
이 기사에서는 크롤러와 관련된 문제를 주로 정리하는 Python에 대한 관련 지식을 제공합니다. 웹 크롤러(웹 스파이더, 웹 로봇이라고도 함)는 브라우저를 시뮬레이션하여 네트워크 요청을 보내고 요청 응답을 받는 프로그램입니다. 특정 규칙에 따른 정보를 살펴보겠습니다. 모두에게 도움이 되기를 바랍니다.

【관련 추천: Python3 비디오 튜토리얼】
웹 크롤러(웹 스파이더, 네트워크 로봇이라고도 함)는 브라우저를 시뮬레이션하여 네트워크 요청을 보내고 자동으로 요청 응답을 받는 프로그램입니다. 인터넷 정보를 크롤링합니다.
원칙적으로 브라우저(클라이언트)가 무엇이든 할 수 있는 한 크롤러도 할 수 있습니다.
인터넷 빅데이터 시대는 우리에게 생활의 편리함과 네트워크상의 대용량 데이터의 폭발적인 등장을 선사합니다.
과거에는 책, 신문, 텔레비전, 라디오 또는 정보를 이용했습니다. 정보의 양이 제한되어 어느 정도 선별을 거쳐야 했지만, 정보의 범위가 너무 좁다는 것이 단점이었습니다. 비대칭 정보 전송은 우리의 비전을 제한하고 더 많은 정보와 지식을 배우지 못하게 합니다.
인터넷 빅데이터 시대에 우리는 갑자기 정보에 자유롭게 접근할 수 있게 되었습니다. 엄청난 양의 정보를 얻었지만, 그 중 대부분은 유효하지 않은 정크 정보입니다.
예를 들어, Sina Weibo는 하루에 수억 개의 상태 업데이트를 생성하는 반면 Baidu 검색 엔진에서는 체중 감량에 관한 메시지 1억 개만 검색할 수 있습니다.
이렇게 많은 정보 조각 속에서 우리에게 유용한 정보를 어떻게 얻을 수 있을까요?
정답은 심사입니다!
특정 기술을 통해 관련 콘텐츠를 수집하고, 분석과 선택을 거쳐야 정말 필요한 정보를 얻을 수 있습니다.
이러한 정보 수집, 분석 및 통합 작업은 생활 서비스, 여행, 금융 투자, 다양한 제조 산업의 제품 시장 수요 등 매우 광범위한 분야에 적용될 수 있습니다. 이 기술을 사용하여 더욱 정확하고 효과적인 정보를 활용하세요.
웹 크롤러 기술은 이름이 이상해서 Neng의 첫 반응이 부드럽고 꿈틀거리는 생물처럼 보이지만 실제로는 가상 세계에서 앞으로 나아갈 수 있는 강력한 도구입니다.
우리는 일반적으로 Python 크롤러에 대해 이야기합니다. 실제로 여기서는 오해가 있을 수 있습니다. 크롤러는 Python에만 사용할 수 있는 언어가 아닙니다. 예: PHP, JAVA, C#, C++, Python. 크롤러를 하는 이유는 Python이 비교적 간단하고 완전한 기능을 갖추고 있기 때문입니다.
먼저 Python을 다운로드해야 합니다. 최신 공식 버전인 3.8.3을 다운로드했습니다.
두 번째로 Python을 실행할 환경이 필요합니다. 저는 pychram을 사용합니다

공식에서도 다운로드할 수 있습니다.
라이브러리도 필요합니다 크롤러 작동을 지원하기 위해(일부 라이브러리는 Python과 함께 제공될 수 있음)
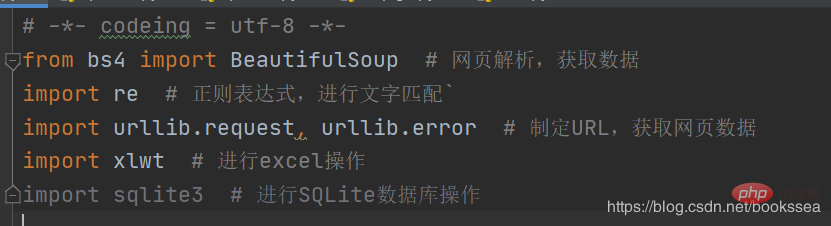
거의 이것들이 라이브러리입니다. 이미 뒤에 주석을 작성했습니다

(크롤러 실행 프로세스 중에 반드시 사용자만 그런 것은 아닙니다. 위의 라이브러리가 필요합니다. 어쨌든 라이브러리가 필요하면 설정에서 직접 설치할 수 있습니다.)
