

MySQL 제약 조건 및 다중 테이블 쿼리의 기본 사항에 대한 자세한 설명

이 글에서는 주로 제약 조건 및 다중 테이블 쿼리와 관련된 문제를 정리하는 mysql에 대한 관련 지식을 제공합니다. 제약 조건은 테이블의 필드에 작용하고 테이블에 저장된 데이터를 제한하는 데 사용되는 규칙입니다. 함께 보시고, 모두에게 도움이 되었으면 좋겠습니다.

추천 학습: mysql 비디오 튜토리얼
1. 제약 조건
개요
개념: 제약 조건은 테이블에 저장된 데이터를 제한하기 위해 테이블의 필드에 작용하는 규칙입니다.
목적: 데이터베이스에 있는 데이터의 정확성, 유효성 및 무결성을 보장합니다.
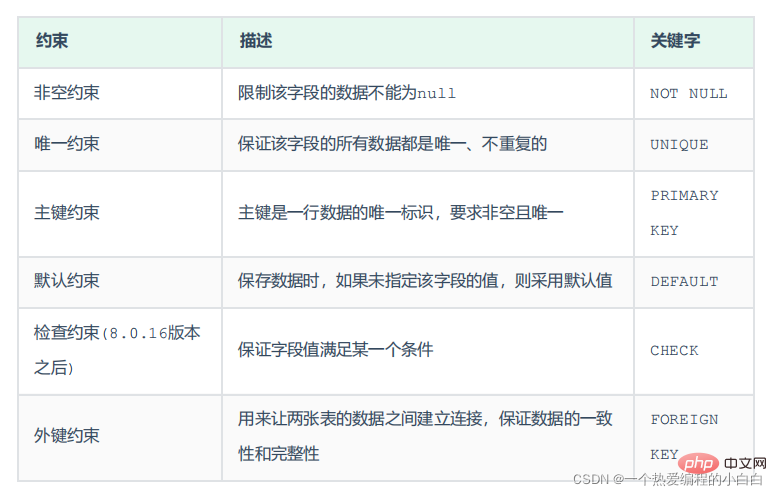
참고: 제약 조건은 테이블의 필드에 적용됩니다. 테이블을 생성/수정할 때 제약 조건을 추가할 수 있습니다.
제약 조건 증명
지금까지 데이터베이스의 공통 제약 조건과 제약 조건에 관련된 키워드를 소개했습니다. 그러면 테이블을 생성하고 테이블을 수정할 때 이러한 제약 조건을 어떻게 지정해야 할까요? 다음으로 사례를 통해 이를 보여드리겠습니다.
케이스 요구사항: 요구사항에 따라 테이블 구조 생성을 완료하세요. 요구 사항은 다음과 같습니다.
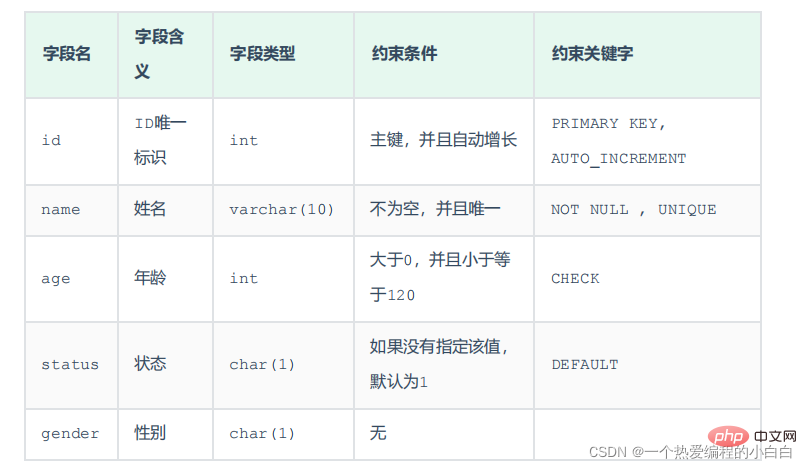 해당 테이블 생성 문은 다음과 같습니다.
해당 테이블 생성 문은 다음과 같습니다.
CREATE TABLE tb_user ( id int AUTO_INCREMENT PRIMARY KEY COMMENT 'ID唯一标识', name varchar(10) NOT NULL UNIQUE COMMENT '姓名', age tinyint unsigned COMMENT '年龄', status char(1) default '1' COMMENT '状态', gender char(1) COMMENT '性别' );
Mysql 버전이 8 이상인 경우 다음과 같이 age를 생성할 수 있습니다.
age int check (age > 0 && age <p> 필드에 제약 조건을 추가할 때 추가하기만 하면 됩니다. 키워드 필드 뒤에 제약 조건이 있으면 충분하지만 해당 구문에 주의를 기울여야 합니다. 위의 SQL을 실행하여 테이블 구조를 생성한 다음 데이터 세트를 통해 테스트하여 제약 조건이 적용될 수 있는지 확인합니다. </p><pre class="brush:php;toolbar:false">insert into tb_user(name, age, status, gender)
values ('Tom1', 19, '1', '男'),
('Tom2', 25, '0', '男');
insert into tb_user(name, age, status, gender)
values ('Tom3', 19, '1', '男');
insert into tb_user(name, age, status, gender)
values (null, 19, '1', '男');
insert into tb_user(name, age, status, gender)
values ('Tom3', 19, '1', '男');
insert into tb_user(name, age, status, gender)
values ('Tom4', 80, '1', '男');
insert into tb_user(name, age, status, gender)
values ('Tom5', -1, '1', '男');
insert into tb_user(name, age, status, gender)
values ('Tom5', 121, '1', '男');
insert into tb_user(name, age, gender)
values ('Tom5', 120, '男');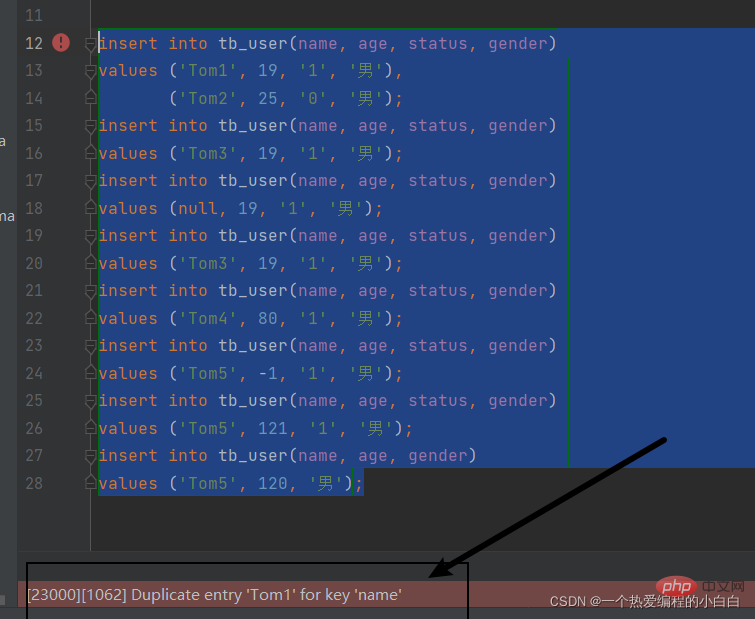
 Visible 우리가 설정한 이름에 대한 제약 조건: 비어 있지 않고 고유한 효과가 적용됩니다.
