

노드가 OCR을 구현하는 방법에 대한 간략한 분석

OCR(광학 문자 인식)을 구현하는 방법은 무엇입니까? 다음 글에서는 node를 사용하여 OCR을 구현하는 방법을 소개하겠습니다. 도움이 되셨으면 좋겠습니다!

ocr은 광학 문자 인식입니다. 쉽게 말하면 사진 속 텍스트를 인식하는 것입니다.
안타깝게도 저는 AI에 대해 잘 모르는 저급 웹 프로그래머입니다. OCR을 구현하려면 타사 라이브러리만 찾을 수 있습니다.
Python 언어에는 OCR을 위한 타사 라이브러리가 많이 있습니다. 저는 오랫동안 OCR을 구현하기 위한 nodejs용 타사 라이브러리를 찾고 있었는데, 마침내 tesseract.js 라이브러리가 여전히 OCR을 구현할 수 있다는 것을 알게 되었습니다. 아주 편리하게. [관련 튜토리얼 권장 사항: nodejs 비디오 튜토리얼]
효과 표시
온라인 예시: http://www.lolmbbs.com/tool/ocr
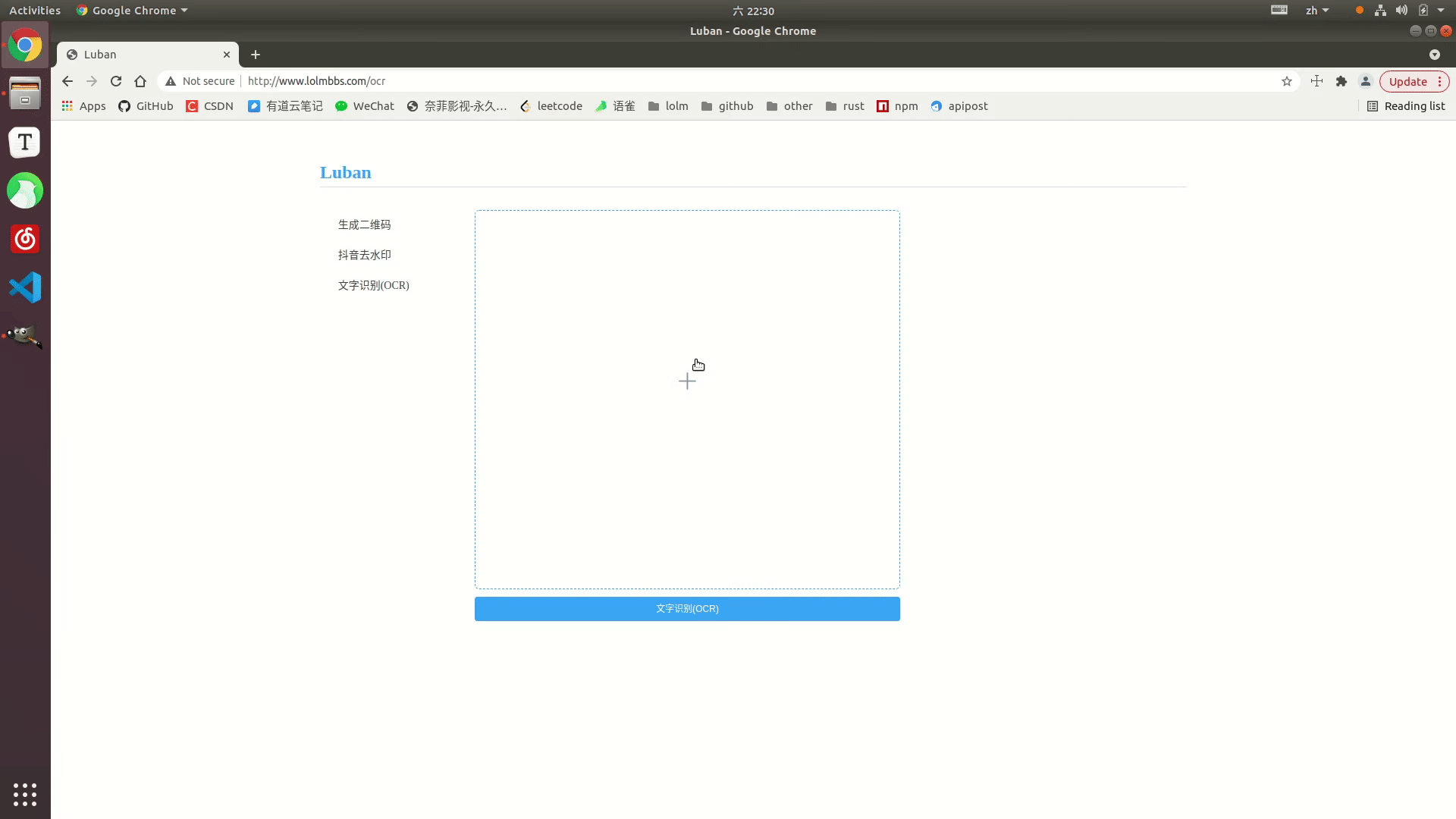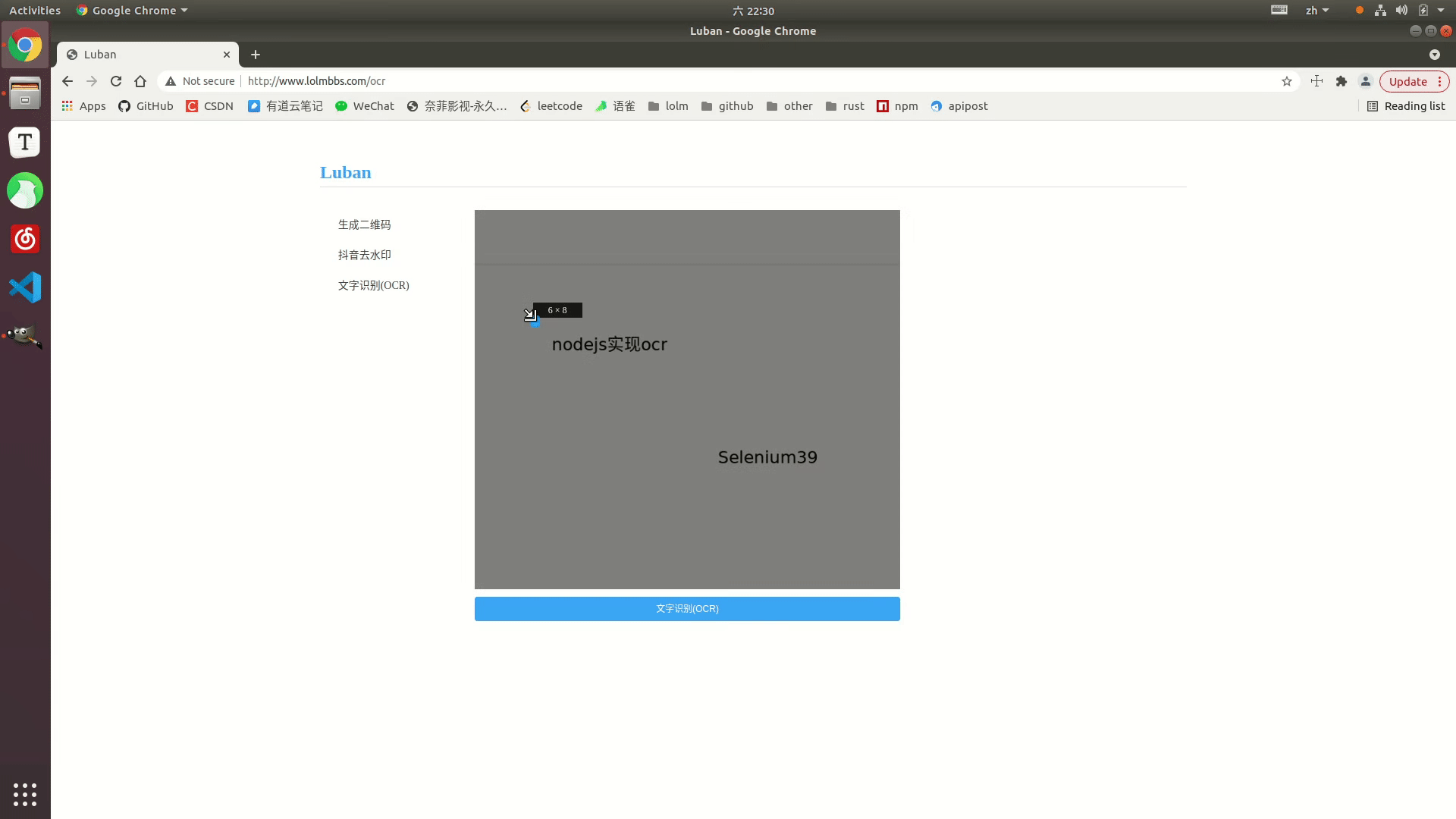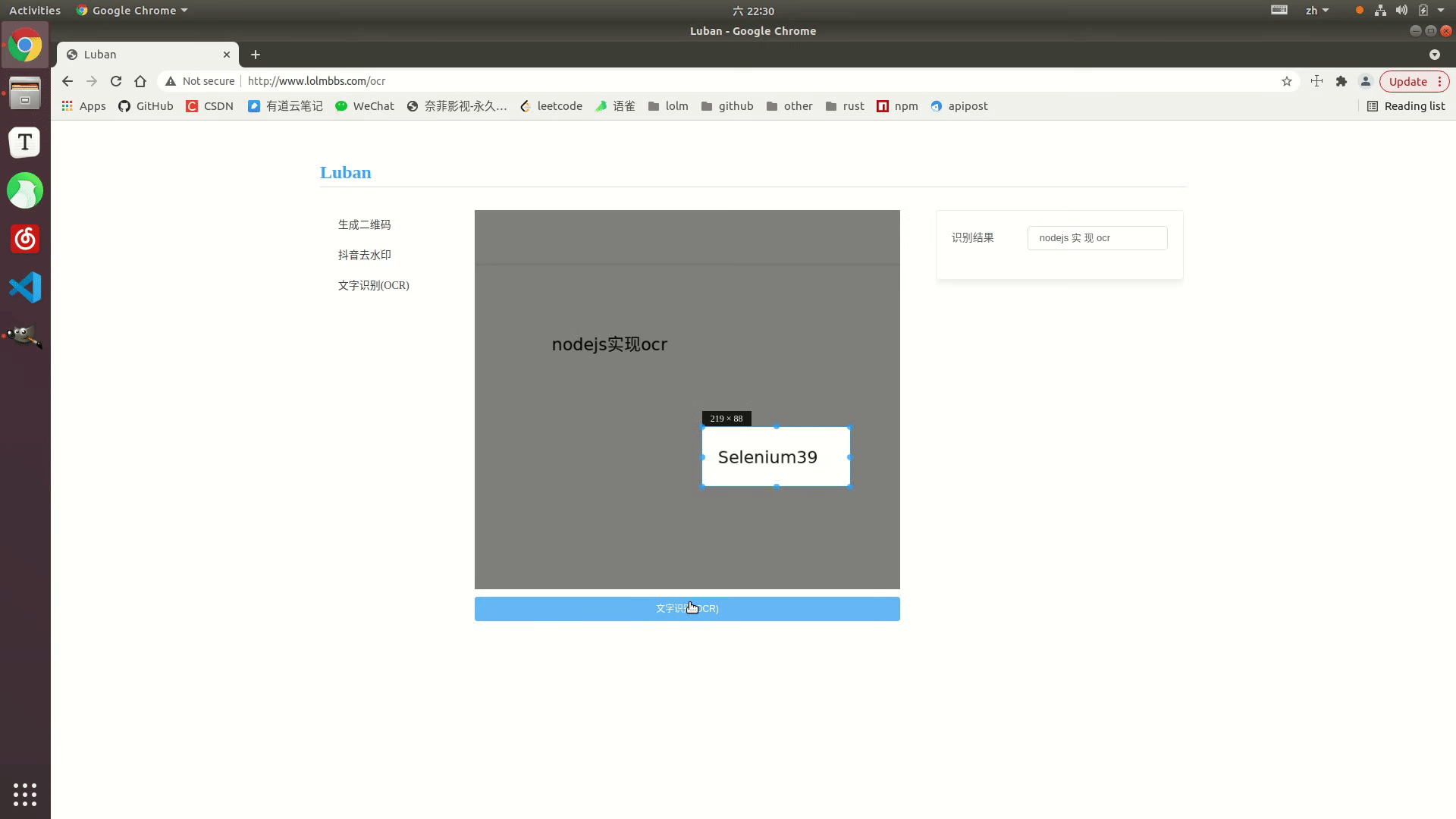