

SQL에서 order By 문을 최적화하는 방법에 대해 이야기해 보겠습니다.

SQL에서 orderBy 문을 최적화하는 방법은 무엇입니까? 다음 글에서는 SQL에서 orderBy 문을 최적화하는 방법을 소개하겠습니다. 좋은 참고값이 있으니 도움이 되셨으면 좋겠습니다.

데이터 쿼리를 위해 데이터베이스를 사용할 때 필연적으로 특정 필드를 기반으로 쿼리 결과 집합을 정렬해야 할 필요성이 발생합니다. SQL에서는 이를 달성하기 위해 일반적으로 orderby 문이 사용됩니다. 정렬해야 할 필드를 키워드 뒤에 배치하세요. 필드가 여러 개인 경우 ","를 사용하여 구분하세요.
select * from table t order by t.column1,t.column2;
위 sql은 테이블의 데이터를 조회한 후 1열에 따라 정렬하는 것을 의미합니다. 1열이 동일하면 2열에 따라 정렬합니다. 기본 정렬 방법은 내림차순입니다. 물론 정렬 방법도 지정할 수 있습니다. 정렬된 필드 뒤에 DESC와 ASE를 추가하여 각각 내림차순과 오름차순을 나타냅니다.
이 orderby를 사용하면 일일 정렬 작업을 쉽게 구현할 수 있습니다. 많이 사용해봤지만 이런 경우를 겪어보셨는지 모르겠습니다. 가끔 orderby를 사용하고 나면 SQL 실행 효율이 매우 느리기도 하고, 하루 종일 Curd에 푹 빠져 있기 때문에 때로는 더 빨라지기도 합니다. 공부할 시간이 없어요. 어쨌든 정말 대단하다는 느낌이 들거든요. 이번 주말에 시간이 있는 동안 mysql에서 orderby가 어떻게 구현되는지 연구해 보겠습니다.
설명의 편의를 위해 먼저 데이터 테이블 t1을 다음과 같이 생성합니다.
CREATE TABLE `t1` ( `id` int(11) NOT NULL not null auto_increment, `a` int(11) DEFAULT NULL, `b` int(11) DEFAULT NULL, `c` int(11) DEFAULT NULL, PRIMARY KEY (`id`) , KEY `a` (`a`) USING BTREE ) ENGINE=InnoDB;
그리고 데이터를 삽입합니다.
insert into t1 (a,b,c) values (1,1,3); insert into t1 (a,b,c) values (1,4,5); insert into t1 (a,b,c) values (1,3,3); insert into t1 (a,b,c) values (1,3,4); insert into t1 (a,b,c) values (1,2,5); insert into t1 (a,b,c) values (1,3,6);
인덱스를 유효하게 하기 위해 관련 없는 데이터 10,000개를 삽입합니다. 그리고 데이터 양이 적을 경우 테이블 전체를 직접 스캔하게 됩니다
insert into t1 (a,b,c) values (7,7,7);
이제 a=1인 레코드를 모두 찾아 b 필드에 따라 정렬해야 합니다.
쿼리 sql은
select a,b,c from t1 where a = 1 order by b limit 2;
쿼리 프로세스 중 전체 테이블 스캔을 방지하기 위해 필드 a에 인덱스를 추가했습니다.
먼저 아래와 같이
explain select a,b,c from t1 where a = 1 order by b lmit 2;
문을 통해 SQL 실행 계획을 확인합니다.

추가로 Using filesort가 나타나는 것을 볼 수 있는데, 이는 SQL 실행 중에 정렬 작업이 수행된다는 의미입니다. 정렬 작업은 MySQL이 각 스레드에 할당한 메모리 버퍼인 sort_buffer에서 완료됩니다. 이 버퍼는 정렬을 완료하는 데 특별히 사용되며, 크기는 sort_buffer_size 변수에 의해 제어됩니다.
mysql이 orderby를 구현할 때 sort_buffer에 입력된 다양한 필드 내용에 따라 두 가지 구현 방법, 즉 전체 필드 정렬과 rowid 정렬을 구현합니다.
전체 필드 정렬
먼저 SQL 실행 과정을 그림을 통해 전체적으로 살펴보겠습니다.
