

MySQL 인덱스 최적화 지식 포인트 요약 및 구성

이 기사는 mysql에 대한 관련 지식을 제공합니다. 인덱스 최적화 원칙에 대한 관련 내용을 포함하여 주로 인덱싱과 관련된 내용을 소개합니다. 모두에게 도움이 되기를 바랍니다.

추천 학습: mysql 비디오 튜토리얼
머리말: 인덱스가 MySQL의 검색 속도를 크게 향상시킬 수 있다는 것은 모두가 알고 있다고 생각합니다. 그러나 실제로 일상 작업에서 SQL을 작성할 때 이것을 고려할 것입니다. SQL. 실행 효율성을 높이기 위해 인덱스를 사용할 수 있습니까? 이 블로그에서는 인덱스 최적화의 20가지 원칙을 자세히 소개합니다. 이를 업무에 언제든지 적용할 수 있다면 여러분이 작성하는 SQL이 인덱스에 도달하여 매우 효율적일 수 있다고 믿습니다.
1. 인덱스 분류
인덱스는 MySQL의 검색 속도를 크게 향상시킬 수 있습니다. 인덱스는 마치 책의 목차와도 같습니다. 원하는 데이터를 더 빨리 찾을 수 있도록 MySQL에서 흔히 사용되는 인덱스를 소개합니다.
1.1. 일반 인덱스, 기본 키 인덱스, 고유 인덱스
(1) 일반 인덱스
가장 기본적인 인덱스로 제한이 없습니다.
사용 방법은?
//方式1 ALTER TABLE table_name ADD INDEX index_name ( column )
예: ALTER TABLE users ADD INDEX index_users(id)
//方式2 CREATE INDEX index_name ON table_name (column_name)
예: CREATE INDEX index_users ON users (id)
(2) 고유 인덱스
는 일반 인덱스와 유사하지만 차이점은 다음과 같습니다. is: 인덱스 컬럼 값은 고유해야 하지만 null 값은 허용됩니다. 복합 인덱스인 경우 컬럼 값의 조합은 1이어야 합니다.
사용 방법은?
//方式1 ALTER TABLE table_name ADD UNIQUE [indexName] (column)
예: ALTER TABLE users ADD UNIQUE index_users(id)
//方式2 CREATE UNIQUE INDEX index_name ON table_name (column_name)
예: CREATE UNIQUE INDEX index_users ON users(id)
(3) 기본 키 인덱스
특별한 고유 인덱스입니다. NULL 값은 허용되지 않습니다. 일반적으로 테이블을 생성할 때 기본 키를 지정하면 기본 키 인덱스가 자동으로 생성됩니다. 대신 CREATE INDEX를 사용하여 기본 키 인덱스를 생성할 수 없습니다.
사용 방법은?
//方式1 ALTER TABLE table_name ADD PRIMARY KEY ( column )
예: ALTER TABLE 사용자 ADD PRIMARY KEY(id)
방법 2: 테이블 생성 시 기본 키 지정
1.2, 클러스터형 인덱스 및 비클러스터형 인덱스
(1) 클러스터형 인덱스
클러스터형 인덱스는 클러스터형 인덱스라고 하며, 모든 데이터는 클러스터형 인덱스에 존재하며, 리프 노드는 데이터에 직접 대응하고, 중간 인덱스 페이지의 인덱스 행은 데이터 페이지에 직접 대응합니다. InnoDB 스토리지 엔진의 기본 키는 기본적으로 클러스터형 인덱스를 생성하며, 테이블당 하나의 클러스터형 인덱스만 생성할 수 있습니다. 레코드의 인덱스 순서는 물리적 순서와 동일하므로 작업 간 및 순서별 작업에 더 적합합니다.
InnoDB클러스터형 인덱스의 리프 노드는 행 레코드를 저장합니다. 따라서 InnoDB에는 클러스터형 인덱스가 하나만 있어야 합니다.
(1) 테이블이 PK를 정의하는 경우 PK는 클러스터형 인덱스입니다. 테이블이 PK를 정의하지 않으면 NULL이 아닌 첫 번째 고유 열은 클러스터형 인덱스입니다.
(3) 그렇지 않으면 InnoDB는 숨겨진 행 ID를 클러스터형 인덱스로 생성합니다.
