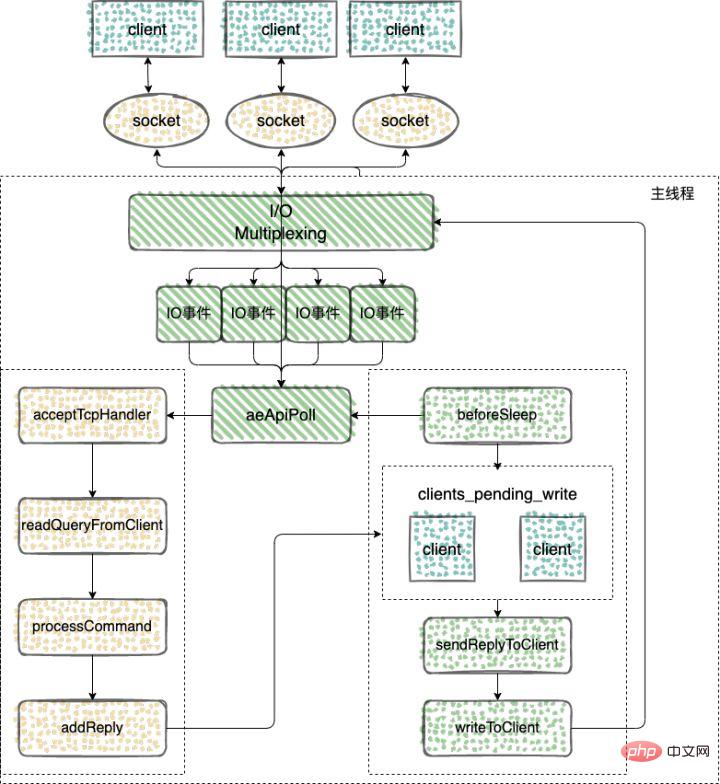
在 Redis 事件驱动框架每次循环进入事件处理函数前,来处理监听到的已触发事件或是到时的时间事件之前,都会调用 beforeSleep 函数,进行一些任务处理,这其中就包括了调用 handleClientsWithPendingWrites 函数,它会将 Redis sever
// https://github.com/redis/redis/blob/5.0/src/server.c#L1380
void beforeSleep(struct aeEventLoop *eventLoop) {
UNUSED(eventLoop);
...
// 将 Redis sever 客户端缓冲区中的数据写回客户端
handleClientsWithPendingWrites();
...
}
// https://github.com/redis/redis/blob/5.0/src/networking.c#L1082
int handleClientsWithPendingWrites(void) {
listIter li;
listNode *ln;
// 遍历 clients_pending_write 队列,调用 writeToClient 把 client 的写出缓冲区里的数据回写到客户端
int processed = listLength(server.clients_pending_write);
listRewind(server.clients_pending_write,&li);
while((ln = listNext(&li))) {
client *c = listNodeValue(ln);
c->flags &= ~CLIENT_PENDING_WRITE;
listDelNode(server.clients_pending_write,ln);
...
// 调用 writeToClient 函数,将客户端输出缓冲区中的数据写回
if (writeToClient(c->fd,c,0) == C_ERR) continue;
// 如果输出缓冲区的数据还没有写完,此时,handleClientsWithPendingWrites 函数就
// 会调用 aeCreateFileEvent 函数,创建可写事件,并设置回调函数 sendReplyToClien
if (clientHasPendingReplies(c)) {
int ae_flags = AE_WRITABLE;
if (server.aof_state == AOF_ON &&
server.aof_fsync == AOF_FSYNC_ALWAYS)
{
ae_flags |= AE_BARRIER;
}
// 将文件描述符fd和AE_WRITABLE事件关联起来,当客户端可写时,就会触发事件,调用sendReplyToClient()函数,执行写事件
if (aeCreateFileEvent(server.el, c->fd, ae_flags,
sendReplyToClient, c) == AE_ERR)
{
freeClientAsync(c);
}
}
}
return processed;
}
// https://github.com/redis/redis/blob/5.0/src/networking.c#L1072
// 写事件处理程序,只是发送回复给client
void sendReplyToClient(aeEventLoop *el, int fd, void *privdata, int mask) {
UNUSED(el);
UNUSED(mask);
writeToClient(fd,privdata,1);
}
// https://github.com/redis/redis/blob/5.0/src/networking.c#L979
// 将输出缓冲区的数据写给client,如果client被释放则返回C_ERR,没被释放则返回C_OK
int writeToClient(int fd, client *c, int handler_installed) {
ssize_t nwritten = 0, totwritten = 0;
size_t objlen;
clientReplyBlock *o;
// 如果指定的client的回复缓冲区中还有数据,则返回真,表示可以写socket
while(clientHasPendingReplies(c)) {
// 固定缓冲区发送未完成
if (c->bufpos > 0) {
// 将缓冲区的数据写到fd中
nwritten = write(fd,c->buf+c->sentlen,c->bufpos-c->sentlen);
...
// 如果发送的数据等于buf的偏移量,表示发送完成
if ((int)c->sentlen == c->bufpos) {
c->bufpos = 0;
c->sentlen = 0;
}
// 固定缓冲区发送完成,发送回复链表的内容
} else {
// 回复链表的第一条回复对象,和对象值的长度和所占的内存
o = listNodeValue(listFirst(c->reply));
objlen = o->used;
if (objlen == 0) {
c->reply_bytes -= o->size;
listDelNode(c->reply,listFirst(c->reply));
continue;
}
// 将当前节点的值写到fd中
nwritten = write(fd, o->buf + c->sentlen, objlen - c->sentlen);
if (nwritten <= 0) break;
c->sentlen += nwritten;
totwritten += nwritten;
...