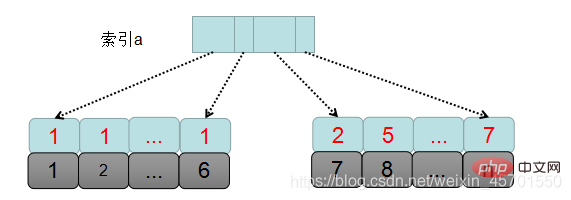
mysql은 먼저 쿼리 조건에 따라 정렬이 필요한 데이터 세트를 결정하는데, 이것이 바로 데이터 세트입니다. 테이블에 a=1이 있습니다. 즉, 이 레코드에는 1에서 6까지의 기본 키 ID가 있습니다.
전체 SQL 실행 과정은 다음과 같습니다.
1. sort_buffer를 생성 및 초기화하고, 버퍼에 넣어야 할 필드, 즉 a, b, c 3개 필드를 결정합니다.
2. 인덱스 트리 a에서 a=1을 만족하는 첫 번째 기본 키 ID, 즉 id=1을 찾습니다.
3. id 인덱스가 있는 테이블로 돌아가 전체 데이터 행을 꺼낸 다음 전체 데이터 행에서 a, b, c의 값을 꺼내서 sort_buffer에 넣습니다.
4. 인덱스 a부터 순서대로 a=1의 다음 기본 키 ID를 찾습니다.
5. a=1인 마지막 레코드, 즉 기본 키 ID=5를 얻을 때까지 3단계와 4단계를 반복합니다.
6. 이때 a=1 조건을 만족하는 모든 레코드의 a, b, c 필드를 모두 읽어서 sort_buffer에 배치합니다. 그런 다음 이 데이터를 b 값에 따라 정렬합니다. 방법은 퀵 정렬이다. 인터뷰에서 자주 접하게 되는 퀵소트인데, 퀵소트의 시간복잡도는 log2n이다.
7. 그런 다음 정렬된 결과 집합에서 처음 2행의 데이터를 꺼냅니다.
위는 msql에서 orderby의 실행 과정입니다. sort_buffer에 넣은 데이터가 출력해야 하는 필드가 전부이기 때문에 이러한 정렬을 전체 정렬이라고 합니다.
이것을 보시고 궁금한 점이 있으신가요? 정렬해야 할 데이터의 양이 많고 sort_buffer가 들어갈 수 없는 경우 어떻게 해야 하나요?
실제로 a=1인 데이터 행이 많고, sort_buffer에 저장해야 할 필드가 많은 경우 a, b, c 필드가 3개 이상 있을 수 있습니다. 더 많은 분야. 그러면 기본 크기가 1M인 sort_buffer가 이를 수용하지 못할 수도 있습니다.
sort_buffer가 이를 수용할 수 없는 경우 mysql은 정렬을 돕기 위해 임시 디스크 파일 배치를 생성합니다. 기본적으로 12개의 임시 파일이 생성되며 정렬할 데이터는 12개의 부분으로 나누어집니다. 각 부분은 별도로 정렬되어 12개의 내부 데이터 정렬 파일을 형성한 다음 이 12개의 정렬된 파일을 정렬된 파일로 병합합니다. . 대용량 파일을 저장하고 마지막으로 데이터 정렬을 완료합니다.
파일 기반 정렬은 메모리 기반 정렬보다 효율성이 훨씬 낮습니다. 파일 기반 정렬을 피하려면 파일 기반 정렬을 최대한 피해야 합니다. 정렬해야 하는 항목을 수용할 수 있도록 sort_buffer를 허용합니다.
그래서 mysql은 sort_buffer가 이를 수용할 수 없는 상황에 최적화되었습니다. 정렬 시 sort_buffer에 저장되는 필드 수를 줄이기 위한 것입니다.
