

Linux는 가상 메모리를 구현하기 위해 무엇을 사용합니까?

가상 메모리 구현은 세 가지 구현 방법을 기반으로 해야 합니다. 1. 요청 분할 저장소 관리 방법 3. 세그먼트 페이지 저장소 관리 방법. 어떤 방법을 사용하든 특정 하드웨어 지원이 필요합니다. 1. 특정 용량의 메모리 및 외부 메모리 2. 기본 데이터 구조인 페이지 테이블 메커니즘(또는 세그먼트 테이블 메커니즘) 3. 사용자가 인터럽트할 때 메커니즘 프로그램 필요 액세스된 부분이 아직 메모리로 전송되지 않은 경우 인터럽트가 발생합니다. 4. 주소 변환 메커니즘, 논리 주소에서 물리적 주소로 변환.

이 튜토리얼의 운영 환경: linux7.3 시스템, Dell G3 컴퓨터.
1. 가상 메모리 개요
기존 스토리지 관리에서는 여러 프로세스를 동시에 메모리에 저장하여 다중 프로그래밍이 가능합니다. 모두 다음과 같은 두 가지 공통 특성을 가지고 있습니다.
따라서 프로그램 운영 중 사용하지 않거나 일시적으로 사용하지 않는 많은 프로그램(데이터)이 많은 메모리 공간을 차지하고, 실행해야 하는 일부 작업을 로드하여 실행할 수 없어 귀중한 메모리 자원이 낭비되는 것은 당연합니다. .
- 일회성: 작업은 실행을 시작하기 전에 한 번에 메모리에 로드되어야 합니다. 이로 인해 다음 두 가지 상황이 발생합니다. 1) 작업이 커서 메모리에 로드할 수 없는 경우 작업을 실행할 수 없습니다.
2) 메모리가 부족하여 많은 수의 작업을 실행해야 하는 경우 모든 작업을 수용할 수 있을 만큼 충분하지만 몇 가지 작업만 먼저 실행되어 다중 프로그래밍이 줄어들 수 있습니다.
- 상주: 작업이 메모리에 로드된 후에는 항상 메모리에 상주하며 작업이 완료될 때까지 어떤 부분도 교체되지 않습니다. 실행 중인 프로세스는 I/O를 기다리면서 차단되며 장기간 대기 상태에 있을 수 있습니다.
1.1 가상 메모리의 정의와 특징
지역성원리에 따라 프로그램이 로드되면 프로그램의 일부만 메모리에 로드하고 나머지는 외부 메모리에 남겨두면 됩니다. . 프로그램 실행을 시작합니다. 프로그램 실행 중 접근한 정보가 메모리에 없으면 운영체제는 필요한 부분을 메모리로 옮긴 후 프로그램을 계속 실행합니다. 반면, 운영 체제는 메모리에서 일시적으로 사용되지 않는 콘텐츠를 외부 메모리로 교체하여 메모리로 전송될 정보를 저장할 공간을 확보합니다. 이렇게 시스템이
부분 로딩, 요청 로딩, 교체 기능(사용자에게 완전히 투명함)을 제공하기 때문에 사용자는 실제 물리적 메모리보다 훨씬 큰 메모리가 있는 것처럼 느끼게 됩니다. 가상 메모리. 가상 메모리의 크기는 컴퓨터의 주소 구조
에 따라 결정되며, 메모리와 외부 메모리의 단순한 합이 아닙니다.가상 메모리는 다음과 같은 세 가지 주요 특징을 가지고 있습니다.
여러 번
- : 작업 실행 시 메모리를 한꺼번에 로드할 필요는 없지만 여러 번 나누어 로드할 수 있습니다. 실행을 위해 메모리에 저장됩니다.
- Swapability : 작업이 실행되는 동안 메모리에 머물 필요는 없지만 작업 실행 프로세스 중에 교체가 가능합니다.
