

Python의 API 호출에 대한 자세한 설명 및 예

이 글은 python에 대한 관련 지식을 제공하며, API 호출 및 데이터 인터페이스 호출, 요청 방법, 몇 가지 일반적인 API 호출 예제 등을 포함하여 API 호출과 관련된 문제를 주로 소개합니다. 아래 내용을 살펴보겠습니다. 모든 사람에게 도움이 되기를 바랍니다.

추천 학습: python 비디오 튜토리얼
일상 업무에서는 해당 데이터를 얻거나 해당 기능을 구현하기 위해 인터넷의 일부 최신 API 또는 회사에서 제공하는 데이터 인터페이스를 결합해야 할 수도 있습니다.
따라서 API 호출 및 데이터 인터페이스 액세스는 데이터 분석을 위한 일반적인 작업입니다. API 및 데이터 인터페이스에 대한 호출을 빠르게 구현하는 방법은 일반적으로 온라인에서 사용할 수 있지만 소스를 추적하는 데 사용되는 방법은 모두 HTTP 요청입니다. 구현하다.
API
API: 간단히 말해서 서로 다른 애플리케이션 간의 통신 방법을 정의하고 특정 구현 프로세스를 숨기고 개발자가 호출해야 하는 부분만 노출하는 프로토콜 집합, 도구 또는 규칙 집합입니다. 사용 .
위의 정의는 비교적 공식적인 것입니다. 예를 들어 외부 맥도날드와 같은 패스트푸드 레스토랑에서는 이제 휴대폰을 사용하여 온라인으로 주문하고 프런트 데스크에서 식사를 픽업합니다. 이 과정에서 소비자는 일반적으로 휴대폰에서 해당 식사를 선택하고 클릭하여 주문하고 결제한 후 프런트 데스크에서 식사를 픽업할 번호로 전화할 때까지 기다립니다. 우리는 이 프로세스가 어떻게 구현되는지 정확히 알지 못합니다. 전체 프로세스에는 주방 데이터와 통신하는 해당 앱이나 작은 프로그램이 있고 요리사가 식사를 준비합니다. 이 APP와 애플릿은 해당 API 기능으로 사용됩니다.
간단히 예를 들자면, 소셜 플랫폼은 매일 다양한 언어로 댓글을 받습니다. 분석가로서 복잡한 언어 데이터 처리에 직면하는 것은 번역을 달성하기 위한 모델을 개발해야 한다고 말할 수도 있습니다. 기능을 통합하는 방법은 실현 가능해 보이지만 비용이 많이 듭니다. 둘째, 문제를 해결하려면 더 어려운 문제를 개발해야 합니다. 이는 원래 목표에서 점점 더 멀어지고 있으며, 이때 상대적으로 성숙한 국내 번역 플랫폼 API를 사용하여 기존 데이터를 직접 처리할 수 있습니다. 이는 상대적으로 저렴하고 편리하며 기존 목표를 빠르게 달성할 수 있습니다. 여기서 API의 역할에 대해서는 의심의 여지가 없습니다.
데이터 인터페이스
데이터 인터페이스: 간단히 말해서 캡슐화된 데이터 세트 비밀번호 세트입니다. 이는 해당 규칙에 따라 해당 매개변수를 전송한 다음 해당 관련 데이터 정보를 반환하는 것을 의미합니다. API 호출과 데이터 인터페이스는 일상적인 호출에서 매우 유사합니다. 상대적으로 말하면 API는 더 넓은 범위를 가지며 더 많은 기능을 구현하는 반면 데이터 인터페이스는 데이터 수집 도구로 더 많은 역할을 합니다.
예를 들어 대형 전자상거래 회사는 일반적으로 통합 SKU를 사용하여 제품을 관리합니다. 예를 들어 이 회사는 브랜드 소유자이고 다른 플랫폼에서 판매하며 이러한 플랫폼에 매핑된 제품 로고의 ID는 회사의 SKU와 다릅니다. 회사의 SKU는 제품을 기반으로 할 뿐만 아니라 다양한 현지 창고와 다양한 제품 모델을 고려하기 때문에 이 매핑은 상대적으로 복잡합니다.
