

이력서 심사를 위한 Python 자동화 실습

이 기사에서는 단어 파일을 읽는 ReadDoc 클래스를 정의하고 필터링하는 search_word 함수를 정의하는 등 이력서 심사와 관련된 문제를 주로 소개하는 python에 대한 관련 지식을 제공하므로 함께 살펴보시기 바랍니다. 모두에게 도움이 되십시오. Y 추천 학습: tPython 동영상 튜토리얼
 이력서 심사
이력서 심사
 조건을 알고 있음:
조건을 알고 있음:
지정된 키워드(예: Python, Java)가 포함된 이력서를 찾으려면
구현 아이디어:
각 단어 파일을 일괄적으로 읽고(glob을 통해 단어 정보 얻기) 읽을 수 있는 모든 콘텐츠를 얻은 다음 키워드를 전달합니다. 대상 이력서 주소를 가져오는 방법입니다.
这里有个需要注意的地方就是,并不是所有的 "简历" 都是以段落的形式呈现的,比如从 "猎聘" 网下载下来的简历就是 "表格形式" 的,而 "boss" 上下载的简历就是 "段落形式" 的,这里再进行读取的时候需要注意下,我们做的演示脚本练习就是 "表格形式" 的。
这里的话,我们就可以专门定义一个 "ReadDoc" 的类,里面定义两个函数,分别用于读取 "段落" 和 "表格" 。
实操案例脚本如下:
# coding:utf-8from docx import Documentclass ReadDoc(object): # 定义一个 ReadDoc ,用以读取 word 文件 def __init__(self, path): # 构造函数默认传入读取 word 文件的路径 self.doc = Document(path) self.p_text = '' self.table_text = '' self.get_para() self.get_table() def get_para(self): # 定义 