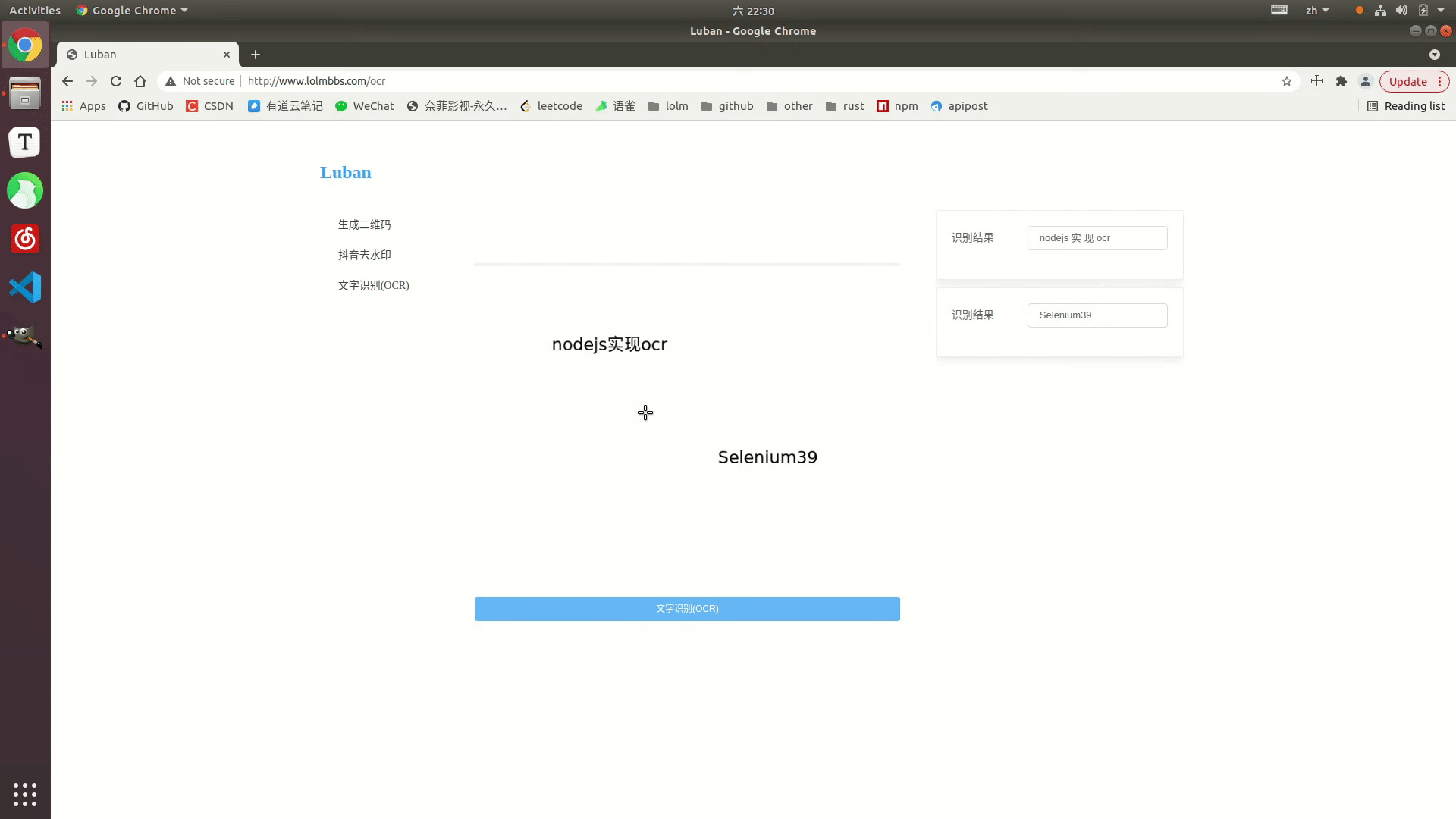
자세한 코드
tesserract.js 이 라이브러리는 선택할 수 있는 여러 버전을 제공합니다. 저는 오프라인 버전인 tesseract.js-offline을 사용하고 있습니다. 결국 모든 사람이 열악한 네트워크 상태의 영향을 받습니다.