다양한 플랫폼에서 데이터를 다루는 사람들은 일반적으로 회사의 데이터베이스를 직접 사용하여 제품을 분석할 수 없습니다. 왜냐하면 세분화가 너무 미세하여 분석이 더 복잡하고 어려워지기 때문입니다. 이때 개발은 기존 시스템에 따라 수행될 수 있습니다. 복잡한 데이터베이스 프로세스 등 해당 정보를 직접 요청하지 않도록 해당 기업에 별도의 데이터 인터페이스를 제공하는 것입니다. 그러나 실시간 데이터베이스에 비해 데이터 인터페이스에는 일정한 지연이 있습니다.
API 호출 및 데이터 인터페이스 호출
API 및 데이터 인터페이스는 이전 예제를 통해 논의되었으며, 대략적으로 이해하면 비교적 간단합니다. API 호출 및 데이터 인터페이스 호출을 구현하는 방법에 대해 간략하게 소개합니다.
간단히 말해서 API 호출과 인터페이스 호출은 HTTP 요청과 유사합니다. 호출하는 가장 중요한 것은 해당 규칙에 따라 요청 메서드, 요청 헤더, URL 및 요청 본문을 캡슐화한 다음 요청을 보내는 것입니다. 해당 통화.
그러나 데이터 인터페이스 및 API 호출에 비해 일반 데이터 인터페이스는 상대적으로 간단한 경우가 많으며 데이터 인터페이스는 회사 인트라넷에서 데이터 액세스에 사용되므로 정보 요청이 상대적으로 간단하며 API는 대부분 개발됩니다. 이 서비스는 상대적으로 요청의 보안을 보장하기 위해 AK, SK, 서명 및 기타 정보를 추가하는 것이 더 복잡합니다. 타임스탬프.
소스를 역추적하기 위한 두 호출은 HTTP 요청과 유사합니다. 주로 API 호출에 요청 매개변수에 대한 더 많은 정보가 포함되어 있기 때문입니다. 구체적인 구현 방법은 아래에서 간략히 소개하겠습니다.
호출의 기본 - 요청 방법
일반적으로 일반적인 HTTP 요청 호출 방법이 많이 있습니다. 이 영역에는 두 가지 일반적인 요청 방법이 있습니다.
GET 요청
GET 요청은 단순히 서버에서 리소스를 얻고 브라우저의 캐시에 로드될 수 있습니다.
POST 요청
POST 요청은 일반적으로 양식 형태로 서버에 요청을 보냅니다. 요청 본문에 포함된 요청 매개변수는 리소스 생성 및 변경으로 이어질 수 있습니다. POST 요청의 정보는 브라우저에 캐시될 수 없습니다.
이 두 가지 요청 방법은 매우 간단하지만 가장 중요한 점은 이 두 요청의 차이점을 이해하여 인터페이스 디자인과 API 사용에 더 익숙해지는 것입니다.
GET 요청과 POST 요청의 차이점
1. GET 요청의 요청 길이는 최대 1024kb이며 POST는 요청 데이터에 제한이 없습니다. 그 이유는 GET 요청이 해당 정보를 URL에 넣는 경우가 많으며, URL의 길이가 제한되어 GET 요청 길이에 일정한 제한이 있기 때문입니다. POST 요청의 해당 매개변수 정보는 요청 본문에 배치되므로 일반적으로 길이 제한이 적용되지 않습니다.
2. POST 요청은 GET보다 안전합니다. GET 요청의 URL에 해당 정보가 포함되어 있고 페이지가 브라우저에 캐시되어 다른 사람들이 해당 정보를 볼 수 있기 때문입니다.
3.GET은 하나의 TCP 데이터 패킷을 생성하고, POST는 두 개의 TCP 데이터 패킷을 생성합니다.
GET 요청을 하면 헤더와 데이터가 함께 전송되고 서버는 200으로 응답합니다. POST는 먼저 헤더를 보내고 서버가 100으로 응답할 때까지 기다린 다음 데이터를 보내고 마지막으로 서버가 200으로 응답합니다. 하지만 여기서 POST 요청은 두 번으로 나뉘지만 요청 본문은 헤더 바로 다음에 전송됩니다. , 따라서 이 사이의 시간은 무시할 수 있습니다.
4. GET 요청은 URL 인코딩만 지원하는 반면 POST에는 다양한 인코딩 방법이 있습니다.
5. GET 요청 매개변수는 URL을 통해 전달되고, 여러 매개변수는 &로 연결되며, POST 요청은 요청 본문에 배치됩니다.
6.GET 요청은 ASCII 문자만 지원하지만 POST에는 제한이 없습니다.
일반적으로 브라우저에서 직접 접근할 수 있는 URL은 GET 요청인 경우가 많습니다.