get_para 函数用以读取 word 文件的段落 for p in self.doc.paragraphs: self.p_text += p.text + '\n' # 读取的段落内容进行换行 print(self.p_text) def get_table(self): # 定义 get_table 函数循环读取表格内容 for table in self.doc.tables: for row in table.rows: _cell_str = '' # 获取每一行的完整信息 for cell in row.cells: _cell_str += cell.text + ',' # 每一行加一个 "," 隔开 self.table_text += _cell_str + '\n' # 读取的表格内容进行换行 print(self.table_text)if __name__ == '__main__': path = glob.os.path.join(glob.os.getcwd(), 'test_file/简历1.docx') doc = ReadDoc(path) print(doc)
看一下 ReadDoc
여기서 한 가지 주목할 점은 모든 "이력서"가 문단 형식으로 표시되는 것은 아니라는 점입니다. 예를 들어 "Liepin" 웹사이트에서 다운로드한 이력서는 "표 형식"으로 되어 있고, 에서 다운로드한 이력서는 "표 형식"입니다. "boss"는 "단락 형식"입니다. 여기서 읽을 때 주의할 점은 우리가 수행한 데모 스크립트 연습이 "표 형식"입니다. 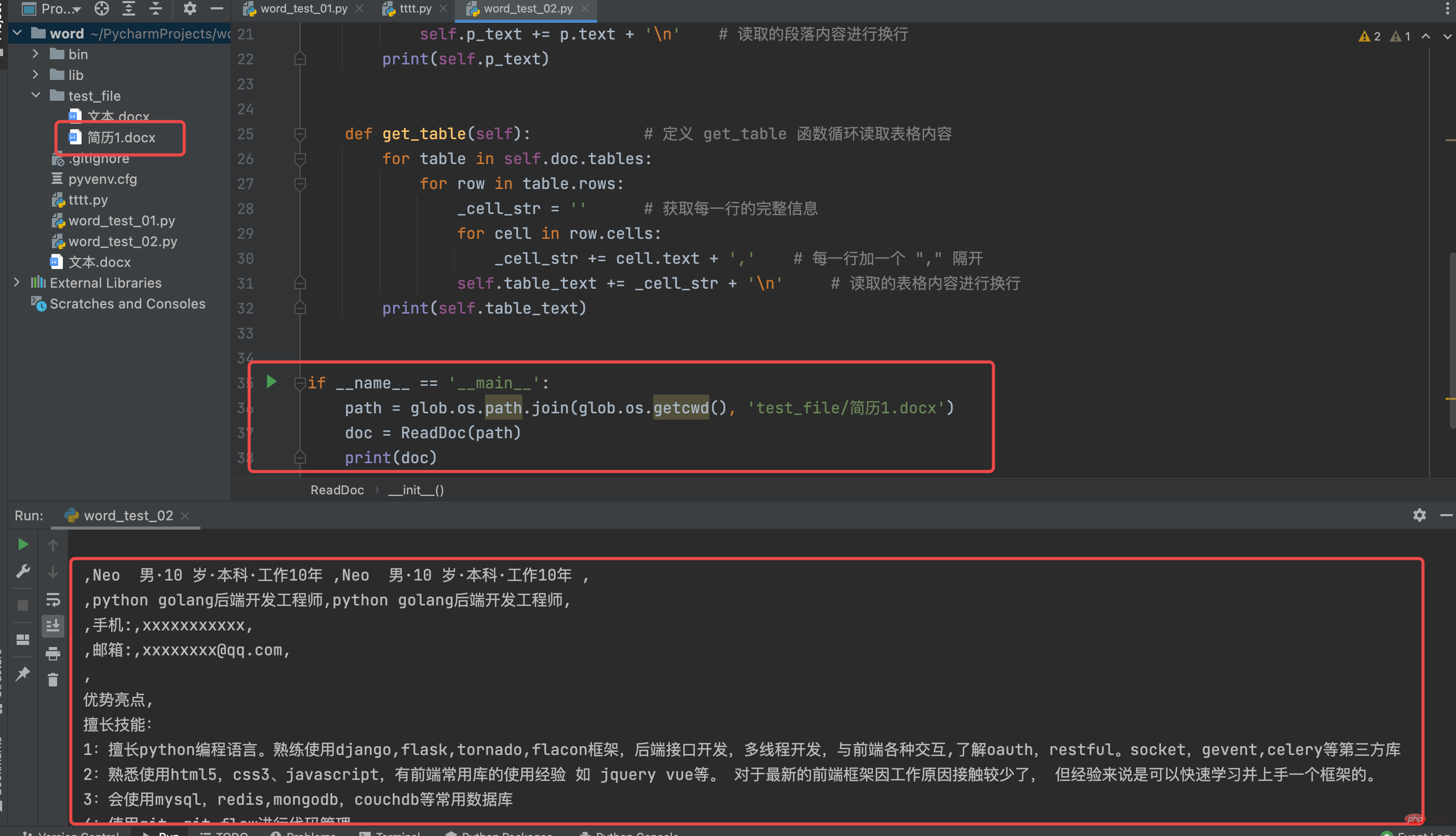
여기서 "단락"과 "표"를 읽는 두 가지 함수를 정의하는 "ReadDoc" 클래스를 구체적으로 정의할 수 있습니다. 실제 사례 스크립트는 다음과 같습니다.
