


추천 학습: mysql 비디오 튜토리얼
REDO LOG는 MySQL 서버가 예기치 않게 충돌하거나 다운될 때 제출된 트랜잭션이 디스크에 유지되도록 보장합니다(지속성). .
InnoDB는 페이지 단위로 레코드를 연산하며, 추가, 삭제, 수정 및 쿼리를 수행하면 전체 페이지가 버퍼 풀(디스크 -> 메모리)에 로드됩니다. 트랜잭션의 수정 작업은 디스크의 데이터를 직접 수정하지 않습니다. 먼저 메모리의 버퍼 풀에 있는 데이터가 정기적인 간격으로 백그라운드 스레드에 의해 디스크에 비동기적으로 새로 고쳐집니다.
버퍼 풀: 인덱스와 데이터를 저장하고, 읽기 및 쓰기 속도를 높이고, 메모리에서 데이터 페이지를 직접 조작할 수 있으며, 버퍼 풀의 더티 페이지를 디스크에 쓰는 전용 스레드가 있습니다.
디스크의 데이터를 직접 수정하면 어떨까요?
디스크 데이터를 직접 수정하는 경우에는 랜덤 IO이기 때문에 수정된 데이터는 디스크의 여러 위치에 분산되어 있어 앞뒤로 검색해야 하기 때문에 적중률이 낮고 게다가 소모량이 높습니다. , 약간의 수정으로 전체 페이지를 교체해야 합니다. 디스크에 플러시하면 활용도가 낮습니다.
이에 비해 순차 IO는 디스크 데이터가 디스크 한 부분에 분산되므로 검색 프로세스가 생략되고 탐색 시간이 걸립니다. 저장되었습니다.
백그라운드 스레드를 사용하여 특정 빈도로 디스크를 새로 고치면 임의 IO의 빈도를 줄이고 처리량을 늘릴 수 있습니다. 이것이 버퍼 풀을 사용하는 근본적인 이유입니다.
메모리를 수정한 후 디스크에 비동기적으로 동기화하는 문제:
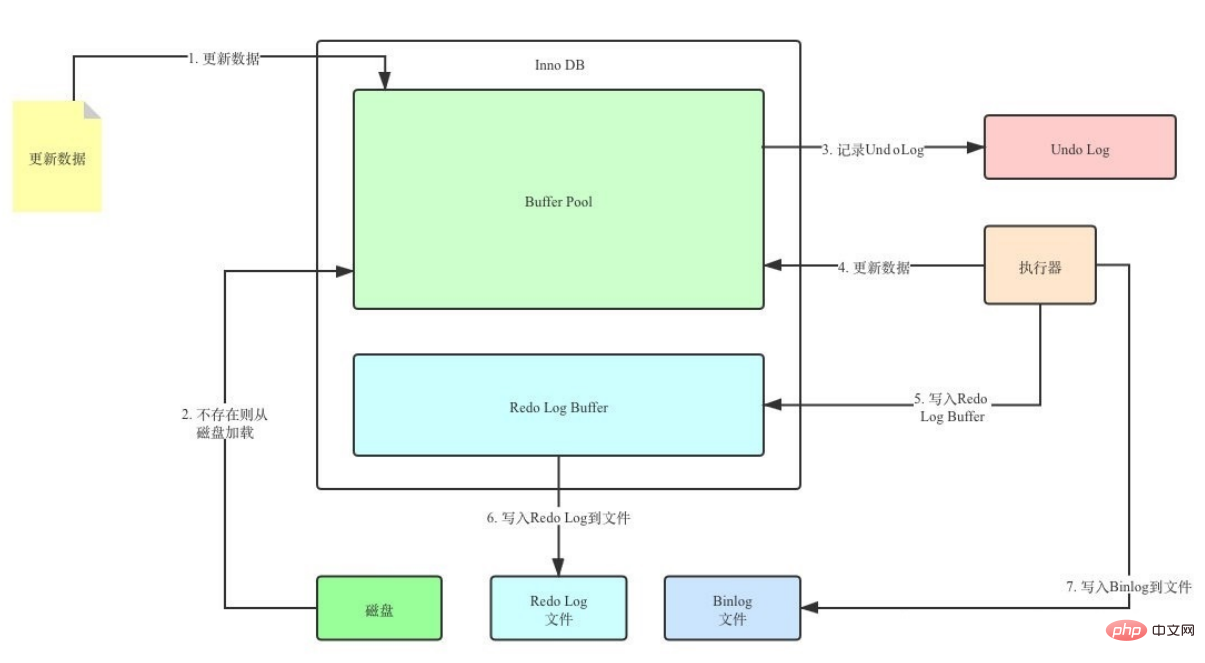
버퍼 풀은 메모리의 영역이므로 시스템이 예기치 않게 충돌하면 일부 더티 데이터가 새로 고쳐지지 않을 수 있습니다. 제때에 디스크가 삭제되고 거래의 내구성이 보장되지 않습니다. 따라서 리두 로그가 도입되었습니다. 데이터 수정 시 xx 페이지의 xx 오프셋이 xx만큼 변경되었음을 알리는 추가 로그가 기록됩니다. 시스템 충돌 시 로그 내용을 기반으로 복구할 수 있습니다.