Python은 GET 요청과 POST 요청을 구현합니다
위에서는 몇 가지 데이터 인터페이스, API 관련 지식 및 요청 방법을 많은 시간에 소개했습니다. 아래에서는 사용하기가 비교적 간단합니다. 해당 요청 방법. 일반적으로 Python의 요청 라이브러리를 직접 사용할 수 있습니다.
GET 요청
import request
# GET请求发送的参数一定要是字典的形式,可以发送多个参数。
# 发送格式:{'key1':value1', 'key2':'value2', 'key3', 'value3'}
# 样例不能运行
url ='http://www.xxxxx.com'
params = {'user':'lixue','password':111112333}
requests.get(url,data = parms)POST 요청
POST 요청에는 일반적으로 세 가지 제출 양식이 있습니다: application/x-www-form-urlencoded, multipart/form-data, application/json.
볼 수 있는 세 가지 유형이 있습니다. 구체적으로 어떤 요청 방법인지 확인하세요: Google Chrome → 네트워크 → 파일 로드 선택 → 헤더 → Reuqest 헤더 → Content-Type
구체적인 인코딩 방법은 다음 세 가지입니다. 일반적으로 회사 내부에서 구현됩니다. 데이터 인터페이스는 LAN으로 설정되므로 일부는 헤더를 추가할 필요가 없습니다.
POST 요청의 세 가지 제출 형식
1. 가장 일반적인 사후 제출 데이터는 주로 양식 형식입니다: application/x-www-form-urlencoded
import request
data={'k1':'v1','k2':'v2'}
headers= {'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36'}
requests.post(url,headers = headers,data=data)2. json 형식으로 데이터를 제출합니다: application/json
data = {'user':'lixue','password':12233}
data_json = json.dumps(params)
requests.post(url,headers = headers,data = data_json)3. 일반적으로 파일 전송에 사용됩니다(크롤러에서는 거의 사용되지 않음): multipart/form-data
files = {'files':open('c://xxx.txt','rb')}
requests.post(url = url,headers = headers,files = files)간단한 API 요청의 예
위의 간단한 소개를 통해 특정 요청에 대한 일반적인 이해를 가질 수 있습니다. , 여기에 수집됨 많은 유용한 기능을 제공하는 간단한 API 집계 센터가 생성되었습니다. 다음은 이 간단한 API를 간단한 데모 API 주소로 사용합니다.
이 작은 예는 날씨 API 인터페이스를 사용하여 지난 15일 동안의 날씨를 가져옵니다. 이 API를 사용하기 전에 해당 apiKey를 얻고 특정 사용 문서를 확인하는 것을 잊지 마세요. 이 API 웹사이트는 일반적으로 학습에 사용할 수 있는 해당 API에 대해 일정 횟수의 무료 시간을 제공하고 GET 및 POST 요청을 지원합니다. 연습하기에 딱 맞습니다.
GET 요청
params = {
"apiKey":'换成你的apikey',
"area":'武汉市',
}
url = 'https://api.apishop.net/common/weather/get15DaysWeatherByArea'
response = requests.get(url,params)
print(response.text)POST 요청
여기의 POST 요청은 위의 가장 일반적인 게시물 제출 데이터에 해당하며 주로 양식 형식: application/x-www-form-urlencoded
url = 'https://api.apishop.net/common/weather/get15DaysWeatherByArea'
params = {
"apiKey":'换成你的apikey',
"area":'武汉市武昌区',
}
response = requests.post(url,params)
print(response.text)이 API 인터페이스를 호출합니다. 일반적으로 다음과 같습니다. 요청이 정상인지 확인하기 위해 상태 코드 및 기타 반환 정보 테스트를 수행하는 데 필요한 다음을 참조할 수 있습니다.
params = {
"apiKey":'换成你的apikey,
"area":'武汉市',
}
url = 'https://api.apishop.net/common/weather/get15DaysWeatherByArea'
response = requests.post(url,params)
print(response.text)
if response.status_code != 200:
raise ConnectionError(f'{url} status code is {response.status_code}.')
response = json.loads(response.content)
if 'desc' not in response.keys():
raise ValueError(f'{url} miss key msg.')
if response['desc'] != '请求成功':
print(11)데이터 추출
사실 API 호출은 매우 간단하지만 그 핵심은 반환된 정보에서 데이터를 추출하는 것입니다. 일반적으로 반환되는 정보는 json 형식이므로 데이터를 추출해야 합니다. 사전 키-값 쌍을 사용하여 다음 블록은 요청된 데이터를 기반으로 해당 정보를 반환하고 이를 추출합니다. 얻은 정보는 나중에 표시됩니다.
