

한 기사에서 SQL 창 기능에 대한 자세한 설명

이 기사에서는 주로 윈도우 기능과 관련된 문제를 정리하는 SQL에 대한 관련 지식을 제공합니다. SQL 윈도우 기능은 온라인 분석 처리(OLAP) 및 비즈니스 인텔리전스(BI) 기능에 대한 복잡한 분석 및 보고서 통계를 제공합니다. 판매통계, 카테고리 순위, 연/월별 분석 등 모두에게 도움이 되기를 바랍니다.

추천 학습: "SQL 튜토리얼"
윈도우 기능이란 무엇입니까?
SQL 창 기능은 온라인 분석 처리(OLAP) 및 비즈니스 인텔리전스(BI)를 위한 복잡한 분석 및 보고 통계 기능을 제공합니다. 상품 누적 판매 통계, 카테고리 순위, 전년/월별 분석 등 이러한 기능은 집계 함수 및 그룹화 작업으로 구현하기 어려운 경우가 많습니다.
윈도우 함수(Window Function)는 집계 함수처럼 데이터 집합을 분석하고 결과를 반환할 수 있습니다. 둘의 차이점은 윈도우 함수는 데이터 집합을 단일 결과로 집계하지 않고 대신 집합을 분석한다는 것입니다. 데이터의 각 행에 대한 데이터입니다. 결과를 반환합니다. 집계 함수와 창 함수의 차이점은 아래 그림과 같습니다.

두 함수의 차이점을 보여주기 위해 SUM 함수를 예로 들어 보겠습니다. 다음 명령문의 SUM()은 집계 함수입니다.
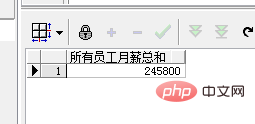
SELECT SUM(salary) AS "所有员工月薪总和" FROM employee
위 SUM 함수는 집계 함수로 사용될 수 있습니다. 모든 직원 데이터가 결과로 요약됩니다. 따라서 쿼리는 모든 직원의 월급 총액을 반환합니다. 다음 명령문의
SUM()은 창 함수입니다.
SELECT emp_name AS "员工姓名", SUM(salary) OVER () AS "所有员工月薪总和" FROM employee;
그 중 OVER 키워드는 SUM()이 창 함수임을 나타냅니다. 빈 괄호는 모든 데이터가 하나의 그룹으로 요약된다는 것을 나타냅니다. 이 쿼리에서 반환된 결과는 다음과 같습니다.
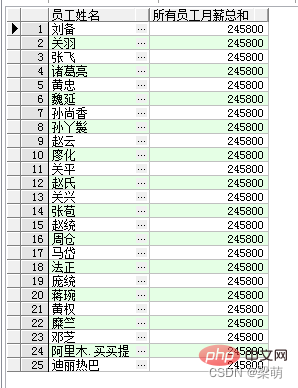
위 쿼리 결과는 모든 직원 이름을 반환하며, 집계 함수 SUM()을 통해 각 직원에 대해 동일한 요약 결과가 반환됩니다.
위의 예에서 볼 수 있듯이 윈도우 함수의 구문은 OVER 절을 포함한다는 점에서 집계 함수와 다릅니다. OVER 절은 데이터 분석을 위한 창을 지정하는 데 사용됩니다. 전체 창 함수 정의는 다음과 같습니다.

여기서 window_function은 창 함수의 이름이고, 표현식은 선택적 분석 개체(필드 이름 또는 표현식)입니다. OVER 절에는 파티션(PARTITION BY), 정렬(ORDER BY) 및 창 크기(frame_clause)의 세 가지 옵션이 포함되어 있습니다.
팁: 집계 함수는 동일한 그룹에 있는 여러 데이터 행을 단일 결과로 요약하는 반면 창 함수는 모든 원본 데이터를 유지합니다. 일부 데이터베이스에서는 창 기능을 OLAP(온라인 분석 처리) 기능 또는 분석 기능이라고도 합니다.