구체적인 최적화 방법은 다음과 같은 rowId 정렬입니다
RowId 排序
在全字段排序实现中,排序的过程中,要把需要输出的字段全部放到sort_buffer中,当输出的字段比较多的时候,可以放到sort_buffer中的数据行就会变少。也就增大了sort_buffer无法容纳数据的风险,直至出现基于文件的排序。
rowId排序对全字段排序的优化手段,主要是减少了放到sort_buffer中字段个数。
在rowId排序中,只会将需要排序的字段和主键Id放到sort_buffer中。
select a,b,c from t1 where a = 1 order by b limit 2;
在rowId的排序中的执行流程如下:
1.初始化并创建sort_buffer,并确认要放入的的字段,id和b。
2.从索引树a中找到第一个满足a=1的主键id,也就是id=1。
3.回表主键索引id,取出整行数据,从整行数据中取出id和b,存入sort_buffer中。
4.从索引a中取出下一条满足a=1的 记录的主键id。
5.重复步骤3和4,直到最后一个满足a=1的主键id,也就是a=6。
6.对sort_buffer中的数据,按照字段b排序。
7.从sort_buffer中的有序数据集中,取出前2个,因为此时取出的数据只有id和b,要想获取a和c字段,需要根据id字段,回表到主键索引中取出整行数据,从整行数据中获取需要的数据。
根据rowId排序的执行步骤,可以发现:相比全字段排序,rowId排序的实现方式,减少了存放到sort_buffer中的数据量,降低了基于文件的外部排序的可能性。
那rowid排序有不足的地方吗?肯定有的,要不然全字段排序就没有存在的意义了。rowid排序不足之处在于,在最后的步骤7中,增加了回表的次数,不过这个回表的次数,取决于limit后的值,如果返回的结果集比较小的话,回表的次数还是比较小的。
mysql是如何在全字段排序和rowId排序的呢?其实是根据存放的sort_buffer中每行字段的长度决定的,如果mysql认为每次放到sort_buffer中的数据量很大的话,那么就用rowId排序实现,否则使用全字段排序。那么多大算大呢?这个大小的阈值有一个变量的值来决定,这个变量就是 max_length_for_sort_data。如果每次放到sort_buffer中的数据大小大于该字段值的话,就使用rowId排序,否则使用全字段排序。
orderby的优化
上面讲述了orderby的两种排序的方式,以及一些优化策略,优化的目的主要就是避免基于磁盘文件的外部排序。因为基于磁盘文件的排序效率要远低于基于sort_buffer的内存排序。
但是当数据量比较大的时候,即使sort_buffer比较大,所有数据全部放在内存中排序,sql的整体执行效率也不高,因为排序这个操作,本身就是比较消耗性能的。
试想,如果基于索引a获取到所有a=1的数据,按照字段b,天然就是有序的,那么就不用执行排序操作,直接取出来的数据,就是符合结果的数据集,那么sql的执行效率就会大幅度增长。
其实要实现整个sql执行过程中,避免排序操作也不难,只需要创建一个a和b的联合索引即可。
alter table t1 add index a_b (a,b);
添加a和b的联合索引后,sql执行流程就变成了:
1.从索引树(a,b)中找到第一个满足a=1的主键id,也就是id=1。
2.回表到主键索引树,取出整行数据,并从中取出a,b,c,直接作为结果集的一部分返回。
3.从索引树(a,b)上取出下一个满足a=1的主键id。
4.重复步骤2和3,直到找到第二个满足a=1的主键id,并回表获取字段a,b,c。
此时我们可以通过查看sql的执行计划,来判断sql的执行过程中是否执行了排序操作。
explain select a,b from t1 where a = 1 order by b lmit 2;

通过查看执行计划,我们发现extra中已经没有了using filesort了,也就是没有执行排序操作了。
其实还可以通过覆盖索引,对该sql进一步优化,通过在索引中覆盖字段c,来避免回表的操作。
alter table t1 add index a_b_c (a,b,c);
添加索引a_b_c后,sql的执行过程如下:
1.从索引树(a,b,c)中找到第一个满足a=1的索引,从中取出a,b,c。直接作为结果集的一部分直接返回。
2.从索引(a,b,c)中取出下一个,满足a=1的记录作为结果集的一部分。
3.重复执行步骤2,直到查到第二个a=1或者不满足a=1的记录。
此时通过查看执行sql的的还行计划可以发现 extra中只有 Using index。
explain select a,b from t1 where a = 1 order by b lmit 2;

요약
이 SQL의 여러 최적화를 통해 SQL의 최종 실행 효율성은 기본적으로 정렬을 수행하지 않은 일반 SQL의 쿼리 효율성과 동일합니다. orderby 정렬 작업을 피할 수 있는 이유는 인덱스의 자연스러운 정렬 특성을 활용하기 위해서입니다.
