

Redis에서 일반적으로 사용되는 데이터 구조(구성 및 공유)

이 글은 Redis에 대한 관련 지식을 제공하며, 주로 일반적인 데이터 구조에 대한 관련 내용을 소개합니다. 가장 일반적으로 사용되는 5가지, 즉 문자열, 해시, 집합 및 순서가 있습니다. 모든 사람에게 도움이 되기를 바랍니다.

추천 학습: Redis 동영상 튜토리얼
Redis 일반 데이터 구조
Redis는 Redis에서 데이터에 액세스하는 데 가장 일반적으로 사용되는 5가지 데이터 구조를 제공합니다. String, Hash, list, set, 주문 세트(ZSET).
String
문자열 형식은 Redis의 가장 기본적인 데이터 구조입니다. 우선, 키는 모두 문자열 유형이고, 기타 여러 데이터 구조는 문자열 유형을 기반으로 구축되므로 문자열 유형은 다른 4가지 데이터 구조 학습의 기반을 마련할 수 있습니다. 문자열 유형의 값은 실제로 문자열(간단한 문자열, 복잡한 문자열(예: JSON, XML)), 숫자(정수, 부동 소수점 숫자) 또는 심지어 이진수(그림, 오디오, 비디오)일 수 있지만 값은 다음과 같습니다. 가장 큰 크기는 512MB를 초과할 수 없습니다.
(Redis는 C로 작성되었고, C에는 되는 문자열이 있지만 여러 가지 고려 사항으로 인해 Redis는 여전히 문자열 형식 자체를 구현합니다.)
작업 명령
set 값 설정
키 값 설정
set 명령에는 여러 가지 옵션이 있습니다.
ex 초: 키의 두 번째 수준 만료 시간을 설정합니다.
px 밀리초: 키의 만료 시간을 밀리초로 설정합니다.
nx: 키가 성공적으로 설정되고 추가에 사용되기 전에는 키가 존재하지 않아야 합니다(일반적으로 분산 잠금에 사용됨).
xx: nx와 달리 키를 성공적으로 설정하고 업데이트에 사용하려면 키가 존재해야 합니다.
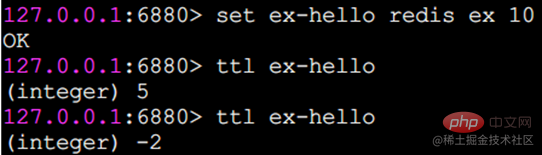
실행 효과에서 ex 매개변수는 기본적으로 만료 명령과 동일합니다. 특별한 주의가 필요한 또 다른 점은 문자열에 만료 시간이 설정되어 있고 이를 수정하기 위해 set 메서드를 호출하면 해당 만료 시간이 사라진다는 것입니다.
nx와 xx의 실행 효과는 다음과 같습니다
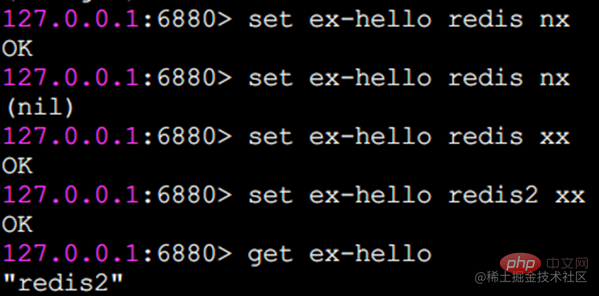
Redis는 set 옵션 외에도 setex 및 setnx 명령도 제공합니다.
setex 키 초 값
setnx 키 값
setex 및 setnx는 ex 및 nx 옵션과 동일한 기능을 갖습니다. 즉, setex는 키에 대한 두 번째 수준 만료 시간을 설정합니다. setnx를 설정할 때 키가 존재하지 않아야 성공적으로 설정할 수 있습니다.
setex 예:

setnx 예:
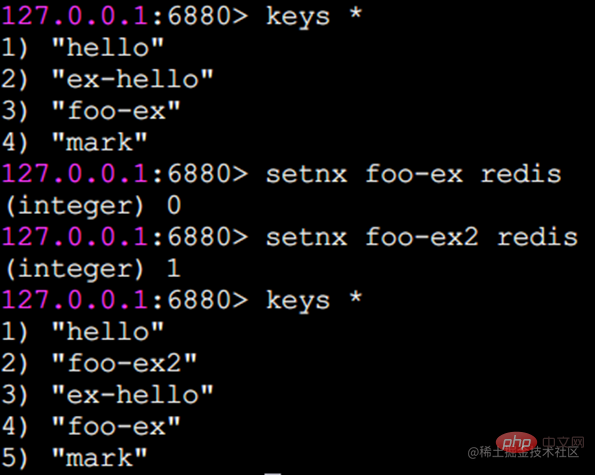
foo-ex 키가 이미 존재하므로 setnx는 실패하고 반환 결과는 0입니다. foo-ex2 키가 존재하지 않으므로 setnx는 성공하고 반환 결과는 1 입니다.
응용 시나리오가 있습니까? Redis의 단일 스레드 명령 처리 메커니즘으로 인해 여러 클라이언트가 동시에 setnx 키 값을 실행하는 경우 setnx 명령을 예로 들어 보겠습니다. Setnx의 특징은 분산 잠금을 위한 구현 솔루션으로 사용될 수 있습니다. 물론 분산 잠금에는 하나의 명령만 필요한 것은 아닙니다. 주의할 점이 많습니다. Redis 기반의 분산 잠금에 대해서는 나중에 별도의 장을 사용하여 설명하겠습니다.
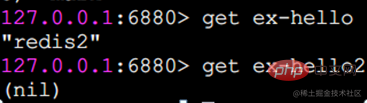
get 값 가져오기
얻을 키가 존재하지 않으면 nil(비어 있음)을 반환합니다.
mset 값을 일괄 설정
한 번에 4개의 키-값 쌍을 설정합니다. mset 명령을 통해