로그 쓰기와 디스크 새로 고침의 차이점은 다음과 같습니다. 로그 쓰기는 추가 쓰기, 순차 IO, 속도가 빠르고 기록된 내용이 상대적으로 작습니다.
redo 로그는 두 부분으로 구성됩니다.
수정 작업의 일반 프로세스:
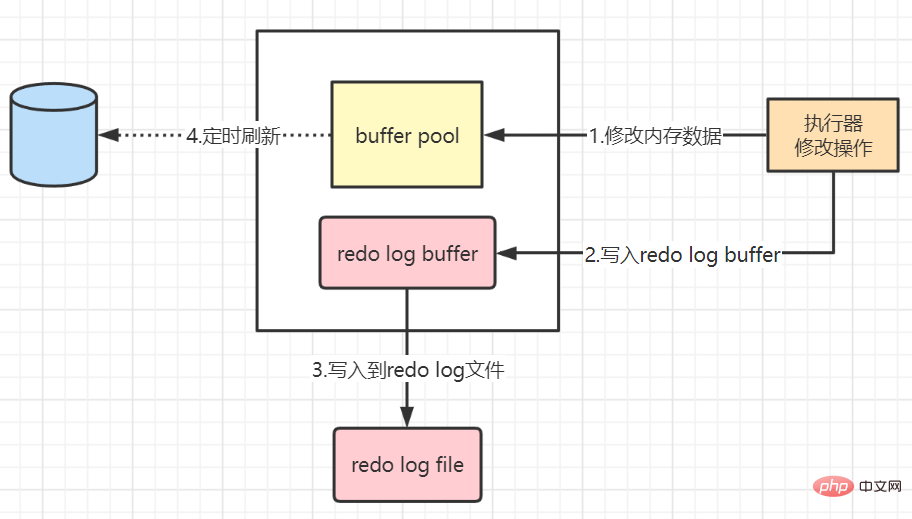
1단계: 먼저 디스크에서 원본 데이터를 읽습니다. 메모리에 데이터의 메모리 복사본을 수정하고 더티 데이터를 생성합니다
2단계: 리두 로그를 생성하고 이를 리두 로그 버퍼에 씁니다. 그러면 데이터의 수정된 값이 기록됩니다.
3단계: 기본적으로 제출 후 리두 로그 버퍼의 내용을 리두 로그 파일에 새로 고치고 리두 로그 파일에 추가 쓰기를 사용합니다
4단계: 메모리의 수정된 데이터를 정기적으로 디스크에 새로 고칩니다. 시간 내에 업데이트되지 않은 데이터에 대해 백그라운드 스레드에 의해 플러시되는 더티 데이터)
일반적으로 미리 쓰기 로그(사전 로그 지속성)라고 하는 것은 데이터 페이지를 유지하기 전에 해당 로그 페이지를 메모리에 유지하는 것을 의미합니다.
리두 로그의 이점:
리두 로그가 트랜잭션의 내구성을 확실히 보장할 수 있습니까?
반드시 그런 것은 아니지만 이는 리두 로그 버퍼도 메모리에 있기 때문에 리두 로그 플러시 전략에 따라 다릅니다. 트랜잭션이 제출된 후 리두 로그 버퍼가 지속성을 위해 리두 로그 파일에 데이터를 새로 고칠 시간이 없습니다. . 현재로서는 가동 중지 시간이 발생해도 데이터가 손실됩니다. 어떻게 해결하나요? 스윕 전략.
InnoDB는 리두 로그 버퍼가 리두 로그 파일로 플러시되는 시기를 제어하기 위해 innodb_flush_log_at_trx_commit 매개변수에 대한 세 가지 전략을 제공합니다.