# coding:utf-8import globfrom docx import Documentclass ReadDoc(object): # 定义一个 ReadDoc ,用以读取 word 文件
def __init__(self, path): # 构造函数默认传入读取 word 文件的路径
self.doc = Document(path)
self.p_text = ''
self.table_text = ''
self.get_para()
self.get_table()
def get_para(self): # 定义 get_para 函数用以读取 word 文件的段落
for p in self.doc.paragraphs:
self.p_text += p.text + '\n' # 读取的段落内容进行换行
# print(self.p_text) # 调试打印输出 word 文件的段落内容
def get_table(self): # 定义 get_table 函数循环读取表格内容
for table in self.doc.tables:
for row in table.rows:
_cell_str = '' # 获取每一行的完整信息
for cell in row.cells:
_cell_str += cell.text + ',' # 每一行加一个 "," 隔开
self.table_text += _cell_str + '\n' # 读取的表格内容进行换行
# print(self.table_text) # 调试打印输出 word 文件的表格内容def search_word(path, targets): # 定义 search_word 用以筛选符合内容的简历;传入 path 与 targets(targets 为列表)
result = glob.glob(path)
final_result = [] # 定义一个空列表,用以后续存储文件的信息
for i in result: # for 循环获取 result 内容
isuse = True # 是否可用
if glob.os.path.isfile(i): # 判断是否是文件
if i.endswith('.docx'): # 判断文件后缀是否是 "docx" ,若是,则利用 ReadDoc类 实例化该文件对象
doc = ReadDoc(i)
p_text = doc.p_text # 获取 word 文件内容
table_text = doc.table_text
all_text = p_text + table_text for target in targets: # for 循环判断关键字信息内容是否存在
if target not in all_text:
isuse = False
break
if not isuse:
continue
final_result.append(i)
return final_resultif __name__ == '__main__':
path = glob.os.path.join(glob.os.getcwd(), '*')
result = search_word(path, ['python', 'golang', 'react', '埋点']) # 埋点是为了演示效果,故意在 "简历1.docx" 加上的