제가 하는 일은 다음의 크롤러 코드를 크롤링하는 것입니다. the Top 250 Douban 등급 영화
우리가 크롤링하려는 웹사이트는 다음과 같습니다: https://movie.douban.com/top250
여기서 크롤링을 마쳤습니다. 크롤링된 콘텐츠를 xls에 저장했습니다.
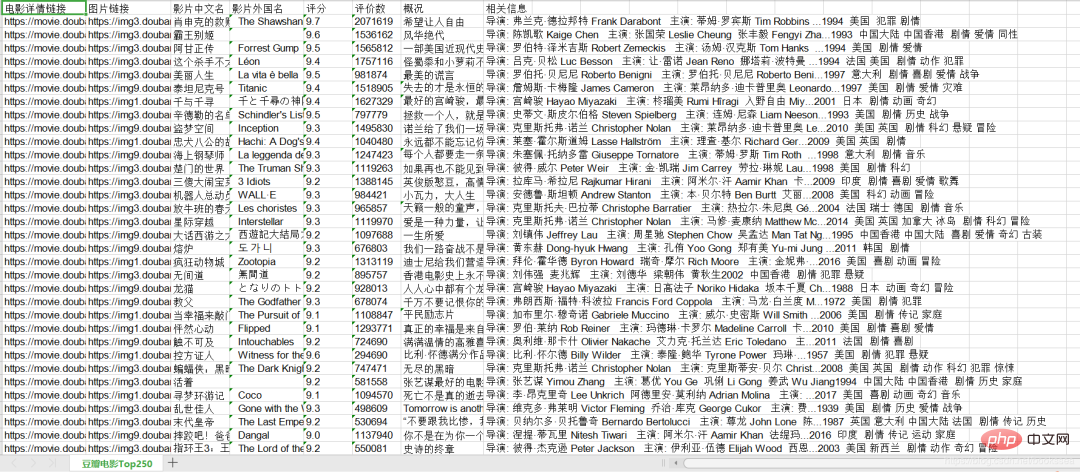
우리가 크롤링한 콘텐츠는 다음과 같습니다: 영화 세부 정보 링크, 사진 링크, 영화의 중국어 이름, 영화의 외국 이름, 평가, 리뷰 수, 개요 및 관련 정보.
먼저 코드를 올려주시고, 그다음 코드를 기준으로 차근차근 분석해보겠습니다
# -*- codeing = utf-8 -*-
from bs4 import BeautifulSoup # 网页解析,获取数据
import re # 正则表达式,进行文字匹配`
import urllib.request, urllib.error # 制定URL,获取网页数据
import xlwt # 进行excel操作
#import sqlite3 # 进行SQLite数据库操作
findLink = re.compile(r'<a href="(.*?)">') # 创建正则表达式对象,标售规则 影片详情链接的规则
findImgSrc = re.compile(r'<img.*src="(.*?)"', re.S)
findTitle = re.compile(r'<span class="title">(.*)</span>')
findRating = re.compile(r'<span class="rating_num" property="v:average">(.*)</span>')
findJudge = re.compile(r'<span>(\d*)人评价</span>')
findInq = re.compile(r'<span class="inq">(.*)</span>')
findBd = re.compile(r'<p class="">(.*?)</p>', re.S)
def main():
baseurl = "https://movie.douban.com/top250?start=" #要爬取的网页链接
# 1.爬取网页
datalist = getData(baseurl)
savepath = "豆瓣电影Top250.xls" #当前目录新建XLS,存储进去
# dbpath = "movie.db" #当前目录新建数据库,存储进去
# 3.保存数据
saveData(datalist,savepath) #2种存储方式可以只选择一种
# saveData2DB(datalist,dbpath)
# 爬取网页
def getData(baseurl):
datalist = [] #用来存储爬取的网页信息
for i in range(0, 10): # 调用获取页面信息的函数,10次
url = baseurl + str(i * 25)
html = askURL(url) # 保存获取到的网页源码
# 2.逐一解析数据
soup = BeautifulSoup(html, "html.parser")
for item in soup.find_all('p', class_="item"): # 查找符合要求的字符串
data = [] # 保存一部电影所有信息
item = str(item)
link = re.findall(findLink, item)[0] # 通过正则表达式查找
data.append(link)
imgSrc = re.findall(findImgSrc, item)[0]
data.append(imgSrc)
titles = re.findall(findTitle, item)
if (len(titles) == 2):
ctitle = titles[0]
data.append(ctitle)
otitle = titles[1].replace("/", "") #消除转义字符
data.append(otitle)
else:
data.append(titles[0])
data.append(' ')
rating = re.findall(findRating, item)[0]
data.append(rating)
judgeNum = re.findall(findJudge, item)[0]
data.append(judgeNum)
inq = re.findall(findInq, item)
if len(inq) != 0:
inq = inq[0].replace("。", "")
data.append(inq)
else:
data.append(" ")
bd = re.findall(findBd, item)[0]
