

Python 크롤러는 웹페이지 데이터를 크롤링하고 데이터를 구문 분석합니다.

이 글에서는 Python에 대한 관련 지식을 소개합니다. 주로 Python 크롤러가 웹 페이지 데이터를 크롤링하고 데이터를 구문 분석하여 크롤러를 사용하여 웹 페이지를 분석하는 데 도움이 되기를 바랍니다. 모두에게 도움이 됩니다.

【관련 추천: Python3 동영상 튜토리얼】
1. 웹 크롤러의 기본 개념
웹 크롤러(웹 스파이더, 로봇이라고도 함)는 클라이언트가 네트워크 요청을 보내고 요청 응답 수신 , 특정 규칙에 따라 인터넷 정보를 자동으로 캡처하는 프로그램입니다.
브라우저가 무엇이든 할 수 있다면 원칙적으로 크롤러도 할 수 있습니다.
2. 웹 크롤러의 기능
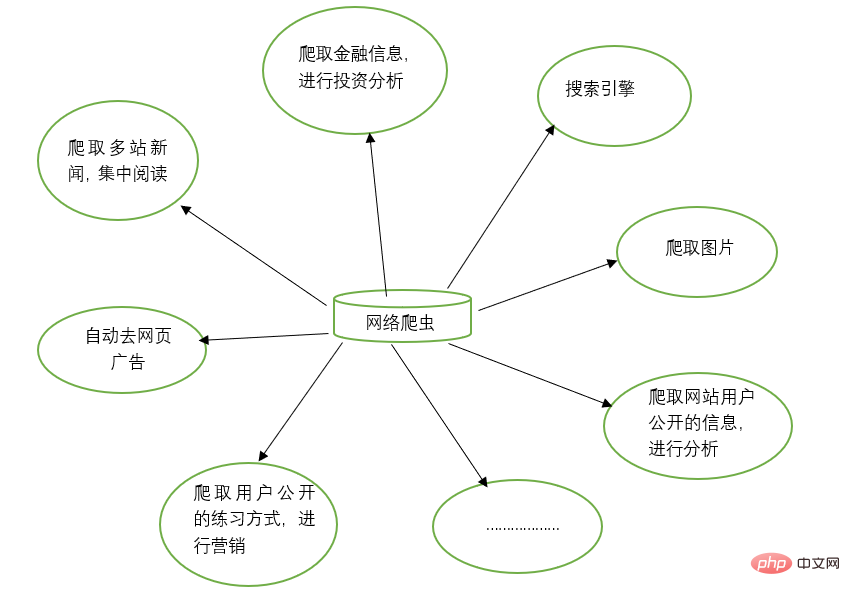
웹 크롤러는 검색 엔진, 웹사이트의 이미지 크롤링 등 많은 작업을 수행하는 수동 작업을 대체할 수 있습니다. 동시에 웹 크롤러는 금융 투자 분야에서도 사용할 수 있습니다. 예를 들어 일부 금융 정보를 자동으로 크롤링하고 투자 분석을 수행할 수 있습니다.
때때로 즐겨찾는 뉴스 웹사이트가 여러 개 있을 수 있으며, 탐색할 때마다 이러한 뉴스 웹사이트를 별도로 열어야 하는 것이 번거롭습니다. 이때 웹 크롤러를 이용하면 이러한 여러 뉴스 사이트의 뉴스 정보를 크롤링하여 함께 읽을 수 있습니다.
가끔 웹에서 정보를 검색하다 보면 광고가 많이 나올 때가 있습니다. 이때, 귀하는 크롤러를 이용하여 해당 웹페이지의 정보를 크롤링할 수 있으며, 이러한 광고를 자동으로 필터링하여 정보를 쉽게 읽고 이용할 수 있도록 할 수 있습니다.
때때로 마케팅을 해야 할 때도 있기 때문에 타겟 고객을 어떻게 찾고 연락처를 찾는지가 중요한 문제입니다. 인터넷에서 수동으로 검색할 수 있지만 이는 매우 비효율적입니다. 이때 당사는 크롤러를 사용하여 해당 규칙을 설정하고 마케팅 용도로 인터넷에서 대상 사용자의 연락처 정보 및 기타 데이터를 자동으로 수집할 수 있습니다.
