

Python 랜덤 포레스트 모델 예제에 대한 자세한 설명

이 글에서는 앙상블 모델 소개, 랜덤 포레스트 모델의 기본 원리, sklearn을 사용한 랜덤 포레스트 모델 구현 등 랜덤 포레스트 모델과 관련된 문제를 주로 정리한 Python에 대한 관련 지식을 제공합니다. , 함께 살펴 보겠습니다. 모두에게 도움이되기를 바랍니다.

[관련 권장 사항: Python3 동영상 튜토리얼 ]
1 앙상블 모델 소개
앙상블 학습 모델은 일련의 약한 학습자(기본 모델 또는 기본 모델이라고도 함)를 사용하여 각각을 학습하고 결합합니다. 약한 학습자의 결과를 통합하여 단일 학습자보다 더 좋은 학습 결과를 얻을 수 있습니다.
통합 학습 모델의 일반적인 알고리즘에는 Bagged 알고리즘과 Boosting 알고리즘이 있습니다.
Bagged 알고리즘의 일반적인 기계 학습 모델은 Random Forest 모델이고 Boosting 알고리즘의 일반적인 기계 학습 모델은 AdaBoost, GBDT, XGBoost 및 LightGBM 모델입니다.
1.1 배깅 알고리즘 소개
배깅 알고리즘의 원리는 투표와 유사합니다. 각 약한 학습자는 하나의 투표권을 가집니다. 마지막으로 모든 약한 학습자의 투표를 기반으로 "소수자"의 원칙에 따라 최종 예측 결과가 생성됩니다. 아래 그림과 같이 다수에 복종합니다."
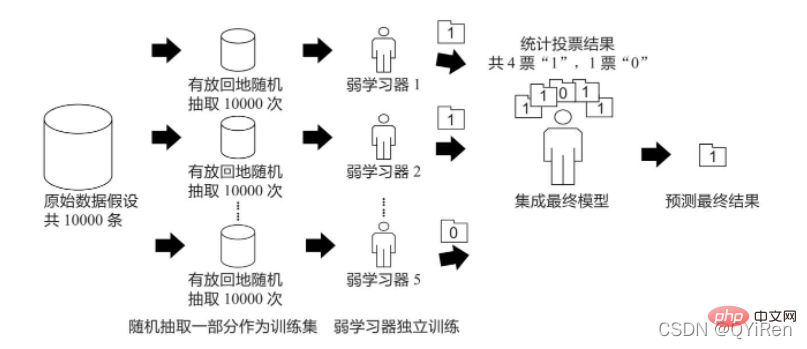
10,000개의 원본 데이터가 있고, 10,000개의 데이터를 무작위로 교체하여 선택하여 새로운 훈련 세트를 구성한다고 가정합니다. (임의로 교체로 샘플링하기 때문에 특정 데이터가 여러 번 선택될 수 있습니다. , 특정 데이터 조각이 한 번 선택되지 않았을 수도 있음) 약한 학습기는 매번 훈련 세트를 사용하여 훈련됩니다. 이러한 방식으로 n번의 교체를 무작위로 샘플링한 후, 훈련이 끝나면 '의 원리에 따라 서로 다른 훈련 세트로 훈련된 n개의 약한 학습자를 얻을 수 있습니다. 소수는 다수에 복종합니다." 를 통해 보다 정확하고 합리적인 최종 예측 결과를 얻을 수 있습니다.
구체적으로 분류 문제에서는 n명의 약한 학습자가 투표를 통해 최종 결과를 얻고, 회귀 문제에서는 n명의 약한 학습자의 평균이 최종 결과로 사용됩니다.
1.2 부스팅 알고리즘 소개
부스팅 알고리즘의 본질은 약한 학습자를 강한 학습자로 승격시키는 것입니다. 배깅 알고리즘의 차이점은 배깅 알고리즘은 약한 학습자를 동등하게 취급한다는 것입니다. 치료'란 평신도의 관점에서 '엘리트 육성'에 집중하고 '실수에 관심을 기울이는 것'을 의미합니다.
"엘리트 육성"은 각 훈련 라운드 후에 더 정확한 예측 결과를 가진 약한 학습자에게 더 큰 가중치를 부여하고, 성과가 좋지 않은 약한 학습자에게는 더 낮은 가중치를 부여하는 것을 의미합니다. 이렇게 최종 예측에서 '우수 모델'은 가중치가 커서 여러 표를 행사할 수 있는 반면, '일반 모델'은 한 표만 행사할 수 있거나 투표를 할 수 없는 것과 같습니다.
"오류에 주의하세요"는 이전 라운드에서 약한 학습자가 잘못 예측한 예제의 가중치를 높이고 가중치를 줄여 매 훈련 라운드 후에 훈련 세트의 가중치 또는 확률 분포를 변경하는 것을 의미합니다. 이전 라운드에서 약한 학습자가 잘못 학습한 예제 중 기계가 예측한 올바른 예제의 가중치를 사용하여 잘못 예측한 데이터에 대한 약한 학습자의 강조를 높여 전반적인 예측 효과를 향상시킵니다. 모델의.
2 랜덤 포레스트 모델의 기본 원리랜덤 포레스트(Random Forest)는 고전적인 배깅 모델이고, 약한 학습자는 의사결정 트리 모델입니다. 아래 그림에 표시된 것처럼 랜덤 포레스트 모델은 원본 데이터 세트에서 무작위로 샘플링하여 n개의 서로 다른 샘플 데이터 세트를 구성한 다음 이러한 데이터 세트를 기반으로 n개의 서로 다른 의사 결정 트리 모델을 구축하고 최종적으로 이들의 평균을 기반으로 합니다. 최종 결과를 얻기 위한 의사결정 트리 모델(회귀 모델의 경우) 또는 투표(분류 모델의 경우).