}
...
}
...
// 如果指定的client的回复缓冲区中已经没有数据,发送完成
if (!clientHasPendingReplies(c)) {
c->sentlen = 0;
// 删除当前client的可读事件的监听
if (handler_installed) aeDeleteFileEvent(server.el,c->fd,AE_WRITABLE);
/* Close connection after entire reply has been sent. */
// 如果指定了写入按成之后立即关闭的标志,则释放client
if (c->flags & CLIENT_CLOSE_AFTER_REPLY) {
freeClient(c);
return C_ERR;
}
}
return C_OK;
}클라이언트 연결 응답
🎜소켓의 읽기 이벤트를 수신합니다. 클라이언트 연결 요청이 오면 acceptTcpHandler 함수를 사용하여 클라이언트와 연결을 설정합니다.🎜🎜Redis 서버가 시작되면 프로그램의 기본 기능은 초기화를 위해 initSever 함수를 호출합니다. 초기화 프로세스 중에 initServer 함수에 의해 aeCreateFileEvent가 호출되어 모니터링할 이벤트와 해당 이벤트 처리 기능을 등록합니다. 🎜// https://github.com/redis/redis/blob/6.2/src/networking.c#L3573
void initThreadedIO(void) {
server.io_threads_active = 0; /* We start with threads not active. */
/* Don't spawn any thread if the user selected a single thread:
* we'll handle I/O directly from the main thread. */
// 如果用户只配置了一个 I/O 线程,不需要创建新线程了,直接在主线程中处理
if (server.io_threads_num == 1) return;
if (server.io_threads_num > IO_THREADS_MAX_NUM) {
serverLog(LL_WARNING,"Fatal: too many I/O threads configured. "
"The maximum number is %d.", IO_THREADS_MAX_NUM);
exit(1);
}
/* Spawn and initialize the I/O threads. */
// 初始化线程
for (int i = 0; i < server.io_threads_num; i++) {
/* Things we do for all the threads including the main thread. */
io_threads_list[i] = listCreate();
// 编号为0是主线程
if (i == 0) continue; /* Thread 0 is the main thread. */
/* Things we do only for the additional threads. */
pthread_t tid;
// 初始化io_threads_mutex数组
pthread_mutex_init(&io_threads_mutex[i],NULL);
// 初始化io_threads_pending数组
setIOPendingCount(i, 0);
// 主线程在启动 I/O 线程的时候会默认先锁住它,直到有 I/O 任务才唤醒它。
pthread_mutex_lock(&io_threads_mutex[i]); /* Thread will be stopped. */
// 调用pthread_create函数创建IO线程,线程运行函数为IOThreadMain
if (pthread_create(&tid,NULL,IOThreadMain,(void*)(long)i) != 0) {
serverLog(LL_WARNING,"Fatal: Can't initialize IO thread.");
exit(1);
}
io_threads[i] = tid;
}
}// https://github.com/redis/redis/blob/6.2/src/networking.c#L2219
void readQueryFromClient(connection *conn) {
client *c = connGetPrivateData(conn);
int nread, readlen;
size_t qblen;
/* Check if we want to read from the client later when exiting from
* the event loop. This is the case if threaded I/O is enabled. */
// 判断是否从客户端延迟读取数据
if (postponeClientRead(c)) return;
...
}
// https://github.com/redis/redis/blob/6.2/src/networking.c#L3746
int postponeClientRead(client *c) {
// 当多线程 I/O 模式开启、主线程没有在处理阻塞任务时,将 client 加入异步队列。
if (server.io_threads_active &&
server.io_threads_do_reads &&
!ProcessingEventsWhileBlocked &&
!(c->flags & (CLIENT_MASTER|CLIENT_SLAVE|CLIENT_PENDING_READ|CLIENT_BLOCKED)))
{
// 给客户端的flag添加CLIENT_PENDING_READ标记,表示推迟该客户端的读操作
c->flags |= CLIENT_PENDING_READ;
// 将可获得加入clients_pending_write列表
listAddNodeHead(server.clients_pending_read,c);
return 1;
} else {
return 0;
}
}명령 수신
🎜readQueryFromClient는 요청 처리, 클라이언트의 요청 명령 구문 분석 및 실행의 시작점입니다. 🎜// https://github.com/redis/redis/blob/6.2/src/networking.c#L3766
int handleClientsWithPendingReadsUsingThreads(void) {
// 当多线程 I/O 模式开启,才能执行下面的流程
if (!server.io_threads_active || !server.io_threads_do_reads) return 0;
int processed = listLength(server.clients_pending_read);
if (processed == 0) return 0;
// 遍历待读取的 client 队列 clients_pending_read,
// 根据IO线程的数量,让clients_pending_read中客户端数量对IO线程进行取模运算
// 取模的结果就是客户端分配给对应IO线程的编号
listIter li;
listNode *ln;
listRewind(server.clients_pending_read,&li);
int item_id = 0;
while((ln = listNext(&li))) {
client *c = listNodeValue(ln);
int target_id = item_id % server.io_threads_num;
listAddNodeTail(io_threads_list[target_id],c);
item_id++;
}
// 设置当前 I/O 操作为读取操作,给每个 I/O 线程的计数器设置分配的任务数量,
// 让 I/O 线程可以开始工作:只读取和解析命令,不执行