Visible 우리가 설정한 이름에 대한 제약 조건: 비어 있지 않고 고유한 효과가 적용됩니다.
위에서 SQL 문을 작성하여 제약 조건 지정을 완료했습니다. 그런데 그래픽 인터페이스를 통해 테이블 구조를 생성할 때 제약 조건을 어떻게 지정해야 할까요? 테이블을 생성할 때 필요에 따라 해당 제약 조건을 선택하기만 하면 됩니다.
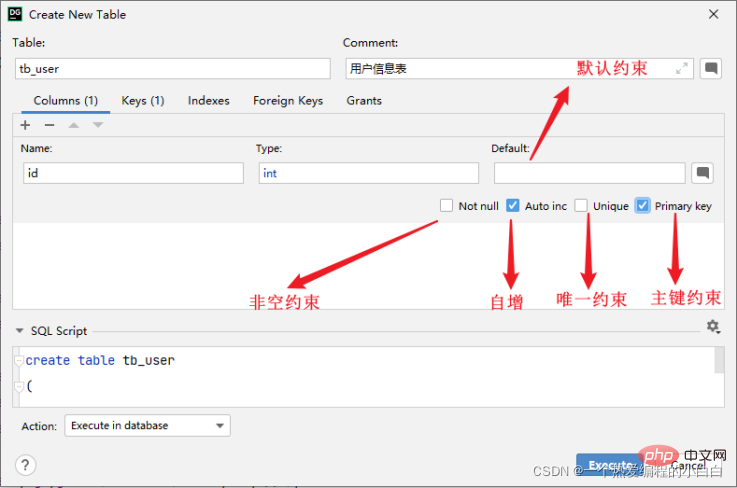
소개
외래 키: 데이터의 일관성과 무결성을 보장하기 위해 두 테이블의 데이터 간 연결을 설정하는 데 사용됩니다.
예제를 살펴보겠습니다.
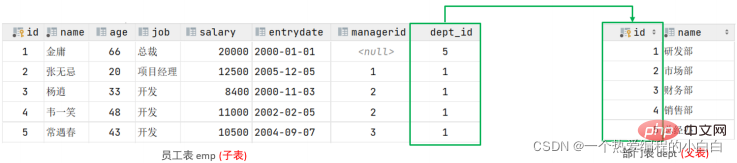 왼쪽의 emp 테이블은 직원 ID, 이름, 나이, 직위, 급여, 입사일, 감독자 등 직원의 기본 정보를 저장하는 직원 테이블입니다. ID, 부서 ID, 직원 정보에 저장되는 것은 부서 ID dept_id이고, 이 부서의 ID는 연관된 부서 테이블 dept의 기본 키 id입니다. 그러면 emp 테이블의 dept_id는 외래 키입니다. 다른 테이블의 기본 키와 연결됩니다.
왼쪽의 emp 테이블은 직원 ID, 이름, 나이, 직위, 급여, 입사일, 감독자 등 직원의 기본 정보를 저장하는 직원 테이블입니다. ID, 부서 ID, 직원 정보에 저장되는 것은 부서 ID dept_id이고, 이 부서의 ID는 연관된 부서 테이블 dept의 기본 키 id입니다. 그러면 emp 테이블의 dept_id는 외래 키입니다. 다른 테이블의 기본 키와 연결됩니다.
데이터베이스 외래 키 연결 없이 일관성과 무결성을 보장할 수 있나요? 테스트해 보겠습니다.
데이터 준비
create table dept ( id int auto_increment comment 'ID' primary key, name varchar(50) not null comment '部门名称' ) comment '部门表'; INSERT INTO dept (id, name) VALUES (1, '研发部'), (2, '市场部'), (3, '财务部'), (4, '销售部'), (5, '总经办'); create table emp ( id int auto_increment comment 'ID' primary key, name varchar(50) not null comment '姓名', age int comment '年龄', job varchar(20) comment '职位', salary int comment '薪资', entrydate date comment '入职时间', managerid int comment '直属领导ID', dept_id int comment '部门ID' ) comment '员工表'; INSERT INTO emp (id, name, age, job, salary, entrydate, managerid, dept_id) VALUES (1, '金庸', 66, '总裁', 20000, '2000-01-01', null, 5), (2, '张无忌', 20, '项目经理', 12500, '2005-12-05', 1, 1), (3, '杨逍', 33, '开发', 8400, '2000-11-03', 2, 1), (4, '韦一笑', 48, '开 发', 11000, '2002-02-05', 2, 1), (5, '常遇春', 43, '开发', 10500, '2004-09-07', 3, 1), (6, '小昭', 19, '程 序员鼓励师', 6600, '2004-10-12', 2, 1);
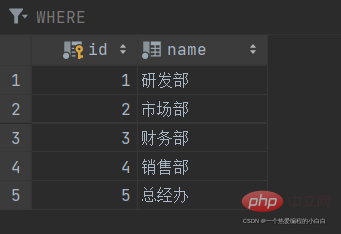
接下来,我们可以做一个测试,删除id为1的部门信息。
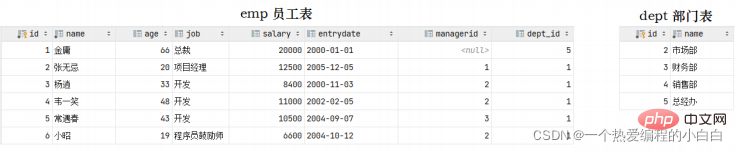
结果,我们看到删除成功,而删除成功之后,部门表不存在id为1的部门,而在emp表中还有很多的员工,关联的为id为1的部门,此时就出现了数据的不完整性。 而要想解决这个问题就得通过数据库的外键约束。
语法
1). 添加外键
CREATE TABLE 表名 ( 字段名 数据类型, ... [ CONSTRAINT] [ 外键名称] FOREIGN KEY ( 外键字段名 ) REFERENCES 主表 ( 主表列名 ) );
ALTER TABLE 表名 ADD CONSTRAINT 外键名称 FOREIGN KEY (外键字段名) REFERENCES 主表 (主表列名);
案例:
为emp表的dept_id字段添加外键约束,关联dept表的主键id。
alter table emp add constraint fk_emp_dept_id foreign key (dept_id) references dept (id);
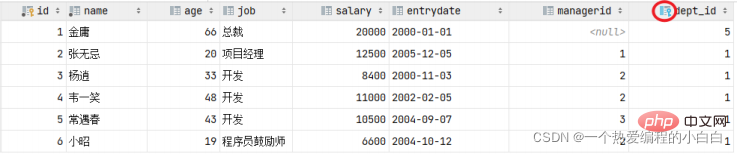
添加了外键约束之后,我们再到dept表(父表)删除id为1的记录,然后看一下会发生什么现象。 此时
将会报错,不能删除或更新父表记录,因为存在外键约束。

2). 删除外键
ALTER TABLE 表名 DROP FOREIGN KEY 外键名称;
案例:
删除emp表的外键fk_emp_dept_id
alter table emp drop foreign key fk_emp_dept_id; 1
删除/更新行为
添加了外键之后,再删除父表数据时产生的约束行为,我们就称为删除/更新行为。具体的删除/更新行为有以下几种:
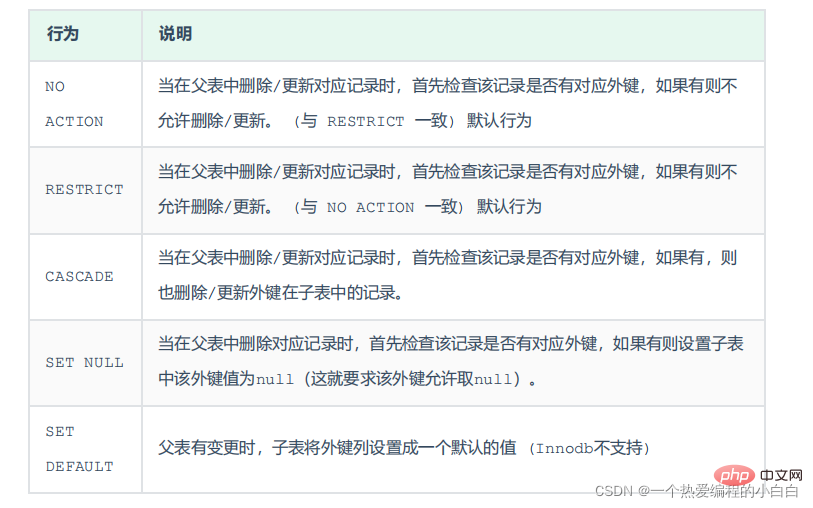
具体语法为:
ALTER TABLE 表名 ADD CONSTRAINT 外键名称 FOREIGN KEY (外键字段) REFERENCES 主表名 (主表字段名) ON UPDATE CASCADE ON DELETE CASCADE;
演示如下:
由于NO ACTION 是默认行为,我们前面语法演示的时候,已经测试过了,就不再演示了,这里我们再
演示其他的两种行为:CASCADE、SET NULL。
1). CASCADE
alter table emp add constraint fk_emp_dept_id foreign key (dept_id) references dept (id) on update cascade on delete cascade;
A. 修改父表id为1的记录,将id修改为6

我们发现,原来在子表中dept_id值为1的记录,现在也变为6了,这就是cascade级联的效果
在一般的业务系统中,不会修改一张表的主键值。