기본 샘플 코드
const { createWorker } = require('tesseract.js');
const path = require('path');
const worker = createWorker({
langPath: path.join(__dirname, '..', 'lang-data'),
logger: m => console.log(m),
});
(async () => {
await worker.load();
await worker.loadLanguage('eng');
await worker.initialize('eng');
const { data: { text } } = await worker.recognize(path.join(__dirname, '..', 'images', 'testocr.png'));
console.log(text);
await worker.terminate();
})();默认示例代码await worker.loadLanguage('chi_sim+jpn+eng'); await worker.initialize('chi_sim+jpn+eng');
1. 支持多语言识别
tesseract.js 离线版本默认示例代码只支持识别英文,如果识别中文,结果会是一堆问号。但是幸运的是你可以导入多个训练好的语言模型,让它支持多个语言的识别。
从https://github.com/naptha/tessdata/tree/gh-pages/4.0.0这里下载你需要的对应语言模型,放入到根目录下的lang-data目录下
我这里选择了中(chi_sim.traineddata.gz)日(jpn.traineddata.gz)英(eng.traineddata.gz)三国语言模型。修改代码中加载和初始化模型的语言项配置,来同时支持中日英三国语言。
const Koa = require('koa')
const Router = require('koa-router')
const router = new Router()
const app = new Koa()
const path = require('path')
const moment = require('moment')
const { createWorker, createScheduler } = require('tesseract.js')
;(async () => {
const scheduler = createScheduler()
for (let i = 0; i < 4; i++) {
const worker = createWorker({
langPath: path.join(__dirname, '.', 'lang-data'),
cachePath: path.join(__dirname, '.'),
logger: m => console.log(`${moment().format('YYYY-MM-DD HH:mm:ss')}-${JSON.stringify(m)}`)
})
await worker.load()
await worker.loadLanguage('chi_sim+jpn+eng')
await worker.initialize('chi_sim+jpn+eng')
scheduler.addWorker(worker)
}
app.context.scheduler = scheduler
})()
router.get('/test', async (ctx) => {
const { data: { text } } = await ctx.scheduler.addJob('recognize', path.join(__dirname, '.', 'images', 'chinese.png'))
// await ctx.scheduler.terminate()
ctx.body = text
})
app.use(router.routes(), router.allowedMethods())
app.listen(3002)为了方便大家的测试,我在示例的离线版本,已经放入了中日韩三国语言的训练模型和实例代码以及测试图片。
https://github.com/Selenium39/tesseract.js-offline
2. 提高识别性能
如果你运行了离线的版本,你会发现模型的加载和ocr的识别有点慢。可以通过这两个步骤优化。
web项目中,你可以在应用一启动的时候就加载模型,这样后续接收到ocr请求的时候就可以不用等待模型加载了。
参照Why I refactor tesseract.js v2?这篇博客,可以通过
createScheduler方法添加多个worker线程来并发的处理ocr请求。
多线程并发处理ocr请求示例
<template>
<div>
<div style="margin-top:30px;height:500px">
<div class="show">
<vueCropper
v-if="imgBase64"
ref="cropper"
:img="imgBase64"
:output-size="option.size"
:output-type="option.outputType"
:info="true"
:full="option.full"
:can-move="option.canMove"
:can-move-box="option.canMoveBox"
:original="option.original"
:auto-crop="option.autoCrop"
:fixed="option.fixed"
:fixed-number="option.fixedNumber"
:center-box="option.centerBox"
:info-true="option.infoTrue"
:fixed-box="option.fixedBox"
:max-img-size="option.maxImgSize"
style="background-image:none"
@mouseenter.native="enter"
@mouseleave.native="leave"
></vueCropper>
<el-upload
v-else
ref="uploader"
class="avatar-uploader"
drag
multiple
action=""
:show-file-list="false"
:limit="1"
:http-request="upload"
>
<i class="el-icon-plus avatar-uploader-icon"></i>
</el-upload>
</div>
<div
class="ocr"
@mouseleave="leaveCard"
>
<el-card
v-for="(item,index) in ocrResult"
:key="index"