mget은 일괄적으로 값을 얻습니다
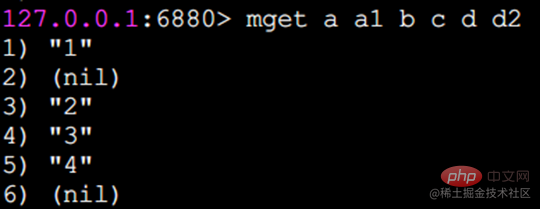
키 a, b, c, d의 값을 일괄로 얻습니다.
일부 키가 존재하지 않는 경우 이면 해당 값은 nil(비어 있음)이고 결과는 전달된 대로입니다. 키를 입력한 순서가 반환됩니다.
Mget과 같은 명령이 없는 경우, n get 명령을 실행하는 데 필요한 구체적인 시간은 다음과 같습니다.
n get 회 = n 네트워크 회 + n 명령 회
mget 사용 후 명령에서 n get 명령 작업을 실행하는 데 필요한 특정 시간은 다음과 같습니다.
n get 시간 = 1 네트워크 시간 + n 명령 시간
Redis는 초당 수만 번의 읽기 및 쓰기 작업을 지원할 수 있지만 이는 Redis 서버의 처리 능력을 의미하며, 명령에는 네트워크 시간도 있습니다. 1밀리초, 명령 시간은 0.1밀리초(초당 10,000개의 명령 처리 기준), 1000개의 get 명령을 실행하는 데 1.1초(10001+10000.1=1100ms), 1 mget 명령에 0.101초( 11+1000 0.1=101ms).
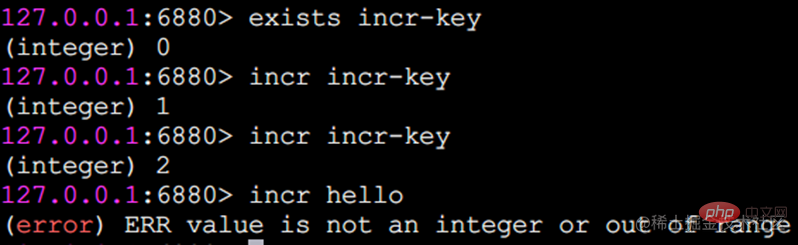
Incr 숫자 연산
incr 명령은 값을 증가시키는 데 사용됩니다. 반환된 결과는 세 가지 상황으로 구분됩니다.
값이 정수가 아니며 오류가 반환됩니다.
값은 정수이며, 증가시킨 후의 결과를 반환합니다.
키가 존재하지 않습니다. 0 값에 따라 증가하고 반환되는 결과는 1입니다.
incr 명령 외에도 Redis는 decr(자동 감소), incrby(지정된 숫자로 자동 증가), decrby(지정된 숫자로 자동 감소) 및 incrbyfloat(자동 증가)를 제공합니다. 부동 소수점 숫자) 특정 효과를 직접 시도해 보십시오. Append Append Append CommandAppend는 StringStrlen String Length의 끝까지 값을 추가 할 수 있습니다. String Length inturns : 각 중국어 문자는 3 바이트를 차지합니다.
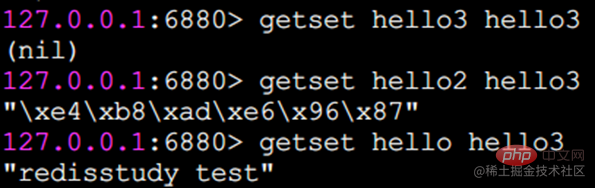
getset은 원래 값을 설정하고 반환합니다.
getset은 set과 마찬가지로 값을 설정하지만 차이점은 키의 원래 값도 반환한다는 것입니다.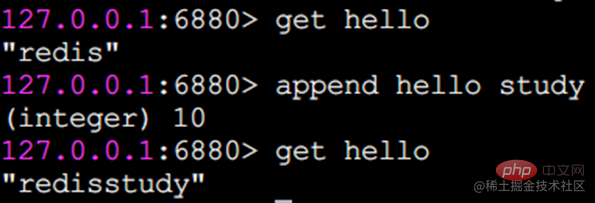
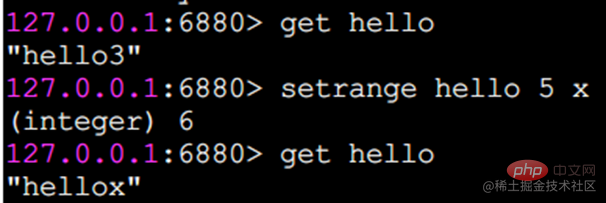
setrange는 지정된 위치에 문자를 설정합니다
아래 첨자는 0부터 시작합니다. 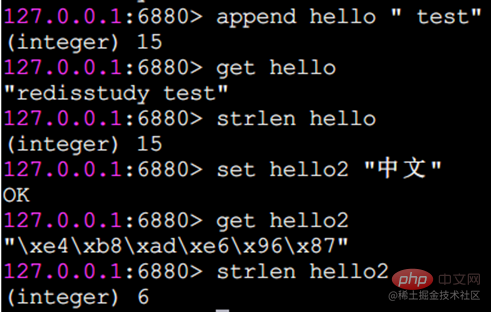
getrange는 문자열을 가로챕니다.
getrange는 문자열의 일부를 가로채서 하위 문자열을 형성합니다. 가로채는 범위는 닫힌 간격입니다.
 명령의 시간 복잡도
명령의 시간 복잡도
String 여러 키의 일괄 작업을 지원하는 del, mset, mget 명령을 제외한 명령 중 시간 복잡도는 키 수, 즉 O(n)과 관련이 있습니다. getrange는 문자열 길이와 관련이 있으며 또한 O(n)입니다. 나머지 명령은 기본적으로 O(1)의 시간 복잡도를 가지며 이는 여전히 매우 빠릅니다.