값이 0인 경우:
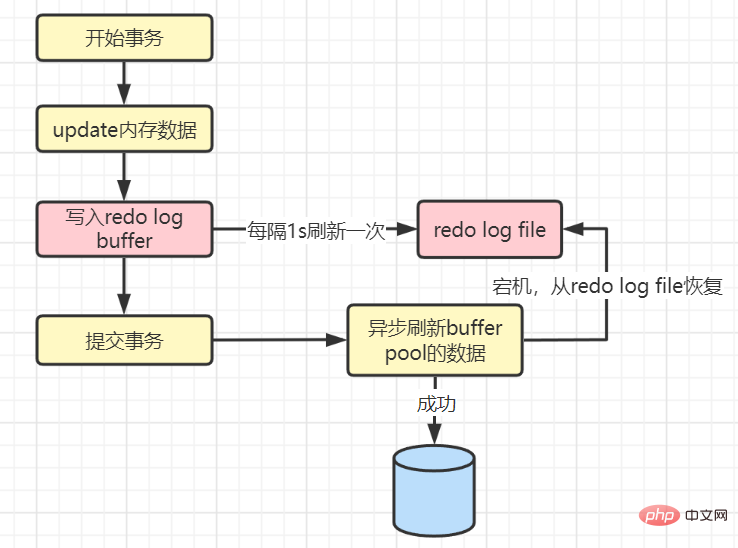
1초 간격이 있기 때문에 1초의 데이터가 손실됩니다. 최악의 경우.
값이 1인 경우:
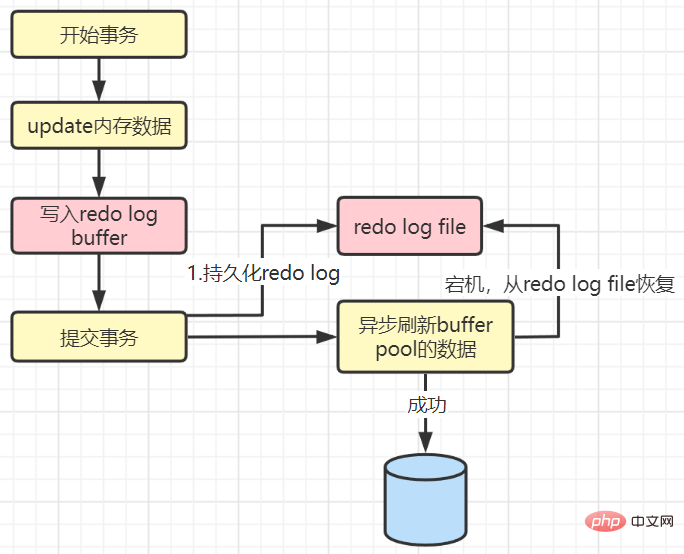
커밋할 때 리두 로그 버퍼를 리두 로그 파일로 적극적으로 새로 고쳐야 합니다. 컴퓨터가 중간에 충돌하면 손실 없이 트랜잭션이 실패하며 트랜잭션의 내구성이 진정으로 보장될 수 있습니다. 하지만 효율성은 최악이다.
값이 2인 경우: OS에 따라 결정됩니다.
트랜잭션 성능을 향상시키기 위해 0 또는 2로 조정할 수 있지만 ACID 특성이 손실됩니다
undo 로그는 트랜잭션의 원자성과 일관성을 보장하는 데 사용됩니다. 두 가지 기능을 가지고 있습니다. ① 롤백 작업 제공 ② 다중 버전 제어 MVVC
Rollback 작업
앞서 Redo 로그에서 언급했듯이 백그라운드 스레드는 버퍼 풀에 있는 데이터를 수시로 디스크에 새로 고치지만, 이 기간 동안 다양한 오류(다운타임)가 발생하거나 롤백 문이 실행된 다음 이전에 브러싱된 작업을 롤백하여 원자성을 보장해야 합니다. 실행 취소 로그는 트랜잭션 롤백을 제공합니다.
MVVC
읽기 행이 다른 트랜잭션에 의해 잠긴 경우 실행 취소 로그에서 해당 행에 기록된 이전 데이터 버전을 분석할 수 있으므로 사용자는 현재 트랜잭션 작업 이전에 데이터를 읽을 수 있습니다. — —스냅샷 읽기.
스냅샷 읽기: SQL에서 읽은 데이터는 기록 버전이며 잠금이 필요하지 않으며 일반 SELECT는 스냅샷 읽기입니다.
실행 취소 로그 구성 요소:
선택 작업은 실행 취소 로그를 생성하지 않습니다
InnoDB 스토리지 엔진에서 실행 취소 로그는 롤백 세그먼트 롤백 세그먼트를 사용하여 저장하며 각 롤백 세그먼트에는 1024개의 실행 취소 로그 세그먼트가 포함됩니다. MySQL5.5 이후에는 총 128개의 롤백 세그먼트가 있습니다. 즉, 총 128*1024번의 실행 취소 작업을 기록할 수 있습니다.
각 트랜잭션은 하나의 롤백 세그먼트만 사용하며 하나의 롤백 세그먼트는 동시에 여러 트랜잭션을 제공할 수 있습니다.