B. 删除父表id为6的记录

我们发现,父表的数据删除成功了,但是子表中关联的记录也被级联删除了。
2). SET NULL
在进行测试之前,我们先需要删除上面建立的外键 fk_emp_dept_id。然后再通过数据脚本,将 emp、dept表的数据恢复了。
alter table emp add constraint fk_emp_dept_id foreign key (dept_id) references dept (id) on update set null on delete set null;
接下来,我们删除id为1的数据,看看会发生什么样的现象。
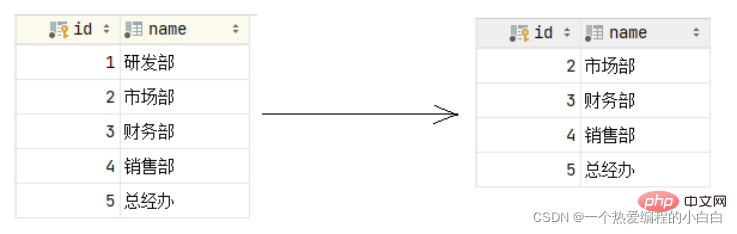
我们发现父表的记录是可以正常的删除的,父表的数据删除之后,再打开子表 emp,我们发现子表emp 的dept_id字段,原来dept_id为1的数据,现在都被置为NULL了
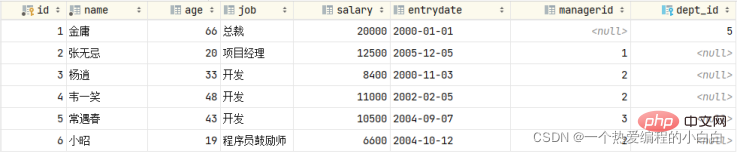
这就是SET NULL这种删除/更新行为的效果。
2.多表查询
我们之前在讲解SQL语句的时候,讲解了DQL语句,也就是数据查询语句,但是之前讲解的查询都是单表查询,而本章节我们要学习的则是多表查询操作,主要从以下几个方面进行讲解。
多表关系
项目开发中,在进行数据库表结构设计时,会根据业务需求及业务模块之间的关系,分析并设计表结 构,由于业务之间相互关联,所以各个表结构之间也存在着各种联系,基本上分为三种:
一对多(多对一) 多对多 一对一
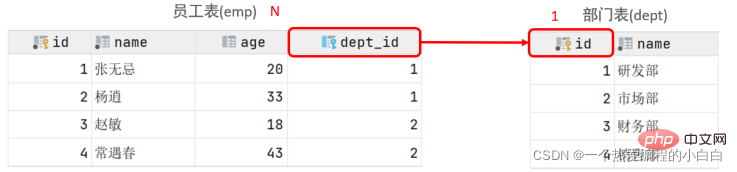
1.一对多
案例: 部门 与 员工的关系
关系: 一个部门对应多个员工,一个员工对应一个部门
实现: 在多的一方建立外键,指向一的一方的主键
2.多对多
案例: 学生 与 课程的关系
关系: 一个学生可以选修多门课程,一门课程也可以供多个学生选择
实现: 建立第三张中间表,中间表至少包含两个外键,分别关联两方主键
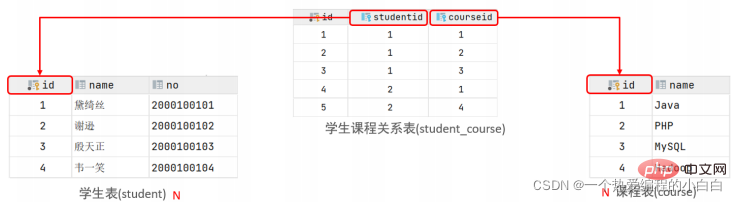
对应的SQL脚本:
create table student ( id int auto_increment primary key comment '主键ID', name varchar(10) comment '姓名', no varchar(10) comment '学号' ) comment '学生表'; insert into student values (null, '黛绮丝', '2000100101'), (null, '谢逊', '2000100102'), (null, '殷天正', '2000100103'), (null, '韦一笑', '2000100104'); create table course ( id int auto_increment primary key comment '主键ID', name varchar(10) comment '课程名称' ) comment '课程表'; insert into course values (null, 'Java'), (null, 'PHP'), (null, 'MySQL'), (null, 'Hadoop'); create table student_course ( id int auto_increment comment '主键' primary key, studentid int not null comment '学生ID', courseid int not null comment '课程ID', constraint fk_courseid foreign key (courseid) references course (id), constraint fk_studentid foreign key (studentid) references student (id) ) comment '学生课程中间表'; insert into student_course values (null, 1, 1), (null, 1, 2), (null, 1, 3), (null, 2, 2), (null, 2, 3), (null, 3, 4);
3.一对一
案例: 用户与 用户详情的关系
关系: 一对一关系,多用于单表拆分,将一张表的基础字段放在一张表中,其他详情字段放在另一张表中,以提升操作效率
实现: 在任意一方加入外键,关联另外一方的主键,并且设置外键为唯一的(UNIQUE)
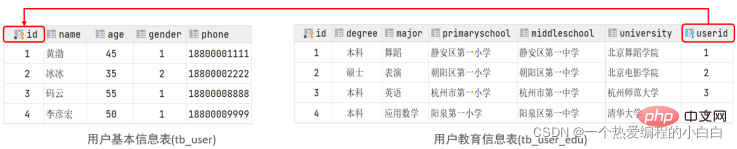
对应的SQL脚本:
create table tb_user ( id int auto_increment primary key comment '主键ID', name varchar(10) comment '姓名', age int comment '年龄', gender char(1) comment '1: 男 , 2: 女', phone char(11) comment '手机号' ) comment '用户基本信息表'; create table tb_user_edu ( id int auto_increment primary key comment '主键ID', degree varchar(20) comment '学历', major varchar(50) comment '专业', primaryschool varchar(50) comment '小学', middleschool varchar(50) comment '中学', university varchar(50) comment '大学', userid int unique comment '用户ID', constraint fk_userid foreign key (userid) references tb_user (id) ) comment '用户教育信息表'; insert into tb_user(id, name, age, gender, phone) values (null, '黄渤', 45, '1', '18800001111'), (null, '冰冰', 35, '2', '18800002222'), (null, '码云', 55, '1', '18800008888'), (null, '李彦宏', 50, '1', '18800009999'); insert into tb_user_edu(id, degree, major, primaryschool, middleschool, university, userid) values (null, '本科', '舞蹈', '静安区第一小学', '静安区第一中学', '北京舞蹈学院', 1), (null, '硕士', '表演', '朝阳区第一小学', '朝阳区第一中学', '北京电影学院', 2), (null, '本科', '英语', '杭州市第一小学', '杭州市第一中学', '杭州师范大学', 3), (null, '本科', '应用数学', '阳泉第一小学', '阳泉区第一中学', '清华大学', 4);