import requestsimport pandas as pd
import numpy as npimport jsondef get_url(area):
url = 'https://api.apishop.net/common/weather/get15DaysWeatherByArea'
params = {
"apiKey":'换成你的apikey',
"area":area,
}
response = requests.get(url,params)
if response.status_code != 200:
raise ConnectionError(f'{url} status code is {response.status_code}.')
response = json.loads(response.content)
if 'desc' not in response.keys():
raise ValueError(f'{url} miss key msg.')
if response['desc'] != '请求成功':
print(11)
return responsedef extract_data(web_data):
data= web_data['result']['dayList']
weather_data = pd.DataFrame(columns = ['city','daytime','day_weather','day_air_temperature','day_wind_direction','day_wind_power', 'night_weather','night_air_temperature','night_wind_direction','night_wind_power'])
for i in range(len(data)):
city = data[i]["area"]
daytime = data[i]["daytime"]
daytime = daytime[:4]+'-'+daytime[4:6]+'-'+daytime[-2:]
day_weather = data[i]["day_weather"]
day_air_temperature = data[i]['day_air_temperature']
day_wind_direction = data[i]["day_wind_direction"]
day_wind_power = data[i]['day_wind_power']
night_weather = data[i]['night_weather']
night_air_temperature = data[i]["night_air_temperature"]
night_wind_direction = data[i]['night_wind_direction']
night_wind_power = data[i]["night_wind_power"]
c = {"city": city,"daytime": daytime,"day_weather":day_weather,"day_air_temperature":day_air_temperature,
"day_wind_direction":day_wind_direction,"day_wind_power":day_wind_power,"night_weather":night_weather,
"night_air_temperature":night_air_temperature,"night_wind_direction":night_wind_direction,
"night_wind_power":night_wind_power}
weather_data = weather_data.append(c,ignore_index = True)
weather_data.to_excel(r"C:\Users\zhangfeng\Desktop\最近十五天天气.xlsx",index = None)
return weather_dataif __name__ == '__main__':
print("请输入对应的城市")
web_data = get_url(input())
weather_data = extract_data(web_data)결과의 일부는 다음과 같습니다. 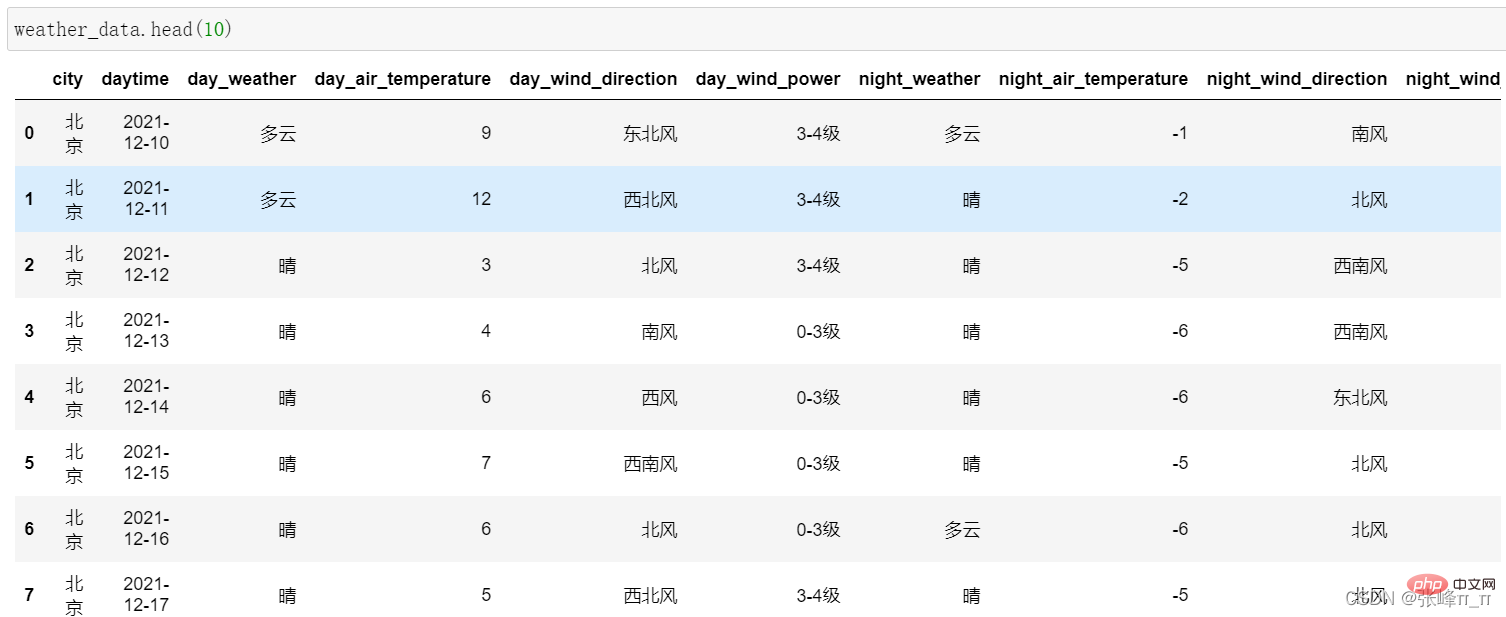
데이터 인터페이스 예제
일상 학습에서는 데이터 인터페이스의 사용이 상대적으로 드물 수 있습니다. 대부분의 경우 데이터 인터페이스의 적용 시나리오는 학습 내에서 데이터를 검색하는 데 사용됩니다. 회사가 많기 때문에 여기서는 작업 시 발생하는 두 가지 데이터 인터페이스의 사용을 보여줍니다. 표시된 코드는 샘플이므로 호출할 수 없습니다. 호출 구현 및 사양을 참조할 수 있습니다.
POST请求调用数据接口
# 销售状态查询def id_status(id_dir):
id_data = pd.read_excel(id_dir,sheet_name="Sheet1")
id_data.columns = ['shop', 'Campaign Name','Ad Group Name','Item Id'] # 方便后期处理更改列名