io_threads_op = IO_THREADS_OP_READ;
for (int j = 1; j < server.io_threads_num; j++) {
int count = listLength(io_threads_list[j]);
setIOPendingCount(j, count);
}
// 主线程自己也会去执行读取客户端请求命令的任务,以达到最大限度利用 CPU。
listRewind(io_threads_list[0],&li);
while((ln = listNext(&li))) {
client *c = listNodeValue(ln);
readQueryFromClient(c->conn);
}
listEmpty(io_threads_list[0]);
// 忙轮询,等待所有 IO 线程完成待读客户端的处理
while(1) {
unsigned long pending = 0;
for (int j = 1; j < server.io_threads_num; j++)
pending += getIOPendingCount(j);
if (pending == 0) break;
}
// 遍历待读取的 client 队列,清除 CLIENT_PENDING_READ标记,
// 然后解析并执行所有 client 的命令。
while(listLength(server.clients_pending_read)) {
ln = listFirst(server.clients_pending_read);
client *c = listNodeValue(ln);
c->flags &= ~CLIENT_PENDING_READ;
listDelNode(server.clients_pending_read,ln);
serverAssert(!(c->flags & CLIENT_BLOCKED));
// client 的第一条命令已经被解析好了,直接尝试执行。
if (processPendingCommandsAndResetClient(c) == C_ERR) {
/* If the client is no longer valid, we avoid
* processing the client later. So we just go
* to the next. */
continue;
}
// 解析并执行 client 命令
processInputBuffer(c);
// 命令执行完成之后,如果 client 中有响应数据需要回写到客户端,则将 client 加入到待写出队列 clients_pending_write
if (!(c->flags & CLIENT_PENDING_WRITE) && clientHasPendingReplies(c))
clientInstallWriteHandler(c);
}
/* Update processed count on server */
server.stat_io_reads_processed += processed;
return processed;
}Redis 서버 클라이언트 버퍼의 데이터를 클라이언트에 다시 쓰는 handlerClientsWithPendingWrites 함수 호출을 포함하여 일부 작업 처리를 수행합니다. 🎜// https://github.com/redis/redis/blob/6.2/src/networking.c#L3662
int handleClientsWithPendingWritesUsingThreads(void) {
int processed = listLength(server.clients_pending_write);
if (processed == 0) return 0; /* Return ASAP if there are no clients. */
// 如果用户设置的 I/O 线程数等于 1 或者当前 clients_pending_write 队列中待写出的 client
// 数量不足 I/O 线程数的两倍,则不用多线程的逻辑,让所有 I/O 线程进入休眠,
// 直接在主线程把所有 client 的相应数据回写到客户端。
if (server.io_threads_num == 1 || stopThreadedIOIfNeeded()) {
return handleClientsWithPendingWrites();
}
// 唤醒正在休眠的 I/O 线程(如果有的话)。
if (!server.io_threads_active) startThreadedIO();
/* Distribute the clients across N different lists. */
// 和上面的handleClientsWithPendingReadsUsingThreads中的操作一样分配客户端给IO线程
listIter li;
listNode *ln;
listRewind(server.clients_pending_write,&li);
int item_id = 0;
while((ln = listNext(&li))) {
client *c = listNodeValue(ln);
c->flags &= ~CLIENT_PENDING_WRITE;
/* Remove clients from the list of pending writes since
* they are going to be closed ASAP. */
if (c->flags & CLIENT_CLOSE_ASAP) {
listDelNode(server.clients_pending_write, ln);
continue;
}
int target_id = item_id % server.io_threads_num;
listAddNodeTail(io_threads_list[target_id],c);
item_id++;
}
// 设置当前 I/O 操作为写出操作,给每个 I/O 线程的计数器设置分配的任务数量,
// 让 I/O 线程可以开始工作,把写出缓冲区(client->buf 或 c->reply)中的响应数据回写到客户端。
// 可以看到写回操作也是多线程执行的
io_threads_op = IO_THREADS_OP_WRITE;
for (int j = 1; j < server.io_threads_num; j++) {
int count = listLength(io_threads_list[j]);
setIOPendingCount(j, count);
}
// 主线程自己也会去执行读取客户端请求命令的任务,以达到最大限度利用 CPU。
listRewind(io_threads_list[0],&li);
while((ln = listNext(&li))) {
client *c = listNodeValue(ln);
writeToClient(c,0);
}
listEmpty(io_threads_list[0]);
/* Wait for all the other threads to end their work. */
// 等待所有的线程完成对应的工作
while(1) {
unsigned long pending = 0;
for (int j = 1; j < server.io_threads_num; j++)
pending += getIOPendingCount(j);
if (pending == 0) break;
}
// 最后再遍历一次 clients_pending_write 队列,检查是否还有 client 的写出缓冲区中有残留数据,
// 如果有,那就为 client 注册一个命令回复器 sendReplyToClient,等待客户端写就绪再继续把数据回写。
listRewind(server.clients_pending_write,&li);
while((ln = listNext(&li))) {
client *c = listNodeValue(ln);
// 检查 client 的写出缓冲区是否还有遗留数据。
if (clientHasPendingReplies(c) &&