랜덤 포레스트 모델은 모델의 일반화 능력(또는 보편적 능력)을 보장하기 위해 각 트리를 구축할 때 "랜덤 데이터"와 "랜덤 특징"이라는 두 가지 기본 원칙을 따르는 경우가 많습니다.
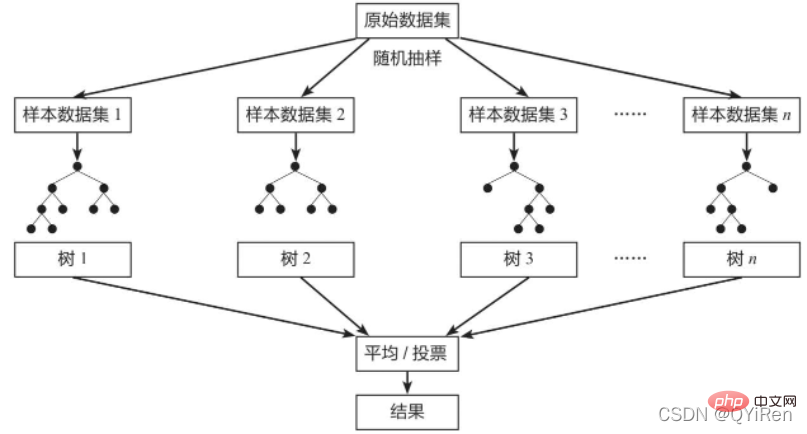
단일 의사결정 트리 모델에 비해 랜덤 포레스트 모델은 여러 의사결정 트리를 통합하므로 예측 결과가 더 정확하고 과적합이 쉽게 발생하지 않으며 일반화 능력이 더 강합니다.Random data: 의사결정 트리 모델 중 하나에 대한 교육 데이터로 모든 데이터에서 대체 데이터를 무작위로 추출합니다. 예를 들어, 특정 의사결정 트리 모델을 훈련하기 위한 새로운 데이터 세트를 형성하기 위해 1,000개의 원본 데이터를 1,000번 교체하여 추출했습니다.
Feature Random: 각 샘플의 특징 차원이 M인 경우 상수 k
3 sklearn을 사용하여 Random Forest 모델 구현
Random Forest 모델은 분류 분석과 회귀 분석을 모두 수행할 수 있습니다. 해당 모델은 다음과 같습니다.
· Random Forest 분류 모델(RandomForestClassifier)
· Random Forest 회귀 모델(RandomForestRegressor)
랜덤 포레스트 분류 모델의 약한 학습자는 분류 결정 트리 모델이고, 랜덤 포레스트 회귀 모델의 약한 학습자는 회귀 결정 트리 모델입니다.
코드는 다음과 같습니다.
from sklearn.ensemble import RandomForestClassifier X = [[1,2],[3,4],[5,6],[7,8],[9,10]] y = [0,0,0,1,1] # 设置弱学习器数量为10 model = RandomForestClassifier(n_estimators=10,random_state=123) model.fit(X,y) model.predict([[5,5]]) # 输出为:array([0])
4 사례: 주식 상승 및 하락 예측 모델
4.1 주식 파생 변수 생성
이 섹션에서는 주식의 기본 데이터를 사용하여 5일 이동 평균 가격 MA5와 같은 일부 파생 변수 데이터를 얻는 방법을 설명합니다. 주식 기술적 분석에서 일반적으로 사용되는 이동 평균 지표인 MA10, 상대 강도 지표 RSI, 모멘텀 지표 MOM, 지수 이동 평균 EMA, 이동 평균 수렴 및 발산 MACD 등.
4.1.1 기본 주식 데이터 가져오기
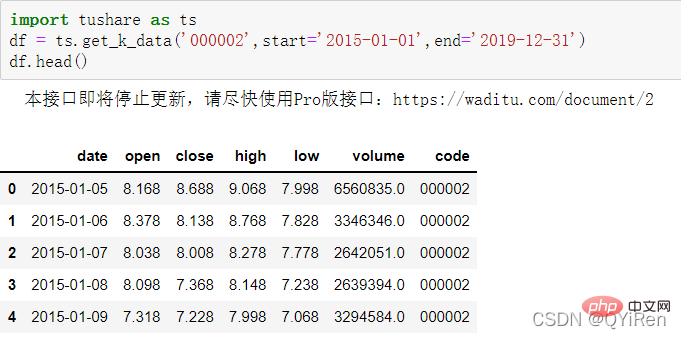
먼저 get_k_data() 함수를 사용하여 2015-01-01부터 2019-12-31까지 기본 주식 데이터를 가져오는 코드는 다음과 같습니다.
아래 그림은 데이터의 처음 5행이 표시되어 있으며 누락된 데이터는 휴일(비거래일) 데이터입니다.
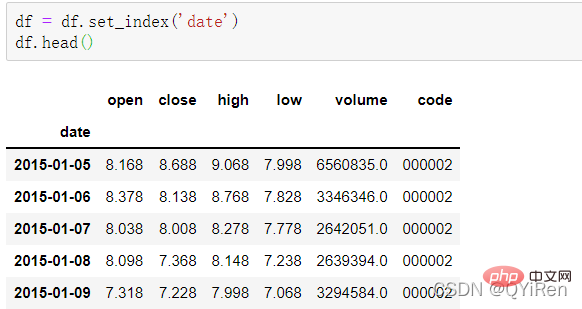
날짜 열을 행 인덱스로 설정하려면 set_index() 함수를 사용하세요. 코드는 다음과 같습니다.
4.1.2 단순 파생 변수 생성
다음 코드를 통해 일부 단순 파생 변수 데이터를 생성할 수 있습니다.