bd = re.sub('<br(\s+)?/>(\s+)?', "", bd)
bd = re.sub('/', "", bd)
data.append(bd.strip())
datalist.append(data)
return datalist
# 得到指定一个URL的网页内容
def askURL(url):
head = { # 模拟浏览器头部信息,向豆瓣服务器发送消息
"User-Agent": "Mozilla / 5.0(Windows NT 10.0; Win64; x64) AppleWebKit / 537.36(KHTML, like Gecko) Chrome / 80.0.3987.122 Safari / 537.36"
}
# 用户代理,表示告诉豆瓣服务器,我们是什么类型的机器、浏览器(本质上是告诉浏览器,我们可以接收什么水平的文件内容)
request = urllib.request.Request(url, headers=head)
html = ""
try:
response = urllib.request.urlopen(request)
html = response.read().decode("utf-8")
except urllib.error.URLError as e:
if hasattr(e, "code"):
print(e.code)
if hasattr(e, "reason"):
print(e.reason)
return html
# 保存数据到表格
def saveData(datalist,savepath):
print("save.......")
book = xlwt.Workbook(encoding="utf-8",style_compression=0) #创建workbook对象
sheet = book.add_sheet('豆瓣电影Top250', cell_overwrite_ok=True) #创建工作表
col = ("电影详情链接","图片链接","影片中文名","影片外国名","评分","评价数","概况","相关信息")
for i in range(0,8):
sheet.write(0,i,col[i]) #列名
for i in range(0,250):
# print("第%d条" %(i+1)) #输出语句,用来测试
data = datalist[i]
for j in range(0,8):
sheet.write(i+1,j,data[j]) #数据
book.save(savepath) #保存
# def saveData2DB(datalist,dbpath):
# init_db(dbpath)
# conn = sqlite3.connect(dbpath)
# cur = conn.cursor()
# for data in datalist:
# for index in range(len(data)):
# if index == 4 or index == 5:
# continue
# data[index] = '"'+data[index]+'"'
# sql = '''
# insert into movie250(
# info_link,pic_link,cname,ename,score,rated,instroduction,info)
# values (%s)'''%",".join(data)
# # print(sql) #输出查询语句,用来测试
# cur.execute(sql)
# conn.commit()
# cur.close
# conn.close()
# def init_db(dbpath):
# sql = '''
# create table movie250(
# id integer primary key autoincrement,
# info_link text,
# pic_link text,
# cname varchar,
# ename varchar ,
# score numeric,
# rated numeric,
# instroduction text,
# info text
# )
#
#
# ''' #创建数据表
# conn = sqlite3.connect(dbpath)
# cursor = conn.cursor()
# cursor.execute(sql)
# conn.commit()
# conn.close()
# 保存数据到数据库
if __name__ == "__main__": # 当程序执行时
# 调用函数
main()
# init_db("movietest.db")
print("爬取完毕!")이제 코드를 기준으로 밑바닥부터 설명하고 분석하겠습니다 -- 코딩 = utf -8 --, Starting 인코딩을 utf-8로 설정하고 맨 앞에 써서 문자 깨짐을 방지하는 것입니다.