connSetWriteHandler(c->conn, sendReplyToClient) == AE_ERR)
{
freeClientAsync(c);
}
}
listEmpty(server.clients_pending_write);
/* Update processed count on server */
server.stat_io_writes_processed += processed;
return processed;
}2、如果输出缓冲区的数据还没有写完,此时,handleClientsWithPendingWrites 函数就会调用 aeCreateFileEvent 函数,注册 sendReplyToClient 到该连接的写就绪事件,等待将后续将数据写回给客户端。
上面的执行流程总结下来就是
1、Redis Server 启动后,主线程会启动一个时间循环(Event Loop),持续监听事件;
2、client 到 server 的新连接,会调用 acceptTcpHandler 函数,之后会注册读事件 readQueryFromClient 函数,client 发给 server 的数据,都会在这个函数处理,这个函数会解析 client 的数据,找到对应的 cmd 函数执行;
3、cmd 逻辑执行完成后,server 需要写回数据给 client,调用 addReply 函数族的一系列函数将响应数据写入到对应 client 的写出缓冲区:client->buf 或者 client->reply ,client->buf 是首选的写出缓冲区,固定大小 16KB,一般来说可以缓冲足够多的响应数据,但是如果客户端在时间窗口内需要响应的数据非常大,那么则会自动切换到 client->reply 链表上去,使用链表理论上能够保存无限大的数据(受限于机器的物理内存),最后把 client 添加进一个 LIFO 队列 clients_pending_write;
4、在 Redis 事件驱动框架每次循环进入事件处理函数前,来处理监听到的已触发事件或是到时的时间事件之前,都会调用 beforeSleep 函数,进行一些任务处理,这其中就包括了调用 handleClientsWithPendingWrites 函数,它会将 Redis sever 客户端缓冲区中的数据写回客户端;
- beforeSleep 函数调用的 handleClientsWithPendingWrites 函数,会遍历 clients_pending_write(待写回数据的客户端) 队列,调用 writeToClient 把 client 的写出缓冲区里的数据回写到客户端,然后调用 writeToClient 函数,将客户端输出缓冲区中的数据发送给客户端;
- 如果输出缓冲区的数据还没有写完,此时,handleClientsWithPendingWrites 函数就会调用 aeCreateFileEvent 函数,注册 sendReplyToClient 到该连接的写就绪事件,等待将后续将数据写回给客户端。
Redis 多IO线程
在 Redis6.0 的版本中,引入了多线程来处理 IO 任务,多线程的引入,充分利用了当前服务器多核特性,使用多核运行多线程,让多线程帮助加速数据读取、命令解析以及数据写回的速度,提升 Redis 整体性能。
Redis6.0 之前的版本用的是单线程 Reactor 模式,所有的操作都在一个线程中完成,6.0 之后的版本使用了主从 Reactor 模式。
由一个 mainReactor 线程接收连接,然后发送给多个 subReactor 线程处理,subReactor 负责处理具体的业务。
来看下 Redis 多IO线程的具体实现过程
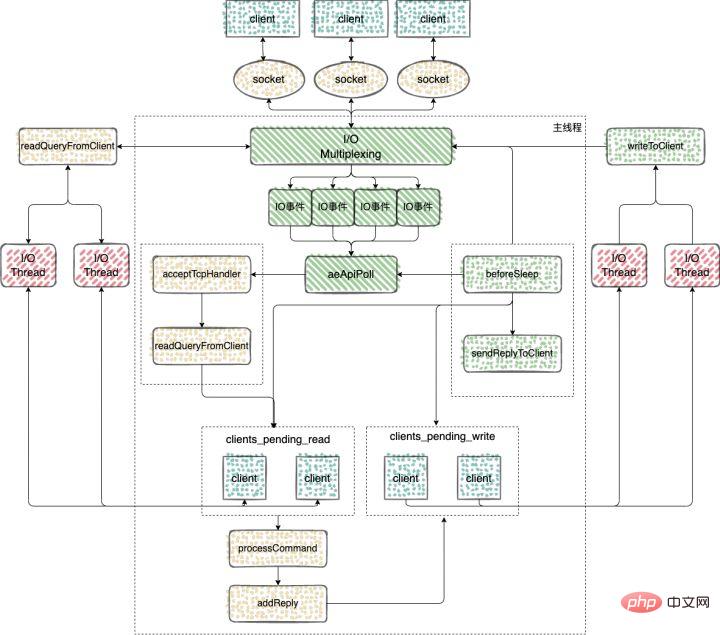
多 IO 线程的初始化
使用 initThreadedIO 函数来初始化多 IO 线程。
// https://github.com/redis/redis/blob/6.2/src/networking.c#L3573
void initThreadedIO(void) {
server.io_threads_active = 0; /* We start with threads not active. */
/* Don't spawn any thread if the user selected a single thread:
* we'll handle I/O directly from the main thread. */
// 如果用户只配置了一个 I/O 线程,不需要创建新线程了,直接在主线程中处理
if (server.io_threads_num == 1) return;
if (server.io_threads_num > IO_THREADS_MAX_NUM) {
serverLog(LL_WARNING,"Fatal: too many I/O threads configured. "
"The maximum number is %d.", IO_THREADS_MAX_NUM);
exit(1);
}
/* Spawn and initialize the I/O threads. */
// 初始化线程
for (int i = 0; i < server.io_threads_num; i++) {
/* Things we do for all the threads including the main thread. */
io_threads_list[i] = listCreate();
// 编号为0是主线程
if (i == 0) continue; /* Thread 0 is the main thread. */
/* Things we do only for the additional threads. */
pthread_t tid;
// 初始化io_threads_mutex数组
pthread_mutex_init(&io_threads_mutex[i],NULL);
// 初始化io_threads_pending数组
setIOPendingCount(i, 0);
// 主线程在启动 I/O 线程的时候会默认先锁住它,直到有 I/O 任务才唤醒它。
pthread_mutex_lock(&io_threads_mutex[i]); /* Thread will be stopped. */
// 调用pthread_create函数创建IO线程,线程运行函数为IOThreadMain
if (pthread_create(&tid,NULL,IOThreadMain,(void*)(long)i) != 0) {
serverLog(LL_WARNING,"Fatal: Can't initialize IO thread.");
exit(1);
}
io_threads[i] = tid;
}
}可以看到在 initThreadedIO 中完成了对下面四个数组的初始化工作
io_threads_list 数组:保存了每个 IO 线程要处理的客户端,将数组每个元素初始化为一个 List 类型的列表;
io_threads_pending 数组:保存等待每个 IO 线程处理的客户端个数;
io_threads_mutex 数组:保存线程互斥锁;
io_threads 数组:保存每个 IO 线程的描述符。
命令的接收
Redis server 在和一个客户端建立连接后,就开始了监听客户端的可读事件,处理可读事件的回调函数就是 readQueryFromClient
// https://github.com/redis/redis/blob/6.2/src/networking.c#L2219
void readQueryFromClient(connection *conn) {
client *c = connGetPrivateData(conn);
int nread, readlen;
size_t qblen;
/* Check if we want to read from the client later when exiting from
* the event loop. This is the case if threaded I/O is enabled. */
// 判断是否从客户端延迟读取数据
if (postponeClientRead(c)) return;
...
