

Golang의 자체 HttpClient 시간 초과 메커니즘에 대해 이야기해 보겠습니다.

Go를 작성하는 과정에서 나는 종종 이 두 언어의 특성을 비교하며 많은 함정을 밟았고 많은 흥미로운 부분을 발견했습니다. 이번 글에서는 Go와 함께 제공되는 HttpClient의 시간 초과 메커니즘에 대해 이야기하겠습니다. 모두에게 도움이 될 것입니다.

Java HttpClient 시간 초과의 기본 원칙
Go의 HttpClient 시간 초과 메커니즘을 소개하기 전에 먼저 Java가 시간 초과를 구현하는 방법을 살펴보겠습니다. [관련 권장 사항: Go 동영상 튜토리얼]
Java 네이티브 HttpClient를 작성하고 기본 메서드에 해당하는 연결 시간 초과 및 읽기 시간 초과를 설정합니다.
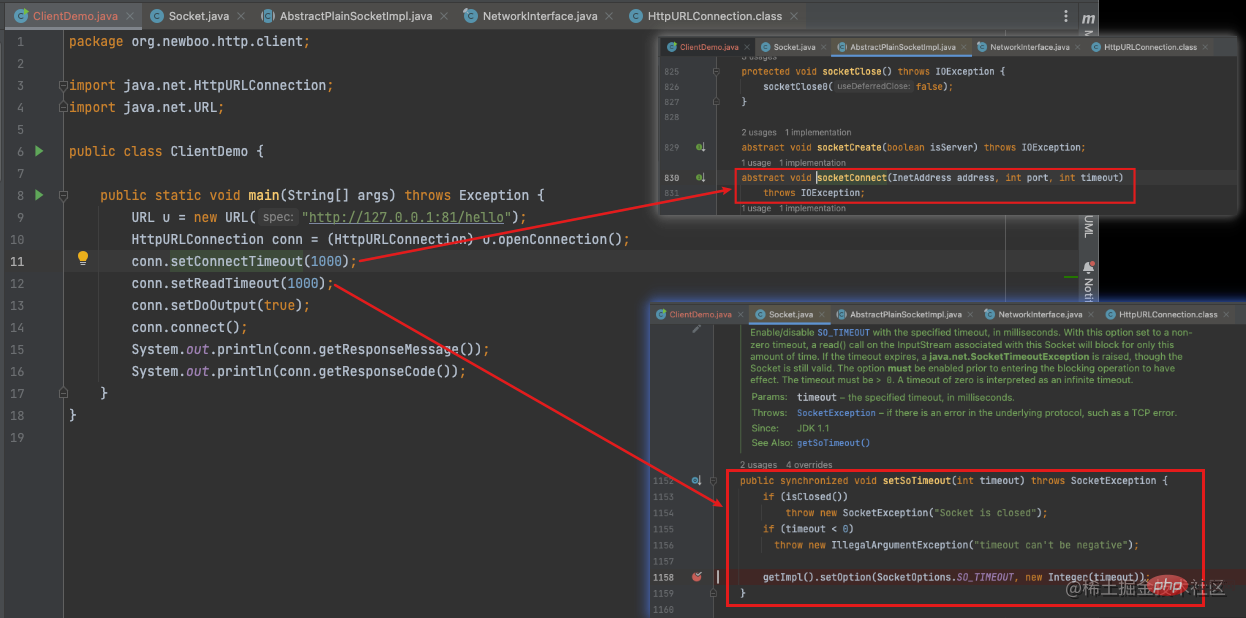
JVM 소스 코드로 돌아가서 올바른 것으로 확인했습니다. 시스템 호출의 캡슐화는 실제로 Java뿐만 아니라 대부분의 프로그래밍 언어가 운영 체제에서 제공하는 시간 초과 기능을 활용합니다.