id_data["Item Id"] = id_data["Item Id"].astype(str)
id_list = list(id_data['Item Id'])
print(len(id_list))
id_list = ','.join(id_list)
if isinstance(id_list, int):
id_list = str(id_list)
id1 = id_list.strip().replace(',', ',').replace(' ', '')
request_url = "http://xxx.com"
# 通过item_id查询id状态
params = {
"item_id":id1,
}
data_json = json.dumps(params) # 属于POST第二种请求方式
response = requests.post(request_url, data = data_json)
print(response.text)
if response.status_code != 200:
raise ConnectionError(f'{request_url} status code is {response.status_code}.')
response = json.loads(response.content)
if 'message' not in response.keys():
raise ValueError(f'{request_url} miss key msg.')
if response['message'] != 'ok':
print(11)
data= response['result']
ad_data = pd.DataFrame(columns = ['Item Id','saleStatusName'])
for j in range(len(data)):
item_id =data[j]["item_id"]
saleStatusName = data[j]['saleStatusName']
c = {"Item Id": item_id,
"saleStatusName": saleStatusName,
}
ad_data = ad_data.append(c,ignore_index = True)
total_data = pd.merge(ad_data,id_data,on ='Item Id', how ='left')
df_column = ['shop', 'Campaign Name','Ad Group Name','Item Id','saleStatusName']
total_data = total_data.reindex(columns=df_column)
return total_dataGET请求调用数据接口
### 库存数据查询def Smart_investment_treasure(investment_dir):
product_data = pd.read_excel(investment_dir,sheet_name="product")
if len(product_data)>0:
product_data['商品ID']=product_data['商品ID'].astype(str)
product_list=list(product_data['商品ID'])
product_id = ','.join(product_list)
else:
product_id='没有数据'
return product_id
def stock_query(investment_dir):
product_data = pd.read_excel(investment_dir,sheet_name="product")
if len(product_data)>0:
product_data['商品ID']=product_data['商品ID'].astype(str)
product_list=list(product_data['商品ID'])
product_id = ','.join(product_list)
else:
product_id='没有数据'
if isinstance(product_id, int):
product_id = str(id)
product_id = product_id.strip().replace(',', ',').replace(' ', '')
request_url = "http://xxx.com"
# 通过ali_sku查询erpsku
params = {
"product_id":product_id,
}
response = requests.get(request_url, params) #属于GET请求
if response.status_code != 200:
raise ConnectionError(f'{request_url} status code is {response.status_code}.')
response = json.loads(response.content)
if 'msg' not in response.keys():
raise ValueError(f'{request_url} miss key msg.')