하지만 인덱스가 쿼리 효율성을 높일 수 있다는 것은 모두 알고 있지만 인덱스 유지 관리 비용은 상대적으로 높습니다. 데이터 테이블에 데이터를 추가하고 수정하면 인덱스가 변경되므로 인덱스가 많을수록 추가할 가치가 없습니다. 일반적이지 않은 쿼리와 정렬로 인해 인덱스가 너무 많습니다.
【관련 추천: mysql 비디오 튜토리얼】
위 내용은 SQL에서 order By 문을 최적화하는 방법에 대해 이야기해 보겠습니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7488
7488
 15
1377
52
77
11
52
19
19
40
15
1377
52
77
11
52
19
19
40

 Hibernate 프레임워크에서 HQL과 SQL의 차이점은 무엇입니까?
Apr 17, 2024 pm 02:57 PM
Hibernate 프레임워크에서 HQL과 SQL의 차이점은 무엇입니까?
Apr 17, 2024 pm 02:57 PM
HQL과 SQL은 Hibernate 프레임워크에서 비교됩니다. HQL(1. 객체 지향 구문, 2. 데이터베이스 독립적 쿼리, 3. 유형 안전성), SQL은 데이터베이스를 직접 운영합니다(1. 데이터베이스 독립적 표준, 2. 복잡한 실행 파일) 쿼리 및 데이터 조작).
 Oracle SQL의 나누기 연산 사용법
Mar 10, 2024 pm 03:06 PM
Oracle SQL의 나누기 연산 사용법
Mar 10, 2024 pm 03:06 PM
"OracleSQL의 나눗셈 연산 사용법" OracleSQL에서 나눗셈 연산은 일반적인 수학 연산 중 하나입니다. 데이터 쿼리 및 처리 중에 나누기 작업은 필드 간의 비율을 계산하거나 특정 값 간의 논리적 관계를 도출하는 데 도움이 될 수 있습니다. 이 문서에서는 OracleSQL의 나누기 작업 사용법을 소개하고 구체적인 코드 예제를 제공합니다. 1. OracleSQL의 두 가지 분할 연산 방식 OracleSQL에서는 두 가지 방식으로 분할 연산을 수행할 수 있습니다.
 Oracle과 DB2의 SQL 구문 비교 및 차이점
Mar 11, 2024 pm 12:09 PM
Oracle과 DB2의 SQL 구문 비교 및 차이점
Mar 11, 2024 pm 12:09 PM
Oracle과 DB2는 일반적으로 사용되는 관계형 데이터베이스 관리 시스템으로, 각각 고유한 SQL 구문과 특성을 가지고 있습니다. 이 기사에서는 Oracle과 DB2의 SQL 구문을 비교 및 차이점을 설명하고 구체적인 코드 예제를 제공합니다. 데이터베이스 연결 Oracle에서는 다음 문을 사용하여 데이터베이스에 연결합니다. CONNECTusername/password@database DB2에서 데이터베이스에 연결하는 문은 다음과 같습니다. CONNECTTOdataba
 MyBatis 동적 SQL 태그의 Set 태그 기능에 대한 자세한 설명
Feb 26, 2024 pm 07:48 PM
MyBatis 동적 SQL 태그의 Set 태그 기능에 대한 자세한 설명
Feb 26, 2024 pm 07:48 PM
MyBatis 동적 SQL 태그 해석: Set 태그 사용법에 대한 자세한 설명 MyBatis는 풍부한 동적 SQL 태그를 제공하고 데이터베이스 작업 명령문을 유연하게 구성할 수 있는 탁월한 지속성 계층 프레임워크입니다. 그 중 Set 태그는 업데이트 작업에서 매우 일반적으로 사용되는 UPDATE 문에서 SET 절을 생성하는 데 사용됩니다. 이 기사에서는 MyBatis에서 Set 태그의 사용법을 자세히 설명하고 특정 코드 예제를 통해 해당 기능을 보여줍니다. Set 태그란 무엇입니까? Set 태그는 MyBati에서 사용됩니다.