Voiceover: 따라서 PK 쿼리는 매우 빠르고 직접적인 위치 결정 라인 기록. 예를 들어 테이블은 이전에 사용했던 Xinhua 사전과 같고, 클러스터형 인덱스는 Pinyin 디렉토리와 같으며, 각 단어가 저장된 페이지 번호는 데이터의 물리적 주소입니다. 와우' 단어의 경우, 신화사전의 병음 카탈로그에서 '와우'라는 단어에 해당하는 페이지 번호만 조회하면 되고, 해당 단어 '와우'의 위치를 조회할 수 있습니다. 병음에 해당하는 A-Z의 어순 카탈로그는 실제로 신화사전에 저장된 것과 동일합니다. 문자 A-Z의 순서도 동일합니다. 새로운 한자가 있고 병음 시작 부분의 첫 번째 문자가 B이면 삽입할 때 반드시 동일해야 합니다. 병음 디렉토리 순서에 따라 문자 A 뒤에 삽입됩니다.
(2) 비클러스터형 인덱스비클러스터형 인덱스라고도 불리는 비클러스터형 인덱스, 보조 인덱스, 모든 데이터와 인덱스 디렉토리는 별도로 저장되며 리프 노드는 특정 데이터 행 전체를 저장하지 않습니다(리프 노드) 포인트는 데이터 페이지를 직접 가리키지 않지만) 이 행의 기본 키 값을 저장합니다.
레코드의 색인 순서는 물리적 순서와 아무런 관련이 없습니다. 각 테이블에는 여러 개의 비클러스터형 인덱스가 있을 수 있으며, 이는 더 많은 디스크와 메모리를 필요로 합니다. 여러 인덱스는 삽입 및 업데이트 속도에 영향을 미칩니다.
음성 해설: 비클러스터형 인덱스를 테이블로 다시 쿼리해야 합니다. 먼저 기본 키 값을 찾은 다음 행 레코드를 찾습니다. 인덱스 트리를 두 번 스캔해야 하기 때문에 성능이 스캔보다 낮습니다. 인덱스 트리를 한 번.실제로는 클러스터형 인덱스 이외의 인덱스도 정의상 비클러스터형 인덱스인데 사람들은 비클러스터형 인덱스를 일반 인덱스, 고유 인덱스, 전체 텍스트 인덱스로 세분화하고 싶어합니다. 논클러스터형 인덱스를 실생활의 어떤 것과 비교해야 한다면 논클러스터형 인덱스는 신화사전의 급진적 사전과 같으며 그 구조적 순서가 실제 저장 순서와 반드시 일치하지는 않습니다.
1.3、联合索引最左匹配原则
联合索引又叫复合索引,对表上的多个字段同时建立的索引(有顺序,ABC,ACB是完全不同的两种联合索引。)以联合索引(a,b,c)为例,建立这样的索引相当于建立了索引a、ab、abc三个索引。
遵循最左前缀原则(必须带着最左边的列做条件才能命中索引),且从出现范围开始索引失效;
当遇到范围查询(>、<、between、like)就会停止匹配。也就是:
#这样a,b可以用到(a,b,c),c不可以 select * from t where a=1 and b>1 and c =1;</p> <p>这条语句只有 a,b 会用到索引,c 都不能用到索引。</p> <pre class="brush:php;toolbar:false">create index mix_ind on 表名 (id,name,email); select * from 表名 where id = 123; # 命中索引 select * from 表名 where id = 123 and name = 'pamela'; # 命中索引 select * from 表名 where id > 123 and name = 'pamela'; # id命中,name不命中索引,因为出现范围 select * from 表名 where id = 123 and email = 'pamela@123.com'; # 命中索引 select * from 表名 where email = 'pamela@123.com'; # 不命中索引,因为条件中没有id select * from 表名 where name='pamela' and email = 'pamela@123.com'; # 不命中
A:select * from student where age = 16 and name = '小张' B:select * from student where name = '小张' and sex = '男' C:select * from student where name = '小张' and sex = '男' and age = 18 D:select * from student where age > 20 and name = '小张' E:select * from student where age != 15 and name = '小张'
A遵从最左匹配原则,age是在最左边,所以A走索引;
B直接从name开始,没有遵从最左匹配原则,所以不走索引;
C虽然从name开始,但是有索引最左边的age,mysql内部会自动转成where age = '18' and name = '小张' and sex = '男' 这种,所以还是遵从最左匹配原则;
D这个是因为age>20是范围,范围字段会结束索引对范围后面索引字段的使用,所以只有走了age这个索引;
E这个虽然遵循最左匹配原则,但是不走索引,因为!= 不走索引;
question1:如何给下列sql语句加上联合索引?