if response['msg'] != 'success':
print(11)
data= response['data']['data']
# requestProductId = id.split(',')
id_state=[]
overseas_stock=[]
china_stock=[]
id_list=[]
for j in range(len(data)):
inventory_data= data[j]['list']
overseas_inventory=0
ep_sku_list=[]
sea_test=0
china_inventory=0
test="paused"
id_test=""
id_test=data[j]['product_id']
for i in range(len(inventory_data)):
if inventory_data[i]["simple_code"] in ["FR","DE","PL","CZ","RU"] and inventory_data[i]["erp_sku"] not in ep_sku_list:
overseas_inventory+=inventory_data[i]["ipm_sku_stock"]
ep_sku_list.append(inventory_data[i]["erp_sku"])
sea_test=1
elif inventory_data[i]["simple_code"] == 'CN':
china_inventory+=int(inventory_data[i]["ipm_sku_stock"])
if overseas_inventory>30:
test="open"
elif overseas_inventory==0 and china_inventory>100:
test="open"
id_list.append(id_test)
overseas_stock.append(overseas_inventory)
china_stock.append(china_inventory)
id_state.append(test)
c={"id":id_list,
"id_state":id_state,
"海外仓库存":overseas_stock,
"国内大仓":china_stock }
ad_data=pd.DataFrame(c)
return ad_data几种常见API调用实例
百度AI相关API
百度API是市面上面比较成熟的API服务,在大二期间由于需要使用一些文本打标签和图像标注工作了解了百度API,避免了重复造轮子,当时百度API的使用比较复杂,参考文档很多不规范,之前也写过类似的百度API调用极其不稳定,但最近查阅了百度API参考文档,发现目前的调用非常简单。
通过安装百度开发的API第三方包,直接利用Python调包传参即可使用非常简单。这里展示一个具体使用,相应安装第三方库官方文档查阅。
''' 第三方包名称:baidu-aip 百度API """ 你的 APPID AK SK """ APP_ID = '你的 App ID' API_KEY = '你的 Api Key' SECRET_KEY = '你的 Secret Key' 参考文档:https://ai.baidu.com/ai-doc/NLP/tk6z52b9z ''' from aip import AipNlp APP_ID = 'xxxxxx' API_KEY = '换成你的apikey' SECRET_KEY = '换成你的SECRET_KEY' client = AipNlp(APP_ID, API_KEY, SECRET_KEY) text = "我还没饭吃" # 调用文本纠错 client.ecnet(text)

百度地图API
这个API当时为了设计一个推荐体系引入经纬度换算地址,这样为数据计算带来极大的方便,而且对于一般人来说文本地址相比经纬度信息更加直观,然后结合Python一个第三方包实现两个地址之间经纬度计算得出相对的距离。
# https://lbsyun.baidu.com/
# 计算校验SN(百度API文档说明需要此步骤)
import pandas as pd
import numpy as np
import warnings
import requests
import urllib
import hashlib
import json
from geopy.distance import geodesic
location = input("输入所在的位置\n") # "广州市天河区"
ak = "ak1111" # 参照自己的应用
sk = "sk111111" # 参照自己的应用
url = "http://api.map.baidu.com"
query = "/geocoding/v3/?address={0}&output=json&ak={1}&callback=showLocation".format(location, ak)
encodedStr = urllib.parse.quote(query, safe="/:=&?#+!$,;'@()*[]")
sn = hashlib.md5(urllib.parse.quote_plus(encodedStr + sk).encode()).hexdigest()
# 使用requests获取返回的json
response = requests.get("{0}{1}&sn={2}".format(url, query, sn))
data1=response.text.replace("showLocation&&showLocation(","").replace(")","")
data = json.loads(data1)
print(data)
lat = data["result"]["location"]["lat"]
lon = data["result"]["location"]["lng"]
print("纬度: ", lat, " 经度: ", lon)
distance=geodesic((lat,lon), (39.98028,116.30495))
print("距离{0}这个位置大概{1}".format(location, distance))
有道API
在网上查阅了很多API,前面介绍的几种API,他们携带的请求参数信息相对比较简单,调用实现和基础请求没啥区别,这里找了一个相对而言比较多的请求参数的API,相对而言这种API数据付费API,它的安全性以及具体的实现都相对复杂,但是更适合商用。下面可以简单看看。
import requests
import time
import hashlib
import uuid
youdao_url = 'https://openapi.youdao.com/api' # 有道api地址
translate_text = "how are you!"