그 다음 import는 몇몇 라이브러리를 import해서 준비하는 것입니다(저는 sqlite3 라이브러리를 사용해본 적이 없어서 주석 처리했습니다).
find로 시작하는 다음 단어 중 일부는 정보를 필터링하는 데 사용되는 정규식입니다.
(정규식은 re 라이브러리를 사용하며, 정규식은 필수가 아닙니다. 필요하지 않습니다.)
일반적인 프로세스는 세 단계로 나뉩니다.
1. 웹페이지 크롤링
2. 데이터를 하나씩 구문 분석합니다
3 . 웹페이지 저장
先分析流程1,爬取网页,baseurl 就是我们要爬虫的网页网址,往下走,调用了 getData(baseurl) ,
我们来看 getData方法
for i in range(0, 10): # 调用获取页面信息的函数,10次 url = baseurl + str(i * 25)
这段大家可能看不懂,其实是这样的:
因为电影评分Top250,每个页面只显示25个,所以我们需要访问页面10次,25*10=250。
baseurl = "https://movie.douban.com/top250?start="
我们只要在baseurl后面加上数字就会跳到相应页面,比如i=1时
https://movie.douban.com/top250?start=25
我放上超链接,大家可以点击看看会跳到哪个页面,毕竟实践出真知。
然后又调用了askURL来请求网页,这个方法是请求网页的主体方法,
怕大家翻页麻烦,我再把代码复制一遍,让大家有个直观感受
def askURL(url):
head = { # 模拟浏览器头部信息,向豆瓣服务器发送消息
"User-Agent": "Mozilla / 5.0(Windows NT 10.0; Win64; x64) AppleWebKit / 537.36(KHTML, like Gecko) Chrome / 80.0.3987.122 Safari / 537.36"
}
# 用户代理,表示告诉豆瓣服务器,我们是什么类型的机器、浏览器(本质上是告诉浏览器,我们可以接收什么水平的文件内容)
request = urllib.request.Request(url, headers=head)
html = ""
try:
response = urllib.request.urlopen(request)
html = response.read().decode("utf-8")
except urllib.error.URLError as e:
if hasattr(e, "code"):
print(e.code)
if hasattr(e, "reason"):
print(e.reason)
return html这个askURL就是用来向网页发送请求用的,那么这里就有老铁问了,为什么这里要写个head呢?
这是因为我们要是不写的话,访问某些网站的时候会被认出来爬虫,显示错误,错误代码
这是一个梗大家可以百度下,
418 I’m a teapot
The HTTP 418 I’m a teapot client error response code indicates that
the server refuses to brew coffee because it is a teapot. This error
is a reference to Hyper Text Coffee Pot Control Protocol which was an
April Fools’ joke in 1998.
