

MySQL에서 대체(replace into)와 대체(replace into)의 차이점을 분석해 보겠습니다.

이 글은 mysql에 대한 관련 지식을 제공하며, MySQL에서의 대체와 대체의 차이점에 대한 자세한 설명을 주로 소개합니다. 이 글은 모든 사람의 학습이나 작업에 특정 참조 학습 가치가 있는 샘플 코드를 통해 자세히 소개합니다. 그것은 모두에게 도움이 됩니다.

추천 학습: mysql 비디오 튜토리얼
이 기사는 단지 소개일 뿐입니다. 나는 이전에 교체와 교체의 차이점에 주의를 기울인 적이 없습니다. 여러 시나리오에서 테스트한 후 데이터를 삽입할 때 둘 사이의 본질적인 차이점을 찾을 수 없습니까? 혹시 자세한 내용 아시는 분 계시면 메시지 남겨주시면 정말 감사하겠습니다! ! !
0. 이야기의 배경
[테이블 구조]
CREATE TABLE `xtp_algo_white_list` ( `strategy_type` int DEFAULT NULL, `user_name` varchar(64) COLLATE utf8_bin DEFAULT NULL, `status` int DEFAULT NULL, `destroy_at` datetime DEFAULT NULL, `created_at` datetime DEFAULT CURRENT_TIMESTAMP, `updated_at` datetime DEFAULT CURRENT_TIMESTAMP, UNIQUE KEY `xtp_algo_white_list_UN` (`strategy_type`,`user_name`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin # `strategy_type`,`user_name` 这两个是联合唯一索引,多关注后续需要用到!!!
[요구 사항:]
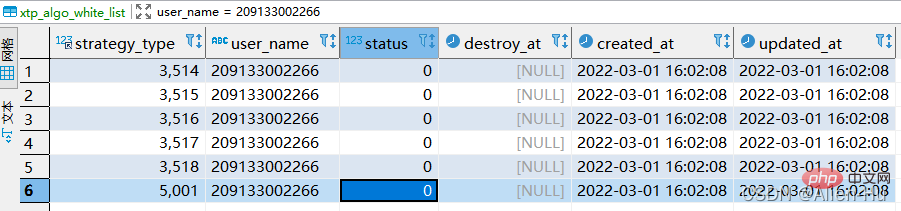
- 테이블에 있는 계정 209133002266의 데이터에 따라 strategy_type 및 status가 되도록 사용자 20220302001을 다시 삽입합니다. 새로 생성된 data & destroy_at 필드는 사용자 209133002266의 필드와 일치합니다.
- 업데이트를 사용하여 하나씩 업데이트하는 것도 가능하지만 속도가 느립니다.
- replace into를 사용하면 효과가 훨씬 높아지지만 심층 조사에 따르면 몇 가지 함정도 있는 것으로 나타났습니다
1. replacement into
replace into xtp_algo_white_list (`strategy_type`, `user_name`, `status`, `destroy_at`) select strategy_type ,20220302001, status, destroy_at from xtp_algo_white_list xawl where xawl.user_name = 209133002266; # replace into 后面跟表格+需要插入的所有字段名(自动递增字段不用写) # select 后面选择的字段,如果根据查询结果取值,则写字段名;如果是写死的,则直接写具体值即可 # 可以理解为,第一部分是插入表格的结构,第二部分是你查询的数据结果
2를 사용하는 방법 —replace into & 그리고 교체 효과
step1 : 1단계 sql을 1회 실행한 상황
replace into xtp_algo_white_list (`strategy_type`, `user_name`, `status`, `destroy_at`) select strategy_type ,20220302001, status, destroy_at from xtp_algo_white_list xawl where xawl.user_name = 209133002266;

