

Java 스레드 학습을 위한 동시 프로그래밍 지식 포인트

이 기사에서는 Java 메모리 모델, 휘발성에 대한 자세한 설명, 동기화 구현 원리 등 동시성 프로그래밍과 관련된 문제를 주로 정리하는 java에 대한 관련 지식을 제공합니다. 함께 살펴보시기 바랍니다. 모두를 돕습니다.

추천 학습: "java 비디오 튜토리얼"
1. JMM 기본 - 컴퓨터 원리
Java 메모리 모델은 Java Memory Model 또는 줄여서 JMM입니다. JMM은 JVM(Java Virtual Machine)이 컴퓨터 메모리(RAM)에서 작동하는 방식을 정의합니다. JVM은 전체 컴퓨터 가상 모델이므로 JMM은 JVM과 제휴되어 있습니다. Java1.5 버전에서는 이를 리팩토링했으며 현재 Java는 여전히 Java1.5 버전을 사용합니다. Jmm이 직면한 문제는 현대 컴퓨터에서 직면한 문제와 유사합니다.
실제 컴퓨터의 동시성 문제. 실제 컴퓨터에서 발생하는 동시성 문제는 가상 컴퓨터의 상황과 많은 유사성을 가지고 있습니다. D "Google의 GOOGLE Plot에 있는 Jeff Dean의 보고서"에 따르면
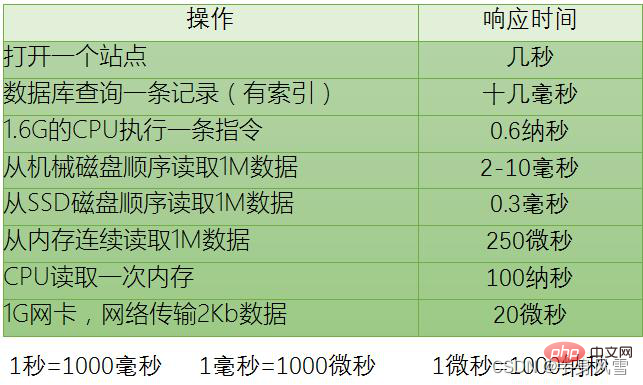
다음 사례는 예시일 뿐이며 실제 상황을 나타내지는 않습니다.int형 데이터 1M을 메모리에서 읽어와 CPU가 쌓는다면 얼마나 걸릴까요?
간단히 계산해 보면 Java의 int 유형은 32비트, 4바이트입니다. CPU 계산 시간은 262144
0.6 = 157286나노초입니다. 우리는 메모리에서 1M 데이터를 읽는 데 250,000나노초가 걸린다는 것을 알고 있지만, 둘 사이에는 간격이 있지만(물론 이 간격은 작지 않으며, 100,000나노초는 CPU가 거의 200,000개의 명령을 실행하는 데 충분한 시간입니다). 여전히 같은 규모입니다. 그러나 캐싱 메커니즘이 없으면 각 숫자를 메모리에서 읽어야 함을 의미합니다. 이 경우 CPU가 메모리를 한 번 읽는 데 100나노초가 걸리고 262144개의 정수가 메모리에서 CPU로 읽혀집니다. 계산 시간은 262144100+250000 = 26464400나노초가 소요되며 이는 크기의 차이입니다.