실행 취소 로그는 트랜잭션이 제출된 후 즉시 삭제할 수 없습니다. 일부 트랜잭션에서는 이전 데이터 버전을 읽고 싶을 수도 있습니다(스냅샷 읽기). 따라서 트랜잭션이 커밋되면 실행 취소 로그는 버전 체인이라는 연결된 목록에 저장됩니다. 실행 취소 로그의 삭제 여부는 제거라는 스레드에 의해 판단됩니다.
undo 로그는 다음과 같이 구분됩니다.
insert undo log
삽입 작업 기록은 트랜잭션 자체에만 표시되고 다른 트랜잭션에는 표시되지 않기 때문에(트랜잭션 격리의 요구 사항) undo는 로그는 트랜잭션이 커밋된 후 직접 삭제할 수 있습니다. 퍼지 작업이 필요하지 않습니다.
update undo log
update undo log는 삭제 및 업데이트 작업으로 생성된 실행 취소 로그를 기록합니다. 실행 취소 로그는 MVCC 메커니즘을 제공해야 할 수 있으므로 트랜잭션이 커밋될 때 삭제할 수 없습니다. 제출할 때 실행 취소 로그 목록에 넣고 퍼지 스레드가 최종 삭제를 수행할 때까지 기다립니다.
A=1, B=2라는 2개의 값이 있고 트랜잭션이 A를 3으로, B를 4로 수정한다고 가정합니다. 수정 프로세스는 다음과 같이 단순화될 수 있습니다.
1 . 시작
2.기록 A=1을 기록해 로그
3.업데이트 A=3
4.기록 A=3을 기록해 로그
5.기록 B=2를 기록해 로그
6.업데이트 B=4
7.기록 B =4 - 재실행 로그
8. 디스크에 재실행 로그 새로 고침
9.commit
InnoDB 엔진의 경우 레코드 자체의 데이터 외에도 각 행 레코드에는 여러 개의 숨겨진 열이 있습니다.

INSERT를 실행할 때:
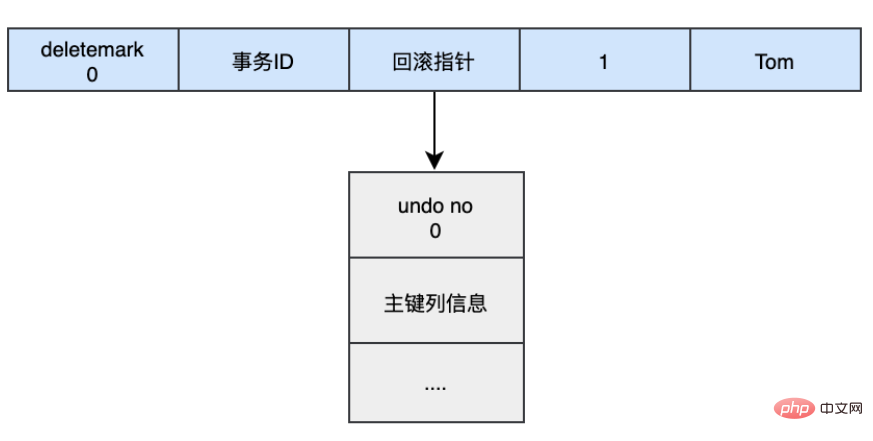
begin; INSERT INTO user (name) VALUES ('tom');
삽입된 데이터는 삽입 취소 로그를 생성하고 데이터의 롤백 포인터가 이를 가리킵니다. Undo 로그에는 Undo 로그의 일련번호, 삽입된 기본 키의 열과 값이 기록됩니다. 그러면 롤백 수행 시 기본 키를 통해 해당 데이터를 직접 삭제할 수 있습니다.
UPDATE를 실행할 때:
업데이트된 작업에 대해 업데이트 실행 취소 로그가 생성되며, 지금 실행한다고 가정하면 기본 키를 업데이트하는 로그와 기본 키를 업데이트하지 않는 로그로 구분됩니다.