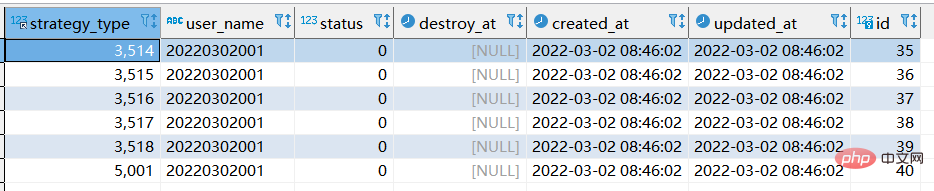
【실행 후 쿼리 결과는 다음과 같습니다.】
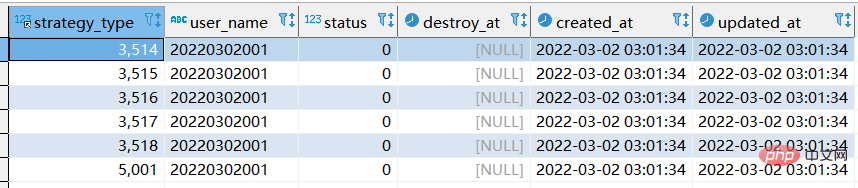
step2 : sql을 두 번째 실행하는 상황

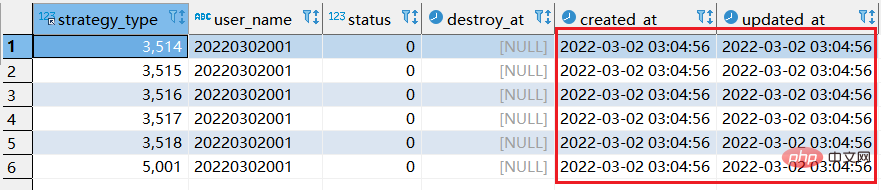
두 번째 실행 시 업데이트된 12행의 데이터가 표시되고 생성된 데이터가 업데이트되는데 처음으로 업데이트된 6행이 표시되는 이유는 무엇인가요? ? ?
1.SQL을 실행할 때 실제로는 두 단계로 교체가 수행되기 때문입니다. 첫 번째 단계는 쿼리 데이터를 새 데이터로 변환하는 것입니다. 두 번째 단계에서는 새 데이터에 이미 테이블에 동일한 내용이 있으면 삭제됩니다. 동일한 내용이 없으면 새로운 데이터가 바로 삽입됩니다.
2. 위의 내용을 처음 실행하면 새로운 데이터가 생성되기 때문에 두 번째 실행 시에는 가장 최근의 데이터가 삽입됩니다.
step3: 세 번째 SQL 실행
# 此时执行的是replace replace xtp_algo_white_list (`strategy_type`, `user_name`, `status`, `destroy_at`) select strategy_type ,20220302001, status, destroy_at from xtp_algo_white_list xawl where xawl.user_name = 209133002266;

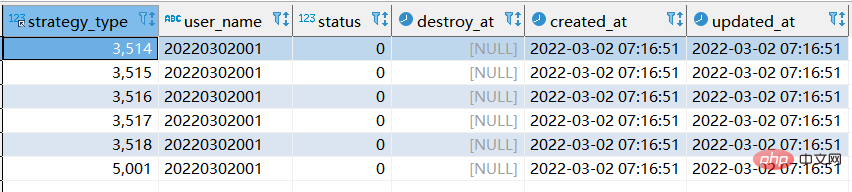
- 최종 상황은 두 번째 SQL 실행과 동일합니다.
- 새 데이터가 이미 존재하는 경우에는 바꾸기와 바꾸기가 동일합니다.
- 이후 20220302001을 모두 삭제하고 SQL을 한 번, 두 번 실행하여 바꾸기와 바꾸기의 효과가 동일한 것을 확인합니다
[요약:] 고유 인덱스 제한이 있는 경우 새로 추가된 데이터가 고유 인덱스에 의해 제한되는 경우 해당 데이터는 한 번만 삽입되며, 이미 존재하는 경우 먼저 삭제한 후 삽입됩니다. 이때, 바꾸기는 바꾸기와 동일한 효과를 갖습니다.
3. 고유 인덱스가 없는 경우 - 교체 및 교체
strategy_type 및 user_name의 공동 고유 인덱스를 삭제하고 20220302001 사용자의 데이터를 모두 삭제합니다. 최종 테이블 구조는 다음과 같습니다.
CREATE TABLE `xtp_algo_white_list` ( `strategy_type` int DEFAULT NULL, `user_name` varchar(64) COLLATE utf8_bin DEFAULT NULL, `status` int DEFAULT NULL, `destroy_at` datetime DEFAULT NULL, `created_at` datetime DEFAULT CURRENT_TIMESTAMP, `updated_at` datetime DEFAULT CURRENT_TIMESTAMP ) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin
1) 교체 함수의 구체적인 상황
step1: sql에 해당하는 다음 교체 실행:
replace xtp_algo_white_list (`strategy_type`, `user_name`, `status`, `destroy_at`) select strategy_type ,20220302001, status, destroy_at from xtp_algo_white_list xawl where xawl.user_name = 209133002266;