- Virtuality : 사용자가 보는 메모리 용량이 실제 메모리 용량보다 훨씬 크도록 메모리 용량을 논리적으로 확장합니다.
가상 메모리를 사용하면 작업을 메모리로 여러 번 전송할 수 있습니다
.연속 할당 방식을 사용하면 메모리 공간의 상당 부분이 일시적이거나 "영구적으로" 유휴 상태가 되어 심각한 메모리 자원 낭비를 초래하게 되며, 논리적으로 메모리 용량을 확장할 수 없게 됩니다.
따라서 가상 메모리 구현은 이산 할당메모리 관리 방법을 기반으로 해야 합니다. 가상 메모리를 구현하는 방법에는 세 가지가 있습니다.
요청 페이징- 스토리지 관리
- 요청 분할 스토리지 관리
- 세그먼트 페이징 스토리지 관리
- 어떤 방법이든 특정 요구 사항이 필요합니다. 하드웨어 지원
일정량의 메모리 및 외부 저장소.
- 페이지 테이블 메커니즘(또는 세그먼트 테이블 메커니즘)을 기본 데이터 구조로 사용합니다.
- 인터럽트 메커니즘은 사용자 프로그램이 액세스할 부분이 메모리로 전송되지 않은 경우 인터럽트가 생성됩니다.
- 주소 변환 메커니즘, 논리 주소를 실제 주소로 변환합니다.
연속 할당 방법: 사용자 프로그램에 연속적인 메모리 공간을 할당하는 것을 말합니다.
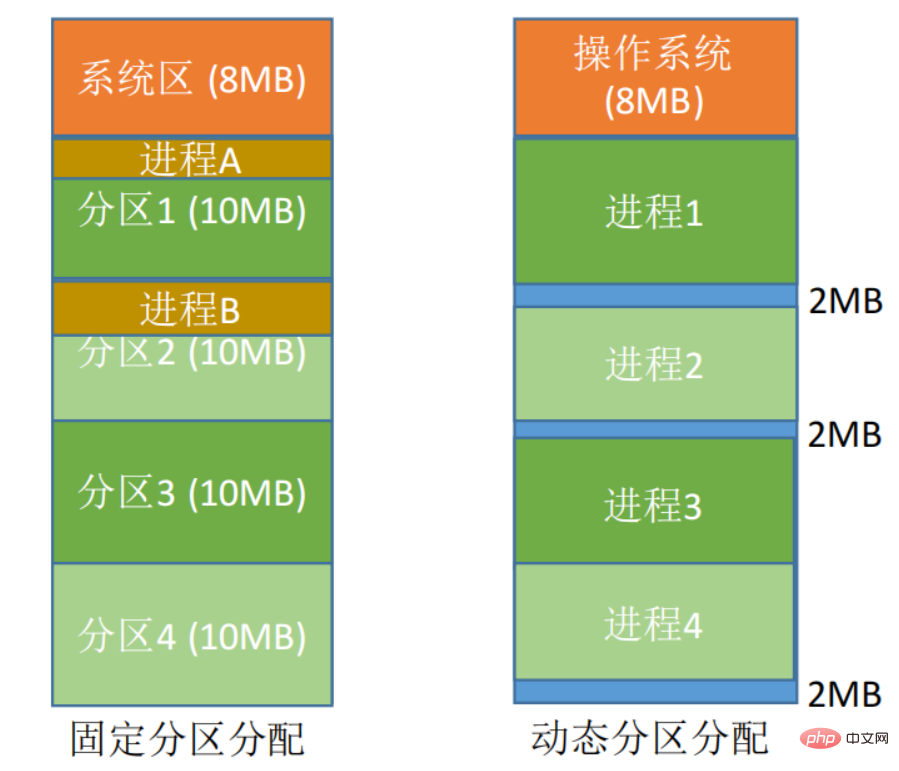
- 고정 파티션 할당: 메모리 공간을 여러 고정 크기 영역으로 나눕니다. 각 파티션에는 하나의 작업만 로드되며 여러 작업을 동시에 실행할 수 있습니다. 유연성이 부족하면 내부 조각이 많이 발생하고 메모리 활용도가 매우 낮습니다.
