

Oracle 예제에서는 그룹화된 데이터를 자세히 설명합니다.

이 기사에서는 주로 그룹화된 데이터와 관련된 문제를 정리하는 Oracle에 대한 관련 지식을 제공합니다. 그룹화를 사용하면 데이터를 논리적 그룹으로 나누어 각 그룹에서 집계 계산을 수행할 수 있습니다. 그것이 모두에게 도움이 되기를 바랍니다.

추천 튜토리얼: "Oracle Video Tutorial"
그룹화를 사용하면 데이터를 논리적 그룹으로 나누어 각 그룹에서 집계 계산을 수행할 수 있습니다.
1. 그룹 만들기
그룹은 SELECT 문의 GROUP BY 절을 사용하여 생성됩니다.
예:
SELECT vend_id, count(*) as num_prodsfrom productsgroup by vend_id;

GROUP BY를 사용하면 평가하고 계산할 각 그룹화를 지정할 필요가 없으며 자동으로 수행됩니다. GROUP BY 절은 Oracle에게 데이터를 그룹화하고 (전체 결과 집합이 아닌) 각 그룹에 대해 집계를 수행하도록 지시합니다.
GROUP BY를 사용하기 전에 다음은 GROUP BY 사용에 대해 알아야 할 몇 가지 중요한 규칙입니다.
- GROUP BY 절에는 필요한 만큼의 열이 포함될 수 있습니다. 중첩된 그룹화를 허용하여 데이터 그룹화 방법을 보다 세밀하게 제어할 수 있습니다.
- group by 절에 중첩된 그룹이 있는 경우 마지막으로 지정된 그룹에 데이터가 요약됩니다. 즉, 그룹화를 구축할 때 지정된 모든 열이 함께 평가됩니다(따라서 각 개별 열에 대한 데이터가 검색되지 않습니다).
- 그룹 기준에 나열된 각 열은 검색된 열이거나 유효한 표현식(집계 함수 아님)이어야 합니다. Select에서 표현식을 사용하는 경우 Group by에서도 동일한 표현식을 지정해야 합니다. 별칭은 사용할 수 없습니다.
- 집계 계산 문을 제외하고 SELECT 문의 각 열은 GROUP BY 절에 나타나야 합니다.
- 그룹화 열에 NULL 값이 포함된 열이 포함된 경우 NULL이 그룹화로 반환됩니다. NULL 값이 있는 행이 여러 개인 경우 모두 함께 그룹화됩니다.
- GROUP BY 절은 WHERE 절 뒤, ORDER BY 절 앞에 와야 합니다.
2. 필터 그룹화
where 절은 일반적으로 행 필터링에도 사용됩니다. 그러나 여기서는 특정 행을 그룹화하는 것이 아니라 필터링할 수 있으므로 여기서는 적용되지 않습니다. 실제로 그룹화에는 적용할 수 없습니다.
Oracle은 이에 대한 또 다른 조항인 HAVING을 제공합니다. where 절과 have 절의 유일한 차이점은 where 절은 행을 필터링하고, where 절은 필터 그룹을 갖는 것입니다.
**팁: **having은 모든 where 연산자를 지원합니다
where와 had의 규칙은 키워드만 다를 뿐 완전히 동일합니다.
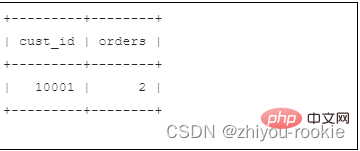
예:
SELECT cust_id, COUNT(*) AS ordersFROM ordersGROUP BY cust_idHAVING COUNT(*) >= 2;
참고: 갖는 것과 위치의 차이점
다른 각도에서 갖는 것과 위치의 차이점을 살펴보세요. 필터링은 데이터 이전에 발생하는 반면 필터링은 데이터 이전에 발생합니다. 데이터 그룹화 후. 이는 중요한 차이점입니다. where 절에 의해 삭제된 행은 그룹화에 포함되지 않습니다. 이는 have 절에 사용된 값을 기반으로 계산된 값을 변경할 수 있으며, 결과적으로 필터링할 그룹에 영향을 미칠 수 있습니다.
where 절과 had 절을 함께 사용하는 예:
select vend_id, count(*), as num_prodsfrom productswhere prod_price>=10group by vend_idhaving count(*) > 2;
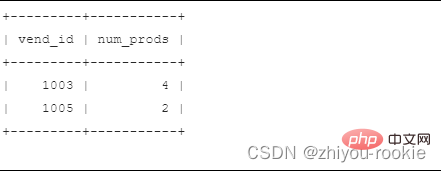
SELECT vend_id, COUNT(*) AS num_prodsFROM productsGROUP BY vend_idHAVING COUNT(*) >= 2;