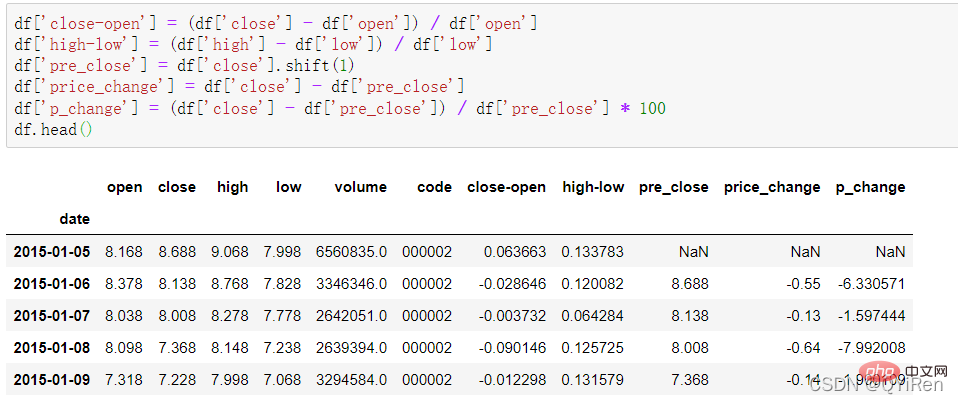
종가는 (종가 - 개장가)/시가를 의미합니다.
고저가는 (최고가 - 최저가)/최저가를 의미합니다.
pre_close는 어제 종가를 의미합니다. (1) 마감 열의 모든 데이터를 한 행 아래로 이동하고 새 열을 만듭니다. 시프트(-1)이면 한 행 위로 이동한다는 의미입니다.
price_change는 오늘 종가, 즉 어제 종가를 의미합니다. 은, 그날 주가 변동입니다.
p_change는 당일 주가의 변동률을 나타내며, 당일 주가의 상승 또는 하락이라고도 합니다.
4.1.3 이동평균 지표 MA 값 생성
주가의 5일 이동평균과 10일 이동평균은 다음 코드를 통해 생성할 수 있습니다.
참고: 롤링 함수 사용
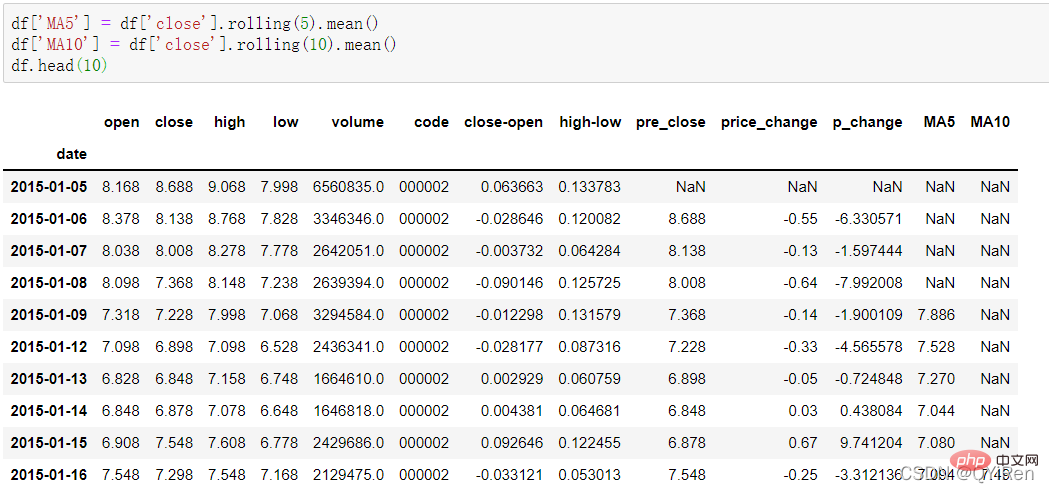
그 중 MA는 이동 평균을 의미하고, "평균"은 지난 n일 종가의 산술 평균을 의미하고, "이동"은 항상 계산 지난 n일간의 가격 데이터를 사용합니다.
예: MA5 계산
위 데이터에 따르면 5번의 MA5 값은 (1.2+1.4+1.6+1.8+2.0)/5=1.6이고, 5번의 MA5 값은 1.6입니다. 6은 (1.4 +1.6+1.8+2.0+2.2)/5=1.8 등입니다. 일정 기간 동안의 주가 이동 평균은 이동 평균인 곡선으로 연결됩니다. 마찬가지로 MA10은 계산일로부터 이전 10일간의 평균 주가입니다.

MA5와 같은 데이터를 계산할 때 처음 4일 동안의 데이터 양이 부족하기 때문에 이 4일에 해당하는 이동 평균을 계산할 수 없으므로 null 값 NaN이 생성됩니다. 일반적으로 후속 계산에서 null 값으로 인해 발생하는 문제를 방지하기 위해 dropna() 함수를 사용하여 null 값을 삭제합니다.
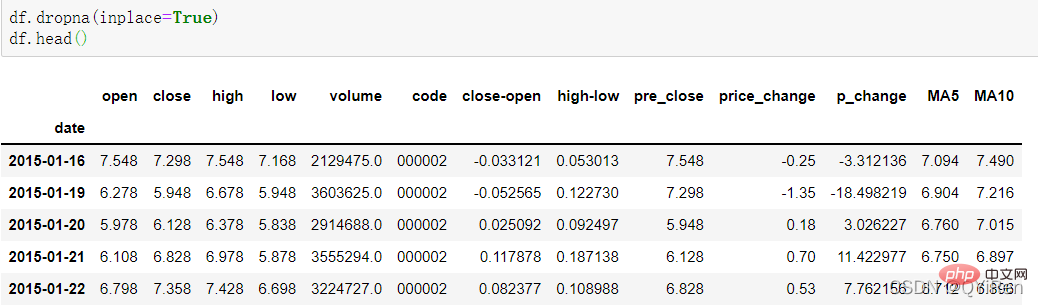
16일 이전의 행이 삭제된 것을 확인할 수 있습니다.