select * from test where a = 1 and b = 1 and c = 1;
answer:
咱们一看,直接加索引(a,b,c)就可以了,其实不然,也不能说这个答案不对,只能说这个答案不够完整。因为mysql在执行的时候会经历优化器过程,所以会把sql语句自动优化成符合索引的顺序,所以索引(a,b,c) (a,c,b) 或者是(c,b,a)都是可以的,那我们究竟如何确定索引呢?这个就得根据实际情况来了,比如a字段是表示性别的,只有0,1和2三个值来表示 未知,男,女三种性别,那么把a字段放在联合索引的最后会比较合适,反正哪个字段的内容重复率越高,就把哪个字段往联合索引的后面放。
question2:如何给下列sql语句加上索引?
SELECT * FROM table WHERE a > 1 and b = 2;
answer:
如果咱们建立索引(a,b),那么a>1是可以走到索引的,但是b=2就没法走到索引了。但是如果咱们建立索引(b,a),那么sql语句会被自动优化成 where b=2 and a> 1,这样a和b都能走到索引,所以建立索引(b,a)比较合适
1.4、索引覆盖和回表
使用聚集索引(主键或第一个唯一索引)就不会回表,非聚集索引就会回表。当select的数据列被所建索引覆盖时不需要回表,可以直接取得数据。
覆盖索引是select的数据列只用从索引中就能够取得,不必读取数据行,换句话说查询列要被所建的索引覆盖。覆盖索引在查询过程中不需要回表。只需要在一棵索引树上就能获取SQL所需的所有列数据,无需回表速度更快。
覆盖索引其核心就是只从辅助索引要数据。那么, 普通索引(单字段)和联合索引,以及唯一索引都能实现覆盖索引的作用。explain的输出结果Extra字段为Using index时,能够触发索引覆盖。
create index ind_id on 表名(id); # 对id字段创建了索引 select id from 表名 where id > 100; # 覆盖索引:在查找一条数据的时候,命中索引,不需要再回表 select max(id) from 表名 where id > 100; # 覆盖索引:在查找一条数据的时候,命中索引,不需要再回表 select count(id) from 表名 where id > 100; # 覆盖索引:在查找一条数据的时候,命中索引,不需要再回表 select name from 表名 where id > 100; # 相对慢
(1) 如何实现索引覆盖?
常见的方法是:将被查询的字段,建立到联合索引里去。
select id,name from user where name='shenjian';

能够命中name索引,索引叶子节点存储了主键id,通过name的索引树即可获取id和name,无需回表,符合索引覆盖,效率较高。
Extra:Using index。
(2)哪些场景可以利用索引覆盖来优化SQL?
场景1:全表count查询优化
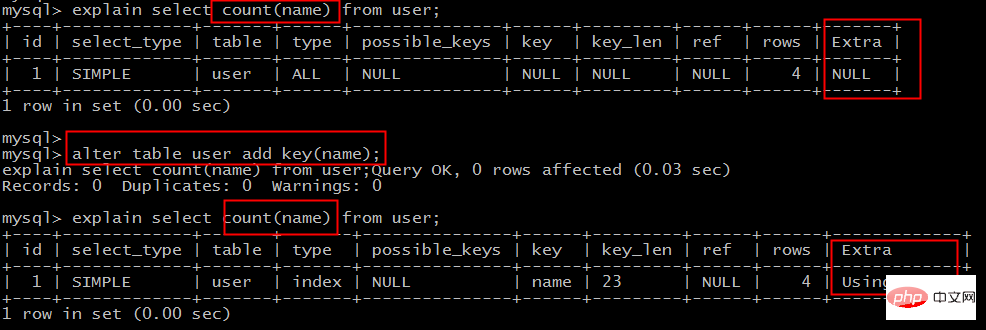
原表为:user(PK id, name, sex);不能利用索引覆盖
select count(name) from user;
添加索引,就能够利用索引覆盖提效
alter table user add key(name);
场景2:列查询回表优化
这个例子不再赘述,将单列索引(name)升级为联合索引(name, sex),即可避免回表。
场景3:分页查询
将单列索引(name)升级为联合索引(name, sex),也可以避免回表。
1.5、前缀索引
前缀索引说白了就是对文本的前几个字符(具体是几个字符在建立索引时指定)建立索引,这样建立起来的索引更小,所以查询更快。
ALTER TABLE table_name ADD KEY(column_name(prefix_length));
MySQL 前缀索引能有效减小索引文件的大小,提高索引的速度。但是前缀索引也有它的坏处:MySQL 不能在 ORDER BY 或 GROUP BY 中使用前缀索引,也不能把它们用作覆盖索引(Covering Index)。
1.6、索引合并
深入理解 index merge 是使用索引进行优化的重要基础之一。理解了 index merge 技术,我们才知道应该如何在表上建立索引。
为什么会有index merge?