}
// https://github.com/redis/redis/blob/6.2/src/networking.c#L3746
int postponeClientRead(client *c) {
// 当多线程 I/O 模式开启、主线程没有在处理阻塞任务时,将 client 加入异步队列。
if (server.io_threads_active &&
server.io_threads_do_reads &&
!ProcessingEventsWhileBlocked &&
!(c->flags & (CLIENT_MASTER|CLIENT_SLAVE|CLIENT_PENDING_READ|CLIENT_BLOCKED)))
{
// 给客户端的flag添加CLIENT_PENDING_READ标记,表示推迟该客户端的读操作
c->flags |= CLIENT_PENDING_READ;
// 将可获得加入clients_pending_write列表
listAddNodeHead(server.clients_pending_read,c);
return 1;
} else {
return 0;
}
}使用 clients_pending_read 保存了需要进行延迟读操作的客户端之后,这些客户端又是如何分配给多 IO 线程执行的呢?
handleClientsWithPendingWritesUsingThreads 函数:该函数主要负责将 clients_pending_write 列表中的客户端分配给 IO 线程进行处理。
看下如何实现
// https://github.com/redis/redis/blob/6.2/src/networking.c#L3766
int handleClientsWithPendingReadsUsingThreads(void) {
// 当多线程 I/O 模式开启,才能执行下面的流程
if (!server.io_threads_active || !server.io_threads_do_reads) return 0;
int processed = listLength(server.clients_pending_read);
if (processed == 0) return 0;
// 遍历待读取的 client 队列 clients_pending_read,
// 根据IO线程的数量,让clients_pending_read中客户端数量对IO线程进行取模运算
// 取模的结果就是客户端分配给对应IO线程的编号
listIter li;
listNode *ln;
listRewind(server.clients_pending_read,&li);
int item_id = 0;
while((ln = listNext(&li))) {
client *c = listNodeValue(ln);
int target_id = item_id % server.io_threads_num;
listAddNodeTail(io_threads_list[target_id],c);
item_id++;
}
// 设置当前 I/O 操作为读取操作,给每个 I/O 线程的计数器设置分配的任务数量,
// 让 I/O 线程可以开始工作:只读取和解析命令,不执行
io_threads_op = IO_THREADS_OP_READ;
for (int j = 1; j < server.io_threads_num; j++) {
int count = listLength(io_threads_list[j]);
setIOPendingCount(j, count);
}
// 主线程自己也会去执行读取客户端请求命令的任务,以达到最大限度利用 CPU。
listRewind(io_threads_list[0],&li);
while((ln = listNext(&li))) {
client *c = listNodeValue(ln);
readQueryFromClient(c->conn);
}
listEmpty(io_threads_list[0]);
// 忙轮询,等待所有 IO 线程完成待读客户端的处理
while(1) {
unsigned long pending = 0;
for (int j = 1; j < server.io_threads_num; j++)
pending += getIOPendingCount(j);
if (pending == 0) break;
}
// 遍历待读取的 client 队列,清除 CLIENT_PENDING_READ标记,
// 然后解析并执行所有 client 的命令。
while(listLength(server.clients_pending_read)) {
ln = listFirst(server.clients_pending_read);
client *c = listNodeValue(ln);
c->flags &= ~CLIENT_PENDING_READ;
listDelNode(server.clients_pending_read,ln);
serverAssert(!(c->flags & CLIENT_BLOCKED));
// client 的第一条命令已经被解析好了,直接尝试执行。
if (processPendingCommandsAndResetClient(c) == C_ERR) {
/* If the client is no longer valid, we avoid
* processing the client later. So we just go
* to the next. */
continue;
}
// 解析并执行 client 命令
processInputBuffer(c);
// 命令执行完成之后,如果 client 中有响应数据需要回写到客户端,则将 client 加入到待写出队列 clients_pending_write
if (!(c->flags & CLIENT_PENDING_WRITE) && clientHasPendingReplies(c))
clientInstallWriteHandler(c);
}
/* Update processed count on server */
server.stat_io_reads_processed += processed;
return processed;
}1、当客户端发送命令请求之后,会触发 Redis 主线程的事件循环,命令处理器 readQueryFromClient 被回调,多线程模式下,则会把 client 加入到 clients_pending_read 任务队列中去,后面主线程再分配到 I/O 线程去读取客户端请求命令;
2、主线程会根据 clients_pending_read 中客户端数量对IO线程进行取模运算,取模的结果就是客户端分配给对应IO线程的编号;
3、忙轮询,等待所有的线程完成读取客户端命令的操作,这一步用到了多线程的请求;
4、遍历 clients_pending_read,执行所有 client 的命令,这里就是在主线程中执行的,命令的执行是单线程的操作。
命令的回复
完成命令的读取、解析以及执行之后,客户端命令的响应数据已经存入 client->buf 或者 client->reply 中。
主循环在捕获 IO 事件的时候,beforeSleep 函数会被调用,进而调用 handleClientsWithPendingWritesUsingThreads ,写回响应数据给客户端。
// https://github.com/redis/redis/blob/6.2/src/networking.c#L3662
int handleClientsWithPendingWritesUsingThreads(void) {