UPDATE user SET name='Sun' WHERE id=1;
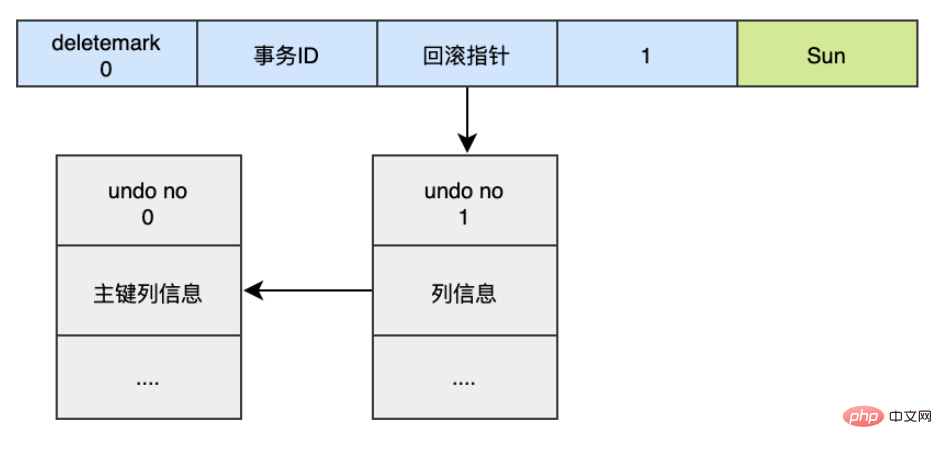
이때 새 로그가 생성됩니다. 실행 취소 로그 기록이 버전 체인에 추가되고 해당 실행 취소 번호는 1이며 새 실행 취소 로그의 롤백 포인터는 이전 실행 취소 로그( 실행 취소 번호=0).
지금 실행한다고 가정해 보겠습니다.
UPDATE user SET id=2 WHERE id=1;
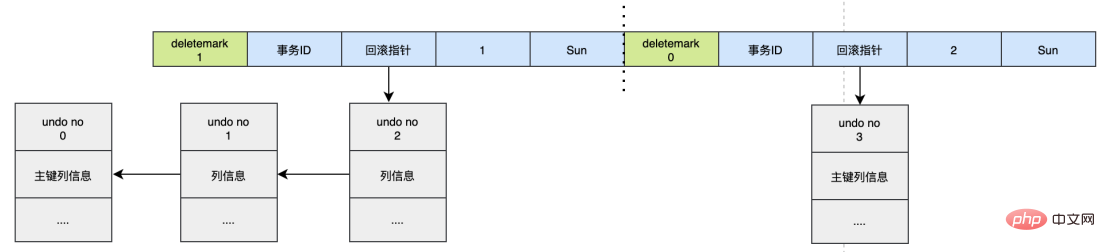
기본 키 업데이트 작업의 경우 원본 데이터 deletemark 플래그가 먼저 열립니다. 이때 데이터는 실제로 삭제되지 않습니다. 나중에 새로운 데이터가 삽입되면 새 데이터도 실행 취소 로그를 생성하고 실행 취소 로그의 시퀀스 번호가 증가합니다.
데이터가 변경될 때마다 실행 취소 로그가 생성되는 것을 확인할 수 있습니다. 레코드가 여러 번 변경되면 실행 취소 로그가 여러 개 생성되며, 실행 취소 로그는 변경 전의 로그를 기록하며, 각 실행 취소 로그의 시퀀스 번호는 증가합니다. , 롤백하고 싶을 때 시퀀스 번호에 따라 앞으로 밀어서 원본 데이터를 찾으세요.
위의 예에서 롤백이 수행되었다고 가정하면 해당 프로세스는 다음과 같습니다.
1 undo no=3의 로그를 통해 id=2인 데이터를 삭제합니다
2 . undo no=2의 로그를 통해 id=1인 데이터의 deletemark를 0으로 복원합니다. 3. undo no=1의 로그를 통해 id=1인 데이터의 이름을 Tom에게 복원합니다. undo no=를 통해 id=1인 데이터를 Tom에게 보냅니다. 0의 로그는 id=1인 데이터를 삭제합니다.
MySQL MVVC 다중 버전 동시성 제어
확장
bin log
show variables like '%log_bin%';
mysqlbinlog -v "/var/lib/mysql/binlog/xxx.000002"
mysqlbinlog [option] filename|mysql –uuser -ppass;
바이너리 로그 삭제:
PURGE {MASTER | BINARY} LOGS TO ‘指定日志文件名'
PURGE {MASTER | BINARY} LOGS BEFORE ‘指定日期'쓰기 타이밍
트랜잭션 실행 중에 로그는 먼저 bin 로그 캐시에 기록됩니다. 트랜잭션이 제출되면 binlog 캐시를 binlog 파일에 씁니다. 트랜잭션의 binlog는 분할할 수 없기 때문에 트랜잭션의 크기에 관계없이 한 번만 작성해야 하므로 시스템은 각 스레드에 메모리 블록을 binlog 캐시로 할당합니다.