윈도우 함수 구성요소
1. 데이터 파티션 생성
윈도우 함수의 OVER 절에 있는 PARTITION BY 옵션은 파티션을 정의하는 데 사용되며, 그 역할은 쿼리문의 GROUP BY 절과 유사합니다. 파티션 옵션을 지정하면 창 기능이 각 파티션을 개별적으로 분석합니다.
예를 들어 다음 명령문은 부서별 직원의 월급 총액을 계산합니다.
SELECT emp_name AS "员工姓名", salary "月薪", dept_id AS "部门编号", SUM(salary) OVER ( PARTITION BY dept_id ) AS "部门合计" FROM employee;
그 중 PARTITION BY 옵션은 부서별 파티셔닝을 나타냅니다. 쿼리에 의해 반환된 결과는 다음과 같습니다.
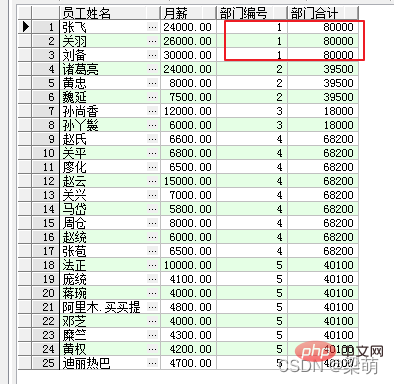
쿼리 결과에 있는 데이터의 처음 세 행은 동일한 부서에 속하므로 해당 부서 전체 필드는 80000(30000+26000+24000)과 같습니다. 다른 부서의 직원도 같은 방식으로 계산됩니다.
Tips: 윈도우 함수 OVER 절에 PARTITION BY 옵션을 지정한 후 GROUP BY 절을 사용하지 않고도 그룹 통계 결과를 얻을 수 있습니다.
PARTITION BY 옵션을 지정하지 않으면 모든 데이터를 전체적으로 분석한다는 의미입니다.
2. 파티션 내 정렬
윈도우 함수의 OVER 절에 있는 ORDER BY 옵션은 파티션 내 데이터의 정렬 방법을 지정하는 데 사용되며 해당 기능은 쿼리문의 ORDER BY 절과 유사합니다. .
정렬 옵션은 일반적으로 데이터의 범주별 순위를 지정하는 데 사용됩니다. 예를 들어, 부서 내 직원의 월급 순위를 분석하려면 다음 명령문을 사용합니다.
SELECT emp_name AS "员工姓名", salary "月薪", dept_id AS "部门编号", RANK() OVER ( PARTITION BY dept_id ORDER BY salary DESC ) AS "部门内排名" FROM employee;
그 중 RANK 함수를 사용하여 데이터의 순위를 계산하고 PARTITION BY 옵션은 부서별 파티셔닝을 나타내며, ORDER BY 옵션은 해당 부서 내 월급을 높은 순부터 낮은 순으로 표시합니다. 쿼리에서 반환된 결과는 다음과 같습니다.