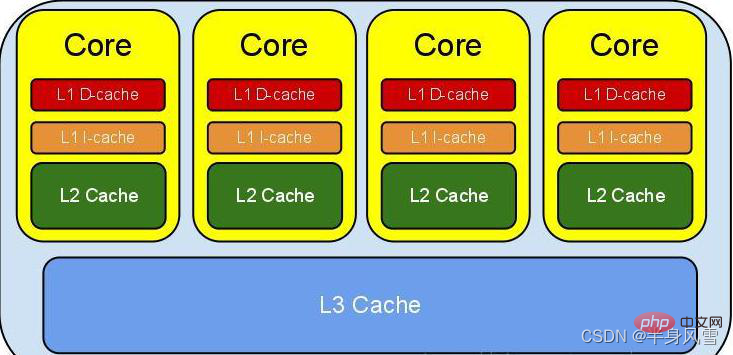
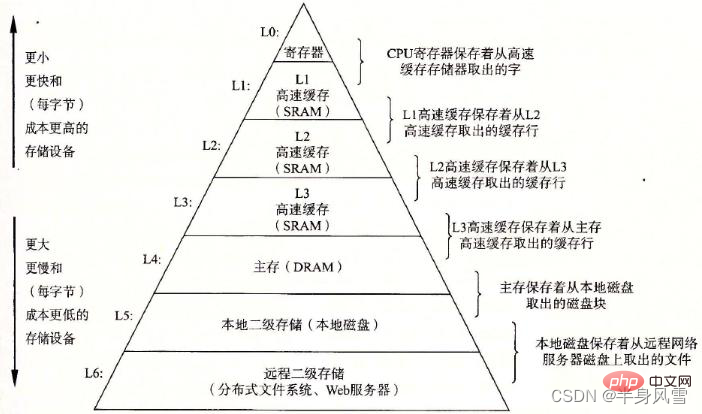
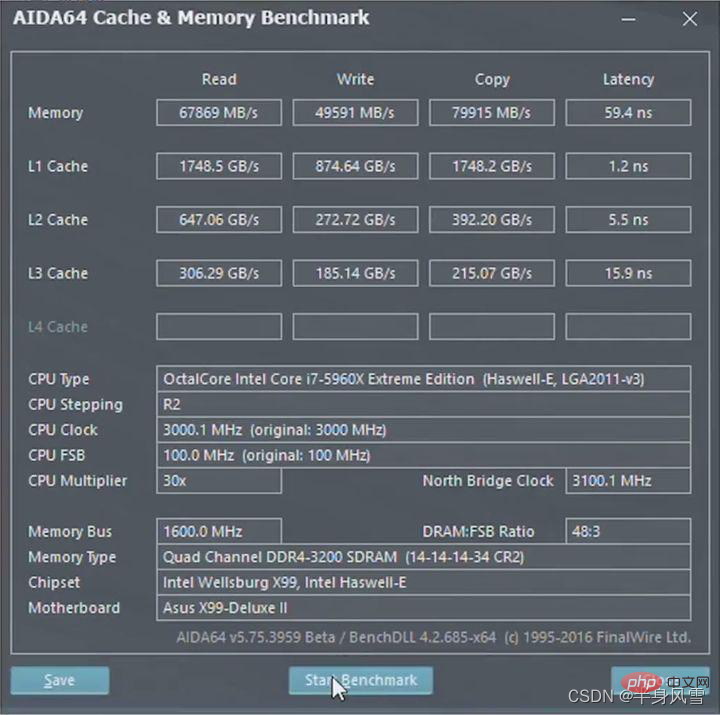
2. Java 메모리 모델(JMM)
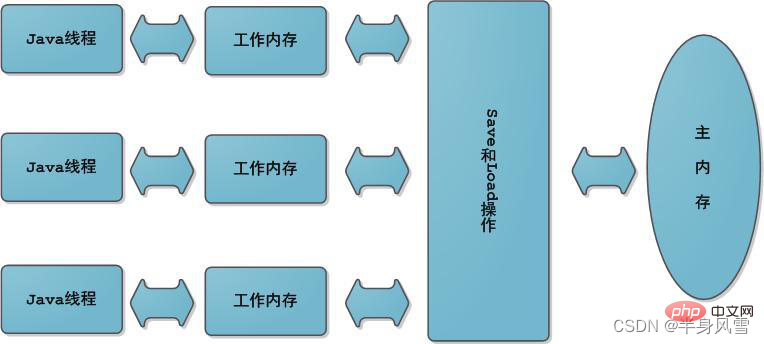
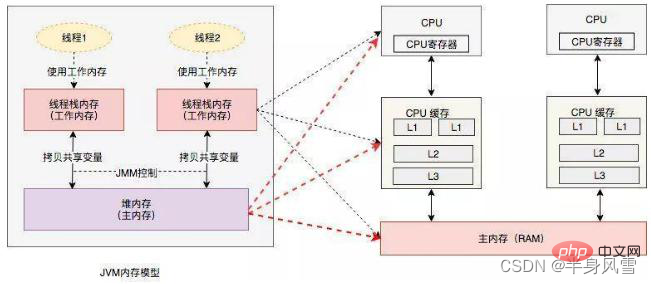
추상적인 관점에서 JMM은 스레드와 메인 메모리 사이의 추상적인 관계를 정의합니다. 스레드 간의 공유 변수는 메인 메모리(메인 메모리)에 저장되며, 각 스레드에는 프라이빗이 있습니다. 스레드가 읽고 쓸 수 있는 공유 변수의 복사본을 저장하는 로컬 메모리(로컬 메모리). 로컬 메모리는 JMM의 추상적인 개념이며 실제로 존재하지 않습니다. 캐시, 쓰기 버퍼, 레지스터, 기타 하드웨어 및 컴파일러 최적화를 다룹니다.