사용 시나리오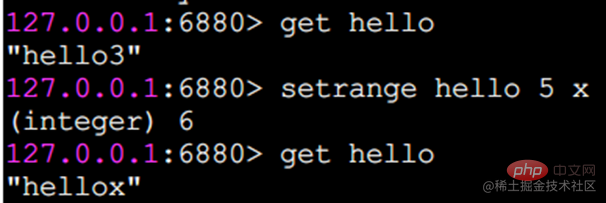
문자열 유형에는 다양한 사용 시나리오가 있습니다.
캐시 기능
Redis는 캐시 계층으로, MySQL은 스토리지 계층으로, 요청된 데이터의 대부분은 Redis에서 가져옵니다. Redis는 높은 동시성을 지원하는 특성을 가지고 있으므로 캐싱은 일반적으로 읽기 및 쓰기 속도를 높이고 백엔드 부담을 줄이는 역할을 할 수 있습니다.
 Counting
Counting
Redis를 계산의 기본 도구로 사용하면 빠른 계산 및 쿼리 캐싱 기능을 실현할 수 있으며 데이터를 다른 데이터 소스에 비동기적으로 전달할 수 있습니다.
공유 세션
분산형 웹 서비스는 사용자의 세션 정보(예: 사용자 로그인 정보)를 자체 서버에 저장하므로 로드 밸런싱을 고려하여 분산형 서비스는 사용자의 세션 정보( 사용자 로그인 정보 등) 액세스가 다른 서버에 균형을 이루고 있습니다. 액세스를 새로 고치는 사용자는 이 문제를 참을 수 없습니다.
이 문제를 해결하기 위해 Redis를 사용하여 사용자 세션을 중앙에서 관리할 수 있습니다. 이 모드에서는 Redis가 가용성과 확장성이 뛰어난 한 사용자가 로그인 정보를 업데이트하거나 쿼리할 때마다 Redis에서 직접 가져옵니다. .속도 제한
예를 들어, 보안상의 이유로 많은 애플리케이션에서는 사용자가 본인인지 확인하기 위해 로그인할 때마다 휴대폰 인증 코드를 입력하도록 사용자에게 요청합니다. 그러나 SMS 인터페이스에 자주 액세스하는 것을 피하기 위해 사용자가 분당 인증 코드를 받는 빈도는 분당 5회 이하로 제한됩니다. 일부 웹사이트에서는 IP 주소가 1초에 n번 이상 요청되지 않도록 제한하며 유사한 아이디어를 채택할 수 있습니다.Hash
Java는 HashMap을 제공하고 Redis도 비슷한 데이터 구조를 가지고 있는데, 바로 해시형입니다. 하지만 해시 유형의 매핑 관계를 필드-값이라고 합니다. 여기서 값은 키에 해당하는 값이 아니라 필드에 해당하는 값을 의미합니다. 연산 명령기본적으로 해시 연산 명령은 문자열 연산 명령과 매우 유사합니다. 많은 명령이 문자열 유형 명령 앞에 문자 h를 추가하는데, 이는 해시 유형이 연산된다는 의미와 동시에 시간이면 작업할 필드의 값을 지정해야 합니다.
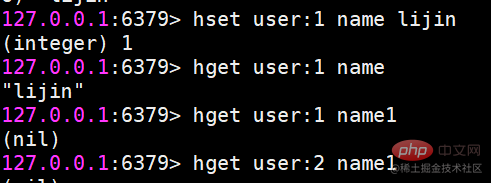
hset 설정값hset 사용자:1 이름 lijin
설정이 성공하면 1을 반환하고, 그렇지 않으면 0을 반환합니다. 또한 Redis는 hsetnx 명령을 제공합니다. 해당 관계는 범위가 키에서 필드로 변경된다는 점을 제외하면 set 및 setnx 명령과 동일합니다.
hget value
hget user:1 name
키나 필드가 없으면 nil이 반환됩니다.
hdel delete field
hdel은 하나 이상의 필드를 삭제하며 반환 결과는 성공적으로 삭제된 필드의 수입니다.
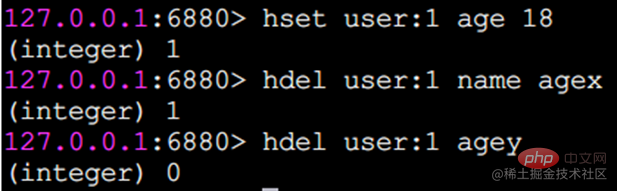
hlen은 필드 수를 계산합니다
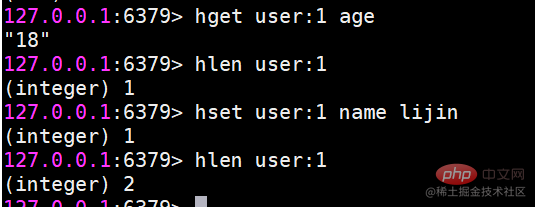
hmset는 값을 배치로 설정합니다