4.1.4 TA-Lib 라이브러리를 사용하여 상대 강도 지수 RSI 값을 생성하세요
상대 강도 지수 RSI 값은 다음 코드를 통해 생성할 수 있습니다.
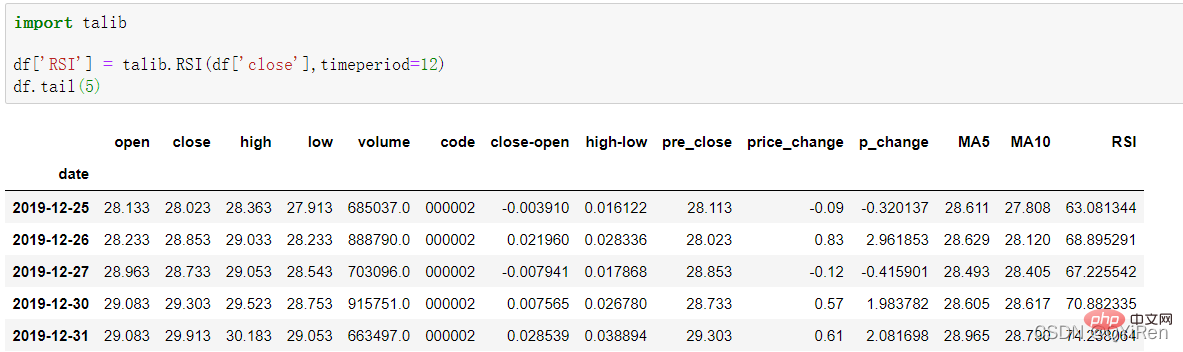
RSI 값은 단기 하락 대비 주가 상승 강도를 반영할 수 있으며 주가의 상승 및 하락 추세를 더 잘 판단하는 데 도움이 됩니다.
RSI 값이 클수록 하락 추세에 비해 상승 추세가 강하고, 반대로 하락 추세에 비해 상승 추세가 약합니다.
RSI 값의 계산식은 다음과 같습니다.

예:
위 표의 데이터에 따라 N=6을 취하면 6일 평균 상승 가격은 (2+2+2)/6=1로 구할 수 있으며, 6일 평균 하락 가격은 (1+1+1)/6=0.5이므로 RSI 값은 (1/(1+0.5))×100=66.7입니다.
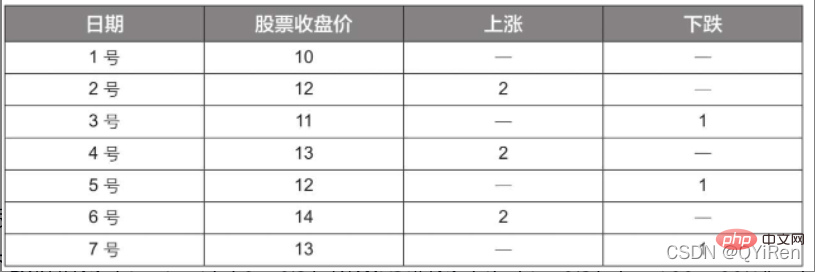
일반적으로 RSI 값은 20~80 사이입니다. 80을 초과하면 과매수, 20 미만이면 50과 같으면 과매도 상태로 간주됩니다. 동일합니다. 예를 들어, 주가가 6일 연속 상승했다면 6일째 평균 하락 가격은 0이 되고, 6일째 RSI 값은 100이 됩니다. 이는 주식 구매자가 현재 매우 강력한 위치에 있음을 나타냅니다. 하지만 이 역시 과도한 기간이 될 수 있다는 점을 투자자들 역시 주의해야 할 점이다. 매수 상태에서는 주가가 하락할 위험을 막아야 한다.
4.1.5 TA-Lib 라이브러리를 사용하여 모멘텀 지표 MOM 값을 생성합니다.
다음 코드를 통해 모멘텀 지표 MOM 값을 생성할 수 있습니다.
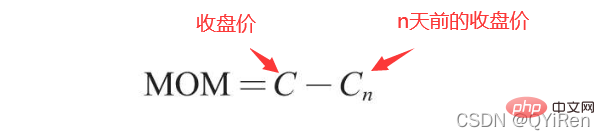
MOM은 모멘텀의 약어로, 일정 기간 동안의 주가 상승 및 하락 속도를 반영합니다.
예:
6번의 MOM 값을 계산하려고 하고 이전 코드에서 매개변수 time period가 5로 설정되어 있는 경우 6번 종가에서 1번 가격, 즉 6번의 MOM 값은 2.2-1.2=1입니다. 마찬가지로 7번의 MOM 값은 2.4-1.4=1입니다. 연속된 일수에 대한 MOM 값을 연결하면 주가의 상승과 하락을 반영하는 곡선이 형성됩니다.

4.1.6 TA-Lib 라이브러리를 사용하여 지수 이동 평균 EMA 생성
다음 코드를 통해 지수 이동 평균 EMA를 생성할 수 있습니다.