2.1 가시성
가시성은 여러 스레드가 동일한 변수에 액세스할 때 한 스레드가 변수 값을 수정하면 다른 스레드가 수정된 값을 즉시 볼 수 있음을 의미합니다.
스레드에 의한 변수에 대한 모든 작업은 작업 메모리에서 수행되어야 하고 주 메모리에서 변수를 직접 읽고 쓸 수 없기 때문에 공유 변수 V의 경우 먼저 자체 작업 메모리에 있는 다음 주 메모리에 동기화됩니다. 그러나 시간이 지나면 메인 메모리로 플러시되지는 않지만 일정한 시간 차이가 있습니다. 분명히 현재로서는 변수 V에 대한 스레드 A의 작업이 더 이상 스레드 B에 표시되지 않습니다.
공유 객체 가시성 문제를 해결하기 위해 휘발성 키워드나 잠금을 사용할 수 있습니다.
2.2.Atomicity
Atomicity: 즉, 하나의 작업 또는 여러 작업이 모두 실행되고 실행 프로세스가 어떤 요인으로 인해 중단되지 않거나 전혀 실행되지 않습니다.
우리 모두는 CPU 리소스 할당이 스레드를 기반으로 하며 시간 공유 방식으로 호출된다는 것을 알고 있습니다. 운영 체제에서는 50밀리초와 같은 짧은 시간 동안 프로세스를 실행할 수 있습니다. 프로세스를 다시 선택합니다("작업 전환"이라고 함). 이 50밀리초를 "타임 슬라이스"라고 합니다. 대부분의 작업은 시간 세그먼트가 끝난 후 전환됩니다.
그렇다면 스레드 전환이 버그를 일으키는 이유는 무엇일까요? 운영 체제가 작업 전환을 수행하기 때문에 CPU 명령이 실행된 후에 이러한 일이 발생할 수 있습니다! 이는 고급 언어의 명령문이 아니라 CPU 명령어, CPU 명령어, CPU 명령어라는 점에 유의하십시오. 예를 들어 count++는 Java에서는 한 문장에 불과하지만 고급 언어에서는 명령문을 완료하려면 여러 CPU 명령이 필요한 경우가 많습니다. 실제로 count++에는 적어도 3개의 CPU 명령어가 포함되어 있습니다! 那么线程切换为什么会带来 bug 呢?因为操作系统做任务切换,可以发生在任何一条 CPU 指令执行完!注意,是 CPU 指令,CPU 指令,CPU 指令,而不是高级语言里的一条语句。比如 count++,在 java 里就是一句话,但高级语言里一条语句往往需要多条 CPU 指令完成。其实 count++至少包含了三个 CPU 指令!
三、volatile 详解
3.1、volatile 特性
可以把对 volatile 变量的单个读/写,看成是使用同一个锁对这些单个读/写
휘발성 변수의 단일 읽기/쓰기는 동일한 잠금을 사용하여 이러한 단일 코드를 읽고 쓰는 것으로 간주할 수 있습니다.3.1. 휘발성 기능
public class Volati {
// 使用volatile 声明一个64位的long型变量
volatile long i = 0L;// 单个volatile 变量的读
public long getI() {
return i;
}// 单个volatile 变量的写
public void setI(long i) {
this.i = i;
}// 复合(多个)volatile 变量的 读/写
public void iCount(){
i ++;
}}- 는 다음 코드로 볼 수 있습니다.
-
따라서 휘발성 변수 자체는 다음과 같은 특성을 갖습니다.
public class VolaLikeSyn { // 使用 long 型变量 long i = 0L; public synchronized long getI() { return i; }// 对单个的普通变量的读用同一个锁同步 public synchronized void setI(long i) { this.i = i; }// 普通方法调用 public void iCount(){ long temp = getI(); // 调用已同步的读方法 temp = temp + 1L; // 普通写操作 setI(temp); // 调用已同步的写方法 }}로그인 후 복사 - Visibility : 휘발성 변수 읽기는 항상 볼 수 있습니다. 최종 쓰기(모든 스레드에 의해) )를 이 휘발성 변수에 추가합니다.
: 단일 휘발성 변수를 읽고 쓰는 것은 원자적이지만 휘발성++과 같은 복합 연산은 원자적이지 않습니다.
- 휘발성은 실행 후 시간 내에 변수가 주 메모리로 플러시되도록 보장할 수 있지만, 스레드 전환으로 인해 비원자적 다중 명령 상황인 count++의 경우 스레드 A는 방금 count=0을 작업 메모리에 로드했습니다. , 스레드 B는 방금 작업 메모리에 count=0을 로드했습니다. 그러면 스레드 A와 B의 실행 결과가 모두 1이 되고 둘 다 주 메모리에 기록됩니다. 메모리는 여전히 2가 아니라 1입니다
- 3.2 휘발성
- 휘발성 키의 구현 원칙 Word 수정 변수에는 "lock:" 접두사가 있습니다.