binlog와 redo 로그의 비교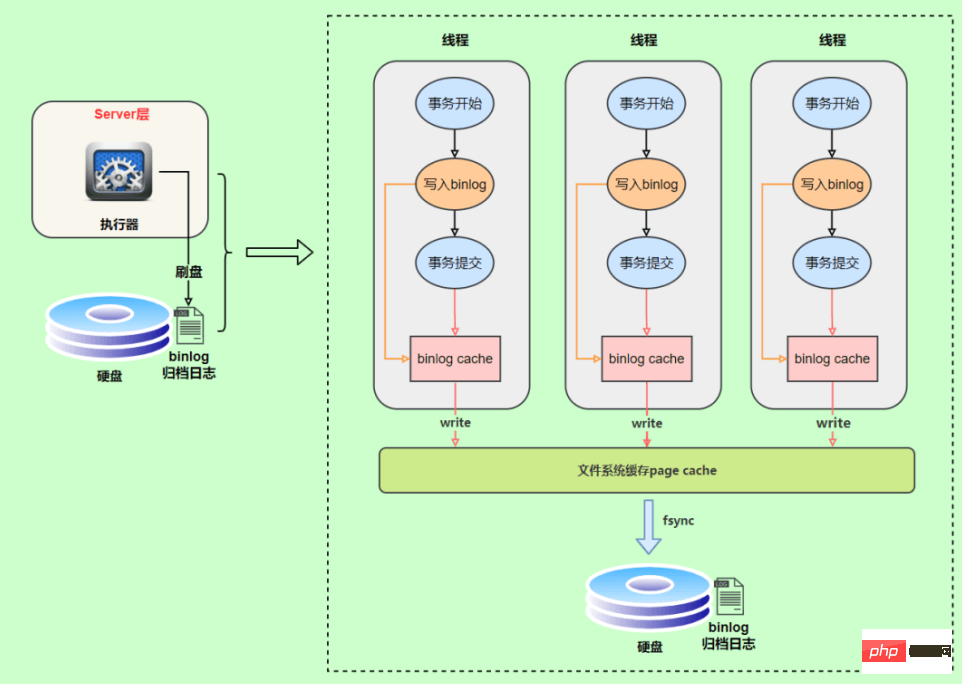
업데이트 문이 실행되는 동안 redo 로그와 binlog 두 개의 로그가 기록됩니다. 기본 트랜잭션을 기반으로 redo 로그는 트랜잭션 실행 중에 지속적으로 기록될 수 있지만 binlog는 로그만 기록됩니다. 트랜잭션이 제출될 때 기록되므로 redo 로그와 binlog의 작성 시점이 다릅니다.
리두 로그와 binlog 사이의 논리가 일치하지 않습니다. 어떤 문제가 발생하나요?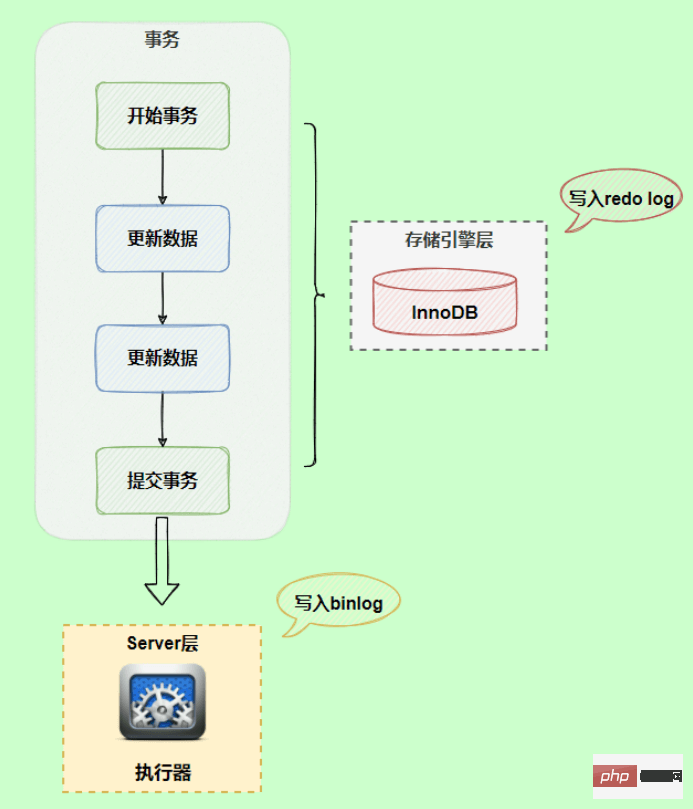 업데이트 문을 예로 들어 보겠습니다. id=2인 레코드의 경우 필드 c 값이 0이라고 가정합니다. 필드 c 값을 1로 업데이트합니다. SQL 문은 update T set c=1 where id=2입니다.
