

Python을 사용하여 KNN 분류 알고리즘 처리


【相关推荐:Python3视频教程 】
KNN分类算法的介绍
KNN分类算法(K-Nearest-Neighbors Classification),又叫K近邻算法,是一个概念极其简单,而分类效果又很优秀的分类算法。
他的核心思想就是,要确定测试样本属于哪一类,就寻找所有训练样本中与该测试样本“距离”最近的前K个样本,然后看这K个样本大部分属于哪一类,那么就认为这个测试样本也属于哪一类。简单的说就是让最相似的K个样本来投票决定。
这里所说的距离,一般最常用的就是多维空间的欧式距离。这里的维度指特征维度,即样本有几个特征就属于几维。
KNN示意图如下所示。(图片来源:百度百科)
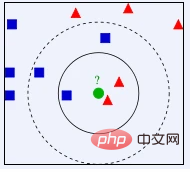
上图中要确定测试样本绿色属于蓝色还是红色。
显然,当K=3时,将以1:2的投票结果分类于红色;而K=5时,将以3:2的投票结果分类于蓝色。
KNN算法简单有效,但没有优化的暴力法效率容易达到瓶颈。如样本个数为N,特征维度为D的时候,该算法时间复杂度呈O(DN)增长。
所以通常KNN的实现会把训练数据构建成K-D Tree(K-dimensional tree),构建过程很快,甚至不用计算D维欧氏距离,而搜索速度高达O(D*log(N))。
不过当D维度过高,会产生所谓的”维度灾难“,最终效率会降低到与暴力法一样。
因此通常D>20以后,最好使用更高效率的Ball-Tree,其时间复杂度为O(D*log(N))。
人们经过长期的实践发现KNN算法虽然简单,但能处理大规模的数据分类,尤其适用于样本分类边界不规则的情况。最重要的是该算法是很多高级机器学习算法的基础。
当然,KNN算法也存在一切问题。比如如果训练数据大部分都属于某一类,投票算法就有很大问题了。这时候就需要考虑设计每个投票者票的权重了。
测试数据
测试数据的格式仍然和前面使用的身高体重数据一致。不过数据稍微增加了一些
1.5 40 thin 1.5 50 fat 1.5 60 fat 1.6 40 thin 1.6 50 thin 1.6 60 fat 1.6 70 fat 1.7 50 thin 1.7 60 thin 1.7 70 fat 1.7 80 fat 1.8 60 thin 1.8 70 thin 1.8 80 fat 1.8 90 fat 1.9 80 thin 1.9 90 fat
Python代码实现
scikit-learn提供了优秀的KNN算法支持。
import numpy as np
from sklearn import neighbors
from sklearn.metrics import precision_recall_curve
from sklearn.metrics import classification_report
from sklearn.cross_validation import train_test_split
import matplotlib.pyplot as plt
''' 数据读入 '''
data = []
labels = []
with open("data\\1.txt") as ifile:
for line in ifile:
tokens = line.strip().split(' ')
data.append([float(tk) for tk in tokens[:-1]])
labels.append(tokens[-1])
x = np.array(data)
labels = np.array(labels)
y = np.zeros(labels.shape)
''' 标签转换为0/1 '''
y[labels=='fat']=1
''' 拆分训练数据与测试数据 '''
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size = 0.2)
''' 创建网格以方便绘制 '''
h = .01