Lock 접두사, Lock은 메모리 장벽이 아니지만 메모리 장벽과 유사한 기능을 수행할 수 있습니다. 잠금은 CPU 버스와 캐시를 잠그는데, 이는 CPU 명령 수준에서 잠금으로 이해될 수 있습니다.
동시에 이 명령어는 현재 프로세서 캐시 라인의 데이터를 시스템 메모리에 직접 기록하며, 이 쓰기 작업은 다른 CPU의 이 주소에 캐시된 데이터를 무효화합니다.
- 모니터의 항목 번호가 0이면 스레드가 모니터에 들어간 후 항목 번호를 1로 설정하고 스레드가 모니터의 소유자가 됩니다.
- 스레드가 이미 모니터를 점유하고 있다가 다시 진입하면 모니터에 진입하는 횟수가 1 증가합니다.
- 다른 스레드가 이미 모니터를 점유하고 있는 경우 해당 스레드는 모니터의 항목 번호가 0이 될 때까지 차단 상태에 들어간 후 다시 모니터 소유권을 얻으려고 시도합니다. 동기화 방법의 경우, 동기화 방법의 디컴파일 결과로 볼 때, monitorenter 및 monitorexit 명령을 통해 메서드의 동기화가 구현되지 않습니다. 일반 방법과 비교하여 상수 풀에는 추가 ACC_SYNCHRONIZED 식별자가 있습니다.
JVM은 이 식별자를 기반으로 메서드 동기화를 구현합니다. 메서드가 호출되면 호출 명령은 메서드의 ACC_SYNCHRONIZED 액세스 플래그가 설정되어 있는지 확인하고 실행 스레드는 먼저 모니터를 얻은 다음 실행합니다. 획득이 성공한 후 메서드 본문, 메서드가 실행된 후 모니터가 해제됩니다. 메서드 실행 중에는 다른 스레드가 동일한 모니터 개체를 다시 얻을 수 없습니다.
Synchronized에서 사용하는 잠금은 Java 객체 헤더에 저장됩니다. Java 객체의 객체 헤더는 마크 워드와 클래스 포인터의 두 부분으로 구성됩니다.
- 마크 워드는 동기화 상태, 로고, 해시코드, GC 상태를 저장합니다. 등.
- klass 포인터는 클래스 메타데이터를 가리키는 객체의 유형 포인터를 저장합니다. 또한 배열의 경우 배열 길이를 기록하는 데이터도 있습니다.

객체의 마크 워드에 잠금 정보가 존재합니다. MarkWord의 기본 데이터는 객체의 HashCode 및 기타 정보를 저장하는 것입니다.

객체의 동작이 변경됨에 따라 변경됩니다. 다양한 잠금 상태는 다양한 기록 저장 방법에 해당합니다.
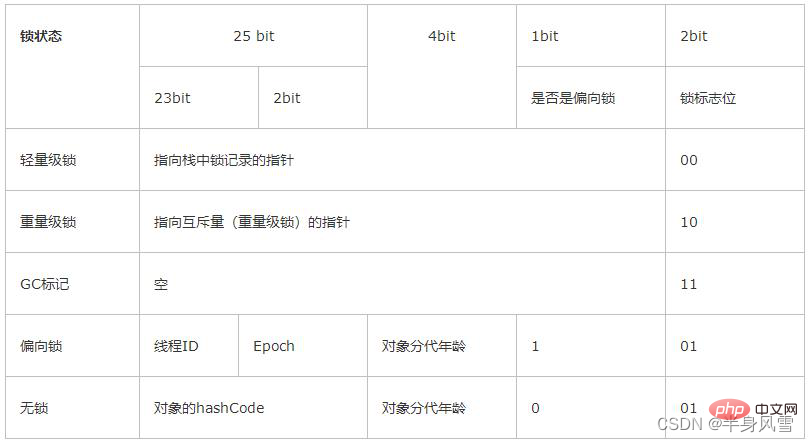
4.1. 잠금 상태
위 사진을 비교하면 총 잠금 잠금 없음 상태, 바이어스 잠금 상태, 경량 잠금 상태 및 중량 잠금 상태 의 네 가지 상태가 있으며 이는 경쟁 상황에 따라 점차 확대됩니다. 잠금 획득 및 해제의 효율성을 높이기 위해 잠금을 업그레이드할 수 있지만 다운그레이드할 수는 없습니다.