我们的 where 中可能有多个条件(或者join)涉及到多个字段,它们之间进行 AND 或者 OR,那么此时就有可能会使用到 index merge 技术。index merge 技术如果简单的说,其实就是:对多个索引分别进行条件扫描,然后将它们各自的结果进行合并(intersect/union)。
MySQL5.0之前,一个表一次只能使用一个索引,无法同时使用多个索引分别进行条件扫描。但是从5.1开始,引入了 index merge 优化技术,对同一个表可以使用多个索引分别进行条件扫描。
索引合并是指分别创建的两个索引,在某一次查询中临时合并成一条索引。
# 索引合并 create index ind_id on 表名(id); create index ind_email on 表名(email); select * from 表名 where id=100 or email = 'pamela@123.com' # 索引合并,临时把两个索引ind_id和ind_email合并成一个索引
1.7、索引下推
(1)索引下推简介
索引条件下推(Index Condition Pushdown),简称ICP。MySQL5.6新添加,用于优化数据的查询。 通过索引下推对于非主键索引进行优化,可有效减少回表次数,从而提高效率。
如果没有索引下推优化(或称ICP优化),当进行索引查询时,首先根据索引来查找记录,然后再根据where条件来过滤记录;在支持ICP优化后,MySQL会在取出索引的同时,判断是否可以进行where条件过滤再进行索引查询,也就是说提前执行where的部分过滤操作,在某些场景下,可以大大减少回表次数,从而提升整体性能。
当你不使用ICP,通过使用非主键索引(普通索引or二级索引)进行查询,存储引擎通过索引检索数据,然后返回给MySQL服务器,服务器再判断是否符合条件。
使用ICP,当存在索引的列做为判断条件时,MySQL服务器将这一部分判断条件传递给存储引擎,然后存储引擎通过判断索引是否符合MySQL服务器传递的条件,只有当索引符合条件时才会将数据检索出来返回给MySQL服务器。
(2)适用场景
当需要整表扫描,e.g.:range,ref,eq_ref....