웹사이트의 사용자 활동, 댓글 수, 인기 기사 및 기타 정보를 분석하는 등 특정 웹사이트의 사용자 정보를 분석하려는 경우가 있습니다. 웹사이트 관리자가 아닌 경우 수동 통계는 매우 어려울 수 있습니다. 거대한 프로젝트. 이때 크롤러를 사용하면 추가 분석을 위해 이러한 데이터를 쉽게 수집할 수 있습니다. 모든 크롤링 작업은 해당 크롤러를 작성하고 해당 규칙을 설계하기만 하면 됩니다.
또한 크롤러는 많은 강력한 기능을 수행할 수도 있습니다. 즉, 크롤러의 출현은 웹 페이지에 대한 수동 액세스를 어느 정도 대체할 수 있습니다. 따라서 이전에 인터넷 정보에 수동으로 액세스해야 했던 작업을 이제 크롤러를 사용하여 자동화할 수 있으며, 이는 인터넷에서 효과적인 정보를 보다 효율적으로 사용할 수 있습니다. .
3. 타사 라이브러리 설치
데이터를 크롤링하고 구문 분석하기 전에 Python 실행 환경에서 타사 라이브러리 요청을 다운로드하고 설치해야 합니다.
Windows 시스템에서 cmd(명령 프롬프트) 인터페이스를 열고 인터페이스에 pip 설치 요청을 입력한 후 Enter를 눌러 설치하세요. (네트워크 연결에 주의하세요) 아래와 같이
그림과 같이 설치가 완료되었습니다.
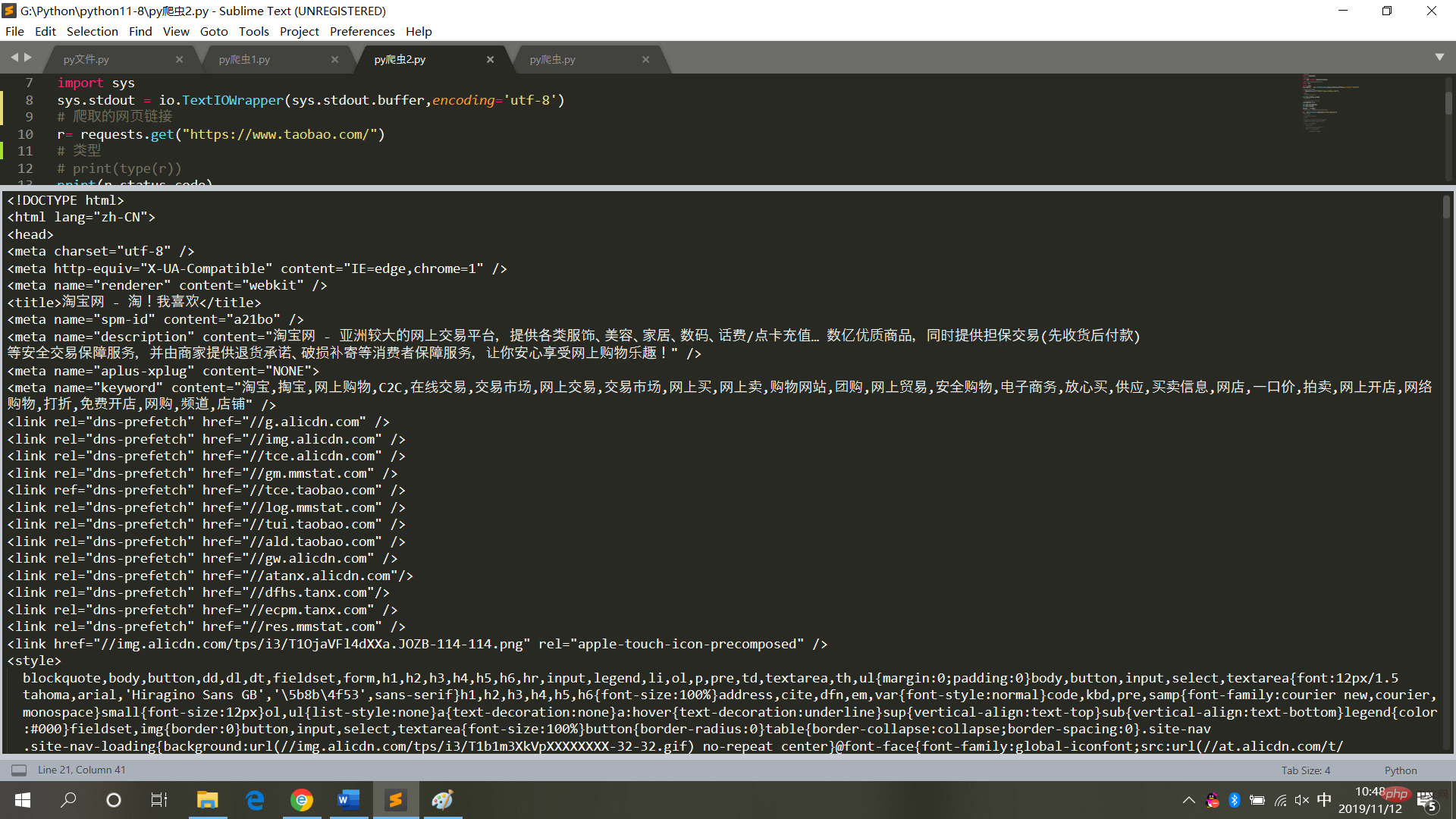
4. 타오바오 홈페이지를 크롤링
# 请求库
import requests
# 用于解决爬取的数据格式化
import io
import sys
sys.stdout = io.TextIOWrapper(sys.stdout.buffer,encoding='utf-8')
