이 기사에서는 Redis에 대한 관련 지식을 제공합니다. 주로 클러스터링 및 확장과 관련된 문제를 정리합니다. 고가용성을 달성하는 일반적인 방법은 데이터베이스의 여러 복사본을 복사하여 다른 서버에 배포하는 것입니다. 고가용성을 달성하기 위해 마스터-슬레이브 모드, 센티넬 모드, 클러스터 모드의 세 가지 배포 모드가 모두에게 도움이 되기를 바랍니다.

추천 학습: Redis 비디오 튜토리얼
Redis의 고가용성
1. 고가용성이 필요한 이유
- 단일 장애 지점을 방지하고 전체 클러스터를 사용할 수 없도록 하기 위함
- 고가용성을 달성하는 일반적인 방법은 배포할 데이터베이스의 복사본을 여러 개 복사하는 것입니다. 하나의 머신이 다운되더라도 계속 서비스를 제공할 수 있습니다.
- Redis에는 고가용성을 달성하기 위한 세 가지 배포 모드가 있습니다: 마스터-슬레이브 모드, 센티넬 모드, 클러스터 모드
2. 마스터- 슬레이브 모드
-
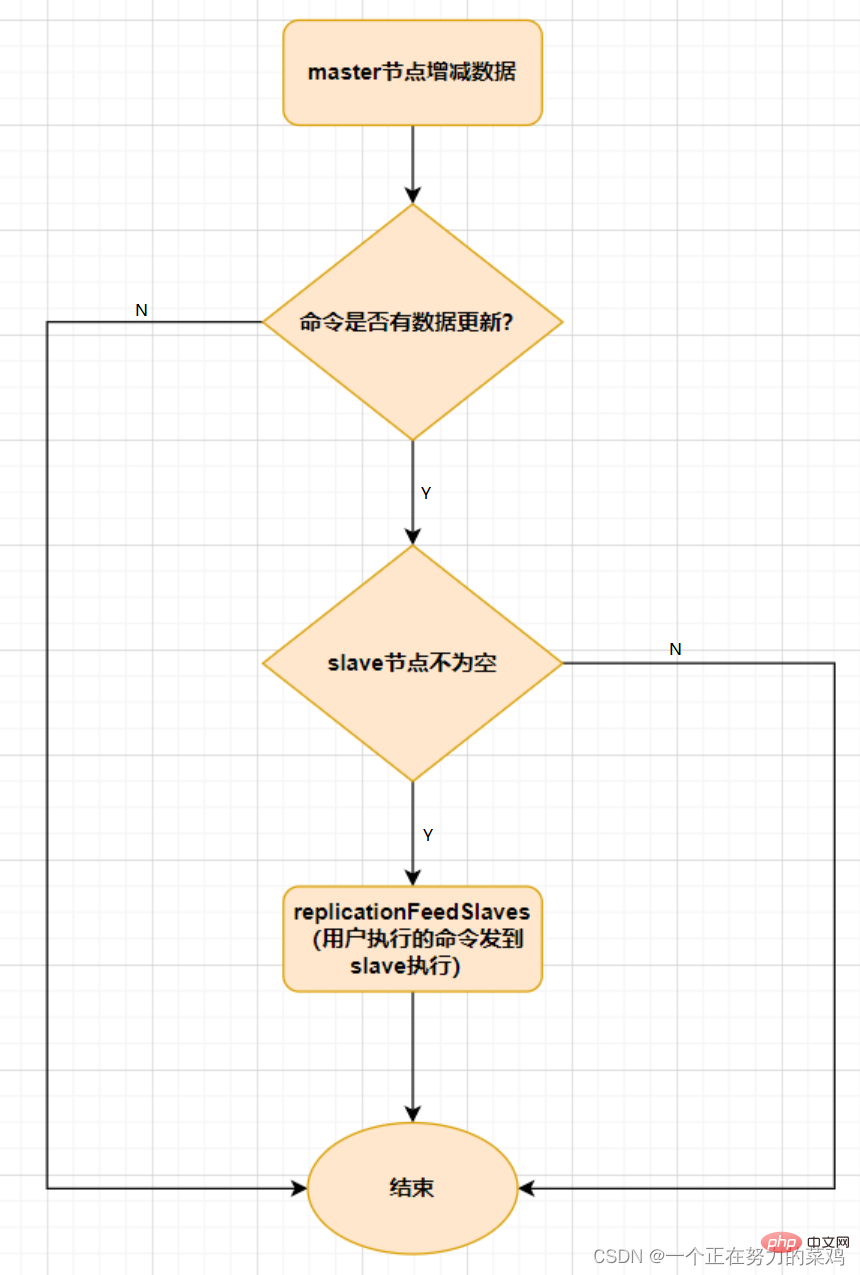
마스터 노드는 읽기 및 쓰기작업
-
슬레이브 노드는읽기작업
-
만 담당합니다. 슬레이브 노드의 데이터는 마스터 노드에서 옵니다. 구현 원칙은 마스터-슬레이브 복제 메커니즘
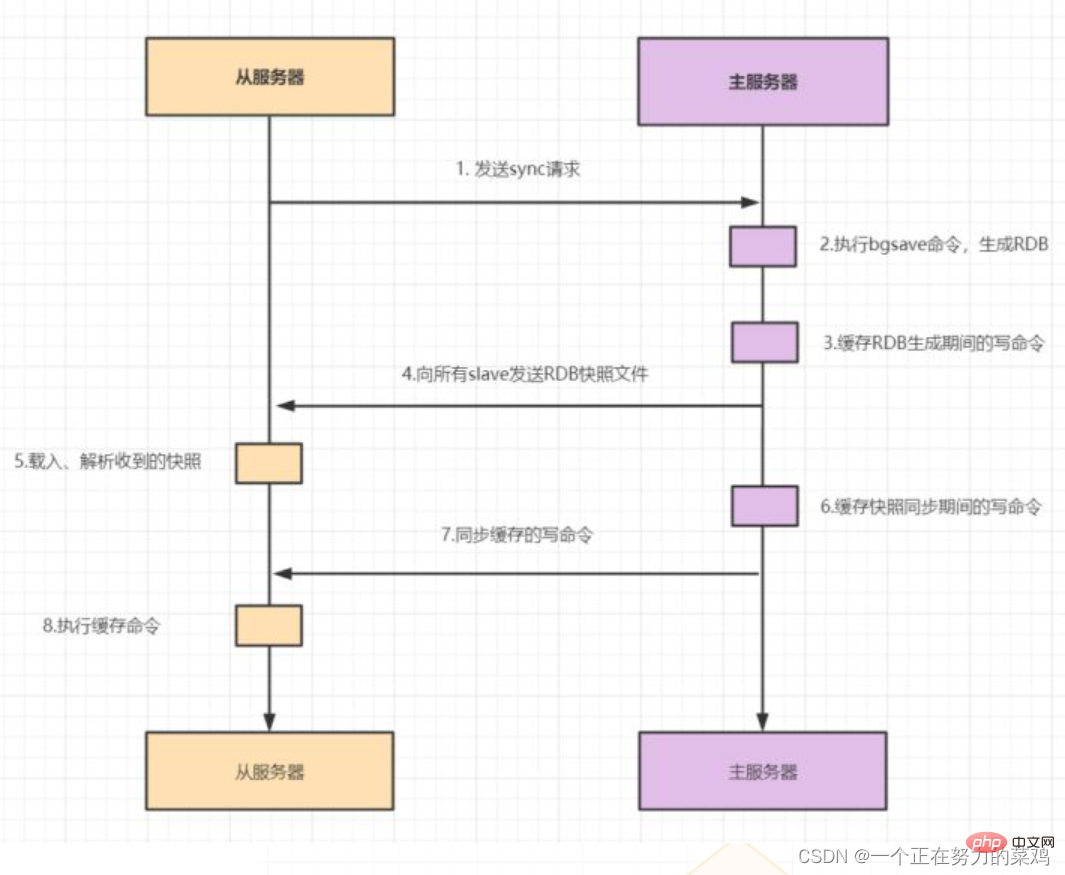
- 마스터-슬레이브 복제에는 전체 복제와 증분 복제두 가지가 포함됩니다. 이런
-
슬레이브가 처음으로 마스터에 연결을 시작하거나, 첫 번째 연결로 간주되어 전체 복제를 사용합니다
-
슬레이브가 마스터와 완전히 동기화된 후 마스터의 데이터가 다시 업데이트되면 볼륨 복제가 증가합니다
.