我是一个茶壶
所以我们需要 “装” ,装成我们就是一个浏览器,这样就不会被认出来,
伪装一个身份。
来,我们继续往下走,
html = response.read().decode("utf-8")这段就是我们读取网页的内容,设置编码为utf-8,目的就是为了防止乱码。
访问成功后,来到了第二个流程:
2.逐一解析数据
解析数据这里我们用到了 BeautifulSoup(靓汤) 这个库,这个库是几乎是做爬虫必备的库,无论你是什么写法。
下面就开始查找符合我们要求的数据,用BeautifulSoup的方法以及 re 库的
正则表达式去匹配,
findLink = re.compile(r'<a href="(.*?)">') # 创建正则表达式对象,标售规则 影片详情链接的规则 findImgSrc = re.compile(r'<img.*src="(.*?)"', re.S) findTitle = re.compile(r'<span class="title">(.*)</span>') findRating = re.compile(r'<span class="rating_num" property="v:average">(.*)</span>') findJudge = re.compile(r'<span>(\d*)人评价</span>') findInq = re.compile(r'<span class="inq">(.*)</span>') findBd = re.compile(r'<p class="">(.*?)</p>', re.S)
匹配到符合我们要求的数据,然后存进 dataList , 所以 dataList 里就存放着我们需要的数据了。
最后一个流程:
3.保存数据
# 3.保存数据 saveData(datalist,savepath) #2种存储方式可以只选择一种 # saveData2DB(datalist,dbpath)
保存数据可以选择保存到 xls 表, 需要(xlwt库支持)
也可以选择保存数据到 sqlite数据库, 需要(sqlite3库支持)
这里我选择保存到 xls 表 ,这也是为什么我注释了一大堆代码,注释的部分就是保存到 sqlite 数据库的代码,二者选一就行
保存到 xls 的主体方法是 saveData (下面的saveData2DB方法是保存到sqlite数据库):
def saveData(datalist,savepath):
print("save.......")
book = xlwt.Workbook(encoding="utf-8",style_compression=0) #创建workbook对象
sheet = book.add_sheet('豆瓣电影Top250', cell_overwrite_ok=True) #创建工作表
col = ("电影详情链接","图片链接","影片中文名","影片外国名","评分","评价数","概况","相关信息")
for i in range(0,8):
sheet.write(0,i,col[i]) #列名
for i in range(0,250):
# print("第%d条" %(i+1)) #输出语句,用来测试
data = datalist[i]
for j in range(0,8):
sheet.write(i+1,j,data[j]) #数据
book.save(savepath) #保存创建工作表,创列(会在当前目录下创建),
sheet = book.add_sheet('豆瓣电影Top250', cell_overwrite_ok=True) #创建工作表
col = ("电影详情链接","图片链接","影片中文名","影片外国名","评分","评价数","概况","相关信息")然后把 dataList里的数据一条条存进去就行。
最后运作成功后,会在左侧生成这么一个文件

打开之后看看是不是我们想要的结果
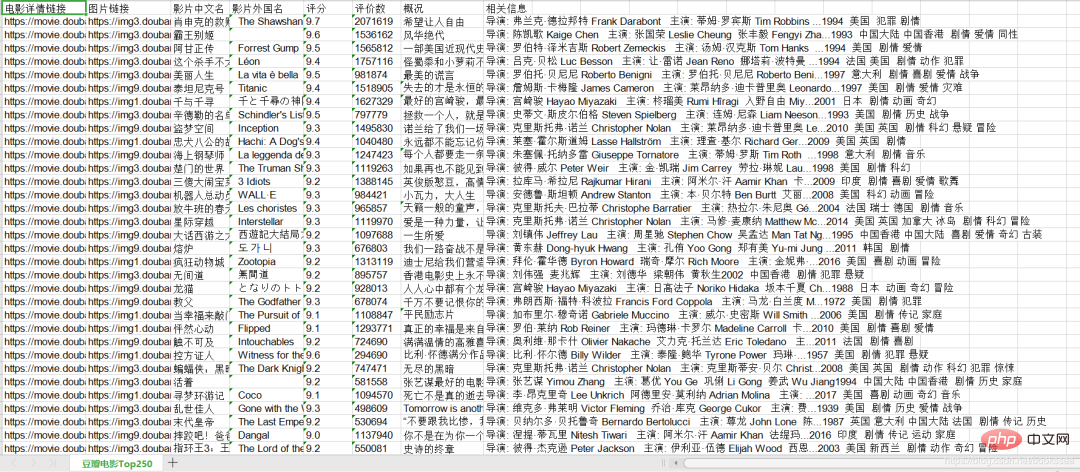
成了,成了!如果我们需要以数据库方式存储,可以先生成 xls 文件,再把 xls 文件导入数据库中,就可以啦!
【相关推荐:Python3视频教程 】
위 내용은 Python 크롤러에 대한 매우 자세한 설명의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!


















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