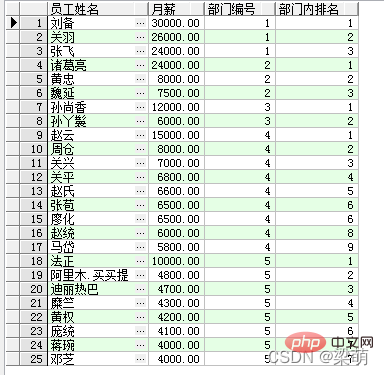
查询结果中的前3行数据属于同一个部门:“刘备”的月薪最高,在部门内排名第1;“关羽”排名第2;“张飞”排名第3。其他部门的员工采用同样的方式进行排名。
提示:窗口函数OVER子句中的ORDER BY选项和查询语句中的ORDER BY子句的使用方法相同。因此,也可以使用NULLS FIRST或者NULLS LAST选项指定空值的排序位置。
3.指定窗口大小
窗口函数OVER子句中的frame_clause选项用于指定一个移动的分析窗口,窗口总是位于分区的范围之内,是分区的一个子集。在指定了分析窗口之后,窗口函数不再基于分区进行分析,而是基于窗口内的数据进行分析。
窗口选项可以用于实现各种复杂的分析功能,例如计算累计到当前日期为止的销售额总和,每个月及其前后各N个月的平均销售额等。
指定窗口大小的具体选项如下:

其中,ROWS表示以数据行为单位计算窗口的偏移量,RANGE表示以数值(例如10天、5km等)为单位计算窗口的偏移量。
frame_start选项用于定义窗口的起始位置,可以指定以下内容之一:
●UNBOUNDED PRECEDING——表示窗口从分区的第一行开始。
●N PRECEDING——表示窗口从当前行之前的第N行开始。
●CURRENT ROW——表示窗口从当前行开始。
frame_end选项用于定义窗口的结束位置,可以指定以下内容之一:
●CURRENT ROW——表示窗口到当前行结束。
●M FOLLOWING——表示窗口到当前行之后的第M行结束。
●UNBOUNDED FOLLOWING——表示窗口到分区的最后一行结束。
下图说明了这些窗口大小选项的含义
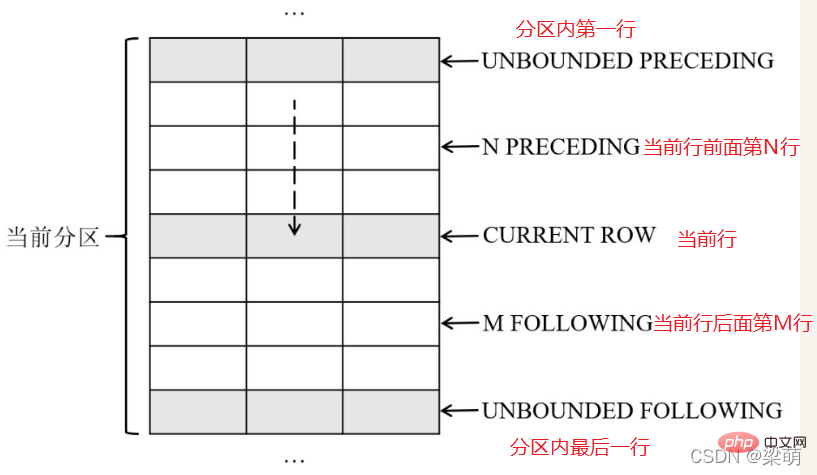
下面语句表示分析窗口从当前分区的第一行开始,直到当前行结束,即对应到图中前面5行记录。
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW
窗口函数分类
1.聚合窗口函数
许多常见的聚合函数也可以作为窗口函数使用,包括AVG()、SUM()、COUNT()、MAX()以及MIN()等函数。
SQL窗口函数-聚合窗口函数
2.排名窗口函数
排名窗口函数用于对数据进行分组排名,包括ROW_NUMBER()、RANK()、DENSE_RANK()、PERCENT_RANK()、CUME_DIST()以及NTILE()等函数。
SQL窗口函数-排名窗口函数
3.取值窗口函数
取值窗口函数用于返回指定位置上的数据行,包括FIRST_VALUE()、LAST_VALUE()、LAG()、LEAD()、NTH_VALUE()等函数。
SQL窗口函数-取值窗口函数
示例表和脚本
--员工信息表 CREATE TABLE employee ( emp_id NUMBER , emp_name VARCHAR2(50) NOT NULL , sex VARCHAR2(10) NOT NULL , dept_id INTEGER NOT NULL , manager INTEGER , hire_date DATE NOT NULL , job_id INTEGER NOT NULL , salary NUMERIC(8,2) NOT NULL , bonus NUMERIC(8,2) , email VARCHAR2(100) NOT NULL , comments VARCHAR2(500) , create_by VARCHAR2(50) NOT NULL , create_ts TIMESTAMP NOT NULL , update_by VARCHAR2(50) , update_ts TIMESTAMP ) ; COMMENT ON TABLE employee IS '员工信息表'; COMMENT ON COLUMN employee.emp_id IS '员工编号,自增主键'; COMMENT ON COLUMN employee.emp_name IS '员工姓名'; COMMENT ON COLUMN employee.sex IS '性别'; COMMENT ON COLUMN employee.dept_id IS '部门编号'; COMMENT ON COLUMN employee.manager IS '上级经理'; COMMENT ON COLUMN employee.hire_date IS '入职日期'; COMMENT ON COLUMN employee.job_id IS '职位编号'; COMMENT ON COLUMN employee.salary IS '月薪'; COMMENT ON COLUMN employee.bonus IS '年终奖金'; COMMENT ON COLUMN employee.email IS '电子邮箱'; COMMENT ON COLUMN employee.comments IS '备注信息'; COMMENT ON COLUMN employee.create_by IS '创建者'; COMMENT ON COLUMN employee.create_ts IS '创建时间'; COMMENT ON COLUMN employee.update_by IS '修改者'; COMMENT ON COLUMN employee.update_ts IS '修改时间'; INSERT INTO employee(EMP_ID,emp_name, sex, dept_id, manager, hire_date, job_id, salary, bonus, email, comments, create_by, create_ts, update_by, update_ts) VALUES (1,'刘备', '男', 