그러나 Go의 HttpClient는 또 다른 시간 초과 메커니즘을 제공하는데, 이는 매우 흥미롭습니다. 하지만 시작하기 전에 먼저 Go의 Context를 이해해 봅시다.
Go Context 소개
Context란 무엇인가요?
Go 소스 코드의 설명에 따르면:
// 컨텍스트는 마감일, 취소 신호 및 기타 값을 전달합니다. // API 경계. // 컨텍스트의 메소드는 여러 고루틴에 의해 동시에 호출될 수 있습니다.
컨텍스트는 단순히 시간 초과, 취소 신호 및 기타 데이터를 전달할 수 있는 인터페이스입니다.
Context는 Java의 ThreadLocal과 다소 유사합니다. 스레드에서 데이터를 전송할 수 있지만 완전히 동일하지는 않지만 ThreadLocal은 데이터를 전송하는 것 외에도 시간 초과를 수행할 수 있습니다. 그리고 취소 신호.
Context는 인터페이스만 정의하며 Go에서는 몇 가지 특정 구현이 제공됩니다.
- Background: 빈 구현, 아무것도 하지 않습니다.
- TODO: 아직 어떤 Context를 사용해야 할지 모르므로 대신 TODO를 사용하세요. cancelCtx: 취소 가능한 Context
- timerCtx: Active timeout Context
Context 세 가지 기능 예제
예제의 이 부분은src/context/example_test.go
src/context/example_test.go携带数据
使用 context.WithValue 来携带,使用 Value 来取值,源码中的例子如下:
// 来自 src/context/example_test.go
func ExampleWithValue() {
type favContextKey string
f := func(ctx context.Context, k favContextKey) {
if v := ctx.Value(k); v != nil {
fmt.Println("found value:", v)
return
}
fmt.Println("key not found:", k)
}
k := favContextKey("language")
ctx := context.WithValue(context.Background(), k, "Go")
f(ctx, k)
f(ctx, favContextKey("color"))
// Output:
// found value: Go
// key not found: color
}取消
先起一个协程执行一个死循环,不停地往 channel 中写数据,同时监听 ctx.Done() 的事件
// 来自 src/context/example_test.go
gen := func(ctx context.Context) <-chan int {
dst := make(chan int)
n := 1
go func() {
for {
select {
case <-ctx.Done():
return // returning not to leak the goroutine
case dst <- n:
n++
}
}
}()
return dst
}然后通过 context.WithCancel 生成一个可取消的 Context,传入 gen 方法,直到 gen 返回 5 时,调用 cancel 取消 gen 方法的执行。
// 来自 src/context/example_test.go
ctx, cancel := context.WithCancel(context.Background())
defer cancel() // cancel when we are finished consuming integers
for n := range gen(ctx) {
fmt.Println(n)
if n == 5 {
break
}
}
// Output:
// 1
// 2
// 3
// 4
// 5这么看起来,可以简单理解为在一个协程的循环中埋入结束标志,另一个协程去设置这个结束标志。
超时
有了 cancel 的铺垫,超时就好理解了,cancel 是手动取消,超时是自动取消,只要起一个定时的协程,到时间后执行 cancel 即可。
设置超时时间有2种方式:context.WithTimeout 与 context.WithDeadline,WithTimeout 是设置一段时间后,WithDeadline 是设置一个截止时间点,WithTimeout 最终也会转换为 WithDeadline。
// 来自 src/context/example_test.go
func ExampleWithTimeout() {
// Pass a context with a timeout to tell a blocking function that it
// should abandon its work after the timeout elapses.
ctx, cancel := context.WithTimeout(context.Background(), shortDuration)
defer cancel()
select {
case <-time.After(1 * time.Second):
fmt.Println("overslept")
case <-ctx.Done():
fmt.Println(ctx.Err()) // prints "context deadline exceeded"
}
// Output:
// context deadline exceeded
}Go HttpClient 的另一种超时机制
基于 Context 可以设置任意代码段执行的超时机制,就可以设计一种脱离操作系统能力的请求超时能力。
超时机制简介
看一下 Go 的 HttpClient 超时配置说明:
client := http.Client{
Timeout: 10 * time.Second,
}
// 来自 src/net/http/client.go
type Client struct {
// ... 省略其他字段
// Timeout specifies a time limit for requests made by this
// Client. The timeout includes connection time, any
// redirects, and reading the response body. The timer remains
// running after Get, Head, Post, or Do return and will
// interrupt reading of the Response.Body.