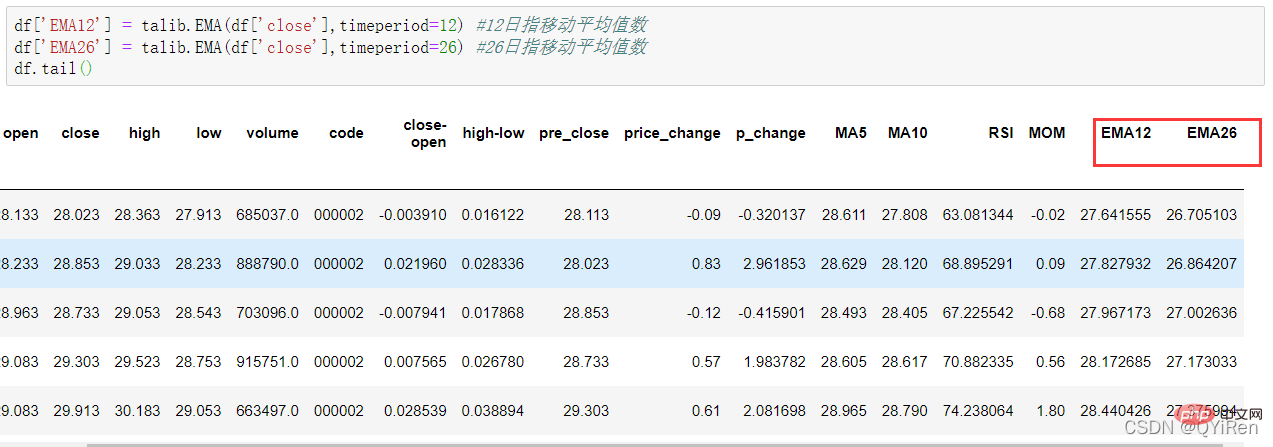
EMA는 지수적으로 감소하는 가중 이동 평균으로, 계산 결과를 바탕으로 분석됩니다. 향후 주가 추세를 판단하는 데 사용됩니다.
EMA의 계산식은 다음과 같습니다.
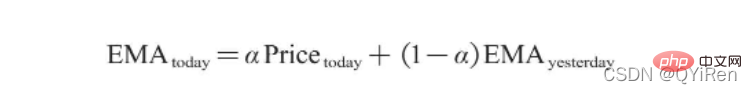
그 중 EMAtoday는 그날의 EMA 값이고, Pricetoday는 그날의 종가이고, EMAyesterday는 어제의 EMA 값이며 일반적으로 값은 2/(N+1)입니다. N은 일수를 나타내며, N이 6일 때 α는 2/7이고 해당 EMA를 EMA6이라 부르는데 이는 6일 지수이동평균이다. 공식은 첫 번째 EMA 값이 나타날 때까지 계속해서 반복됩니다(첫 번째 EMA 값은 일반적으로 처음 5개 숫자의 평균입니다).
예: EMA6
첫 번째 EMA 값은 처음 5개 숫자의 평균이므로 처음 5일 동안의 EMA 값은 없습니다. 6번의 EMA 값은 첫 번째 EMA 값입니다. 는 처음 5일의 평균값이 1이고, 7번의 EMA 값이 두 번째 EMA 값입니다. 계산 과정은 다음과 같습니다.

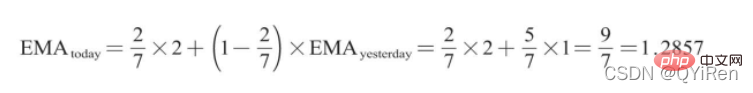
4.1.7 TA-Lib 라이브러리를 사용하여 이동 평균 수렴 및 발산에 대한 MACD 값을 생성합니다.
다음 코드를 통해 이동 평균 수렴 및 발산에 대한 MACD 값을 생성할 수 있습니다.
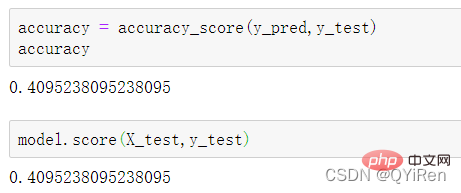
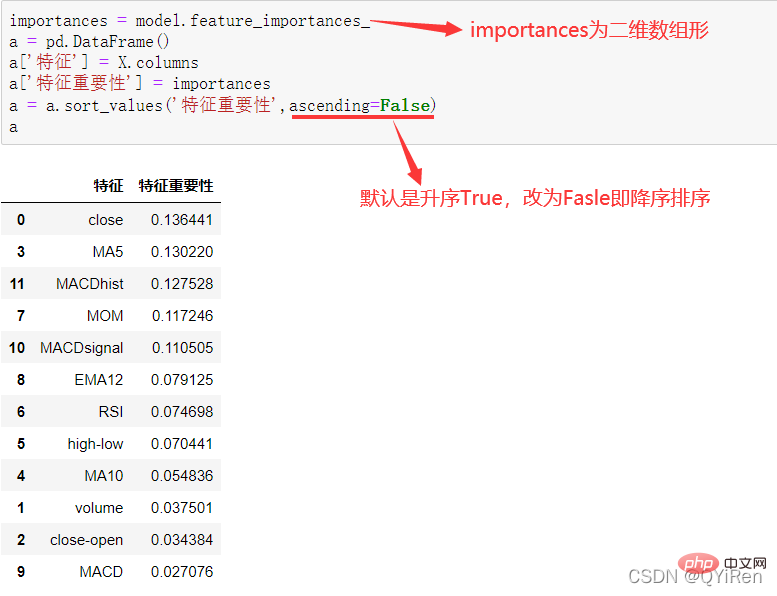
MACD는 주식 시장에서 흔히 사용되는 지표입니다. EMA 값을 기반으로 한 파생 변수입니다. 계산 방법은 관심 있는 독자가 스스로 알아볼 수 있습니다. 여기서 알아야 할 것은 MACD는 추세 지표이고 그 변화는 다양한 K-라인 수준의 MACD가 현재 수준 주기의 매수 및 매도 추세를 나타낸다는 것입니다. 首先强调最核心的一点:应该是用当天的股价数据预测下一天的股价涨跌情况,所以目标变量y应该是下一天的股价涨跌情况。为什么是用当天的股价数据预测下一天的股价涨跌情况呢?这是因为特征变量中的很多数据只有在当天交易结束后才能确定(例如,收盘价close只有收盘了才有),所以当天正在交易时的股价涨跌情况是无法预测的,而等到收盘时尽管所需数据齐备,但是当天的股价涨跌情况已成定局,也就没有必要预测了,所以是用当天的股价数据预测下一天的股价涨跌情况。 第2行代码中使用了NumPy库中的where()函数,传入的3个参数的含义分别为判断条件、满足条件的赋值、不满足条件的赋值。其中df['price_change'].shift(-1)是利用shift()函数将price_change(股价变化)这一列的所有数据向上移动1行,这样就获得了每一行对应的下一天的股价变化。因此,这里的判断条件就是下一天的股价变化是否大于0,如果大于0,说明下一天股价涨了,则y赋值为1;如果不大于0,说明下一天股价不变或跌了,则y赋值为-1。预测结果就只有1或-1两种分类。 这里需要注意的是,划分要按照时间序列进行,而不能用train_test_split()函数进行随机划分。这是因为股价的变化趋势具有时间性特征,而随机划分会破坏这种特征,所以需要根据当天的股价数据预测下一天的股价涨跌情况,而不能根据任意一天的股价数据预测下一天的股价涨跌情况。 将前90%的数据作为训练集,后10%的数据作为测试集,代码如下。 设置模型参数:决策树的最大深度max_depth设置为3,即每个决策树最多只有3层;弱学习器(即决策树模型)的个数n_estimators设置为10,即该随机森林中共有10个决策树;叶子节点的最小样本数min_samples_leaf设置为10,即如果叶子节点的样本数小于10则停止分裂;随机状态参数random_state的作用是使每次运行结果保持一致,这里设置的数字123没有特殊含义,可以换成其他数字。 用predict_proba()函数可以预测属于各个分类的概率,代码如下。 通过如下代码可以查看整体的预测准确度。 打印输出score为0.40,说明模型对整个测试集中约40%的数据预测正确。