- 동적 파티션 할당: 실제 필요에 따라 프로세스에 메모리 공간을 동적으로 할당합니다. 작업이 메모리에 로드되면 사용 가능한 메모리가 작업에 대한 연속 영역으로 나뉘며 파티션의 크기는 작업 크기에 딱 맞습니다. 외부 이물질이 많을 거에요.
이산 할당 방법: 프로세스를 인접하지 않은 여러 파티션에 분산 로드하여 메모리를 최대한 활용할 수 있습니다.
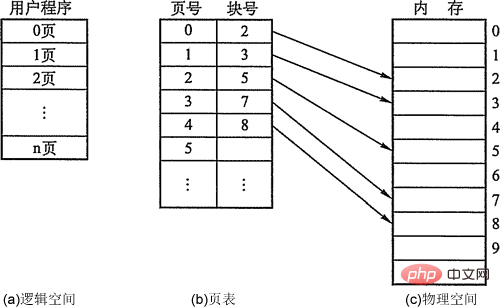
페이징 저장의 개념:은 현재 가상 메모리 구현에 가장 일반적으로 사용되는 방법입니다.페이지, 페이지 프레임 및 블록.
- process의 블록은 page 또는 페이지(Page)라고 하며, 페이지 번호가 있습니다. memory의 블록은 Page Frame이라고 합니다. (페이지 프레임, 페이지 프레임 = 메모리 블록 = 물리적 블록 = 물리적) 페이지 ), 페이지 프레임 번호 포함. 외부 저장소도 동일한 단위로 나누어져 있으며, 바로 Block이라고 합니다. 프로세스가 실행되면 주 메모리 공간을 적용해야 합니다. 즉, 각 페이지에는 주 메모리에서 사용 가능한 페이지 프레임이 할당되어야 하며, 이는 페이지와 페이지 프레임 간에 일대일 대응을 생성합니다. 각 페이지는 연속적으로 저장될 필요가 없으며 인접하지 않은 페이지 프레임에 배치될 수 있습니다.
- 주소 구조: 전자는 페이지 번호 P이고 후자는 페이지 내 오프셋 W입니다. 주소 길이는 32비트이며, 그 중 비트 0~11은 페이지 내 주소입니다. 즉, 각 페이지의 크기는 4KB입니다. 비트 12~31은 페이지 번호이고 주소 공간은 최대 2^20입니다. 페이지.
- 페이지 테이블. 프로세스의 각 페이지에 해당하는 물리 블록을 메모리에 쉽게 찾기 위해 시스템은 각 프로세스마다 페이지 테이블을 구축하여 해당 페이지에 해당하는 물리 블록 번호를 메모리에 기록하는 것이 일반적입니다. 메모리. . 페이지 테이블이 구성된 후 프로세스가 실행되면 테이블을 조회하여 메모리에 있는 각 페이지의 물리적 블록 번호를 알 수 있습니다. 페이지 테이블의 역할은 페이지 번호에서 물리적 블록 번호로의 주소 매핑을 구현하는 것임을 알 수 있습니다.