//
// A Timeout of zero means no timeout.
//
// The Client cancels requests to the underlying Transport
// as if the Request's Context ended.
//
// For compatibility, the Client will also use the deprecated
// CancelRequest method on Transport if found. New
// RoundTripper implementations should use the Request's Context
// for cancellation instead of implementing CancelRequest.
Timeout time.Duration
}翻译一下注释:TimeoutCarry data
context.WithValue를 사용하여 이를 전달하고 Value를 사용하여 값을 가져옵니다. 소스 코드의 예는 다음과 같습니다. 다음과 같습니다: client := http.Client{
Timeout: 10 * time.Minute,
}
resp, err := client.Get("http://127.0.0.1:81/hello")
먼저 코루틴을 시작하여 무한 루프를 실행하고, 지속적으로 채널에 데이터를 쓰면서 동시에 ctx.Done() 이벤트
// 来自 src/net/http/client.go deadline = c.deadline()
그런 다음 context.WithCancel을 통해 취소 가능한 컨텍스트를 생성하고 gen 메서드를 까지 전달합니다. >gen은 5를 반환하고 cancel을 호출합니다. gen 메서드의 실행을 취소합니다. // 来自 src/net/http/client.go
stopTimer, didTimeout := setRequestCancel(req, rt, deadline)
Cancel을 예로 들면, Timeout은 이해하기 쉽습니다. Cancel은 수동 취소이고 Timeout은 예약된 코루틴인 경우 자동 취소입니다. 시작되면 시간이 다 된 후에 취소를 실행하세요.
🎜시간 초과를 설정하는 방법에는context.WithTimeout 및 context.WithDeadline 두 가지가 있습니다. WithTimeout은 일정 시간 후에 설정되고 WithDeadline은 마감 시점으로 설정됩니다. , WithTimeout은 결국 WithDeadline으로 변환됩니다. 🎜// 来自 src/net/http/client.go
var cancelCtx func()
if oldCtx := req.Context(); timeBeforeContextDeadline(deadline, oldCtx) {
req.ctx, cancelCtx = context.WithDeadline(oldCtx, deadline)
}// 来自 src/net/http/client.go
timer := time.NewTimer(time.Until(deadline))
var timedOut atomicBool
go func() {
select {
case <-initialReqCancel:
doCancel()
timer.Stop()
case <-timer.C:
timedOut.setTrue()
doCancel()
case <-stopTimerCh:
timer.Stop()
}
}()Timeout에는 연결, 리디렉션 및 데이터 읽기 시간이 포함됩니다. 타임아웃 시간 이후 데이터 읽기를 중단합니다. 0으로 설정하면 타임아웃 제한이 없습니다. 🎜🎜즉, 이 시간 초과는 🎜요청의 전체 시간 초과🎜이며, 연결 시간 초과, 읽기 시간 초과 등을 별도로 설정할 필요가 없습니다. 🎜🎜이것은 사용자에게 더 나은 선택일 수 있습니다. 대부분의 시나리오에서 사용자는 시간 초과의 원인이 되는 부분에 대해 신경 쓸 필요가 없지만 HTTP 요청 전체가 언제 반환될 수 있는지 알고 싶어합니다. 🎜🎜🎜🎜시간 초과 메커니즘의 기본 원리🎜🎜🎜🎜가장 간단한 예를 사용하여 시간 초과 메커니즘의 기본 원리를 설명합니다. 🎜这里我起了一个本地服务,用 Go HttpClient 去请求,超时时间设置为 10 分钟,建议使 Debug 时设置长一点,否则可能超时导致无法走完全流程。
client := http.Client{
Timeout: 10 * time.Minute,
}
resp, err := client.Get("http://127.0.0.1:81/hello")1. 根据 timeout 计算出超时的时间点
// 来自 src/net/http/client.go deadline = c.deadline()
2. 设置请求的 cancel
// 来自 src/net/http/client.go stopTimer, didTimeout := setRequestCancel(req, rt, deadline)