print(result)ReadDoc 클래스의 실행 결과를 살펴보세요
필터링할 search_word 함수 정의 원하는 이력서와 일치하는 단어 파일 내용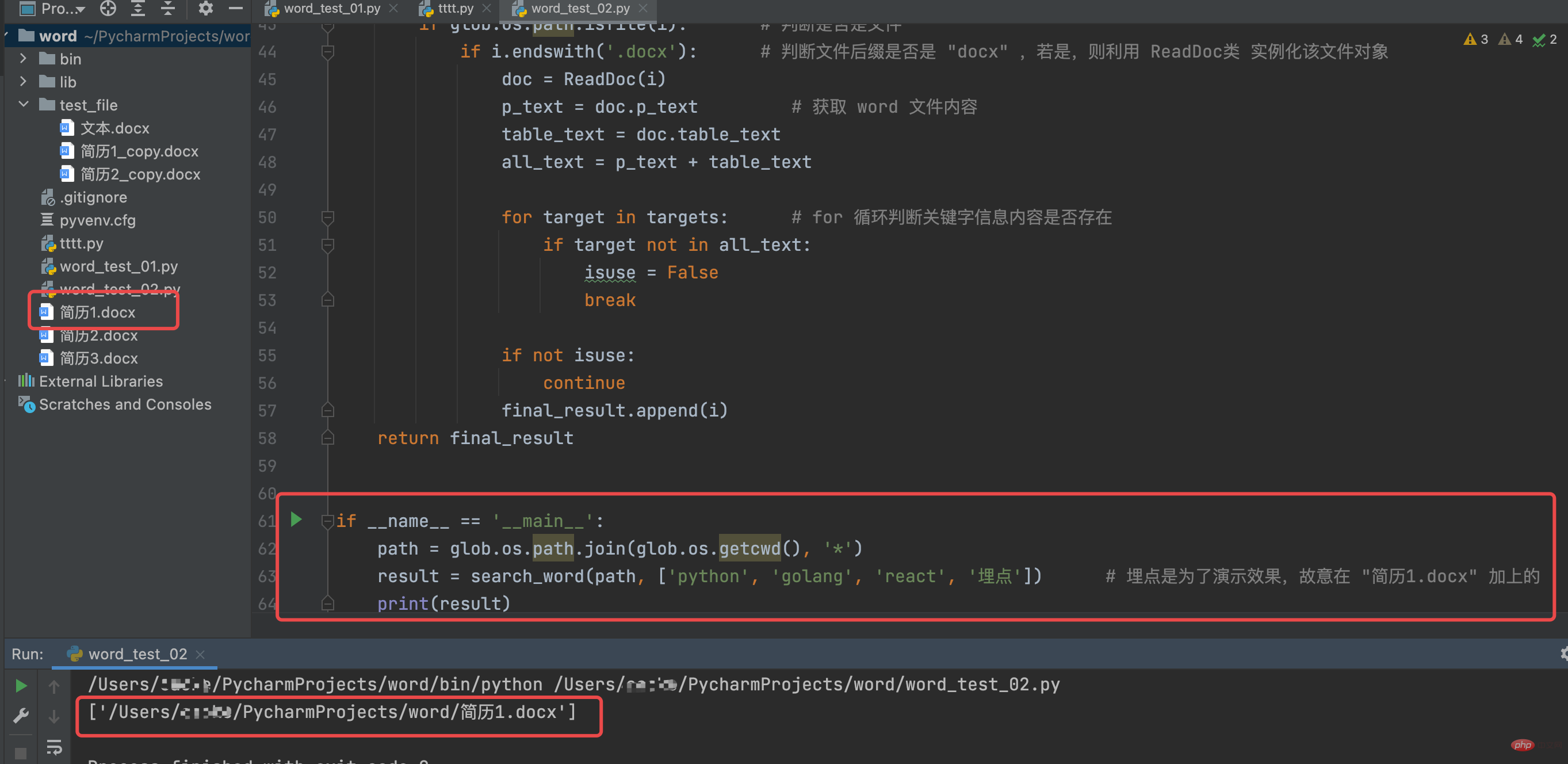
실제 사례 스크립트는 다음과 같습니다. rrreee실행 결과는 다음과 같습니다.
🎜🎜🎜🎜🎜🎜추천 학습: 🎜python 비디오 튜토리얼🎜🎜위 내용은 이력서 심사를 위한 Python 자동화 실습의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

Video Face Swap
완전히 무료인 AI 얼굴 교환 도구를 사용하여 모든 비디오의 얼굴을 쉽게 바꾸세요!

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7652
7652
 15
1393
52
91
11
73
19
37
110
15
1393
52
91
11
73
19
37
110

 PHP와 Python : 다른 패러다임이 설명되었습니다
Apr 18, 2025 am 12:26 AM
PHP와 Python : 다른 패러다임이 설명되었습니다
Apr 18, 2025 am 12:26 AM
PHP는 주로 절차 적 프로그래밍이지만 객체 지향 프로그래밍 (OOP)도 지원합니다. Python은 OOP, 기능 및 절차 프로그래밍을 포함한 다양한 패러다임을 지원합니다. PHP는 웹 개발에 적합하며 Python은 데이터 분석 및 기계 학습과 같은 다양한 응용 프로그램에 적합합니다.
 PHP와 Python 중에서 선택 : 가이드
Apr 18, 2025 am 12:24 AM
PHP와 Python 중에서 선택 : 가이드
Apr 18, 2025 am 12:24 AM
PHP는 웹 개발 및 빠른 프로토 타이핑에 적합하며 Python은 데이터 과학 및 기계 학습에 적합합니다. 1.PHP는 간단한 구문과 함께 동적 웹 개발에 사용되며 빠른 개발에 적합합니다. 2. Python은 간결한 구문을 가지고 있으며 여러 분야에 적합하며 강력한 라이브러리 생태계가 있습니다.
 Python에서 비주얼 스튜디오 코드를 사용할 수 있습니다
Apr 15, 2025 pm 08:18 PM
Python에서 비주얼 스튜디오 코드를 사용할 수 있습니다
Apr 15, 2025 pm 08:18 PM
VS 코드는 파이썬을 작성하는 데 사용될 수 있으며 파이썬 애플리케이션을 개발하기에 이상적인 도구가되는 많은 기능을 제공합니다. 사용자는 다음을 수행 할 수 있습니다. Python 확장 기능을 설치하여 코드 완료, 구문 강조 및 디버깅과 같은 기능을 얻습니다. 디버거를 사용하여 코드를 단계별로 추적하고 오류를 찾아 수정하십시오. 버전 제어를 위해 git을 통합합니다. 코드 서식 도구를 사용하여 코드 일관성을 유지하십시오. 라인 도구를 사용하여 잠재적 인 문제를 미리 발견하십시오.