3. 센티넬 모드
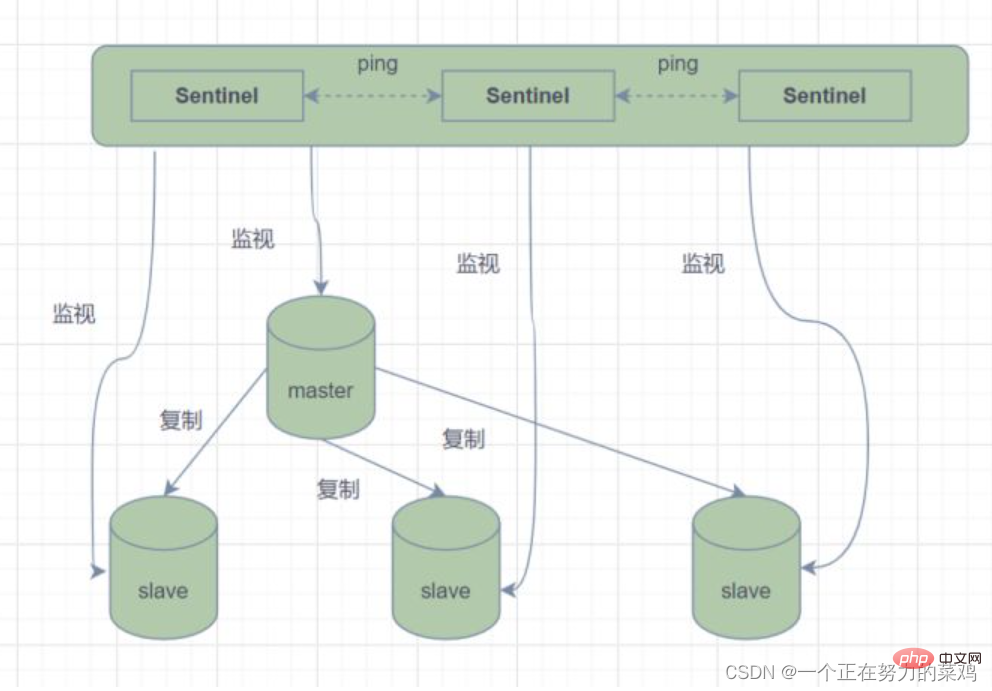
- 마스터-슬레이브 모드에서는 마스터 노드가 장애로 인해 서비스를 제공할 수 없게 되면 슬레이브 노드를 마스터 노드로 수동 승격시켜야 하며 동시에 애플리케이션 측에서도 마스터 노드 주소를 업데이트하려면 알림을 받아야 합니다. 당연히 대부분의 비즈니스 시나리오에서는 이러한 오류 처리 방법을 사용할 수 없습니다. Redis는 이 문제를 해결하기 위해 2.8부터 공식적으로 Redis Sentinel(Sentinel) 아키텍처를 제공합니다. 또는 더 많은 Sentinel 인스턴스를 모니터링할 수 있으며, 모니터링되는
마스터 노드가 오프라인 상태가 되면 오프라인 마스터 서버 아래의 슬레이브 노드가 자동으로 새로운 마스터 노드로 업그레이드됩니다 -
하지만 Sentinel 프로세스 Redis 노드를 모니터링할 때 문제(단일 지점)가 발생할 수 있으므로 여러 Sentinel을 사용하여 Redis 노드를 모니터링할 수 있으며, 각 Sentinel도 간단히 모니터링합니다.
1.发送命令,等待Redis服务器(包括主服务器和从服务器)返回监控其运行状态
2.哨兵监测到主节点宕机会自动将从节点切换成主节点,然后通过发布订阅模式通知其他的从节点修改配置文件,让它们切换主机
3.哨兵之间还会相互监控,从而达到高可用
로그인 후 복사
- 장애 조치 프로세스는 다음과 같습니다
假设主服务器宕机,哨兵1先检测到这个结果,系统并不会马上进行 failover 过程,仅仅是哨兵1主观的认为主服务器不可用,这个现象称为主观下线
当后面的哨兵也检测到主服务器不可用并且数量达到一定值时,那么哨兵之间就会进行一次投票,投票的结果由一个哨兵发起,进行failover操作
切换成功后通过发布订阅模式,让各个哨兵把自己监控的从服务器实现切换主机,这个过程称为客观下线
这样对于客户端而言,一切都是透明的
로그인 후 복사
- Sentinel의 작업 모드
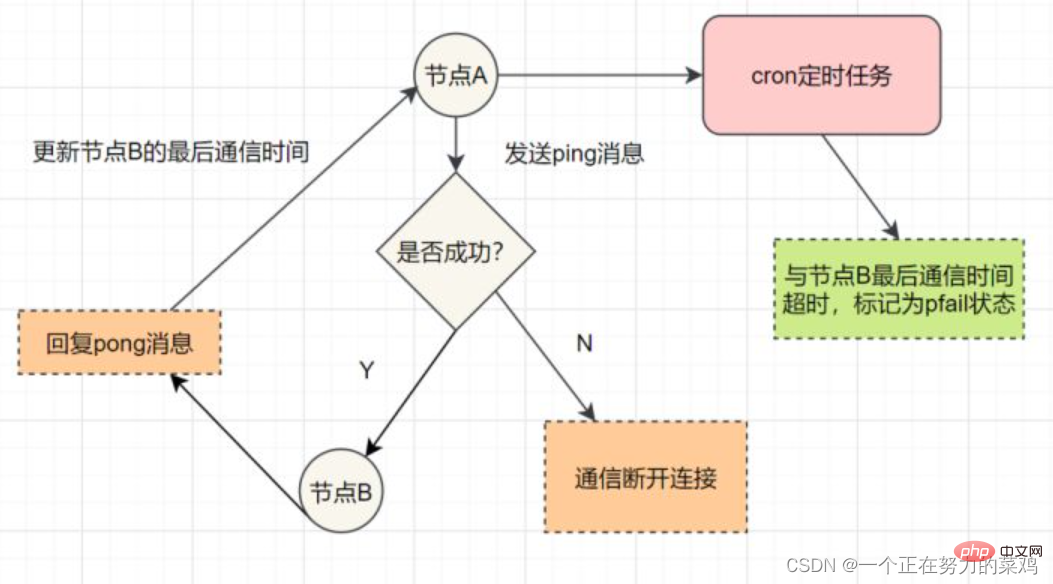
每个Sentinel以每秒钟一次的频率向它所知的Master,Slave以及其他Sentinel实例发送一个PING命令
如果实例距离最后一次有效回复PING命令的时间超过down-after-milliseconds选项所指定的值,则这个实例会被Sentinel标记为主观下线
如果一个Master被标记为主观下线,则正在监视这个Master的所有Sentinel要以每秒一次的频率确认Master的确进入了主观下线状态
当有足够数量的Sentinel(大于等于配置文件指定的值)在指定的时间范围内确认Master的确进入了主观下线状态,则Master会被标记为客观下线
一般情况下,每个Sentinel会以每10秒一次的频率向它已知的所有Master,Slave发送INFO命令
当Master被Sentinel标记为客观下线时,Sentinel向下线的Master的所有Slave发送INFO命令的频率会从10秒一次改为每秒一次
若没有足够数量的Sentinel同意Master已经下线,Master的客观下线状态就会被移除;若Master重新向Sentinel的PING命令返回有效回复,Master 的主观下线状态就会被移除