hmget은 값을 배치로 가져옵니다

hexists는 필드가 존재하는지 확인합니다
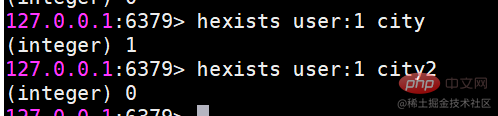
만약 존재하지 않으면 1을 반환합니다. 0을 반환합니다.
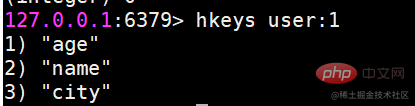
hkeys는 모든 필드를 가져옵니다.
지정된 해시 키가 있는 모든 필드를 반환합니다.
hvals는 모든 값을 가져옵니다.
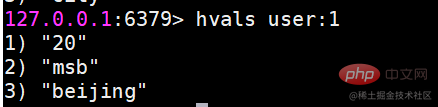
hgetall은 모든 필드와 값을 가져옵니다.
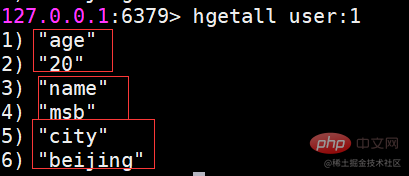
hgetall을 사용할 때 해시 요소의 개수가 상대적으로 많으면 Redis를 차단할 가능성이 있습니다. 필드의 일부만 가져와야 하는 경우 hmget을 사용할 수 있습니다. 모든 필드 값을 가져와야 하는 경우 hscan 명령을 사용할 수 있습니다. 이 명령은 이후 장에서 hscan을 점진적으로 탐색합니다. .
hincrby는 incrby 및 incrbyfloat 명령과 마찬가지로
hincrby 및 hincrbyfloat를 추가하지만 해당 범위는 지정됩니다.
hstrlen 값의 문자열 길이를 계산합니다
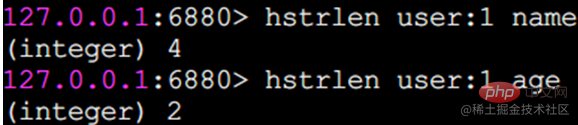
명령의 시간 복잡도
해시형 연산 명령에서 hdel, hmget, hmset의 시간 복잡도는 명령의 필드 수와 관련이 있습니다. O( k ), hkeys, hgetall, hvals는 저장된 총 필드 수 O(N)과 관련됩니다. 나머지 명령의 시간 복잡도는 O(1)입니다.
사용 시나리오
이전 작업에서 볼 수 있듯이 String과 Hash의 작업은 매우 유사하므로 저장용 해시를 생성해야 하는 이유는 무엇입니까?
해시 유형은 데이터베이스의 테이블 레코드에 있는 사용자가
| id | name | age |
|---|---|---|
| 1인 경우 비교할 수 있습니다. | lijin | 18 |
| 2 | msb | 20 |
1. 문자열 유형을 사용하려면
하나씩 삽입하고 검색해야 합니다.
set user:1:name lijin;
set user:1:age 18;
set user:2:name msb;
set user:2:age 20;
장점: 간단하고 직관적이며 각각 키는 값에 해당합니다
단점: 키가 너무 많고 메모리를 많이 차지하며 사용자 정보가 너무 분산되어 프로덕션 환경에서 사용되지 않습니다
2. 객체를 직렬화하여 redis에 저장합니다
set user:1 serialize( userInfo);
장점: 간단한 프로그래밍, 직렬화가 사용되는 경우 높은 메모리 사용량
단점: 직렬화 및 역직렬화에는 특정 오버헤드가 있으며, 속성을 업데이트할 때 모든 userInfo를 제거해야 합니다. 업데이트 후 redis
로 직렬화합니다. 해시 유형을 사용하세요
hmset user:1 name lijin age 18
hmset user:2 name msb age 20
장점: 간단하고 직관적입니다. 메모리 소모를 줄일 수 있습니다
단점: 내부 인코딩 형식을 제어하기 위해 부적절한 형식은 더 많은 메모리를 소모합니다
List(list)
list(list) 유형은 여러 개의 정렬된 문자열을 저장하는 데 사용됩니다. 요소, b, c, c 및 b는 왼쪽에서 오른쪽으로 순서가 지정된 목록을 형성합니다. 목록의 각 문자열을 요소라고 합니다. 목록은 최대 (2^32-1)개의 요소(4294967295)를 저장할 수 있습니다.

Redis에서는 목록의 양쪽 끝을 삽입(푸시) 및 팝(팝)할 수 있고, 지정된 범위의 요소 목록을 가져오고, 지정된 인덱스 첨자가 있는 요소를 가져오는 등의 작업도 가능합니다. 리스트는 스택과 큐 역할을 할 수 있고 실제 개발에서 많은 응용 시나리오를 가질 수 있는 비교적 유연한 데이터 구조입니다.
목록 유형에는 두 가지 특징이 있습니다.
첫째, 목록의 요소는 순서가 지정됩니다. 즉, 색인 첨자를 통해 특정 범위의 요소 또는 요소 목록을 얻을 수 있습니다.
둘째, 목록의 요소는 반복될 수 있습니다.
작업 명령
lrange 지정된 범위 내의 요소 목록을 가져옵니다(요소는 삭제되지 않음)
key start end
색인 아래 첨자 기능: 왼쪽에서 오른쪽으로 0~N-1
lrange 0 -1 명령 목록의 모든 요소를 왼쪽에서 오른쪽으로 가져옵니다
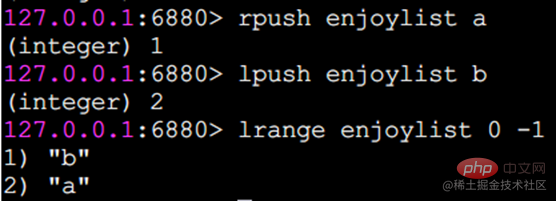
rpush 오른쪽에 삽입
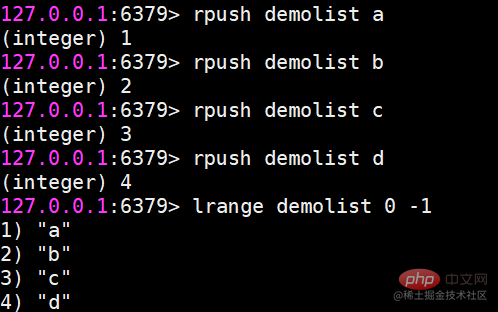
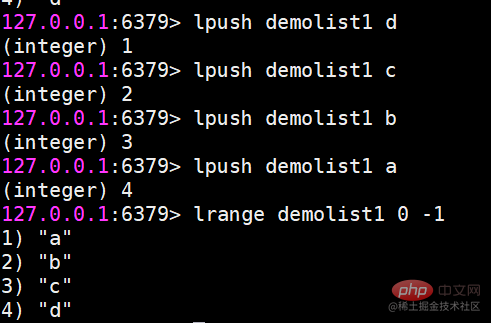
lpush 왼쪽에 삽입
linsert 요소 앞이나 뒤에 새 요소 삽입
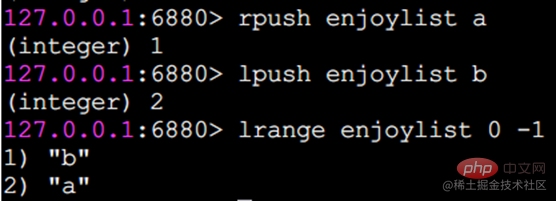
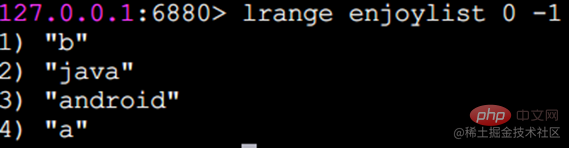
이 세 가지 반환 결과는 명령이 완료된 후 현재 목록의 길이, 즉 목록에 포함된 요소의 수입니다. 동시에 rpush와 lpush는 모두 여러 삽입을 지원합니다. 동시에 요소.
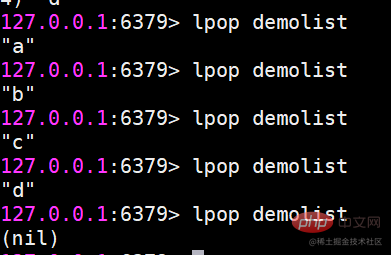
lpop은 목록 왼쪽에서 팝업됩니다. (요소가 삭제됩니다.)
 r
r
팝업 후 해당 요소는 사라집니다.
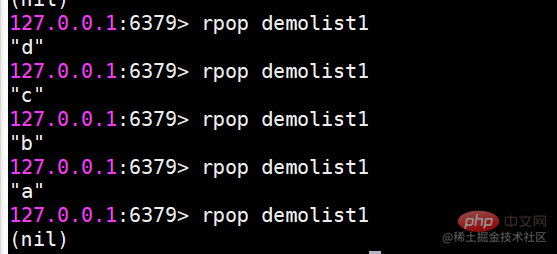
rpop 목록 오른쪽에서 팝
rpop은 목록의 맨 오른쪽에 d 요소를 팝업합니다.
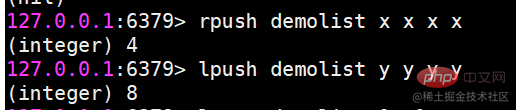
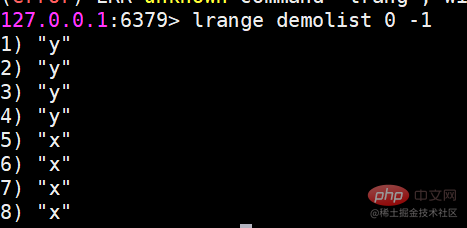
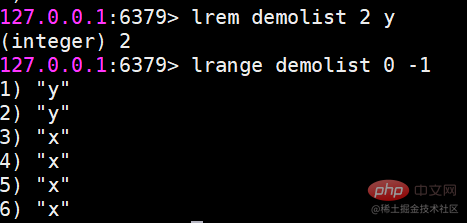
lrem 지정된 요소 삭제