这里返回的 stopTimer 就是可以手动 cancel 的方法,didTimeout 是判断是否超时的方法。这两个可以理解为回调方法,调用 stopTimer() 可以手动 cancel,调用 didTimeout() 可以返回是否超时。
设置的主要代码其实就是将请求的 Context 替换为 cancelCtx,后续所有的操作都将携带这个 cancelCtx:
// 来自 src/net/http/client.go
var cancelCtx func()
if oldCtx := req.Context(); timeBeforeContextDeadline(deadline, oldCtx) {
req.ctx, cancelCtx = context.WithDeadline(oldCtx, deadline)
}同时,再起一个定时器,当超时时间到了之后,将 timedOut 设置为 true,再调用 doCancel(),doCancel() 是调用真正 RoundTripper (代表一个 HTTP 请求事务)的 CancelRequest,也就是取消请求,这个跟实现有关。
// 来自 src/net/http/client.go
timer := time.NewTimer(time.Until(deadline))
var timedOut atomicBool
go func() {
select {
case <-initialReqCancel:
doCancel()
timer.Stop()
case <-timer.C:
timedOut.setTrue()
doCancel()
case <-stopTimerCh:
timer.Stop()
}
}()Go 默认 RoundTripper CancelRequest 实现是关闭这个连接
// 位于 src/net/http/transport.go
// CancelRequest cancels an in-flight request by closing its connection.
// CancelRequest should only be called after RoundTrip has returned.
func (t *Transport) CancelRequest(req *Request) {
t.cancelRequest(cancelKey{req}, errRequestCanceled)
}3. 获取连接
// 位于 src/net/http/transport.go
for {
select {
case <-ctx.Done():
req.closeBody()
return nil, ctx.Err()
default:
}
// ...
pconn, err := t.getConn(treq, cm)
// ...
}代码的开头监听 ctx.Done,如果超时则直接返回,使用 for 循环主要是为了请求的重试。
后续的 getConn 是阻塞的,代码比较长,挑重点说,先看看有没有空闲连接,如果有则直接返回
// 位于 src/net/http/transport.go
// Queue for idle connection.
if delivered := t.queueForIdleConn(w); delivered {
// ...
return pc, nil
}如果没有空闲连接,起个协程去异步建立,建立成功再通知主协程
// 位于 src/net/http/transport.go // Queue for permission to dial. t.queueForDial(w)
再接着是一个 select 等待连接建立成功、超时或者主动取消,这就实现了在连接过程中的超时
// 位于 src/net/http/transport.go
// Wait for completion or cancellation.
select {
case <-w.ready:
// ...
return w.pc, w.err
case <-req.Cancel:
return nil, errRequestCanceledConn
case <-req.Context().Done():
return nil, req.Context().Err()
case err := <-cancelc:
if err == errRequestCanceled {
err = errRequestCanceledConn
}
return nil, err
}4. 读写数据
在上一条连接建立的时候,每个链接还偷偷起了两个协程,一个负责往连接中写入数据,另一个负责读数据,他们都监听了相应的 channel。
// 位于 src/net/http/transport.go go pconn.readLoop() go pconn.writeLoop()
其中 wirteLoop 监听来自主协程的数据,并往连接中写入
// 位于 src/net/http/transport.go
func (pc *persistConn) writeLoop() {
defer close(pc.writeLoopDone)
for {
select {
case wr := <-pc.writech:
startBytesWritten := pc.nwrite
err := wr.req.Request.write(pc.bw, pc.isProxy, wr.req.extra, pc.waitForContinue(wr.continueCh))
// ...