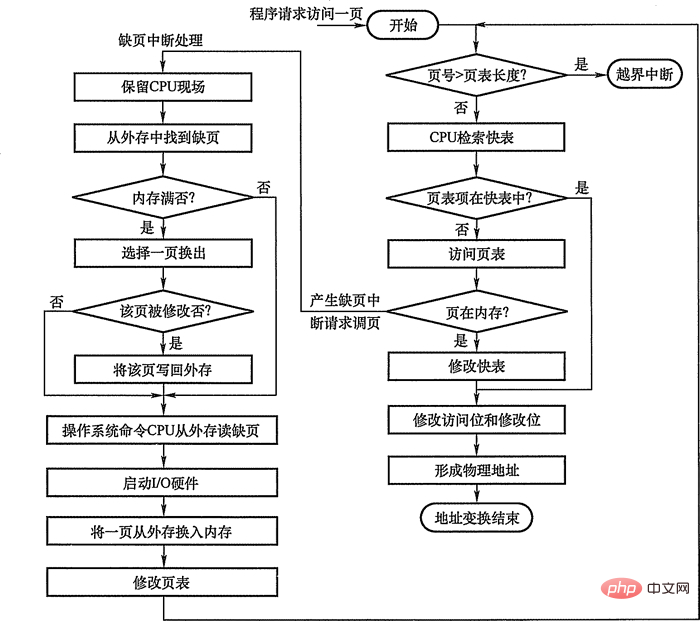
2. 가상 메모리 구현을 위한 요청 페이징 관리요청 페이징
요청 페이징 시스템은 기본 페이징 시스템
을 바탕으로 가상 메모리 기능을 지원하기 위해요청 페이징 기능과 페이지 교체
기능이 추가되었습니다.요청 페이징 시스템에서는 작업을 시작하기 전에 현재 필요한 페이지 중 일부만 메모리에 로드하면 됩니다. 작업 실행 중 액세스하려는 페이지가 메모리에 없으면 페이징 기능을 통해 가져올 수 있으며, 동시에 교체 기능을 통해 일시적으로 사용되지 않는 페이지를 외부 저장소로 교체할 수 있습니다. 메모리 공간을 확보하기 위해. 요청 페이징을 구현하려면 시스템에서 특정 하드웨어 지원을 제공해야 합니다. 일정량의 메모리와 외부 저장소
가 필요한 컴퓨터 시스템 외에도
도 필요합니다. 2.1 페이지 테이블 메커니즘
요청 페이징 시스템의 페이지 테이블 메커니즘은 기본 페이징 시스템과 다릅니다. 요청 페이징 시스템은 작업 전에 모든 데이터를 한 번에 메모리에 로드할 필요가 없습니다. 실행됩니다.따라서 작업 실행 과정에서 접근할 페이지가 메모리에 없는 상황이 필연적으로 발생하게 됩니다. 이러한 상황을 감지하고 처리하는 방법은 요청 페이징 시스템이 해결해야 하는 두 가지 기본 문제입니다. 이를 위해 요청 페이지 테이블 항목에 4개의 필드가 추가됩니다. 요청 페이징 시스템의 페이지 테이블 항목
페이지 번호| 상태 비트 P | 액세스 필드 A | 비트 M 수정 | 외부 저장 주소 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 0 | 1 | 2 | 0 | 3 | 0 | 4 | 2 | 3 | 0 | 3 | 2 | 1 | 2 | 0 | 1 | 7 | 0 | 1 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 7 | 7 | 2 | ㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋ | 7 | 물리 블록 2 |
0 | 0
0 |
0 |
4 |
0 |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
0 |
0 | 물리 블록 3 |
1 | 1
3 |
|
3 |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 1 | |
누락된 페이지 No | √
√ |
√ |
√ |
√ |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| √ | √ |
|
페이지 폴트 중단 횟수는 9회, 페이지 교체 횟수는 6회임을 알 수 있습니다. 3.2 FIFO(선입선출) 페이지 교체 알고리즘 메모리에 가장 먼저 들어간 페이지, 즉 메모리에 가장 오래 머물렀던 페이지를 제거하는 데 우선순위를 부여합니다. 이 알고리즘은 구현하기가 간단합니다. 순서에 따라 메모리로 전송된 페이지를queue에 연결하고 항상 가장 빠른 페이지를 가리키도록 포인터를 설정하면 됩니다. 그러나 이 알고리즘은 프로세스 중에 일부 페이지에 자주 액세스하기 때문에 프로세스의 실제 실행 규칙에는 적합하지 않습니다.