class="card-box"
@mouseenter.native="enterCard(item)"
>
<el-form
size="small"
label-width="100px"
label-position="left"
>
<el-form-item label="识别结果">
<el-input v-model="item.text"></el-input>
</el-form-item>
</el-form>
</el-card>
</div>
</div>
<div style="margin-top:10px">
<el-button
size="small"
type="primary"
style="width:60%"
@click="doOcr"
>
文字识别(OCR)
</el-button>
</div>
</div>
</template>
<script>
import { uploadImage, ocr } from '../utils/api'
export default {
name: 'Ocr',
data () {
return {
imgSrc: '',
imgBase64: '',
option: {
info: true, // 裁剪框的大小信息
outputSize: 0.8, // 裁剪生成图片的质量
outputType: 'jpeg', // 裁剪生成图片的格式
canScale: false, // 图片是否允许滚轮缩放
autoCrop: true, // 是否默认生成截图框
fixedBox: false, // 固定截图框大小 不允许改变
fixed: false, // 是否开启截图框宽高固定比例
fixedNumber: [7, 5], // 截图框的宽高比例
full: true, // 是否输出原图比例的截图
canMove: false, // 时候可以移动原图
canMoveBox: true, // 截图框能否拖动
original: false, // 上传图片按照原始比例渲染
centerBox: true, // 截图框是否被限制在图片里面
infoTrue: true, // true 为展示真实输出图片宽高 false 展示看到的截图框宽高
maxImgSize: 10000
},
ocrResult: []
}
},
methods: {
upload (fileObj) {
const file = fileObj.file
const reader = new FileReader()
reader.readAsDataURL(file)
reader.onload = () => {
this.imgBase64 = reader.result
}
const formData = new FormData()
formData.append('image', file)
uploadImage(formData).then(res => {
this.imgUrl = res.imgUrl
})
},
doOcr () {
const cropAxis = this.$refs.cropper.getCropAxis()
const imgAxis = this.$refs.cropper.getImgAxis()
const cropWidth = this.$refs.cropper.cropW
const cropHeight = this.$refs.cropper.cropH
const position = [
(cropAxis.x1 - imgAxis.x1) / this.$refs.cropper.scale,
(cropAxis.y1 - imgAxis.y1) / this.$refs.cropper.scale,
cropWidth / this.$refs.cropper.scale,
cropHeight / this.$refs.cropper.scale
]
const rectangle = {
top: position[1],
left: position[0],
width: position[2],
height: position[3]
}
if (this.imgUrl) {
ocr({ imgUrl: this.imgUrl, rectangle }).then(res => {
this.ocrResult.push(
{
text: res.text,
cropInfo: { //截图框显示的大小
width: cropWidth,
height: cropHeight,
left: cropAxis.x1,
top: cropAxis.y1
},
realInfo: rectangle //截图框在图片上真正的大小
})
})
}
},
enterCard (item) {
this.$refs.cropper.goAutoCrop()// 重新生成自动裁剪框
this.$nextTick(() => {
// if cropped and has position message, update crop box
// 设置自动裁剪框的宽高和位置
this.$refs.cropper.cropOffsertX = item.cropInfo.left
this.$refs.cropper.cropOffsertY = item.cropInfo.top
this.$refs.cropper.cropW = item.cropInfo.width
this.$refs.cropper.cropH = item.cropInfo.height
})
},
leaveCard () {
this.$refs.cropper.clearCrop()
},
enter () {
if (this.imgBase64 === '') {
return
}
this.$refs.cropper.startCrop() // 开始裁剪
},
leave () {
this.$refs.cropper.stopCrop()// 停止裁剪
}
}
}
</script>发起并发请求,可以看到多个worker再并发执行ocr任务
ab -n 4 -c 4 localhost:3002/test
-
https://github.com/naptha/tessdata/tree/gh-pages/4.0.0 에서 필요한 해당 언어 모델을 다운로드하세요. 루트 디렉토리의 lang-data 디렉토리에 넣으세요 저는 중국어(
chi_sim.traineddata.gz) 일본어(jpn.traineddata.gz) 영어( )를 선택했습니다 eng.traineddata.gz) 3개국 언어 모델.
chi_sim.traineddata.gz) 일본어(jpn.traineddata.gz) 영어( )를 선택했습니다 eng.traineddata.gz) 3개국 언어 모델. 중국어, 일본어, 영어를 동시에 지원하도록 코드에서 모델 로드 및 초기화의 언어 구성을 수정합니다.