 Windows 8에서 코드를 실행할 수 있습니다
Apr 15, 2025 pm 07:24 PM
Windows 8에서 코드를 실행할 수 있습니다
Apr 15, 2025 pm 07:24 PM
VS 코드는 Windows 8에서 실행될 수 있지만 경험은 크지 않을 수 있습니다. 먼저 시스템이 최신 패치로 업데이트되었는지 확인한 다음 시스템 아키텍처와 일치하는 VS 코드 설치 패키지를 다운로드하여 프롬프트대로 설치하십시오. 설치 후 일부 확장은 Windows 8과 호환되지 않을 수 있으며 대체 확장을 찾거나 가상 시스템에서 새로운 Windows 시스템을 사용해야합니다. 필요한 연장을 설치하여 제대로 작동하는지 확인하십시오. Windows 8에서는 VS 코드가 가능하지만 더 나은 개발 경험과 보안을 위해 새로운 Windows 시스템으로 업그레이드하는 것이 좋습니다.
 VScode 확장자가 악의적입니까?
Apr 15, 2025 pm 07:57 PM
VScode 확장자가 악의적입니까?
Apr 15, 2025 pm 07:57 PM
VS 코드 확장은 악의적 인 코드 숨기기, 취약성 악용 및 합법적 인 확장으로 자위하는 등 악성 위험을 초래합니다. 악의적 인 확장을 식별하는 방법에는 게시자 확인, 주석 읽기, 코드 확인 및주의해서 설치가 포함됩니다. 보안 조치에는 보안 인식, 좋은 습관, 정기적 인 업데이트 및 바이러스 백신 소프트웨어도 포함됩니다.
 Python vs. JavaScript : 학습 곡선 및 사용 편의성
Apr 16, 2025 am 12:12 AM
Python vs. JavaScript : 학습 곡선 및 사용 편의성
Apr 16, 2025 am 12:12 AM
Python은 부드러운 학습 곡선과 간결한 구문으로 초보자에게 더 적합합니다. JavaScript는 가파른 학습 곡선과 유연한 구문으로 프론트 엔드 개발에 적합합니다. 1. Python Syntax는 직관적이며 데이터 과학 및 백엔드 개발에 적합합니다. 2. JavaScript는 유연하며 프론트 엔드 및 서버 측 프로그래밍에서 널리 사용됩니다.
 PHP와 Python : 그들의 역사에 깊은 다이빙
Apr 18, 2025 am 12:25 AM
PHP와 Python : 그들의 역사에 깊은 다이빙
Apr 18, 2025 am 12:25 AM
PHP는 1994 년에 시작되었으며 Rasmuslerdorf에 의해 개발되었습니다. 원래 웹 사이트 방문자를 추적하는 데 사용되었으며 점차 서버 측 스크립팅 언어로 진화했으며 웹 개발에 널리 사용되었습니다. Python은 1980 년대 후반 Guidovan Rossum에 의해 개발되었으며 1991 년에 처음 출시되었습니다. 코드 가독성과 단순성을 강조하며 과학 컴퓨팅, 데이터 분석 및 기타 분야에 적합합니다.
 터미널 VSCODE에서 프로그램을 실행하는 방법
Apr 15, 2025 pm 06:42 PM
터미널 VSCODE에서 프로그램을 실행하는 방법
Apr 15, 2025 pm 06:42 PM
vs 코드에서는 다음 단계를 통해 터미널에서 프로그램을 실행할 수 있습니다. 코드를 준비하고 통합 터미널을 열어 코드 디렉토리가 터미널 작업 디렉토리와 일치하는지 확인하십시오. 프로그래밍 언어 (예 : Python의 Python Your_file_name.py)에 따라 실행 명령을 선택하여 성공적으로 실행되는지 여부를 확인하고 오류를 해결하십시오. 디버거를 사용하여 디버깅 효율을 향상시킵니다.