# 爬取的网页链接
r= requests.get("https://www.taobao.com/")
# 类型
# print(type(r))
print(r.status_code)
# 中文显示
# r.encoding='utf-8'
r.encoding=None
print(r.encoding)
print(r.text)
result = r.text실행 결과는 다음과 같습니다. 그림
5. 타오바오 홈페이지
# 请求库
import requests
# 解析库
from bs4 import BeautifulSoup
# 用于解决爬取的数据格式化
import io
import sys
sys.stdout = io.TextIOWrapper(sys.stdout.buffer,encoding='utf-8')
# 爬取的网页链接
r= requests.get("https://www.taobao.com/")
# 类型
# print(type(r))
print(r.status_code)
# 中文显示
# r.encoding='utf-8'
r.encoding=None
print(r.encoding)
print(r.text)
result = r.text
# 再次封装,获取具体标签内的内容
bs = BeautifulSoup(result,'html.parser')
# 具体标签
print("解析后的数据")
print(bs.span)
a={}
# 获取已爬取内容中的script标签内容
data=bs.find_all('script')
# 获取已爬取内容中的td标签内容
data1=bs.find_all('td')
# 循环打印输出
for i in data:
a=i.text
print(i.text,end='')
for j in data1:
print(j.text)실행 결과는 그림
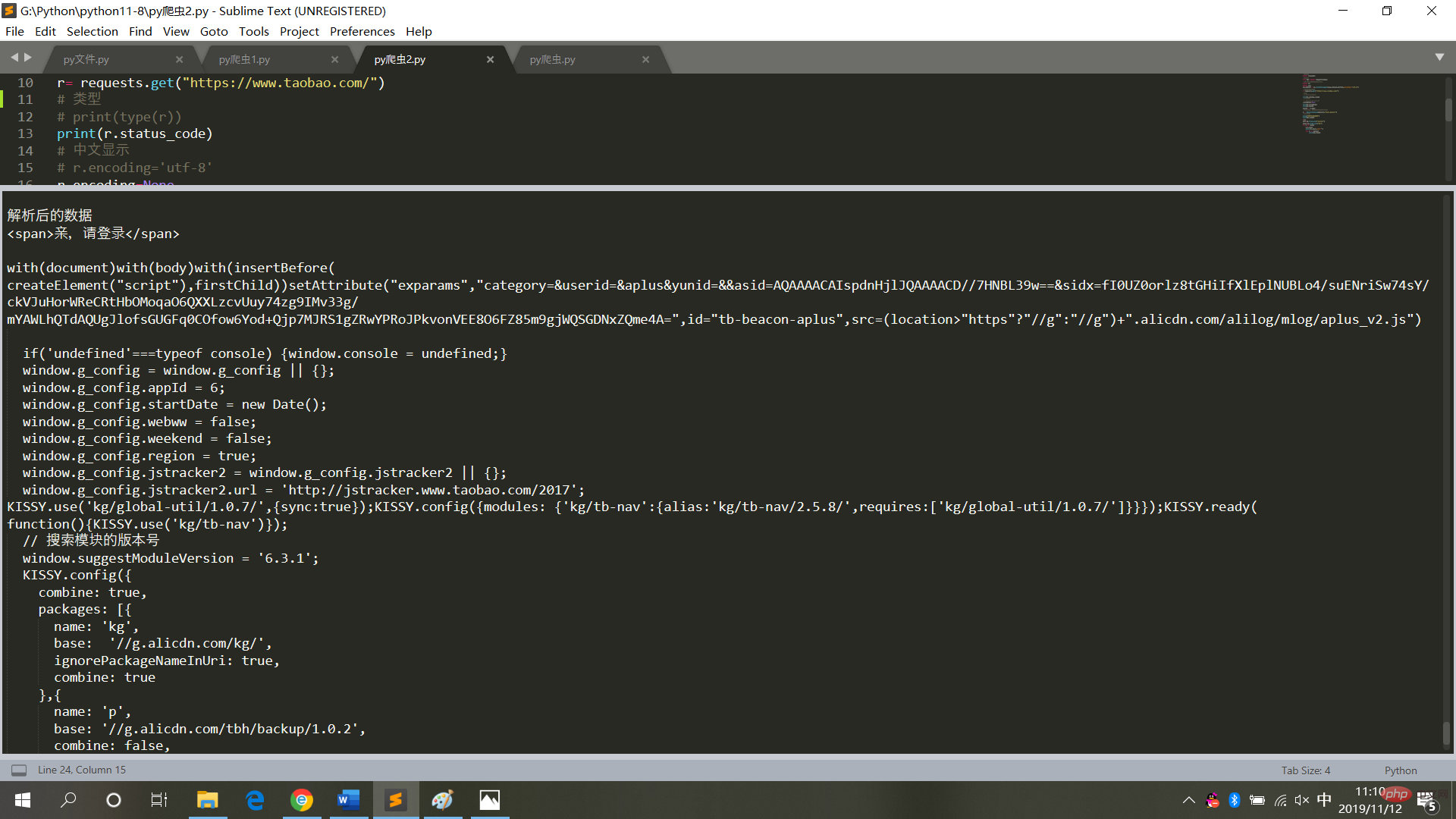
과 같습니다. 6. 웹페이지 코드 크롤링 시에는 동작하지 마세요. 무한 루프 모드로 설정하는 것은 물론 자주(크롤링을 통해 웹 페이지에 액세스할 때마다. 빈번한 작업으로 인해 시스템이 중단되고 법적 책임이 추구됩니다).
그러므로 웹페이지 데이터를 가져온 후 로컬 텍스트 모드로 저장한 다음 구문 분석하세요(더 이상 웹페이지에 액세스할 필요가 없습니다). 【관련 추천:Python3 비디오 튜토리얼
】위 내용은 Python 크롤러는 웹페이지 데이터를 크롤링하고 데이터를 구문 분석합니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7321
7321
 9
1625
14
1349
46
1261
25
1209
29
9
1625
14
1349
46
1261
25
1209
29

 램프 아키텍처에서 Node.js 또는 Python 서비스를 효율적으로 통합하는 방법은 무엇입니까?
Apr 01, 2025 pm 02:48 PM
램프 아키텍처에서 Node.js 또는 Python 서비스를 효율적으로 통합하는 방법은 무엇입니까?
Apr 01, 2025 pm 02:48 PM
많은 웹 사이트 개발자는 램프 아키텍처에서 Node.js 또는 Python 서비스를 통합하는 문제에 직면 해 있습니다. 기존 램프 (Linux Apache MySQL PHP) 아키텍처 웹 사이트 요구 사항 ...