3.多表查询概述
1.数据准备
1). 删除之前 emp, dept表的测试数据
2). 执行如下脚本,创建emp表与dept表并插入测试数据
-- 创建dept表,并插入数据 create table dept ( id int auto_increment comment 'ID' primary key, name varchar(50) not null comment '部门名称' ) comment '部门表'; INSERT INTO dept (id, name) VALUES (1, '研发部'), (2, '市场部'), (3, '财务部'), (4, '销售部'), (5, '总经办'), (6, '人事部'); -- 创建emp表,并插入数据 create table emp ( id int auto_increment comment 'ID' primary key, name varchar(50) not null comment '姓名', age int comment '年龄', job varchar(20) comment '职位', salary int comment '薪资', entrydate date comment '入职时间', managerid int comment '直属领导ID', dept_id int comment '部门ID' ) comment '员工表'; -- 添加外键 alter table emp add constraint fk_emp_dept_id foreign key (dept_id) references dept (id); INSERT INTO emp (id, name, age, job, salary, entrydate, managerid, dept_id) VALUES (1, '金庸', 66, '总裁', 20000, '2000-01-01', null, 5), (2, '张无忌', 20, '项目经理', 12500, '2005-12-05', 1, 1), (3, '杨逍', 33, '开发', 8400, '2000-11-03', 2, 1), (4, '韦一笑', 48, '开发', 11000, '2002-02-05', 2, 1), (5, '常遇春', 43, '开发', 10500, '2004-09-07', 3, 1), (6, '小昭', 19, '程序员鼓励师', 6600, '2004-10-12', 2, 1), (7, '灭绝', 60, '财务总监', 8500, '2002-09-12', 1, 3), (8, '周芷若', 19, '会计', 48000, '2006-06-02', 7, 3), (9, '丁敏君', 23, '出纳', 5250, '2009-05-13', 7, 3), (10, '赵敏', 20, '市场部总监', 12500, '2004-10-12', 1, 2), (11, '鹿杖客', 56, '职员', 3750, '2006-10-03', 10, 2), (12, '鹤笔翁', 19, '职员', 3750, '2007-05-09', 10, 2), (13, '方东白', 19, '职员', 5500, '2009-02-12', 10, 2), (14, '张三丰', 88, '销售总监', 14000, '2004-10-12', 1, 4), (15, '俞莲舟', 38, '销售', 4600, '2004-10-12', 14, 4), (16, '宋远桥', 40, '销售', 4600, '2004-10-12', 14, 4), (17, '陈友谅', 42, null, 2000, '2011-10-12', 1, null)
dept表共6条记录,emp表共17条记录。
2.概述
多表查询就是指从多张表中查询数据。
原来查询单表数据,执行的SQL形式为:select * from emp;
那么我们要执行多表查询,就只需要使用逗号分隔多张表即可,如: select * from emp , dept ; 具体的执行结果如下:
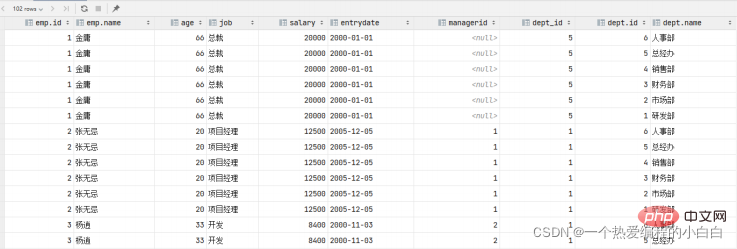
此时,我们看到查询结果中包含了大量的结果集,总共102条记录,而这其实就是员工表emp所有的记录 (17) 与 部门表dept所有记录(6) 的所有组合情况,这种现象称之为笛卡尔积。接下来,就来简单 介绍下笛卡尔积。
笛卡尔积: 笛卡尔乘积是指在数学中,两个集合A集合 和 B集合的所有组合情况。
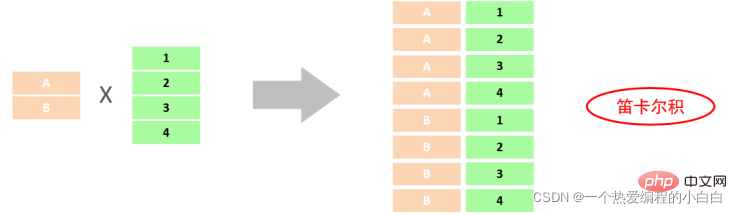
而在多表查询中,我们是需要消除无效的笛卡尔积的,只保留两张表关联部分的数据。

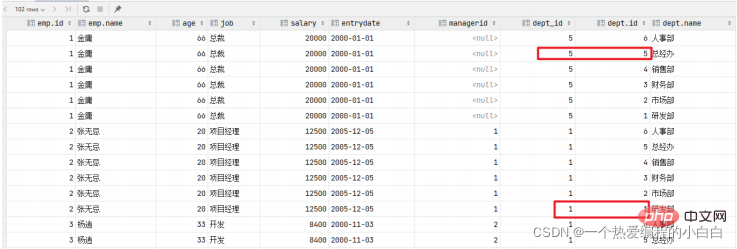
在SQL语句中,如何来去除无效的笛卡尔积呢? 我们可以给多表查询加上连接查询的条件即可。
select * from emp , dept where emp.dept_id = dept.id;

而由于id为17的员工,没有dept_id字段值,所以在多表查询时,根据连接查询的条件并没有查询到。
4.分类
连接查询
内连接:相当于查询A、B交集部分数据
外连接:
左外连接:查询左表所有数据,以及两张表交集部分数据
右外连接:查询右表所有数据,以及两张表交集部分数据
自连接:当前表与自身的连接查询,自连接必须使用表别名
子查询
1.内连接
内连接查询的是两张表交集部分的数据。(也就是绿色部分的数据)
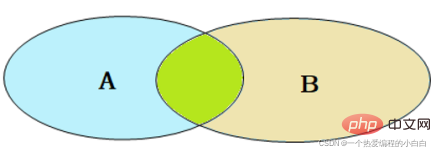
内连接的语法分为两种: 隐式内连接、显式内连接。先来学习一下具体的语法结构。
1). 隐式内连接
SELECT 字段列表 FROM 表1 , 表2 WHERE 条件 ... ;
2). 显式内连接
SELECT 字段列表 FROM 表1 [ INNER ] JOIN 表2 ON 连接条件 ... ;
案例:
A. 查询每一个员工的姓名 , 及关联的部门的名称 (隐式内连接实现)
表结构: emp , dept
连接条件: emp.dept_id = dept.id
select emp.name, dept.name from emp, dept where emp.dept_id = dept.id; -- 为每一张表起别名,简化SQL编写 select e.name,d.name from emp e , dept d where e.dept_id = d.id;