x_min, x_max = x[:, 0].min() - 0.1, x[:, 0].max() + 0.1
y_min, y_max = x[:, 1].min() - 1, x[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, h),
np.arange(y_min, y_max, h))
''' 训练KNN分类器 '''
clf = neighbors.KNeighborsClassifier(algorithm='kd_tree')
clf.fit(x_train, y_train)
'''测试结果的打印'''
answer = clf.predict(x)
print(x)
print(answer)
print(y)
print(np.mean( answer == y))
'''准确率与召回率'''
precision, recall, thresholds = precision_recall_curve(y_train, clf.predict(x_train))
answer = clf.predict_proba(x)[:,1]
print(classification_report(y, answer, target_names = ['thin', 'fat']))
''' 将整个测试空间的分类结果用不同颜色区分开'''
answer = clf.predict_proba(np.c_[xx.ravel(), yy.ravel()])[:,1]
z = answer.reshape(xx.shape)
plt.contourf(xx, yy, z, cmap=plt.cm.Paired, alpha=0.8)
''' 绘制训练样本 '''
plt.scatter(x_train[:, 0], x_train[:, 1], c=y_train, cmap=plt.cm.Paired)
plt.xlabel(u'身高')
plt.ylabel(u'体重')
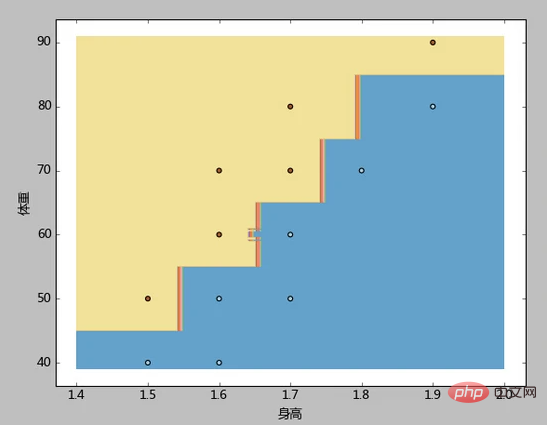
plt.show()结果分析
输出结果:
[ 0. 0. 1. 0. 0. 1. 1. 0. 0. 1. 1. 0. 0. 1. 1. 0. 1.]
[ 0. 1. 1. 0. 0. 1. 1. 0. 0. 1. 1. 0. 0. 1. 1. 0. 1.]
准确率=0.94, score=0.94
precision recall f1-score support
thin 0.89 1.00 0.94 8
fat 1.00 0.89 0.94 9
avg / total 0.95 0.94 0.94 17
KNN分类器在众多分类算法中属于最简单的之一,需要注意的地方不多。有这几点要说明:
1、KNeighborsClassifier可以设置3种算法:‘brute',‘kd_tree',‘ball_tree'。如果不知道用哪个好,设置‘auto'让KNeighborsClassifier自己根据输入去决定。
2、注意统计准确率时,分类器的score返回的是计算正确的比例,而不是R2。R2一般应用于回归问题。
3、本例先根据样本中身高体重的最大最小值,生成了一个密集网格(步长h=0.01),然后将网格中的每一个点都当成测试样本去测试,最后使用contourf函数,使用不同的颜色标注出了胖、廋两类。
容易看到,本例的分类边界,属于相对复杂,但却又与距离呈现明显规则的锯齿形。
이런 종류의 경계 선형 함수는 처리하기 어렵습니다. KNN 알고리즘은 이러한 경계 문제를 처리하는 데 고유한 이점을 가지고 있습니다. 후속 시리즈에서 볼 수 있듯이 이 데이터 세트의 정확도 = 0.94는 탁월한 결과로 간주됩니다.
【관련 추천: Python3 비디오 튜토리얼】
위 내용은 Python을 사용하여 KNN 분류 알고리즘 처리의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