适用InnoDB引擎和MyISAM引擎查询(5.6版本不适用分区查询,5.7版本可以用于分区表查询)。
InnoDB引擎仅仅适用二级索引。(原因InnoDB聚簇索引将整行数据读到InnoDB缓冲区)。
子查询条件不能下推。触发条件不能下推,调用存储过程条件不能下推。
二、索引优化规则
查询的条件字段尽量用索引字段
2.0、and/or条件相连
and条件相连,有一列有索引就会命中索引,加快查询速度;or条件相连,所有列都有索引才能命中索引,加快查询速度;
create index mix_ind on 表名 (id); select * from 表名 where id = 123 and name = 'pamela'; # 有一列有索引,速度快 select * from 表名 where id = 123 or name = 'pamela'; # 不是所有列都有索引,速度慢
2.1、like语句的前导模糊查询不能使用索引
select * from doc where title like '%XX'; --不能使用索引 select * from doc where title like 'XX%'; --非前导模糊查询,可以使用索引
因为页面搜索严禁左模糊或者全模糊,如果需要可以使用搜索引擎来解决。
2.2、union、in、or 都能够命中索引,建议使用 in
union能够命中索引,并且MySQL 耗费的 CPU 最少。
select * from doc where status=1 union all select * from doc where status=2;
in能够命中索引,查询优化耗费的 CPU 比 union all 多,但可以忽略不计,一般情况下建议使用 in。
select * from doc where status in (1, 2);
or 新版的 MySQL(MySQL5.0后) 索引合并能够命中索引,查询优化耗费的 CPU 比 in多,不建议频繁用or。
select * from doc where status = 1 or status = 2
补充:有些地方说在where条件中使用or,索引会失效,造成全表扫描,这是个误区:
要求where子句使用的所有字段,都必须建立索引;
如果数据量太少,mysql制定执行计划时发现全表扫描比索引查找更快,所以会不使用索引;
确保mysql版本5.0以上,且查询优化器开启了index_merge_union=on, 也就是变量optimizer_switch里存在index_merge_union且为on。
2.3、负向条件查询不能使用索引
负向条件有:!=、<>、not in、not exists、not like 等。
例如下面SQL语句:
select * from doc where status != 1 and status != 2;
可以优化为 in 查询:
select * from doc where status in (0,3,4);
2.4、联合索引最左前缀原则
如果在(a,b,c)三个字段上建立联合索引,那么他会自动建立 a| (a,b) | (a,b,c)组索引。联合索引遵循最左前缀原则(必须带着最左边的列做条件才能命中索引),且从出现范围开始索引失效;
create index mix_ind on 表名 (id,name,email); select * from 表名 where id = 123; # 命中索引 select * from 表名 where id > 123; # 不命中索引,因为出现范围 select * from 表名 where id = 123 and name = 'pamela'; # 命中索引 select * from 表名 where id > 123 and name = 'pamela'; # 不命中索引,因为出现范围 select * from 表名 where id = 123 and email = 'pamela@123.com'; # 命中索引 select * from 表名 where email = 'pamela@123.com'; # 不命中索引,因为条件中没有id select * from 表名 where name='pamela' and email = 'pamela@123.com'; # 不命中索引,因为条件中没有id
登录业务需求,SQL语句如下:
select uid, login_time from user where login_name=? andpasswd=?
可以建立(login_name, passwd)的联合索引。因为业务上几乎没有passwd 的单条件查询需求,而有很多login_name 的单条件查询需求,所以可以建立(login_name, passwd)的联合索引,而不是(passwd, login_name)。
2.5、不能使用索引中范围条件右边的列(范围列可以用到索引),范围列之后列的索引全失效。
范围条件有:<、<=、>、>=、between等。
索引最多用于一个范围列,如果查询条件中有两个范围列则无法全用到索引。
假如有联合索引 (empno、title、fromdate),那么下面的 SQL 中 emp_no 可以用到索引,而title 和 from_date 则使用不到索引。
select * from employees.titles where emp_no < 10010' and title='Senior Engineer'and from_date between '1986-01-01' and '1986-12-31'
2.6、不要在索引列上面做任何操作(计算、函数),否则会导致索引失效而转向全表扫描。
例如下面的 SQL 语句,即使 date 上建立了索引,也会全表扫描:
select * from doc where YEAR(create_time) <= '2016';
可优化为值计算,如下:
select * from doc where create_time <= '2016-01-01';
比如下面的 SQL 语句:
select * from order where date < = CURDATE();
可以优化为:
select * from order where date < = '2018-01-2412:00:00';
2.7、强制类型转换会全表扫描
字符串类型不加单引号会导致索引失效,因为mysql会自己做类型转换,相当于在索引列上进行了操作。
如果 phone 字段是 varchar 类型,则下面的 SQL 不能命中索引。
select * from user where phone=13800001234
可以优化为:
select * from user where phone='13800001234';
2.8、更新十分频繁、数据区分度不高的列不宜建立索引
更新会变更 B+ 树,更新频繁的字段建立索引会大大降低数据库性能。
“性别”这种区分度不大的属性,建立索引是没有什么意义的,不能有效过滤数据,性能与全表扫描类似。
一般区分度在80%以上的时候就可以建立索引,区分度可以使用 count(distinct(列名))/count(*) 来计算。
2.9、利用覆盖索引来进行查询操作,避免回表,减少select * 的使用
覆盖索引:查询的列和所建立的索引的列个数相同,字段相同。
被查询的列,数据能从索引中取得,而不用通过行定位符 row-locator 再到 row 上获取,即“被查询列要被所建的索引覆盖”,这能够加速查询速度。
例如登录业务需求,SQL语句如下。
select uid, login_time from user where login_name=? and passwd=?