input_text = ""
# 当文本长度小于等于20时,取文本
if(len(translate_text) 20):
input_text = translate_text[:10] + str(len(translate_text)) + translate_text[-10:]
uu_id = uuid.uuid1()
now_time = int(time.time())
app_id = '1111111'
app_key = '11111111111'
sign = hashlib.sha256((app_id + input_text + str(uu_id) + str(now_time) + app_key).encode('utf-8')).hexdigest() # sign生成
data = {
'q':translate_text, # 翻译文本
'from':"en", # 源语言
'to':"zh-CHS", # 翻译语言
'appKey':app_id, # 应用id
'salt':uu_id, # 随机生产的uuid码
'sign':sign, # 签名
'signType':"v3", # 签名类型,固定值
'curtime':now_time, # 秒级时间戳
}
r = requests.get(youdao_url, params = data).json() # 获取返回的json()内容
print("翻译后的结果:" + r["translation"][0]) # 获取翻译内容翻译后的结果:你好!
这个API调用中引用了几个真正商用中的一些为了安全性等设置的验证信息,比如uuid、sign、timestamp,这几个在API调用中也是老生常谈的几个概念,是比较全面的。下面简单介绍一下。
uuid
uuid码:UUID是一个128比特的数值,这个数值可以通过一定的算法计算出来。为了提高效率,常用的UUID可缩短至16位。UUID用来识别属性类型,在所有空间和时间上被视为唯一的标识。一般来说,可以保证这个值是真正唯一的任何地方产生的任意一个UUID都不会有相同的值。使用UUID的一个好处是可以为新的服务创建新的标识符。是一种独特的唯一标识符,python 第三方库uuid 提供对应的uuid生成方式,有以下的几种 uuid1(),uuid3(),uuid4(),uuid5()上面采用的是uuid1()生成,还可以使用uuid4()生成。
sign
sign:一般为了防止被恶意抓包,通过数字签名等保证API接口的安全性。为了防止发送的信息被串改,发送方通过将一些字段要素按一定的规则排序后,在转化成密钥,通过加密机制发送,当接收方接受到请求后需要验证该信息是否被篡改过,也需要将对应的字段按照同样的规则生成验签sign,然后在于后台接收到的进行比对,可以发现信息是否被串改过。在上面的例子利用hashlib.sha256()来进行随机产生一段密钥,最后使用.hexdigest()返回最终的密钥。
curtime:引入一个时间戳参数,保证接口仅在一分钟内有效,需要和客户端时间保持一致。避免重复访问。
推荐学习:python视频教程
위 내용은 Python의 API 호출에 대한 자세한 설명 및 예의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7523
7523
 15
1378
52
81
11
54
19
21
74
15
1378
52
81
11
54
19
21
74

 PHP 및 Python : 두 가지 인기있는 프로그래밍 언어를 비교합니다
Apr 14, 2025 am 12:13 AM
PHP 및 Python : 두 가지 인기있는 프로그래밍 언어를 비교합니다
Apr 14, 2025 am 12:13 AM
PHP와 Python은 각각 고유 한 장점이 있으며 프로젝트 요구 사항에 따라 선택합니다. 1.PHP는 웹 개발, 특히 웹 사이트의 빠른 개발 및 유지 보수에 적합합니다. 2. Python은 간결한 구문을 가진 데이터 과학, 기계 학습 및 인공 지능에 적합하며 초보자에게 적합합니다.
 파이썬 : 게임, Guis 등
Apr 13, 2025 am 12:14 AM
파이썬 : 게임, Guis 등
Apr 13, 2025 am 12:14 AM
Python은 게임 및 GUI 개발에서 탁월합니다. 1) 게임 개발은 Pygame을 사용하여 드로잉, 오디오 및 기타 기능을 제공하며 2D 게임을 만드는 데 적합합니다. 2) GUI 개발은 Tkinter 또는 PYQT를 선택할 수 있습니다. Tkinter는 간단하고 사용하기 쉽고 PYQT는 풍부한 기능을 가지고 있으며 전문 개발에 적합합니다.