1, NULL, DATE '2000-01-01', 1, 30000, 10000, 'liubei@shuguo.com', NULL, 'Admin', TIMESTAMP '2000-01-01 10:00:00', NULL, NULL); INSERT INTO employee(EMP_ID,emp_name, sex, dept_id, manager, hire_date, job_id, salary, bonus, email, comments, create_by, create_ts, update_by, update_ts) VALUES (2,'关羽', '男', 1, 1, DATE '2000-01-01', 2, 26000, 10000, 'guanyu@shuguo.com', NULL, 'Admin', TIMESTAMP '2000-01-01 10:00:00', NULL, NULL); INSERT INTO employee(EMP_ID,emp_name, sex, dept_id, manager, hire_date, job_id, salary, bonus, email, comments, create_by, create_ts, update_by, update_ts) VALUES (3,'张飞', '男', 1, 1, DATE '2000-01-01', 2, 24000, 10000, 'zhangfei@shuguo.com', NULL, 'Admin', TIMESTAMP '2000-01-01 10:00:00', NULL, NULL); INSERT INTO employee(EMP_ID,emp_name, sex, dept_id, manager, hire_date, job_id, salary, bonus, email, comments, create_by, create_ts, update_by, update_ts) VALUES (4,'诸葛亮', '男', 2, 1, DATE '2006-03-15', 3, 24000, 8000, 'zhugeliang@shuguo.com', NULL, 'Admin', TIMESTAMP '2006-03-15 10:00:00', NULL, NULL); INSERT INTO employee(EMP_ID,emp_name, sex, dept_id, manager, hire_date, job_id, salary, bonus, email, comments, create_by, create_ts, update_by, update_ts) VALUES (5,'黄忠', '男', 2, 4, DATE '2008-10-25', 4, 8000, NULL, 'huangzhong@shuguo.com', NULL, 'Admin', TIMESTAMP '2008-10-25 10:00:00', NULL, NULL); INSERT INTO employee(EMP_ID,emp_name, sex, dept_id, manager, hire_date, job_id, salary, bonus, email, comments, create_by, create_ts, update_by, update_ts) VALUES (6,'魏延', '男', 2, 4, DATE '2007-04-01', 4, 7500, NULL, 'weiyan@shuguo.com', NULL, 'Admin', TIMESTAMP '2007-04-01 10:00:00', NULL, NULL); INSERT INTO employee(EMP_ID,emp_name, sex, dept_id, manager, hire_date, job_id, salary, bonus, email, comments, create_by, create_ts, update_by, update_ts) VALUES (7,'孙尚香', '女', 3, 1, DATE '2002-08-08', 5, 12000, 5000, 'sunshangxiang@shuguo.com', NULL, 'Admin', TIMESTAMP '2002-08-08 10:00:00', NULL, NULL); INSERT INTO employee(EMP_ID,emp_name, sex, dept_id, manager, hire_date, job_id, salary, bonus, email, comments, create_by, create_ts, update_by, update_ts) VALUES (8,'孙丫鬟', '女', 3, 7, DATE '2002-08-08', 6, 6000, NULL, 'sunyahuan@shuguo.com', NULL, 'Admin', TIMESTAMP '2002-08-08 10:00:00', NULL, NULL); INSERT INTO employee(EMP_ID,emp_name, sex, dept_id, manager, hire_date, job_id, salary, bonus, email, comments, create_by, create_ts, update_by, update_ts) VALUES (9,'赵云', '男', 4, 1, DATE '2005-12-19', 7, 15000, 6000, 'zhaoyun@shuguo.com', NULL, 'Admin', TIMESTAMP '2005-12-19 