업데이트 문을 예로 들어 보겠습니다. id=2인 레코드의 경우 필드 c 값이 0이라고 가정합니다. 필드 c 값을 1로 업데이트합니다. SQL 문은 update T set c=1 where id=2입니다.
실행 과정에서 redo 로그를 작성한 후, binlog 로그 작성 중에 예외가 발생한다고 가정하면, 어떻게 될까요?
binlog가 작성이 완료되기 전에 이상하므로 해당 수정 기록이 없습니다. 현재 binlog에 있습니다. 따라서 binlog 로그를 사용하여 데이터를 복원하거나 슬레이브가 마스터의 binlog를 읽을 때 이 업데이트는 복원된 행의 c 값이 0인 반면 원본 데이터베이스에서는 redo 로그 복원으로 인해 c 값이 생략됩니다. 이 행의 값은 1입니다. 최종 데이터가 일치하지 않습니다.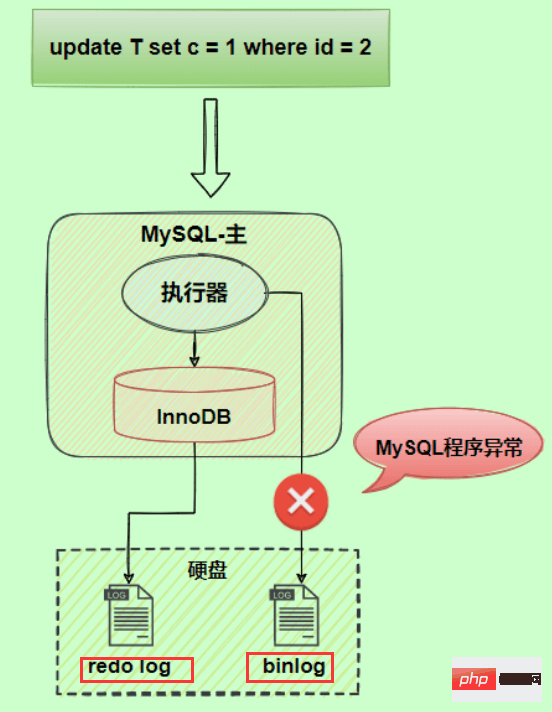
두 로그 간의 논리적 일관성 문제를 해결하기 위해 InnoDB 스토리지 엔진은 2단계 커밋 방식을 사용합니다. 리두 로그를 준비와 커밋의 두 단계로 나눕니다. 이는 2단계 커밋입니다.
최종 제출된 리두 로그와 bin 로그를 함께 바인딩하도록 합니다. 앞서 언급한 것처럼 트랜잭션이 커밋되면 기본적으로 커밋이 성공하기 전에 리두 로그를 동기화해야 하므로 함께 바인딩하면 bin 로그에도 이 기능이 있어 데이터가 손실되지 않도록 보장합니다.
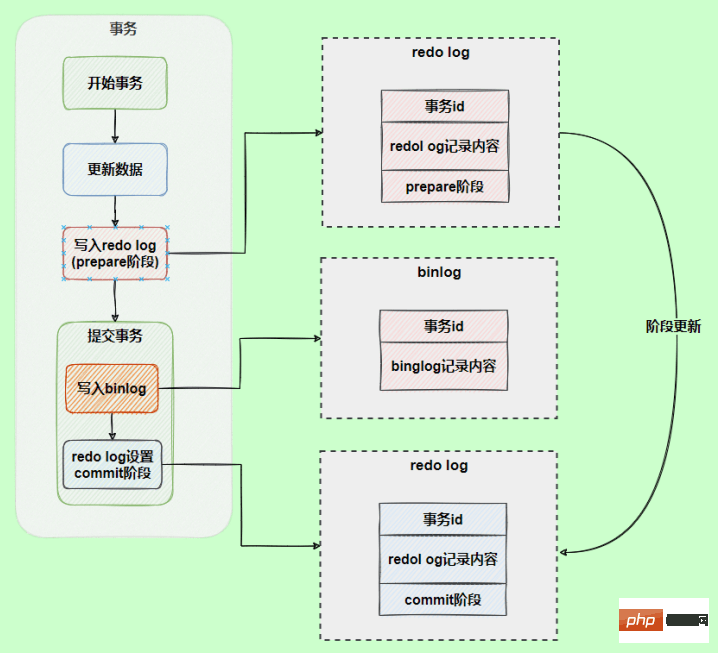
2단계 커밋을 사용한 후, binlog를 작성할 때 예외가 발생하더라도 아무런 영향이 없습니다. MySQL이 리두 로그를 기반으로 데이터를 복원할 때 리두 로그가 여전히 준비 단계에 있음을 발견하기 때문입니다. 해당 binlog 로그가 없으므로 제출이 실패하면 데이터를 롤백합니다.