3 그룹화 및 정렬
일반적으로 사용되지만 group by와 order by의 차이는 엄청납니다. 완료를 위해 마찬가지입니다.
다음 표에서는 order by와 group by의 차이점을 설명합니다.
| order by | group by |
|---|---|
| 생성된 출력을 정렬 | 행을 그룹화하지만 출력이 그렇지 않을 수 있습니다. 그룹화 순서 |
| 모든 열(선택되지 않은 열 포함)을 사용할 수 있습니다. | 선택한 열이나 표현식만 사용할 수 있으며 선택한 모든 열 표현식을 반드시 사용할 수 있습니다. |
| 절대 필요하지 않습니다 | 다음과 같은 열(또는 표현식)을 사용하는 경우 필수입니다. 집계 함수 |
时常,你会发现使用GROUP BY分组的数据的确是以分组顺序输出的。但是并非总是如此,并且实际上SQL规范也并没有如此要求。而且你实际上可能希望它以不同于分组的方式进行排序。你以一种方式对数据进行分组(以获得特定于分组的聚合值),并不意味着你也希望输出以相同的方式进行排序。总是应该还提供一个显式的ORDER BY子句,即使它与GROUP BY子句完全相同。
提示:不要忘记ORDER BY
通常,无论何时使用GROUP BY子句,还应该指定一个ORDER BY子句,这是确保正确地对数据进行排序的唯一方式。永远不要依靠GROUP BY对数据排序。
为了演示同时使用GROUP BY和ORDER BY的情况,让我们看一个示例。下面的SELECT语句类似于之前使用的SELECT语句。它用于检索总价在50以上(含50)的所有订单的订单号和订单总价:
SELECT order_num, SUM(quantity*item_price) AS ordertotalFROM orderitemsGROUP BY order_numHAVING SUM(quantity*item_price) >= 50;
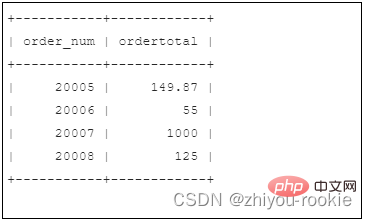
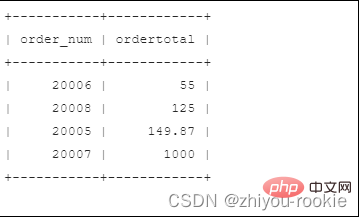
要按订单总价对输出进行排序,只需添加一个ORDER BY子句,如下:
SELECT order_num, SUM(quantity*item_price) AS ordertotalFROM orderitemsGROUP BY order_numHAVING SUM(quantity*item_price) >= 50ORDER BY ordertotal;
4、select子句排序
select子句和它们的顺序
| 子句 | 描述 | 是否必须 |
|---|---|---|
| select | 要返回的列或表达式 | Y |
| from | 要从中检索数据的表 | Y(在Oracle中是必须的;在大多数其他的DBMS中则不是) |
| where | 行级过滤(分组前过滤) | N |
| group by | 分组规范 | 仅当按分组计算聚合值时是必须的 |
| having | 分组级过滤(分组后过滤) | N |
| order by | 输出的排列顺序 | N |
推荐教程:《Oracle视频教程》
위 내용은 Oracle 예제에서는 그룹화된 데이터를 자세히 설명합니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7536
7536
 15
1379
52
82
11
55
19
21
86
15
1379
52
82
11
55
19
21
86