10:00:00', 'Admin', TIMESTAMP '2006-12-31 10:00:00'); INSERT INTO employee(EMP_ID,emp_name, sex, dept_id, manager, hire_date, job_id, salary, bonus, email, comments, create_by, create_ts, update_by, update_ts) VALUES (10,'廖化', '男', 4, 9, DATE '2009-02-17', 8, 6500, NULL, 'liaohua@shuguo.com', NULL, 'Admin', TIMESTAMP '2009-02-17 10:00:00', NULL, NULL); INSERT INTO employee(EMP_ID,emp_name, sex, dept_id, manager, hire_date, job_id, salary, bonus, email, comments, create_by, create_ts, update_by, update_ts) VALUES (11,'关平', '男', 4, 9, DATE '2011-07-24', 8, 6800, NULL, 'guanping@shuguo.com', NULL, 'Admin', TIMESTAMP '2011-07-24 10:00:00', NULL, NULL); INSERT INTO employee(EMP_ID,emp_name, sex, dept_id, manager, hire_date, job_id, salary, bonus, email, comments, create_by, create_ts, update_by, update_ts) VALUES (12,'赵氏', '女', 4, 9, DATE '2011-11-10', 8, 6600, NULL, 'zhaoshi@shuguo.com', NULL, 'Admin', TIMESTAMP '2011-11-10 10:00:00', NULL, NULL); INSERT INTO employee(EMP_ID,emp_name, sex, dept_id, manager, hire_date, job_id, salary, bonus, email, comments, create_by, create_ts, update_by, update_ts) VALUES (13,'关兴', '男', 4, 9, DATE '2011-07-30', 8, 7000, NULL, 'guanxing@shuguo.com', NULL, 'Admin', TIMESTAMP '2011-07-30 10:00:00', NULL, NULL); INSERT INTO employee(EMP_ID,emp_name, sex, dept_id, manager, hire_date, job_id, salary, bonus, email, comments, create_by, create_ts, update_by, update_ts) VALUES (14,'张苞', '男', 4, 9, DATE '2012-05-31', 8, 6500, NULL, 'zhangbao@shuguo.com', NULL, 'Admin', TIMESTAMP '2012-05-31 10:00:00', NULL, NULL); INSERT INTO employee(EMP_ID,emp_name, sex, dept_id, manager, hire_date, job_id, salary, bonus, email, comments, create_by, create_ts, update_by, update_ts) VALUES (15,'赵统', '男', 4, 9, DATE '2012-05-03', 8, 6000, NULL, 'zhaotong@shuguo.com', NULL, 'Admin', TIMESTAMP '2012-05-03 10:00:00', NULL, NULL); INSERT INTO employee(EMP_ID,emp_name, sex, dept_id, manager, hire_date, job_id, salary, bonus, email, comments, create_by, create_ts, update_by, update_ts) VALUES (16,'周仓', '男', 4, 9, DATE '2010-02-20', 8, 8000, NULL, 'zhoucang@shuguo.com', NULL, 'Admin', TIMESTAMP '2010-02-20 10:00:00', NULL, NULL); INSERT INTO employee(EMP_ID,emp_name, sex, dept_id, manager, hire_date, job_id, salary, bonus, email, comments, create_by, create_ts, update_by, update_ts) VALUES (17,'马岱', '男', 4, 9, DATE '2014-09-16', 8, 5800, NULL, 'madai@shuguo.com', NULL, 'Admin', TIMESTAMP '2014-09-16 10:00:00', NULL, NULL); INSERT INTO