B. 查询每一个员工的姓名 , 及关联的部门的名称 (显式内连接实现) --- INNER JOIN ...
ON ...
表结构: emp , dept
连接条件: emp.dept_id = dept.id
select e.name, d.name from emp e inner join dept d on e.dept_id = d.id; -- 为每一张表起别名,简化SQL编写 select e.name, d.name from emp e join dept d on e.dept_id = d.id;
表的别名:
①. tablea as 别名1 , tableb as 别名2 ;
②. tablea 别名1 , tableb 别名2 ;
注意事项:一旦为表起了别名,就不能再使用表名来指定对应的字段了,此时只能够使用别名来指定字段。
2.外连接
外连接分为两种,分别是:左外连接 和 右外连接。具体的语法结构为:
1). 左外连接
SELECT 字段列表 FROM 表1 LEFT [ OUTER ] JOIN 表2 ON 条件 ... ;
左外连接相当于查询表1(左表)的所有数据,当然也包含表1和表2交集部分的数据。
2). 右外连接
SELECT 字段列表 FROM 表1 RIGHT [ OUTER ] JOIN 表2 ON 条件 ... ;
右外连接相当于查询表2(右表)的所有数据,当然也包含表1和表2交集部分的数据。
案例:
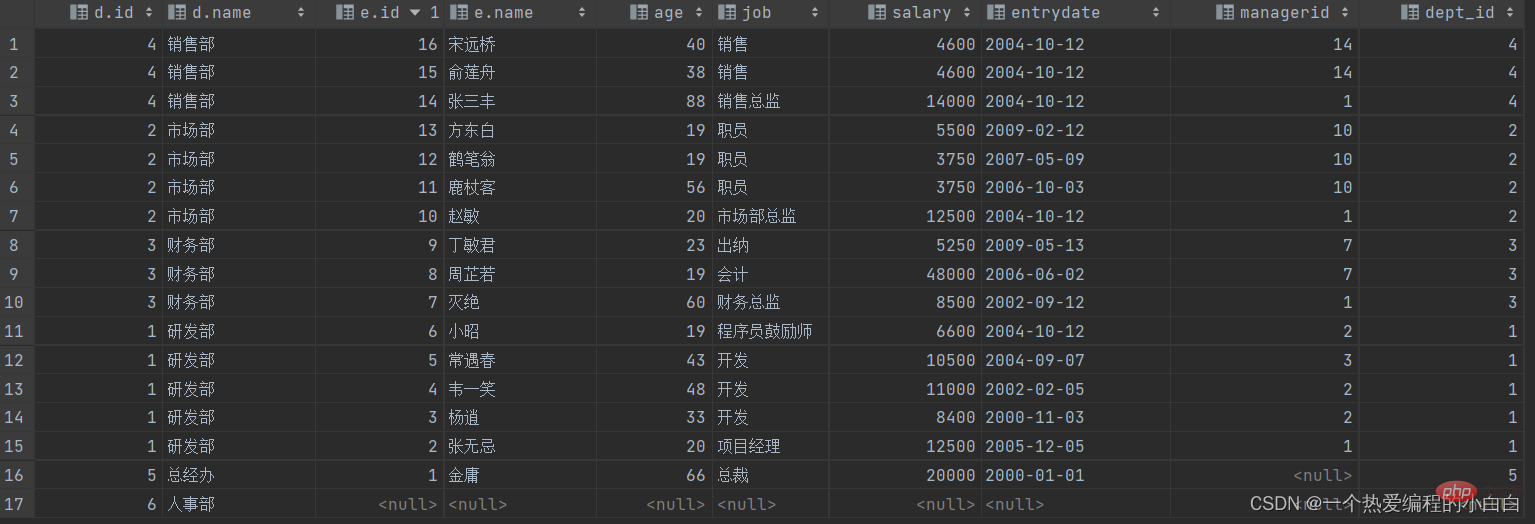
A. 查询emp表的所有数据, 和对应的部门信息
由于需求中提到,要查询emp的所有数据,所以是不能内连接查询的,需要考虑使用外连接查询。
表结构: emp, dept
连接条件: emp.dept_id = dept.id
select e.*, d.name from emp e left outer join dept d on e.dept_id = d.id; select e.*, d.name from emp e left join dept d on e.dept_id = d.id;
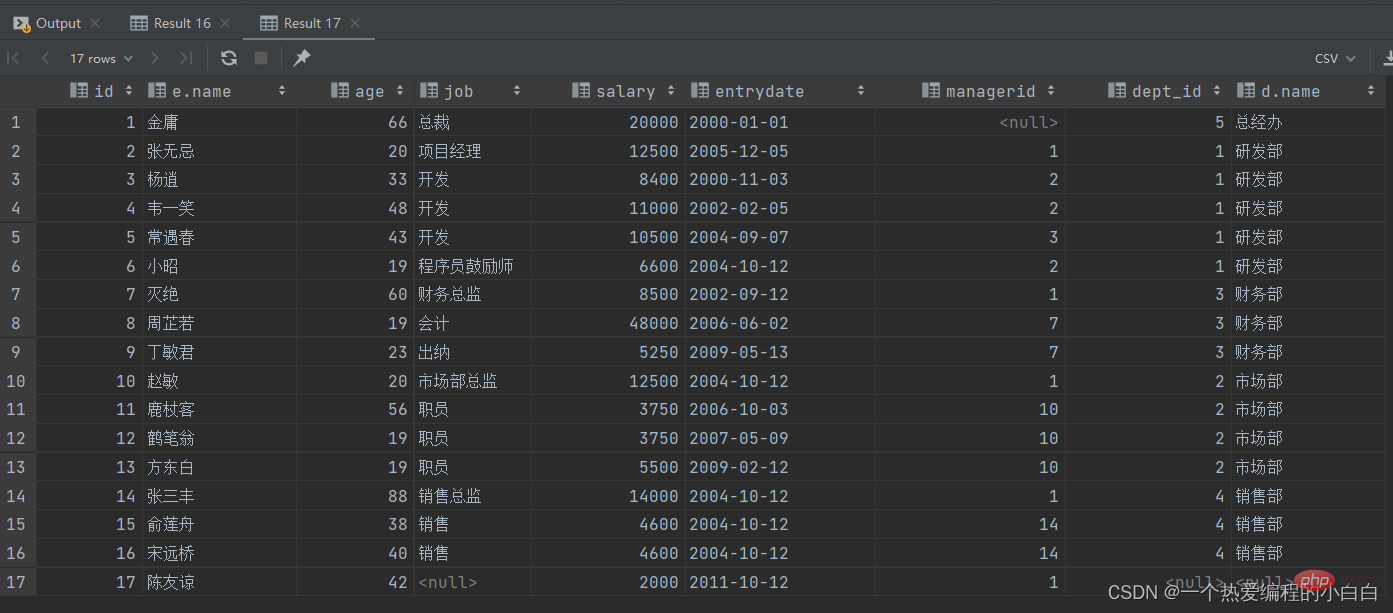
B. 查询dept表的所有数据, 和对应的员工信息(右外连接)
由于需求中提到,要查询dept表的所有数据,所以是不能内连接查询的,需要考虑使用外连接查询。
表结构: emp, dept