4.2. 편향된 잠금
배경 소개: 대부분의 경우 잠금은 다중 스레드 경쟁이 없을 뿐만 아니라 스레드가 잠금을 획득하는 데 비용을 더 저렴하게 만들기 위해 항상 동일한 스레드에 의해 여러 번 획득됩니다. , 편향된 잠금이 도입되었습니다. 불필요한 CAS 작업을 줄입니다. 편향된 잠금은 이름에서 알 수 있듯이 스레드에 대한 첫 번째 방문으로 편향됩니다. 작업 중에 스레드에서만 동기 잠금에 액세스하면 다중 스레드 분쟁이 없으므로 스레드가 트리거될 필요가 없습니다. 동기화, 감소 감소, 감소 잠금/잠금 해제의 일부 CAS 작업(예: 대기 대기열의 일부 CAS 작업), 이 경우 바이어스 잠금이 스레드에 추가됩니다. 작업 중에 다른 스레드가 잠금을 선점하면 바이어스 잠금을 보유한 스레드가 일시 중지되고 JVM은 해당 스레드에 대한 바이어스 잠금을 제거하고 잠금을 표준 경량 잠금으로 복원합니다. 리소스에 대한 경쟁이 없을 때 동기화 기본 요소를 제거하여 프로그램의 실행 성능을 더욱 향상시킵니다.
바이어스 잠금 획득 프로세스를 이해하려면 아래 그림을 보십시오.
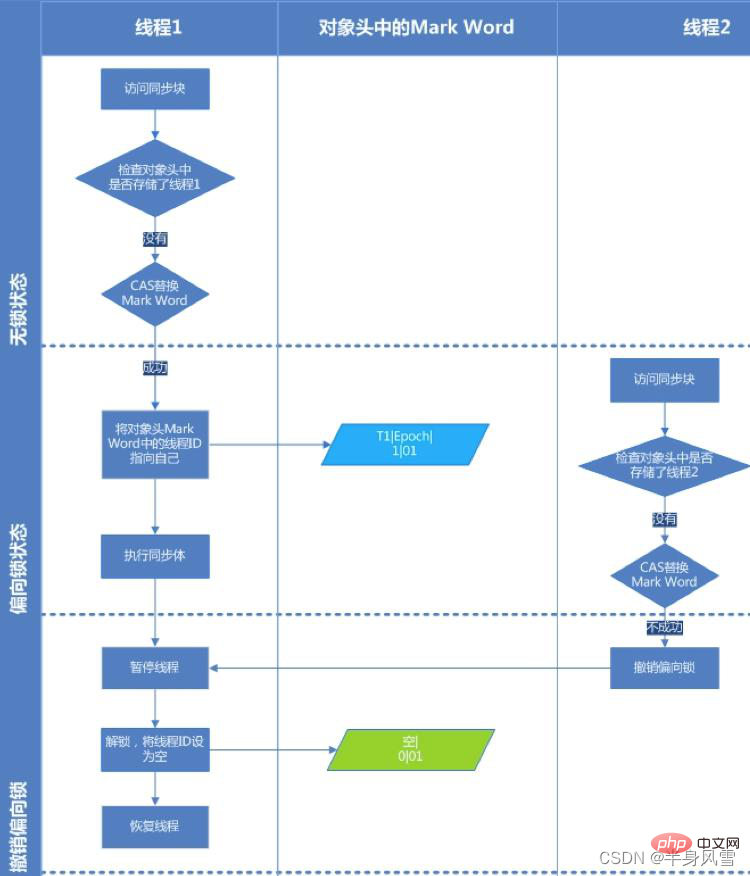
2단계. 바이어스 가능 상태인 경우 스레드 ID가 현재 스레드를 가리키는지 테스트합니다. 그렇다면 5단계로 이동하고, 그렇지 않으면 3단계로 이동합니다.
Step 3. 스레드 ID가 현재 스레드를 가리키지 않는 경우 CAS 연산을 통해 잠금 경쟁을 합니다. 경쟁이 성공하면 Mark Word의 스레드 ID를 현재 스레드 ID로 설정한 다음 5를 실행하고, 경쟁이 실패하면 4를 실행합니다.
4단계. CAS가 바이어스 잠금을 획득하지 못하면 경쟁이 있음을 의미합니다. 전역 안전 지점(safepoint)에 도달하면 바이어스 잠금을 획득한 스레드가 일시 중단되고 바이어스 잠금이 경량 잠금으로 업그레이드된 후 안전 지점에서 차단된 스레드가 계속해서 동기화 코드를 실행합니다. (바이어스 잠금을 해제하면 단어가 중지됩니다.)