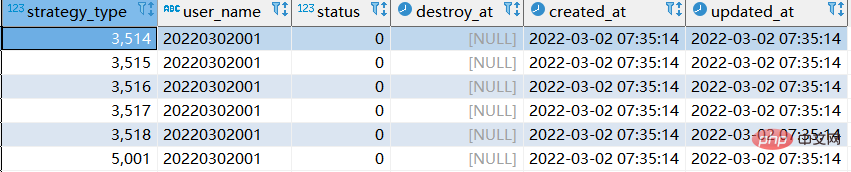
2단계: sql에 해당하는 교체를 다시 실행합니다. :

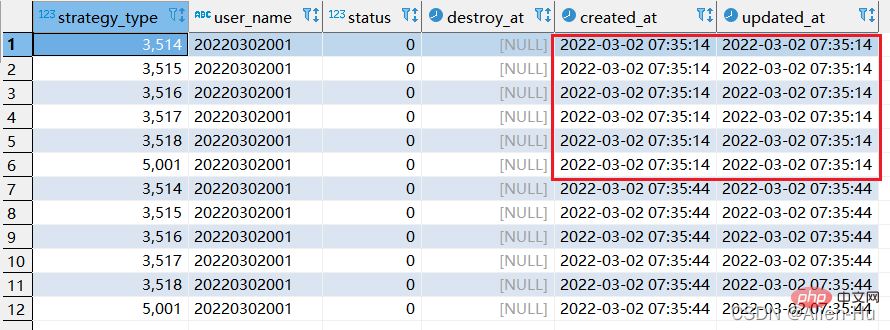
- replace의 두 번째 실행은 sql에 해당합니다. 고유 인덱스 제한이 없으므로 원본 데이터는 변경되지 않습니다. 6개의 새로운 데이터가 재생성되었습니다.
- 나중에 위의 SQL을 실행하면 데이터가 계속해서 늘어납니다
2) .replace into function
의 구체적인 상황
실행 전 먼저 데이터를 정리하고 20220302001
🎜의 데이터를 모두 삭제하세요. sql에 해당하는 다음 교체를 실행합니다. 🎜replace into xtp_algo_white_list (`strategy_type`, `user_name`, `status`, `destroy_at`) select strategy_type ,20220302001, status, destroy_at from xtp_algo_white_list xawl where xawl.user_name = 209133002266;

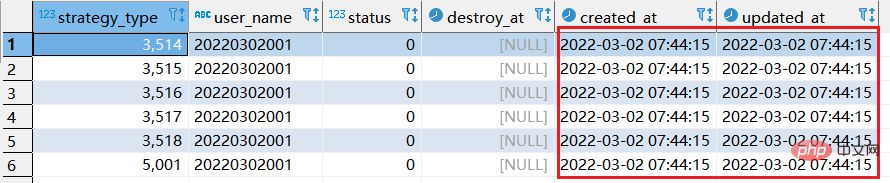
step2:再次执行replace into 对应sql:

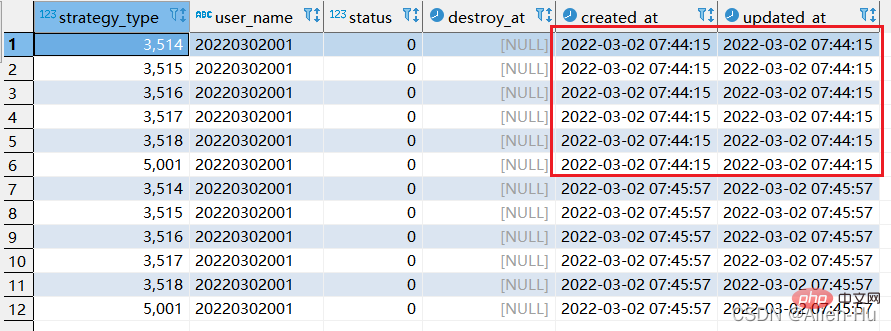
最终发现,没有唯一索引的时候,replace into 与replace 居然一摸一样的效果,都是继续增加数据。
通过以上分析,没看出replace into 与replace 具体有啥区别????有谁知道呢?
4.replace的用法
- 单独replace的作用是替换字段中某数值的显示效果。可以数值中的部分替换、也可以全部替换。
- 如下表格,将user_name的字段,20220302改为"A_20220303"显示,并且新字段叫做new_name显示
select *, replace(user_name,20220302,'A_20220303') as "new_name" from xtp_algo_white_list where user_name = 20220302001;

推荐学习:mysql视频教程
위 내용은 MySQL에서 대체(replace into)와 대체(replace into)의 차이점을 분석해 보겠습니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7486
7486
 15
1377
52
77
11
51
19
19
38
15
1377
52
77
11
51
19
19
38