这一预测准确度并不算高,也的确符合股票市场千变万化的特点。 通过如下代码可以分析各个特征变量的特征重要性。 由图可知,当日收盘价close、MA5、MACDhist相关指标等特征变量对下一天股价涨跌结果的预测准确度影响较大。 前面已经评估了模型的预测准确度,不过在商业实战中,更关心它的收益回测曲线(又称为净值曲线),也就是看根据搭建的模型获得的结果是否比不利用模型获得的结果更好。 可视化结果如下图所示。图中上方的曲线为根据模型得到的收益率曲线,下方的曲线为股票本身的收益率曲线,可以看到,利用模型得到的收益还是不错的。 要说明的是,这里讲解的量化金融内容比较浅显,搭建的模型过于理想化,真正的股市是错综复杂的,股票交易也有很多限制,如不能做空、不能T+0交易,还要考虑手续费等因素。 随机森林模型是一种非常重要的集成模型,它集成了决策树模型的众多优点,又规避了决策树模型容易过度拟合等缺点,在实战中应用较为广泛。 【相关推荐:Python3视频教程 】4.2 模型搭建
4.2.1 引入需要搭建的库
# 导入相关库
import tushare as ts
import numpy as np
import pandas as pd
import talib
import matplotlib.pyplot as plt
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
4.2.2 获取数据
# 1.股票基本数据获取
import tushare as ts
df = ts.get_k_data('000002',start='2015-01-01',end='2019-12-31')
df = df.set_index('date')
# 2.简单衍生变量数据构造
df['close-open'] = (df['close'] - df['open']) / df['open']
df['high-low'] = (df['high'] - df['low']) / df['low']
df['pre_close'] = df['close'].shift(1)
df['price_change'] = df['close'] - df['pre_close']
df['p_change'] = (df['close'] - df['pre_close']) / df['pre_close'] * 100
# 3.移动平均线相关数据构造
df['MA5'] = df['close'].rolling(5).mean()
df['MA10'] = df['close'].rolling(10).mean()
df.dropna(inplace=True)
# 4.通过TA-Lib库构造衍生变量数据
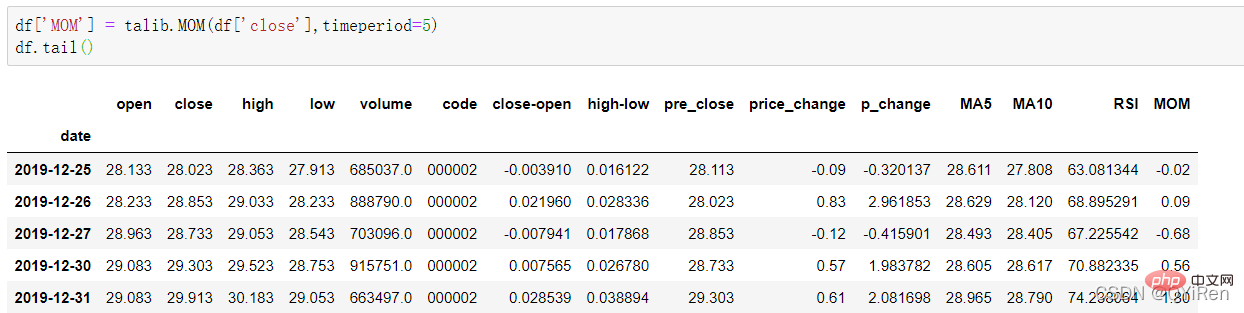
df['RSI'] = talib.RSI(df['close'],timeperiod=12)
df['MOM'] = talib.MOM(df['close'],timeperiod=5)
df['EMA12'] = talib.EMA(df['close'],timeperiod=12) #12日指移动平均值数
df['EMA26'] = talib.EMA(df['close'],timeperiod=26) #26日指移动平均值数
df['MACD'],df['MACDsignal'],df['MACDhist'] = talib.MACD(df['close'],fastperiod=6,slowperiod=12,signalperiod=9)
df.dropna(inplace=True)4.2.3 提取特征变量和目标变量
X = df[['close','volume','close-open','MA5','MA10','high-low','RSI','MOM','EMA12','MACD','MACDsignal','MACDhist']]
y = np.where(df['price_change'].shift(-1) > 0,1,-1)
4.2.4 划分训练集和测试集
X_length = X.shape[0]
split = int(X_length * 0.9)
X_train,X_test = X[:split],X[split:]