 Debian Readdir가 다른 도구와 통합하는 방법
Apr 13, 2025 am 09:42 AM
Debian Readdir가 다른 도구와 통합하는 방법
Apr 13, 2025 am 09:42 AM
데비안 시스템의 readdir 함수는 디렉토리 컨텐츠를 읽는 데 사용되는 시스템 호출이며 종종 C 프로그래밍에 사용됩니다. 이 기사에서는 ReadDir를 다른 도구와 통합하여 기능을 향상시키는 방법을 설명합니다. 방법 1 : C 언어 프로그램을 파이프 라인과 결합하고 먼저 C 프로그램을 작성하여 readDir 함수를 호출하고 결과를 출력하십시오.#포함#포함#포함#포함#includinTmain (intargc, char*argv []) {dir*dir; structdirent*entry; if (argc! = 2) {
 파이썬과 시간 : 공부 시간을 최대한 활용
Apr 14, 2025 am 12:02 AM
파이썬과 시간 : 공부 시간을 최대한 활용
Apr 14, 2025 am 12:02 AM
제한된 시간에 Python 학습 효율을 극대화하려면 Python의 DateTime, Time 및 Schedule 모듈을 사용할 수 있습니다. 1. DateTime 모듈은 학습 시간을 기록하고 계획하는 데 사용됩니다. 2. 시간 모듈은 학습과 휴식 시간을 설정하는 데 도움이됩니다. 3. 일정 모듈은 주간 학습 작업을 자동으로 배열합니다.
 NGINX SSL 인증서 업데이트 Debian Tutorial
Apr 13, 2025 am 07:21 AM
NGINX SSL 인증서 업데이트 Debian Tutorial
Apr 13, 2025 am 07:21 AM
이 기사에서는 Debian 시스템에서 NginxSSL 인증서를 업데이트하는 방법에 대해 안내합니다. 1 단계 : CertBot을 먼저 설치하십시오. 시스템에 CERTBOT 및 PYTHON3-CERTBOT-NGINX 패키지가 설치되어 있는지 확인하십시오. 설치되지 않은 경우 다음 명령을 실행하십시오. sudoapt-getupdatesudoapt-getinstallcertbotpython3-certbot-nginx 2 단계 : 인증서 획득 및 구성 rectbot 명령을 사용하여 nginx를 획득하고 nginx를 구성하십시오.
 Debian OpenSSL에서 HTTPS 서버를 구성하는 방법
Apr 13, 2025 am 11:03 AM
Debian OpenSSL에서 HTTPS 서버를 구성하는 방법
Apr 13, 2025 am 11:03 AM
데비안 시스템에서 HTTPS 서버를 구성하려면 필요한 소프트웨어 설치, SSL 인증서 생성 및 SSL 인증서를 사용하기 위해 웹 서버 (예 : Apache 또는 Nginx)를 구성하는 등 여러 단계가 포함됩니다. 다음은 Apacheweb 서버를 사용하고 있다고 가정하는 기본 안내서입니다. 1. 필요한 소프트웨어를 먼저 설치하고 시스템이 최신 상태인지 확인하고 Apache 및 OpenSSL을 설치하십시오 : Sudoaptupdatesudoaptupgradesudoaptinsta
 데비안에 대한 Gitlab의 플러그인 개발 안내서
Apr 13, 2025 am 08:24 AM
데비안에 대한 Gitlab의 플러그인 개발 안내서
Apr 13, 2025 am 08:24 AM
데비안에서 gitlab 플러그인을 개발하려면 몇 가지 특정 단계와 지식이 필요합니다. 다음은이 과정을 시작하는 데 도움이되는 기본 안내서입니다. Gitlab을 먼저 설치하려면 Debian 시스템에 Gitlab을 설치해야합니다. Gitlab의 공식 설치 매뉴얼을 참조 할 수 있습니다. API 액세스 토큰을 얻으십시오 API 통합을 수행하기 전에 Gitlab의 API 액세스 토큰을 먼저 가져와야합니다. Gitlab 대시 보드를 열고 사용자 설정에서 "AccessTokens"옵션을 찾은 다음 새 액세스 토큰을 생성하십시오. 생성됩니다
 Apache는 어떤 서비스입니까?
Apr 13, 2025 pm 12:06 PM
Apache는 어떤 서비스입니까?
Apr 13, 2025 pm 12:06 PM
아파치는 인터넷 뒤의 영웅입니다. 웹 서버 일뿐 만 아니라 큰 트래픽을 지원하고 동적 콘텐츠를 제공하는 강력한 플랫폼이기도합니다. 모듈 식 설계를 통해 매우 높은 유연성을 제공하여 필요에 따라 다양한 기능을 확장 할 수 있습니다. 그러나 Modularity는 또한 신중한 관리가 필요한 구성 및 성능 문제를 제시합니다. Apache는 사용자 정의가 필요한 서버 시나리오에 적합하고 복잡한 요구를 충족시킵니다.