lrem 명령은 목록에서 값과 동일한 요소를 찾아 삭제합니다. 개수에 따라 세 가지 상황으로 구분됩니다. 왼쪽부터
count>0. 오른쪽으로 최대 개수의 요소를 삭제합니다.
count
count=0, 모두 삭제하세요.
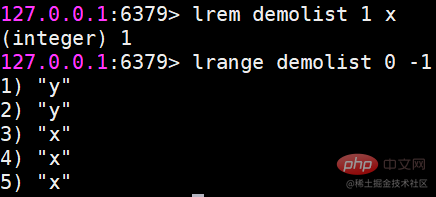
반환 값은 실제로 삭제된 요소의 수입니다.
ltirm은 인덱스 범위에 따라 목록을 자릅니다
예를 들어 목록의 0번째부터 첫 번째 요소를 유지하려는 경우
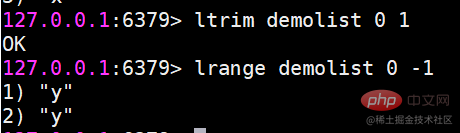 ls
ls
lset는 지정된 인덱스 첨자로 요소를 수정합니다
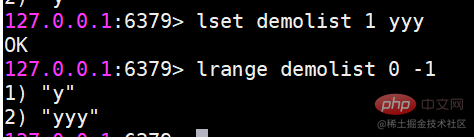
lindex 목록의 지정된 인덱스 첨자가 있는 요소를 가져옵니다
 l
l
llen 목록 길이 가져오기

blpop 및 brpop 차단 팝업 요소
blpop 및 brpop은 lpop 및 rpop의 버전도 차단합니다. , 또한 여러 목록 유형을 지원하고 차단 시간(초)도 지원합니다. 차단 시간이 0이면 계속 차단된다는 의미입니다. brpop을 예로 들어보겠습니다.
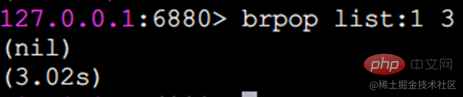
클라이언트가 차단되었습니다(요소가 없으면 차단되므로)

클라이언트는 항상 차단됩니다. 이때 다른 클라이언트 B에서

A 클라이언트를 실행하고

을 출력합니다. 참고: brpop 뒤에 키가 여러 개 있으면 brpop은 키가 있으면 왼쪽에서 오른쪽으로 키를 순회합니다. , 요소를 팝하면 클라이언트가 즉시 반환됩니다.
사용 시나리오
목록 유형은 다음과 같이 사용할 수 있습니다.
메시지 대기열, Redis lpush+brpop 명령 조합은 차단 대기열을 실현할 수 있으며 생산자 클라이언트는 lrpush를 사용하여 목록 왼쪽의 요소를 삽입합니다. 소비자 클라이언트 brpop 명령을 사용하여 목록 끝에 있는 요소를 차단 방식으로 "잡아" 여러 클라이언트가 로드 밸런싱과 높은 소비 가용성을 보장합니다.
기사 목록
각 사용자는 자신만의 기사 목록을 가지고 있으며 이제 기사 목록을 페이지에 표시해야 합니다. 이때 리스트 사용을 고려해 볼 수 있는 이유는 리스트는 순서가 정해져 있을 뿐만 아니라 인덱스 범위에 따른 요소 획득도 지원하기 때문이다.
다른 데이터 구조 구현
lpush+lpop =Stack(스택)
lpush +rpop =Queue(큐)
lpsh+ ltrim =Capped Collection(제한된 컬렉션)
lpush+brpop=Message Queue(메시지 큐)
Set

세트형도 여러 개의 문자열 요소를 저장할 때 사용하는데 리스트형과 달리 세트에 중복된 요소가 허용되지 않으며, 세트에 포함된 요소가 없음 순서대로 요소를 얻을 수 없습니다. 색인 첨자.
컬렉션에는 최대 2~32제곱(1개의 요소)을 저장할 수 있습니다. 컬렉션 내에서 추가, 삭제, 수정 및 쿼리를 지원하는 것 외에도 Redis는 여러 컬렉션의 교차, 합집합 및 차이 집합을 지원합니다. 컬렉션 유형을 적절하게 사용하면 실제 개발 시 많은 실제 문제를 해결할 수 있습니다.
In-set 작업 명령
sadd 요소 추가
여러 요소를 추가할 수 있으며, 반환 결과는 성공적으로 추가된 요소의 수입니다.