FIFO 알고리즘을 사용하면 최적 교체 알고리즘의 정확히 2배인 12번의 페이지 교체가 수행됩니다. FIFO 알고리즘에서도 할당된 물리적 블록 수가 증가하면 페이지 폴트 수가 감소하지 않고 증가하는 비정상적인 현상이 발생합니다. 이는 1969년 Belady가 발견하여 Belady anomaly라고 합니다. 아래 표에 나와 있습니다.
FIFO 알고리즘에서만 Belady 이상 현상이 발생할 수 있지만 LRU 및 OPT 알고리즘에서는 Belady 이상 현상이 발생하지 않습니다. 3.3 LRU(Least Recent Used) 교체 알고리즘 Least Recent Used(LRU, Least Recent Used)교체 알고리즘 선택가장 오랫동안 방문하지 않은 페이지는 삭제됩니다, 지난 기간에 방문하지 않은 페이지는 가까운 시일 내에 방문하지 않을 수 있다고 가정합니다. 이 알고리즘은 각 페이지에 대해 방문 필드를 설정하여 페이지에 마지막으로 액세스한 이후 경과된 시간을 기록합니다. 페이지를 제거할 때 제거할 기존 페이지 중에서 가장 큰 값을 가진 페이지를 선택합니다.
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
위 내용은 Linux는 가상 메모리를 구현하기 위해 무엇을 사용합니까?의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7540
7540
 15
1381
52
83
11
55
19
21
86
15
1381
52
83
11
55
19
21
86

 Centos와 Ubuntu의 차이
Apr 14, 2025 pm 09:09 PM
Centos와 Ubuntu의 차이
Apr 14, 2025 pm 09:09 PM
Centos와 Ubuntu의 주요 차이점은 다음과 같습니다. Origin (Centos는 Red Hat, Enterprise의 경우, Ubuntu는 Debian에서 시작하여 개인의 경우), 패키지 관리 (Centos는 안정성에 중점을 둡니다. Ubuntu는 APT를 사용하여 APT를 사용합니다), 지원주기 (Ubuntu는 5 년 동안 LTS 지원을 제공합니다), 커뮤니티에 중점을 둔다 (Centos Conciors on ubuntu). 튜토리얼 및 문서), 사용 (Centos는 서버에 편향되어 있으며 Ubuntu는 서버 및 데스크탑에 적합), 다른 차이점에는 설치 단순성 (Centos는 얇음)이 포함됩니다.
 Centos를 설치하는 방법
Apr 14, 2025 pm 09:03 PM
Centos를 설치하는 방법
Apr 14, 2025 pm 09:03 PM
CentOS 설치 단계 : ISO 이미지를 다운로드하고 부팅 가능한 미디어를 실행하십시오. 부팅하고 설치 소스를 선택하십시오. 언어 및 키보드 레이아웃을 선택하십시오. 네트워크 구성; 하드 디스크를 분할; 시스템 시계를 설정하십시오. 루트 사용자를 만듭니다. 소프트웨어 패키지를 선택하십시오. 설치를 시작하십시오. 설치가 완료된 후 하드 디스크에서 다시 시작하고 부팅하십시오.
 Centos는 유지 보수를 중지합니다. 2024
Apr 14, 2025 pm 08:39 PM
Centos는 유지 보수를 중지합니다. 2024
Apr 14, 2025 pm 08:39 PM
Centos는 2024 년에 상류 분포 인 RHEL 8이 종료 되었기 때문에 폐쇄 될 것입니다. 이 종료는 CentOS 8 시스템에 영향을 미쳐 업데이트를 계속받지 못하게합니다. 사용자는 마이그레이션을 계획해야하며 시스템을 안전하고 안정적으로 유지하기 위해 Centos Stream, Almalinux 및 Rocky Linux가 포함됩니다.