int processed = listLength(server.clients_pending_write);
if (processed == 0) return 0; /* Return ASAP if there are no clients. */
// 如果用户设置的 I/O 线程数等于 1 或者当前 clients_pending_write 队列中待写出的 client
// 数量不足 I/O 线程数的两倍,则不用多线程的逻辑,让所有 I/O 线程进入休眠,
// 直接在主线程把所有 client 的相应数据回写到客户端。
if (server.io_threads_num == 1 || stopThreadedIOIfNeeded()) {
return handleClientsWithPendingWrites();
}
// 唤醒正在休眠的 I/O 线程(如果有的话)。
if (!server.io_threads_active) startThreadedIO();
/* Distribute the clients across N different lists. */
// 和上面的handleClientsWithPendingReadsUsingThreads中的操作一样分配客户端给IO线程
listIter li;
listNode *ln;
listRewind(server.clients_pending_write,&li);
int item_id = 0;
while((ln = listNext(&li))) {
client *c = listNodeValue(ln);
c->flags &= ~CLIENT_PENDING_WRITE;
/* Remove clients from the list of pending writes since
* they are going to be closed ASAP. */
if (c->flags & CLIENT_CLOSE_ASAP) {
listDelNode(server.clients_pending_write, ln);
continue;
}
int target_id = item_id % server.io_threads_num;
listAddNodeTail(io_threads_list[target_id],c);
item_id++;
}
// 设置当前 I/O 操作为写出操作,给每个 I/O 线程的计数器设置分配的任务数量,
// 让 I/O 线程可以开始工作,把写出缓冲区(client->buf 或 c->reply)中的响应数据回写到客户端。
// 可以看到写回操作也是多线程执行的
io_threads_op = IO_THREADS_OP_WRITE;
for (int j = 1; j < server.io_threads_num; j++) {
int count = listLength(io_threads_list[j]);
setIOPendingCount(j, count);
}
// 主线程自己也会去执行读取客户端请求命令的任务,以达到最大限度利用 CPU。
listRewind(io_threads_list[0],&li);
while((ln = listNext(&li))) {
client *c = listNodeValue(ln);
writeToClient(c,0);
}
listEmpty(io_threads_list[0]);
/* Wait for all the other threads to end their work. */
// 等待所有的线程完成对应的工作
while(1) {
unsigned long pending = 0;
for (int j = 1; j < server.io_threads_num; j++)
pending += getIOPendingCount(j);
if (pending == 0) break;
}
// 最后再遍历一次 clients_pending_write 队列,检查是否还有 client 的写出缓冲区中有残留数据,
// 如果有,那就为 client 注册一个命令回复器 sendReplyToClient,等待客户端写就绪再继续把数据回写。
listRewind(server.clients_pending_write,&li);
while((ln = listNext(&li))) {
client *c = listNodeValue(ln);
// 检查 client 的写出缓冲区是否还有遗留数据。
if (clientHasPendingReplies(c) &&
connSetWriteHandler(c->conn, sendReplyToClient) == AE_ERR)
{
freeClientAsync(c);
}
}
listEmpty(server.clients_pending_write);
/* Update processed count on server */
server.stat_io_writes_processed += processed;
return processed;
}1、也是会将 client 分配给所有的 IO 线程;
2、忙轮询,等待所有的线程将缓存中的数据写回给客户端,这里写回操作使用的多线程;
3、最后再遍历 clients_pending_write,为那些还残留有响应数据的 client 注册命令回复处理器 sendReplyToClient,等待客户端可写之后在事件循环中继续回写残余的响应数据。
通过上面的分析可以得出结论,Redis 多IO线程中多线程的应用
1、解析客户端的命令的时候用到了多线程,但是对于客户端命令的执行,使用的还是单线程;
2、给客户端回复数据的时候,使用到了多线程。
来总结下 Redis 中多线程的执行过程
1、Redis Server 启动后,主线程会启动一个时间循环(Event Loop),持续监听事件;
2、client 到 server 的新连接,会调用 acceptTcpHandler 函数,之后会注册读事件 readQueryFromClient 函数,client 发给 server 的数据,都会在这个函数处理;
3、客户端发送给服务端的数据,不会类似 6.0 之前的版本使用 socket 直接去读,而是会将 client 放入到 clients_pending_read 中,里面保存了需要进行延迟读操作的客户端;
4、处理 clients_pending_read 的函数 handleClientsWithPendingReadsUsingThreads,在每次事件循环的时候都会调用;
- 1、主线程会根据 clients_pending_read 中客户端数量对IO线程进行取模运算,取模的结果就是客户端分配给对应IO线程的编号;
- 2、忙轮询,等待所有的线程完成读取客户端命令的操作,这一步用到了多线程的请求;
- 3、遍历 clients_pending_read,执行所有 client 的命令,这里就是在主线程中执行的,命令的执行是单线程的操作。
5、命令执行完成以后,回复的内容还是会被写入到 client 的缓存区中,这些 client 和6.0之前的版本处理方式一样,也是会被放入到 clients_pending_write(待写回数据的客户端);
6、6.0 对于clients_pending_write 的处理使用到了多线程;
- 1、也是会将 client 分配给所有的 IO 线程;
- 2、忙轮询,等待所有的线程将缓存中的数据写回给客户端,这里写回操作使用的多线程;
- 3、最后再遍历 clients_pending_write,为那些还残留有响应数据的 client 注册命令回复处理器 sendReplyToClient,等待客户端可写之后在事件循环中继续回写残余的响应数据。