srem 요소 삭제
여러 요소를 삭제할 수 있으며, 반환 결과는 다음과 같습니다. 성공적으로 삭제된 요소 수

scard 요소 수 계산

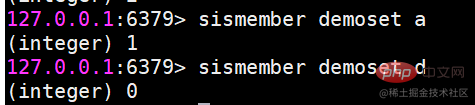
sismember 해당 요소가 집합에 있는지 확인
주어진 요소 요소가 집합에 있으면 1을 반환하고 그렇지 않으면 0을 반환
srandmember 집합 Count 요소에서 지정된 개체를 무작위로 반환합니다.
숫자를 지정하지 않으면 기본값은 1
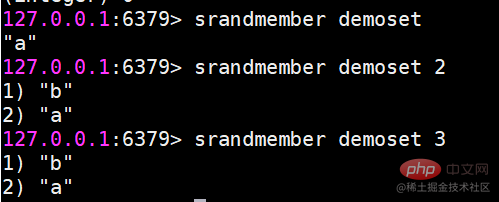
spop은 컬렉션에서 요소를 무작위로 팝합니다.
숫자를 지정할 수도 있습니다. 지정하지 않으면 기본값은 1입니다. 팝핑 중이므로 spop 명령이 실행된 후에는 컬렉션에서 요소가 삭제됩니다. srandmember는 그렇지 않습니다.

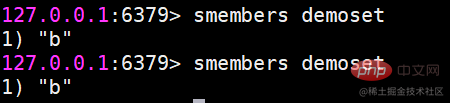
smembers 모든 요소 가져오기(요소가 튀어나오지 않음)
반환된 결과는 순서가 없습니다
Inter-set 연산 명령
이제 두 세트가 있습니다. set1과 set2입니다
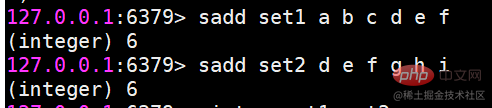
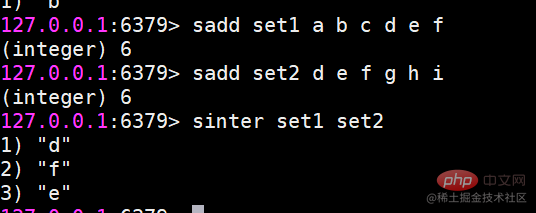
sinter 여러 집합의 교집합을 찾습니다
suinon 여러 집합의 합집합을 찾습니다
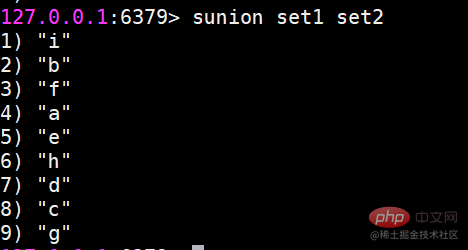
sdiff 여러 집합의 차이를 찾습니다
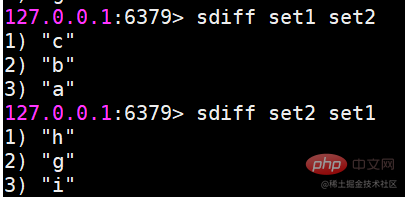
교집합, 합집합, 차이의 결과를 저장합니다
sinterstore destination key [key ...] suionstore destination key [key ...] sdiffstore destination key [key ...]复制代码
요소가 많을 때 세트 간 작업에 시간이 더 많이 걸리므로 Redis는 위의 세 가지 명령(원래 명령 + 저장)을 제공하여 세트 간 교집합, 합집합 및 차이의 결과를 대상 키에 저장합니다. 예:
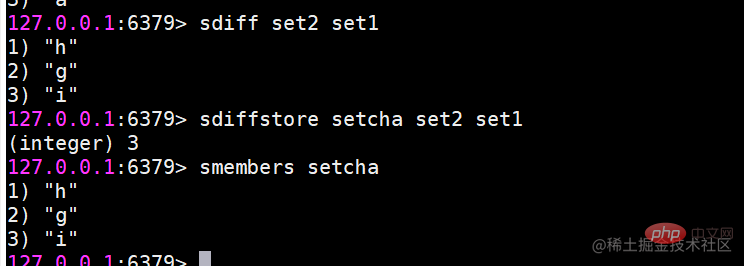
사용 시나리오
컬렉션 유형의 일반적인 사용 시나리오는 태그입니다. 예를 들어, 한 사용자는 엔터테인먼트와 스포츠에 관심이 있고 다른 사용자는 역사와 뉴스에 관심이 있을 수 있습니다. 이 데이터를 통해 우리는 동일한 태그를 좋아하는 사람들과 사용자들이 공통적으로 좋아하는 태그를 얻을 수 있습니다. 이 데이터는 사용자 경험과 사용자 접착력을 높이는 데 중요합니다.
예를 들어, 전자상거래 웹사이트는 다양한 라벨을 가진 사용자에게 다양한 유형의 추천을 제공합니다. 예를 들어, 디지털 제품에 더 관심이 있는 사람들은 일반적으로 다양한 페이지나 이메일을 통해 최신 디지털 제품을 추천합니다. 더 많은 혜택을 누리세요.
또한 컬렉션은 복권 활동, 소셜 그래프 등과 같은 활동에 대해 난수를 생성할 수도 있습니다.
Ordered Set(ZSET)

Ordered Set은 해시, 리스트, Set에 비해 조금 생소하지만 Ordered Set이라고 하기 때문에 반드시 Set과 연관되어 있어야 하고 Set을 유지하므로 Set은 중복된 멤버를 가질 수 없습니다. , 그러나 차이점은 순서가 지정된 세트의 요소를 정렬할 수 있다는 것입니다. 그러나 정렬 기준으로 색인 첨자를 사용하는 목록과 달리 각 요소에 대한 점수를 정렬 기준으로 설정합니다.
순서화된 세트의 요소는 반복될 수 없지만 점수는 반복될 수 있습니다. 마찬가지로 같은 반에 있는 동급생의 학생 수는 반복될 수 없지만 시험 점수는 동일할 수 있습니다.
정렬 집합은 지정된 점수 및 요소 범위 쿼리 가져오기, 멤버 순위 계산 등과 같은 기능을 제공합니다. 정렬 집합을 올바르게 사용하면 실제 개발에서 많은 문제를 해결하는 데 도움이 될 수 있습니다.
In-set 작업 명령
zadd는 멤버를 추가합니다
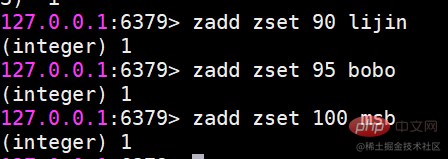
반환 결과는 성공적으로 추가된 멤버의 수를 나타냅니다.
참고:

zadd 명령에는 nx, xx, ch, incr 네 가지 옵션도 있습니다. 네 가지 옵션
nx: 추가를 위해 성공적으로 설정되려면 멤버가 존재하지 않아야 합니다.
xx: 성공적으로 설정하고 업데이트에 사용하려면 먼저 구성원이 있어야 합니다.
ch: 이 작업 이후에 변경된 순서 집합의 요소 수와 점수를 반환합니다.
incr: 점수를 높입니다. 이는 나중에 소개되는 아연rby
zcard 계산과 동일합니다.

zscore 계산 점수 of a member
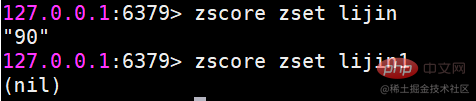
멤버가 존재하지 않으면 nil을 반환합니다.
zrank는 해당 멤버의 순위를 계산합니다
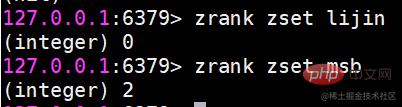
zrank是从分数从低到高返回排名
zrevrank反之
很明显,排名从0开始计算。
zrem 删除成员
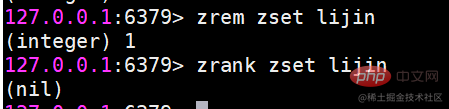
允许一次删除多个成员。
返回结果为成功删除的个数。
zincrby 增加成员的分数
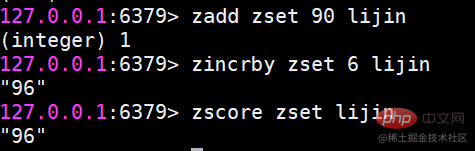
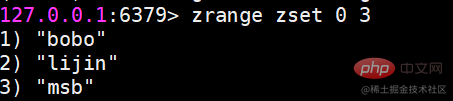
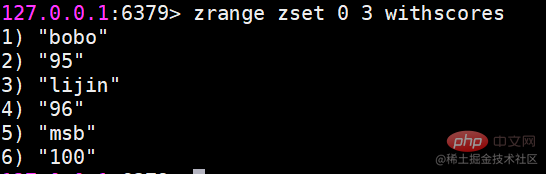
zrange和zrevrange返回指定排名范围的成员
有序集合是按照分值排名的,zrange是从低到高返回,zrevrange反之。如果加上 withscores选项,同时会返回成员的分数
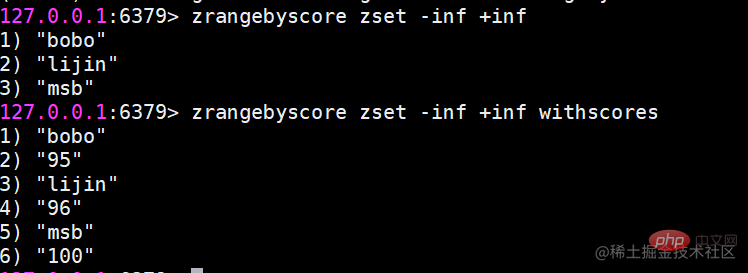
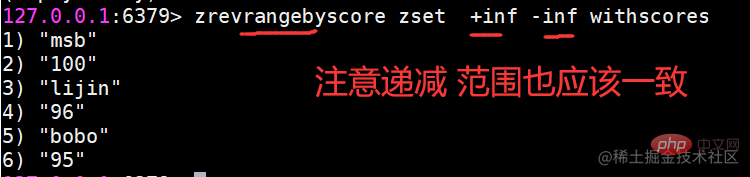
zrangebyscore返回指定分数范围的成员
zrangebyscore key min max [withscores] [limit offset count] zrevrangebyscore key max min [withscores][limit offset count]复制代码
其中zrangebyscore按照分数从低到高返回,zrevrangebyscore反之。例如下面操作从低到高返回200到221分的成员,withscores选项会同时返回每个成员的分数。
同时min和max还支持开区间(小括号)和闭区间(中括号),-inf和+inf分别代表无限小和无限大:

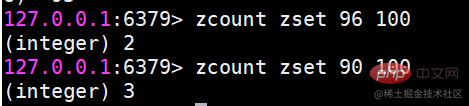
zcount 返回指定分数范围成员个数
zcount key min max
zremrangebyrank 按升序删除指定排名内的元素
zremrangebyrank key start end
zremrangebyscore 删除指定分数范围的成员
zremrangebyscore key min max
集合间操作命令
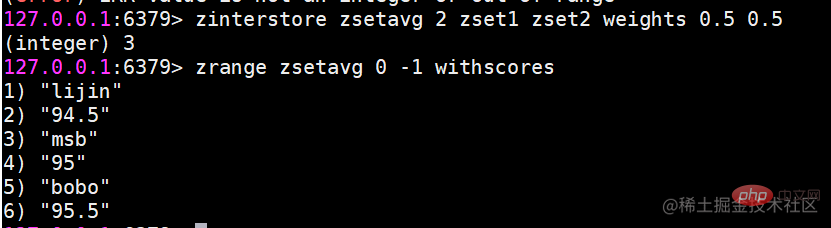
zinterstore 交集
zinterstore
这个命令参数较多,下面分别进行说明
destination:交集计算结果保存到这个键。
numkeys:需要做交集计算键的个数。
key [key ...]:需要做交集计算的键。
weights weight [weight ...]:每个键的权重,在做交集计算时,每个键中的每个member 会将自己分数乘以这个权重,每个键的权重默认是1。
aggregate sum/ min |max:计算成员交集后,分值可以按照sum(和)、min(最小值)、max(最大值)做汇总,默认值是sum。
不太好理解,我们用一个例子来说明。(算平均分)

zunionstore 并集
该命令的所有参数和zinterstore是一致的,只不过是做并集计算,大家可以自行实验。
使用场景
有序集合比较典型的使用场景就是排行榜系统。例如视频网站需要对用户上传的视频做排行榜,榜单的维度可能是多个方面的:按照时间、按照播放数量、按照获得的赞数。
持续创作,加速成长!这是我参与「掘金日新计划 · 10 月更文挑战」的第26天,点击查看活动详情
推荐学习:Redis视频教程
위 내용은 Redis에서 일반적으로 사용되는 데이터 구조(구성 및 공유)의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7471
7471
 15
1377
52
77
11
48
19
19
30
15
1377
52
77
11
48
19
19
30