连接条件: emp.dept_id = dept.id
select d.*, e.* from emp e right outer join dept d on e.dept_id = d.id; select d.*, e.* from dept d left outer join emp e on e.dept_id = d.id;
注意事项:
左外连接和右外连接是可以相互替换的,只需要调整在连接查询时SQL中,表结构的先后顺
序就可以了。而我们在日常开发使用时,更偏向于左外连接。
3.自连接
1.自连接查询
自连接查询,顾名思义,就是自己连接自己,也就是把一张表连接查询多次。我们先来学习一下自连接的查询语法:
SELECT 字段列表 FROM 表A 别名A JOIN 表A 别名B ON 条件 ... ;로그인 후 복사而对于自连接查询,可以是内连接查询,也可以是外连接查询
案例:
A. 查询员工 及其 所属领导的名字
表结构: emp
select a.name , b.name from emp a , emp b where a.managerid = b.id;
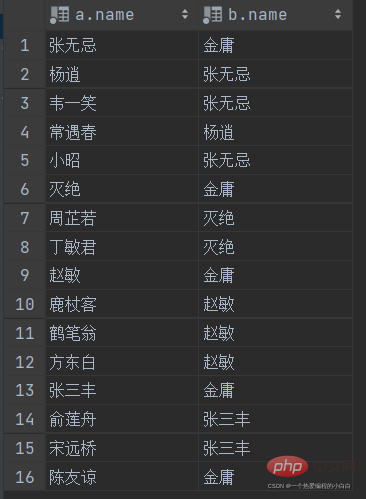
B. 查询所有员工 emp 及其领导的名字 emp , 如果员工没有领导, 也需要查询出来
表结构: emp a , emp b
select a.name '员工', b.name '领导' from emp a left join emp b on a.managerid = b.id;
注意事项:
在自连接查询中,必须要为表起别名,要不然我们不清楚所指定的条件、返回的字段,到底
是哪一张表的字段。
2.联合查询
对于union查询,就是把多次查询的结果合并起来,形成一个新的查询结果集。
SELECT 字段列表 FROM 表A... UNION [ ALL ] SELECT 字段列表 FROM 表B....;
对于联合查询的多张表的列数必须保持一致,字段类型也需要保持一致。
union all 会将全部的数据直接合并在一起,union 会对合并之后的数据去重。
案例:
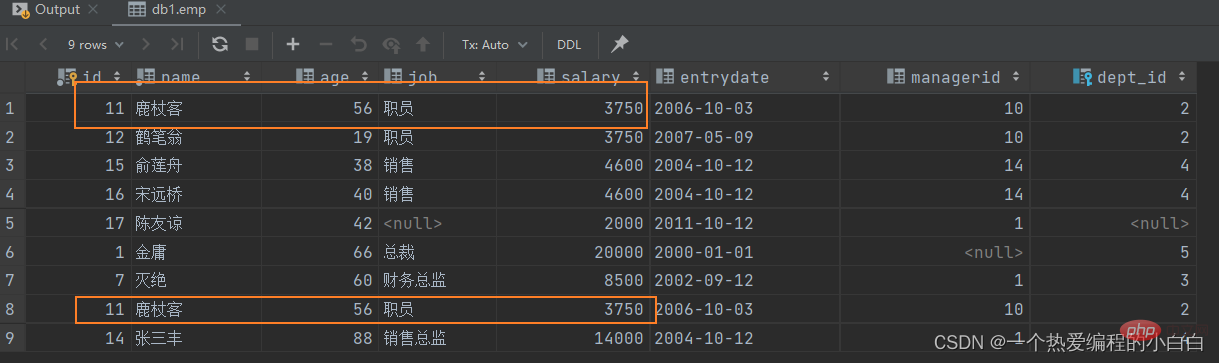
A. 将薪资低于 5000 的员工 , 和 年龄大于 50 岁的员工全部查询出来.
当前对于这个需求,我们可以直接使用多条件查询,使用逻辑运算符 or 连接即可。 那这里呢,我们 也可以通过union/union all来联合查询.