로그인 후 복사
Sentinel 모드는 마스터-슬레이브 모드를 기반으로 하며 읽기 및 쓰기 분리를 달성하며 또한 자동으로 전환되어 시스템의 가용성이 높아지지만 각 노드에 저장된 데이터가 동일하여 메모리가 낭비되고 온라인 확장이 쉽지 않습니다. 그래서 추가된
- 클러스터 클러스터
가 탄생했습니다. Redis3.0은 Redis
의 분산 스토리지를 구현합니다. 즉, 각 Redis 노드에 서로 다른 콘텐츠를 저장하여 온라인 확장 문제를 해결할 수 있으며 프로토콜 통신
도 제공합니다. , 노드는 지속적으로 정보를 교환합니다.
노드 실패, 신규 노드 가입, 마스터-슬레이브 노드 변경 정보, 슬롯 정보 등이 있습니다.
일반적으로 사용되는 가십 메시지는 핑, 퐁, 미팅, 실패-
ping消息:集群内交换最频繁的消息,集群内每个节点每秒向多个其他节点发送ping消息,用于检测节点是否在线和交换彼此状态信息
meet消息:通知新节点加入,消息发送者通知接收者加入到当前集群,meet消息通信正常完成后,接收节点会加入到集群中并进行周期性的ping、pong消息交换
pong消息:当接收到ping、meet消息时,作为响应消息回复给发送方确认消息正常通信;pong消息内部封装了自身状态数据,节点也可以向集群内广播自身的pong消息来通知整个集群对自身状态进行更新
fail消息:当节点判定集群内另一个节点下线时,会向集群内广播一个fail消息,其他节点接收到fail消息之后把对应节点更新为下线状态
로그인 후 복사
既然是分布式存储,Cluster集群使用的分布式算法是一致性Hash嘛?并不是,而是Hash Slot插槽算法
插槽算法把整个数据库被分为16384个slot(槽),每个进入Redis的键值对根据key进行散列,分配到这16384插槽中的一个
使用的哈希映射也比较简单,用CRC16算法计算出一个16位的值,再对16384取模,数据库中的每个键都属于这16384个槽的其中一个,集群中的每个节点都可以处理这16384个槽
集群中的每个节点负责一部分的hash槽,比如当前集群有A、B、C个节点,每个节点上的哈希槽数 =16384/3,那么就有:
节点A负责0~5460号哈希槽
节点B负责5461~10922号哈希槽
节点C负责10923~16383号哈希槽Redis Cluster集群中,需要确保16384个槽对应的node都正常工作,如果某个node出现故障,它负责的slot也会失效,整个集群将不能工作
为了保证高可用,Cluster集群引入了主从复制,一个主节点对应一个或者多个从节点,当其它主节点ping一个主节点A时,如果半数以上的主节点与 A通信超时,那么认为主节点A宕机,如果主节点宕机时,就会启用从节点Redis的每一个节点上都有两个玩意,一个是插槽slot(0~16383),另外一个是cluster,可以理解为一个集群管理的插件,当我们存取的key到达时,Redis会根据Hash Slot插槽算法取到编号在0~16383之间的哈希槽,通过这个值去找到对应的插槽所对应的节点,然后直接自动跳转到这个对应的节点上进行存取操作
로그인 후 복사
: 노드가 다른 노드를 사용할 수 없다고 생각하는 상태, 즉 오프라인 상태는 최종 장애 판단이 아닙니다.