y_train,y_test = y[:split],y[split:]
4.2.5 模型搭建
model = RandomForestClassifier(max_depth=3,n_estimators=10,min_samples_leaf=10,random_state=123)
model.fit(X_train,y_train)
4.3 模型评估与使用
4.3.1 预测下一天的股价涨跌情况
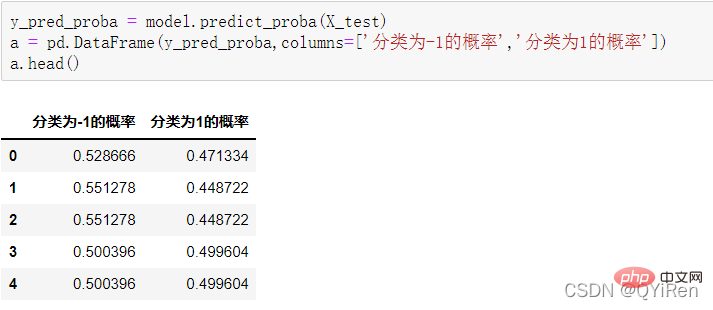
4.3.2 模型准确度评估
4.3.3 分析特征变量的特征重要性
4.4 参数调优
from sklearn.model_selection import GridSearchCV
parameters={'n_estimators':[5,10,20],'max_depth':[2,3,4,5,6],'min_samples_leaf':[5,10,20,30]}
new_model = RandomForestClassifier(random_state=123)
grid_search = GridSearchCV(new_model,parameters,cv=6,scoring='accuracy')
grid_search.fit(X_train,y_train)
grid_search.best_params_
# 输出
# {'max_depth': 5, 'min_samples_leaf': 20, 'n_estimators': 5} 4.5 收益回测曲线绘制
# 在测试数据上添加一列,预测收益
X_test['prediction'] = model.predict(X_test)
# 计算每天的股价变化率
X_test['p_change'] = (X_test['close'] - X_test['close'].shift(1)) / X_test['close'].shift(1)
# 计算累积收益率
# 例如,初始股价是1,2天内的价格变化率为10%
# 那么用cumprod()函数可以求得2天后的股价为1×(1+10%)×(1+10%)=1.21
# 此结果也表明2天的收益率为21%。
X_test['origin'] = (X_test['p_change'] + 1).cumprod()
# 计算利用模型预测后的收益率
X_test['strategy'] = (X_test['prediction'].shift(1) * X_test['p_change'] + 1).cumprod()
X_test[['strategy','origin']].dropna().plot()
# 设置自动倾斜
plt.gcf().autofmt_xdate()
plt.show()
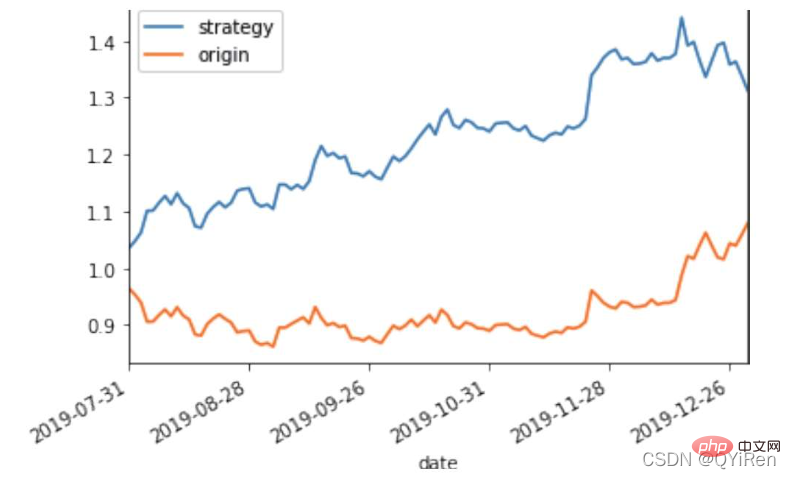
위 내용은 Python 랜덤 포레스트 모델 예제에 대한 자세한 설명의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7569
7569
 15
1386
52
87
11
62
19
28
108
15
1386
52
87
11
62
19
28
108

 Python vs. JavaScript : 커뮤니티, 라이브러리 및 리소스
Apr 15, 2025 am 12:16 AM
Python vs. JavaScript : 커뮤니티, 라이브러리 및 리소스
Apr 15, 2025 am 12:16 AM
Python과 JavaScript는 커뮤니티, 라이브러리 및 리소스 측면에서 고유 한 장점과 단점이 있습니다. 1) Python 커뮤니티는 친절하고 초보자에게 적합하지만 프론트 엔드 개발 리소스는 JavaScript만큼 풍부하지 않습니다. 2) Python은 데이터 과학 및 기계 학습 라이브러리에서 강력하며 JavaScript는 프론트 엔드 개발 라이브러리 및 프레임 워크에서 더 좋습니다. 3) 둘 다 풍부한 학습 리소스를 가지고 있지만 Python은 공식 문서로 시작하는 데 적합하지만 JavaScript는 MDNWebDocs에서 더 좋습니다. 선택은 프로젝트 요구와 개인적인 이익을 기반으로해야합니다.