原子性的单命令
通过上面的分析,我们知道,Redis 的主线程是单线程执行的,所有 Redis 中的单命令,都是原子性的。
所以对于一些场景的操作尽量去使用 Redis 中单命令去完成,就能保证命令执行的原子性。
比如对于上面的读取-修改-写回操作可以使用 Redis 中的原子计数器, INCRBY(自增)、DECRBR(自减)、INCR(加1) 和 DECR(减1) 等命令。
这些命令可以直接帮助我们处理并发控制
127.0.0.1:6379> incr test-1 (integer) 1 127.0.0.1:6379> incr test-1 (integer) 2 127.0.0.1:6379> incr test-1 (integer) 3
分析下源码,看看这个命令是如何实现的
// https://github.com/redis/redis/blob/6.2/src/t_string.c#L617
void incrCommand(client *c) {
incrDecrCommand(c,1);
}
void decrCommand(client *c) {
incrDecrCommand(c,-1);
}
void incrbyCommand(client *c) {
long long incr;
if (getLongLongFromObjectOrReply(c, c->argv[2], &incr, NULL) != C_OK) return;
incrDecrCommand(c,incr);
}
void decrbyCommand(client *c) {
long long incr;
if (getLongLongFromObjectOrReply(c, c->argv[2], &incr, NULL) != C_OK) return;
incrDecrCommand(c,-incr);
}可以看到 INCRBY(自增)、DECRBR(自减)、INCR(加1) 和 DECR(减1)这几个命令最终都是调用的 incrDecrCommand
// https://github.com/redis/redis/blob/6.2/src/t_string.c#L579
void incrDecrCommand(client *c, long long incr) {
long long value, oldvalue;
robj *o, *new;
// 查找有没有对应的键值
o = lookupKeyWrite(c->db,c->argv[1]);
// 判断类型,如果value对象不是字符串类型,直接返回
if (checkType(c,o,OBJ_STRING)) return;
// 将字符串类型的value转换为longlong类型保存在value中
if (getLongLongFromObjectOrReply(c,o,&value,NULL) != C_OK) return;
// 备份旧的value
oldvalue = value;
// 判断 incr 的值是否超过longlong类型所能表示的范围
// 长度的范围,十进制 64 位有符号整数
if ((incr < 0 && oldvalue < 0 && incr < (LLONG_MIN-oldvalue)) ||
(incr > 0 && oldvalue > 0 && incr > (LLONG_MAX-oldvalue))) {
addReplyError(c,"increment or decrement would overflow");
return;
}
// 计算新的 value值
value += incr;
if (o && o->refcount == 1 && o->encoding == OBJ_ENCODING_INT &&
(value < 0 || value >= OBJ_SHARED_INTEGERS) &&
value >= LONG_MIN && value <= LONG_MAX)
{
new = o;
o->ptr = (void*)((long)value);
} else {
new = createStringObjectFromLongLongForValue(value);
// 如果之前的 value 对象存在
if (o) {
// 重写为 new 的值
dbOverwrite(c->db,c->argv[1],new);
} else {
// 如果之前没有对应的 value,新设置 value 的值
dbAdd(c->db,c->argv[1],new);
}
}
// 进行通知
signalModifiedKey(c,c->db,c->argv[1]);
notifyKeyspaceEvent(NOTIFY_STRING,"incrby",c->argv[1],c->db->id);
server.dirty++;
addReply(c,shared.colon);
addReply(c,new);
addReply(c,shared.crlf);
}总结
1、Redis 中的命令执行都是单线程的,所以单命令的执行都是原子性的;
2、虽然 Redis6.0 版本引入了多线程,但是仅是在接收客户端的命令和回复客户端的数据用到了多线程,实际命令的执行还是单线程在处理;
推荐学习:Redis视频教程
위 내용은 Redis의 명령 원자성에 대한 자세한 분석의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

Video Face Swap
완전히 무료인 AI 얼굴 교환 도구를 사용하여 모든 비디오의 얼굴을 쉽게 바꾸세요!

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7742
7742
 15
1643
14
1397
52
1291
25
1234
29
15
1643
14
1397
52
1291
25
1234
29

 Redis 클러스터 모드를 구축하는 방법
Apr 10, 2025 pm 10:15 PM
Redis 클러스터 모드를 구축하는 방법
Apr 10, 2025 pm 10:15 PM
Redis Cluster Mode는 Sharding을 통해 Redis 인스턴스를 여러 서버에 배포하여 확장 성 및 가용성을 향상시킵니다. 시공 단계는 다음과 같습니다. 포트가 다른 홀수 redis 인스턴스를 만듭니다. 3 개의 센티넬 인스턴스를 만들고, Redis 인스턴스 및 장애 조치를 모니터링합니다. Sentinel 구성 파일 구성, Redis 인스턴스 정보 및 장애 조치 설정 모니터링 추가; Redis 인스턴스 구성 파일 구성, 클러스터 모드 활성화 및 클러스터 정보 파일 경로를 지정합니다. 각 redis 인스턴스의 정보를 포함하는 Nodes.conf 파일을 작성합니다. 클러스터를 시작하고 Create 명령을 실행하여 클러스터를 작성하고 복제본 수를 지정하십시오. 클러스터에 로그인하여 클러스터 정보 명령을 실행하여 클러스터 상태를 확인하십시오. 만들다
 Redis 데이터를 지우는 방법
Apr 10, 2025 pm 10:06 PM
Redis 데이터를 지우는 방법
Apr 10, 2025 pm 10:06 PM
Redis 데이터를 지우는 방법 : Flushall 명령을 사용하여 모든 키 값을 지우십시오. FlushDB 명령을 사용하여 현재 선택한 데이터베이스의 키 값을 지우십시오. 선택을 사용하여 데이터베이스를 전환 한 다음 FlushDB를 사용하여 여러 데이터베이스를 지우십시오. del 명령을 사용하여 특정 키를 삭제하십시오. Redis-Cli 도구를 사용하여 데이터를 지우십시오.