可以建立(login_name, passwd, login_time)的联合索引,由于 login_time 已经建立在索引中了,被查询的 uid 和 login_time 就不用去 row 上获取数据了,从而加速查询。
2.10、索引不会包含有NULL值的列
只要列中包含有NULL值都将不会被包含在索引中,复合索引中只要有一列含有NULL值,那么这一列对于此复合索引就是无效的。所以我们在数据库设计时,尽量使用not null 约束以及默认值。
2.11、is null, is not null无法使用索引
2.12、如果有order by、group by的场景,请注意利用索引的有序性
order by 最后的字段是组合索引的一部分,并且放在索引组合顺序的最后,避免出现file_sort 的情况,影响查询性能。
例如对于语句 where a=? and b=? order by c,可以建立联合索引(a,b,c)。
如果索引中有范围查找,那么索引有序性无法利用,如 WHERE a>10 ORDER BY b;,索引(a,b)无法排序。
2.13、使用短索引(前缀索引)
对列进行索引,如果可能应该指定一个前缀长度。例如,如果有一个CHAR(255)的列,如果该列在前10个或20个字符内,可以做到既使得前缀索引的区分度接近全列索引,那么就不要对整个列进行索引。因为短索引不仅可以提高查询速度而且可以节省磁盘空间和I/O操作,减少索引文件的维护开销。可以使用count(distinct leftIndex(列名, 索引长度))/count(*) 来计算前缀索引的区分度。
但缺点是不能用于 ORDER BY 和 GROUP BY 操作,也不能用于覆盖索引。
不过很多时候没必要对全字段建立索引,根据实际文本区分度决定索引长度即可。
2.14、利用延迟关联或者子查询优化超多分页场景
MySQL 并不是跳过 offset 行,而是取 offset+N 行,然后返回放弃前 offset 行,返回 N 行,那当 offset 特别大的时候,效率就非常的低下,要么控制返回的总页数,要么对超过特定阈值的页数进行 SQL 改写。
示例如下,先快速定位需要获取的id段,然后再关联:
select a.* from 表1 a,(select id from 表1 where 条件 limit100000,20 ) b where a.id=b.id;
2.15、如果明确知道只有一条结果返回,limit 1 能够提高效率
比如如下 SQL 语句:
select * from user where login_name=?;
可以优化为:
select * from user where login_name=? limit 1
自己明确知道只有一条结果,但数据库并不知道,明确告诉它,让它主动停止游标移动。
2.16. 3개 이상의 테이블을 조인하지 않는 것이 가장 좋습니다
조인해야 하는 필드는 동일한 데이터 유형을 가져야 합니다. 여러 테이블을 쿼리할 때는 관련 필드에 인덱스가 있어야 합니다.
예를 들어 왼쪽 조인은 왼쪽에 의해 결정되고 왼쪽의 데이터가 있어야 하므로 오른쪽이 우리의 핵심이고 인덱스는 오른쪽에 구축되어야 합니다. 물론, 인덱스가 왼쪽에 있으면 오른쪽 조인을 사용할 수 있습니다.
2.17. 단일 테이블 인덱스 수는 5개 이내로 제어하는 것이 좋습니다.
2.18.SQL 성능 최적화 설명의 유형은 최소한 범위 수준에 도달해야 하며 요구 사항은 ref 수준입니다. const일 수 있다면 가장 좋습니다
consts: 단일 테이블에는 최대 하나의 일치하는 행(기본 키 또는 고유 인덱스)이 있으며 최적화 단계에서 데이터를 읽을 수 있습니다.
ref: 일반 인덱스를 사용합니다.
range: 인덱스에서 범위 검색을 수행합니다.
type=index인 경우 인덱싱된 모든 실제 파일을 검색하므로 속도가 매우 느립니다.
2.19. 비즈니스에서 고유한 특성을 갖는 필드는 여러 필드의 조합이라 하더라도 고유 인덱스로 구축해야 합니다.