if err != nil {
pc.close(err)
return
}
case <-pc.closech:
return
}
}
}同理,readLoop 读取响应数据,并写回主协程。读与写的过程中如果超时了,连接将被关闭,报错退出。
超时机制小结
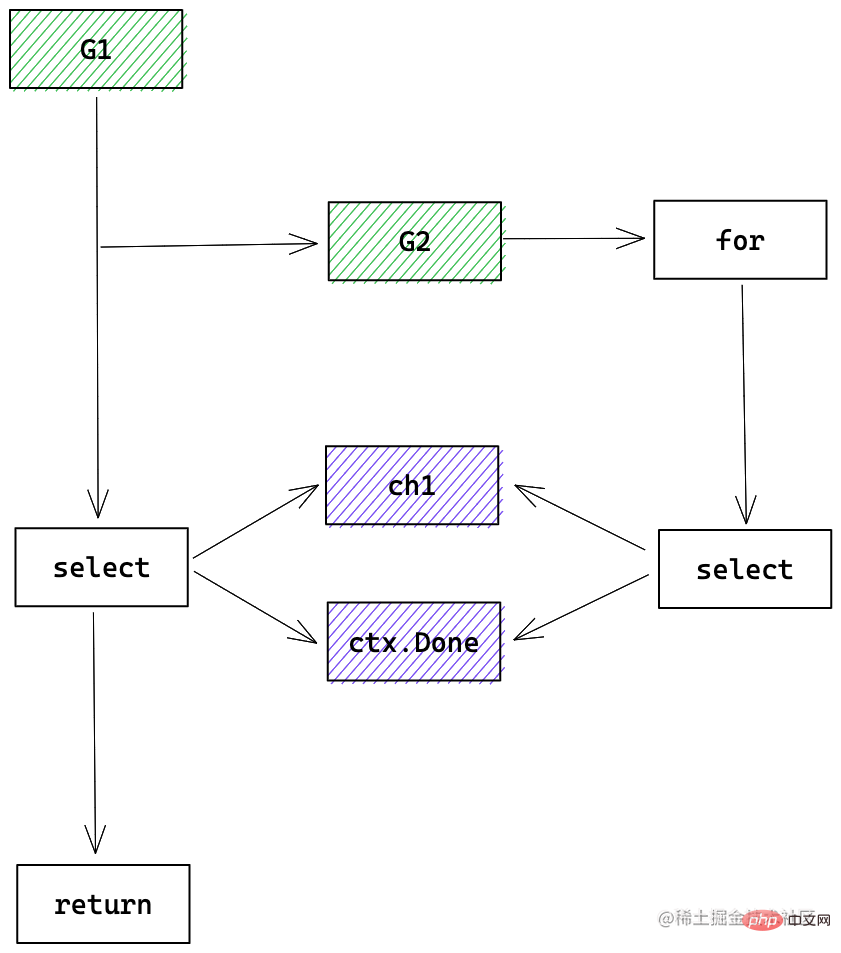
Go 的这种请求超时机制,可随时终止请求,可设置整个请求的超时时间。其实现主要依赖协程、channel、select 机制的配合。总结出套路是:
- 主协程生成 cancelCtx,传递给子协程,主协程与子协程之间用 channel 通信
- 主协程 select channel 和 cancelCtx.Done,子协程完成或取消则 return
- 循环任务:子协程起一个循环处理,每次循环开始都 select cancelCtx.Done,如果完成或取消则退出
- 阻塞任务:子协程 select 阻塞任务与 cancelCtx.Done,阻塞任务处理完或取消则退出
以循环任务为例
Java 能实现这种超时机制吗
直接说结论:暂时不行。
首先 Java 的线程太重,像 Go 这样一次请求开了这么多协程,换成线程性能会大打折扣。
其次 Go 的 channel 虽然和 Java 的阻塞队列类似,但 Go 的 select 是多路复用机制,Java 暂时无法实现,即无法监听多个队列是否有数据到达。所以综合来看 Java 暂时无法实现类似机制。
总结
本文介绍了 Go 另类且有趣的 HTTP 超时机制,并且分析了底层实现原理,归纳出了这种机制的套路,如果我们写 Go 代码,也可以如此模仿,让代码更 Go。
原文地址:https://juejin.cn/post/7166201276198289445
更多编程相关知识,请访问:编程视频!!