목표 오프라인: 클러스터의 여러 노드가 해당 노드를 사용할 수 없는 것으로 간주하여 합의 결과에 도달합니다. 슬롯을 보유하고 있는 마스터 노드에 장애가 발생하면 해당 노드에 대해 장애 조치를 수행해야 합니다
실패 복구
: 장애가 발견된 후 오프라인 노드가 마스터 노드인 경우 노드 중 하나를 선택해야 합니다. 클러스터의 고가용성을 보장하기 위해 교체
-
Redis 분산 잠금으로 인해 발생하는 일련의 문제와 솔루션
1. Redisson
-
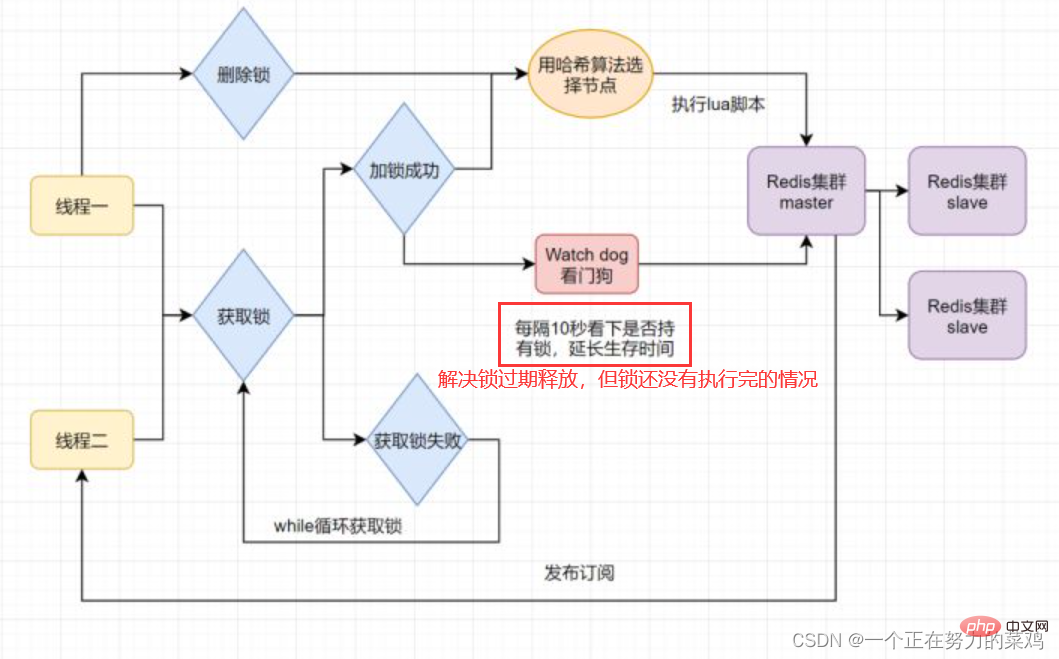
분산 잠금이 존재할 수 있습니다 잠금이 만료되고 해제되어 비즈니스가 중단됩니다. 더 이상 사용할 수 없습니다. 실행 후 질문
이 문제를 해결하려면 잠금 만료 시간을 더 길게 설정할 수 있나요? 분명히 좋지 않습니다. 비즈니스 실행 시간이 불확실합니다-