Step 5. 동기화 코드를 실행합니다.
바이어스 잠금 해제:
바이어스 잠금 취소는 위의 네 번째 단계에서 언급됩니다. 바이어스 잠금은 다른 스레드가 바이어스 잠금을 놓고 경쟁하려고 할 때만 바이어스 잠금을 해제합니다. 바이어스 잠금을 보유한 스레드는 바이어스 잠금을 해제하기 위해 주도권을 갖지 않습니다. 편향된 잠금을 취소하려면 전역 안전 지점(이 시점에서는 바이트코드가 실행되지 않음)을 기다려야 합니다. 먼저 편향된 잠금을 소유한 스레드를 일시 중지하고 잠금 개체가 잠긴 상태인지 확인합니다. , 그런 다음 바이어스 잠금을 취소한 후 바이어스 잠금을 이전 상태로 복원합니다. 잠금 상태(플래그 비트는 "01") 또는 경량 잠금(플래그 비트는 "00")입니다.
편향된 잠금에 적용 가능한 시나리오:
동기화 블록을 실행하는 스레드는 항상 하나만 있습니다. 실행이 완료되고 잠금이 해제되기 전에는 동기화 블록을 실행할 다른 스레드가 없을 때 사용됩니다. 경쟁이 경량 잠금으로 업그레이드되면 편향 잠금을 취소해야 합니다. 잠금, 바이어스 잠금은 많은 추가 작업을 수행합니다. 특히 바이어스 잠금을 취소하면 안전 지점에 진입하게 되어 이 경우 비활성화되어야 합니다. .
jvm 바이어스 잠금 켜기/끄기4.3, 경량 잠금 바이어스 잠금에서 업그레이드된 바이어스 잠금은 한 스레드가 동기화 블록에 들어갈 때 실행됩니다. 두 번째 스레드가 잠금 경합에 참여하면 바이어스 잠금은 경량 잠금으로 업그레이드됩니다.바이어스 잠금 켜기: -XX:+UseBiasedLocking -XX:BiasedLockingStartupDelay=0 바이어스 잠금 끄기: -XX:-UseBiasedLocking
잠금 프로세스:
- 코드가 동기화 블록에 들어갈 때 동기화 개체 잠금 상태가 잠금 해제되고 바이어스가 허용되지 않으면(잠금 플래그는 "01", 바이어스 잠금 여부는 "0") 가상 머신이 먼저 현재 스레드의 스택 프레임에 Lock Record라는 공간을 생성합니다. 이 공간은 공식적으로 Displaced Mark Word라고 불리는 잠금 개체의 현재 Mark Word 복사본을 저장하는 데 사용됩니다.
- 개체 헤더의 마크 단어를 잠금 기록에 복사하세요.
- 복사가 성공한 후 가상 머신은 CAS 작업을 사용하여 개체의 표시 단어를 잠금 레코드에 대한 포인터로 업데이트하고 잠금 레코드의 소유자 포인터를 개체 표시 단어로 가리킵니다. 업데이트가 성공하면 4단계로 진행하고, 그렇지 않으면 5단계로 진행합니다.
- 이 업데이트 작업이 성공하면 이 스레드가 객체의 잠금을 소유하고 객체 Mark Word의 잠금 플래그가 "00"으로 설정됩니다. 이는 이 객체가 경량 잠금 상태에 있음을 의미합니다
- 이렇게 업데이트 작업이 실패하면 가상 머신은 먼저 개체의 Mark Word가 현재 스레드의 스택 프레임을 가리키는지 확인합니다. 그렇다면 현재 스레드가 이미 이 개체의 잠금을 소유하고 있음을 의미합니다. 실행을 계속하려면 동기화 블록을 직접 입력하세요. 그렇지 않으면 여러 스레드가 잠금을 위해 경쟁하고 있으며 회전하고 잠금을 기다리며 특정 횟수 후에 잠금 개체를 얻지 못했음을 의미합니다. 중량급 스레드 포인터는 경쟁 스레드를 가리키며 경쟁 스레드도 차단되어 경량 스레드가 잠금을 해제하고 깨어날 때까지 기다립니다. 잠금 플래그의 상태 값은 "10"으로 변경됩니다. Mark Word에 저장되는 것은 중량 잠금(뮤텍스)에 대한 포인터이며 잠금을 기다리는 후속 스레드도 차단 상태에 들어갑니다.
하지만 스레드 회전에는 CPU 소비가 필요합니다. 직설적으로 말하면 CPU가 쓸데없는 작업을 수행하기 위해 항상 CPU 회전을 점유할 수는 없으므로 최대 회전 대기 시간을 설정해야 합니다.