 SCAPY 크롤러를 사용할 때 파이프 라인 영구 스토리지 파일을 작성할 수없는 이유는 무엇입니까?
Apr 01, 2025 pm 04:03 PM
SCAPY 크롤러를 사용할 때 파이프 라인 영구 스토리지 파일을 작성할 수없는 이유는 무엇입니까?
Apr 01, 2025 pm 04:03 PM
SCAPY 크롤러를 사용할 때 파이프 라인 영구 스토리지 파일을 작성할 수없는 이유는 무엇입니까? 토론 Data Crawler에 Scapy Crawler를 사용하는 법을 배울 때 종종 ...
 Python Process Pool이 동시 TCP 요청을 처리하고 클라이언트가 막히게하는 이유는 무엇입니까?
Apr 01, 2025 pm 04:09 PM
Python Process Pool이 동시 TCP 요청을 처리하고 클라이언트가 막히게하는 이유는 무엇입니까?
Apr 01, 2025 pm 04:09 PM
Python Process Pool은 클라이언트가 갇히게하는 동시 TCP 요청을 처리합니다. 네트워크 프로그래밍에 Python을 사용하는 경우 동시 TCP 요청을 효율적으로 처리하는 것이 중요합니다. ...
 Python functools.partial 객체가 내부적으로 캡슐화 한 원래 함수를 보는 방법?
Apr 01, 2025 pm 04:15 PM
Python functools.partial 객체가 내부적으로 캡슐화 한 원래 함수를 보는 방법?
Apr 01, 2025 pm 04:15 PM
functools.partial in Python의 파이썬 funcTools.partial 객체의 시청 방법을 깊이 탐구하십시오 ...
 Linux 터미널에서 Python 버전을 볼 때 발생하는 권한 문제를 해결하는 방법은 무엇입니까?
Apr 01, 2025 pm 05:09 PM
Linux 터미널에서 Python 버전을 볼 때 발생하는 권한 문제를 해결하는 방법은 무엇입니까?
Apr 01, 2025 pm 05:09 PM
Linux 터미널에서 Python 버전을 보려고 할 때 Linux 터미널에서 Python 버전을 볼 때 권한 문제에 대한 솔루션 ... Python을 입력하십시오 ...
 Python Cross-Platform 데스크탑 응용 프로그램 개발 : 어떤 GUI 라이브러리가 가장 적합합니까?
Apr 01, 2025 pm 05:24 PM
Python Cross-Platform 데스크탑 응용 프로그램 개발 : 어떤 GUI 라이브러리가 가장 적합합니까?
Apr 01, 2025 pm 05:24 PM
Python 크로스 플랫폼 데스크톱 응용 프로그램 개발 라이브러리 선택 많은 Python 개발자가 Windows 및 Linux 시스템 모두에서 실행할 수있는 데스크탑 응용 프로그램을 개발하고자합니다 ...
 파이썬 모래시 그래프 그리기 : 가변적 인 정의되지 않은 오류를 피하는 방법?
Apr 01, 2025 pm 06:27 PM
파이썬 모래시 그래프 그리기 : 가변적 인 정의되지 않은 오류를 피하는 방법?
Apr 01, 2025 pm 06:27 PM
Python : 모래 시계 그래픽 도면 및 입력 검증을 시작 하기이 기사는 모래 시계 그래픽 드로잉 프로그램에서 Python 초보자가 발생하는 변수 정의 문제를 해결합니다. 암호...
 파이썬에서 대형 제품 데이터 세트를 효율적으로 계산하고 정렬하는 방법은 무엇입니까?
Apr 01, 2025 pm 08:03 PM
파이썬에서 대형 제품 데이터 세트를 효율적으로 계산하고 정렬하는 방법은 무엇입니까?
Apr 01, 2025 pm 08:03 PM
데이터 변환 및 통계 : 대규모 데이터 세트의 효율적인 처리이 기사는 제품 정보가 포함 된 데이터 목록을 다른 사람으로 변환하는 방법을 자세히 소개합니다 ...