employee(EMP_ID,emp_name, sex, dept_id, manager, hire_date, job_id, salary, bonus, email, comments, create_by, create_ts, update_by, update_ts) VALUES (18,'法正', '男', 5, 2, DATE '2017-04-09', 9, 10000, 5000, 'fazheng@shuguo.com', NULL, 'Admin', TIMESTAMP '2017-04-09 10:00:00', NULL, NULL); INSERT INTO employee(EMP_ID,emp_name, sex, dept_id, manager, hire_date, job_id, salary, bonus, email, comments, create_by, create_ts, update_by, update_ts) VALUES (19,'庞统', '男', 5, 18, DATE '2017-06-06', 10, 4100, 2000, 'pangtong@shuguo.com', NULL, 'Admin', TIMESTAMP '2017-06-06 10:00:00', NULL, NULL); INSERT INTO employee(EMP_ID,emp_name, sex, dept_id, manager, hire_date, job_id, salary, bonus, email, comments, create_by, create_ts, update_by, update_ts) VALUES (20,'蒋琬', '男', 5, 18, DATE '2018-01-28', 10, 4000, 1500, 'jiangwan@shuguo.com', NULL, 'Admin', TIMESTAMP '2018-01-28 10:00:00', NULL, NULL); INSERT INTO employee(EMP_ID,emp_name, sex, dept_id, manager, hire_date, job_id, salary, bonus, email, comments, create_by, create_ts, update_by, update_ts) VALUES (21,'黄权', '男', 5, 18, DATE '2018-03-14', 10, 4200, NULL, 'huangquan@shuguo.com', NULL, 'Admin', TIMESTAMP '2018-03-14 10:00:00', NULL, NULL); INSERT INTO employee(EMP_ID,emp_name, sex, dept_id, manager, hire_date, job_id, salary, bonus, email, comments, create_by, create_ts, update_by, update_ts) VALUES (22,'糜竺', '男', 5, 18, DATE '2018-03-27', 10, 4300, NULL, 'mizhu@shuguo.com', NULL, 'Admin', TIMESTAMP '2018-03-27 10:00:00', NULL, NULL); INSERT INTO employee(EMP_ID,emp_name, sex, dept_id, manager, hire_date, job_id, salary, bonus, email, comments, create_by, create_ts, update_by, update_ts) VALUES (23,'邓芝', '男', 5, 18, DATE '2018-11-11', 10, 4000, NULL, 'dengzhi@shuguo.com', NULL, 'Admin', TIMESTAMP '2018-11-11 10:00:00', NULL, NULL); INSERT INTO employee(EMP_ID,emp_name, sex, dept_id, manager, hire_date, job_id, salary, bonus, email, comments, create_by, create_ts, update_by, update_ts) VALUES (24,'简雍', '男', 5, 18, DATE '2019-05-11', 10, 4800, NULL, 'jianyong@shuguo.com', NULL, 'Admin', TIMESTAMP '2019-05-11 10:00:00', NULL, NULL); INSERT INTO employee(EMP_ID,emp_name, sex, dept_id, manager, hire_date, job_id, salary, bonus, email, comments, create_by, create_ts, update_by, update_ts) VALUES (25,'孙乾', '男', 5, 18, DATE '2018-10-09', 10, 4700, NULL, 'sunqian@shuguo.com', NULL, 'Admin', TIMESTAMP '2018-10-09 10:00:00', NULL, NULL);
推荐学习:《SQL教程》
위 내용은 한 기사에서 SQL 창 기능에 대한 자세한 설명의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

Video Face Swap
완전히 무료인 AI 얼굴 교환 도구를 사용하여 모든 비디오의 얼굴을 쉽게 바꾸세요!