잠금을 보유한 스레드의 실행 시간이 최대 스핀 대기 시간을 초과하고 잠금이 해제되지 않으면 잠금을 놓고 경쟁하는 다른 스레드는 여전히 최대 대기 시간 내에 잠금을 획득할 수 없습니다. 경합하는 스레드가 자체적으로 중지됩니다. 스핀은 차단 상태로 들어갑니다.
그러나 잠금 경쟁이 치열하거나 잠금을 보유한 스레드가 동기화 블록을 실행하기 위해 오랫동안 잠금을 점유해야 하는 경우 스핀 잠금은 항상 사용되기 때문에 이때 스핀 잠금을 사용하는 것은 적합하지 않습니다. 잠금을 획득하기 전에 쓸모없는 작업을 위해 CPU를 점유하는 것은 그리 큰 함정이 아닙니다. 스레드 차단 및 일시 중지 작업의 소비보다 CPU를 확보할 수 없어 낭비가 발생합니다. CPU의.
4.3.3.스핀 잠금 시간 임계값
스핀 잠금의 목적은 CPU 리소스를 해제하지 않고 점유하고 잠금이 획득될 때까지 기다려 즉시 처리하는 것입니다. 그러나 스핀 실행 시간을 선택하는 방법은 무엇입니까? 스핀 실행 시간이 너무 길면 많은 수의 스레드가 스핀 상태가 되어 CPU 리소스를 점유하게 되어 전체 시스템 성능에 영향을 미치게 됩니다. 그래서 회전수가 중요합니다. 다음 JVM의 회전수 선택, JDK1.5의 기본값은 10회, 1.6에서 적응형 스핀 잠금을 도입했는데, 적응형 스핀 잠금은 회전 시간이 고정되어 있지 않지만 이전 시간부터 이전 시간이 이전 시간에 있었다는 의미입니다. 이전 시간은 동일한 잠금의 스핀 시간과 잠금 소유자의 상태에 따라 결정됩니다. 기본적으로 스레드의 컨텍스트 전환 시간이 가장 좋은 시간으로 간주됩니다.
JDK1.6에서는 -XX:+UseSpinning이 스핀 잠금을 설정합니다. JDK1.7 이후에는 이 매개변수가 제거되고 jvm에 의해 제어됩니다.
4.3.4, 다양한 잠금 비교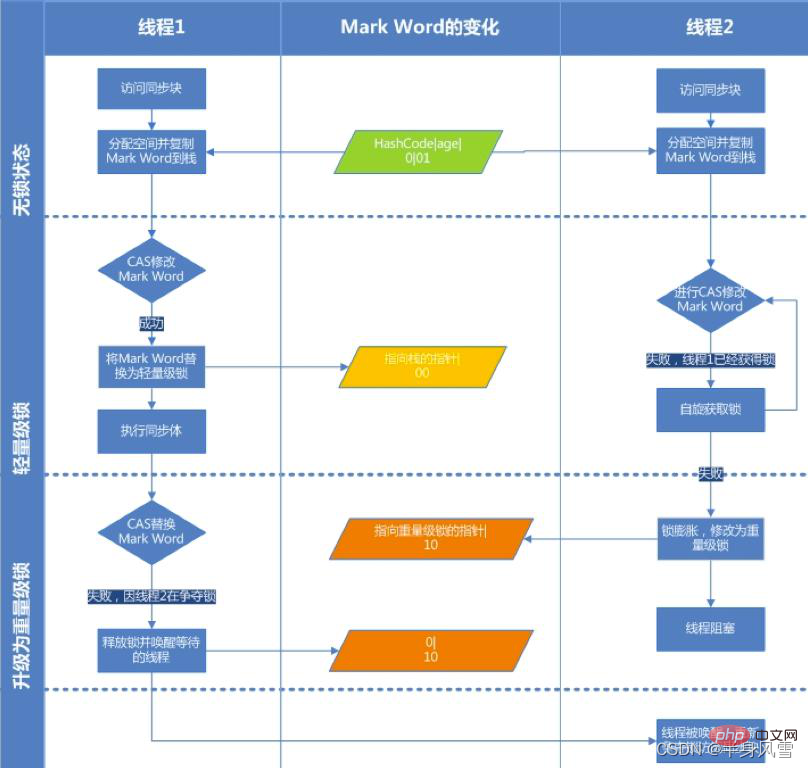
추천 학습: "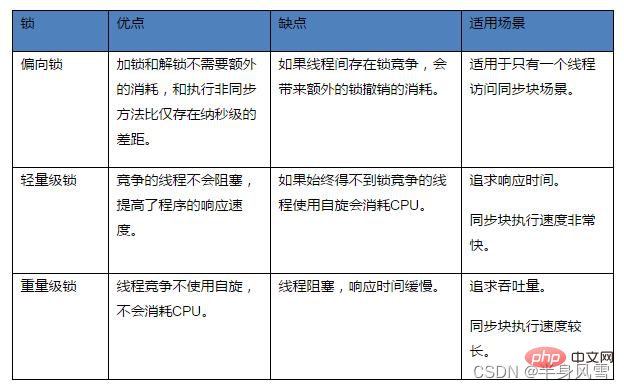 java 비디오 튜토리얼
java 비디오 튜토리얼
위 내용은 Java 스레드 학습을 위한 동시 프로그래밍 지식 포인트의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7486
7486
 15
1377
52
77
11
51
19
19
39
15
1377
52
77
11
51
19
19
39


 Java의 난수 생성기
Aug 30, 2024 pm 04:27 PM
Java의 난수 생성기
Aug 30, 2024 pm 04:27 PM
Java의 난수 생성기 안내. 여기서는 예제를 통해 Java의 함수와 예제를 통해 두 가지 다른 생성기에 대해 설명합니다.