 Redis 클러스터 모드를 구축하는 방법
Apr 10, 2025 pm 10:15 PM
Redis 클러스터 모드를 구축하는 방법
Apr 10, 2025 pm 10:15 PM
Redis Cluster Mode는 Sharding을 통해 Redis 인스턴스를 여러 서버에 배포하여 확장 성 및 가용성을 향상시킵니다. 시공 단계는 다음과 같습니다. 포트가 다른 홀수 redis 인스턴스를 만듭니다. 3 개의 센티넬 인스턴스를 만들고, Redis 인스턴스 및 장애 조치를 모니터링합니다. Sentinel 구성 파일 구성, Redis 인스턴스 정보 및 장애 조치 설정 모니터링 추가; Redis 인스턴스 구성 파일 구성, 클러스터 모드 활성화 및 클러스터 정보 파일 경로를 지정합니다. 각 redis 인스턴스의 정보를 포함하는 Nodes.conf 파일을 작성합니다. 클러스터를 시작하고 Create 명령을 실행하여 클러스터를 작성하고 복제본 수를 지정하십시오. 클러스터에 로그인하여 클러스터 정보 명령을 실행하여 클러스터 상태를 확인하십시오. 만들다
 기본 Redis를 구현하는 방법
Apr 10, 2025 pm 07:21 PM
기본 Redis를 구현하는 방법
Apr 10, 2025 pm 07:21 PM
Redis는 해시 테이블을 사용하여 데이터를 저장하고 문자열, 목록, 해시 테이블, 컬렉션 및 주문한 컬렉션과 같은 데이터 구조를 지원합니다. Redis는 Snapshots (RDB)를 통해 데이터를 유지하고 WRITE 전용 (AOF) 메커니즘을 추가합니다. Redis는 마스터 슬레이브 복제를 사용하여 데이터 가용성을 향상시킵니다. Redis는 단일 스레드 이벤트 루프를 사용하여 연결 및 명령을 처리하여 데이터 원자력과 일관성을 보장합니다. Redis는 키의 만료 시간을 설정하고 게으른 삭제 메커니즘을 사용하여 만료 키를 삭제합니다.
 Redis-Server를 찾을 수없는 경우해야 할 일
Apr 10, 2025 pm 06:54 PM
Redis-Server를 찾을 수없는 경우해야 할 일
Apr 10, 2025 pm 06:54 PM
Redis-Server가 찾을 수없는 문제를 해결하기위한 단계 : Redis가 올바르게 설치되어 있는지 확인하십시오. 환경 변수를 설정 redis_host 및 redis_port; Redis Server Redis-Server를 시작하십시오. 서버가 Redis-Cli Ping을 실행 중인지 확인하십시오.
 Redis에서 모든 키를 보는 방법
Apr 10, 2025 pm 07:15 PM
Redis에서 모든 키를 보는 방법
Apr 10, 2025 pm 07:15 PM
Redis에서 모든 키를 보려면 세 가지 방법이 있습니다. 키 명령을 사용하여 지정된 패턴과 일치하는 모든 키를 반환하십시오. 스캔 명령을 사용하여 키를 반복하고 키 세트를 반환하십시오. 정보 명령을 사용하여 총 키 수를 얻으십시오.
 Redis의 버전 번호를 보는 방법
Apr 10, 2025 pm 05:57 PM
Redis의 버전 번호를 보는 방법
Apr 10, 2025 pm 05:57 PM
Redis 버전 번호를 보려면 다음 세 가지 방법을 사용할 수 있습니다. (1) info 명령을 입력하고 (2) -version 옵션으로 서버를 시작하고 (3) 구성 파일을 봅니다.
 Redis의 소스 코드를 읽는 방법
Apr 10, 2025 pm 08:27 PM
Redis의 소스 코드를 읽는 방법
Apr 10, 2025 pm 08:27 PM
Redis 소스 코드를 이해하는 가장 좋은 방법은 단계별로 이동하는 것입니다. Redis의 기본 사항에 익숙해집니다. 특정 모듈을 선택하거나 시작점으로 기능합니다. 모듈 또는 함수의 진입 점으로 시작하여 코드를 한 줄씩 봅니다. 함수 호출 체인을 통해 코드를 봅니다. Redis가 사용하는 기본 데이터 구조에 익숙해 지십시오. Redis가 사용하는 알고리즘을 식별하십시오.
 Redis 명령을 사용하는 방법
Apr 10, 2025 pm 08:45 PM
Redis 명령을 사용하는 방법
Apr 10, 2025 pm 08:45 PM
Redis 지시 사항을 사용하려면 다음 단계가 필요합니다. Redis 클라이언트를 엽니 다. 명령 (동사 키 값)을 입력하십시오. 필요한 매개 변수를 제공합니다 (명령어마다 다름). 명령을 실행하려면 Enter를 누르십시오. Redis는 작업 결과를 나타내는 응답을 반환합니다 (일반적으로 OK 또는 -err).
 Redis Zset을 사용하는 방법
Apr 10, 2025 pm 07:27 PM
Redis Zset을 사용하는 방법
Apr 10, 2025 pm 07:27 PM
Redis 순서 세트 (ZSETS)는 순서가있는 요소를 저장하고 관련 점수별로 정렬하는 데 사용됩니다. ZSET을 사용하는 단계에는 다음이 포함됩니다. 1. ZSET을 만듭니다. 2. 회원 추가; 3. 회원 점수를 얻으십시오. 4. 순위를 얻으십시오. 5. 순위 범위에서 멤버를 받으십시오. 6. 회원 삭제; 7. 요소 수를 얻으십시오. 8. 점수 범위에서 멤버 수를 얻으십시오.