 Oracle의 테이블 스페이스 크기를 확인하는 방법
Apr 11, 2025 pm 08:15 PM
Oracle의 테이블 스페이스 크기를 확인하는 방법
Apr 11, 2025 pm 08:15 PM
Oracle 테이블 스페이스 크기를 쿼리하려면 다음 단계를 따르십시오. 쿼리를 실행하여 테이블 스페이스 이름을 결정하십시오. 쿼리를 실행하여 테이블 스페이스 크기를 쿼리하십시오. sum (bytes)을 total_size, sum (bytes_free)으로 sum (bytes_free), sum (bytes) - sum (bytes_free)으로 dba_data_fices where tablespace_.
 Oracle의 인스턴스 이름을 보는 방법
Apr 11, 2025 pm 08:18 PM
Oracle의 인스턴스 이름을 보는 방법
Apr 11, 2025 pm 08:18 PM
Oracle에서 인스턴스 이름을 보는 세 가지 방법이 있습니다. 명령 줄에 명령. "show instance_name"을 사용하십시오. sql*plus의 명령. 운영 체제의 작업 관리자, Oracle Enterprise Manager 또는 운영 체제를 통해 환경 변수 (Linux의 Oracle_Sid)를 확인하십시오.
 Oracle View를 암호화하는 방법
Apr 11, 2025 pm 08:30 PM
Oracle View를 암호화하는 방법
Apr 11, 2025 pm 08:30 PM
Oracle View 암호화를 사용하면보기에서 데이터를 암호화 할 수 있으므로 민감한 정보의 보안을 향상시킬 수 있습니다. 단계에는 다음이 포함됩니다. 1) 마스터 암호화 키 생성 (MEK); 2) 암호화 된 뷰 생성, 암호화 할보기 및 MEK를 지정하는 것; 3) 사용자가 암호화 된보기에 액세스하도록 승인합니다. 암호화 된 뷰 작동 방식 : 사용자가 암호화 된보기를 쿼리 할 때 Oracle은 MEK를 사용하여 데이터를 해독하여 공인 사용자 만 읽기 쉬운 데이터에 액세스 할 수 있도록합니다.
 Oracle 설치를 제거하는 방법에 실패했습니다
Apr 11, 2025 pm 08:24 PM
Oracle 설치를 제거하는 방법에 실패했습니다
Apr 11, 2025 pm 08:24 PM
Oracle 설치 실패에 대한 방법 제거 : Oracle Service를 닫고 Oracle Program 파일 및 레지스트리 키 삭제, Oracle 환경 변수를 제거하고 컴퓨터를 다시 시작하십시오. 제거되지 않으면 Oracle 범용 제거 도구를 사용하여 수동으로 제거 할 수 있습니다.
 오라클에서 시간을 얻는 방법
Apr 11, 2025 pm 08:09 PM
오라클에서 시간을 얻는 방법
Apr 11, 2025 pm 08:09 PM
Oracle에는 시간을 얻는 방법이 있습니다. current_timestamp : 현재 시스템 시간을 반환합니다. Systimestamp : current_timestamp보다 나노 초보다 더 정확합니다. sysdate : 시간 부분을 제외하고 현재 시스템 날짜를 반환합니다. to_char (sysdate, 'yyy-mm-dd hh24 : mi : ss') : 현재 시스템 날짜와 시간을 특정 형식으로 변환합니다. 추출 : 1 년, 월 또는 시간과 같은 시간 값에서 특정 부분을 추출합니다.
 Oracle 데이터베이스를 가져 오는 방법
Apr 11, 2025 pm 08:06 PM
Oracle 데이터베이스를 가져 오는 방법
Apr 11, 2025 pm 08:06 PM
데이터 가져 오기 방법 : 1. SQLLOADER 유틸리티 사용 : 데이터 파일 준비, 제어 파일 작성 및 SQLLOADER 실행; 2. IMP/EXP 도구를 사용하십시오 : 데이터 내보내기, 데이터 가져 오기. 팁 : 1. 빅 데이터 세트에 권장되는 SQL*로더; 2. 대상 테이블이 존재해야하고 열 정의가 일치해야합니다. 3. 가져 오기 후에는 데이터 무결성을 확인해야합니다.
 Oracle 사용자를 설정하는 방법
Apr 11, 2025 pm 08:21 PM
Oracle 사용자를 설정하는 방법
Apr 11, 2025 pm 08:21 PM
Oracle에서 사용자를 만들려면 다음 단계를 따르십시오. 사용자 명령문을 사용하여 새 사용자를 만듭니다. 보조금 명세서를 사용하여 필요한 권한을 부여하십시오. 선택 사항 : 리소스 문을 사용하여 할당량을 설정하십시오. 기본 역할 및 임시 테이블 스페이스와 같은 다른 옵션을 구성하십시오.
 Oracle Loop에서 커서를 만드는 방법
Apr 12, 2025 am 06:18 AM
Oracle Loop에서 커서를 만드는 방법
Apr 12, 2025 am 06:18 AM
Oracle에서 FOR 루프 루프는 커서를 동적으로 생성 할 수 있습니다. 단계는 다음과 같습니다. 1. 커서 유형을 정의합니다. 2. 루프를 만듭니다. 3. 커서를 동적으로 만듭니다. 4. 커서를 실행하십시오. 5. 커서를 닫습니다. 예 : 커서는 상위 10 명의 직원의 이름과 급여를 표시하기 위해주기별로 만들 수 있습니다.