select * from emp where salary 50;
union all查询出来的结果,仅仅进行简单的合并,并未去重。
select * from emp where salary 50;
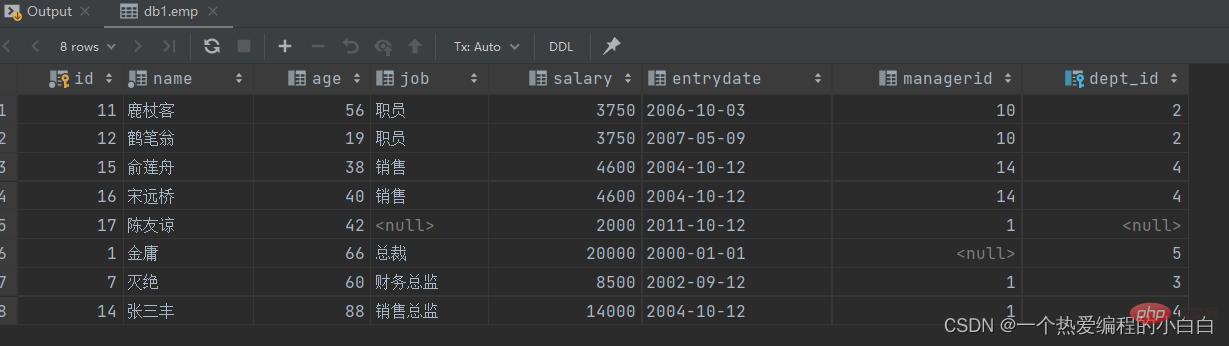
union 联合查询,会对查询出来的结果进行去重处理。
注意:
如果多条查询语句查询出来的结果,字段数量不一致,在进行union/union all联合查询时,将会报
错。如:

4.子查询
1.概述
1). 概念
SQL语句中嵌套SELECT语句,称为嵌套查询,又称子查询。
SELECT * FROM t1 WHERE column1 = ( SELECT column1 FROM t2 );
子查询外部的语句可以是INSERT / UPDATE / DELETE / SELECT 的任何一个。
2). 分类
根据子查询结果不同,分为:
A. 标量子查询(子查询结果为单个值)
B. 列子查询(子查询结果为一列)
C. 行子查询(子查询结果为一行)
D. 表子查询(子查询结果为多行多列)
根据子查询位置,分为:
A. WHERE之后
B. FROM之后
C. SELECT之后
2.标量子查询
子查询返回的结果是单个值(数字、字符串、日期等),最简单的形式,这种子查询称为标量子查询。
常用的操作符:= > >=
案例:
A. 查询 "销售部" 的所有员工信息
完成这个需求时,我们可以将需求分解为两步:
查询 "销售部" 部门ID
select id from dept where name = '销售部';
根据 "销售部" 部门ID, 查询员工信息
select * from emp where dept_id = (select id from dept where name = '销售部');

B. 查询在 "方东白" 入职之后的员工信息
完成这个需求时,我们可以将需求分解为两步:
查询 方东白 的入职日期
select entrydate from emp where name = '方东白';
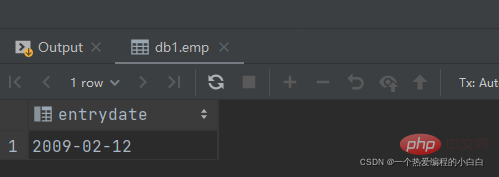
查询指定入职日期之后入职的员工信息
select * from emp where entrydate > (select entrydate from emp where name = '方东白');

3.列子查询
子查询返回的结果是一列(可以是多行),这种子查询称为列子查询。
常用的操作符:IN 、NOT IN 、 ANY 、SOME 、 ALL
案例:
A. 查询 "销售部" 和 "市场部" 的所有员工信息
分解为以下两步:
查询 "销售部" 和 "市场部" 的部门ID
select id from dept where name = '销售部' or name = '市场部';
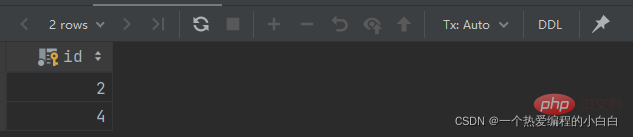
根据部门ID, 查询员工信息
select * from emp where dept_id in (select id from dept where name = '销售部' or name = '市场部');
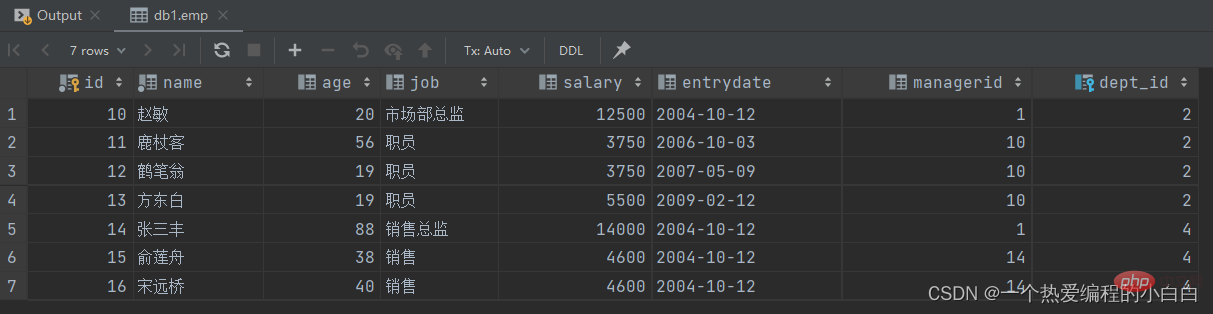
B. 查询比 财务部 所有人工资都高的员工信息
分解为以下两步:
查询所有 财务部 人员工资
select salary from emp where dept_id = (select id from dept where name = '财务部');
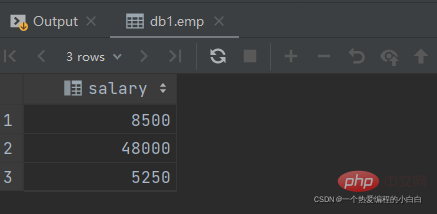
比 财务部 所有人工资都高的员工信息
select * from emp where salary > all (select salary from emp where dept_id = (select id from dept where name = '财务部'));
C. 查询比研发部其中任意一人工资高的员工信息
分解为以下两步:
查询研发部所有人工资
select salary from emp where dept_id = (select id from dept where name = '研发部');
比研部其中任意一人工资高的员工信息
select * from emp where salary > any (select salary from emp where dept_id = (select id from dept where name = '研发部'));
4.行子查询
子查询返回的结果是一行(可以是多列),这种子查询称为行子查询。
常用的操作符:= 、 、IN 、NOT IN
案例:
A. 查询与 "张无忌" 的薪资及直属领导相同的员工信息 ;
这个需求同样可以拆解为两步进行:
查询 "张无忌" 的薪资及直属领导
select salary, managerid from emp where name = '张无忌';
查询与 "张无忌" 的薪资及直属领导相同的员工信息 ;
select * from emp where (salary, managerid) = (select salary, managerid from emp where name = '张无忌');

5.表子查询
子查询返回的结果是多行多列,这种子查询称为表子查询。
常用的操作符:IN
案例:
A. 查询与 "鹿杖客" , "宋远桥" 的职位和薪资相同的员工信息
分解为两步执行:
查询 "鹿杖客" , "宋远桥" 的职位和薪资
select job, salary from emp where name = '鹿杖客' or name = '宋远桥';
查询与 "鹿杖客" , "宋远桥" 的职位和薪资相同的员工信息
select * from emp where (job, salary) in (select job, salary from emp where name = '鹿杖客' or name = '宋远桥');
B. 查询入职日期是 "2006-01-01" 之后的员工信息 , 及其部门信息
分解为两步执行:
入职日期是 "2006-01-01" 之后的员工信息
select * from emp where entrydate > '2006-01-01';
.查询这部分员工, 对应的部门信息;
select e.*, d.* from (select * from emp where entrydate > '2006-01-01') e left join dept d on e.dept_id = d.id;
推荐学习:mysql视频教程
위 내용은 MySQL 제약 조건 및 다중 테이블 쿼리의 기본 사항에 대한 자세한 설명의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7549
7549
 15
1382
52
83
11
58
19
22
90
15
1382
52
83
11
58
19
22
90

 MySQL : 쉽게 학습하기위한 간단한 개념
Apr 10, 2025 am 09:29 AM
MySQL : 쉽게 학습하기위한 간단한 개념
Apr 10, 2025 am 09:29 AM
MySQL은 오픈 소스 관계형 데이터베이스 관리 시스템입니다. 1) 데이터베이스 및 테이블 작성 : CreateAbase 및 CreateTable 명령을 사용하십시오. 2) 기본 작업 : 삽입, 업데이트, 삭제 및 선택. 3) 고급 운영 : 가입, 하위 쿼리 및 거래 처리. 4) 디버깅 기술 : 확인, 데이터 유형 및 권한을 확인하십시오. 5) 최적화 제안 : 인덱스 사용, 선택을 피하고 거래를 사용하십시오.
 phpmyadmin을 여는 방법
Apr 10, 2025 pm 10:51 PM
phpmyadmin을 여는 방법
Apr 10, 2025 pm 10:51 PM
다음 단계를 통해 phpmyadmin을 열 수 있습니다. 1. 웹 사이트 제어판에 로그인; 2. phpmyadmin 아이콘을 찾고 클릭하십시오. 3. MySQL 자격 증명을 입력하십시오. 4. "로그인"을 클릭하십시오.