위 내용은 Golang의 자체 HttpClient 시간 초과 메커니즘에 대해 이야기해 보겠습니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7493
7493
 15
1377
52
77
11
52
19
19
41
15
1377
52
77
11
52
19
19
41

 Golang을 사용하여 파일을 안전하게 읽고 쓰는 방법은 무엇입니까?
Jun 06, 2024 pm 05:14 PM
Golang을 사용하여 파일을 안전하게 읽고 쓰는 방법은 무엇입니까?
Jun 06, 2024 pm 05:14 PM
Go에서는 안전하게 파일을 읽고 쓰는 것이 중요합니다. 지침은 다음과 같습니다. 파일 권한 확인 지연을 사용하여 파일 닫기 파일 경로 유효성 검사 컨텍스트 시간 초과 사용 다음 지침을 따르면 데이터 보안과 애플리케이션의 견고성이 보장됩니다.
 Golang 데이터베이스 연결을 위한 연결 풀을 구성하는 방법은 무엇입니까?
Jun 06, 2024 am 11:21 AM
Golang 데이터베이스 연결을 위한 연결 풀을 구성하는 방법은 무엇입니까?
Jun 06, 2024 am 11:21 AM
Go 데이터베이스 연결을 위한 연결 풀링을 구성하는 방법은 무엇입니까? 데이터베이스 연결을 생성하려면 데이터베이스/sql 패키지의 DB 유형을 사용하고, 최대 동시 연결 수를 제어하려면 MaxIdleConns를 설정하고, 연결의 최대 수명 주기를 제어하려면 ConnMaxLifetime을 설정하세요.
 Golang 단위 테스트에서 어설션에 gomega를 사용하는 방법은 무엇입니까?
Jun 05, 2024 pm 10:48 PM
Golang 단위 테스트에서 어설션에 gomega를 사용하는 방법은 무엇입니까?
Jun 05, 2024 pm 10:48 PM
Golang 단위 테스트에서 어설션에 Gomega를 사용하는 방법 Golang 단위 테스트에서 Gomega는 개발자가 테스트 결과를 쉽게 확인할 수 있도록 풍부한 어설션 방법을 제공하는 인기 있고 강력한 어설션 라이브러리입니다. Gomegagoget-ugithub.com/onsi/gomega 설치 어설션에 Gomega 사용 다음은 어설션에 Gomega를 사용하는 몇 가지 일반적인 예입니다. 1. 동등 어설션 import "github.com/onsi/gomega" funcTest_MyFunction(t*testing.T){
 Golang 프레임워크 vs. Go 프레임워크: 내부 아키텍처와 외부 기능 비교
Jun 06, 2024 pm 12:37 PM
Golang 프레임워크 vs. Go 프레임워크: 내부 아키텍처와 외부 기능 비교
Jun 06, 2024 pm 12:37 PM
GoLang 프레임워크와 Go 프레임워크의 차이점은 내부 아키텍처와 외부 기능에 반영됩니다. GoLang 프레임워크는 Go 표준 라이브러리를 기반으로 하며 기능을 확장하는 반면, Go 프레임워크는 특정 목적을 달성하기 위해 독립적인 라이브러리로 구성됩니다. GoLang 프레임워크는 더 유연하고 Go 프레임워크는 사용하기 더 쉽습니다. GoLang 프레임워크는 성능 면에서 약간의 이점이 있고 Go 프레임워크는 확장성이 더 좋습니다. 사례: gin-gonic(Go 프레임워크)은 REST API를 구축하는 데 사용되고 Echo(GoLang 프레임워크)는 웹 애플리케이션을 구축하는 데 사용됩니다.