 MySQL : 초보자를위한 데이터 관리의 용이성
Apr 09, 2025 am 12:07 AM
MySQL : 초보자를위한 데이터 관리의 용이성
Apr 09, 2025 am 12:07 AM
MySQL은 설치가 간단하고 강력하며 데이터를 쉽게 관리하기 쉽기 때문에 초보자에게 적합합니다. 1. 다양한 운영 체제에 적합한 간단한 설치 및 구성. 2. 데이터베이스 및 테이블 작성, 삽입, 쿼리, 업데이트 및 삭제와 같은 기본 작업을 지원합니다. 3. 조인 작업 및 하위 쿼리와 같은 고급 기능을 제공합니다. 4. 인덱싱, 쿼리 최적화 및 테이블 파티셔닝을 통해 성능을 향상시킬 수 있습니다. 5. 데이터 보안 및 일관성을 보장하기위한 지원 백업, 복구 및 보안 조치.
 Navicat에서 데이터베이스 비밀번호를 검색 할 수 있습니까?
Apr 08, 2025 pm 09:51 PM
Navicat에서 데이터베이스 비밀번호를 검색 할 수 있습니까?
Apr 08, 2025 pm 09:51 PM
Navicat 자체는 데이터베이스 비밀번호를 저장하지 않으며 암호화 된 암호 만 검색 할 수 있습니다. 솔루션 : 1. 비밀번호 관리자를 확인하십시오. 2. Navicat의 "비밀번호 기억"기능을 확인하십시오. 3. 데이터베이스 비밀번호를 재설정합니다. 4. 데이터베이스 관리자에게 문의하십시오.
 Navicat Premium을 만드는 방법
Apr 09, 2025 am 07:09 AM
Navicat Premium을 만드는 방법
Apr 09, 2025 am 07:09 AM
Navicat Premium을 사용하여 데이터베이스 생성 : 데이터베이스 서버에 연결하고 연결 매개 변수를 입력하십시오. 서버를 마우스 오른쪽 버튼으로 클릭하고 데이터베이스 생성을 선택하십시오. 새 데이터베이스의 이름과 지정된 문자 세트 및 Collation의 이름을 입력하십시오. 새 데이터베이스에 연결하고 객체 브라우저에서 테이블을 만듭니다. 테이블을 마우스 오른쪽 버튼으로 클릭하고 데이터 삽입을 선택하여 데이터를 삽입하십시오.
 MySQL : 쉽게 학습하기위한 간단한 개념
Apr 10, 2025 am 09:29 AM
MySQL : 쉽게 학습하기위한 간단한 개념
Apr 10, 2025 am 09:29 AM
MySQL은 오픈 소스 관계형 데이터베이스 관리 시스템입니다. 1) 데이터베이스 및 테이블 작성 : CreateAbase 및 CreateTable 명령을 사용하십시오. 2) 기본 작업 : 삽입, 업데이트, 삭제 및 선택. 3) 고급 운영 : 가입, 하위 쿼리 및 거래 처리. 4) 디버깅 기술 : 확인, 데이터 유형 및 권한을 확인하십시오. 5) 최적화 제안 : 인덱스 사용, 선택을 피하고 거래를 사용하십시오.
 MariaDB 용 Navicat에서 데이터베이스 비밀번호를 보는 방법은 무엇입니까?
Apr 08, 2025 pm 09:18 PM
MariaDB 용 Navicat에서 데이터베이스 비밀번호를 보는 방법은 무엇입니까?
Apr 08, 2025 pm 09:18 PM
MariaDB 용 Navicat은 암호가 암호화 된 양식으로 저장되므로 데이터베이스 비밀번호를 직접 볼 수 없습니다. 데이터베이스 보안을 보장하려면 비밀번호를 재설정하는 세 가지 방법이 있습니다. Navicat을 통해 비밀번호를 재설정하고 복잡한 비밀번호를 설정하십시오. 구성 파일을 봅니다 (권장되지 않음, 위험이 높음). 시스템 명령 줄 도구를 사용하십시오 (권장되지 않으면 명령 줄 도구에 능숙해야 함).
 Navicat에서 SQL을 실행하는 방법
Apr 08, 2025 pm 11:42 PM
Navicat에서 SQL을 실행하는 방법
Apr 08, 2025 pm 11:42 PM
Navicat에서 SQL을 수행하는 단계 : 데이터베이스에 연결하십시오. SQL 편집기 창을 만듭니다. SQL 쿼리 또는 스크립트를 작성하십시오. 실행 버튼을 클릭하여 쿼리 또는 스크립트를 실행하십시오. 결과를 봅니다 (쿼리가 실행 된 경우).
 Navicat에서 MySQL에 새로운 연결을 만드는 방법
Apr 09, 2025 am 07:21 AM
Navicat에서 MySQL에 새로운 연결을 만드는 방법
Apr 09, 2025 am 07:21 AM
응용 프로그램을 열고 새로운 연결 (Ctrl n)을 선택하여 Navicat에서 새로운 MySQL 연결을 만들 수 있습니다. "MySQL"을 연결 유형으로 선택하십시오. 호스트 이름/IP 주소, 포트, 사용자 이름 및 비밀번호를 입력하십시오. (선택 사항) 고급 옵션을 구성합니다. 연결을 저장하고 연결 이름을 입력하십시오.
 MySQL 및 SQL : 개발자를위한 필수 기술
Apr 10, 2025 am 09:30 AM
MySQL 및 SQL : 개발자를위한 필수 기술
Apr 10, 2025 am 09:30 AM
MySQL 및 SQL은 개발자에게 필수적인 기술입니다. 1.MySQL은 오픈 소스 관계형 데이터베이스 관리 시스템이며 SQL은 데이터베이스를 관리하고 작동하는 데 사용되는 표준 언어입니다. 2.MYSQL은 효율적인 데이터 저장 및 검색 기능을 통해 여러 스토리지 엔진을 지원하며 SQL은 간단한 문을 통해 복잡한 데이터 작업을 완료합니다. 3. 사용의 예에는 기본 쿼리 및 조건 별 필터링 및 정렬과 같은 고급 쿼리가 포함됩니다. 4. 일반적인 오류에는 구문 오류 및 성능 문제가 포함되며 SQL 문을 확인하고 설명 명령을 사용하여 최적화 할 수 있습니다. 5. 성능 최적화 기술에는 인덱스 사용, 전체 테이블 스캔 피하기, 조인 작업 최적화 및 코드 가독성 향상이 포함됩니다.