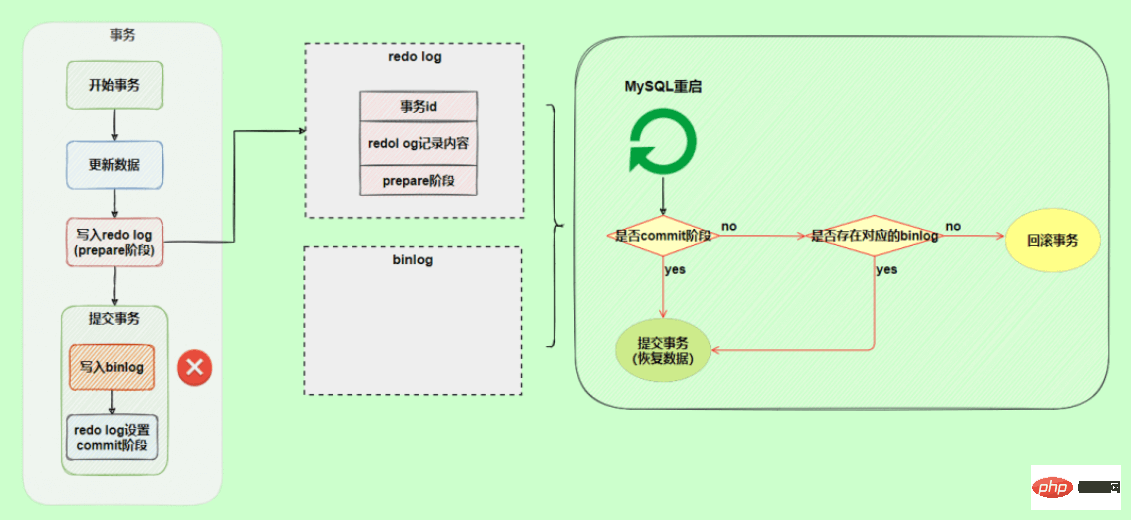
또 다른 시나리오에서는 다시 실행 로그의 커밋 단계 중에 예외가 발생합니다. 트랜잭션이 롤백되나요?
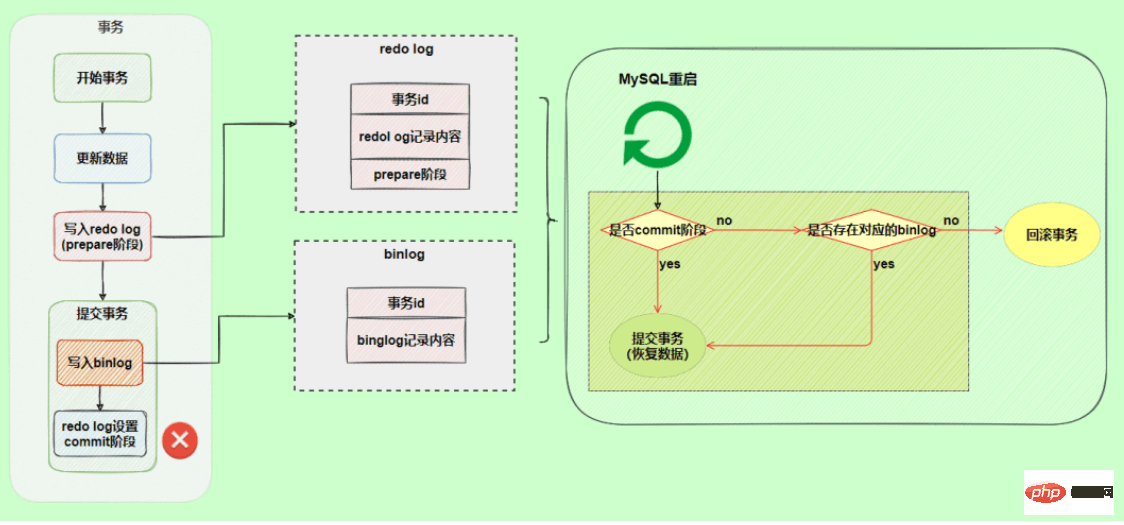
트랜잭션을 롤백하지 않고 위 그림에 프레임된 로직을 실행합니다. 리두 로그는 준비 단계이지만 트랜잭션 ID를 통해 해당 binlog 로그를 찾을 수 있으므로 MySQL에서는 이를 다음과 같이 간주합니다. 데이터를 복원하려면 트랜잭션을 커밋하세요.
추천 학습: mysql 비디오 튜토리얼
위 내용은 MySQL 로그의 특별한 배열: 다시 실행 로그 및 실행 취소 로그의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