 JSON 데이터를 Golang의 데이터베이스에 저장하는 방법은 무엇입니까?
Jun 06, 2024 am 11:24 AM
JSON 데이터를 Golang의 데이터베이스에 저장하는 방법은 무엇입니까?
Jun 06, 2024 am 11:24 AM
JSON 데이터는 gjson 라이브러리 또는 json.Unmarshal 함수를 사용하여 MySQL 데이터베이스에 저장할 수 있습니다. gjson 라이브러리는 JSON 필드를 구문 분석하는 편리한 방법을 제공하며, json.Unmarshal 함수에는 JSON 데이터를 비정렬화하기 위한 대상 유형 포인터가 필요합니다. 두 방법 모두 SQL 문을 준비하고 삽입 작업을 수행하여 데이터를 데이터베이스에 유지해야 합니다.
 Golang 프레임워크의 오류 처리에 대한 모범 사례는 무엇입니까?
Jun 05, 2024 pm 10:39 PM
Golang 프레임워크의 오류 처리에 대한 모범 사례는 무엇입니까?
Jun 05, 2024 pm 10:39 PM
모범 사례: 잘 정의된 오류 유형(오류 패키지)을 사용하여 사용자 정의 오류 생성 자세한 내용 제공 오류를 적절하게 기록 오류를 올바르게 전파하고 컨텍스트를 추가하기 위해 필요에 따라 오류를 숨기거나 억제하지 않음
 golang 프레임워크의 일반적인 보안 문제를 해결하는 방법은 무엇입니까?
Jun 05, 2024 pm 10:38 PM
golang 프레임워크의 일반적인 보안 문제를 해결하는 방법은 무엇입니까?
Jun 05, 2024 pm 10:38 PM
Go 프레임워크에서 일반적인 보안 문제를 해결하는 방법 웹 개발에서 Go 프레임워크가 널리 채택됨에 따라 보안을 보장하는 것이 중요해졌습니다. 다음은 샘플 코드를 통해 일반적인 보안 문제를 해결하기 위한 실용적인 가이드입니다. 1. SQL 주입 SQL 주입 공격을 방지하려면 준비된 문이나 매개변수화된 쿼리를 사용하세요. 예: constquery="SELECT*FROMusersWHEREusername=?"stmt,err:=db.Prepare(query)iferr!=nil{//Handleerror}err=stmt.QueryR
 Golang 정규 표현식과 일치하는 첫 번째 하위 문자열을 찾는 방법은 무엇입니까?
Jun 06, 2024 am 10:51 AM
Golang 정규 표현식과 일치하는 첫 번째 하위 문자열을 찾는 방법은 무엇입니까?
Jun 06, 2024 am 10:51 AM
FindStringSubmatch 함수는 정규 표현식과 일치하는 첫 번째 하위 문자열을 찾습니다. 이 함수는 일치하는 하위 문자열이 포함된 조각을 반환합니다. 첫 번째 요소는 전체 일치 문자열이고 후속 요소는 개별 하위 문자열입니다. 코드 예: regexp.FindStringSubmatch(text,pattern)는 일치하는 하위 문자열의 조각을 반환합니다. 실제 사례: 이메일 주소의 도메인 이름을 일치시키는 데 사용할 수 있습니다. 예를 들어 이메일:="user@example.com", 패턴:=@([^\s]+)$를 사용하여 도메인 이름 일치를 가져옵니다. [1].