 Redis 대기열을 읽는 방법
Apr 10, 2025 pm 10:12 PM
Redis 대기열을 읽는 방법
Apr 10, 2025 pm 10:12 PM
Redis의 대기열을 읽으려면 대기열 이름을 얻고 LPOP 명령을 사용하여 요소를 읽고 빈 큐를 처리해야합니다. 특정 단계는 다음과 같습니다. 대기열 이름 가져 오기 : "큐 :"와 같은 "대기열 : my-queue"의 접두사로 이름을 지정하십시오. LPOP 명령을 사용하십시오. 빈 대기열 처리 : 대기열이 비어 있으면 LPOP이 NIL을 반환하고 요소를 읽기 전에 대기열이 존재하는지 확인할 수 있습니다.
 Redis 명령을 사용하는 방법
Apr 10, 2025 pm 08:45 PM
Redis 명령을 사용하는 방법
Apr 10, 2025 pm 08:45 PM
Redis 지시 사항을 사용하려면 다음 단계가 필요합니다. Redis 클라이언트를 엽니 다. 명령 (동사 키 값)을 입력하십시오. 필요한 매개 변수를 제공합니다 (명령어마다 다름). 명령을 실행하려면 Enter를 누르십시오. Redis는 작업 결과를 나타내는 응답을 반환합니다 (일반적으로 OK 또는 -err).
 Redis Lock을 사용하는 방법
Apr 10, 2025 pm 08:39 PM
Redis Lock을 사용하는 방법
Apr 10, 2025 pm 08:39 PM
Redis를 사용하여 잠금 작업을 사용하려면 SetNX 명령을 통해 잠금을 얻은 다음 만료 명령을 사용하여 만료 시간을 설정해야합니다. 특정 단계는 다음과 같습니다. (1) SETNX 명령을 사용하여 키 값 쌍을 설정하십시오. (2) 만료 명령을 사용하여 잠금의 만료 시간을 설정하십시오. (3) DEL 명령을 사용하여 잠금이 더 이상 필요하지 않은 경우 잠금을 삭제하십시오.
 Centos redis에서 lua 스크립트 실행 시간을 구성하는 방법
Apr 14, 2025 pm 02:12 PM
Centos redis에서 lua 스크립트 실행 시간을 구성하는 방법
Apr 14, 2025 pm 02:12 PM
CentOS 시스템에서는 Redis 구성 파일을 수정하거나 Redis 명령을 사용하여 악의적 인 스크립트가 너무 많은 리소스를 소비하지 못하게하여 LUA 스크립트의 실행 시간을 제한 할 수 있습니다. 방법 1 : Redis 구성 파일을 수정하고 Redis 구성 파일을 찾으십시오. Redis 구성 파일은 일반적으로 /etc/redis/redis.conf에 있습니다. 구성 파일 편집 : 텍스트 편집기 (예 : VI 또는 Nano)를 사용하여 구성 파일을 엽니 다. Sudovi/etc/redis/redis.conf LUA 스크립트 실행 시간 제한을 설정 : 구성 파일에서 다음 줄을 추가 또는 수정하여 LUA 스크립트의 최대 실행 시간을 설정하십시오 (Unit : Milliseconds).
 Redis 명령 줄을 사용하는 방법
Apr 10, 2025 pm 10:18 PM
Redis 명령 줄을 사용하는 방법
Apr 10, 2025 pm 10:18 PM
Redis Command Line 도구 (Redis-Cli)를 사용하여 다음 단계를 통해 Redis를 관리하고 작동하십시오. 서버에 연결하고 주소와 포트를 지정하십시오. 명령 이름과 매개 변수를 사용하여 서버에 명령을 보냅니다. 도움말 명령을 사용하여 특정 명령에 대한 도움말 정보를 봅니다. 종금 명령을 사용하여 명령 줄 도구를 종료하십시오.
 Debian Readdir의 성능을 최적화하는 방법
Apr 13, 2025 am 08:48 AM
Debian Readdir의 성능을 최적화하는 방법
Apr 13, 2025 am 08:48 AM
Debian Systems에서 ReadDir 시스템 호출은 디렉토리 내용을 읽는 데 사용됩니다. 성능이 좋지 않은 경우 다음과 같은 최적화 전략을 시도해보십시오. 디렉토리 파일 수를 단순화하십시오. 대규모 디렉토리를 가능한 한 여러 소규모 디렉토리로 나누어 읽기마다 처리 된 항목 수를 줄입니다. 디렉토리 컨텐츠 캐싱 활성화 : 캐시 메커니즘을 구축하고 정기적으로 캐시를 업데이트하거나 디렉토리 컨텐츠가 변경 될 때 캐시를 업데이트하며 readDir로 자주 호출을 줄입니다. 메모리 캐시 (예 : Memcached 또는 Redis) 또는 로컬 캐시 (예 : 파일 또는 데이터베이스)를 고려할 수 있습니다. 효율적인 데이터 구조 채택 : 디렉토리 트래버스를 직접 구현하는 경우 디렉토리 정보를 저장하고 액세스하기 위해보다 효율적인 데이터 구조 (예 : 선형 검색 대신 해시 테이블)를 선택하십시오.