모든 사람의 테스트를 용이하게 하기 위해 예제의 오프라인 버전에 중국, 일본, 한국의 3개 언어로 된 훈련 모델, 예제 코드 및 테스트 사진을 포함했습니다.
https://github.com/Selenium39/tesseract.js-offline2. 인식 성능 향상
오프라인 버전을 실행해 보면 모델 로딩과 OCR 인식이 조금 느리다. 이 두 단계를 통해 최적화할 수 있습니다.- 웹 프로젝트에서는 애플리케이션이 시작되자마자 모델을 로드할 수 있으므로 모델이 생성될 때까지 기다릴 필요가 없습니다. 나중에 OCR 요청을 받을 때 로드됩니다.
- tesseract.js v2를 리팩토링하는 이유 블로그를 참조하세요.
createScheduler메서드를 통해 여러 작업자 스레드를 추가하여 ocr 요청을 동시에 처리할 수 있습니다. 🎜
OCR 요청의 다중 스레드 동시 처리 예🎜rrreee🎜동시 요청을 시작하면 OCR 작업을 동시에 실행하는 여러 작업자를 볼 수 있습니다🎜🎜ab - n 4 -c 4 localhost:3002/test🎜🎜🎜🎜🎜🎜3. 프런트엔드 코드 🎜🎜🎜효과 표시의 프런트엔드 코드는 주로 elementui 컴포넌트와 vue-cropper를 사용하여 구현됩니다. 요소. 🎜🎜vue-cropper 구성 요소 구체적인 사용법은 내 블로그를 참조하세요. vue 이미지 자르기: 이미지 자르기에 vue-cropper 사용🎜🎜🎜ps: 🎜이미지를 업로드할 때 먼저 업로드된 이미지의 base64를 프런트 엔드에 로드할 수 있습니다. , 먼저 이미지 업로드를 참조한 다음 백엔드에 이미지 업로드를 요청하면 더 나은 사용자 경험을 얻을 수 있습니다🎜🎜전체 코드는 다음과 같습니다🎜rrreee🎜노드 관련 지식을 더 보려면 🎜nodejs 튜토리얼🎜을 방문하세요! 🎜위 내용은 노드가 OCR을 구현하는 방법에 대한 간략한 분석의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

Video Face Swap
완전히 무료인 AI 얼굴 교환 도구를 사용하여 모든 비디오의 얼굴을 쉽게 바꾸세요!

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7677
7677
 15
1393
52
1207
24
91
11
73
19
15
1393
52
1207
24
91
11
73
19

 nodejs는 백엔드 프레임워크인가요?
Apr 21, 2024 am 05:09 AM
nodejs는 백엔드 프레임워크인가요?
Apr 21, 2024 am 05:09 AM
Node.js는 고성능, 확장성, 크로스 플랫폼 지원, 풍부한 생태계, 개발 용이성 등의 기능을 제공하므로 백엔드 프레임워크로 사용할 수 있습니다.
 nodejs를 mysql 데이터베이스에 연결하는 방법
Apr 21, 2024 am 06:13 AM
nodejs를 mysql 데이터베이스에 연결하는 방법
Apr 21, 2024 am 06:13 AM
MySQL 데이터베이스에 연결하려면 다음 단계를 따라야 합니다. mysql2 드라이버를 설치합니다. mysql2.createConnection()을 사용하여 호스트 주소, 포트, 사용자 이름, 비밀번호 및 데이터베이스 이름이 포함된 연결 개체를 만듭니다. 쿼리를 수행하려면 Connection.query()를 사용하세요. 마지막으로 Connection.end()를 사용하여 연결을 종료합니다.
 nodejs의 전역 변수는 무엇입니까
Apr 21, 2024 am 04:54 AM
nodejs의 전역 변수는 무엇입니까
Apr 21, 2024 am 04:54 AM
Node.js에는 다음과 같은 전역 변수가 존재합니다. 전역 개체: 전역 핵심 모듈: 프로세스, 콘솔, 필수 런타임 환경 변수: __dirname, __filename, __line, __column 상수: undefine, null, NaN, Infinity, -Infinity
 nodejs 설치 디렉토리에 있는 npm과 npm.cmd 파일의 차이점은 무엇입니까?
Apr 21, 2024 am 05:18 AM
nodejs 설치 디렉토리에 있는 npm과 npm.cmd 파일의 차이점은 무엇입니까?