고유 인덱스가 삽입 속도에 영향을 미칠 수 있다고 생각하지 마세요. 무시되지만 검색 속도가 향상되는 것은 분명합니다. 또한 애플리케이션 계층에서 매우 완벽한 검증 제어를 구현하더라도 머피의 법칙에 따라 고유 인덱스가 없는 한 더티 데이터는 필연적으로 생성됩니다.
2.20. 인덱스를 생성할 때 다음과 같은 오해를 피하세요.
인덱스가 많을수록 좋습니다. 쿼리가 필요하다고 생각되면 인덱스를 만드세요. 인덱스는 공간을 소비하고 업데이트 및 새로운 추가 속도를 심각하게 느리게 하기 때문에 너무 많지 않은 것이 좋습니다.
고유한 인덱스에 저항하고 비즈니스의 고유성은 "선 확인 후 삽입"을 통해 애플리케이션 레이어에서 해결되어야 한다고 믿습니다.
미숙한 최적화, 시스템을 이해하지 못한 채 최적화를 시작합니다.
3. 인덱스를 사용하고 인덱스를 사용하지 않음
3.1 인덱스 사용
기본 키는 자동으로 고유한 인덱스를 생성합니다.
WHERE 또는 ORDER BY 문에 쿼리 조건으로 자주 나타나는 열을 색인화해야 합니다.
쿼리에서는 다른 테이블 및 외래 키 관계와 관련된 필드가 인덱싱됩니다.
min(), max() 등 집계 함수 등 집계 함수에서 자주 사용되는 열은 색인화해야 합니다.
3.2. 인덱스를 사용하지 마세요.
자주 추가, 삭제, 수정되는 열에 대해서는 인덱스를 생성하지 마세요.
인덱싱되지 않은 중복 열이 많이 있습니다.
테이블 레코드가 너무 적으면 인덱스를 생성하지 마세요. 데이터가 적기 때문에 인덱스를 순회하는 것보다 모든 데이터를 쿼리하는 데 시간이 덜 걸릴 수 있고 인덱스가 최적화 효과를 내지 못할 수도 있습니다.
추천 학습: mysql 비디오 튜토리얼
위 내용은 MySQL 인덱스 최적화 지식 포인트 요약 및 구성의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7338
7338
 9
1627
14
1352
46
1265
25
1210
29
9
1627
14
1352
46
1265
25
1210
29

 PHP의 빅데이터 구조 처리 능력
May 08, 2024 am 10:24 AM
PHP의 빅데이터 구조 처리 능력
May 08, 2024 am 10:24 AM
빅 데이터 구조 처리 기술: 청킹(Chunking): 데이터 세트를 분할하고 청크로 처리하여 메모리 소비를 줄입니다. 생성기: 전체 데이터 세트를 로드하지 않고 데이터 항목을 하나씩 생성하므로 무제한 데이터 세트에 적합합니다. 스트리밍: 파일을 읽거나 결과를 한 줄씩 쿼리하므로 대용량 파일이나 원격 데이터에 적합합니다. 외부 저장소: 매우 큰 데이터 세트의 경우 데이터를 데이터베이스 또는 NoSQL에 저장합니다.
 PHP에서 MySQL 쿼리 성능을 최적화하는 방법은 무엇입니까?
Jun 03, 2024 pm 08:11 PM
PHP에서 MySQL 쿼리 성능을 최적화하는 방법은 무엇입니까?
Jun 03, 2024 pm 08:11 PM
선형 복잡성에서 로그 복잡성까지 조회 시간을 줄이는 인덱스를 구축하여 MySQL 쿼리 성능을 최적화할 수 있습니다. SQL 삽입을 방지하고 쿼리 성능을 향상하려면 PREPAREDStatements를 사용하세요. 쿼리 결과를 제한하고 서버에서 처리되는 데이터의 양을 줄입니다. 적절한 조인 유형 사용, 인덱스 생성, 하위 쿼리 사용 고려 등 조인 쿼리를 최적화합니다. 쿼리를 분석하여 병목 현상을 식별하고, 캐싱을 사용하여 데이터베이스 로드를 줄이고, 오버헤드를 최소화합니다.
 PHP에서 MySQL 백업 및 복원을 사용하는 방법은 무엇입니까?