Redisson은 잠금을 획득한 스레드에 대해 시간 제한이 있는 데몬 스레드를 열어서 잠금이 존재하는지 여부를 가끔씩 확인합니다. 잠금 만료 및 조기 해제를 방지하기 위해 잠금 만료 시간을 연장합니다
2. Redlock 알고리즘
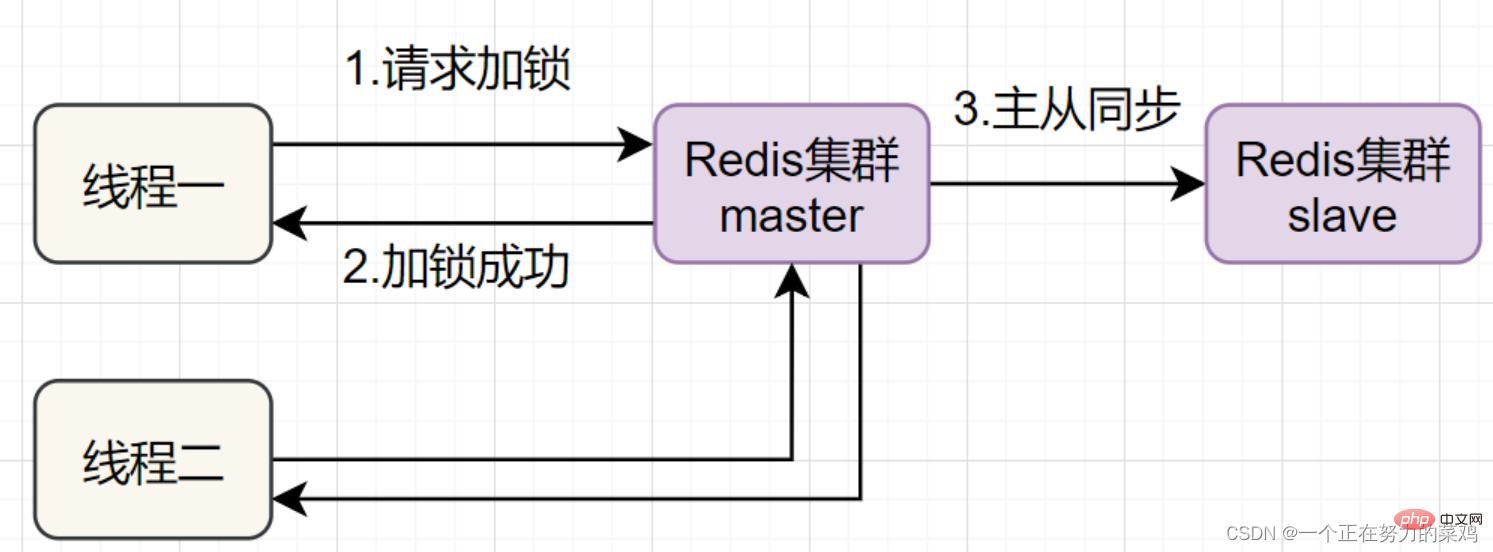
- 스레드가 Redis 마스터 노드에 대한 잠금을 얻었지만 잠긴 키가 슬레이브 노드에 동기화되지 않은 순간, 바로 이때 마스터 노드가 실패하고 슬레이브가 마스터 노드에서는 스레드 2가 동일한 키의 잠금을 얻을 수 있지만 스레드 1도 잠금을 획득했으며 잠금의 보안이 사라졌습니다
-
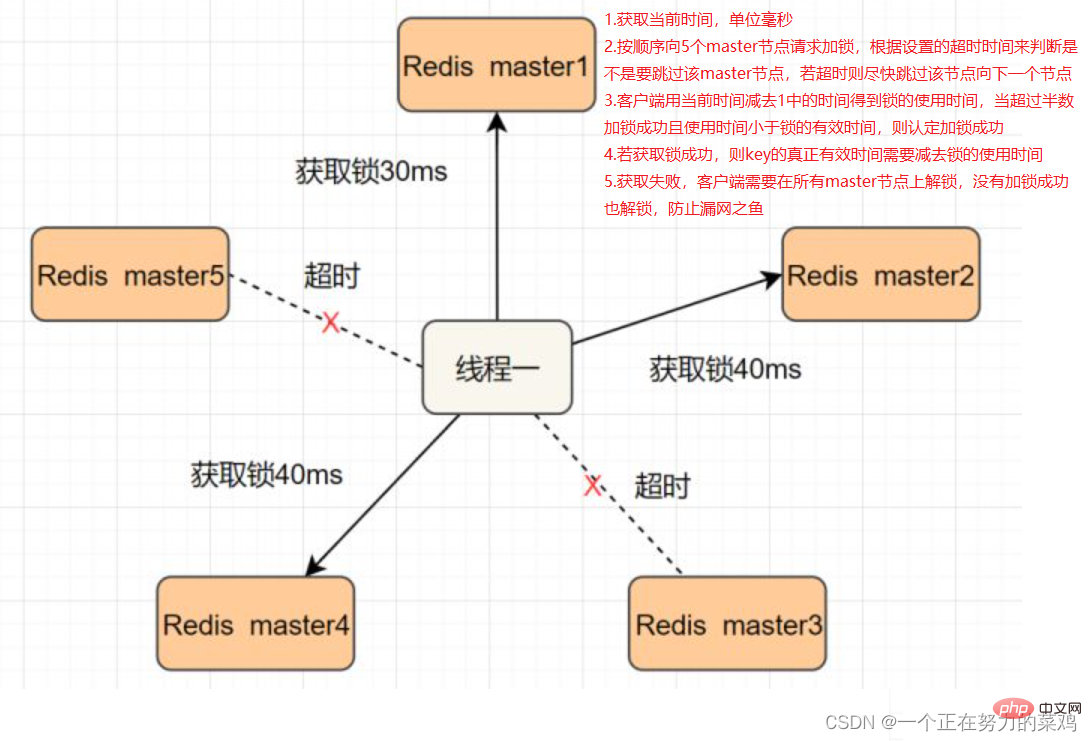
Redlock이 문제를 해결하려면, 동시에 다운되지 않도록 여러 Redis 마스터를 배포합니다. 이러한 마스터 노드는 서로 완전히 독립적이고, 서로 데이터 동기화가 없습니다. 구현 단계는 다음과 같습니다
.