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7677
7677
 15
1393
52
1207
24
91
11
73
19
15
1393
52
1207
24
91
11
73
19

 Hibernate 프레임워크에서 HQL과 SQL의 차이점은 무엇입니까?
Apr 17, 2024 pm 02:57 PM
Hibernate 프레임워크에서 HQL과 SQL의 차이점은 무엇입니까?
Apr 17, 2024 pm 02:57 PM
HQL과 SQL은 Hibernate 프레임워크에서 비교됩니다. HQL(1. 객체 지향 구문, 2. 데이터베이스 독립적 쿼리, 3. 유형 안전성), SQL은 데이터베이스를 직접 운영합니다(1. 데이터베이스 독립적 표준, 2. 복잡한 실행 파일) 쿼리 및 데이터 조작).
 Oracle SQL의 나누기 연산 사용법
Mar 10, 2024 pm 03:06 PM
Oracle SQL의 나누기 연산 사용법
Mar 10, 2024 pm 03:06 PM
"OracleSQL의 나눗셈 연산 사용법" OracleSQL에서 나눗셈 연산은 일반적인 수학 연산 중 하나입니다. 데이터 쿼리 및 처리 중에 나누기 작업은 필드 간의 비율을 계산하거나 특정 값 간의 논리적 관계를 도출하는 데 도움이 될 수 있습니다. 이 문서에서는 OracleSQL의 나누기 작업 사용법을 소개하고 구체적인 코드 예제를 제공합니다. 1. OracleSQL의 두 가지 분할 연산 방식 OracleSQL에서는 두 가지 방식으로 분할 연산을 수행할 수 있습니다.
 Oracle과 DB2의 SQL 구문 비교 및 차이점
Mar 11, 2024 pm 12:09 PM
Oracle과 DB2의 SQL 구문 비교 및 차이점
Mar 11, 2024 pm 12:09 PM
Oracle과 DB2는 일반적으로 사용되는 관계형 데이터베이스 관리 시스템으로, 각각 고유한 SQL 구문과 특성을 가지고 있습니다. 이 기사에서는 Oracle과 DB2의 SQL 구문을 비교 및 차이점을 설명하고 구체적인 코드 예제를 제공합니다. 데이터베이스 연결 Oracle에서는 다음 문을 사용하여 데이터베이스에 연결합니다. CONNECTusername/password@database DB2에서 데이터베이스에 연결하는 문은 다음과 같습니다. CONNECTTOdataba
 MyBatis 동적 SQL 태그의 Set 태그 기능에 대한 자세한 설명
Feb 26, 2024 pm 07:48 PM
MyBatis 동적 SQL 태그의 Set 태그 기능에 대한 자세한 설명
Feb 26, 2024 pm 07:48 PM
MyBatis 동적 SQL 태그 해석: Set 태그 사용법에 대한 자세한 설명 MyBatis는 풍부한 동적 SQL 태그를 제공하고 데이터베이스 작업 명령문을 유연하게 구성할 수 있는 탁월한 지속성 계층 프레임워크입니다. 그 중 Set 태그는 업데이트 작업에서 매우 일반적으로 사용되는 UPDATE 문에서 SET 절을 생성하는 데 사용됩니다. 이 기사에서는 MyBatis에서 Set 태그의 사용법을 자세히 설명하고 특정 코드 예제를 통해 해당 기능을 보여줍니다. Set 태그란 무엇입니까? Set 태그는 MyBati에서 사용됩니다.