Video Face Swap
완전히 무료인 AI 얼굴 교환 도구를 사용하여 모든 비디오의 얼굴을 쉽게 바꾸세요!

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7663
7663
 15
1393
52
1205
24
91
11
73
19
15
1393
52
1205
24
91
11
73
19

 PHP와 Python : 다른 패러다임이 설명되었습니다
Apr 18, 2025 am 12:26 AM
PHP와 Python : 다른 패러다임이 설명되었습니다
Apr 18, 2025 am 12:26 AM
PHP는 주로 절차 적 프로그래밍이지만 객체 지향 프로그래밍 (OOP)도 지원합니다. Python은 OOP, 기능 및 절차 프로그래밍을 포함한 다양한 패러다임을 지원합니다. PHP는 웹 개발에 적합하며 Python은 데이터 분석 및 기계 학습과 같은 다양한 응용 프로그램에 적합합니다.
 PHP와 Python 중에서 선택 : 가이드
Apr 18, 2025 am 12:24 AM
PHP와 Python 중에서 선택 : 가이드
Apr 18, 2025 am 12:24 AM
PHP는 웹 개발 및 빠른 프로토 타이핑에 적합하며 Python은 데이터 과학 및 기계 학습에 적합합니다. 1.PHP는 간단한 구문과 함께 동적 웹 개발에 사용되며 빠른 개발에 적합합니다. 2. Python은 간결한 구문을 가지고 있으며 여러 분야에 적합하며 강력한 라이브러리 생태계가 있습니다.
 Python에서 비주얼 스튜디오 코드를 사용할 수 있습니다
Apr 15, 2025 pm 08:18 PM
Python에서 비주얼 스튜디오 코드를 사용할 수 있습니다
Apr 15, 2025 pm 08:18 PM
VS 코드는 파이썬을 작성하는 데 사용될 수 있으며 파이썬 애플리케이션을 개발하기에 이상적인 도구가되는 많은 기능을 제공합니다. 사용자는 다음을 수행 할 수 있습니다. Python 확장 기능을 설치하여 코드 완료, 구문 강조 및 디버깅과 같은 기능을 얻습니다. 디버거를 사용하여 코드를 단계별로 추적하고 오류를 찾아 수정하십시오. 버전 제어를 위해 git을 통합합니다. 코드 서식 도구를 사용하여 코드 일관성을 유지하십시오. 라인 도구를 사용하여 잠재적 인 문제를 미리 발견하십시오.
 Windows 8에서 코드를 실행할 수 있습니다
Apr 15, 2025 pm 07:24 PM
Windows 8에서 코드를 실행할 수 있습니다
Apr 15, 2025 pm 07:24 PM
VS 코드는 Windows 8에서 실행될 수 있지만 경험은 크지 않을 수 있습니다. 먼저 시스템이 최신 패치로 업데이트되었는지 확인한 다음 시스템 아키텍처와 일치하는 VS 코드 설치 패키지를 다운로드하여 프롬프트대로 설치하십시오. 설치 후 일부 확장은 Windows 8과 호환되지 않을 수 있으며 대체 확장을 찾거나 가상 시스템에서 새로운 Windows 시스템을 사용해야합니다. 필요한 연장을 설치하여 제대로 작동하는지 확인하십시오. Windows 8에서는 VS 코드가 가능하지만 더 나은 개발 경험과 보안을 위해 새로운 Windows 시스템으로 업그레이드하는 것이 좋습니다.
 Python vs. JavaScript : 학습 곡선 및 사용 편의성
Apr 16, 2025 am 12:12 AM
Python vs. JavaScript : 학습 곡선 및 사용 편의성
Apr 16, 2025 am 12:12 AM
Python은 부드러운 학습 곡선과 간결한 구문으로 초보자에게 더 적합합니다. JavaScript는 가파른 학습 곡선과 유연한 구문으로 프론트 엔드 개발에 적합합니다. 1. Python Syntax는 직관적이며 데이터 과학 및 백엔드 개발에 적합합니다. 2. JavaScript는 유연하며 프론트 엔드 및 서버 측 프로그래밍에서 널리 사용됩니다.
 VScode 확장자가 악의적입니까?
Apr 15, 2025 pm 07:57 PM
VScode 확장자가 악의적입니까?
Apr 15, 2025 pm 07:57 PM
VS 코드 확장은 악의적 인 코드 숨기기, 취약성 악용 및 합법적 인 확장으로 자위하는 등 악성 위험을 초래합니다. 악의적 인 확장을 식별하는 방법에는 게시자 확인, 주석 읽기, 코드 확인 및주의해서 설치가 포함됩니다. 보안 조치에는 보안 인식, 좋은 습관, 정기적 인 업데이트 및 바이러스 백신 소프트웨어도 포함됩니다.
 PHP와 Python : 그들의 역사에 깊은 다이빙
Apr 18, 2025 am 12:25 AM
PHP와 Python : 그들의 역사에 깊은 다이빙
Apr 18, 2025 am 12:25 AM
PHP는 1994 년에 시작되었으며 Rasmuslerdorf에 의해 개발되었습니다. 원래 웹 사이트 방문자를 추적하는 데 사용되었으며 점차 서버 측 스크립팅 언어로 진화했으며 웹 개발에 널리 사용되었습니다. Python은 1980 년대 후반 Guidovan Rossum에 의해 개발되었으며 1991 년에 처음 출시되었습니다. 코드 가독성과 단순성을 강조하며 과학 컴퓨팅, 데이터 분석 및 기타 분야에 적합합니다.
 터미널 VSCODE에서 프로그램을 실행하는 방법
Apr 15, 2025 pm 06:42 PM
터미널 VSCODE에서 프로그램을 실행하는 방법
Apr 15, 2025 pm 06:42 PM
vs 코드에서는 다음 단계를 통해 터미널에서 프로그램을 실행할 수 있습니다. 코드를 준비하고 통합 터미널을 열어 코드 디렉토리가 터미널 작업 디렉토리와 일치하는지 확인하십시오. 프로그래밍 언어 (예 : Python의 Python Your_file_name.py)에 따라 실행 명령을 선택하여 성공적으로 실행되는지 여부를 확인하고 오류를 해결하십시오. 디버거를 사용하여 디버깅 효율을 향상시킵니다.