MySQL과 Redis가 이중 쓰기 일관성을 보장하는 방법
1 .지연된 이중 삭제
데이터베이스를 업데이트한 후 잠시 절전 모드를 연기한 다음 캐시를 삭제하세요- 이 솔루션은 휴면 기간에만 괜찮습니다. 더티 데이터일 수도 있고, 일반 업체에서도 인정합니다
- 그런데 두 번째로 삭제하면 캐시 오류는 어떻게 되나요? 캐시와 데이터베이스의 데이터가 여전히 일치하지 않을 수 있습니다. 키에 대한 자연 만료 만료 시간을 설정하고 자동으로 만료되도록 하는 것은 어떻습니까? 만료 시간 내에 기업에서 승인한 데이터가 일치하지 않는 경우 어떻게 해야 합니까? 더 나은 솔루션도 있습니다
-
-
2. 캐시 삭제 재시도 메커니즘
지연된 이중 삭제로 인해 캐시 삭제의 두 번째 단계가 실패하여 데이터 불일치 문제가 발생할 수 있습니다
삭제에 실패하면 여러 번 삭제하세요. 네, 캐시 삭제가 성공했는지 확인하면 - 캐시 삭제 재시도 메커니즘
-
3. biglog를 읽고 캐시를 비동기적으로 삭제합니다.
삭제 재시도 메커니즘으로 인해 비즈니스 코드 침입이 많으므로 biglog 읽기 및 캐시 비동기 삭제 소개