 SQL의 ID 속성은 무엇을 의미합니까?
Feb 19, 2024 am 11:24 AM
SQL의 ID 속성은 무엇을 의미합니까?
Feb 19, 2024 am 11:24 AM
SQL에서 ID란 무엇입니까? SQL에서 ID는 자동 증가 숫자를 생성하는 데 사용되는 특수 데이터 유형으로, 테이블의 각 데이터 행을 고유하게 식별하는 데 사용됩니다. ID 열은 일반적으로 기본 키 열과 함께 사용되어 각 레코드에 고유한 식별자가 있는지 확인합니다. 이 문서에서는 Identity를 사용하는 방법과 몇 가지 실제 코드 예제를 자세히 설명합니다. Identity를 사용하는 기본 방법은 테이블을 생성할 때 Identit을 사용하는 것입니다.
 여러 테이블을 추가하기 위해 SQL 문을 사용하지 않고 Springboot+Mybatis-plus를 구현하는 방법
Jun 02, 2023 am 11:07 AM
여러 테이블을 추가하기 위해 SQL 문을 사용하지 않고 Springboot+Mybatis-plus를 구현하는 방법
Jun 02, 2023 am 11:07 AM
Springboot+Mybatis-plus가 다중 테이블 추가 작업을 수행하기 위해 SQL 문을 사용하지 않을 때 내가 직면한 문제는 테스트 환경에서 생각을 시뮬레이션하여 분해됩니다. 매개 변수가 있는 BrandDTO 개체를 생성하여 배경으로 매개 변수 전달을 시뮬레이션합니다. Mybatis-plus에서 다중 테이블 작업을 수행하는 것은 매우 어렵다는 것을 Mybatis-plus-join과 같은 도구를 사용하지 않으면 해당 Mapper.xml 파일을 구성하고 냄새나고 긴 ResultMap만 구성하면 됩니다. 해당 SQL 문을 작성합니다. 이 방법은 번거로워 보이지만 매우 유연하며 다음을 수행할 수 있습니다.
 SQL에서 5120 오류를 해결하는 방법
Mar 06, 2024 pm 04:33 PM
SQL에서 5120 오류를 해결하는 방법
Mar 06, 2024 pm 04:33 PM
해결 방법: 1. 로그인한 사용자에게 데이터베이스에 액세스하거나 운영할 수 있는 충분한 권한이 있는지 확인하고 해당 사용자에게 올바른 권한이 있는지 확인하십시오. 2. SQL Server 서비스 계정에 지정된 파일에 액세스할 수 있는 권한이 있는지 확인하십시오. 3. 지정된 데이터베이스 파일이 다른 프로세스에 의해 열렸거나 잠겼는지 확인하고 파일을 닫거나 해제한 후 쿼리를 다시 실행하십시오. .관리자로 Management Studio를 실행해 보세요.
 MySQL에서 데이터 집계 및 통계를 위해 SQL 문을 사용하는 방법은 무엇입니까?
Dec 17, 2023 am 08:41 AM
MySQL에서 데이터 집계 및 통계를 위해 SQL 문을 사용하는 방법은 무엇입니까?
Dec 17, 2023 am 08:41 AM
MySQL에서 데이터 집계 및 통계를 위해 SQL 문을 사용하는 방법은 무엇입니까? 데이터 집계 및 통계는 데이터 분석 및 통계를 수행할 때 매우 중요한 단계입니다. 강력한 관계형 데이터베이스 관리 시스템인 MySQL은 데이터 집계 및 통계 작업을 쉽게 수행할 수 있는 풍부한 집계 및 통계 기능을 제공합니다. 이 기사에서는 SQL 문을 사용하여 MySQL에서 데이터 집계 및 통계를 수행하는 방법을 소개하고 구체적인 코드 예제를 제공합니다. 1. COUNT 함수를 사용합니다. COUNT 함수는 가장 일반적으로 사용됩니다.