Apr 21, 2024 am 05:18 AM
Node.js 설치 디렉터리에는 npm과 npm.cmd라는 두 가지 npm 관련 파일이 있습니다. 차이점은 다음과 같습니다. 확장자가 다릅니다. npm은 실행 파일이고 npm.cmd는 명령 창 바로 가기입니다. Windows 사용자: npm.cmd는 명령 프롬프트에서 사용할 수 있으며, npm은 명령줄에서만 실행할 수 있습니다. 호환성: npm.cmd는 Windows 시스템에만 해당되며 npm은 크로스 플랫폼에서 사용할 수 있습니다. 사용 권장사항: Windows 사용자는 npm.cmd를 사용하고, 기타 운영 체제는 npm을 사용합니다.
 PI 노드 교육 : PI 노드 란 무엇입니까? Pi 노드를 설치하고 설정하는 방법은 무엇입니까?
Mar 05, 2025 pm 05:57 PM
PI 노드 교육 : PI 노드 란 무엇입니까? Pi 노드를 설치하고 설정하는 방법은 무엇입니까?
Mar 05, 2025 pm 05:57 PM
Pinetwork 노드에 대한 자세한 설명 및 설치 안내서이 기사에서는 Pinetwork Ecosystem을 자세히 소개합니다. Pi 노드, Pinetwork 생태계의 주요 역할을 수행하고 설치 및 구성을위한 전체 단계를 제공합니다. Pinetwork 블록 체인 테스트 네트워크가 출시 된 후, PI 노드는 다가오는 주요 네트워크 릴리스를 준비하여 테스트에 적극적으로 참여하는 많은 개척자들의 중요한 부분이되었습니다. 아직 Pinetwork를 모른다면 Picoin이 무엇인지 참조하십시오. 리스팅 가격은 얼마입니까? PI 사용, 광업 및 보안 분석. Pinetwork 란 무엇입니까? Pinetwork 프로젝트는 2019 년에 시작되었으며 독점적 인 Cryptocurrency Pi Coin을 소유하고 있습니다. 이 프로젝트는 모든 사람이 참여할 수있는 사람을 만드는 것을 목표로합니다.
 nodejs와 java 사이에 큰 차이가 있나요?
Apr 21, 2024 am 06:12 AM
nodejs와 java 사이에 큰 차이가 있나요?
Apr 21, 2024 am 06:12 AM
Node.js와 Java의 주요 차이점은 디자인과 기능입니다. 이벤트 중심 대 스레드 중심: Node.js는 이벤트 중심이고 Java는 스레드 중심입니다. 단일 스레드 대 다중 스레드: Node.js는 단일 스레드 이벤트 루프를 사용하고 Java는 다중 스레드 아키텍처를 사용합니다. 런타임 환경: Node.js는 V8 JavaScript 엔진에서 실행되는 반면 Java는 JVM에서 실행됩니다. 구문: Node.js는 JavaScript 구문을 사용하고 Java는 Java 구문을 사용합니다. 목적: Node.js는 I/O 집약적인 작업에 적합한 반면, Java는 대규모 엔터프라이즈 애플리케이션에 적합합니다.
 nodejs는 백엔드 개발 언어인가요?
Apr 21, 2024 am 05:09 AM
nodejs는 백엔드 개발 언어인가요?
Apr 21, 2024 am 05:09 AM
예, Node.js는 백엔드 개발 언어입니다. 서버 측 비즈니스 로직 처리, 데이터베이스 연결 관리, API 제공 등 백엔드 개발에 사용됩니다.
 nodejs 프로젝트를 서버에 배포하는 방법
Apr 21, 2024 am 04:40 AM
nodejs 프로젝트를 서버에 배포하는 방법
Apr 21, 2024 am 04:40 AM
Node.js 프로젝트의 서버 배포 단계: 배포 환경 준비: 서버 액세스 권한 획득, Node.js 설치, Git 저장소 설정. 애플리케이션 빌드: npm run build를 사용하여 배포 가능한 코드와 종속성을 생성합니다. Git 또는 파일 전송 프로토콜을 통해 서버에 코드를 업로드합니다. 종속성 설치: SSH를 서버에 연결하고 npm install을 사용하여 애플리케이션 종속성을 설치합니다. 애플리케이션 시작: node index.js와 같은 명령을 사용하여 애플리케이션을 시작하거나 pm2와 같은 프로세스 관리자를 사용합니다. 역방향 프록시 구성(선택 사항): Nginx 또는 Apache와 같은 역방향 프록시를 사용하여 트래픽을 애플리케이션으로 라우팅합니다.