 SQL의 ID 속성은 무엇을 의미합니까?
Feb 19, 2024 am 11:24 AM
SQL의 ID 속성은 무엇을 의미합니까?
Feb 19, 2024 am 11:24 AM
SQL에서 ID란 무엇입니까? SQL에서 ID는 자동 증가 숫자를 생성하는 데 사용되는 특수 데이터 유형으로, 테이블의 각 데이터 행을 고유하게 식별하는 데 사용됩니다. ID 열은 일반적으로 기본 키 열과 함께 사용되어 각 레코드에 고유한 식별자가 있는지 확인합니다. 이 문서에서는 Identity를 사용하는 방법과 몇 가지 실제 코드 예제를 자세히 설명합니다. Identity를 사용하는 기본 방법은 테이블을 생성할 때 Identit을 사용하는 것입니다.
 SQL에서 5120 오류를 해결하는 방법
Mar 06, 2024 pm 04:33 PM
SQL에서 5120 오류를 해결하는 방법
Mar 06, 2024 pm 04:33 PM
해결 방법: 1. 로그인한 사용자에게 데이터베이스에 액세스하거나 운영할 수 있는 충분한 권한이 있는지 확인하고 해당 사용자에게 올바른 권한이 있는지 확인하십시오. 2. SQL Server 서비스 계정에 지정된 파일에 액세스할 수 있는 권한이 있는지 확인하십시오. 3. 지정된 데이터베이스 파일이 다른 프로세스에 의해 열렸거나 잠겼는지 확인하고 파일을 닫거나 해제한 후 쿼리를 다시 실행하십시오. .관리자로 Management Studio를 실행해 보세요.
 여러 테이블을 추가하기 위해 SQL 문을 사용하지 않고 Springboot+Mybatis-plus를 구현하는 방법
Jun 02, 2023 am 11:07 AM
여러 테이블을 추가하기 위해 SQL 문을 사용하지 않고 Springboot+Mybatis-plus를 구현하는 방법
Jun 02, 2023 am 11:07 AM
Springboot+Mybatis-plus가 다중 테이블 추가 작업을 수행하기 위해 SQL 문을 사용하지 않을 때 내가 직면한 문제는 테스트 환경에서 생각을 시뮬레이션하여 분해됩니다. 매개 변수가 있는 BrandDTO 개체를 생성하여 배경으로 매개 변수 전달을 시뮬레이션합니다. Mybatis-plus에서 다중 테이블 작업을 수행하는 것은 매우 어렵다는 것을 Mybatis-plus-join과 같은 도구를 사용하지 않으면 해당 Mapper.xml 파일을 구성하고 냄새나고 긴 ResultMap만 구성하면 됩니다. 해당 SQL 문을 작성합니다. 이 방법은 번거로워 보이지만 매우 유연하며 다음을 수행할 수 있습니다.
 MySQL에서 데이터 집계 및 통계를 위해 SQL 문을 사용하는 방법은 무엇입니까?
Dec 17, 2023 am 08:41 AM
MySQL에서 데이터 집계 및 통계를 위해 SQL 문을 사용하는 방법은 무엇입니까?
Dec 17, 2023 am 08:41 AM
MySQL에서 데이터 집계 및 통계를 위해 SQL 문을 사용하는 방법은 무엇입니까? 데이터 집계 및 통계는 데이터 분석 및 통계를 수행할 때 매우 중요한 단계입니다. 강력한 관계형 데이터베이스 관리 시스템인 MySQL은 데이터 집계 및 통계 작업을 쉽게 수행할 수 있는 풍부한 집계 및 통계 기능을 제공합니다. 이 기사에서는 SQL 문을 사용하여 MySQL에서 데이터 집계 및 통계를 수행하는 방법을 소개하고 구체적인 코드 예제를 제공합니다. 1. COUNT 함수를 사용합니다. COUNT 함수는 가장 일반적으로 사용됩니다.