 터미널 VSCODE에서 프로그램을 실행하는 방법
Apr 15, 2025 pm 06:42 PM
터미널 VSCODE에서 프로그램을 실행하는 방법
Apr 15, 2025 pm 06:42 PM
vs 코드에서는 다음 단계를 통해 터미널에서 프로그램을 실행할 수 있습니다. 코드를 준비하고 통합 터미널을 열어 코드 디렉토리가 터미널 작업 디렉토리와 일치하는지 확인하십시오. 프로그래밍 언어 (예 : Python의 Python Your_file_name.py)에 따라 실행 명령을 선택하여 성공적으로 실행되는지 여부를 확인하고 오류를 해결하십시오. 디버거를 사용하여 디버깅 효율을 향상시킵니다.
 Python에서 비주얼 스튜디오 코드를 사용할 수 있습니다
Apr 15, 2025 pm 08:18 PM
Python에서 비주얼 스튜디오 코드를 사용할 수 있습니다
Apr 15, 2025 pm 08:18 PM
VS 코드는 파이썬을 작성하는 데 사용될 수 있으며 파이썬 애플리케이션을 개발하기에 이상적인 도구가되는 많은 기능을 제공합니다. 사용자는 다음을 수행 할 수 있습니다. Python 확장 기능을 설치하여 코드 완료, 구문 강조 및 디버깅과 같은 기능을 얻습니다. 디버거를 사용하여 코드를 단계별로 추적하고 오류를 찾아 수정하십시오. 버전 제어를 위해 git을 통합합니다. 코드 서식 도구를 사용하여 코드 일관성을 유지하십시오. 라인 도구를 사용하여 잠재적 인 문제를 미리 발견하십시오.
 VScode 확장자가 악의적입니까?
Apr 15, 2025 pm 07:57 PM
VScode 확장자가 악의적입니까?
Apr 15, 2025 pm 07:57 PM
VS 코드 확장은 악의적 인 코드 숨기기, 취약성 악용 및 합법적 인 확장으로 자위하는 등 악성 위험을 초래합니다. 악의적 인 확장을 식별하는 방법에는 게시자 확인, 주석 읽기, 코드 확인 및주의해서 설치가 포함됩니다. 보안 조치에는 보안 인식, 좋은 습관, 정기적 인 업데이트 및 바이러스 백신 소프트웨어도 포함됩니다.
 Windows 8에서 코드를 실행할 수 있습니다
Apr 15, 2025 pm 07:24 PM
Windows 8에서 코드를 실행할 수 있습니다
Apr 15, 2025 pm 07:24 PM
VS 코드는 Windows 8에서 실행될 수 있지만 경험은 크지 않을 수 있습니다. 먼저 시스템이 최신 패치로 업데이트되었는지 확인한 다음 시스템 아키텍처와 일치하는 VS 코드 설치 패키지를 다운로드하여 프롬프트대로 설치하십시오. 설치 후 일부 확장은 Windows 8과 호환되지 않을 수 있으며 대체 확장을 찾거나 가상 시스템에서 새로운 Windows 시스템을 사용해야합니다. 필요한 연장을 설치하여 제대로 작동하는지 확인하십시오. Windows 8에서는 VS 코드가 가능하지만 더 나은 개발 경험과 보안을 위해 새로운 Windows 시스템으로 업그레이드하는 것이 좋습니다.
 파이썬 : 자동화, 스크립팅 및 작업 관리
Apr 16, 2025 am 12:14 AM
파이썬 : 자동화, 스크립팅 및 작업 관리
Apr 16, 2025 am 12:14 AM
파이썬은 자동화, 스크립팅 및 작업 관리가 탁월합니다. 1) 자동화 : 파일 백업은 OS 및 Shutil과 같은 표준 라이브러리를 통해 실현됩니다. 2) 스크립트 쓰기 : PSUTIL 라이브러리를 사용하여 시스템 리소스를 모니터링합니다. 3) 작업 관리 : 일정 라이브러리를 사용하여 작업을 예약하십시오. Python의 사용 편의성과 풍부한 라이브러리 지원으로 인해 이러한 영역에서 선호하는 도구가됩니다.
 VScode 란 무엇입니까?
Apr 15, 2025 pm 06:45 PM
VScode 란 무엇입니까?
Apr 15, 2025 pm 06:45 PM
VS Code는 Full Name Visual Studio Code로, Microsoft가 개발 한 무료 및 오픈 소스 크로스 플랫폼 코드 편집기 및 개발 환경입니다. 광범위한 프로그래밍 언어를 지원하고 구문 강조 표시, 코드 자동 완료, 코드 스 니펫 및 스마트 프롬프트를 제공하여 개발 효율성을 향상시킵니다. 풍부한 확장 생태계를 통해 사용자는 디버거, 코드 서식 도구 및 GIT 통합과 같은 특정 요구 및 언어에 확장을 추가 할 수 있습니다. VS 코드에는 코드에서 버그를 신속하게 찾아서 해결하는 데 도움이되는 직관적 인 디버거도 포함되어 있습니다.
 코드를 실행할 수 있습니다
Apr 15, 2025 pm 08:21 PM
코드를 실행할 수 있습니다
Apr 15, 2025 pm 08:21 PM
예, 대 코드는 Python 코드를 실행할 수 있습니다. 대 코드에서 Python을 효율적으로 실행하려면 다음 단계를 완료하십시오. Python 통역사를 설치하고 환경 변수를 구성하십시오. 대 코드에 파이썬 확장을 설치하십시오. 명령 줄을 통해 대 코드 터미널에서 파이썬 코드를 실행하십시오. VS Code의 디버깅 기능 및 코드 서식을 사용하여 개발 효율성을 향상시킵니다. 좋은 프로그래밍 습관을 채택하고 성능 분석 도구를 사용하여 코드 성능을 최적화하십시오.