 MySQL : 세계에서 가장 인기있는 데이터베이스 소개
Apr 12, 2025 am 12:18 AM
MySQL : 세계에서 가장 인기있는 데이터베이스 소개
Apr 12, 2025 am 12:18 AM
MySQL은 오픈 소스 관계형 데이터베이스 관리 시스템으로, 주로 데이터를 신속하고 안정적으로 저장하고 검색하는 데 사용됩니다. 작업 원칙에는 클라이언트 요청, 쿼리 해상도, 쿼리 실행 및 반환 결과가 포함됩니다. 사용의 예로는 테이블 작성, 데이터 삽입 및 쿼리 및 조인 작업과 같은 고급 기능이 포함됩니다. 일반적인 오류에는 SQL 구문, 데이터 유형 및 권한이 포함되며 최적화 제안에는 인덱스 사용, 최적화 된 쿼리 및 테이블 분할이 포함됩니다.
 MySQL을 사용하는 이유는 무엇입니까? 혜택과 장점
Apr 12, 2025 am 12:17 AM
MySQL을 사용하는 이유는 무엇입니까? 혜택과 장점
Apr 12, 2025 am 12:17 AM
MySQL은 성능, 신뢰성, 사용 편의성 및 커뮤니티 지원을 위해 선택됩니다. 1.MYSQL은 효율적인 데이터 저장 및 검색 기능을 제공하여 여러 데이터 유형 및 고급 쿼리 작업을 지원합니다. 2. 고객-서버 아키텍처 및 다중 스토리지 엔진을 채택하여 트랜잭션 및 쿼리 최적화를 지원합니다. 3. 사용하기 쉽고 다양한 운영 체제 및 프로그래밍 언어를 지원합니다. 4. 강력한 지역 사회 지원을 받고 풍부한 자원과 솔루션을 제공합니다.
 단일 스레드 레 디스를 사용하는 방법
Apr 10, 2025 pm 07:12 PM
단일 스레드 레 디스를 사용하는 방법
Apr 10, 2025 pm 07:12 PM
Redis는 단일 스레드 아키텍처를 사용하여 고성능, 단순성 및 일관성을 제공합니다. 동시성을 향상시키기 위해 I/O 멀티플렉싱, 이벤트 루프, 비 블로킹 I/O 및 공유 메모리를 사용하지만 동시성 제한 제한, 단일 고장 지점 및 쓰기 집약적 인 워크로드에 부적합한 제한이 있습니다.
 MySQL 및 SQL : 개발자를위한 필수 기술
Apr 10, 2025 am 09:30 AM
MySQL 및 SQL : 개발자를위한 필수 기술
Apr 10, 2025 am 09:30 AM
MySQL 및 SQL은 개발자에게 필수적인 기술입니다. 1.MySQL은 오픈 소스 관계형 데이터베이스 관리 시스템이며 SQL은 데이터베이스를 관리하고 작동하는 데 사용되는 표준 언어입니다. 2.MYSQL은 효율적인 데이터 저장 및 검색 기능을 통해 여러 스토리지 엔진을 지원하며 SQL은 간단한 문을 통해 복잡한 데이터 작업을 완료합니다. 3. 사용의 예에는 기본 쿼리 및 조건 별 필터링 및 정렬과 같은 고급 쿼리가 포함됩니다. 4. 일반적인 오류에는 구문 오류 및 성능 문제가 포함되며 SQL 문을 확인하고 설명 명령을 사용하여 최적화 할 수 있습니다. 5. 성능 최적화 기술에는 인덱스 사용, 전체 테이블 스캔 피하기, 조인 작업 최적화 및 코드 가독성 향상이 포함됩니다.
 MySQL의 장소 : 데이터베이스 및 프로그래밍
Apr 13, 2025 am 12:18 AM
MySQL의 장소 : 데이터베이스 및 프로그래밍
Apr 13, 2025 am 12:18 AM
데이터베이스 및 프로그래밍에서 MySQL의 위치는 매우 중요합니다. 다양한 응용 프로그램 시나리오에서 널리 사용되는 오픈 소스 관계형 데이터베이스 관리 시스템입니다. 1) MySQL은 웹, 모바일 및 엔터프라이즈 레벨 시스템을 지원하는 효율적인 데이터 저장, 조직 및 검색 기능을 제공합니다. 2) 클라이언트 서버 아키텍처를 사용하고 여러 스토리지 엔진 및 인덱스 최적화를 지원합니다. 3) 기본 사용에는 테이블 작성 및 데이터 삽입이 포함되며 고급 사용에는 다중 테이블 조인 및 복잡한 쿼리가 포함됩니다. 4) SQL 구문 오류 및 성능 문제와 같은 자주 묻는 질문은 설명 명령 및 느린 쿼리 로그를 통해 디버깅 할 수 있습니다. 5) 성능 최적화 방법에는 인덱스의 합리적인 사용, 최적화 된 쿼리 및 캐시 사용이 포함됩니다. 모범 사례에는 거래 사용 및 준비된 체계가 포함됩니다
 SQL이 행을 삭제 한 후 데이터를 복구하는 방법
Apr 09, 2025 pm 12:21 PM
SQL이 행을 삭제 한 후 데이터를 복구하는 방법
Apr 09, 2025 pm 12:21 PM
백업 또는 트랜잭션 롤백 메커니즘이없는 한 데이터베이스에서 직접 삭제 된 행 복구는 일반적으로 불가능합니다. 키 포인트 : 거래 롤백 : 트랜잭션이 데이터를 복구하기 전에 롤백을 실행합니다. 백업 : 데이터베이스의 일반 백업을 사용하여 데이터를 신속하게 복원 할 수 있습니다. 데이터베이스 스냅 샷 : 데이터베이스의 읽기 전용 사본을 작성하고 데이터를 실수로 삭제 한 후 데이터를 복원 할 수 있습니다. 주의해서 삭제 명령문을 사용하십시오. 실수로 데이터를 삭제하지 않도록 조건을주의 깊게 점검하십시오. WHERE 절을 사용하십시오 : 삭제할 데이터를 명시 적으로 지정하십시오. 테스트 환경 사용 : 삭제 작업을 수행하기 전에 테스트하십시오.