 Docker 원리에 대한 자세한 설명
Apr 14, 2025 pm 11:57 PM
Docker 원리에 대한 자세한 설명
Apr 14, 2025 pm 11:57 PM
Docker는 Linux 커널 기능을 사용하여 효율적이고 고립 된 응용 프로그램 실행 환경을 제공합니다. 작동 원리는 다음과 같습니다. 1. 거울은 읽기 전용 템플릿으로 사용되며, 여기에는 응용 프로그램을 실행하는 데 필요한 모든 것을 포함합니다. 2. Union 파일 시스템 (Unionfs)은 여러 파일 시스템을 스택하고 차이점 만 저장하고 공간을 절약하고 속도를 높입니다. 3. 데몬은 거울과 컨테이너를 관리하고 클라이언트는 상호 작용을 위해 사용합니다. 4. 네임 스페이스 및 CGroup은 컨테이너 격리 및 자원 제한을 구현합니다. 5. 다중 네트워크 모드는 컨테이너 상호 연결을 지원합니다. 이러한 핵심 개념을 이해 함으로써만 Docker를 더 잘 활용할 수 있습니다.
 유지 보수를 중단 한 후 Centos의 선택
Apr 14, 2025 pm 08:51 PM
유지 보수를 중단 한 후 Centos의 선택
Apr 14, 2025 pm 08:51 PM
Centos는 중단되었으며 대안은 다음과 같습니다. 1. Rocky Linux (Best Compatibility); 2. Almalinux (Centos와 호환); 3. Ubuntu 서버 (구성 필수); 4. Red Hat Enterprise Linux (상업용 버전, 유료 라이센스); 5. Oracle Linux (Centos 및 Rhel과 호환). 마이그레이션시 고려 사항은 호환성, 가용성, 지원, 비용 및 커뮤니티 지원입니다.
 Centos 후해야 할 일은 유지 보수를 중단합니다
Apr 14, 2025 pm 08:48 PM
Centos 후해야 할 일은 유지 보수를 중단합니다
Apr 14, 2025 pm 08:48 PM
Centos가 중단 된 후 사용자는 다음과 같은 조치를 취할 수 있습니다. Almalinux, Rocky Linux 및 Centos 스트림과 같은 호환되는 분포를 선택하십시오. Red Hat Enterprise Linux, Oracle Linux와 같은 상업 분포로 마이그레이션합니다. Centos 9 Stream : 롤링 분포로 업그레이드하여 최신 기술을 제공합니다. Ubuntu, Debian과 같은 다른 Linux 배포판을 선택하십시오. 컨테이너, 가상 머신 또는 클라우드 플랫폼과 같은 다른 옵션을 평가하십시오.
 Docker Desktop을 사용하는 방법
Apr 15, 2025 am 11:45 AM
Docker Desktop을 사용하는 방법
Apr 15, 2025 am 11:45 AM
Docker Desktop을 사용하는 방법? Docker Desktop은 로컬 머신에서 Docker 컨테이너를 실행하는 도구입니다. 사용 단계는 다음과 같습니다. 1. Docker Desktop 설치; 2. Docker Desktop을 시작하십시오. 3. Docker 이미지를 만듭니다 (Dockerfile 사용); 4. Docker Image 빌드 (Docker 빌드 사용); 5. 도커 컨테이너를 실행하십시오 (Docker Run 사용).
 VSCODE는 확장자를 설치할 수 없습니다
Apr 15, 2025 pm 07:18 PM
VSCODE는 확장자를 설치할 수 없습니다
Apr 15, 2025 pm 07:18 PM
VS 코드 확장을 설치하는 이유는 다음과 같습니다. 네트워크 불안정성, 불충분 한 권한, 시스템 호환성 문제, C 코드 버전은 너무 오래된, 바이러스 백신 소프트웨어 또는 방화벽 간섭입니다. 네트워크 연결, 권한, 로그 파일, 업데이트 대 코드 업데이트, 보안 소프트웨어 비활성화 및 대 코드 또는 컴퓨터를 다시 시작하면 점차 문제를 해결하고 해결할 수 있습니다.