Jun 03, 2024 pm 12:19 PM
PHP에서 MySQL 백업 및 복원을 사용하는 방법은 무엇입니까?
Jun 03, 2024 pm 12:19 PM
PHP에서 MySQL 데이터베이스를 백업하고 복원하는 작업은 다음 단계에 따라 수행할 수 있습니다. 데이터베이스 백업: mysqldump 명령을 사용하여 데이터베이스를 SQL 파일로 덤프합니다. 데이터베이스 복원: mysql 명령을 사용하여 SQL 파일에서 데이터베이스를 복원합니다.
 PHP를 사용하여 MySQL 테이블에 데이터를 삽입하는 방법은 무엇입니까?
Jun 02, 2024 pm 02:26 PM
PHP를 사용하여 MySQL 테이블에 데이터를 삽입하는 방법은 무엇입니까?
Jun 02, 2024 pm 02:26 PM
MySQL 테이블에 데이터를 삽입하는 방법은 무엇입니까? 데이터베이스에 연결: mysqli를 사용하여 데이터베이스에 대한 연결을 설정합니다. SQL 쿼리 준비: 삽입할 열과 값을 지정하는 INSERT 문을 작성합니다. 쿼리 실행: query() 메서드를 사용하여 삽입 쿼리를 실행하면 확인 메시지가 출력됩니다.
 MySQL 8.4에서 mysql_native_password가 로드되지 않음 오류를 수정하는 방법
Dec 09, 2024 am 11:42 AM
MySQL 8.4에서 mysql_native_password가 로드되지 않음 오류를 수정하는 방법
Dec 09, 2024 am 11:42 AM
MySQL 8.4(2024년 최신 LTS 릴리스)에 도입된 주요 변경 사항 중 하나는 "MySQL 기본 비밀번호" 플러그인이 더 이상 기본적으로 활성화되지 않는다는 것입니다. 또한 MySQL 9.0에서는 이 플러그인을 완전히 제거합니다. 이 변경 사항은 PHP 및 기타 앱에 영향을 미칩니다.
 PHP에서 MySQL 저장 프로시저를 사용하는 방법은 무엇입니까?
Jun 02, 2024 pm 02:13 PM
PHP에서 MySQL 저장 프로시저를 사용하는 방법은 무엇입니까?
Jun 02, 2024 pm 02:13 PM
PHP에서 MySQL 저장 프로시저를 사용하려면: PDO 또는 MySQLi 확장을 사용하여 MySQL 데이터베이스에 연결합니다. 저장 프로시저를 호출하는 문을 준비합니다. 저장 프로시저를 실행합니다. 결과 집합을 처리합니다(저장 프로시저가 결과를 반환하는 경우). 데이터베이스 연결을 닫습니다.
 PHP를 사용하여 MySQL 테이블을 만드는 방법은 무엇입니까?
Jun 04, 2024 pm 01:57 PM
PHP를 사용하여 MySQL 테이블을 만드는 방법은 무엇입니까?
Jun 04, 2024 pm 01:57 PM
PHP를 사용하여 MySQL 테이블을 생성하려면 다음 단계가 필요합니다. 데이터베이스에 연결합니다. 데이터베이스가 없으면 작성하십시오. 데이터베이스를 선택합니다. 테이블을 생성합니다. 쿼리를 실행합니다. 연결을 닫습니다.
 오라클 데이터베이스와 mysql의 차이점
May 10, 2024 am 01:54 AM
오라클 데이터베이스와 mysql의 차이점
May 10, 2024 am 01:54 AM
Oracle 데이터베이스와 MySQL은 모두 관계형 모델을 기반으로 하는 데이터베이스이지만 호환성, 확장성, 데이터 유형 및 보안 측면에서 Oracle이 우수하고, MySQL은 속도와 유연성에 중점을 두고 중소 규모 데이터 세트에 더 적합합니다. ① Oracle은 광범위한 데이터 유형을 제공하고, ② 고급 보안 기능을 제공하고, ③ 엔터프라이즈급 애플리케이션에 적합하고, ① MySQL은 NoSQL 데이터 유형을 지원하고, ② 보안 조치가 적고, ③ 중소 규모 애플리케이션에 적합합니다.