 자바의 웨카
Aug 30, 2024 pm 04:28 PM
자바의 웨카
Aug 30, 2024 pm 04:28 PM
Java의 Weka 가이드. 여기에서는 소개, weka java 사용 방법, 플랫폼 유형 및 장점을 예제와 함께 설명합니다.
 Java의 스미스 번호
Aug 30, 2024 pm 04:28 PM
Java의 스미스 번호
Aug 30, 2024 pm 04:28 PM
Java의 Smith Number 가이드. 여기서는 정의, Java에서 스미스 번호를 확인하는 방법에 대해 논의합니다. 코드 구현의 예.
 Java Spring 인터뷰 질문
Aug 30, 2024 pm 04:29 PM
Java Spring 인터뷰 질문
Aug 30, 2024 pm 04:29 PM
이 기사에서는 가장 많이 묻는 Java Spring 면접 질문과 자세한 답변을 보관했습니다. 그래야 면접에 합격할 수 있습니다.
 Java 8 Stream foreach에서 나누거나 돌아 오시겠습니까?
Feb 07, 2025 pm 12:09 PM
Java 8 Stream foreach에서 나누거나 돌아 오시겠습니까?
Feb 07, 2025 pm 12:09 PM
Java 8은 스트림 API를 소개하여 데이터 컬렉션을 처리하는 강력하고 표현적인 방법을 제공합니다. 그러나 스트림을 사용할 때 일반적인 질문은 다음과 같은 것입니다. 기존 루프는 조기 중단 또는 반환을 허용하지만 스트림의 Foreach 메소드는이 방법을 직접 지원하지 않습니다. 이 기사는 이유를 설명하고 스트림 처리 시스템에서 조기 종료를 구현하기위한 대체 방법을 탐색합니다. 추가 읽기 : Java Stream API 개선 스트림 foreach를 이해하십시오 Foreach 메소드는 스트림의 각 요소에서 하나의 작업을 수행하는 터미널 작동입니다. 디자인 의도입니다
 Java의 날짜까지의 타임스탬프
Aug 30, 2024 pm 04:28 PM
Java의 날짜까지의 타임스탬프
Aug 30, 2024 pm 04:28 PM
Java의 TimeStamp to Date 안내. 여기서는 소개와 예제와 함께 Java에서 타임스탬프를 날짜로 변환하는 방법에 대해서도 설명합니다.
 미래를 창조하세요: 완전 초보자를 위한 Java 프로그래밍
Oct 13, 2024 pm 01:32 PM
미래를 창조하세요: 완전 초보자를 위한 Java 프로그래밍
Oct 13, 2024 pm 01:32 PM
Java는 초보자와 숙련된 개발자 모두가 배울 수 있는 인기 있는 프로그래밍 언어입니다. 이 튜토리얼은 기본 개념부터 시작하여 고급 주제를 통해 진행됩니다. Java Development Kit를 설치한 후 간단한 "Hello, World!" 프로그램을 작성하여 프로그래밍을 연습할 수 있습니다. 코드를 이해한 후 명령 프롬프트를 사용하여 프로그램을 컴파일하고 실행하면 "Hello, World!"가 콘솔에 출력됩니다. Java를 배우면 프로그래밍 여정이 시작되고, 숙달이 깊어짐에 따라 더 복잡한 애플리케이션을 만들 수 있습니다.