-
권장 학습: Redis 비디오 튜토리얼
위 내용은 Redis 클러스터 및 확장에 대한 자세한 그래픽 설명의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!


 1. Redisson
1. Redisson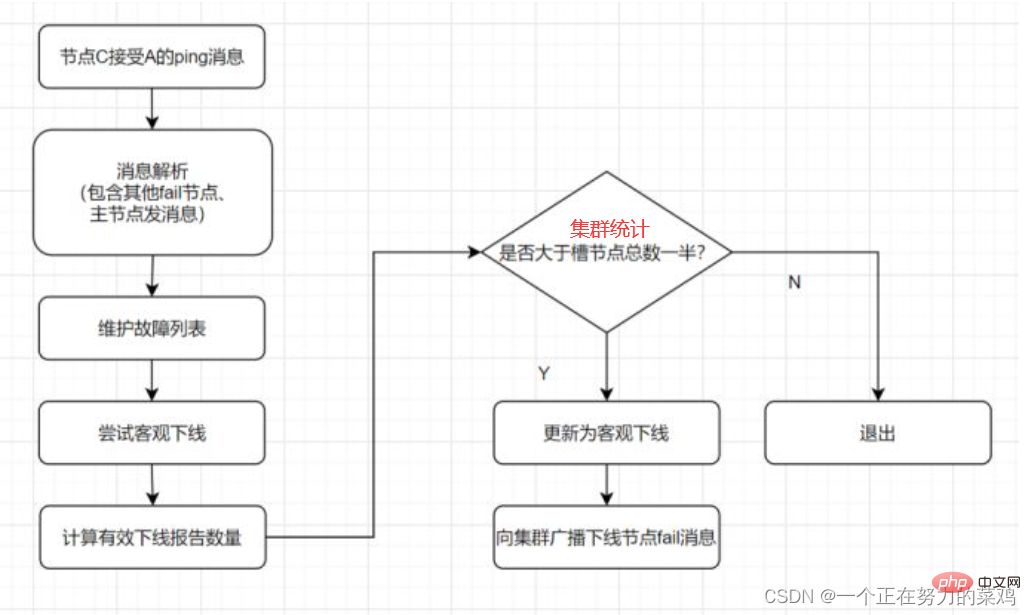
 .
. 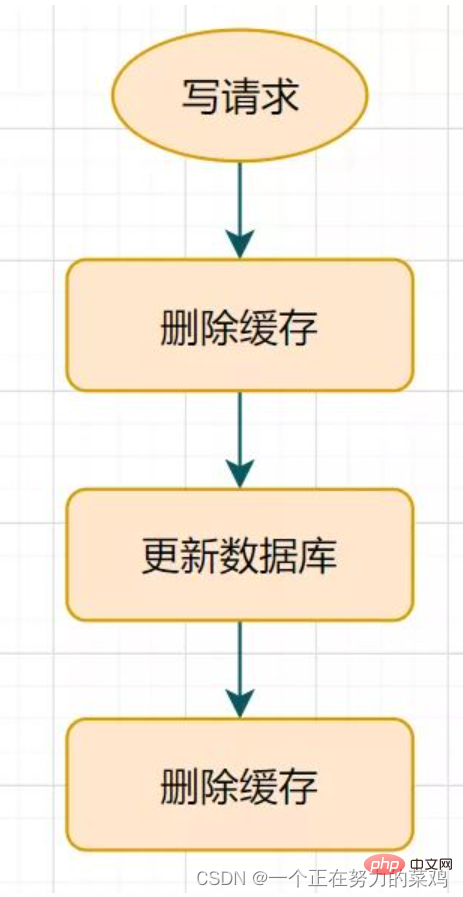 2. 캐시 삭제 재시도 메커니즘
2. 캐시 삭제 재시도 메커니즘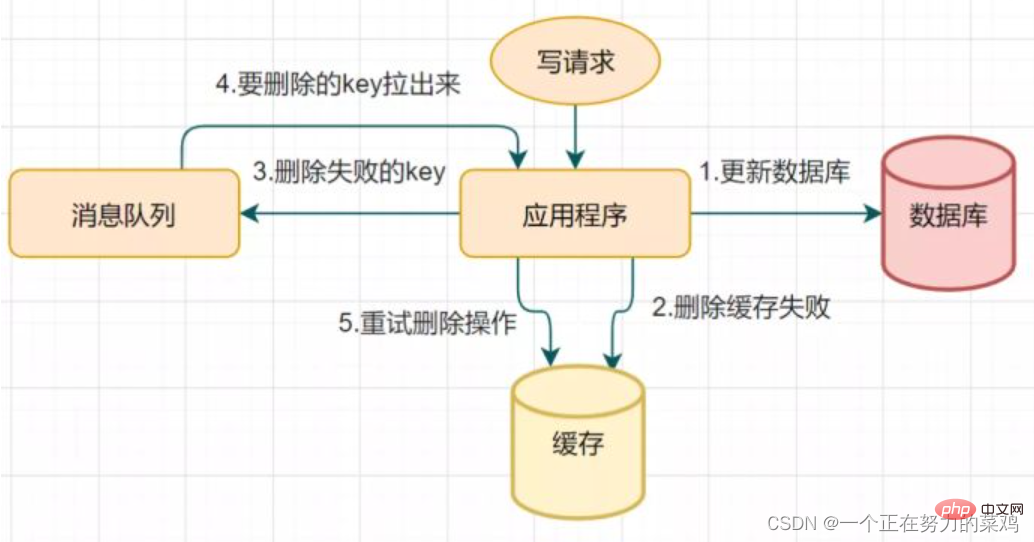 3. biglog를 읽고 캐시를 비동기적으로 삭제합니다.
3. biglog를 읽고 캐시를 비동기적으로 삭제합니다.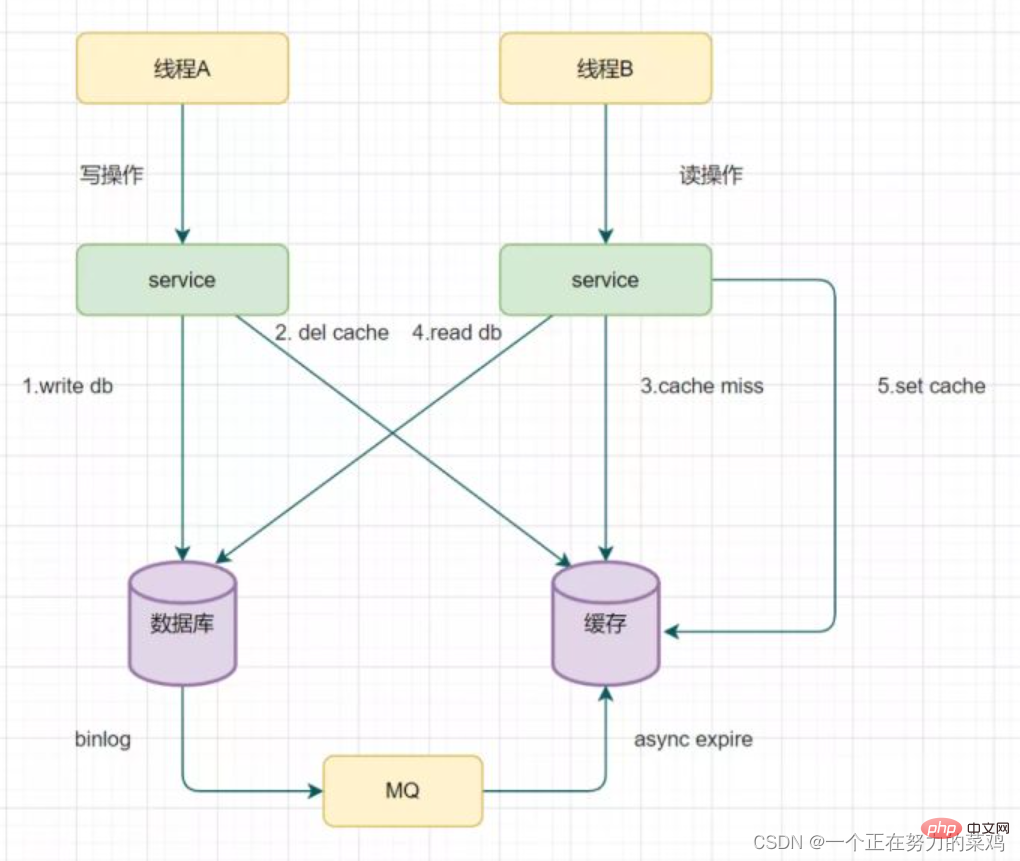 권장 학습:
권장 학습: 


















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



